
Технология построения распределенных информационных систем (Преимущества и недостатки использования распределённых информационных систем)
Содержание:

ВВЕДЕНИЕ
Одним из основных результатов созидательной, социальной и интеллектуальной человеческой деятельности является создание и накопление информационных ресурсов с целью их дальнейшего использования и сохранения опыта предыдущих поколений. Не будет преувеличением сказать, что уровень развития технологий сохранения информации и эффективности использования накопленной ранее информации на протяжении всей истории человечества значительно влиял на развитие производительных сил. Утеря информации приводила к отбрасыванию цивилизации на века назад. Однако, чтобы эффективно пользоваться накопленной ранее информацией, необходимы специальные инструменты и технологии, при помощи которых могут быть реализованы специальные приемы работы с информацией. Стремительное развитие глобальных информационных и вычислительных сетей ведет к изменению фундаментальных парадигм обработки данных, которые можно охарактеризовать как переход к поддержке и развитию распределенных информационных ресурсов. Поэтому важнейшей задачей, связанной с технологией работы с информацией, является исследование способов интеграции распределенных источников данных и создание научного задела в области распределенных информационных систем и баз данных в целях разработки технологии, поддерживающей создание и функционирование широкомасштабных информационных инфраструктур на основе виртуальной интеграции. Такая технология позволит создавать глобальные инфраструктуры из десятков и сотен гетерогенных баз данных и решать стратегические задачи в области автоматизации различных форм распределенной деятельности. Более узкой целью является разработка принципов и программных средств виртуальной интеграции распределенных источников данных на основе международных стандартов и рекомендаций для создания масштабных информационных инфраструктур, предназначенных для виртуализации доступа к данным различных СУБД с использованием единых правил и политик. На самом деле идея создания универсальной системы доступа к информационным ресурсам, распределенным в мировом пространстве, далеко ненова. По всей видимости, впервые ее четко осознал известный бельгийский ученый Поль Отле1 в конце XIX в., предложив совершенно новый метод, названным им “Документацией”: “Цели Документации состоят в том, чтобы суметь предложить документированные ответы на запросы по любому предмету в любой области знания: 1) универсальные по содержанию; 2) точные и истинные; 3) полные; 4) оперативные; 5) отражающие последние данные; 6) доступные; 7) заранее собранные и готовые к передаче; 8) предоставленные как можно большему числу людей”. “... человеческое знание позволит создать оборудование, действующее на расстоянии, в котором соединятся радио, рентгеновские лучи, кинематограф и микроскопическая фотография. Все предметы Вселенной, все предметы, созданные Человеком, будут регистрироваться на расстоянии с момента их создания. Тем самым будет создан движущийся образ мира — его память, его подлинная копия. Любой человек сможет прочесть отрывок, спроецированный на его личный экран”. Под интеграцией информационных ресурсов понимают их объединение с целью использования (с помощью удобных и унифицированных пользовательских интерфейсов) разнородной информации с сохранением ее свойств, особенностей представления и возможностей манипулирования с ней. При этом объединение ресурсов не обязательно должно осуществляться физически, оно может быть виртуальным, главное — оно должно обеспечивать пользователю восприятие доступной информации как единого информационного пространства. В частности, такие системы позволяют работать с гетерогенными наборами и базами данных или системами баз данных, обеспечивая эффективность информационных поисков независимо от особенностей конкретных систем хранения ресурсов, к которым осуществляется доступ.
1 Распределенные информационные системы и технологии
Вопрос об использовании распределенных систем обработки данных стал актуален с появлением мощных вычислительных систем с распределенными ресурсами в пределах одного компьютера, локальных корпоративных и внешних (региональных и глобальных) сетей, технологий поиска и многомерного анализа данных, развитием Web-технологий. Использование технологий распределенной обработки данных (Distributed Data Processing — DDP) стало особенно актуально для высокотехнологичных географически распределенных компаний, деятельность которых поддерживается и сопровождается современными ИТ и системами (рис. 1).
 |
|
Рисунок 1 |
Суть распределенной обработки данных заключается в том, что пользователь получает возможность работать с базами и хранилищами данных, прикладными процессами программами и сервисами, расположенными в нескольких взаимосвязанных оконечных системах. При этом возможны следующие виды работ:
• удаленный запрос, например, посылка команды пользователя
на выполнение задания, связанного с обработкой данных;
• удаленное действие (Transaction), осуществляющее направление группы запросов прикладному процессу; это может быть, например, часть вычислительного процесса, использующего удаленную базу данных;
• распределенная трансакция, дающая возможность использования нескольких серверов и прикладных процессов, выполняемых в группе оконечных систем;
• обработка в системе «клиент-сервер».
Существует несколько технологий распределенной обработки, которые могут использовать как промежуточный слой программного обеспечения, ориентированного на запросы и сообщения, так и распределенную интегрированную среду обработки данных. Первая технология является самой простой, но возможности ее ограничены взаимодействием с одним из выбранных серверов приложений. Технологии второго типа предусматривают совместную работу клиентов с одним или с группой серверов. При этом некоторые серверы могут выступать в роли клиентов для других серверов. Для распределенной обработки осуществляется тематическая сегментация прикладных программ. Для работы в реальном времени используется протокол резервирования ресурсов и предоставляется специализированное инструментальное программное обеспечение распределенной среды обработки данных. Способы конкретной организации процессов обработки и технические решения чрезвычайно разнообразны, однако архитектура таких систем является, как правило, двух- или трехзвенной архитектурой «клиент-сервер» (Client-Server Architecture — CSA).
1.1 История создания и использования распределенных информационных систем
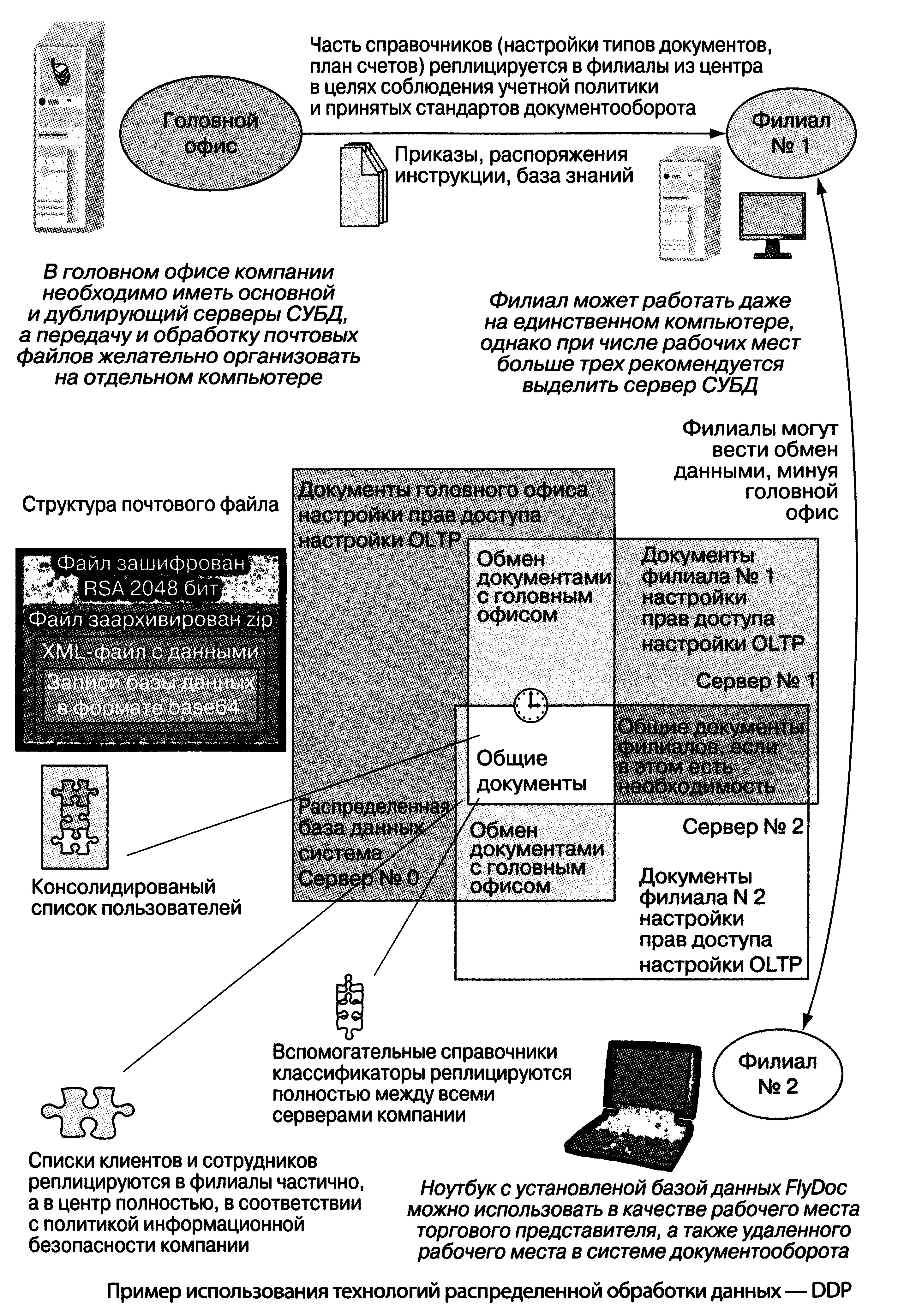
До конца 90-х годов прошлого века основным вектором развития распределенных вычислительных систем (РВС) являлась парадигма создания сосредоточенных систем. Типичным примером данного подхода явилось создание вычислительных кластеров научных организаций. Под термином вычислительный кластер обычно понимают систему, состоящую из вычислительных узлов, объединенных коммутационной сетью. Среди реализованных проектов можно выделить кластеры таких научных организаций, как ИРЭ РАН и ВЦ РАН. Данные системы были созданы для решения трудоемких задач, во многих областях науки, таких, например, как меторологические исследования, исследования задач динамики и ряда др. Использование РВС для решения подобных задач является необходимым условием для качествен-ного решения, так как многие задачи не могут быть решены на одном вычислительном узле за полиноминальное время. Особого внимания заслуживает разработки отечественных ученых по построению распре-деленных вычислительных систем с программи-руемой структурой. Исследования в данном на-правлении активно поддерживаются Сибирским отделением РАН. Под вычислительной системой с программируемой структурой стоит пони-мать совокупность элементарных машин (ЭМ), действие которой основано на модели коллек-тива вычислителей [4]. Основной задачей дан-ных систем является распределенная обработка информации. Первыми опытными разработками по созданию ВС с программируемой архитектурой начались в 60-х годах прошлого века. Сре-ди реализованных проектов ВС можно выделить такие системы как МИНИМАКС, СУММА, МИКРОС-1, МИКРОС-2, МИКРОС-T. Идеология объединения географически распределенных кластеров развилась в начале 90-х годов прошлого века. Основная сложность для развития данного подхода была заключена в объединениии гетерогенных компонентов вы-числительных узлов. Частично, данная пробле-ма была решена благодаря новому подходу к построению ПО, за счет его разделение на два слоя: • слой распределенного приложения• связующий слой программного обеспечения (англ. middleware) Первыми экспериментами по объединению территориально-разрозненных вычислительных компьютерных центров стали американский проект CASA и отечественный Астра. Именно в то время и возник термин метакомпьютинг. Первыми экспериментальными системами по объединению территориально-распределенных стали такие проекты, как FAFNER и I-WAY [17]. Хотя, конечно же, проекты FAFNER и I-WAY были созданы для различных целей (FAFNER предполагал объединение в единую сеть простых рабочих станций, а проект I-WAY предполагал объединение ресурсов суперкомпью-терных центров), но все же они имели немало общих черт. Основной задачей для данных проектов являлось создание распределенных систем с эффективным обменом данными, управлением ресурсами и обработкой данных. Проект FAFNER (англ. Factoring via Network enabled recursion) был создан для умножения простых чисел криптографических задач, путем разделения задачи на небольшие фрагменты и их дальнейшего распределения на узлы системы. Целью создания проект I-WAY являлось объединение ресурсов вычислительных центров в единое целое. Отличительной особенностью данного проекта являлось использование для управлением потоками задач брокера ресурсов. Идеи, заложенные в проекты FAFNER и I-WAY, оказали сильное влияние на развитие таких проектов, как ГЛОБУС (Globus) [18] и Legion [19]. Первым отечественным опытом по созданию территориально-распределенной вычисли-тельной системой стал проект Астра, инициро-ванный ИМ СО АН СССР и Новосибирским электротехническим институтом MB и ССО РСФСР. Проект предполагал построение территориально-распределенных систем на базе ЭВМ «Минск-32» и телефонных каналов связи. Пер-вая рабочая конфигурация системы была введена в эксплуатацию в 1972 г. Система предполагала неограниченные возможности по наращиванию вычислительных мощностей, но каждая ЭВМ, входящая в состав системы, могла соединяться только лишь с двумя соседними ЭВМ. На рис. 2 представлена схема распределенной системы Астра [4]. В дальнейшем, работа по модернизации системы продолжилась. Весь опыт по по-строению системы Астра, в дальнейшем лег в основу системы АРАККС (Асинхронная Распре-деленная вычислительная система с Комбиниро-ванными Каналами Связи).
 |
|
Рисунок 2 |
Существенный прорыв в области построения пространственно-распределенных систем обра-зовался благодаря развитию концепции GRID (Global Resource Information Distribution). Кон-цепция Grid Computing (распределенные сети, или "решетки" вычислительных ресурсов) на сегодняшний день представляет собой ведущую технологию создания распределенных вычисли-тельных систем (РВС). В 1998 году Фостер и Кельман опублико-вали статью [20], в которой предложили кон-цептуально новый подход к организации гло-бально-распределенных систем. Как следует из статьи, грид-системы являются «программно-аппаратными структурами, обеспечивающими надежный и недорогой доступ к высокопроиз-водительным вычислительным возможностям». По своей сути, идеология компьютерных грид-системы является моделированием электрических сетей. Грид – архитектура позволяет соединять между собой географически рас средоточенные вычислительные узлы посред-ством сети Интернет в некоторую абстрактную решетку (англ. GRID – решетка), в которой каждый узел предоставляет ресурсы для со-вместного использования в конкретной задаче. Данная вычислительная модель системы позво-ляет объединять не только сосредоточенные кластеры, но и ПК обычных пользователей сети Интернет в некий единый виртуальный суперкомпьютер. Возможность использования данного подхода к организации территориально-распределенных систем стало возможным, благодаря развитию общей индустрии инфор-мационных технологий, а именно:• развитию высокоскоростных сетей переда-чи данных;• увеличению производительности ПК;•созданию стандартизированных протоколов передачи данных. На рис.3 представлена одна из возможных структур Grid Computing.
