
Операции, производимые с данными.
Содержание:

ВВЕДЕНИЕ
Получение и использование информации тесно связано с операциями над данными, поэтому имеет смысл более подробно рассмотреть эту тему. В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. В структуре возможных операций с данными можно выделить следующие операции:
Сбор данных — это деятельность субъекта по накоплению данных с целью обеспечения достаточной полноты. Соединяясь с адекватными методами, данные рождают информацию, способную помочь в принятии решения. Например, интересуясь ценой товара, его потребительскими свойствами, мы собираем информацию для того, чтобы принять решение: покупать или не покупать его.
Передача данных — это процесс обмена данными. Предполагается, что существует источник информации, канал связи, приемник информации и между ними приняты соглашения о порядке обмена данными, эти соглашения называются протоколами обмена. Скорость передачи информации измеряется в бодах (1 бод = 1 бит/с).
Хранение данных — это поддержание данных в форме, постоянно готовой к выдаче их потребителю. Одни и те же данные могут быть востребованы неоднократно, поэтому разрабатывается способ их хранения (обычно на материальных носителях) и методы доступа к ним по запросу потребителя.
Обработка данных — это процесс преобразования информации от исходной ее формы до определенного результата. Сбор, накопление, хранение информации часто не являются конечной целью информационного процесса. Чаще всего первичные данные привлекаются для решения какой-либо проблемы, затем они преобразуются шаг за шагом в соответствии с алгоритмом решения задачи до получения необходимых выходных данных.
Данные могут быть представлены следующими видами:
- числовые
- логические
- текстовые
- графические
Далее мы рассмотрим операции над различными видами данных. Также рассмотрим структуры данных, т.к. работа с большими объемами данных становиться при их использовании более эффективной. И для полноты картины уделим внимание единицам хранения данных.
2. ОБЩЕЕ ПРЕДСТАВЛЕНИЕ ДАННЫХ
Любая ЭВМ предназначена для обработки, преобразования и хранения данных. Для выполнения этих функций ЭВМ должна обладать некоторым способом представления этих данных. Представление данных заключается в их преобразовании в вид, удобный для последующей обработки либо пользователем, либо ЭВМ. Форма представления данных определяется их конечным предназначением. В зависимости от этого данные имеют внутреннее и внешнее представление (см. рис. 1.2).
Внутреннее представление данных определяется физическими принципами, по которым происходит обмен
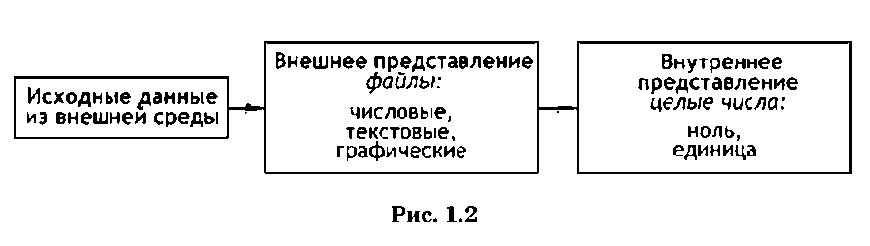
сигналами между аппаратными средствами компьютера, принципами организации памяти, логикой работы ЭВМ. Любые данные для обработки ЭВМ представляются последовательностями двух целых чисел — единицы и нуля. Такая форма представления данных получила название двоичной.
Во внешнем представлении (для пользователя) все данные хранятся в виде файлов.
Файл — область памяти на внешнем носителе, которой присвоено имя.
Простейшими способами внешнего представления данных являются:
• вещественные и целые числа (числовые данные);
• последовательность символов (текст);
• изображение (графика, фотографии, рисунки, схемы).
Важным понятием при представлении данных в компьютерах является понятие системы счисления.
Система счисления — это способ наименования и представления чисел с помощью символов, имеющих определенные количественные значения. В зависимости от способа представления чисел системы счисления делятся на непозиционные и позиционные.
В непозиционных системах цифры не меняют своего количественного значения при изменении их расположения в числе. В римской непозиционной системе в качестве цифр используются: 1(1), V (5), Х(10), L(50), С (100), D(500), М (1000). Величина числа в римской системе счисления определяется так: если меньшая цифра стоит слева от большей, то она вычитается, если справа — прибавляется. Например, десятичное число 1998 в римской системе исчисления будет выглядеть следующим образом:
MCMXCVIII = 1000 + (1000 - 100) + (100 - 10) 4-54-1 + 1 + 1 = 1998.
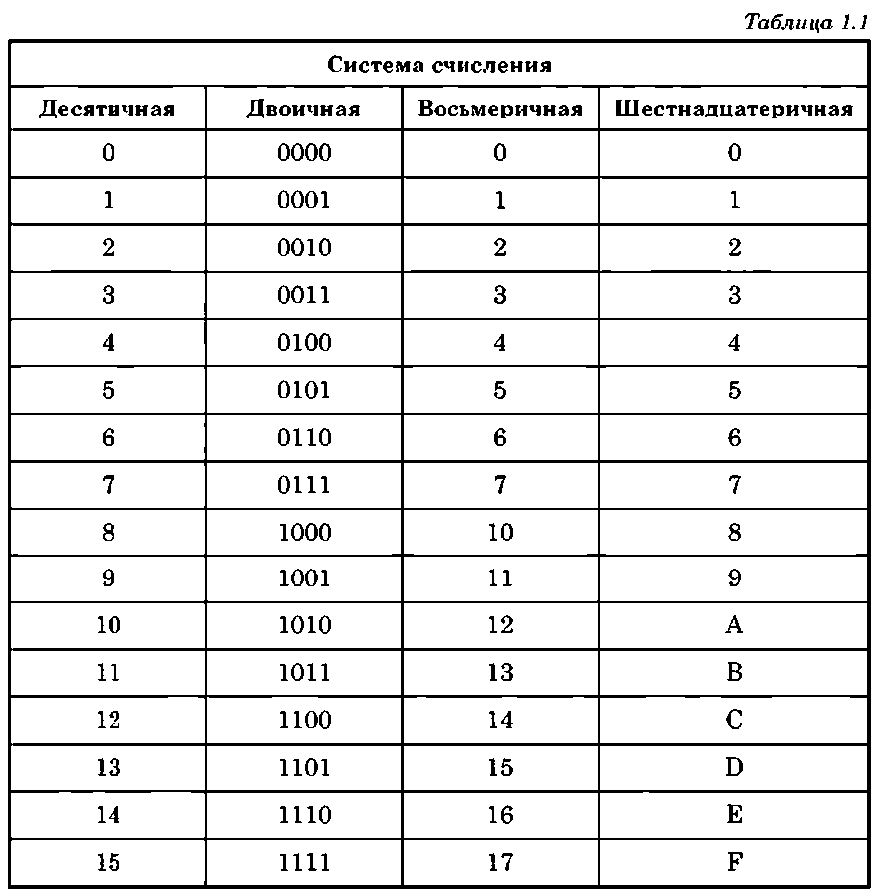
В позиционных системах количественное значение каждой цифры зависит от места (позиции) в числе. Примером позиционной системы является арабская десятичная система, а также двоичная и шестнадцатеричная системы, применяемые в ЭВМ. Шестнадцатеричная система счисления оказалась востребованной программистами из-за более компактного представления чисел по сравнению с двоичной системой. Иногда для представления данных используется восьмеричная система счисления.
3. ПРЕДСТАВЛЕНИЕ ЧИСЛОВЫХ ДАННЫХ. ОПЕРАЦИИ НАД ЧИСЛОВЫМИ ДАННЫМИ.
Количество используемых символов определяет название системы счисления (см. табл. 1.1): двоичная — два (О и 1); восьмеричная — восемь (0, 1, 2, 3, 4, 5, 6, 7); десятичная — десять (0-9); шестнадцатеричная — шестнадцать (0-9, A-F).
