
Сортировка данных в массиве. Оценка эффективности метода
Содержание:

ВВЕДЕНИЕ
В условиях современного глобализированого мира и бурного развития информационных технологий. Все больше проникает во все сферы, а все данные и информация хранятся на серверах. Для бизнеса и любой другой отрясли поиск информации и обработка данных становится проблемой, а скорость решаюшим фактором. В условиях рыночной экономики потребность ускорения обработки данных привела к созданию алгоритмов и мотодов сортировки.
Для решения проблем связаных с различними поисками конкретной информации среди огромнного количества данныйх было предложено множество различных алгоритмов сортировки: например, слияние с вставкой, обменная поразрядная сортировка, каскадное слияние и метод Шелла, многофазное слияние и вставки в дерево, осциллирующая сортировка и быстрая сортировка Хоара, пирамидальная сортировка Уильямса и обменная сортировка со слиянием Бэтчера. В итоге и произошло интенсивное развитие теории сортировки.
Появившиеся позже алгоритмы во многом являлись вариациями уже известных методов. Они начали распространение как адаптивные методы сортировки, ориентированные на более быстрое выполнение в случаях, когда входные данные удовлетворют заранее установленным критериям.
Актуальность курсовой работы заключается в том, что понимание и моделирование процесса «Сортировки данных в массиве» помогает значитьльно ускорить поиск значений данных в массиве и базе данных.
Цель курсовой работы - разработка регламента выполнения процесса «Оценка эффективности метода».
В связи с поставленной целью решались седующие задачи курсовой работы:
Описать предметную область. Поставить задачи;
Моделирование сортировки данных в массиве;
Сравнение алгаритмов сортировки;
Оценка эфективности алгоритмов.
Обектом исследования является изучение процесса алгоритма сортировки данных, сравнение алгоритмов .
Предметом исследования явлется Сортировка данных в массиве, а так же Оценка эффективности метода.
Структура курсовой работы состоит из введения, двух глав, заключения и списка использованных источников.
Глава 1. Аналитическая часть
1.1 Описание предметной области. Постановка задачи
Для оценки метода будут использованы 3 алгоритма сортировки:
1. Сортировка пузырьком — для каждой пары элемента массива производится обмен, если элементы данных расположены в случайном порядке.
2. Сортировка выбором — ищет наименьшее или наибольшее значение элемента массива и помещяет его в начало или конец упорядоченного списка.
3. Сортировка слиянием — выстраивет первую и вторую половину списка по отдельности , а затем объединяет упорядоченные списки в отсортировоном виде, но требует много дополнительной памяти.
Сам же алгоритм сортировки — это алгоритм для упорядочивания элементов в списке. На данный момент существует множество видов алгаритмов сортировки, таких как: Слиянием, Вставками, Пузырьком, Гномья, Шелла, Пирамидальная, с помощью двоичного дерева, Выбором и т.д.
А массив —это упорядоченный набор данных, используемый для хранения информации одного типа, определяющиеся с помощью одного или нескольких индексов. В обычном распространеном случае массив имеет постоянную длину и хранит единицы данных одного и того же типа.
Массивы могут исользовать различное количество используемых индексов: одномерные массивы это с одним индексом массив, с двумя — двумерными, и т. д. .Одномерные массивы — нестрого соответствуя вектору в математике; двумерные это «строка», «столбец»— матрице. Больше всего используют массивы с одним или двумя индексами; чуть реже — с тремя; все что большее количество индексов — встречается крайне редко.
Алгоритмы сортировки разделяются по своим свойствам и классификациям:
1.Устойчивость — устойчивая сортировка не меняет взаимного расположения элементов с одинаковыми ключами.
2.Естественность поведения —это эффективность метода при обработке уже отсортированый или частично отсортированых данных. Алгоритм ведёт себя естественно, если использовать данную характеристику входной последовательности то работает лучше.