 |
|
Рисунок 3 |
Среди значимых систем второго поколения можно выделить такие проекты как Globus, gLite, Legion, Unicore. Проект Globus с раз-работанным инструментарием Globus Toolkit, позволяет объединить множество территори-ально распределенных гетерогенных ресурсов в единую виртуальную систему. Инструментарий Globus Toolkit имеет открытый исходный код. Стоит понимать, что данный инструментарий не является готовым техническим решением для организации распределенных вычислений, а представляет собой лишь набор стандартов и инструментов. Широкое применение инструментария обуславливается, прежде всего, отсутствием жесткой модели программирования, в результате чего разработчик может использовать широкий набор инструментов в соответствии с потребностью. Проект Globus был поддержан многими производителями программного обеспечения, такими как IBM, Sun, HP, Intel. Проект Legion был разработан в университете Вирджиния и предоставляет собой программную среду для организации географически распределенной системы, в состав которой могут входить рабочие станции, векторные супер-компьютеры и параллельные суперкомпьютеры [19]. Основное отличие от подобного рода систем является поддержка объектно-ориентиро-ванного модели, в которой грид представлялся в виде легиона и все компоненты являются компонентами. Однако многих исследователей отталкивала объектно-ориентированная модель, вследствие чего их внимание смещалось в сторону Globus, а проект был закрыт.Концепция гридсистем активно развивается и отечественными учеными. К примеру, исследователями Лаборатории вычислительных си-стем Института физики полупроводников им. А.В. Ржанова СО РАН и Центром параллельных вычислительных технологий Сибирского государственного университета телекоммуни-каций и информатики (СибГУТИ) создана мас-штабируемая GRID-модель – пространственнораспределенная мультикластерная ВС. В состав системы входят вычислительные кластеры данных организаций. Операционная систе-ма системы построена на ядре Linux. Так же в состав системы входит инструментарий раз-работчика для разработки программных продуктов, включаещий такие средства как GCC, ряд библиотек для организации параллельных вычислений(MPI, OpenMP). Дальнейшим развитием в области построения пространственно-распределенных систем явилась разработка третьего поколения GRID. Основная задача построения данных систем на-правлена не на стандартизации интерфейсов, а на решение вопросов самоорганизации и автоматизации процессов, происходящих в GRID [20]. Стоит понимать, что исследования в области стандартизации интерфейсов не остановились, а продолжают развиваться в таких концепциях, как SOA и SOC, что привело к созданию новых коммуникационных протоколов, в частности SOAP (Simple Object Access Protocol). Ярким примером демонстрирующий вектор развития систем является концепция, выдвинутая фирмой IBM в 2001 году, которая полу-чила название «автономные вычисления». Для реализации концепции автономных вычислений необходимо, чтобы система удовлетворяла ряду требований:
• Самовосстановление. Система должна вос-станавливаться в рабочее состояние в случае возникновения сбоя
• Самоконфигурирования. Система должна самостоятельно конфигурировать свое ПО в случае обновления.
• Самозащита. Система должна обеспечивать сохранность данных при возможных попытках вторжения в систему. Развитием создания грид-систем с идеоло-гией «автономных вычислений» явились такой проект как IBM OptimalGrid. В дальнейшем идеология автономных грид-систем была подхвачена многими проектами в области распре-деленной обработки данных и существующие системы в той или иной степени поддерживают идеологию автономных вычислений.
1.2 Преимущества и недостатки использования распределённых информационных систем
В настоящее время практически все большие программные системы являются распределенными. Распределенная система - система, в которой обработка информации сосредоточена не на одной вычислительной машине, а распределена между несколькими компьютерами. При проектировании распределенных систем, которое имеет много общего с проектированием ПО в общем, все же следует учитывать некоторые специфические особенности.
Существует шесть основных достоинств распределенных систем:
•Совместное использование ресурсов. Распределенные системы допускают совместное использование как аппаратных (жестких дисков, принтеров), так и программных (файлов, компиляторов) ресурсов.
•Открытость. Это возможность расширения системы путем добавления новых ресурсов.
•Параллельность. В распределенных системах несколько процессов могут одновременно выполнятся на разных компьютерах в сети. Эти процессы могут взаимодействовать во время их выполнения.
•Масштабируемость. Под масштабируемостью понимается возможность добавления новых свойств и методов.
•Отказоустойчивость. Наличие нескольких компьютеров позволяет дублирование информации и устойчивость к некоторым аппаратным и программным ошибкам. Распределенные системы в случае ошибки могут поддерживать частичную функциональность. Полный сбой в работе системы происходит только при сетевых ошибках.
•Прозрачность. Пользователям предоставляется полный доступ к ресурсам в системе, в то же время от них скрыта информация о распределении ресурсов по системе.
Распределенные системы обладают и рядом недостатков:
•Сложность. Намного труднее понять и оценить свойства распределенных систем в целом, их сложнее проектировать, тестировать и обслуживать. Также производительность системы зависит от скорости работы сети, а не отдельных процессоров. Перераспределение ресурсов может существенно изменить скорость работы системы.
•Безопасность. Обычно доступ к системе можно получить с нескольких разных машин, сообщения в сети могут просматриваться и перехватываться. Поэтому в распределенной системе намного труднее поддерживать безопасность.
•Управляемость. Система может состоять из разнотипных компьютеров, на которых могут быть установлены различные версии операционных систем. Ошибки на одной машине могут распространиться непредсказуемым образом на другие машины.
•Непредсказуемость. Реакция распределенных систем на некоторые события непредсказуема и зависит от полной загрузки системы, ее организации и сетевой нагрузки. Так как эти параметры могут постоянно изменятся, поэтому время ответа на запрос может существенно отличаться от времени.
•Из этих недостатков можно увидеть, что при проектировании распределенных систем возникает ряд проблем, которые надо учитывать разработчикам:
•Идентификация ресурсов. Ресурсы в распределенных системах располагаются на разных компьютерах, поэтому систему имен ресурсов следует продумать так, чтобы пользователи могли без труда открывать необходимые им ресурсы и ссылаться на них. Примером может служить система URL(унифицированный указатель ресурсов), которая определяет имена Web-страниц.
•Коммуникация. Универсальная работоспособность Internet и эффективная реализация протоколов TCP/IP в Internet для большинства распределенных систем служат примером наиболее эффективного способа организации взаимодействия между компьютерами. Однако в некоторых случаях, когда требуется особая производительность или надежность, возможно использование специализированных средств.
•Качество системного сервиса. Этот параметр отражает производительность, работоспособность и надежность. На качество сервиса влияет ряд факторов: распределение процессов, ресурсов, аппаратные средства и возможности адаптации системы.
•Архитектура программного обеспечения. Архитектура ПО описывает распределение системных функций по компонентам системы, а также распределение этих компонентов по процессорам. Если необходимо поддерживать высокое качество системного сервиса, выбор правильной архитектуры является решающим фактором.
2. Классификация существующих подходов к построению распределённой информационной системы
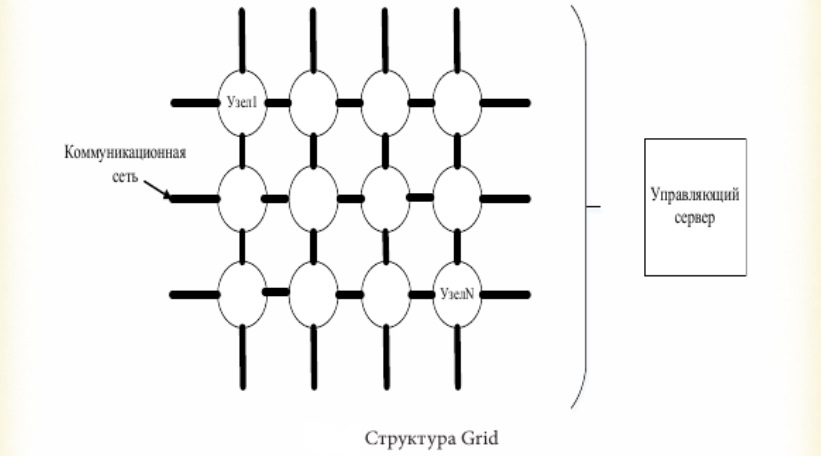
Современная вычислительная сеть является сложным комплексом взаимосвязанных программных и аппаратных компонентов (рис. 4). Весь комплекс программно-аппаратных средств сети может быть описан многослойной моделью, которая должна соответствовать общему назначению сети1: компьютеры, коммуникационное оборудование, операционные системы, сетевые приложения.
 |
|
Рисунок 4 |
В основе любой сети лежит аппаратный слой стандартизированных компьютерных платформ, серверов, рабочих станций и ПК. В настоящее время в сетях успешно работают компьютеры различных классов — от персональных до мейнфреймов и супер ЭВМ. Второй слой — коммуникационное оборудование. Кабельные системы, повторители, коммутаторы, маршрутизаторы и модульные концентраторы превратились в полноправные компоненты сети.
Сегодня коммуникационное устройство может представлять собой сложное специализированное мультипроцессорное устройство, которое нужно конфигурировать, администрировать и оптимизировать его работу в сети.
Третьим слоем, образующим программную платформу сети, являются операционные системы. От того, какие концепции управления локальными и распределенными ресурсами положены в основу сетевой операционной системы, зависит эффективность работы всей сети. При проектировании сети важно учитывать:
• насколько легко данная операционная система может взаимодействовать с другими сетевыми операционными системами;
• какой она обеспечивает уровень безопасности и защищенности данных;
• до какой степени позволяет наращивать число пользователей;
• можно ли перенести ее на компьютер другого типа и многие другие соображения.
Самый верхний, четвертый слой образуют различные сетевые приложения, такие, как сетевые базы данных, средства передачи и архивирования данных, системы автоматизации коллективной работы и т.д. Очень важно представлять диапазон возможностей, предоставляемых приложениями для различных областей применения, а также знать, насколько они совместимы с другими сетевыми приложениями и операционными системами.
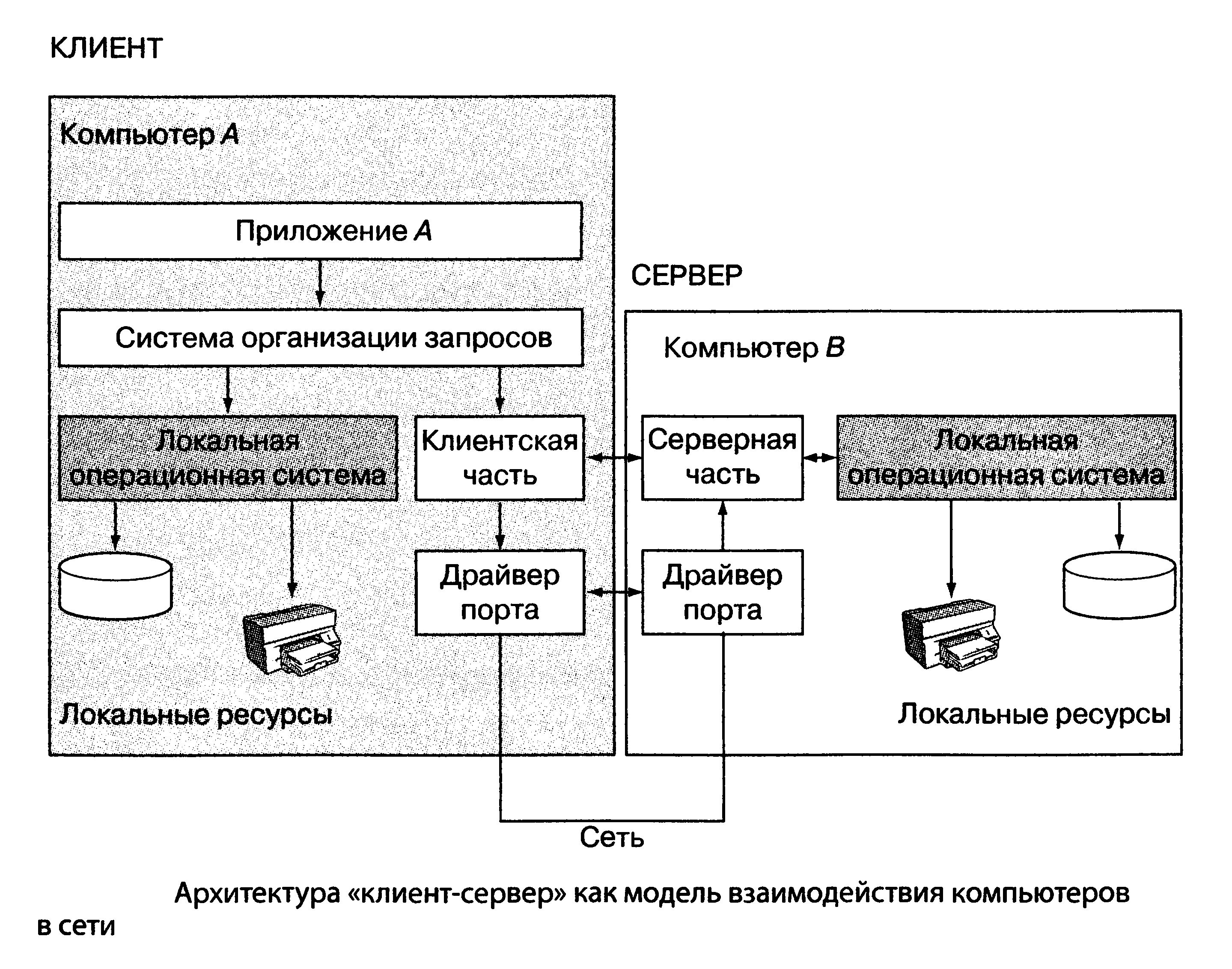
Архитектура «клиент-сервер» представляет собой модель взаимодействия компьютеров в сети. Как правило, один компьютер в сети располагает информационно-вьиислительными ресурсами, такими, как мощные процессоры, программные приложения, базы данных и различные сервисы. Другие же компьютеры пользуются ими (рис. 5). Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса (Resource Server — RS), а компьютер, который пользуется этим ресурсом, — клиентом (Clients).