В общем случае любое число X в позиционной системе исчисления с основанием Q может быть представлено в развернутой форме
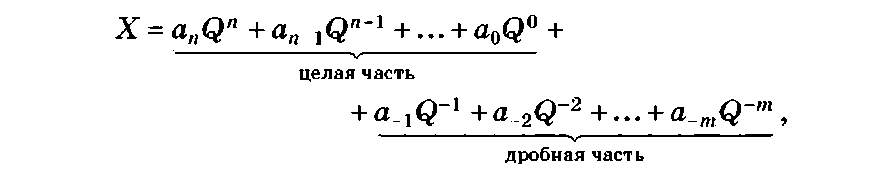
где коэффициенты а. — целые числа в интервале [О, Q - 1], i = п, п - 1, 1,0, -1, ..., -т.
Числа принято представлять в виде последовательности коэффициентов, называемой свернутой формой:
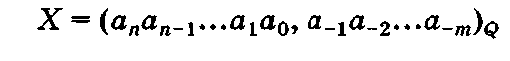
с указанием основания Q системы счисления.
Пр и м е р 1.4. Запишем числа в развернутой (а) и свернутой (б) формах:
• в двоичной системе (Q = 2):
а) Х2 = 1 х 22 + 0 х 21 + 1 х 2° + 0 х 2'1 + 1 х 2"2,
б) Х2 = 101,012;
• в десятичной системе (Q = 10):
а) Х10 = 3 х Ю2 + 0 х 101 + 6 х 10° + 2 х 10*1 + 5 х 10 2,
б) Х10 = 306,2510;
• в восьмеричной системе (Q = 8):
а) Х8 = 2 х 82 + 3 х 81 + 1 х 8° + 4 х 81 + 6 х 8"2,
б) Х8 = 231,468;
• в шестнадцатеричной системе (Q = 16):
а) Х16 = 7 х 162 + В х 161 + D х 16° + 3 х 16"1 + А х 16'2,
б) Х16 = 7BD,3A16.
Если выразить шестнадцатеричные цифры через их десятичные значения (В = 11, D = 13, А = 10), то развернутая форма числа примет вид
Х1в = 7 х 162 + 11 х 161 + 13 х 16° + 3 х 16'1 + 10 х 16“2.
3.1. ПЕРЕВОД ЧИСЕЛ В ПОЗИЦИОННЫХ СИСТЕМАХ СЧИСЛЕНИЯ
Перевод чисел в десятичную систему. Преобразование чисел, представленных в двоичной, восьмеричной и шестнадцатеричной системах счисления, выполняется так: число записывается в развернутой форме и вычисляется его значение.
Пример 1.5. Перевести числа в десятичную систему.
Из двоичной системы число 10,112:
10,112 = 1 х 21 4- 0 х 2° 4-1 х 2'1 4- 1 х 2'2 = 2,7510.
Из восьмеричной системы число 67,58:
67,58 = 6 х 81 + 7 х 8° + 5 х 8"1 = 55,62510.
Из шестнадцатеричной системы число 19F16:
19F16 = 1 х 162 + 9 х 162 + F х 16° =
= 1 х 256 + 9 х 16 + 15 х 1 = 41510.
Перевод чисел в системах счисления с разными основаниями. Перевод числа X из системы счисления с основанием Q в систему счисления с основанием К выполняется путем нахождения остатков от деления числа X на основание К.
Процесс деления продолжается до тех пор, пока частное от деления не будет меньше основания К. Полученные остатки записываются в обратном порядке.
П р и м е р 1.6. Перевести число 2710 в двоичную систему. Для обозначения остатков будем использовать цифры числа в свернутой форме aAa3a2aia0.
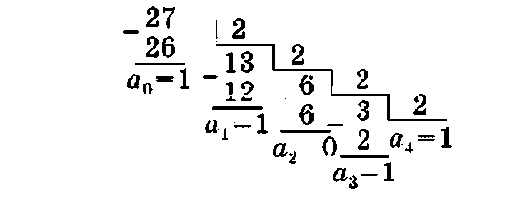
Ответ: 2710 = (a4asa2ala0)2 = 110112.
Пример 1.7. Перевести десятичное число 31810 в восьмеричную и шестнадцатеричную системы.
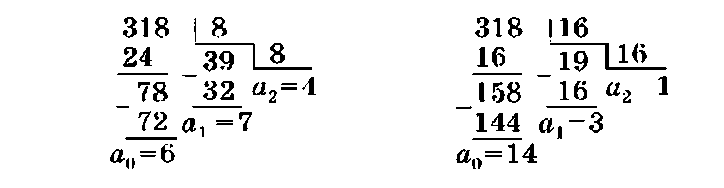
Ответ: 31810 = {а2аха0)& = 4 768; 31810 = (а2ага0)16 = 13Е1б.
Перевод десятичных дробей в другие системы счисления. Последовательность действий при переводе десятичной дроби следующая.
1. Последовательно умножать десятичную дробь и получаемые дробные части произведений на основание новой системы счисления до тех пор, пока дробная часть произведения не станет равной нулю или не будет достигнута требуемая точность вычисления.
2. Записать полученные целые части произведения в прямом порядке.
П р и м е р 1.8. Перевести десятичную дробь 0,1875 в двоичную, восьмеричную и шестнадцатеричную системы.
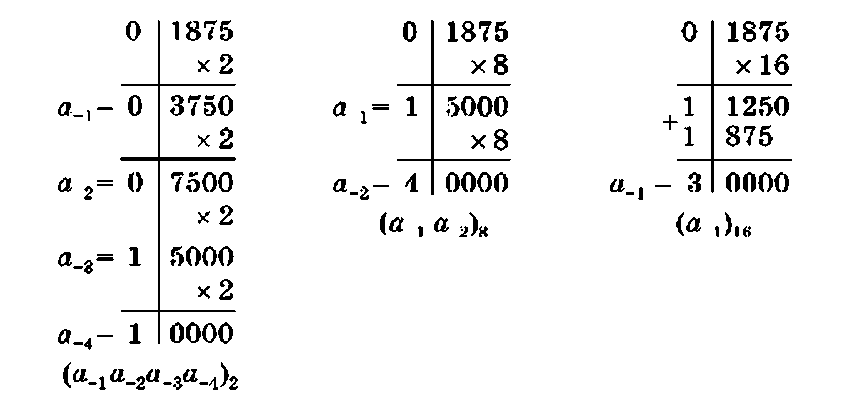
Здесь вертикальная черта отделяет целые части чисел от дробных частей.
Ответ: 0,187510 = 0,00112 = 0,148 = 0,316.
Перевод смешанных чисел, содержащих целую и дробную части, осуществляется в два этапа. Вначале переводятся раздельно целая и дробная часть числа, а затем при
записи числа в новой системе счисления целая часть запятой (точкой) отделяется от дробной.
П р и м е р 1.9. Перевести десятичное число 318,1875 в восьмеричную и шестнадцатеричную системы счисления. Ответ: 318Д87510 = 476,148 = 13Е,31б.
Перевод чисел из двоичной системы в системы с основанием 2п (Q = 2") может производиться по более простым алгоритмам. Начнем с алгоритма перевода целого десятичного числа.
1. Двоичное число разбить справа налево на группы по п цифр в каждой. Если в последней левой группе окажется менее п цифр, то ее необходимо дополнить слева нулями до нужных п цифр.
2. Для каждой группы, состоящей из п двоичных цифр, записать соответствующее число в системе счисления Q = 2п.
Пример 1.10. Двоичное число 101111111000000112 перевести в восьмеричную систему счисления:
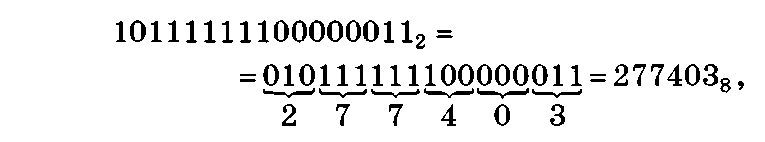
и шестнадцатеричную систему счисления:
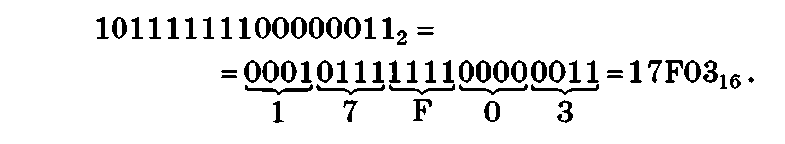
В первом случае группа содержит п = 3 цифр и называется триадой, а во втором — п = 4 цифр и называется тетрадой.