3.Использование операции сравнения. Все алгоритмы, использующие для сортировки сравнений элементов друг с другом, называются основанными на сравнениях. Наименьшая затратность времени и памяти для этих алгоритмов составляет O( n • log n), но они хороши своей возможностью гибкостью применения. Для специальных типов данных существует более эффективные алгоритмы.
Так же к важным свойством алгоритмов относится их сфера применения. Здесь основных типов упорядочения два:
1.Внутренняя сортировка управляет массивами, полностью помещающимися в оперативной памяти с случайным доступом к ячейке в рандомном порядке. Данные массива отсортируются на том же месте без дополнительных расходов ресурсов.
Сейчас во всех архитектурах персональных компьютеров широко используется загрузка и кэширование памяти. Алгоритмы сортировки должены подстраиваться и подходить к применяемыми алгоритмами кэширования и подкачки.
2.Внешняя сортировка манепулирует устройствами используещие большие объёмы памяти, но не с случайным доступом, а с последовательным по упорядоченым файлам, то есть в сейчас «виден» только один элемент массива, а расходы на перемотку по сравнению с памятью слишком велики. Изза чего и получается многие дополнительные ограничения на алгоритм и как результат возникают специальные методы упорядочения, а они в свою очередь используюют дополнительное место в памяти. Кроме этого, доступ к информации на внешней памяти производится медленнее, чем операции с оперативной памятью.
Доступ в массиве осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
Объём данных не дает им возможности разместиться в ОЗУ.
Ещее алгоритмы классифицируются по:
потребности в дополнительной памяти или её отсутствию,
потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, или отсутствию таковой.
Для моделирования сортировки были выбраны 3 алгоритма из разных классификаций и с разными свойствами , для более точногой оценки.
Таким оброзом:
Алгоритмы устойчивой сортировки:
- Сортировка пузырьком
- Сортировка слиянием
Алгоритмы неустойчивой сортировки:
- Сортировка выбором
Формулировка задачи.
Допустим нужно упорядочить N элементов: R1, R2, ……., Rn. Каждый элемент представляет из себя запись Rj, содержащую какието данные и ключ Kj, управляющий процессом сортировки. На множестве ключей определено отношение порядка « < » так, чтобы для всех трёх значений ключей a, b, c выполнялись следующие условия:
-закон трихотомии: либо a < b, либо a > b, либо a = b;
-закон транзитивности: если a < b и b < c, то a < c.
Такие условия определяют математическое понятие линейного или совершенного упорядочения, а удовлетворяющие им множества поддаются сортировке многих методов.
Целью сортировки является нахождение перестановки записей p(1) p(2) … p(n) с индексами {1, 2, … ,N} , после которой ключи расположились бы в порядке неубывания:
Kp(1) ≤ Kp(2) ≤ … ≤ Kp(n)
Сортировка будет устойчивой, если не меняет взаимного расположения элементов с одинаковыми ключами:
p(i) < p(j) для любых Kp(i) = Kp(j) и i < j.
Методы сортировки деляться на внутренние и внешние. Внутренняя сортировка используется для данных, ноходящиеся внутри оперативной памяти, за благодаря чему более гибкая в плане структур данных. Внешняя сортировка используется, когда данные слишком большие и в оперативную память не влезают, а ориентирована она на получение результата в ограниченых условиями ресурсов.
Этот вариант модели, подвергает рецензированию, обсуждению и последующему редактированию, после этого цикл повторяется .
При создание моделей нужно как можно реже использовать изначальную привязку функций изучаемой системы к текушей организационной структуре моделированию алгоритма сортировки. Это поможет избежать субъектной точки зрения, навязанной организацией и ее руководством. Организационная структура должна являться результатом использования модели. Сравнение результата с существующей структурой позволяет:
1. Оценить адекватность модели.
2. Предложить решение, направленные на улучшение данной структуры.
А так же я решил проверить, реально проверяете вы курсовую или просто прогоните через антиплагиат не глядя. Раз вы это читаете, то напишите в коментарии к оценке курсовой об этом, плиз.Чтоб я мог знать стоит ли париться так, если никто не будет читать, Спасибо.