Конкретный сервер характеризуется видом ресурса, которым он владеет. Если используемым ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого состоит в обслуживании запросов клиентов по выдаче или преобразованию данных. Если применяется файловая система или система пересылки сообщений, то говорят о файловом или почтовом сервере. Этот же принцип распространяется и на взаимодействие процессов. Если один из них выполняет некоторые функции, предоставляя соответствующий набор услуг, такой процесс рассматривается
 |
|
Рисунок 5 |
в качестве сервера. Сегодня технология «клиент-сервер» получает все большее распространение, однако сама по себе она не предлагает универсальных рецептов, а лишь дает общее представление о том, как должна быть организована современная распределенная ИС. В каждом конкретном случае технологическое решение должно быть основано на конкретных предметных областях и соответствующих прикладных платформах.
В соответствии с этим один из основных принципов технологии «клиент-сервер» заключается в разделении функций стандартного приложения на три группы, имеющие различные назначение и структуру. В любом приложении выделяются следующие логические компоненты:
• компонент ввода и представления данных (Data Input/ Presentation);
• прикладной компонент (Business Application), который поддерживает функции, необходимые для выполнения действий в данной предметной области;
• компонент доступа к информационным ресурсам (Resource Acces) или менеджер ресурсов (Resource Manager), поддерживающий глобальные функции хранения и управления данными (базами данных, файловыми и почтовыми системами и т.д.).
Различия в реализации приложений в рамках технологии «клиент-сервер» определяются тем, какие механизмы используются для реализации функций всех трех групп и как логические компоненты распределяются между компьютерами в сети. Выделяют три подхода, каждый из которых реализован в соответствующей модели: доступа к удаленным данным (Remote Date Access — RDA), сервера базы данных (DateBase Server — DBS), сервера приложений (Application Server — AS).
2.1 По месту обработки данных
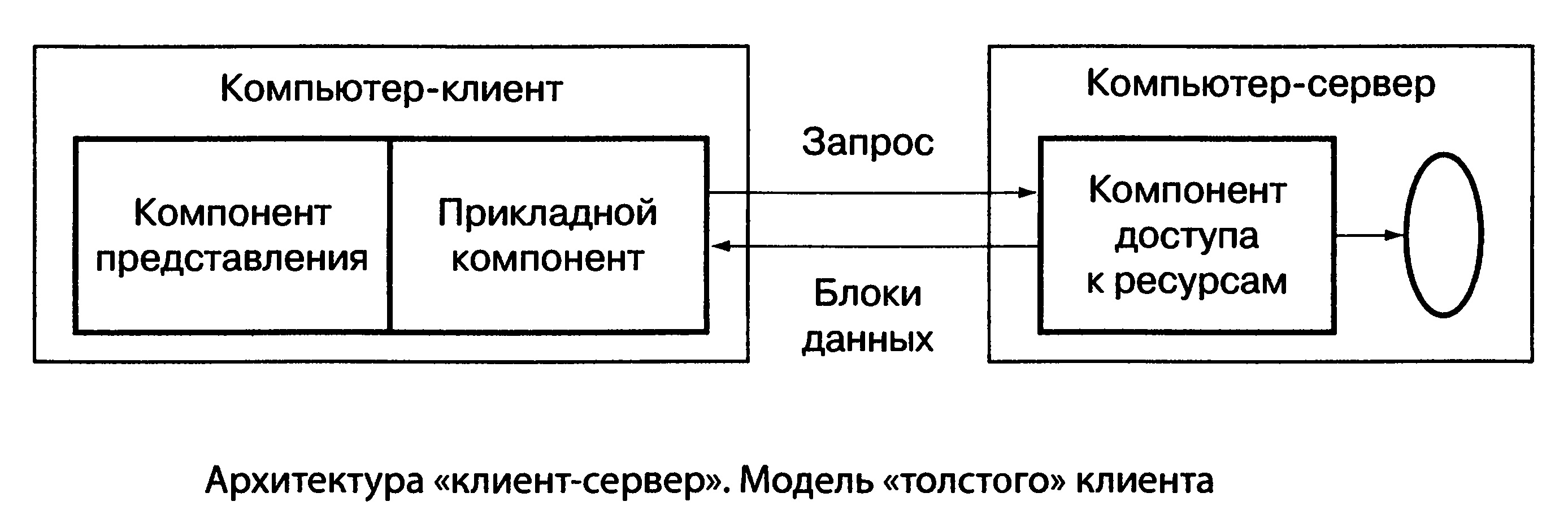
В модели доступа к удаленным данным (RDA-модель) реализации компонента представления данных и прикладного компонента совмещены и выполняются на компьютере-клиенте. Этот компьютер поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к удаленным ИР обеспечивается, как правило, с помощью специального языка запросов SQL — если речь идет о базах данных, или вызовами функций специальных библиотек — если имеется соответствующий интерфейс API. Запросы направляются по сети удаленному компьютеру (например, серверу базы данных), который обрабатывает и выполняет запросы и возвращает клиенту блоки данных. Говоря о таком виде архитектуры «клиент-сервер», в большинстве случаев имеют в виду модель, называемую «толстым клиентом» (рис. 6).
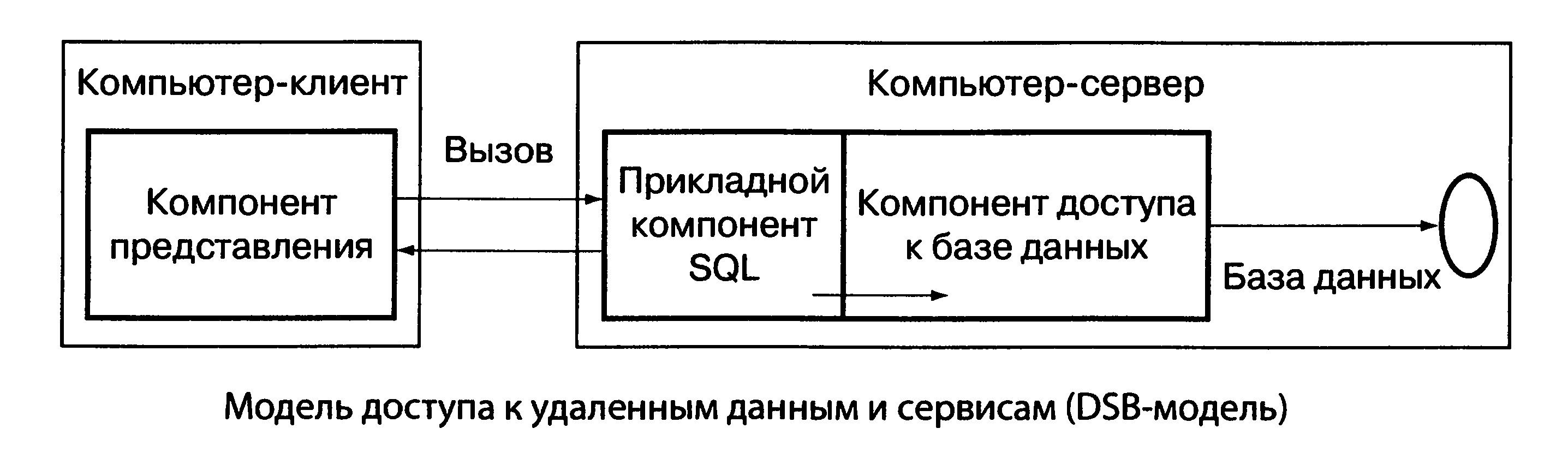
Модель доступа к удаленным, данным и сервисам, обслуживающим работу по извлечению, передаче и записи данных (DSB-модель), строится в предположении, что процесс, выполняемый на компьютере-клиенте, ограничивается функциями представления, а собственно прикладные функции реализованы в хранимых процедурах
 |
|
Рисунок 6 |
 |
|
Рисунок 7 |
(Stored Procedure — SP), которые называют компилируемыми резидентными процедурами или процедурами базы данных: (рис. 7). Они находятся непосредственно в базе данных и выполняются на компьютере-сервере (где функционирует ядро СУБД). В этом случае понятие «информационный ресурс» сужено до конкретной базы данных, поскольку механизм управления хранимыми процедурами заложен прямо в СУБД. На практике часто используются смешанные модели, когда поддержка целостности базы данных и некоторые прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а часть сложных функций реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель).
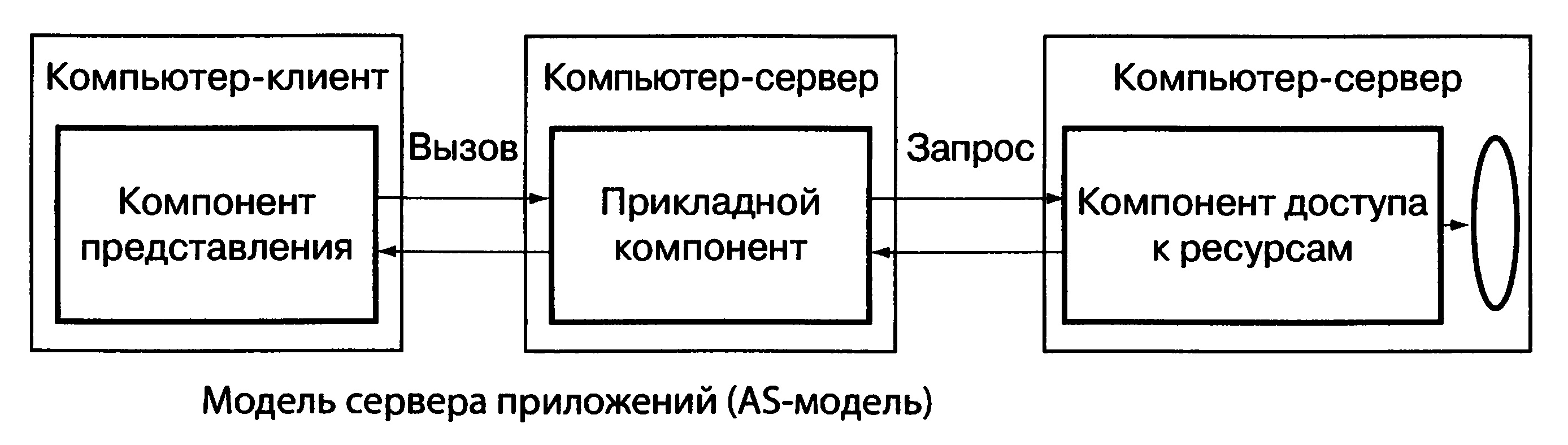
В модели сервера приложений (AS-модель) процесс, выполняющийся на компьютере-клиенте, отвечает, как правило, за ввод и отображение данных. Прикладные функции выполняются группой процессов (серверов приложений), функционирующих на удаленном компьютере (или нескольких компьютерах). Доступ к ИР, необходимым для решения прикладных задач, обеспечивается ровно тем же способом, что и в RDA-модели. Из прикладных компонентов доступны ресурсы различных типов: базы данных, индексированные файлы, очереди, и др. Серверы приложений выполняются, как правило, на том же компьютере, где функционирует менеджер ресурсов, однако могут находиться и на других компьютерах (рис. 8). Модель «клиент-сервер», когда подавляющее
 |
|
Рисунок 8 |
большинство прикладных программ и сервисов расположено на стороне сервера, называется «тонким» клиентом. Подчеркнем важное архитектурное и функциональное различие между рассмотренными моделями.
Модели RDA и DBS реализуют двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором — интегрируется в комдонент доступа к информационным ресурсам.
Напротив, в AS-модели реализована классическая трехзвенная схема разделения функций, когда прикладной компонент выделен как важнейший элемент приложения. Для его реализации используются универсальные механизмы многозадачной операционной системы и стандартизованные интерфейсы для взаимодействия с двумя другими компонентами. Собственно, из этой особенности AS-модели и вытекают ее преимущества, которые имеют важнейшее значение для чисто практической деятельности по организации коллективной работы в локальной сети или распределенной работы с удаленными базами данных или сервисными приложениями через Internet.
В распределенных корпоративных информационных системах
(КИС) с портальной моделью представления данных, информационного отображения и сопровождения процессов, а также жесткой системой информационной безопасности используется, как правило, трехзвенная модель, однако каждая из описанные выше моделей свои имеет преимущества и используется самостоятельно и в разных сочетаниях с другими моделями и приложениями.
Для передачи данных применяются различные структуры коммутации. В первой из них взаимодействующие ИС связаны выделенным каналом. Такое взаимодействие называется смежным, и это наиболее эффективная структура в смысле безопасности и надежности передачи данных, но пригодная лишь в том случае, когда система должна взаимодействовать лишь с одним партнером и расстояние между ними невелико. При большом расстоянии в канал следует «врезать» повторители, усилители и другие подобные им устройства. В тех случаях, когда система должна работать с группой партнеров, используется ячеистая сеть, состоящая из каналов и узлов коммутации. В другой структуре передатчик направляет блоки данных в сервер, который накапливает их и передает получателю тогда, когда последний будет готов их принять, например, ПК или мобильному устройству, которые часть времени отключены от сети.
Передача данных между смежными и несмежными системами происходит по-разному. Между смежными системами передача опирается на физическую платформу, которая включает в себя лишь физический уровень и физические средства соединения (рис. 9).
В соответствии с эталонной семиуровневой моделью взаимодействия открытых систем (Reference Model of Open System Interconnection — RM OSI) в сетях коммутации пакетов для передачи данных между несмежными системами создается сетевая платформа, образуемая физическими средствами соединения, физическим, канальным и сетевым уровнями. Оконечные системы частично погружены в эту платформу, а над ней располагаются только 4—7 уровни этих систем. На границе сетевого и транспортного уровня прикладные процессы передают друг другу пакеты данных.