Для того чтобы дробное двоичное число записать в системе счисления с основанием Q= 2", нужно выполнить следующие действия.
1. Двоичное число разбить слева направо на группы по п цифр в каждой. Если в последней правой группе окажется меньше п цифр, то ее надо дополнить справа нулями до п цифр.
2. Для каждой группы, состоящей из п двоичных цифр, записать соответствующее число в системе счисления Q = 2”.
Пример 1.11. Перевести двоичное дробное число 0,101010012 в восьмеричную систему счисления:
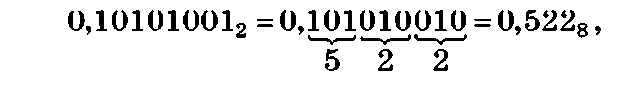
и шестнадцатеричную систему счисления:
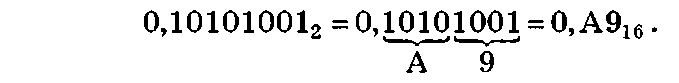
Перевод смешанных двоичных чисел осуществляется по аналогии с примером 1.9.
3.2. АРИФМЕТИЧЕСКИЕ ОПЕРАЦИИ В ПОЗИЦИОННЫХ СИСТЕМАХ СЧИСЛЕНИЯ
В основе арифметических операций сложения, вычитания, умножения и деления, выполняемых в двоичной системе счисления, лежат таблицы сложения и умножения:
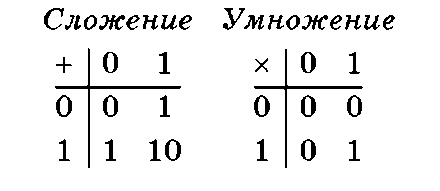
Сложение. В таблице сложения важно отметить, что при сложении двух единиц величина разряда становится равной (в других системах может быть и большей) основанию, происходит переполнение разряда и производится перенос в старший разряд (1 + 1 = 102).
Пример 1.12. Используя таблицу сложения, сложить два двоичных числа 1012, 112> или десятичные 5, 3, и проверить правильность вычисления.
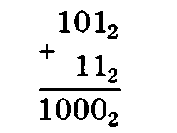
Правильность сложения двоичных чисел проверяется сложением соответствующих десятичных чисел: 510 + 310 = = 810 = 10002.
Вычитание. Операция вычитания одного числа — вычитаемого (например, 3) из большего другого — уменьшав-
мого (например, 5) путем сложения выполняется так: отрицательное число (вычитаемое) преобразуется в число, которое дополняет его до полного разряда (для 3 это будет 7=10- 3), затем происходит суммирование (5 + 7 = 12), после чего у результата отбрасывается высший разряд (получается 2).
Пример 1.13. Из двоичного числа 1012 (десятичного 5) вычесть двоичное число 112 (десятичное 3). Дополним вычитаемое 112 до полного разряда: представим число 112 в виде четырехразрядного числа 00112, для которого определим обратный код 11002 (заменой 0 на 1 и 1 на 0) и дополнительный код 11012 = 11002 + 1 (добавлением 1 к младшему разряду). Производим сложение двоичных (десятичных) чисел:
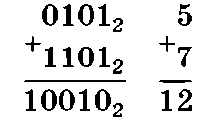
Удаление высшего разряда 1 из двоичного числа 100102 дает 102, а из десятичного 12 — дает 2.
Ответ: 102, 2.
Пример 1.14. Умножить двоичные числа 1102 и 112.
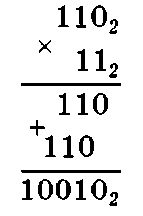
Ответ: 100 1 02.
Операция деления двоичных чисел подобна операции деления десятичных чисел.
Пример 1.15. Разделить число 1102 на 112.
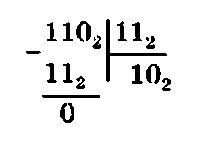
Ответ: 102.
Аналогичным способом арифметические операции выполняются в восьмеричной и шестнадцатеричной системах счисления.
3.3. ПРЕДСТАВЛЕНИЕ ЧИСЕЛ В КОМПЬЮТЕРЕ
Числовая информация в памяти компьютера хранится и обрабатывается в двоичном коде.
В компьютерах применяются две формы представления
1 V V V
двоичных чисел: с фиксированной и плавающей запятой.
В форме с фиксированной запятой хранятся целые числа. На рис. 1.3 приводится ячейка памяти, содержащая 8 разрядов, или 1 байт, в которой записано целое положительное двоичное число 101110112.
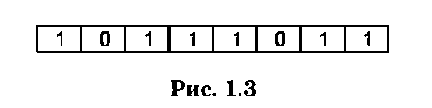
Максимальное число соответствует восьми единицам и равно
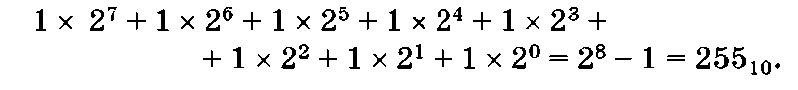
Следовательно, в однобайтовой ячейке памяти можно записать целое число, изменяющееся в пределах от 0 до 255. Если в ячейке памяти п разрядов, то в ней можно сохранить целое число

Для представления целого числа в компьютере ячейка памяти, называемая машинным словом, содержит 16 разрядов (битов). Причем старший левый разряд отводится для знака (0 соответствует плюсу, а 1 — минусу). Тогда компьютер может оперировать следующим максимальным целым числом: 215 - 1 = 32 767.
В формате с плавающей запятой хранятся и обрабатываются в компьютере вещественные числа. Формат с плавающей запятой предполагает запись вещественного числа в экспоненциональном виде:
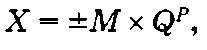
где М — мантисса числа (\М\ < 1); Q — основание системы счисления; Р — порядок числа (Р — целое число).
Пр и м е р 1.16. Преобразовать десятичное число 324,52 в экспоненциальную форму.
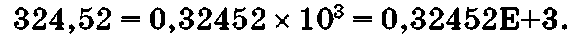
Здесь мантисса М = 0,32452, порядок Р = 3.
Число в формате с плавающей запятой занимает в памяти компьютера 4 (число обычной точности) или 8 байт (число двойной точности).
4.ПРЕДСТАВЛЕНИЕ ЛОГИЧЕСКИХ ДАННЫХ. ОПЕРАЦИИ ПРОИЗВОДИМЫЕ НАД ЛОГИЧЕСКИМИ ДАННЫМИ
Логические данные (переменные) принимают два значения: Истина или Ложь, 1 или 0 — и обозначаются прописными латинскими буквами A, В, С, D,..., X, У, Z. В компьютере для логической переменной отводится два байта, или 16 разрядов, которые заполняются 1, если она имеет значение Истина, и 0, если значение Ложь.
С логическими данными выполняются логические операции, среди которых наибольшее применение получили операции конъюнкции, дизъюнкции, отрицания и импликации. Результатом логической операции является также значение Истина или Ложь, 1 или 0.
Конъюнкция — это операция логического умножения, которая имеет значение Истина, только когда истинны все входящие в нее логические переменные. Операцию конъюнкции принято обозначать буквой И либо значками а или &.
Запишем операцию конъюнкции для двух логических переменных А и В:
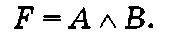
Значение логической функции F можно определить с помощью ее таблицы истинности, которая показывает, какие значения принимает логическая функция при всех наборах ее аргументов, например А и В (см. табл. 1.2).
Одна или несколько операций конъюнкции, выполняемых с логическими переменными или их отрицаниями, называется конъюнктором. Его схема приведена на рис. 1.4.