Стрелки, использующиеся в ниней стороне блока, обозначают механизмы, т.е. все то, с помощью чего происходит преобразование входов в выходы. Стрелки, смотрящие вверх, определяют средства, поддерживающие работу функции. Остальные средства вполне способны наследоваться из родительского блока. Стрелки механизма, направленные вниз, это стрелки вызова. Они обозначают отправку запроса из данной модели к блоку, входящему в состав другой модели, связывая их между собой, т.е. разные модели могут вместе использовать один и тот же элемент блока. Тем самым, можно создать алгоритм сортировки в массиве с учетом, что разные пользователи фактически сами определяют скорость и сохраность данных в процессе сортировки.
Память — ряд алгоритмов просит выделеть дополнительную память под временное хранение данных. В большей части, эти алгоритмы требуют O(log n) памяти. При оценивание этого метода не учитывается место, которое занимает исходный массив и независящие от входной последовательности затраты, например: на хранение кода программы ,потому что это потребляет O(1). Алгоритмы сортировки, не ипользуещие дополнительной памяти, относят к сортировкам на месте.
Цель сортировки в общем случае подрозумевает, что единственной обязательной операцией наличее которой обезательно для элементов является сравнение. Изза этого невозможна реализацая алгоритма Хана, применяющий арифметические действия. Если посмотреть на схему алгоритма, когда единственное возможное действие над элементами является их сравнение.
Если в результате работы алгоритмом выполняется k сравнений. Ответом на сравнение этих элементов a и b может быть один из двух вариантов (a<b или a>b). Тоесть, всего возможно 2k варианта комбинаций ответа на k вопросов.
Количество изменений из n элементов равно n!. Чтобы можно было провести сюръекцию из множества ответов на сравнения на множество перестановок, количество сравнений должно больше, чем log2n!, это необходимо так как единственная разрешённая операция сравнение.
1.2. Моделирование сортировки данных в массиве.
В курсовом проекте я рассматриваю сортировку данных в массиве , исмользуя для сравнения 3 алгорима.
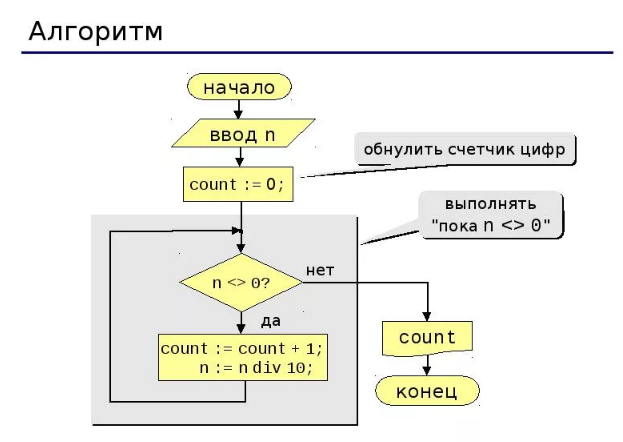
1.Первый алгоритм «Сортировка пузырьком». Отличительной чертой этого алгоритма является в следующем: как только он пройдет первый внутрений цикл, то наибольший элемент массива всегда будет находится на Х-ой точке. На втором круге цикла, следующий по значению наибольший элемент встанет на Х-1 точку, и т.д. Тем самым, при каждом круге цикла, каждое последуйщее наибольший элемент будет уменьшается на 1 и небудет потребности «проходить» весь массив каждый раз по новой.
В результате, раз подмассиву из одного элемента не нужно проходить сортировку, то для сортировки нужно применять менее Х-1 итераций внешнего цикла. Изза этого иногда в реализациях внешний цикл выполняется ровно Х-1 и не отслеживается, выполнение обмена на каждой итерации.