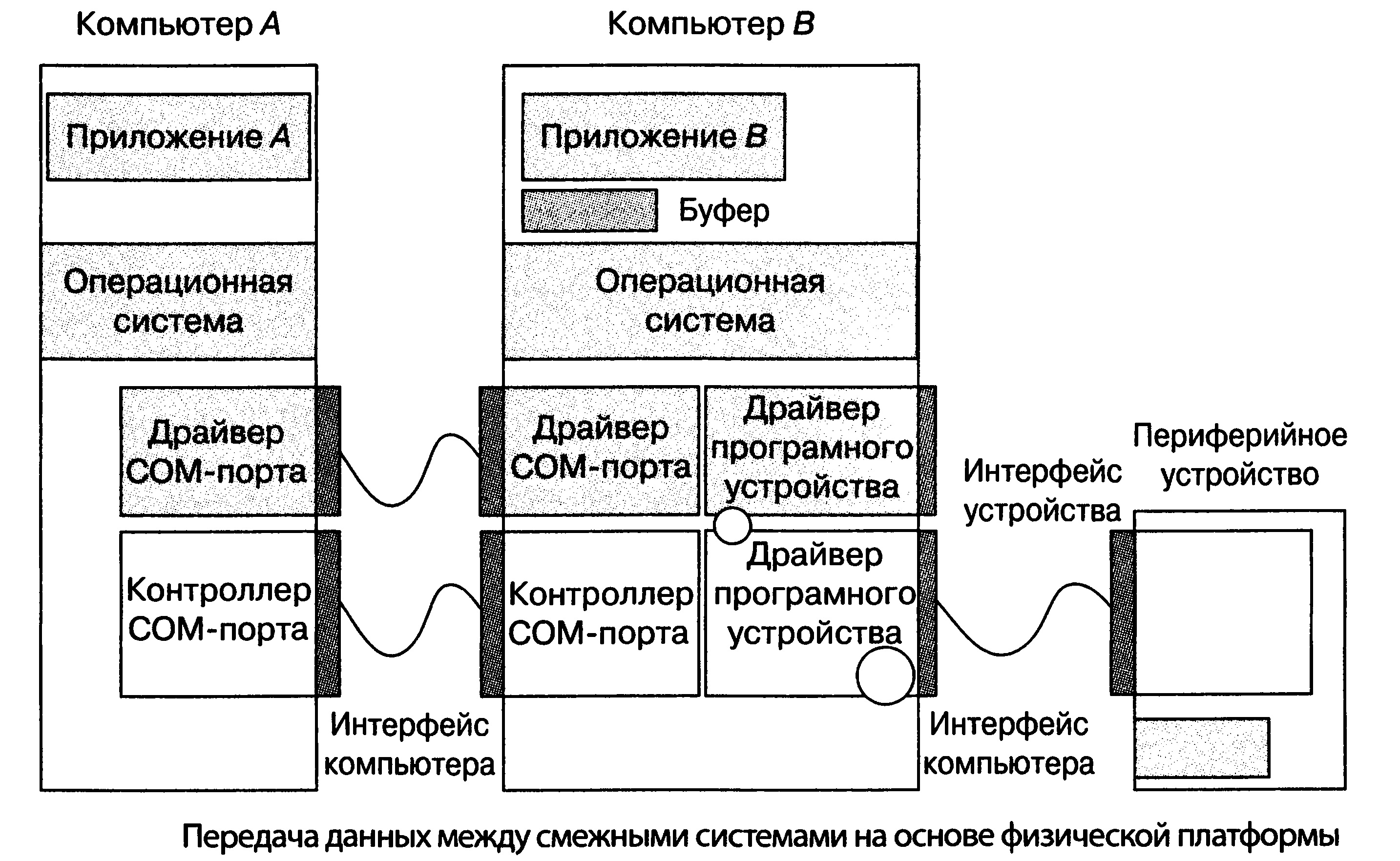 |
|
Рисунок 9 |
2.2 По архитектуре
2.2.1. Двухзвенная архитектура.
Является наиболее распространенной в мелких и средних системах автоматизации. Клиентское ПО сервера БД находится на клиентской машине.
Преимущества: При небольшом количестве клиентов, расположенных локально к серверу – вполне приемлемая архитектура.
Недостатки: Подобные рабочие станции должны предоставлять для самих себя весь требующийся для этого набор сервисов и содержать соответствующее программное обеспечение для их функционирования. Подобное требование нередко приводит к:
• усложнению технических требований, предъявляемых к аппаратной части клиентской рабочей станции,
• в конечном итоге приводит к удорожанию всей системы в целом
• ухудшает масштабируемость
• усложняет возможность оперативной модификации
• работе по настройке ПО на рабочих местах и поддержанию этих настроек в рабочем состоянии.
2.2.2. Трёхзвенная архитектура
Третьим звеном в архитектуре клиент-сервер являются так называемые сервисы промежуточного слоя (middleware services), поскольку они занимают промежуточный уровень между данными и сервисами, их обслуживающими, с одной стороны, и пользовательскими приложениями, ориентированными на конкретную предметную область, с другой стороны. Эти сервисы обычно обладают минимальным пользовательским интерфейсом или не имеют его вовсе. Нередко они могут быть реализованы для нескольких различных платформ, так как являются сервисами более высокого уровня, чем сервисы, специфичные для данной операционной системы или СУБД. Кроме того, на сервере приложений может быть реализована и дополнительная функциональность.
Преимущества: Сервер доступа к данным имеет 1 соединение с СУБД, которое, как правило, разделяется между клиентами, таким образом сервер приложений мультиплексирует соединение. Этот факт может позволить сильно сэкономить в финансовом плане при приобретении лицензионной СУБД, т.к. многие ведущие производители серверных СУБД определяют стоимость использования их продуктов в зависимости от числа подключений к БД, которое при использовании сервера доступа к данным равно 1. Бизнес логика приложения может формироваться на сервере доступа к данным, а отражаться на все клиентские приложения.
Недостатки: Система усложняется.
2.3 По нахождению необходимой функциональности
2.3.1. Статическая функциональность
Программное обеспечение функциональности клиента всегда находится на клиентской машине и изменяется только при модификации его разработчиком.
• Обычные клиентские приложения
Преимущества:
Приложение статично и не требует встроенных в систему механизмов обновления. Вполне приемлемо для редко изменяемого ПО.
Недостатки: Затрудняется оперативная модификация клиентских приложений, особенно в случае если они многочисленных и далеко расположены. При модификации приложения часто требуется замена большей его части.
2.3.2. Динамическая функциональность (рассылка функциональности)
На клиентских местах находится лишь универсальное клиентское программное обеспечение, умеющее читать и обеспечивать работу для пользователя функциональной составляющей приложения, которая присылается с сервера, сохраняется на клиенте и заменяется при появлении на сервере новых её версий.
• Java
• ActiveX
• DHTML
• Системы обработки скриптов на клиенте
Преимущества: Замена версий происходит автоматически. Появляется возможность создавать глобальные системы (WWW).
Недостатки: Усложнение системы.
2.4 По топологии сети
При любом типе соединения, как только компьютеров становится больше двух, возникает проблема выбора конфигурации физических связей или топологии сети. Под топологией сети понимается конфигурация графа, вершинам которого соответствуют конечные узлы сети (компьютеры, рабочие станции, серверы или исполнительные устройства) и коммуникационное оборудование (коммутаторы, маршрутизаторы), а ребрам — электрические, электронные и информационные связи между ними. Число возможных конфигураций резко возрастает при увеличении числа связываемых устройств.
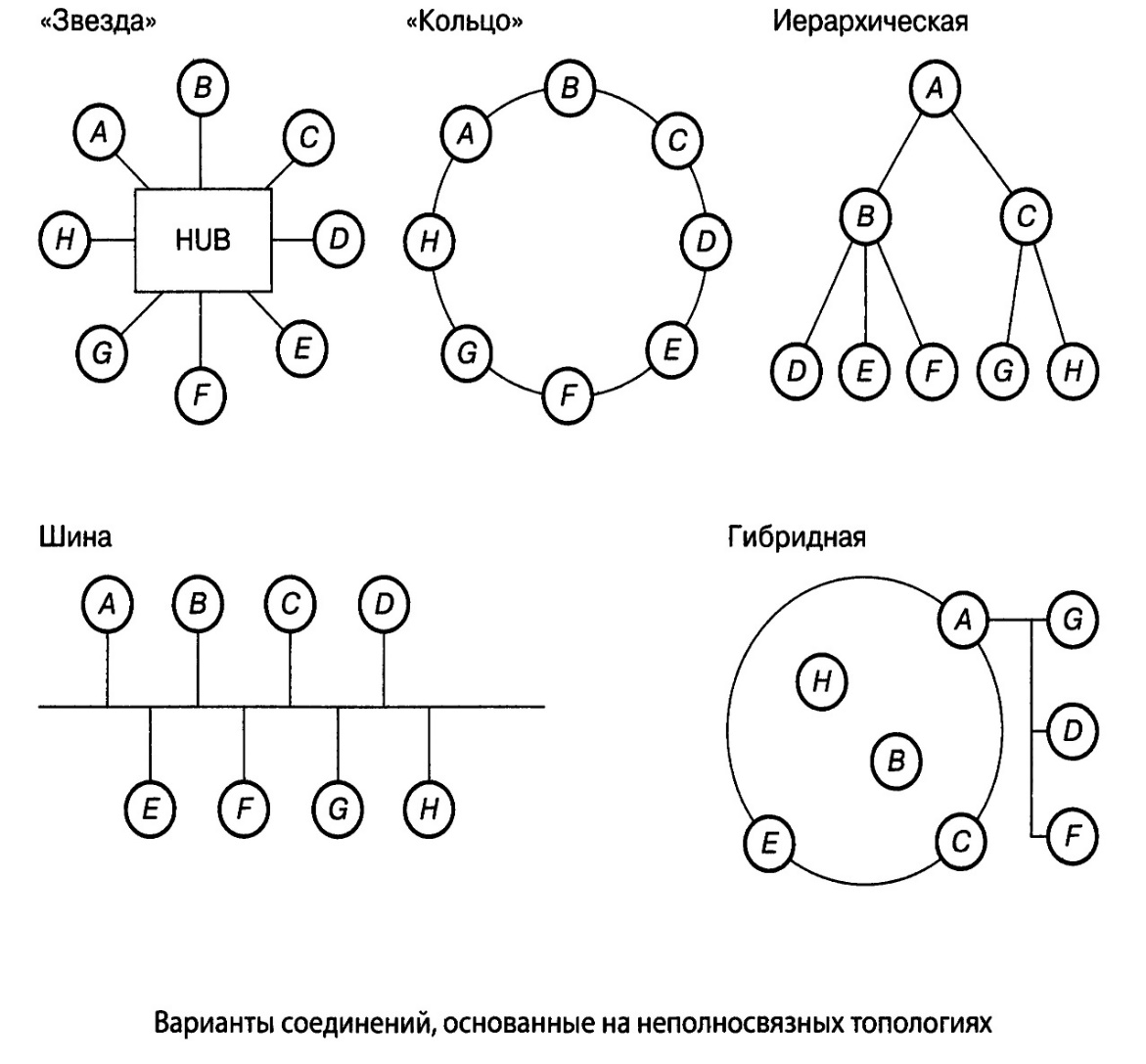
'Гак, если три компьютера однозначно связываются двумя способами, то для четырех компьютеров можно предложить уже шесть топологически различных конфигураций (при условии однотипности компьютеров). Множество возможных конфигураций объединяются в две основные группы: полносвязные (Fully Connected Topology) и неполносвязные (Incompletely Connected Topology) (рис. 10).
Полносвязная топология соответствует сети, в которой каждый компьютер непосредственно связан с каждым. Логически это самый простой вариант, но самый громоздкий и неэффективный. Во-первых, каждый компьютер в сети должен иметь большое число коммуникационных портов, достаточное для связи с каждым из остальных компьютеров. Во-вторых, для каждой пары компьютеров должна быть выделена отдельная физическая линия связи, а в некоторых случаях даже две, если невозможно использование этой линии для двусторонней передачи. Полносвязные топологии в крупных сетях применяются редко, так как для связи N узлов требуется N (N- 1)/2 физических дуплексных линий связи. Чаще этот вид топологии используется в комплексах, где очень жесткие требования к безопасности и надежности, или в сетях, объединяющих небольшое число выделенных компьютеров. Ячеистая топология (Mesh Network) получается из полносвязной путем удаления некоторых нефункциональных связей. Такая топология допускает соединение большого числа компьютеров и характерна для крупных корпоративных сетей.
|
|
|
Рисунок 10 |
Все другие варианты соединений (рис. 11), основанные на неполносвязных топологиях, — когда для обмена данными между двумя несмежными компьютерами может потребоваться промежуточная передача данных через другие узлы сети — применяются в зависимости от числа компьютеров в сети, информационной нагрузки (трафика), уровня распределенности сети, числа прикладных и сервисных программ, требований к безопасности и т.д.
Программно-аппаратные устройства распределенной обработки данных являются составной частью информационной инфраструктуры высокотехнологичных компаний (рис. 11). На сегодняшний день на российском рынке представлены многочисленные продукты зарубежных и российских производителей для реализации соответствующих функций в распределенных корпоративных системах.
|
|
|
Рисунок 11 |
3. Особенности конкретных реализаций
Далее пойдет описание конкретных технологий распределенной обработки данных, таких как DCOM, COBRA, EJB и WEB технологий.
3.1 Технология COM
Распределенный СОМ Microsoft (DCOM) развивает многокомпонентную модель (СОМ) до уровня поддержки связи между объектами различных компьютеров - по ЛВС, ГВС или даже Интернет. Исполнение вашего приложения при помощи DCOM может быть распределено по местам, наиболее удобным для пользователя.
DCOM — это последовательное развитие СОМ, а значит, ваши инвестиции в создание СОМ-приложений, компонентов, инструментария плавно переносятся в сферу стандартизованных распределенных решений.
DCOM берет на себя низкоуровневые детали сетевых протоколов, а вы сможете сфокусироваться на вашем настоящем деле: создании хороших решений для пользователей.
DCOM возможно использовать для решения сложнейших проблем, связанных с распределенными приложениями:
- устойчивой работе в случае аварии аппаратного обеспечения
- работе как по обслуживанию небольшой рабочей группы, так и в качестве большого корпоративного сайта
- устойчивости в работе при авариях сети
- в работе на пользовательских машинах с различными параметрами или в различных географических зонах
- большей эффективности в условиях загруженности сети
Ниже будет описано, каким образом DCOM решает эти и другие проблемы для новых или уже существующих приложений.
