
«Мультипроцессоры»
Содержание:

Введение
С увеличением сложности производимых в вычислительных системах расчётов связан постоянный рост требований и запросов пользователей к скорости самих вычислений. Не последнюю роль в повышении производительности вычислительных систем играют сами способы и алгоритмы организации сложных вычислений.
В зависимости от структуры вычислительной системы существуют различные алгоритмы и методы планирования деятельности, зачастую преследующие конкретные цели (уменьшение времени выполнения задачи, обеспечение равномерной загрузки или максимального использования всех доступных ресурсов системы, максимизация количества выполненных задач/подзадача за единицу времени и т.д.). В общем виде задачу планирования процессов можно свести к следующим пунктам:
- какой из процессов, стоящих в очереди на выполнение, должна система запустить в данный момент времени;
- какие ресурсы и в каком количестве для выполнения этой задачи должны быть использованы.
Во многом именно от эффективности работы планировщика зависит скорость получения результатов, ведь никто не хочет терять драгоценное время в ожидании пока обработается тот или иной процесс, когда другие уже давно завершились. Сами вычисления и без того требуют немалых ресурсов и времени, чтобы еще тратить его впустую из-за неэффективного расписания работ.
Актуальность темы заключается в том, что на текущий момент разработано немало универсальных и всем известных алгоритмов планирования для различных типов вычислительных систем. Существует также большое число специфических планировщиков, использующих методы, которые эффективны только для определенного вида сетей или узко-направленных задач, и число таких алгоритмов растет день ото дня. Нет причин для сомнений в том, что важность эффективного распределения ресурсов и процессов в любой системе будет только увеличиваться с развитием компьютерных технологий, как программных так и аппаратных средств, а значит анализ, изучение и модификации алгоритмов планирования есть и останутся важной частью разработки большинства вычислительных систем высокой сложности.
Основными задачами исследования ставятся:
- Обзор различных существующих методов планирования задач.
- Анализ и сравнительная оценка наиболее перспективных алгоритмов.
Объектом исследования является планировщик многопроцессорных систем.
Предмет исследования: улучшение алгоритма планирования для многопроцессорных вычислительных систем.
В рамках курсовой работы планируется получение актуальных научных результатов по следующим направлениям:
- Создание более эффективного метода планирования процессов.
- Определение перспективных направлений развития планировщиков.
- Модификация известных алгоритмов планирования задач.
1. Мультипроцессорные системы
1.1 Мультипроцессор
Мультипроцессор — это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров. Он запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны [1].
По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access).
В мультипроцессорных системах (МПС) имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В МПС существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Важным свойством МПС является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность [1].
Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных процессорных элементов (ПЭ) и параллельному выполнению большого числа операций.
Параллельные ВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных) [2].
1.2 Конвейерная и векторная обработка
Основу конвейерной обработки составляет раздельное выполнение операций в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Идеальную возможность полной загрузки вычислительного конвейера обеспечивают векторные операции.
1.3 Машины типа SIMD
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все ПЭ в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных. Модели вычислений на векторных и матричных ВМ настолько схожи, что эти ВМ часто рассматриваются как эквивалентные [2].
1.4 Машины типа MIMD
Термин «мультипроцессор» покрывает большинство машин типа MIMD и (подобно тому, как термин «матричный процессор» применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В МПС каждый процессорный элемент выполняет свою программу независимо от других ПЭ. Процессорные элементы, конечно, должны как-то связываться друг с другом, и в МПС с общей памятью (сильносвязанных) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных МПС (машинах с локальной памятью) вся память делится между ПЭ и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом [3].
1.5 МПС с SIMD-процессорами
Многие современные ВС представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD [4].
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы.
Основной характеристикой параллельных МПС является ускорение R, определяемое выражением
R = T1 / Tn ,
где T1 – время выполнения задачи на однопроцессорной ВМ; Tn – время выполнения той же задачи на n-процессорной ВМ.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами:
1. Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения. MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
2. Архитектура MIMD может использовать все преимущества современной МПС технологии на основе учета соотношения стоимость/производительность. В действительности практически все современные МПС строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Одной из отличительных особенностей МПС является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для МПС, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти [4].