Если добавить индикатор флажка Е то это сильно снизит произходящие во внутреннем цикле обменов число избыточных повторов цикла в случаях с отчасти отсортированными элементами массива на входе. При каждом повторе по внутреннему циклу флажок переходит в 0, а потом снова переходит в 1, но только после круга цикла. Если же после завершение внутреннего цикла флажок равен 0, значит перестановок в масиве не было, то есть массив был отсортирован и можно завершить циклы сортировки.
Пример кода более улучшего алгоритма с уже проверкой выполненых перестановок во внутреннем цикле алгоритма массива.
На входе: массив A[N], состоящий из N элементов, с числами от A[1] до A[N]

Пример кода алгоритма сортировки 1. Цикл.
Если цикл выходит раньше из сортировки в этом алгоритме, то он сделает еще один проверочный круг без изменений массива.
Случаи когда не улучшается:
Количество сравнений в теле цикла равно (N-1) N÷2.
Количество сравнений в заголовках циклов (N-1) N÷2.
Общее количество сравнений равно (N-1)N.
Количество присваиваний в заголовках циклов равно (N-1) N÷2..
Количество обменов равно (N-1) N÷2.
Наилучший случай (улучшается):
Количество сравнений в теле цикла равно (N-1).
Количество сравнений в заголовках циклов (N-1).
Общее количество сравнений равно 2(N-1).
Количество обменов равно 0.
Время сортировки 10000 минемальных целых чисел в одной програмной операций, это среднее значение операции сравнения ≈3.4мкс, и обмена ≈2.3мкс, сортировкой выбором получится ≈40сек., ещё бысрее сортировка пузырьком ≈30сек, а быстрой сортировкой ≈0,027сек.
O(n • n) по больше O(n • log n) в сортировки слиянием, но при не больших n разброс не сильно отличается, а структура программы проста, что позволяет использовать сортировку пузырьком для множества задач с массивами небольшой размерности.

Пример кода алгоритма сортировки 2. Массив.
С

Пример кода алгоритма сортировки 3.Постороение програмы.
Пример работы алгоритма:
Пример массива с числами «6 2 5 3 9» и отсортируем элементы по возрастанию, используя сортировку пузырьком. Выделены те элементы, которые сравниваются на данном этапе.
Первый проход:
(6 2 5 3 9) (2 6 5 3 9), Тут алгоритм сопоставляет оба первых элемента и меняет их местами.
(2 6 5 3 9) (2 5 6 3 9), Производим процедуру замены, потому что 5>4
(2 5 6 3 9) (2 5 3 6 9), Производим процедуру замены, потому что 6>3
(2 5 3 6 9) (2 5 3 6 9), Тут замены не происходит изза того что числа стоят на своих позициях (9>6), алгоритм не меняет их местами.
Второй проход:
(2 5 3 6 9) (2 5 3 6 9)
(2 5 3 6 9) (2 3 5 6 9), Меняет местами, потому что 5>3
(2 3 5 6 9) (2 3 5 6 9)
Тут массив полностью отсортирован, но алгоритм не знает об этом. Чтобы понять это, алгоритму придется пройти весь список и понять, что замены чесел не было.
Третий проход:
(2 3 5 6 9) (2 3 5 6 9)
(2 3 5 6 9) (2 3 5 6 9)
Теперь массив отсортирован и алгоритм может быть завершён.
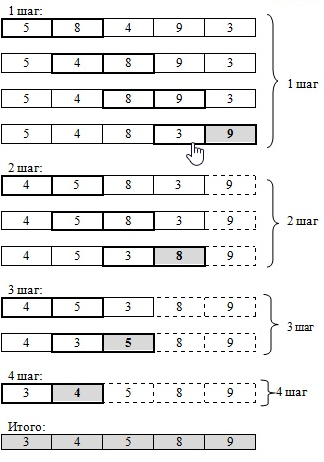
На Рис.1.Пример наглядной демонстрации алгоритма.