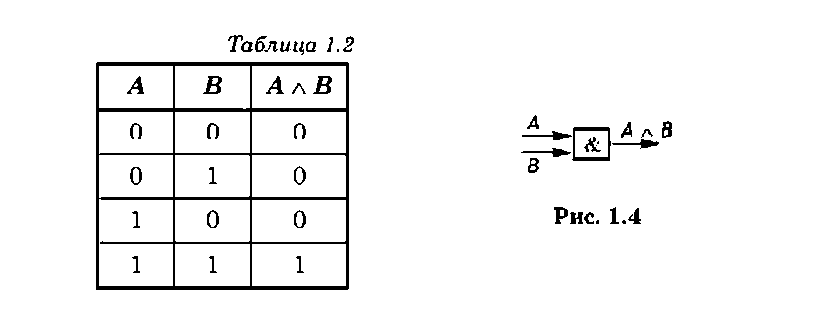
Дизъюнкция — это операция логического сложения, которая имеет значение Ложь только тогда, когда ложны все входящие логические переменные. Операцию дизъюнкции обозначают буквами ИЛИ либо значками v или +.
Операция дизъюнкции с двумя переменными
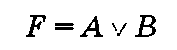
имеет таблицу истинности, представленную в табл. 1.3. Операция дизъюнкции с одной или несколькими логическими переменными или их отрицаниями выполняется дизъюнктором, изображенным на рис. 1.5.
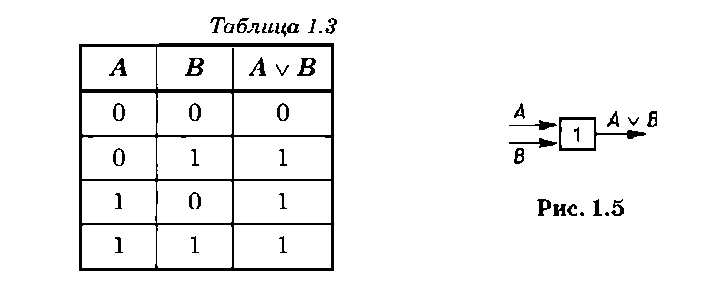
По аналогии с конъюнкцией по таблице истинности операции дизъюнкции можно определить ее выходные значения при любом наборе значений входных переменных.
Логическое отрицание меняет значение переменной: ложное на истинное и истинное на ложное. Операцию логического отрицания (инверсии) логической переменной А в логике принято обозначать А или —.А. Логическая функция F, являющаяся логическим отрицанием А, имеет вид
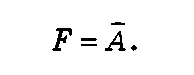
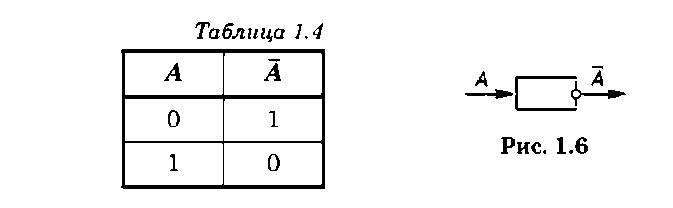
Истинность такого высказывания задается таблицей истинности функции логического отрицания (табл. 1.4). Функцию логического отрицания выполняет инвертор, изображенный на рис. 1.6.
Важно подчеркнуть, что все остальные логические функции двух переменных (их всего 16) могут быть выражены через логические функции конъюнкции, дизъюнкции и импликации.
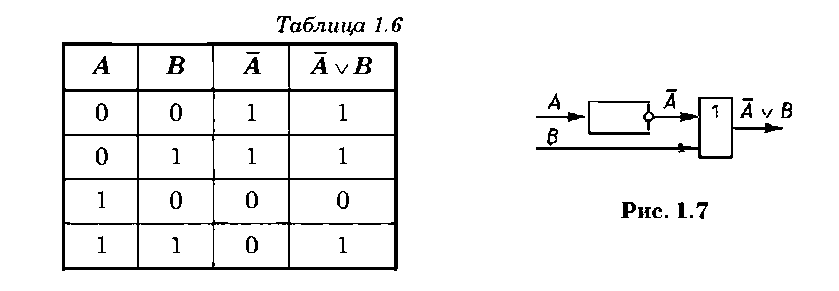
Импликация — это бинарная операция логического следования «если А, то В», которая имеет значение Ложь тогда и только тогда, когда истинна пере
менная А (посылка) и ложна переменная В (вывод). Логическая операция импликации «если А, то В» вы-
V 1 v
ражается логической функцией
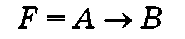
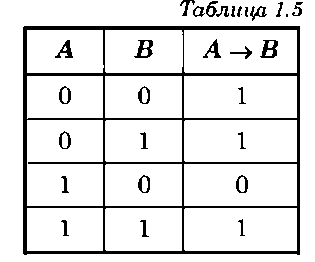
и задается соответствующей таблицей истинности (табл. 1.5).
Логическую функцию импликации описывают инвертор и дизъюнктор, изображенные на рис. 1.7. Если построить таблицу истинности логической функции A v B (табл. 1.6), то видно, что она равносильна логической функции импликации, т. е. AvВ = А ^ В.
Из простых логических функций конъюнкции, дизъюнкции, отрицания, импликации составляются сложные логические функции. Для них также можно построить таблицы истинности, руководствуясь следующими правилами.
1. Определить количество строк (равно 2% где п — количество переменных).
2. Определить количество столбцов (равно сумме количества переменных и логических операций).
3. Заполнить таблицу истинности по столбцам, выполняя логические операции в необходимой последовательности (в скобках, отрицание, конъюнкция, дизъюнкция, импликация).
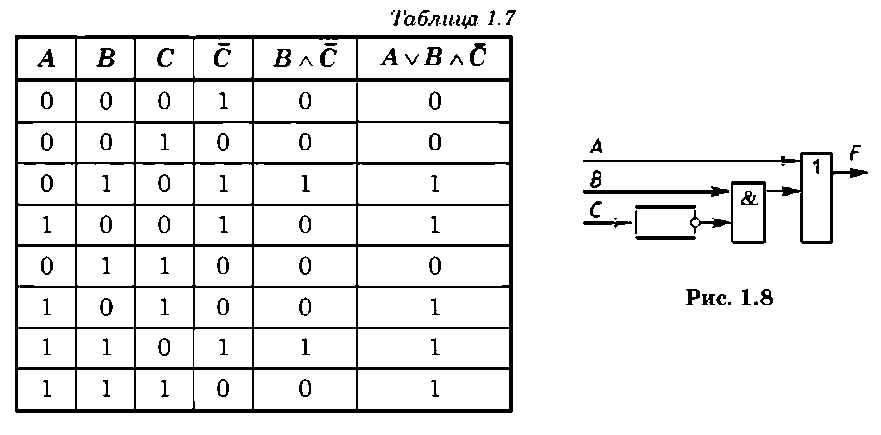
Пример 1.17. Построить таблицу истинности и схему логической функции
1. Определяется количество строк:
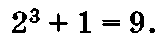
2. Определяется количество столбцов:
3 логические переменные 44- 3 логические операции = 6.
3. В соответствии с порядком выполнения логических операций заполняется таблица истинности (табл. 1.7).
Логической функции соответствует схема элементов, изображенная на рис. 1.8.