В МПС с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом «почтового ящика». Модель системы с общей памятью очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы, даже если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
В МПС с локальной памятью непосредственное разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена. В сетях с коммутацией каналов по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы: каналы, процессоры, буферы сообщений. Объем передаваемой информации может быть сокращен за счет тщательной функциональной декомпозиции задачи и тщательного диспетчирования выполняемых функций.
Таким образом, существующие МПС распадаются на две основные группы.
К первой группе относятся МПС с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти МПС иногда называют UMA (Uniform Memory Access). Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным [4].
Вторую группу МПС составляют крупномасштабные системы с распределенной памятью. Для того чтобы поддерживать большое количество процессоров приходится распределять основную память между ними, в противном случае полосы пропускания памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой [4].
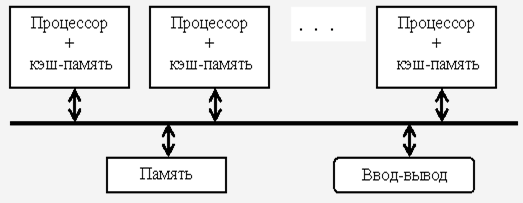
Рисунок 1 - Связь процессоров между собой
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров.
С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т.е. число процессоров в системе), для которых требуется организация распределенной памяти, уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти. Распределение памяти между отдельными узлами системы имеет два главных преимущества [6].
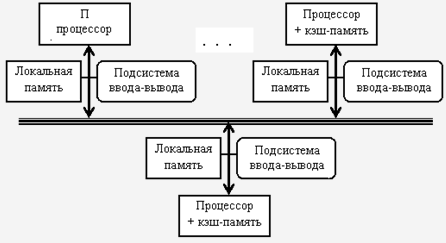
Рисунок 2 - Распределение памяти между отдельными узлами
Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Эти два преимущества еще больше сокращают количество процессоров, для которых архитектура с распределенной памятью имеет смысл.
Существующие ВС класса MIMD образуют три технических подкласса:
симметричные мультипроцессоры;
системы с массовым параллелизмом;
кластеры.
1.6 Симметричные мультипроцессоры
Симметричные мультипроцессоры (SMP) используют принцип разделяемой памяти. В этом случае система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой ячейке памяти с одинаковой скоростью. Процессоры подключены к памяти с помощью общей шины или коммутатора. Аппаратно поддерживается когерентность кэшей. Вся система работает под управлением единой ОС [5].
1.7 Системы с массовым параллелизмом
Системы с массовым параллелизмом содержат множество процессоров c индивидуальной памятью, которые связаны через некоторую коммуникационную среду. Как правило, системы MPP благодаря специализированной высокоскоростной системе обмена обеспечивают наивысшее быстродействие.
Кластерные системы более дешевый вариант MPP-систем, поскольку они также используют принцип передачи сообщений, но строятся из готовых компонентов. Базовым элементом кластера является локальная сеть. Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной [4].
Кластер – параллельный компьютер, все процессоры которого действуют как единое целое для решения одной задачи. Первым кластером на рабочих станциях был Beowulf. Проект Beowulf начался в 1994 г. сборкой в научно-космическом центре NASA 16-процессорного кластера на Ethernet-кабеле. С тех пор кластеры на рабочих станциях обычно называют Beowulf-кластерами. Любой Beowulf-кластер состоит из машин (узлов) и объединяющей их сети (коммутатора). Кроме ОС, необходимо установить и настроить сетевые драйверы, компиляторы, ПО поддержки параллельного программирования и распределения вычислительной нагрузки. В качестве узлов обычно используются однопроцессорные ВМ с быстродействием 1 ГГц и выше или SMP-серверы с небольшим числом процессоров (обычно 2–4).
Для получения хорошей производительности межпроцессорных обменов используют полнодуплексную сеть Fast Ethernetс пропускной способностью 100 Mбит/с. При этом для уменьшения числа коллизий устанавливают несколько «параллельных» сегментов Ethernet или соединяют узлы кластера через коммутатор (switch). В качестве операционных систем обычно используют Linux или Windows NT и ее варианты, а в качестве языка программирования – С++.