Во всех примерах алгоритма есть недостаток: при каждом повторе цикла длина проходимого участка снижается на один, в то время как следующий повтор доходит до места последней замены.
Глава 2. Проектная часть
2.1.Второй алгоритм «Сортировка выбором».
Алгоритм «Сортировка выбором» - этот алгоритм не выделяет дополнительной памяти.
Шаги алгоритма:
1.Находит элемент наименьшено значения в данном списке
2.Заменяет этот элемент с элементом значения первой неотсортированной позиции , но замена не происходит, если этот элемент и так в начале списпа.
3.Сортируем конец списка, пропуская из анализа уже отсортированные элементы.
Для реализации устойчивости алгоритма необходимо в пункте 2 минимальный элемент непосредственно вставлять в первую неотсортированную позицию, не меняя порядок остальных элементов.
void SelectionSort (int k,int x[max]) {
int i,j,min,temp;
for (i=0;i<k-1;i++) {
min=i; //устанавливаем начальное значение наименьшего индекса
for (j=i+1;j<k;j++){ //находим наименьший индекс элемента
if (x[j]<x[min])
min=j; } //меняем значения местами
temp=x[i]; x[i]=x[min];
x[min]=temp; }
Пример неустойчивой реализации на C++ :

Пример неустойчивой реализации на Java:

Пример, почему данная вариация получается неустойчивой.
Представим массив из значений, каждый из них имеет два поля. Сортировка проходит по первому полю.
Массив до сортировки:
{ (2, a), (2, b), (1, a) }
После первой реализации цикла получим отсортированную последовательность:
{ (1, a), (2, b), (2, a) }
Оротим внимание, что элементы расположены взаимно (2, a) и (2, b) поменялось. Тем самым, рассмотренная реализация получелась неустойчивой.
Потому что после каждого оборота по внутреннему циклу происходит только одина замена, то общее число замен равно N-1, что в N/2 раз меньше, чем в сортировке пузырьком.
Количество проходов по внутреннему циклу равно N-1 даже в случае сортировки частично или полностью отсортированного массива.
Наихудший случай:
Количество сравнений в теле цикла равно (N-1)*N/2.
Количество сравнений в заголовках циклов (N-1)*N/2.
Количество сравнений перед операцией обмена N-1.
Суммарное количество сравнений N2−1.
Количество обменов N-1.
Наилучший случай:
Время сортировки 10000 минемальных целых чисел в одной програмной операций, это среднее значение операции выбором составило ≈40сек., а ещё более улучшенной сортировкой пузырьком ≈30сек.
Пирамидальная сортировка значительно улучшает изначальный алгоритм, применяя структуру данных «куча» для ускорения нахождения и удаления наименьшго элемента.
Так же есть двунаправленный вариант сортировки методом выбора, в этом случае на каждом круге находятся и перемещяются на свои места и наименьшее, и наибоьшее значения.

Рис. 2. Демонстрация сортировки по неубыванию методом простого выбора.
Так и в пузырьковой сортировке, внешний цикл исполняется n-1 раз, а внутренний – в среднем n/2 раз. Отсюда, для сортировки методом простого выбора нужно
сравнений. Тем самым, этого порядка алгоритма n2, вследсвие чего он становится очень медленным для сортировки больших количеств элементов. Независемо от того, что сравнение в пузырьковой и сравнение простым выбором имеют одинаковое количество, во втором случаее количество замен в среднем случае гараздо меньше, чем в пузырьковой сортировке.

Рис.3. Демонстрация сортировки по неубыванию методом простого включения.
2.2.Третий алгоритм «Сортировка слиянием».
Сортировка слиянием— алгоритм сортировки, упорядочивает списки или другие структуры данных, доступ к элементам чьих получаеться только последовательно, пример — потоки, в определённом порядке. Этот алгоритм — работает по принципу «разделяй и властвуй». Первым делом задача разделятся на несколько меньших по размерам задачи. Потом они вычесляются с помощью рекурсивного вызова или не посредственно, если они достаточно маленькие. В конеце, решения обьединяются, и выходит результат изначальной задачи.