В некоторых случаях логическая функция представляет собой довольно сложное и громоздкое выражение, которое можно упростить, используя приведенные ниже законы логики:
1) коммутативность:
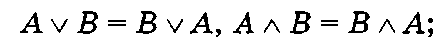
2) ассоциативность:
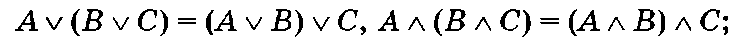
3) отрицание операнда:
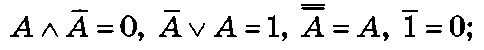
4)дистрибутивность:
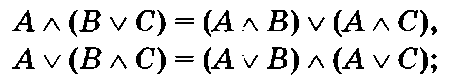
5) поглощение операнда:
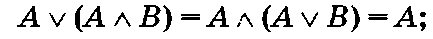
6) отрицание формулы (закон де Моргана):
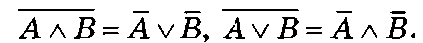
Пример1.18. Упростить выражение
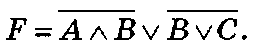
Последовательность действий такова:
1) применить дважды закон де Моргана к
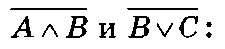
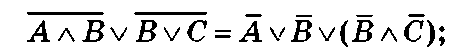
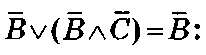
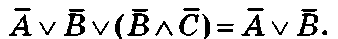
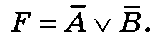
2) применить закон поглощения операнда к B v ( B a C)=B:
A v B v ( B a C) = A v 5 .
Ответ: F = A v В.
5. ПРЕДСТАВЛЕНИЕ ТЕКСТОВЫХ ДАННЫХ. ОПЕРАЦИИ НАД ТЕКСТОВЫМИ ДАННЫМИ.
Правило представления символьной информации (букв алфавита и других символов) заключается в том, что каждому символу в компьютере ставится в соответствие двоичный код — совокупность нулей и единиц.
Так, 1 бит (принимающий значения 0, 1) позволяет закодировать два символа, 2 бита(00,01,10,11) — 4 символа, 3 бита (000,001, 010,100, 011,101,110,111) — 8 символов
и, наконец, п битов — 2п символов. Минимальное количество битов /г, необходимое для кодирования Р символов, определяется из условия

Пример 1.19. Какое минимальное количество битов памяти потребуется для кодирования 33 строчных и прописных букв русского алфавита?
Всего требуется закодировать 66 букв. При Р = 66 минимальное количество битов памяти п> при котором выполняется условие (1.8):
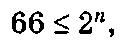
будет равно 7.
Ответ: п = 7.
С текстовыми данными можно производить следующие операции: сравнение двоичных кодов (>, <, =, ф), слияние и разбиение текста на отдельные символы или группы символов.
Наиболее распространенный стандарт кодировки символов ASCII-код (американский стандартный код для обмена информацией — англ. American Standart Code for Information Interchange) был введен в США еще в 1963 г. и после модификации в 1977 г. был принят в качестве всемирного стандарта. Каждому символу поставлено в соответствие двоичное число от 0 до 255 (8-битовый двоичный код), например: А — 01000001, В — 01000010, С — 01000011, D — 01000100 и т. д. Символы от 0 до 127 — латинские буквы, цифры и знаки препинания — составляют постоянную (базовую) часть таблицы. Расширенная таблица от 128-го до 255-го символа отводится под национальный стандарт. Таким образом, каждый введенный в компьютер с клавиатуры символ запоминается и хранится на носителе в виде набора из восьми нулей и единиц. При выводе текста на экран или на принтер соответствующие программно-аппаратные средства вывода выполняют обратную перекодировку из цифровой формы в символьную по тем же правилам.
В настоящее время идет внедрение нового стандарта — Unicode. Этот стандарт определяет кодировку каждого
символа не одним байтом, а двумя. Соответственно число одновременно кодируемых символов возрастает с 256 до 65 536. Данный стандарт позволяет закодировать одновременно все известные символы, в том числе японские и китайские иероглифы.
Существуют и национальные стандарты кодировки. Например, в СССР был введен стандарт КОИ-8 (код обмена информацией восьмизначный), который по сеи день используется для кодировки текста.
6. ПРЕДСТАВЛЕНИЕ ГРАФИЧЕСКИХ ДАННЫХ. ОПРЕРАЦИИ ПРОИЗВОДИМЫЕ НАД ГРАФИЧЕСКИМИ ДАННЫМИ.
Графические данные хранятся, обрабатываются и передаются в двоичном коде, т. е. в виде большого числа нулей и единиц.
Существуют два принципиально разных подхода к представлению (оцифровке) графических данных: растровый и векторный.
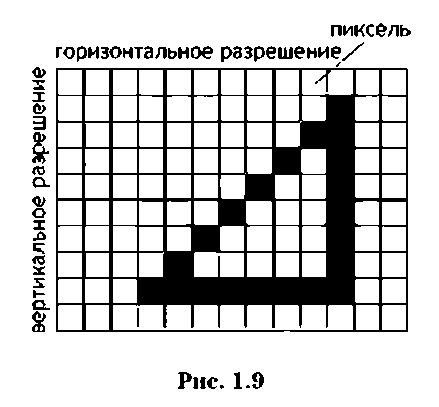
Для оцифровки графических изображений при растровом представлении вся область данных разбивается на множество точечных элементов — пикселей, каждый из которых имеет свой цвет. Совокупность пикселей называется растром, а изображения, которые формируются на основе растра, называются растровыми. Число пикселей по горизонтали и вертикали изображения определяет разрешение изображения. Стандартными являются значения 640x480, 800x600, 1024x768, 1280x1024 и др. Каждый пиксель нумеруется, начиная с нуля, слева на
право и сверху вниз. Пример представления треугольной области растровым способом показан на рис. 1.9.
Очевидно, что чем больше разрешение, тем точнее будут формироваться графические контуры, при этом, естественно, возрастает количество пикселей. Увеличение разрешения по горизонтали и
вертикали в два раза приводит к увеличению числа пикселей в четыре раза.
При растровом способе представления графических данных под каждый пиксель отводится определенное число битов, называемое битовой глубиной и используемое для кодировки цвета пикселя. Каждому цвету соответствует определенный двоичный код (т. е. код из нулей и единиц). Например, если битовая глубина равна 1, то под каждый пиксель отводится 1 бит. В этом случае 0 соответствует черному цвету, 1 — белому, а изображение может быть только черно-белым. Если битовая глубина равна 2, то каждый пиксель может быть закодирован цветовой гаммой из 4 цветов (22) и т. д. Для качественного представления графических данных в современных компьютерах используются цветовые схемы с битовой глубиной 8(1 байт), 24 (3 байта), 32 (4 байта) и даже 40 (5 байт), т. е. каждый пиксель может иметь 28, 224, 232, 240 оттенков. Вполне естественно, что с увеличением глубины цвета увеличивается объем памяти, необходимой для хранения графических данных. Следовательно, количество цветов N> отображаемых на экране монитора, может быть вычислено по формуле

где i — битовая глубина.
Если известны размеры (в пикселях) рисунка по высоте X и ширине У экрана, а также битовая глубина £, то занимаемый объем рисунка V будет равен

Отметим, что качество изображения определяется разрешающей способностью экрана (X х У) и битовой глубиной цвета i.
Пример 1.20. Файл, содержащий восьмицветный квадратный рисунок, составляет объем 2400 байт. Определить размер рисунка в пикселях.
В палитре имеется 8 цветов. При подстановке N = 8 в
формулу (1.9):
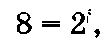
вычисляется битовая глубина i = 3.
При подстановке битовой глубины i = 3, объема рисунка V = 2400 х В = 19200 бит в формулу (1.10):
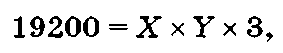
определяется величина произведения:
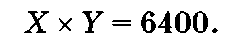
Из X = У вытекает, что X х У = 80 х 80.
Ответ: размер рисунка в пикселях равен 80 х 80.
Основным недостатком растровой графики является большой объем памяти, необходимый для хранения изображения. Это объясняется тем, что запоминается цвет каждого пикселя, общее число которых задается разрешением, определяющим также качество представления графических данных.
При векторном представлении графических данных задается и впоследствии сохраняется математическое описание каждого графического примитива — геометрического объекта (отрезка, окружности, прямоугольника и т. п.), из которых формируется изображение. Например, для воспроизведения окружности достаточно запомнить положение ее центра, радиус, толщину и цвет линии. Благодаря этому для хранения векторных графических данных требуется значительно меньше памяти.