Наиболее распространенным интерфейсом параллельного программирования в мод модели передачи сообщений является MPI(Message Passing Interface). Рекомендуемой бесплатной реализацией MPI является пакет MPICH, разработанный в Аргоннской национальной лаборатории США.
Во многих организациях имеются локальные сети компьютеров с соответствующим программным обеспечением. Если такую сеть снабдить пакетом MPICH, то без дополнительных затрат получается Beowulf-кластер, сравнимый по мощности с супер-ЭВМ. Это является причиной широкого распространения таких кластеров.
2. Программное обеспечение и аппаратные средства мультипроцессорных систем
Тематика высокопроизводительных вычислений и мультипроцессорных систем была одной из основных тематик Института программных систем РАН. Если угодно -- исследования в этом направлении были одной из целей создания Института. В работах по данной тематике можно выделить несколько этапов [6]:
- 1990 - 1995 гг.: работы с транспьютерными системами, участие ИПС РАН в Российской транспьютерной ассоциации; начало исследований и первых экспериментов, в том направлении, которое в дальнейшем приведет к созданию Т-системы.
- 1994 - 1998 гг.: поиск и реализация решений для компонент первых версий Т-системы, в качестве аппаратной базы используются различные сети из ПЭВМ - начиная с самодельных сетей на базе «ускоренного RS-232» (до 1 Mbit/s) и собственных коммутирующих устройств для таких связей; заканчивая кластером на базе FastEthernet (100 Mbit/s).
- 1998 - 1999 гг.: развитие первой версии Т-системы, налаживание кооперации с коллегами из Минска, формирование суперкомпьютерной программы «СКИФ» Союзного государства.
- 2000 - 2004 гг.: период исполнения суперкомпьютерной программы «СКИФ» Союзного государства, в которой ИПС РАН определен как головной исполнитель от Российской Федерации.
- 2007 - 2011 гг. : период исполнения суперкомпьютерной программы «СКИФ» Союзного государства, в которой ИПС РАН определен как головной исполнитель от Российской Федерации.
1993-1994 годы
Работа с транспьютерными системами накладывает свой отпечаток на исследования: ведется разработка алгоритмов маршрутизации сообщений в транспьютерных сетях (многое заимствуется из работ с ЕС 2704 развивается теория расчета оптимальной конфигурации мультипроцессорной системы по заданному составу вычислительных модулей. В последнем случае речь идет о минимизации транзитных передач, устойчивости к отказам и обеспечении равномерности загрузки каналов. Оказывается, что при заданной «валентности» вычислительных узлов транспьютерной сети, то есть, при заданном числе каналов в узле транспьютероной сети(2), оптимальной конфигурацией являлись графы с минимальным диаметром. Отметим, что традиционные архитектуры (многомерные торы, гиперкубы, деревья и т. п.) сильно уступают графам с минимальным диаметром по устойчивости к отказам, поддержке равномерности загрузки каналов и минимизации транзитных передач. Для исследования графов с минимальными диаметрами был реализован комплекс программных средств (лаборатория ПСПА и ЗМР). В сотрудничестве лабораторий ПСПА и «Ботик» в это время ведутся исследования по возможности ускорения связи ПЭВМ при помощи RS-232, разработано и реализовано коммутационное оборудование для связи между собой ПЭВМ класса IBM PC.
1995 год
В рамках работ по транспьютерной тематике была выполнена разработка оригинальной интерфейсной платы для IBM PC на основе транспьютера Т425 (Пономарев А. Ю., Шевчук Ю. В., Позлевич Р. В.). Разработанная плата обеспечивает сопряжение персонального компьютера с аппаратурой на основе транспьютеров: с вычислительной транспьютерной сетью или с аппаратурой сбора экспериментальных данных на базе транспьютеров. Интерфейс с компьютером был построен по принципу разделяемой памяти -- это решение обеспечило скорость передачи данных до 5 Мбайт/сек на шине ISA, что приблизительно на порядок превосходило параметры всех существовавших в то время транспьютерных плат, использующих метод программного обмена через интерфейсный чип С011.