Пример решения задачи в эти три этапа:
1. Массив сортируемого элемента разделяется попалам на равные размеры;
2.Каждая из половинок массива сортируется по отдельности, то есть — тем же способом;
3.Обе отсортированые половинки массива обьединяются в один.
2.1. Рекурсивное деление пополам задачу повторяется, пока размер массива не дойдет до одного, каждый массив длиной 1 должен считать отсортированым.
3.1. Обьединение половинок отсортированых массивов в один.
Принцеп идеи слияния двух упорядоченых массивов можно показать на примере. Допустим у нас есть уже отсортированные половинки массива по неуменьшение подмассива. Получется:
3.2. Слияние половинок подмассива в один результирующий массив.
При каждом шаге алгорит берёт наименьший из двух первых элементов подмассива и записывает его в результирующий массив. Счётчик номера элемента результирующего массива и половины массива, из которого взяли элементы, увеличивае на единицу.
3.3. «Прицепление» остатка.
После оконьчния одного из подмассивов , алгоритм добавит всё содержимое второго подмассива в главный массив.
Разница между пузырьковой сортировкой и сортировкой простым выбором, число соостовлений в сортировкой вставки зависит от первоначального отсортироного списка. Если же список уже упорядочен, число сапостовлений получется n-1 ; иначе его скорость будет равна величине порядка n2.
Алгоритм придумал Джон фон Нейман в 1945 году.
В примере алгоритма на C++ языке выполняется проверка на равенство обоих сравниваемых содержимого подмассива с отличным блоком обработки если они равны. Дополнительная проверка на идентичность увеличевает число сравнений, это увеличивает количества кода программы. Что бы не усложнять программу дополнительными проверками в случаях равенства нужно применять две проверки if(L <= R) и if(L >= R), это в разы снижает колличество кода программы.
Пример быстрого алгоритма слияния без остатка на C++ :


Продолжительность выполнения алгоритма O(n * log n) если не будет деградации на неудачных попытках, что получается уязвимой часть быстрой сортировки , тот же алгоритм O(n * log n), но только для среднего случая. Памяти тратит больше, нежели для быстрой сортировки, в условиях более удобных паттерне выделения памяти — можно выделить часть сектора памяти в начале и не выделять в дальнейшем исполнении кода.
Такой реализации нужно однократное разделание временни буфера памяти, соответсвующяя сортируемому массиву, и нет рекурсии. Шаги реализации:
InputArray = сортируемый массив, OutputArray = временный буфер
В каждом части входящего массива InputArray[N * MIN_CHUNK_SIZE..(N + 1) * MIN_CHUNK_SIZE] исполняется какой либо бополнительный алгоритм сортировки, пример: сортировка Шелла или быстрая сортировка.
вставляется ChunkSize = MIN_CHUNK_SIZE
обьяденяются обе половины: InputArray[N * ChunkSize..(N + 1) * ChunkSize] и InputArray[(N + 1) * ChunkSize..(N + 2) * ChunkSize] поочередно шагами слева и справа (см. выше), результат вставляется в OutputArray[N * ChunkSize..(N + 2) * ChunkSize], и так для всех N, до завершения массива.
ChunkSize удваивается
если ChunkSize получил >= размера массива, то ответ в OutputArray, который изза изменение в массиве получется отредактированный массив, или временный буфер,в другом случае масив полностью копируется в редактируемй массив.
В ином случае меняем местами InputArray и OutputArray перестановкой указателей, и повторям с пункта 4.
Этот способ так же позволяет размещять упорядочиваемого массива и временного буфера в секорах данныйх памяти, значит можно сортировать огромные объёмы данных. Реализация ORDER BY в СУБД MySQL если нет подходящего индекса утановлна таким оброзом источник: filesort.cc в исходном коде MySQL.