Достоинства DCOM:
- Независимость от местоположения.
- Управление соединением.
- Масштабируемость.
- Быстродействие.
- Полоса пропускания и латентность.
- Безопасность.
- Баланс загрузки.
- Устойчивость к авариям.
- Гибкость в перераспределении.
- Нейтральность протокола.
- Нейтральность платформы.
- Безболезненная интеграция с другими протоколами Интернет.
Как получить DCOM?
В данный момент DCOM поставляется с Windows NT 4.0 и до конца 1996 года будет поставляться с Windows 95. В начале 1997 года Microsoft предложит вам DCOM для Apple Macintosh. Кроме того, с начала 1997 года будет доступен инструментарий DCOM для большинства UNIX-платформ, включая его исходные коды. COM и DCOM больше не являются монополией Microsoft, а управляются независимым консорциумом ActiveX (ActiveX Consortium).
Распределение приложений - это не самоцель. Распределенные приложения предоставляют вам абсолютно новые решения в проектировании и развитии. Для того, чтобы получить эти дополнительные возможности, необходимо сделать значительные вложения. Некоторые приложения являются распределенными изначально: многопользовательские игры, приложения для обмена мнениями, для телеконференций - все это примеры подобных приложений. Для них преимущества устойчивой инфраструктуры очевидны. Многие другие приложения также являются распределенными в том смысле, что они имеют как минимум два компонента, работающие на различных машинах. Но, поскольку эти приложения не были созданы для использования в распределенной среде, они достаточно ограничены в масштабируемости и в гибкости перераспределения. Любой тип поточных или групповых приложений, большинство приложений клиент/сервер и даже некоторые desktop-приложения обязательно управляют способом коммуникаций и кооперации своих пользователей. Рассмотрение таких приложений в качестве распределенных и работа с нужным компонентом в нужном месте предоставляют пользователю преимущества и оптимизируют использование сетевых и компьютерных ресурсов. Приложения, которые разрабатывались как распределенные, могут совмещать различных клиентов с различными мощностями посредством работы компонента со стороны клиента, если это возможно, и - со стороны сервера, когда это необходимо.
Разработка распределенных приложений дает системному менеджеру большое преимущество в виде гибкости в перераспределении.
К тому же, распределенные приложения являются гораздо более масштабируемыми, нежели их монолитные собратья. Если вся логика комплексного приложения сосредоточена в едином модуле, есть единственный способ ускорить работу без настройки приложения: более скоростное аппаратное обеспечение. Сегодняшние серверы и операционные системы легко модифицируются, однако чаще бывает дешевле приобрести еще одну такую же машину, нежели сделать upgrade, чтобы ускорить сервер вдвое. При правильно сконструированном распределенном приложении в начале работы все компоненты могут запуститься с одного сервера. При увеличении загрузки некоторые компоненты могут перераспределяться на дополнительные, менее дорогостоящие машины.
DCOM является развитием многокомпонентной модели (СОМ). СОМ определяет, каким образом компоненты взаимодействуют со своими клиентами. Это взаимодействие осуществляется таким образом, чтобы клиент и компонент могли соединяться без необходимости использовать некоторый промежуточный компонент системы и клиент мог вызывать методы компонента. Рисунок 12 иллюстрирует это с точки зрения многокомпонентной модели.
|
|
|
Рисунок 12 |
В сегодняшних операционных системах процессы изолированы друг от друга. Клиент, которому нужно связаться с компонентом другого объекта, не может вызвать компонент напрямую, а должен использовать некоторую форму связи между процессами, предусмотренную операционной системой. СОМ организует подобное соединение в полностью прозрачной манере: он перехватывает вызовы со стороны клиента и адресует их компоненту другого процесса. Рисунок 13 показывает, как run-time библиотеки COM/DCOM организуют соединение между клиентом и компонентом.
|
|
|
Рисунок 13 |
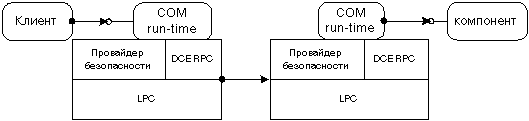
Когда клиент и компонент находятся на различных машинах, DCOM просто заменяет локальное соединение между процессами сетевым протоколом. При этом ни клиент, ни компонент и не подозревают, что провода, соединяющие их, стали чуть длиннее.
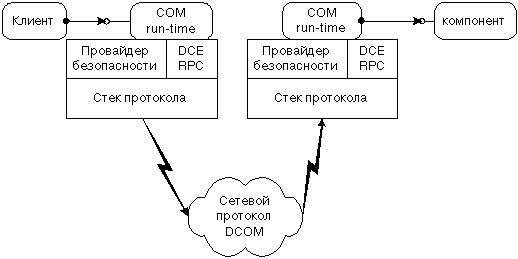
Рисунок 14 показывает архитектуру DCOM в общем: СОМ run-time предлагает клиентам и компонентам объектно-ориентированные сервисы и использует RPC и провайдер безопасности для генерации стандартных сетевых пакетов, соответствующих стандарту протокола DCOM.
|
|
|
Рисунок 14 |
Большая часть распределенных приложений разрабатывалась не наспех и не в вакууме. Существующая инфраструктура аппаратного обеспечения, существующее программное обеспечение, существующие компоненты и инструменты должны быть интегрированы и призваны уменьшить время и стоимость разработки и перераспределения. В смысле инвестиций DCOM имеет несомненные преимущества перед любыми СОМ компонентами и инструментами. Огромный рынок компонентов позволяет уменьшить время разработки с помощью интегрирования стандартизованных решений в пользовательское приложение. Многие разработчики знакомы с СОМ и могут легко применить свои знания в создании распределенных DCOM-приложений.
Любой компонент, разрабатывавшийся как часть распределенного приложения - кандидат для повторного использования в будущем. Организация процесса разработки по компонентному принципу позволяет непрерывно повышать уровень функциональности новых приложений и уменьшать время разработки, используя уже выполненную работу в качестве основы для развития. Проектирование в СОМ и DCOM обеспечивает использование ваших компонентов и сегодня, и в будущем.
Когда вы начинаете использовать распределенное приложение в реальной сети, выявляется несколько особенностей:
- Компоненты, взаимодействующие чаще, должны быть “ближе” друг к другу.
- Некоторые компоненты могут работать на определенных машинах или в определенных местах.
- Использование меньших по размеру компонентов увеличивает гибкость в перераспределении, но при этом увеличивается сетевой трафик.
- Компоненты большего размера уменьшают сетевой траффик, но зато уменьшается и гибкость в перераспределении.
С помощью DCOM эти критические моменты обходятся достаточно легко, поскольку в исходном коде не определены детали перераспределения. DCOM полностью скрывает местоположение компонента, будь он в том же процессе, что и клиент, или на другом конце света. В любом случае способы, которыми клиент соединяется с компонентом и вызывает методы компонента, идентичны. DCOM не нуждается не только в изменениях исходного кода, но даже и в рекомпиляции программы. Простая реконфигурация изменяет способ, которым компоненты соединяются друг с другом.
Независимость DCOM от местоположения значительно упрощает задачу распределения компонентов приложения для получения оптимального быстродействия в целом. Представим, например, что определенные компоненты должны находиться на определенных машинах или в определенных местах. Если приложение имеет большое число маленьких компонентов, вы можете уменьшить загрузку сети перемещением их в нужный сегмент ЛВС, на нужную машину или даже в нужный процесс. Если приложение состоит из меньшего числа больших компонентов, загрузка сети - меньшая из проблем, так как вы можете разместить компоненты на более быстрые из доступных машин.
Рисунок 15 демонстрирует, как один и тот же компонент может быть перенесен на машину клиента при удовлетворительной полосе пропускания между машиной “клиент” и машиной “среднего слоя”, и на машине сервера, если клиент работает с приложением по медленному сетевому соединению.
|
|
|
Рисунок 15 |
Благодаря независимости DCOM от местоположения, приложение может перемещать взаимодействующие компоненты с “близлежащих” машин на одну и ту же машину или даже в один процесс. Даже если функциональность большого логического модуля организуется большим числом маленьких компонентов, они могут по-прежнему эффективно взаимодействовать друг с другом. Компоненты могут работать на машине, на которой это наиболее целесообразно: пользовательский интерфейс находится на машине клиента или “рядом” с ней. Компонент, работающий с базой данных, – на сервере “близко” к базе данных.
Общим вопросом при проектировании и разработке распределенного приложения является выбор языка или инструмента для данного компонента. Язык обычно выбирают с учетом затрат на разработку, с учетом имеющейся квалификации и необходимого быстродействия. Как развитие СОМ, DCOM абсолютно не зависит от языка. Теоретически для создания СОМ-компонентов может использоваться любой язык и эти компоненты могут использоваться большим числом языков и инструментов. Java, Microsoft Visual C++, Microsoft Visual Basic, Delphi, PowerBuilder и Micro Focus COBOL - все они хорошо взаимодействуют с DCOM.
Нейтральность DCOM по отношению к языку позволяет разработчику приложения выбирать язык и инструменты, с которыми он чувствует себя наиболее свободно. Независимость от языка, кроме того, позволяет выполнять быстрое прототипирование: вначале компоненты могут быть разработаны на языке высокого уровня, таком как Microsoft Visual Basic, а позже - на другом языке, таком как C++ или Java, лучше использующем преимущества таких продвинутых функций DCOM, как многопоточность и объединение потоков.
Сетевые соединения не так устойчивы, как соединения внутри машины. Компоненты распределенного приложения должны знать, что клиент более не активен, даже – или в особенности – в случае сетевой или аппаратной аварии.
DCOM управляет соединением компонентов, предназначенных для одного клиента, так же, как и компонентов, обслуживающих несколько клиентов, используя счетчик ссылок для каждого компонента. Когда клиент соединяется с компонентом, DCOM увеличивает значение счетчика ссылок компонента. Когда клиент разрывает соединение, DCOM уменьшает значение счетчика ссылок компонента. Если значение счетчика достигает нуля – компонент свободен.
Для определения активности клиента DCOM использует эффективный протокол отслеживания. Машина клиента посылает периодическое сообщение. При нарушении соединения DCOM уменьшает счетчик и освобождает компонент, если значение счетчика станет равным нулю. С точки зрения компонента, случай отключения клиента, случай аварии сети и случай поломки машины клиента регистрируются одним и тем же механизмом подсчета. Приложения могут использовать такой механизм подсчета соединений для своего высвобождения.
Во многих случаях поток информации между компонентом и его клиентами не однонаправлен: компоненту нужно инициировать некоторые действия со стороны клиента, например, извещение о том, что длительный процесс завершился, обновляются данные, просматриваемые пользователем (обзор новостей), или поступило следующее сообщение в телеконференции или многопользовательской игре. Многие протоколы усложняют процесс осуществления такого типа симметричной связи. В DCOM каждый компонент может быть одновременно провайдером и потребителем функциональности. Один и тот же механизм, одни и те же возможности управляют связью в обоих направлениях, облегчая организацию связи и взаимодействия клиент/сервер.
DCOM предлагает устойчивый распределенный механизм регистрации соединений, который полностью прозрачен для приложения. DCOM - это одновременно симметричный сетевой протокол и модель программирования, предлагающие не только традиционное взаимодействие клиент/сервер, но и полноценную связь между клиентами и серверами.
Критическим фактором распределенных приложений является их способность модифицироваться в соответствии с числом пользователей, объемом данных и требуемой функциональностью. Приложение должно быть маленьким и быстрым при минимальной потребности в нем, но оно должно обеспечить и дополнительные потребности без ущерба быстродействию или надежности. DCOM предлагает ряд возможностей, улучшающих масштабируемость вашего приложения.
DCOM использует возможность Windows NT поддерживать симметричную многопроцессорную обработку. Для приложений, использующих модель свободных потоков, DCOM организует объединение потоков входящих запросов. На многопроцессорных машинах это объединение потоков оптимизируется в соответствии с числом доступных процессоров: чрезмерно большие потоки приводят к слишком частому переключению между содержимым, в то время как слишком маленькие потоки могут привести к простою некоторых процессоров. DCOM ограждает разработчика от деталей управления потоками и обеспечивает оптимальное быстродействие, что может обеспечить лишь кодирование управления объединением потоков вручную, требующее больших затрат.
Используя поддержку симметричной многопроцессорной обработки Windows NT, DCOM-приложения могут безболезненно масштабироваться от уровня однопроцессорных машин до уровня огромных многопроцессорных систем.
Самые скоростные многопроцессорные машины могут не справиться с удовлетворением потребностей при увеличении загруженности приложения (даже если ваш бюджет выдержит приобретение такой машины). Независимость DCOM от местоположения облегчает осуществление перераспределения компонентов на другие компьютеры, предлагая, тем самым, более легкую и недорогую организацию масштабируемости.