Основным недостатком векторной графики является невозможность работы с высококачественными художественными изображениями, фотографиями и фильмами, поэтому основной сферой применения векторной графики является представление в электронном виде чертежей, схем и т. п.
Программы для работы с графическими данными делятся на растровые графические редакторы (Paint, Photoshop) и векторные графические редакторы (Corel Draw, Visio).
Приведем краткие характеристики наиболее популярных графических форматов.
BMP (Bit Map image) — растровый формат, используемый в системе Windows. Поддерживается большинством графических редакторов (в частности, Paint и Photoshop).
Применяется для хранения отсканированных изображений и обмена данными между различными приложениями.
TIFF (Tagged Image File Format) — растровый формат. Поддерживается различными операционными системами. Включает алгоритм сжатия без потери качества изображения. Используется в сканерах, а также для хранения и обмена данными.
GIF (Graphics Interchange Format) — растровый формат. Включает в себя алгоритм сжатия, значительно уменьшающий объем файла без потери информации. Поддерживается приложениями для различных операционных систем. Применяется в изображениях, содержащих до 256 цветов, а также для создания анимации. Используется для размещения графики в Интернете.
JPEG (Joint Photographic Expert Group) — растровый формат, содержащий алгоритм сжатия, который уменьшает объем файла в десятки раз, но приводит к необратимой потере части информации. Поддерживается большинством операционных систем. Используется в основном в Интернете.
PNG (Portable Network Graphic) — растровый формат, аналогичный GIF. Используется для размещения графики в Интернете.
WMF (Windows Metafile) — векторный формат для Windows-приложений.
EPS (Encapsulated PostScript) — векторный формат, поддерживаемый большинством операционных систем.
CDR — векторный формат, используемый графической системой Corel Draw.
В перечисленных графических редакторах для представления цвета используются цветовые модели.
Цветовая модель — это правило, по которому может быть вычислен цвет. Самая простая цветовая модель — битовая. В ней для описания цвета каждого пикселя (черного или белого) используется всего один бит. Для представления полноцветных изображений используются более сложные модели, среди которых самые известные — модели RGB и CMYK.
Цветовая модель RGB (Red-Green-Blue, красный-зе леный-синий) основана на том, что любой цвет может быть
представлен как сумма трех основных цветов: красного, зеленого и синего. В основе цветовой модели лежит декартова система координат. Цветовое пространство представляет собой куб, показанный на рис. 1.10. Любой оттенок цвета (сочетание трех базовых цветов с разной интенсивностью) выражается набором из трех чисел. На каждое число отводится один байт, поэтому интенсивность одного цвета имеет 256 значений (0-255), а общее количество оттенков цвета (224) — примерно 16,7 млн. Белый цвет в модели RGB представляется как (255, 255, 255), черный — (0, 0, 0), красный — (255, 0, 0), зеленый — (0, 255, 0), синий — (О, 0, 255), а оттенки серого — (К, К, К), где 0 < К 255.
Другая цветовая модель — CMY — является производной модели RGB и также построена на базе трех цветов: С — Cyan (голубого), М — Magenta (пурпурного) и У — Yellow (желтого), которые образуются следующим образом. Голубой цветС(0, 255, 255) является комбинацией синего и зеленого, желтый цвет У(255, 255, 0) — зеленого и красного, а пурпурный цветМ(255, 0, 255) — красного и синего. Преобразование данных из RGB в CMY выполняется с помощью простой операции
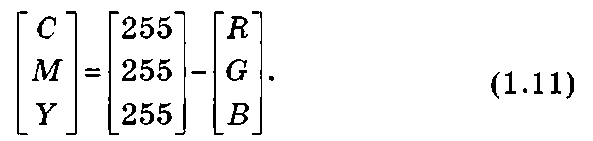
Выражение (1.11) показывает, что свет, отраженный от поверхности чисто голубого цвета, не содержит красного (поскольку в этом выражении С = 255 - R).
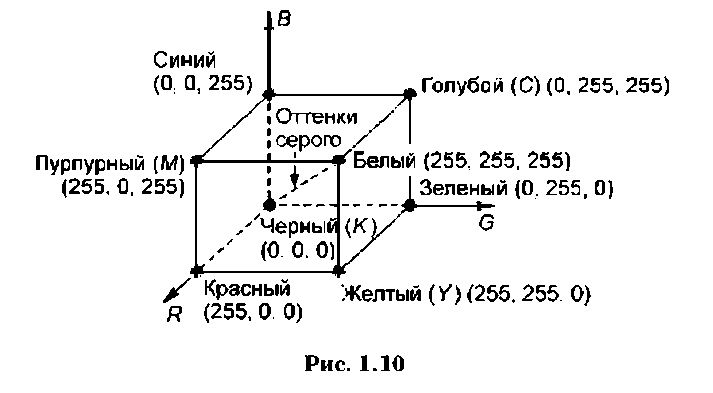
Аналогично, поверхность пурпурного цвета не отражает зеленого, поверхность желтого цвета — синего. Смешение голубого, пурпурного и желтого цветов должно давать черный цвет, который, однако, выглядит осветленным по сравнению с оригиналом. Поэтому для получения чистого черного цвета при печати цветовая модель CMY расширяется до модели CMYK, содержащей четвертый основной цвет — черный (К — black).
7. СТРУКТУРЫ ДАННЫХ
Работа с большими объемами данных становится более продуктивной, когда данные упорядочены, т. е. образуют определенную структуру. Широкое распространение получили три типа структур данных: массивы, списки и деревья.
Под массивом понимают индексируемую совокупность элементов с произвольным доступом к ним. Индекс задает позицию соответствующего элемента в массиве. С помощью индекса осуществляется доступ к элементу. Массив обладает размерностью, определяющей число его элементов.
Различают одномерные и многомерные массивы.
Одномерный массив имеет одно измерение, его примером является вектор
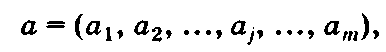
который имеет размерность т ив котором индекс у = 1, ..., т указывает номер элемента.
Многомерный массив имеет несколько измерений. Его примером может служить двумерный массив данных
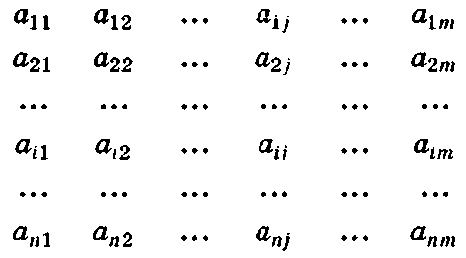
с двумя индексами (измерениями) i = 1, ..., /г, у = 1, ..., т и размерностью п х т.
Многомерные массивы бывают однородными и неоднородными.
Однородный массив состоит из элементов одного типа, а неоднородный массив — из элементов разного типа.
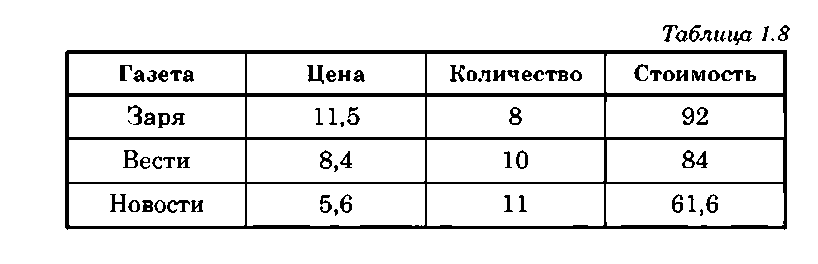
Двумерный неоднородный массив, у которого типы данных одинаковы только в столбцах, называется таблицей. В табл. 1.8 приводятся данные трех типов: в столбце «Газета» — символьные, «Цена» и «Стоимость» —вещественные числа, «Количество» — целые числа.
Поиск нужного элемента в таблице осуществляется так же, как и в однородном массиве. Строки в таблице называются записями, а столбцы — полями. Элементы записи имеют, вообще говоря, разный тип.
Список — это набор записей, расположенных в определенной последовательности. Его примерами могут служить список студентов группы, перечень дел надень или словарь. Различают два типа списков: непрерывный и связный.