Устойчивость - сохраняется порядоке равных элементов находящиеся в одном классе эквивалентности по сравнению.
Псевдокод более быстрого алгоритма слияния без «прицепления» остатка на C++ языке:

Пример реализации алгоритма простого двухпутевого слияния на псевдокоде:

Достоинства:
Способен работать на структурах данных последовательного доступа.
Хорошо сочетается с подкачкой и кэшированием памяти.
Неплохо работает в параллельном варианте: легко разбить задачи между процессорами поровну, но трудно сделать так, чтобы другие процессоры взяли на себя работу, в случае если один процессор задержится.
Не имеет «трудных» входных данных.
Две операции пересылки в переменные L и R упрощают некоторые записи в программе, что может оказаться полезным в учебных целях, но в действительных программах их можно удалить, что сократит программный код. Также можно использовать тернарный оператор, что еще больше сократит программный код.
Пример сортировки на языке С:

Недостатки:
На «почти отсортированных» массивах работает столь же долго, как на хаотичных. Существует вариант сортировки слиянием, который работает быстрее на частично отсортированных данных, но он требует дополнительной памяти, в дополнении ко временному буферу, который используется непосредственно для сортировки.
Требует дополнительной памяти по размеру исходного массива.
ЗАКЛЮЧЕНИЕ
В процессе курсовго исследования была достигнута цель работы - Оценка эффективности метода сортировки в массиве.
А так же решены следующие задачи:
1) Описана предметная область. Поставленны задачи;
2) Смоделированы методы сортировки данных в массиве алгоритмами: «Сортировка выбором»,
«Сортировка пузырьком»,
«Сортировка слиянием».
3)Проведены сравнения меодов сортировки.
4) Определена оценка эфективнось методов;
Моделирование алгоритмов сортировки в массиве позволяет проанализировать как работает метод в целом, но и как организована деятельность на каждом отдельно взятом месте массива.
Алгоритмы сортировки оцениваются по скорости выполнения и эффективности использования памяти:
Время — главный параметр, характеризующий быстродействие алгоритма. Используется так же вычислительная сложность. Для сортировки важные худшей, средней и лучшей поведения алгоритмов в терминах мощности входного множества A. Когда в начале алгоритма даётся множество A, то обозначаем n = |A|. Для обычного алгоритма нормальное решение — это O(n log n) а плохое решение — это O(n2). Отличным же будет сотрировка — O(n). Алгоритм сортировки, применяющий лишь абстрактную операцию сравнения ключей все время должен как минемум сравнивать их. Но при этом, есть алгоритмы сортировки Хана (Yijie Han) с вычислительной сложностью O(n log log n log log log n), применяющий факт, того что пространства ключей ограничены, это очень сложено, а за О-обозначением сокрыт большой коэффициент, изза чего его нельзя использовать повседневно практике. Так же есть понятие сортирующих сетей. Считающие, что можно одновременно пример, при параллельном вычислении, использовать несколько сравнений, можно редактировать n колличество за O(log2 n) операций. Но колличество n должно быть обозначено изначально;
Память —в ряде алгоритмов требуется дополнительная память для временного хранение данных. Обычно они просят O(log n) памяти. При этом не считается место, уже занятое исходным массивом и независящие от входной последовательности расходов, пример: хранение кода программы потому что это занимает O(1). Алгоритм сортировки, не использующие дополнительную память, относят к сортировкам на месте.
Цели данной работы - проведение анализа процесса «Проведение оценки методов». выполнены. В результате моделирования и сравнения , наилучшим алгоритмом оказался: «Сортировка пузырьком». Но при всем этом алгоритмы
«Сортировка выбором» и «Сортировка слиянием», так же эфективны незначительно уступив пузрьковой сортировке. Сформированы рекомендации по повышению эффективности процесса и усилению информационного обеспечения принимаемых решений.
Выполнение данной курсовой работы дало мне навык работы с методами логистического анализа, и навыки применения методов сортировки.