Перераспределение проще всего выполняется для компонентов, которые не должны находиться в определенном месте или делить свое местонахождение с другими компонентами. В этом случае есть возможность работы многочисленных копий компонента на различных машинах. Чаще всего нагрузка может быть разделена между машинами с учетом таких критериев, как емкость машины или даже текущая загруженность. DCOM облегчает изменение способа соединения клиентов с компонентами и компонентов между собой. Одни и те же компоненты могут быть динамично перераспределены без выполнения повторной работы или даже рекомпиляции. Все, что необходимо - это обновить регистрацию, файловую систему или базу данных, в которых занесены местоположения каждого компонента.
|
|
|
Рисунок 16 |
Большая часть реальных распределенных приложений имеют один или более критический компонент, который участвует в большинстве операций. Это могут быть компоненты базы данных или компоненты, связанные с бизнесом, доступ к которым должен осуществляться постоянно для реализации политики “первым пришел - первым обслужен”. Компоненты такого типа не могут дублироваться, поскольку их предназначение заключается в организации единственной точки синхронизации среди всех пользователей приложения. Для увеличения быстродействия распределенного приложения в целом такие компоненты, создающие “узкие места”, должны перераспределяться на специально выделенный мощный сервер. DCOM помогает вам изолировать такие критические компоненты на ранних этапах проектирования, размещать первоначально компоненты на одной машине, а позже - переносить критические компоненты на отдельные машины.
|
|
|
Рисунок 17 |
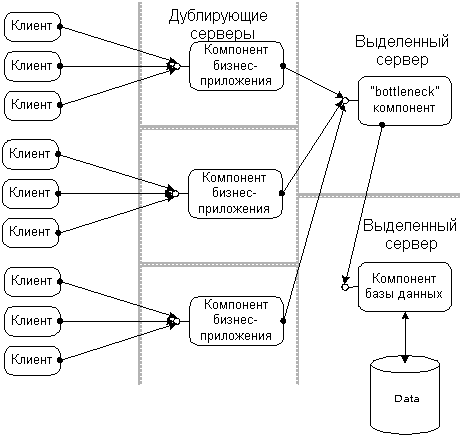
Для таких критических компонентов DCOM в целом может организовать более быстрое выполнение задачи. Подобные компоненты - это обычно часть последовательности процесса организации в электронной торговой системе заказов на покупку или продажу: запросы должны обрабатываться по мере поступления (первым пришел – первым обслужен). Одно из решений заключается в разделении задачи на меньшие компоненты с перераспределением каждого компонента на отдельную машину. Результат этого подобен поточному методу (pipelining), используемому в современных микропроцессорах: первый запрос обрабатывается первым компонентом (например, выполняющим проверку содержимого) и передается на следующий компонент (который, например, выполняет обновление базы данных). Как только первый компонент передал запрос на следующий, он готов обработать следующий запрос. Фактически, две машины параллельно обрабатывают множество запросов в определенном порядке их поступления. То же самое возможно выполнять и на одной машине (при использовании DCOM): многочисленные компоненты могут выполняться в различных потоках или процессах. В дальнейшем, когда потоки смогут быть распределены на одной многопроцессорной машине или на различные машины, этот подход облегчит масштабируемость.
Модель программирования DCOM с ее независимостью от местоположения облегчает схемы перераспределения по мере разрастания приложения: первоначально машина сервера может содержать все компоненты, соединяясь с ними как с очень эффективными серверами в процессе. Фактически приложение выглядит как хорошо отлаженное монолитное приложение. По мере увеличения потребностей можно добавить другие машины с перераспределением компонентов на эти машины без всякого изменения кода.
|
|
|
Рисунок 18 |
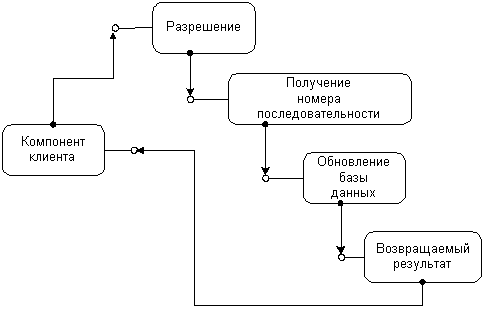
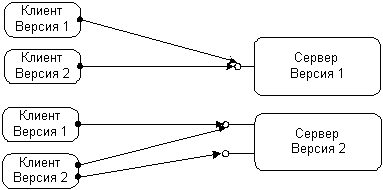
Кроме масштабируемости при изменении числа пользователей или количества транзакций, приложению необходимо масштабироваться при возникновении необходимости в новых функциях. С течением времени должны внедряться новые задачи, а существующие – модифицироваться. В идеале все клиенты и компоненты должны модифицироваться одновременно, либо старый компонент должен модифицироваться после обновления всех клиентов – серьезная, с трудом решаемая в условиях большой географической дисперсии сайтов или пользователей проблема.
DCOM предоставляет гибкие механизмы эволюции для клиентов и компонентов. СОМ и DCOM позволяют клиенту динамично запрашивать функциональность компонента. Вместо объявления своей функциональности в виде монолитной совокупности методов и возможностей, СОМ-компонент может отвечать различным клиентам по-разному. Клиент, использующий определенную возможность, нуждается только в определенных методах. Клиент может использовать более одной возможности компонента одновременно. Добавление к компоненту новых возможностей никак не влияет на старого, не осведомленного о них клиента.
При такой структуризации компонента появляется новый тип развития: изначально компонент объявляет основной набор возможностей COM-интерфейса, к которым может получить доступ любой клиент. После приобретения компонентом новых возможностей, большая часть этих интерфейсов (а чаще - все) будет по-прежнему необходима; новые же функции и возможности появятся в дополнительных интерфейсах без изменения первоначальных интерфейсов. Старые клиенты так же имеют доступ к основному набору интерфейсов, как если бы ничего и не менялось. Новые клиенты могут проверить наличие новых интерфейсов и использовать их, если они есть; если же их нет - клиент может корректно деградировать до набора старых интерфейсов.
Поскольку функциональность в DCOM-модели программирования сгруппирована в интерфейсы, вы можете проектировать новые клиентские приложения для работы со старыми серверами, новые серверы – для работы со старыми клиентами или комбинировать эти возможности для удовлетворения ваших запросов. В обычных моделях объектов даже малейшее изменение метода серьезно сказывается на взаимодействии между клиентом и компонентом. Некоторые модели позволяют добавлять новые методы в конец списка методов, но при этом нет возможности безопасной проверки взаимодействия новых методов со старыми компонентами. Рассмотрение этого вопроса в сетевом аспекте вносит еще большие осложнения, ведь обычно кодирование и наличие проводной связи влияет на набор методов и параметров. Добавление или изменение методов и параметров значительно изменяет и сетевой протокол. DCOM устраняет все эти проблемы единственным, изящным, унифицированным решением и для объектной модели, и для сетевого протокола.
|
|
|
Рисунок 19 |
Масштабируемость нельзя назвать серьезным достоинством при изначально неудовлетворительном быстродействии. Всегда приятно осознавать, что более скоростное аппаратное обеспечение может обеспечить вашему приложению следующий шаг в развитии, но ведь нужно подумать и о потребностях на сегодняшнем уровне. Вы считаете, что не все возможности масштабируемости реализуемы? Что делать, если нет удовлетворительного быстродействия поддержки всех языков от COBOL до Ассемблера? Что делать, если компонент, из-за его удаленного местоположения, исключается из работы в процессе в качестве клиента?
В СОМ и DCOM клиент никогда не видит сам объект сервера, но клиент никогда и не отделяется от сервера системным компонентом до тех пор, пока это абсолютно необходимо. Такая прозрачность достигается поразительно просто: единственный способ, которым клиент может общаться с компонентом - это посредством методов последнего. Клиент получает адреса этих методов из таблицы адресов методов (vtable). Чтобы вызвать метод компонента, клиент получает адрес метода и вызывает его. Только преимущества программирования в СОМ по сравнению с традиционной функцией вызова C или Ассемблера позволяют легко находить адрес метода (косвенный вызов функции вместо прямого вызова функции). Если компонент является компонентом в процессе, работающим в том же потоке, что и клиент, вызов метода адресуется компоненту напрямую. При этом не добавляется никакого СОМ- или системного кода; СОМ лишь определяет стандарт таблицы адресов методов.
Что случается, когда клиент и компонент в действительности расположены не так близко - в различных потоках, процессах или на машинах, далеко отстоящих друг от друга? СОМ размещает код своего вызова удаленной процедуры (RPC) в таблице адресов методов и затем, упаковывая каждый вызов метода в стандартное представление, посылает его клиенту; затем происходит его распаковка и восстановление оригинального вызова метода: СОМ предлагает объектно-ориентированный механизм вызова удаленной процедуры.
Насколько быстр этот механизм RPC? Для определения этого есть различные параметры быстродействия:
- Насколько быстр вызов пустого метода?
- Насколько быстры реальные вызовы методов, посылающие и возвращающие данные?
- Насколько быстра работа по сети?
В Таблице 1 показаны некоторые реальные значения быстродействия для СОМ и DCOM. Вы можете сравнить быстродействие DCOM с другими протоколами.
Первые две колонки представляют вызов пустого метода (пересылка и возврат 4-байтного целого). Последние две колонки можно рассматривать как вызов реальных СОМ-методов (параметры размером 50 байт).
Таблица показывает, что компоненты в процессе имеют высокое быстродействие (строки 1 и 2).
Вызовам пересекающихся процессов (строки 3 и 4) нужно, чтобы параметры заносились в буфер и пересылались в другой процесс. Быстродействие порядка 2000 вызовов в секунду на стандартном desktop-компьютере удовлетворяет большинству требований. Все локальные вызовы ограничиваются скоростью процессора (и в определенной мере доступной памятью) и хорошо масштабируются на многопроцессорных машинах. Удаленные вызовы (строки 5 и 6) ограничиваются параметрами первичной сети и в этих условиях быстродействие DCOM на 35% выше быстродействия TCP/IP (для TCP/IP время вызова по сети составляет 2 мс).
Вскоре Microsoft обнародует значения быстродействия для большинства платформ, что покажет способность DCOM к масштабируемости с учетом числа клиентов и числа процессоров сервера.
Эти неофициальные, но повторяемые значения быстродействия показывают 35-процентное превышение быстродействия DCOM над TCP/IP для “пустых” вызовов. Это соотношение уменьшается при реальной работе сервера. Если серверу нужна 1 мс, например, для обновления базы данных, то соотношение уменьшается до 23 % и до 17 % - если серверу необходимо 2 мс.
Преимущества DCOM в масштабируемости и быстродействии в целом могут быть получены только при использовании хорошо организованного управления объединением потоков и тестовых протоколов (pinging protocols). Большая часть распределенных приложений даже при значительных вложениях не получат приближенно такого же увеличения быстродействия, как при использовании стандартизованных DCOM-протокола и модели программирования.
Распределенные приложения пользуются преимуществами сети, связывая компоненты. DCOM полностью скрывает тот факт, что компоненты работают на разных компьютерах. Однако на практике приложения вынуждены учитывать два параметра сетевого соединения:
- Полоса пропускания: размер параметров вызова метода постоянно влияет на время, которое требуется для выполнения вызова.
- Латентность: физическое расстояние и число задействованных элементов сети (таких как маршрутизаторы и линии коммуникаций) значительно влияют на задержку даже маленьких пакетов данных. В случае глобальной сети, такой как Интернет, эта задержка может измеряться секундами.
Как DCOM помогает приложению работать при таких ограничениях? DCOM минимизирует передачу данных по сети там, где это возможно для того, чтобы уменьшить латентность сети. Наиболее предпочтительный транспортный протокол для DCOM - это UDP-набор протокола TCP/IP без функции соединения: природа этого протокола позволяет выполнить определенную оптимизацию посредством слияния многих низкоуровневых пакетов с данными и тестовыми сообщениями. Даже при работе с протоколами, ориентированными на соединение, DCOM продолжает предоставлять значительные преимущества по сравнению с пользовательскими протоколами приложений.
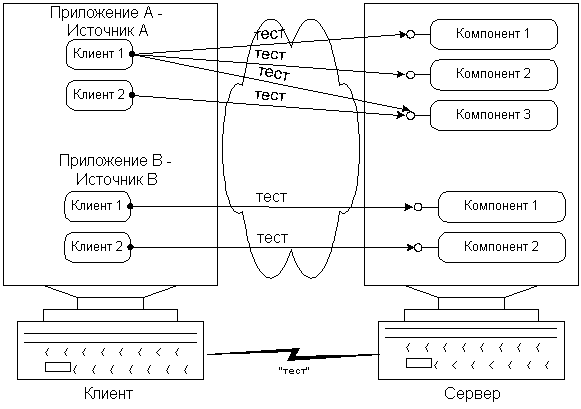
Многие протоколы нуждаются в постоянном управлении. Компонентам нужно знать, что на машине клиента возникла серьезная авария аппаратного обеспечения или сетевое соединение между клиентом и компонентом прервалось на длительное время.
Общим решением этой проблемы является постоянная пересылка сообщений с определенной периодичностью (pinging). Если сервер не получает сообщения в течение определенного времени, это значит, что связи с клиентом нет.
DCOM использует такие сообщения для каждой из машин. Даже если машина клиента использует 100 компонентов с машины сервера, единственное тестовое сообщение поддерживает связь всех клиентов. В дополнение к использованию тестовых сообщений, DCOM минимизирует размер этих тестовых сообщений путем посылки разницы между ними (delta-pinging). Вместо посылки 100 идентификаторов клиентов создается мета-идентификатор, представляющий все 100 ссылок. При изменении набора ссылок пересылается только разница между двумя последовательными наборами ссылок. И, наконец, DCOM накладывает тестовое сообщение на обычные пересылаемые сообщения. Только в случае, если машина клиента простаивает по отношению к машине сервера, с 2-минутным интервалом пересылаются сами тестовые сообщения (рис.9).
DCOM позволяет различным приложениям (даже из различных источников) использовать единое, оптимизированное, постоянное управление и протокол определения аварий сети, незначительно уменьшая полосу пропускания. Если на сервере работает 100 разных приложений с сотней различных пользовательских протоколов, этот сервер должен принять по одному тестовому сообщению для каждого из приложений, от каждого из подключенных клиентов. Загрузка сети в целом может быть уменьшена только в случае, если эти протоколы некоторым образом координируют свою тестовую стратегию. DCOM автоматически предоставляет такое координирование среди пользовательских COM-протоколов.
|
|
|
Рисунок 20 |
Общей проблемой при разработке распределенных приложений является интенсивный сетевой обмен между компонентами различных машин. В Интернет каждый из таких сетевых обменов вызывает задержку в 1 секунду, а чаще – значительно большую. Даже в случае быстрой локальной сети время обмена измеряется в миллисекундах – достаточно много для таких масштабов.
Общим способом уменьшения интенсивности сетевого обмена является “увязывание” многочисленных вызовов методов в единственный запрос метода (пакетирование или упаковка). DCOM использует этот способ для таких задач, как подключение к объекту или создание нового объекта и запрос его функциональности. Недостатком такого способа для большинства компонентов является то, что модель программирования сильно отличается в локальном и удаленном случаях.
Пример. Компонент базы данных предусматривает метод перечисления результатов запроса по одной или более строк за один раз. В локальном случае разработчик может просто использовать этот метод для последовательного добавления строк к окну списка. В удаленном случае это решение приводит к сетевому обмену при перечислении каждой строки. При использовании метода со способом пакетирования разработчику необходимо локализовать достаточно большой буфер для того, чтобы все строки хранились в очередности и пересылались одним вызовом с последующим поочередным добавлением к окну. Поскольку при этом модель программирования значительно изменяется, то, чтобы приложение работало эффективно и в распределенном окружении, разработчик должен пойти на некоторые компромиссы в конструировании..