Непрерывный список предполагает, что его элементы записаны один за другим в последовательные ячейки памяти.
На рис. 1.11 показан расположенный в алфавитном порядке список имен, каждое из которых занимает 8 ячеек памяти.
Непрерывный список имеет недостаток: при удалении имени из начала списка приходится перемещать последующие имена к началу списка, чтобы сохранить существующий порядок. Еще более сложная проблема возникает при добавлении имени, поскольку в этом случае требуется

переместить список для освобождения блока ячеек, необходимого для расширения списка.
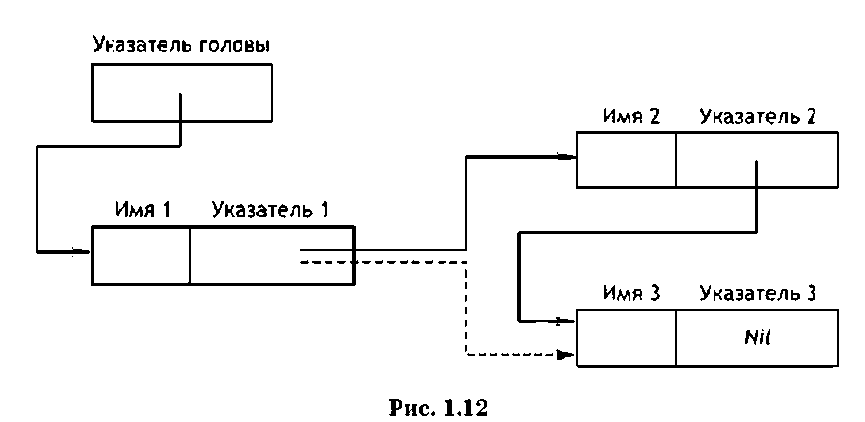
Связный список состоит из элементов, снабженных указателями на имена смежных элементов. Структура связного списка показана на рис. 1.12.
Здесь для записи элемента списка отводится 9 ячеек: первые восемь для имени, а последняя используется как указатель на следующее имя в списке.
От указателя идет стрелка к адресу имени, на который тот указывает. Для прохождения списка надо начать с указателя головы и найти первое имя (запись). Далее необходимо по указателям записей переходить от одного имени к другому до достижения пустого указателя (Nil). Здесь удаление записи (например, записи «Имя 2, Указатель 2»)оз- начает, что меняется Указатель 1, при этом пунктирной линией со стрелкой показана связь с новым элементом, имеющим Имя 3. Важно подчеркнуть, что расположение записей связного списка в памяти компьютера может быть произвольным.
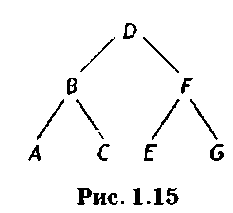
Деревья — это последняя структура данных, которым соответствует организационная схема типичного вуза (рис. 1.13).
Чтобы дать определение дерева, введем ограничение: ни одно подразделение не подчиняется двум разным подразделениям более высокого уровня. Такую древовидную структуру данных называют иерархической. Каждый элемент дерева называется узлом. Узел, находящийся на самом высоком уровне, называется корневым, а узлы, нахо-
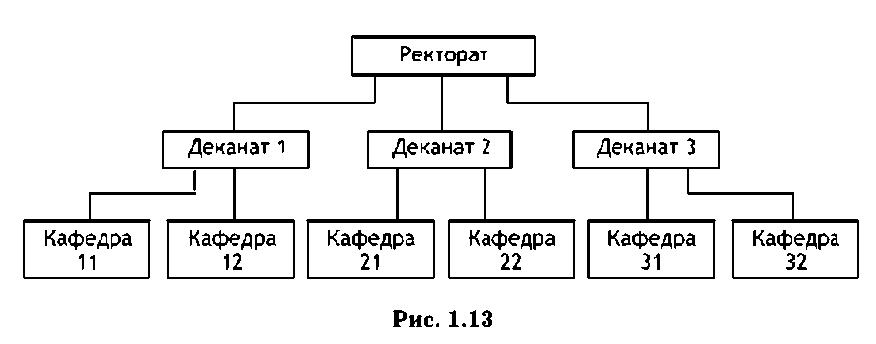
дящиеся на самом низком уровне, — терминальными. Нетерминальные узлы связаны с нижестоящими узлами, называемыми потомками.
При рассмотрении способов хранения деревьев ограничимся бинарными деревьями, т. е. деревьями, с каждым узлом которых могут быть связаны только два узла-потом-
ка. Бинарные деревья представляют собой специальную структуру связанных списков — узлов, формат которых показан на рис. 1.14.

После ячейки с данными следуют ячейки-указатели на левого потомка (УЛП) и правого потомка (УПП). В терминальных узлах значения обоих указателей равны Nil.
Пример 1.21. Построить бинарное дерево, в узлах которого находятся буквы исходной упорядоченной последовательности А, В, С, D, Е, F>G и соответствующую ему структуру связных списков — узлов.
Бинарное дерево, изображенное на рис. 1.15, строится с помощью бинарного поиска. Первым корневым узлом становится центральный элемент D, разбивающий исходный список на два одинаковых по числу букв подсписка А, В, С и Е, В, G, в которых определяются два центральных элемента — узлы В и Fj являющиеся левым и правым потомками D. Оставшиеся элементы А, С и В, G образуют левые и правые
потомки узлов BnF соответственно.
Согласно принятой на рис. 1.14 структуре узла структура связных списков, соответствующая бинарному дереву на рис. 1.15, будет иметь вид, показанный на рис. 1.16.
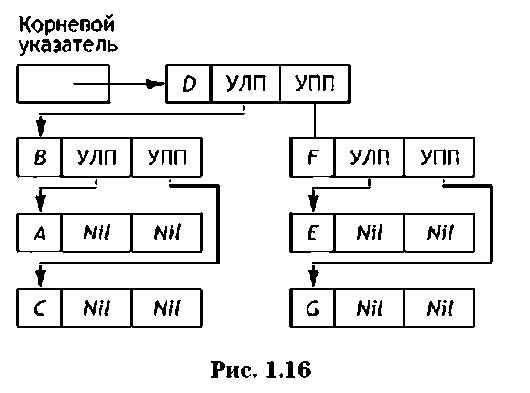
Следует отметить, что поиск заданной буквы достаточно прост: надо двигаться из корневого узла к тем потомкам, где она должна находиться.
8. ЕДИНИЦЫ ХРАНЕНИЯ ДАННЫХ
При хранении данных решаются две проблемы: как сохранить данные в наиболее компактном виде и как обеспечить к ним удобный и быстрый доступ. В качестве единицы хранения данных принят объект переменной длины, называемый файлом.
Файл — это последовательность произвольного числа байтов данных, обладающая уникальным собственным именем.
Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла. Имя файла состоит из двух разделенных точ- кои частей: собственно имени и расширения, определяющего тип файла. Например:
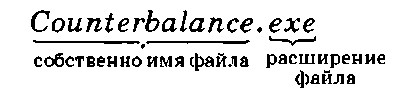
Собственно имя файла может состоять из русских и английских букв, цифр и специальных символов. При этом его длина не должна превышать 256 символов. В зависимости от расширения все файлы делятся на две большие группы: исполняемые и неисполняемые.
Исполняемые файлы — это такие файлы, которые могут выполняться самостоятельно, т. е. не требуют каких-
либо специальных программ для их запуска. Стандартные расширения имен этих файлов следующие:
.ехе — готовый к исполнению файл (tetris.exe; win- word.ехе);
.сот — файл операционной системы (command.com);
.bat — командный файл операционной системы MS-DOS (autoexec.bat).
Неисполняемые файлы для запуска требуют установки специальных программ. Так, например, для того чтобы просмотреть текстовый документ, требуется наличие какого-либо текстового редактора.