Список использованных источников
- Методология функционального моделирования Р.50.1.028-2001
- Гаджинский А.М. логистика. - М.: Издательско-торговая корпорация "Дашков и К", 2013.
- Сергеев В.И. Логистика в бизнесе: Учебник. - М.: ИНФА-М, 2011.
- Миротин Л.Б., Логистика для предпринимателя. - М.: ИНФА-М, 2013.
- Голиков Е.А. Маркетинг и логистика - новые инструменты хозяйствования: Учебник. Пособие. - М.: Издательство "Экзамен", 2016.
- Логистика. / ИМИР. - Екатеринбург, 2013.
- Елиферов В. Г. Бизнес-процессы. Регламентация и управление / В. Г. Елиферов, В. В. Репин. – М.: ИД "ИНФРА-М", 2009. – 320 с.
- Рубцов С. В. Уточнение понятия "бизнес-процесс" // Менеджмент в России и за рубежом / Рубцов С. В. – 2001. – № 6. – С. 24–27.
- Николайчук В.Е. Логистический менеджмент 2-е издание. - М.: Издательско-торговая корпорация «Дашков и К», 2012. - 980 с.
- Бауэрсокс Д. Логистика. Интегрированная цепь поставок / Д. Бауэрсокс, Д. Клосс. – М.: ЗАО «Олимп-Бизнес», 2010. – 640 с.
- Гаджинский А.М. Логистика / А.М. Гаджинский. – М.: Дашков и К, 2012. – 484 с.
- Сергеев В.И. Управление качеством логистического процесса / В.И. Сергеев // Логистика сегодня. - 2010. - № 1. - С. 10-16.
- Модели и методы теории логистики: Учебное пособие. 2-е изд. / Под ред. В.С.Лукинского.-СПб:Питер.2008.- 448 c.
- Сток Д. Стратегическое управление логистикой / Д. Сток, Д. Ламберт. – М.: Инфра-М, 2011. – 830 с.
- Хаммер М. Реинжиниринг корпорации: манифест революции в бизнесе: Пер. с англ. / М. Хаммер, Дж. Чампи Дж. – М. : Изд-во «Манн, Иванов и Фербер», 2006. – 287 с.
- Робсон М. Практическое руководство по реинжинирингу бизнес-процессов / М.: Робсон, Ф. Уллах : пер. с англ. / под ред. Н.Д. Эриашвили. – М. : Изд-во "Аудит", ЮНИТИ, 2007. – 224 с.
- Стандарты IDEF. Электронный ресурс. Режим доступа www.igef.ru.
- Маклаков С. В. BPwin и ERwin: CASE-средства для разработки.
- Устойчивая - сохраняет порядок равных элементов (принадлежащих одному классу эквивалентности по сравнению).
- Кормен, Т., Лейзерсон, Ч., Ривест, Р., Штайн, К. Алгоритмы: построение и анализ.
- Видео лекция курсы Гарварда и Еля SC50 за 2015г.

- Нотариат в РФ (История осуществления нотариальной деятельности в России)
- Виды договоров.(Понятие договора, значение классификаций)
- Эволюция форм и видов денег (Генезис происхождения денег)
- Международный валютный фонд: цели, функции, особенности (МВФ: СОЗДАНИЕ, СУЩНОСТЬ, ОСНОВНЫЕ ФУНКЦИИ)
- Право требования и его передача третьему лицу (Правовая природа уступки права требования)
- Понятие и виды наследования (История становления наследственного права)
- Оценка и анализ состава и структуры активов банка, а также разработка мероприятий по совершенствованию структуры активов
- Банковская система, её элементы и важнейшие свойства
- Финансовая политика и её реализация в РФ (Глава 1. Теоретические основы и задачи финансовой политики)
- Маркетинговые исследования
- Варианты архитектуры клиент-сервер (Глава 1. Аналитическая часть)
- Разработка регламента выполнения процесса «Проведение оценки качества» (Глава 1. Аналитическая часть)