DCOM облегчает дизайнерам компонентов выполнение подобного пакетирования без того, чтобы клиентам нужно было использовать API пакетирования. Механизм маршалинга DCOM позволяет компоненту передавать код, называемый “заместителем объекта” (proxy object) и позволяющий перехватывать многочисленные вызовы методов и упаковывать их в единственный вызов удаленной процедуры клиенту:
Пример. Разработчик из предыдущего примера продолжает перечислять методы один за другим, поскольку это способ, который необходим логике приложения. (Это нужно списку API). Однако, первый вызов для начала перечисления пересылается в заместитель объекта, определенный приложением, который вызывает все строки (или набор строк) и кэширует их в объект-заместитель. Затем последующие вызовы исходят из этого кэша без дополнительных сетевых обменов. Разработчик продолжает работать с простой моделью программирования, хотя в целом приложение уже оптимизировано (рис.10).
|
|
|
Рисунок 21 |
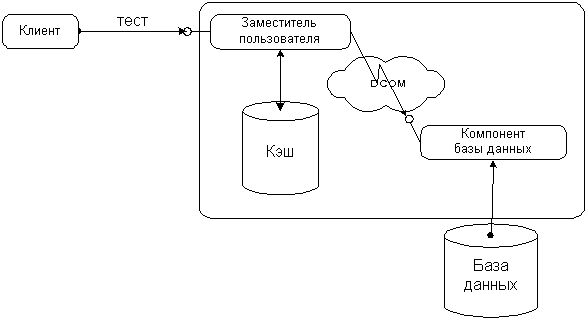
Кроме того, DCOM позволяет выполнять эффективную переадресацию с одного компонента на другой. Если компонент содержит ссылку на другой компонент второй машины, он может передать эту ссылку клиенту, работающему на третьей машине (ссылка клиента на другой компонент, работающий на другой машине). Когда клиент использует эту ссылку, он напрямую соединяется со вторым компонентом. DCOM стыкует эти ссылки и позволяет оригиналу компонента и машине выйти из этой схемы взаимодействия. Это предоставляет пользователю сервисы директорий, позволяющие возвращать ссылки на широкий диапазон
|
|
|
Рисунок 22 |
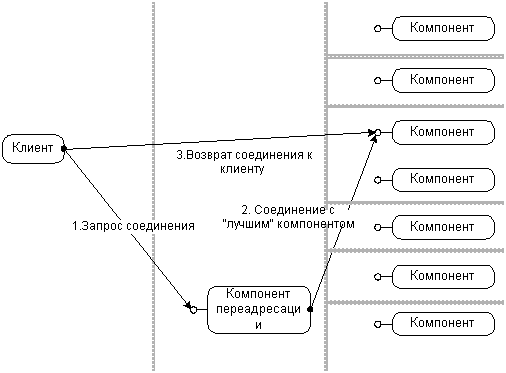
Если необходимо, DCOM даже позволяет компонентам включаться в произвольные пользовательские протоколы, использование которых подразумевает работу вне механизма DCOM. Компонент может использовать пользовательский маршалинг для пересылки заместителя объекта в процесс клиента, который в дальнейшем может использовать любой произвольный протокол для общения с компонентом.
.
|
|
|
Рисунок 23 |
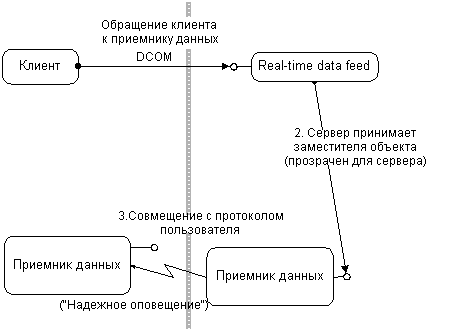
DCOM предоставляет множество способов совместить реальный сетевой протокол с сетевым траффиком без изменения взаимодействия клиента с компонентом: кэширование со стороны клиента, переадресация ссылок и замена сетевого транспорта при необходимости – лишь часть возможных способов.
Использование сети для распределения приложения - это сложная задача не только из-за таких физических ограничений, как полоса пропускания и латентность. Это также вынуждает использовать меры безопасности для клиентов и компонентов. Поскольку сейчас любому физически доступно большое число операций при доступе к сети, доступ к таким действиям должен ограничиваться на более высоком уровне.
При отсутствии поддержки безопасности со стороны разработанной распределенной платформы, каждое приложение должно было бы применять свои механизмы обеспечения безопасности. Обычный механизм использует запрос имени пользователя и пароля – обычно зашифрованного. Приложение сопоставляет эти идентификаторы с каталогом или базой данных пользователя и возвращает некоторый динамичный идентификатор, используемый для будущих вызовов метода. При всех последующих вызовах метода безопасности клиенты должны будут пройти этот идентификатор безопасности. Каждое приложение должно уметь хранить список имен пользователей и паролей, управлять им, защищать каталог пользователя от несанкционированного доступа и управлять изменением паролей, а также обеспечивать надежность при таком действии, как пересылка паролей по сети.
Распределенная платформа должна предусматривать наличие framework, отвечающего за безопасность для того, чтобы была обеспечена возможность различать отдельных клиентов и отдельные группы клиентов. Тогда система или приложение будут иметь возможность определять, кто пытается начать работать с компонентом. DCOM использует framework повышенной безопасности, предлагаемый Windows NT. Windows NT предусматривает серьезный набор встроенных провайдеров безопасности, поддерживающий многочисленные механизмы идентификации и аутентификации, от традиционных моделей доменов доверия (trusted-domain) до нецентрализованно управляемых, хорошо масштабируемых механизмов безопасности. Центральной частью framework, отвечающего за безопасность, является каталог пользователя, который содержит информацию, необходимую для подтверждения прав пользователя (имя пользователя, пароль). Большинство DCOM-реализаций на отличных от Windows NT платформах предусматривают такой же или подобный механизм, какой бы провайдер безопасности ни был доступен для данной платформы. Большая часть UNIX-реализаций DCOM будут включать Windows NT-совместимый провайдер безопасности.
Перед тем, как ближе ознакомиться с Windows NT-провайдерами каталогов и безопасности, давайте обсудим, как DCOM использует этот общий framework безопасности для облегчения создания защищенных приложений.
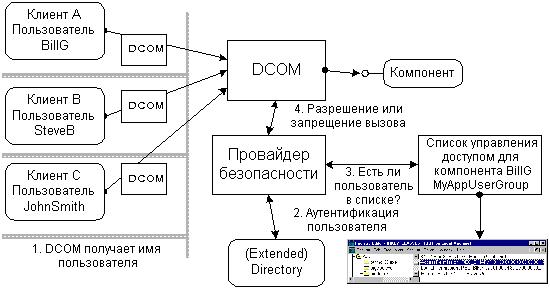
DCOM может обеспечить безопасность распределенному приложению без встраивания специализированного кодирования безопасности в клиент или компонент. Модель программирования DCOM скрывает потребность в безопасности со стороны компонента точно так же, как скрывает и его местонахождение. Тот же двоичный код, который работает на одной машине, где безопасность – не главное требование, может использоваться и в распределенном приложении с обеспечением защищенности.
DCOM достигает подобной прозрачности в безопасности, позволяя разработчикам и администраторам конфигурировать установки защищенности для каждого компонента. Точно так же, как файловая система Windows NT позволяет администратору установить списки управления доступом (ACL) для файлов и каталогов, DCOM содержит списки управления доступом для компонентов. Эти списки показывают, какие пользователи или группы пользователей имеют право доступа к компонентам определенного класса. Эти списки могут легко конфигурироваться инструментом конфигурирования DCOM (DCOMCNFG) или программироваться с помощью реестра Windows NT и функций обеспечения безопасности Win32.
Когда бы клиент ни вызвал метод или создал пример компонента, DCOM получает текущее пользовательское имя клиента, связанного с текущим процессом (на самом деле – текущий исполняемый поток). Windows NT гарантирует, что данный пользовательский идентификатор аутентичен. После этого DCOM передает имя пользователя машине или процессу, где работает этот компонент. На машине компонента DCOM снова проверяет имя пользователя, используя аутентификационный механизм, и проверяет список управления доступом для данного компонента (на самом деле — для первого компонента, работающего в процессе, содержащего интересующий компонент. Более детально это описано в Белых Страницах “Архитектура DCOM”.) Если имя клиента не включено в этот список (прямо или косвенно – в качестве члена группы пользователей), DCOM просто отклоняет этот вызов еще до того, как компонент вовлекся в работу. Этот обычный механизм безопасности полностью прозрачен как для клиента, так и для компонента и оптимизирован. Он базируется на framework безопасности Windows NT, который является наиболее интенсивно используемой (и оптимизированной!) частью операционной системы Windows NT: при каждом доступе к файлу или даже к такому примитиву синхронизации потоков, как сигнализация или событие, Windows NT выполняет идентичную проверку доступа. Тот факт, что Windows NT по-прежнему может неплохо конкурировать в быстродействии с другими операционными системами и сетевыми операционными системами, показывает, насколько эффективен этот механизм безопасности (рис.24).
|
|
|
Рисунок 24 |
DCOM предлагает чрезвычайно эффективный механизм обеспечения безопасности, который позволяет разработчику создавать распределенные приложения, не опасаясь за его защищенность. Любой провайдер безопасности, поддерживаемый Windows NT, может использоваться механизмом безопасности DCOM.
3.2 Технология COBRA
В конце 1980-х и начале 1990-х годов многие ведущие фирмы-разработчики были заняты поиском технологий, которые принесли бы ощутимую пользу на все более изменчивом рынке компьютерных разработок. В качестве такой технологии была определена область распределенных компьютерных систем. Необходимо было разработать единообразную архитектуру, которая позволяла бы осуществлять повторное использование и интеграцию кода, что было особенно важно для разработчиков. Цена за повторное использование кода и интеграцию кода была высока, но ни кто из разработчиков в одиночку не мог воплотить в реальность мечту о широко используемом, языково-независимом стандарте, включающем в себя поддержку сложных многосвязных приложений. Поэтому в мае 1989 была сформирована OMG (Object Managment Group). Как уже отмечалось, сегодня OMG насчитывает более 700 членов (в OMG входят практически все крупнейшие производители ПО, за исключением Microsoft).
Задачей консорциума OMG является определение набора спецификаций, позволяющих строить интероперабельные информационные системы. Спецификация OMG -- The CommonObject Request Broker Architecture (CORBA) является индустриальным стандартом, описывающим высокоуровневые средства поддерживания взаимодействия объектов в распределенных гетерогенных средах.
CORBA специфицирует инфраструктуру взаимодействия компонент (объектов) на представительском уровне и уровне приложений модели OSI. Она позволяет рассматривать все приложения в распределенной системе как объекты. Причем объекты могут одновременно играть роль и клиента, и сервера: роль клиента, если объект является инициатором вызова метода у другого объекта; роль сервера, если другой объект вызывает на нем какой-нибудь метод. Объекты-серверы обычно называют "реализацией объектов". Практика показывает, что большинство объектов одновременно исполняют роль и клиентов, и серверов, попеременно вызывая методы на других объектах и отвечая на вызове извне. Используя CORBA, тем самым, имеется возможность строить гораздо более гибкие системы, чем системы клиент-сервер, основанные на двухуровневой и трехуровневой архитектуре.
Dynamic Invocation Interface (DII): позволяет клиенту находить сервера и вызывать их методы во время работы системы.
IDL Stubs: определяет, каким образом клиент производит вызов сервера.
ORB Interface: общие как для клиента, так и для сервера сервисы.
IDL Skeleton: обеспечивает статические интерфейсы для объектов определенного типа.
Dynamic Skeleton Interface: общие интерфейсы для объектов, независимо от их типа, которые не были определены в IDL Skeleton.
Object Adapter: осуществляет коммуникационное взаимодействие между объектом и ORB.
Вот небольшой список достоинств и недостатков использования технологии CORBA.
Достоинства:
• Платформенная независимость
• Языковая независимость
• Динамические вызовы
• Динамическое обнаружение объектов
• Масштабируемость
• CORBA-сервисы
• Широкая индустриальная поддержка
Недостатки:
• Нет передачи параметров `по значению'
• Отсутствует динамическая загрузка компонент-переходников
• Нет именования через URL
К основным достоинствам CORBA можно отнести межъязыковую и межплатформенную поддержку. Хотя CORBA-сервисы и отнесены к достоинствам технологии CORBA, их в равной степени можно одновременно отнести и к недостаткам CORBA, ввиду практически полного отсутствия их реализации.
3.3 Технология EJB
Основная идея, лежавшая в разработке технологии Enterprise JavaBeans -- создать такую инфраструктуру для компонент, чтобы они могли бы легко ``вставляться'' (``plug in'') и удаляться из серверов, тем самым увеличивая или снижая функциональность сервера. Технология Enterprise JavaBeans похожа на технологию JavaBeans в том смысле, что она использует ту же самую идею (а именно, создание новой компоненты из уже существующих, готовых и настраиваемых компонент, аналогично RAD-системам), но во всем остальном Enterprise JavaBeans -- совершенно иная технология.
Опубликованная в марте 1998 года EJB-спецификация версии 1.0 (Недавно была опубликована версия 1.1 спецификации) определяет следующие цели:
• Облегчить разработчикам создание приложений, избавив их от необходимости реализовывать с нуля такие сервисы, как транзакции (transactions), нити (threads), загрузка (load balancing) и другие. Разработчики могут сконцентрироваться на описании логики своих приложений, оставляя заботы о хранении, передаче и безопасности данных на EJB-систему. При этом все равно имеется возможность самому контролировать и описывать порученные системе процессы.
• Описать основные структуры EJB-системы, описав при этом интерфейсы взаимодействия (contracts) между ее компонентами.
•EJB преследует цель стать стандартом для разработки клиент/сервер приложений на Java. Таким же образом, как исходные JavaBeans (Delphi, или другие) компоненты от различных производителей можно было составлять вместе с помощью соответствующих RAD-систем, получая в результате работоспособные клиенты, таким же образом серверные компоненты EJB от различных производителей также могут быть использованы вместе. EJB-компоненты, будучи Java-классами, должны без сомнения работать на любом EJB-совместимом сервере даже без перекомпиляции, что практически нереально для других систем.