Вот несколько примеров расширений неисполняемых файлов: .pas — текст программы на Паскале; .bas — текст программы на Бейсике; .doc — текст, выполненный в редакторе Word; .mdb — файл СУБД Access; .хIs — электронная таблица Excel; .arj — упакованный файл; .zip — упакованный файл; .txt — текст, выполненный в редакторе Блокнот.
Расширения графических файлов, создаваемых в растровых графических редакторах (Paint, Photoshop): .bmp, .tiff, .gif, .jpeg, .png', в векторных графических редакторах (Corel Draw, Visio): .cdr,.eps, .wmf, .usd и др.
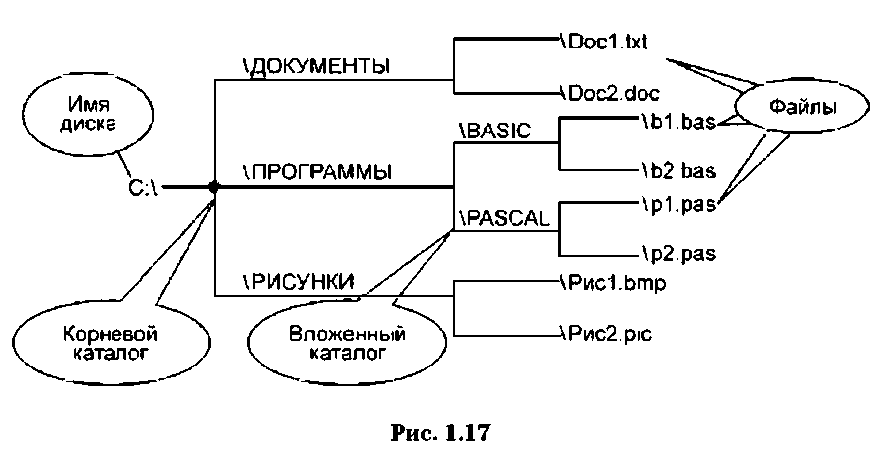
Хранение файлов организуется в иерархической структуре, которая называется файловой структурой. На вершине структуры находится имя носителя, на котором сохраняются файлы и каталоги (папки). Далее следует корневой каталог, содержащий вложенные каталоги первого уровня, каждый из которых может содержать вложенные каталоги второго уровня и т. д.
Необходимо отметить, что в каталогах всех уровней могут находиться файлы, сгруппированные по любому общему признаку, заданному их создателем (по типу, по принадлежности, по назначению, по времени создания и т. п.).
Правила присвоения имени каталогу ничем не отличаются от правил присвоения имени файлу, но каталогам не принято задавать расширения имен. Имена промежуточных каталогов разделяются между собой обратной косой чертой (\). На рис. 1.17 приведен пример иерархической структуры диска С.
Внешние носители (диски или дискеты), на которых хранится информация, имеют свои имена — каждый диск обозначается буквой латинского алфавита, а затем ставится двоеточие. Так, для дискет всегда отводятся буквы А: и/или В:. Логические диски винчестера именуются начиная с буквы С:. После всех имен логических дисков следуют имена дисководов для компакт-дисков. Например, установлены дисковод для дискет, винчестер, разбитый на 3 логических диска, и дисковод для компакт-дисков. Определим буквенные имена всех носителей информации: А: — дисковод для дискет; С:, D:, Е: — логические диски винчестера; F: — дисковод для компакт-дисков.
Полное имя файла. Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путем доступа к нему. На одном носителе не может быть двух файлов с одинаковыми полными именами. Ниже приводится пример записи полного имени Файла:
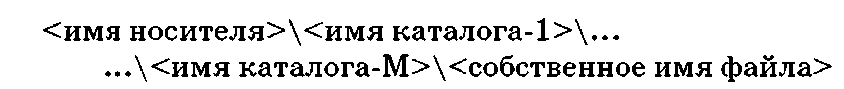
Используя иерархическую структуру диска С (рис. 1.17), запишем полное имя файла bl.bas:
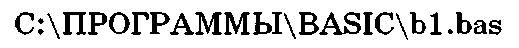
Для наглядности имена каталогов (папок) напечатаны прописными буквами, а имена файлов — строчными.
9. Заключение
Наше информационное пространство развивается чрезвычайно стремительно. И вместе с ним растет как снежный ком, количество информации и данных. И для того чтобы данные не превратились просто в “белый шум”, необходимо чтобы методы работы с данными постоянно совершенствовались, внедрялись новые технологии по сбору, обработке и хранению данных. И только вследствие этого возможно движение вперед технического прогресса в целом.
Список литературы
- Балдин, К. В. Информатика: учеб, для вузов / К. В. Балдин, В. Б. Уткин. М.: Проект, 2003. 304 с.
- Беляев, М. А. Основы информатики: учеб, для вузов / М. А. Беляев, В. В. Лысенко, Л. А. Малинина. Ростов-н/Д: Феникс, 2006. 352 с.
- Брукшир, Д. Информатика и вычислительная техника / Д. Брукшир. СПб.: Питер, 2004. 620 с.
- Головко, В. А. Нейронные сети: обучение, организация и применение: учеб, пособие для вузов / В. А. Головко. М.: ИПРЖР, 2001. Кн. 4. 256 с.
- Заде, Л. А. Понятие лингвистической переменной и его применение к принятию приближенных решений / Л. А. Заде. М.: Мир, 1976. 165 с.
- Информатика: энциклопедический словарь для начинающих / под ред. Д. А. Поспелова. М.: Педагогика-Пресс, 1994. 352 с.
- Информатика. Базовый курс / под ред. С. В. Симоновича. СПб.: Питер, 2005. 640 с.
- Информатика: учеб. / под ред. Н. В. Макаровой. М.: Финансы и статистика, 2003. 768 с.
- Люгер, Д. Ф. Искусственный интеллект. Стратегии и методы решения сложных проблем / Д. Ф. Люгер. М.: Вильямс, 2003. 864 с.
- Осовский, С. Нейронные сети для обработки информации / С. Осовский. М.: Финансы и статистика, 2002. 344 с.
- Острейковский, В. А. Информатика: учеб, для вузов / В. А. Острейковский. М.: Высшая школа, 2005. 511 с.
- Представление и использование знаний / под ред. X. Уэно, М. Исидзука. М.: Мир, 1989. 220 с.
- Соболь, Б. В. Информатика: учеб. / Б. В. Соболь, А. Б. Галин, Ю. В. Панов [и др.]. Ростов-н/Д: Феникс, 2006. 448 с.
- Сырецкий, Г. А. Информатика. Фундаментальный курс / Г. А. Сырецкий. СПб.: БХВ, 2005. Т. 1: Основы информационной и вычислительной техники. 832 с.
- Большая компьютерная энциклопедия. М.: Эксмо, 2007. 480 с.
- Угринович, Н. Д. Информатика и информационные технологии: учеб, для 10-11-х классов / Н. Д. Угринович. М.: БИНОМ; Лаборатория знаний, 2007. 511 с.
- Свириденко, С. С. Информационные технологии: курс лекций / С. С. Свириденко. М.: Изд-во МНЭПУ, 2002. 192 с.
- Алексеев, А. П. Информатика 2001 / А. П. Алексеев. М.: СОЛОН-Р, 2001. 364 с.

- Применение объектно-ориентированного подхода при проектировании информационной системы .
- Исковая давность, ее гражданско-правовое значение (История становления, развития института исковой давности)
- Понятие предпринимательского договора (Особенности предпринимательского договора)
- Исковая давность, ее гражданско-правовое значение (История становления и развития института исковой давности)
- Правовые основы организации нотариата (основы организации нотариата)
- Опыт промышленной политики в разных странах (Сущность и принципы управления промышленной политикой)
- Основы программирования на языке HTML
- Разработка регламента выполнения процесса «Управление информационными ресурсами (Основные понятия процессного подхода)
- Основы спортивного менеджмента (Виды спортивных организаций)
- "Основные средства, формы и методы профилактики девиантного поведения детей и подростков в работе учителя начальных классов"
- "Конфликты между школьниками"
- Технология построения распределенных информационных систем (Преимущества и недостатки использования распределённых информационных систем)