В это же время был завершен перенос свободного копилятора GNU С Compiler на архитектуру транспьютеров семейств Т4, Т8 и Т9 (Шевчук Ю. В.). Интересно отметить, что заключительная отладка и тестирование компилятора была осуществлена в удаленном режиме на установке GCel фирмы Parsytec в High Performance Computing Laboratory в Афинах (Греция). Тестирование показало, что по качеству генерируемого кода компилятор не уступает коммерческому компилятору АСЕ, входящему в состав ОС Parix. Показательно, что эти результаты почти десятилетней давности до сих пор пользуются успехом и разработанной системе посвящен раздел в архиве. В 1995 году впервые четко сформулированы базовые принципы Т-системы - системы программирования, обеспечивающей автоматическое распараллеливание программ на этапе выполнения программ в мультипроцессорных вычислительных системах с распределенной памятью (Абрамов С. М., Нестеров И. А., Суслов И. А., Пономарев А. Ю., Шевчук Ю. В., Позлевич Р. В., Адамович А. И.). В качестве входного языка системы рассматривались диалекты известных языков программирования, с небольшим количеством дополненных специальных конструкций и функционально-ориентированных ограничений. Возможность автоматического распараллеливания основывается на представлении вычислений в виде автотрансформации вычислительной сети, состоящей из процессов и обрабатываемых данных. Выполнена первая экспериментальная реализация Т-системы.
Было выполнено исследование применимости методов автоматического распараллеливания к основным алгоритмам вычислительной математики (Нестеров И. А., Суслов И. А.). Показано, что представление характерных для вычислительной математики структур данных возможно на основе специальных списковых структур, используемых при реализациях Т-системы, что не приводит к существенной потере производительности.
Первые прототипные программные реализации для экспериментов с Т-системой создавались в среде MS DOS. Именно в 1995 г. начились работы по использованияю ОС Linux и локальных сетей UNIX-станций в качестве платформы для Т-системы (Адамович А. И., Позлевич Р. В., Шевчук Ю. В.). Была разработана сетевая компонента Т-системы, обеспечивающая возможность распределенной загрузки задачи и внутризадачного обмена управляющими и инфромационными сообщениями. С использованием проведенной реализации изучены скоростные показатели межпрограммных внутризадачных обменов сообщениями.
2.1 Основные результаты суперкомпьютерной программы «СКИФ» Союзного государства
В 2000-2003 гг. получены следующие результаты:
- Разработана конструкторская документация (КД) и образцы высокопроизводительных систем «СКИФ» Ряда 1, которые прошли приемочные (государственные) испытания. По результатам государственных испытаний конструкторской документации присвоена литера О1.
- Разработано базовое программное обеспечение кластерного уровня (ПО КУ) и ряд прикладных систем суперкомпьютеров «СКИФ» Ряда 1. Данное ПО прошло приемочные (государственные) испытания. На испытания выносилось более двадцати программных систем, среди них:
- модифицированное ядро операционной системы Linux-SKIF (ИПС РАН и МГУ);
- модифицированные пакеты параллельной файловой системы PVFS-SKIF и системы пакетной обработки задач OpenPBS-SKIF (ИПС РАН и МГУ);
- мониторная система FLAME-SKIF кластерных установок семейства «СКИФ»;
- стандартные средства (MPI, PVM) поддержки параллельных вычислений, 12 адаптированных пакетов, библиотек и приложений (ИПС РАН и МГУ);
- Т-система и сопутствующие пакеты: T-ядро, компилятор tgcc, пакет tcmode для редактора Xemacs, демонстрационные и тестовые Т-задачи (ИПС РАН и МГУ);
- отладчик TDB для MPI-программ (ИПС РАН);
- две первые прикладные системы, разрабатываемые по программе «СКИФ»: одна для автоматизации проектирования химических реакторов (ИВВиИС, СПб.), другая, созданная с использованием технологий ИИ, для классификации большого потока текстов (ИЦИИ ИПС РАН).
По результатам испытаний данным программным системам ПО КУ «СКИФ» присвоена литера О1.
- В ОАО «НИЦЭВТ» подготовлена производственная база, проведена разработка КД и освоены в производстве адаптеры (N330, N337, N335) системной сети SCI, которые являются полными функциональными аналогами адаптеров SCI компании Dolphin (D330, D337, D335).