EJB совместима с Java API, может взаимодействовать с другими (не обязательно Java) приложениями, а также совместима с CORBA.
Разработчику, однако, не нужно самому реализовывать EJB-объект. Этот класс создается специальным кодогенератором, поставляемым вместе в EJB-контейнером. Как уже было сказано, EJB-объект (созданный с помощью сервисов контейнера) и EJB-компонента (созданная разработчиком), реализуют один и тот же интерфейс. В результате, когда приложение-клиент хочет вызвать метод у EJB-компоненты, то сначала вызывается аналогичный (по имени) метод у EJB-объекта, что находится на стороне клиента, а тот, в свою очередь, связывается с удаленной EJB-компонентой и вызывает у нее этот метод (с теми же аргументами).
Существует два различных типа ``бинов''.
Session bean представляет собой EJB-компоненту, связанную с одним клиентом. ``Бины'' этого типа, как правило, имеют ограниченный срок жизни (хотя это и не обязательно), и редко участвуют в транзакциях. В частности, они обычно не восстанавливаются после сбоя сервера. В качестве примера session bean можно взять ``бин'', который живет в Web-сервере и динамически создает HTML-страницы клиенту, при этом следя за тем, какая именно страница загружена у клиента. Когда же пользователь покидает Web-узел, или по истечении некоторого времени, session bean уничтожается. Несмотря на то, что в процессе своей работы, session bean мог сохранять некоторую информацию в базе данных, его предназначение заключается все-таки не в отображении состояния или в работе с ``вечными объектами'', а просто в выполнении некоторых функций на стороне сервера от имени одного клиента.
Entity bean, наоборот, представляет собой компоненту, работающую с постоянной (persistent) информацией, хранящейся, например, в базе данных. Entity beans ассоциируются с элементами баз данных и могут быть доступны одновременно нескольким пользователям. Так как информация в базе данных является постоянной, то и entity beans живут постоянно, ``выживая'', тем самым, после сбоев сервера (когда сервер восстанавливается после сбоя, он может восстановить ``бин'' из базы данных). Например, entity bean может представлять собой строку какой-нибудь таблицы из базы данных, или даже результат операции SELECT. В объектно-ориентированных базах данных, entity bean может представлять собой отдельный объект, со всеми его атрибутами и связями.
EJB имеет следующие положительные стороны:
• Быстрое и простое создание
• Java-оптимизация
• Кроссплатформенность
• Динамическая загрузка компонент-переходников
• Возможность передачи объектов по значению
• Встроенная безопасность
Недостатки:
• Поддержка только одного языка - Java
• Трудность интегрирования с существующими приложениями
• Плохая масштабируемость
• Производительность
• Отсутствие международной стандартизации
Благодаря своей легко используемой Java-модели, EJB является самым простым и самым быстрым способом создания распределенных систем. EJB - хороший выбор для создания RAD-компонент и небольших приложений на языке Java. Конечно, EJB не такая мощная технология, как DCOM или CORBA. Тем самым, роль RMI в создании больших, масштабируемых промышленных систем, снижается.
3.4 Web технологии
Под web технологиями понимаются технологии создания распределённых информационных систем архитектуры клиент-сервер, где сервером является web сервер, клиентом web броузер, обмен информацией осуществляется по протоколу http. Web клиент (браузер) способен понимать только HTML, который содержит в себе как прикладную информацию, так и форматирование которое должно присылаться с сервера каждый раз при отправке на клиент какой-либо информации, это разумеется загружает трафик. Попытка освободиться от постоянной пересылки форматирования, и присылать его только в начале предпринята в новом стандарте представления данных XML, которому пророчат развитие (обсуждение принципов XML выходит за рамки данной статьи).
В Web технологиях создания распределённых приложений, как правило, используется кэширование – простое и гениальное изобретение позволяющее сэкономить трафик. Поддержка кэша HTML, ActiveX форм и Java апплетов встроена во все броузеры, что позволяет разработчику освободиться от его обеспечения.Также разработчикам не придется писать своего клиента web броузер зачастую встроен в ОС.
Web технологии являются проверенным и хорошо зарекомендовавшим себя способом построения распределённых систем, при умелом применении которого можно уверенно достигнуть успеха.
DHTML
DHTML хорош для манипуляций внутри документа HTML, но на этом его функциональность заканчивается. Формы HTML обладают бедными возможностями интерфейса и программирования. В тоже время DHTML можно считать межплатформенным продуктом (при применении стрипта JavaScript). Для расширения функциональности, присылаемой клиенту с сервера, были изобретены различные технологии, позволяющие запускать на клиенте приложения различной направленности, не ограниченные работой с HTML документом. Разработчиками таких технологий выступили фирмы, Netscape, Sun, Microsoft.
Java
Java использует свою библиотеку классов, независимую, а следовательно универсальную для операционной системы. Это даёт возможность межплатформенной работы, но в тоже время «отрезает» использование возможностей и особенностей конкретной ОС. В современном Java можно сделать полнофункциональное приложение с довольно красивым и оригинальным интерфейсом. При работе с БД Java имеет свои библиотеки драйверов JDBC и работает также как и приложение, утяжеляя клиента дополнительным промежуточным ПО что может затруднить работу с удалённой БД. Java аплеты работают в изолированном от ОС режиме для поддержания безопасности, это лишает их некоторых важных системных функций, например обращения к файловой системе, вызов функций ОС. Ещё одним и самым крупным недостатком является сильная загрузка ресурсов, определяющаяся интерпретацией «на лету». Тем не менее, Java негласно принят стандартом меж платформенного и межпрограммного взаимодействия, его поддерживают такие крупные корпорации как Oracle, Sun, Lotus в качестве базового языка разработки в своих продуктах. Основное достоинство Java в его переносимости (работает везде, где есть JVM) за которую приходится платить быстродействием и, и безопасности (работает в рамках той же JVM). Хорошо подходит для Internet проектов(рассчитанных на независимость от платформы).
ActiveX
ActiveX технология является продуманной разработкой Microsoft основанной на технологии COM, соответственно активно поддерживается данной организацией. ActiveX элемент может быть создан на любом языке программирования, т.к. представляет собой скомпилированный код. Соответственно он может предоставлять пользователю всё богатство функциональности и удобства конкретного языка программирования и среды разработки. К недостаткам ActiveX можно отнести одноплатформенность (Windows), опасность, обусловленную широкими функциональными возможностями, которую можно снизить за счёт применения цифровых подписей или других механизмов. Является хорошим решением для закрытых или защищенных интрасетей, из-за проблемы безопасности мало подходит для Internet.
Web серверные приложения
CGI
Принципиальные ограничения на функциональные возможности CGI-совместимых продуктов отсутствуют. Эти программы могут взаимодействовать практически с любой реляционной базой данных и Web-сервером. . Сама идея динамического формирования HTML контента на сервере проста и гениальна бала изобретена давно и продолжает использоваться по сей день, поддерживается всеми web серверами. Множество CGI-программ самого различного назначения бесплатно распространяются по Internet. Удобством стандарта CGI является то, что модуль CGI скомпилирован, а это означает, что он будет выполняться быстро, и может быть написан в принципе на любом языке программирования. Использовании API Web сервера даёт ряд преимуществ перед стандартным CGI.
Однако CGI-продукты ( имеется ввиду и Web server API) имеют один существенный недостаток: не поддерживают непрерывную связь между БД и Web-сервером. Они подключаются к базе данных, исполняют запрос пользователя Web-страницы, а затем отключаются от БД. При следующем запросе весь процесс подключения к БД повторяется, это замедляет работу при поступлении множества запросов от одного пользователя. Дальнейшее развитие технология серверных приложений получило в продуктах Baikonur.
Недостатком применения CGI также является его неудобство работы с клиентским запросом, который становится, при усложнении HTML интерфейса плохо структурированным и зачастую содержит лишнюю информацию. Программистам приходится разбираться с ним ,изобретая свои решения, на что расходуется время. Встроенные в универсальные среды разработки компоненты для работы с CGI недостаточно удобны в применении, тем не менее позволяют создать полноценное серверное приложение без переобучения работе с другими языками и инструментами. Вкратце можно сказать так: Не вполне удобно но доступно без лишних затрат на обучение и приобретение дополнительного ПО для сервера и для разработки.
ASP
ASP- аналог CGI и ISAPI, более подходящий для разработчиков, уже столкнувшихся с скриптовыми языками при разработке интерактивных Web страниц, им не придётся переучиваться. Основа дополнительной функциональности –ActiveX, необходимые компоненты уже установлены, дополнительные подключить просто, это обеспечивает технология COM. Страницы формировать удобней, чем при использовании CGI, появляется большая наглядность и структуризация.
Для небольших программ ASP скрипты выполняются быстрее аналогичных CGI, из-за замены трудоёмкого запуска серверного приложения выполнением интерпретируемого скрипта. По той же причине работа крупного приложения опережает интерпретацию аналогичного серверного скрипта, это позволяет сделать вывод о целесообразности применении серверных скриптов в небольших программах генерации HTML страниц.
Для применения не требуется установка дополнительного ПО, достаточно наличие сервера IIS начиная с версии 3.
Вывод: если генерация HTML страниц не нуждается в использовании более развитых средств программирования, и выполняется не слишком трудоёмко, то ASP – оптимальный подход для платформ Microsoft.
Baikonur
Преимущества:
· Удобство написания клиентского интерфейса и серверного приложения для работы с БД средствами Delphi, наиболее продуманного для этого средства
· Разработаны механизмы организаций сессий подключенных пользователей
· Клиентское приложение преобразуется в стандартный HTML, поэтому будет работать на любой платформе
Недостатки:
· Вся обработка происходит на сервере, клиент видит только результат в виде сформированной HTML страницы. Это усложняет написание интерактивного интерфейса пользователя и замедляет скорость работы приложения (хотя в последних вервиях разработчики обещали сократить трафик передачи данных на клиент).
· Пользовательский интерфейс ограничен HTML формами
· Для применения системы необходимо установка дополнительного ПО (сервера Baikonur).
Baikonur хорошо подходит для разработчиков интерфейсов к БД в среде Delphi, здесь им придётся иметь дело со знакомым инструментом, и знакомой методологией, но теперь уже разрабатывать web приложения, которые для них будут мало отличаться от обычных приложений работы с БД. Baikonur удобнее чем CGI и ISAPI, позволяет визуально создавать интерфейс пользователя. Предусмотрены механизмы сессий, ничем не уступающие ASP. Использование для разработки Delphi позволяет расширить функциональность верверного приложения за счёт применения более развитого средства программирования, чем Vbscript в ASP. Хорошо подходит для любителей продуктов InPrice.
ЗАКЛЮЧЕНИЕ
Развитие информационных и телекоммуникационных технологий обусловило исследование и разработку единых информационных сред в рамках различных сфер деятельности человека. В основе единых информационных сред лежат распределенные системы. Распределенная система, являясь совокупностью независимых компьютеров, представляется пользователю единым компьютером. Создание распределенных систем имеют следующие преимущества перед централизованными: 1) экономическое. Закон Гроша (Herb Grosh)- быстродействие процессора пропорциональна квадрату его стоимости. С появлением микропроцессоров закон перестал действовать - за двойную цену можно получить тот же процессор с несколько большей частотой. 2) можно достичь такой высокой производительности путем объединения микропроцессоров, которая недостижима в централизованном компьютере. 3) естественная распределенность (банк, поддержка совместной работы группы пользователей). 4) надежность (выход из строя нескольких узлов незначительно снизит производительность). 5) наращиваемость производительности. В будущем главной причиной будет наличие огромного количества персональных компьютеров и необходимость совместной работы без ощущения неудобства от географического и физического распределения людей, данных и машин. Развитие создаваемых распределенных систем позволит: - разделять данные и дорогие периферийные устройства, уникальные информационные и программные ресурсы. - достичь развитых коммуникаций между людьми. - гибче использовать различные ЭВМ, распределять нагрузки на них. Распределенная система - это единый глобальный межпроцессный коммуникационный механизм, глобальная схема контроля доступа, одинаковое видение файловой системы, иллюзия единой ЭВМ. Однако такая система имеет ряд недостатков: проблемы коммуникационной сети (потери информации, перегрузка, развитие и замена) и обеспечение секретности.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Шокин Ю.И., Федотов А.М., Барахнин В.Б. Проблемы поиска информации. Новосибирск: Наука, 2010. 198 c.
2. Шокин Ю.И., Федотов А.М. Распределенные информационные системы // Вычисл. технологии. 1998. Т. 3, № 5. С. 79–93.
3. Федотов А.М. Методологии построения распределенных систем // Вычисл. технологии. 2006. Т. 11. Спецвыпуск: Избранные доклады X Российской конференции “Распределенные информационно-вычислительные ресурсы” (DICR-2005). С. 3–16.
4. Шокин Ю.И., Федотов А.М., Жижимов О.Л. Технология распределенных информационных систем // Современные информационные технологии для научных исследований: Матер. Всерос. конф., Магадан, 20–24 апреля 2008 г. Магадан: СВНЦ ДВО РАН, 2008. С. 18–21.
5. Лем, С. Сумма технологии / С. Лем. — М. : Гослитиздат, 1968.
6. Лиотар, Ж. Состояние постмодерна / Ж. Лиотар. — СПб. : Алетейя, 1998.
7. Соколов, А. Б. Защита информации в распределенных корпоративных сетях и системах / А. В. Соколов, В. Ф. Шаньгин. — М.: ДМК Пресс, 2002.

- Операции, производимые с данными.
- Применение объектно-ориентированного подхода при проектировании информационной системы .
- Исковая давность, ее гражданско-правовое значение (История становления, развития института исковой давности)
- Понятие предпринимательского договора (Особенности предпринимательского договора)
- Исковая давность, ее гражданско-правовое значение (История становления и развития института исковой давности)
- Правовые основы организации нотариата (основы организации нотариата)
- Языки гипертекстовой разметки. .
- Основы программирования на языке HTML
- Разработка регламента выполнения процесса «Управление информационными ресурсами (Основные понятия процессного подхода)
- Основы спортивного менеджмента (Виды спортивных организаций)
- "Основные средства, формы и методы профилактики девиантного поведения детей и подростков в работе учителя начальных классов"
- "Конфликты между школьниками"