- В 2000-2003 гг. построено 12 опытных образцов и вычилительных установок Ряда 1 и Ряда 2 семейства «СКИФ».
- Самую высокую производительность из них имеет установка «СКИФ К-500»: пиковая производительность составляет 716.8 Gflops, реальная производительность - 471.6 Gflops (на задаче Linpack, 65.79% от пиковой). На 2004 год запланирован выпуск еще двух моделей суперкомпьютеров, самый мощный из них «СКИФ К-1000» ожидается со следующими показателями: пиковая производительность около 2.6 Tflops (ожидаемая реальная производительность на задаче Linpack: 1.7 Tflops).
Начаты работы по инженерным расчетам на системах семейства «СКИФ» и по созданию единого информационного пространства программы «СКИФ». В рамках приемочных (государственных) испытаний сверх программы и методики испытаний были показаны первые результаты в этом направлении:
- продемонстрированы результаты исследований, связанных с построением метакластерной распределенной вычислительной структуры на базе сети Интернет и трех кластерных систем «СКИФ» в г. Переславле-Залесском (ИПС РАН), г. Москве (НИИ механики МГУ) и в г. Минске (ОИПИ НАН Беларуси), подтверждающие функциональность и хорошие перспективы использования Т-системы в качестве базы для создания высокоуровневой среды поддержки подобных конфигураций;
- проведена проверка режима удаленного доступа из г. Минска к ресурсам одного из ведущих в области механики жидкости и газа инженерных пакетов STAR-CD, установленного на суперкомпьютере «СКИФ» в г. Переславле-Залесском (ИПС РАН);
- проведена проверка режима удаленного доступа из г. Минска с помощью Web-интерфейса к ресурсам программного комплекса для расчета процессов в PECVD-реакторах, установленного на суперкомпьютере «СКИФ» в г. Переславле-Залесском (ИПС РАН);
- показаны результаты использования ведущего в области механики деформируемого твердого тела инженерного пакета LS-DYNA, установленного на суперкомпьютере «СКИФ» в г. Минске (УП «НИИ ЭВМ»).
В Программе «СКИФ» было предусмотрено и мероприятие, связанное с подготовкой и переподготовкой кадров для работы с высокопроизводительными установками семейства «СКИФ». В рамках данного мероприятия летом 2002 и 2003 годов в Переславле-Залесском проведена студенческая школа-семинар по Программе «СКИФ», с участием студентов и аспирантов из России, Белоруссии, Украины. На различных секциях школы студенты занимались инженерными расчетами и программированием на Т-системе. В последние дни работы школ проводились конференции, где каждый участник докладывал о результатах, полученных в рамках школы. Подготовлены цифровые видеозаписи всех занятий школы-семинара, пригодные для использования при чтении лекций по Т-системе или инженерным расчетам.
3. Мультипроцессорные компьютеры
В мультипроцессорных компьютерах имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В мультипроцессоре существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Взаимодействие между отдельными процессорами организуется наиболее простым способом - через общую оперативную память [4].
Сам по себе процессорный блок не является законченным компьютером и поэтому не может выполнять программы без остальных блоков мультипроцессорного компьютера - памяти и периферийных устройств. Все периферийные устройства являются для всех процессоров мультипроцессорной системы общими. Территориальную распределенность мультипроцессор не поддерживает - все его блоки располагаются в одном или нескольких близко расположенных конструктивах, как и у обычного компьютера.
Основное достоинство мультипроцессора - его высокая производительность, которая достигается за счет параллельной работы нескольких процессоров. Так как при наличии общей памяти взаимодействие процессоров происходит очень быстро, мультипроцессоры могут эффективно выполнять даже приложения с высокой степенью связи по данным [5].
Еще одним важным свойством мультипроцессорных систем является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
3. 1 Обзор различных видов параллельных вычислительных систем
Для выполнения сложных расчетов и эффективной работы больших вычислительных систем обычно используют одну из следующих моделей:
- мультипроцессорная система;
- мультикомпьютерная система;
- распределенная система.
Мультипроцессорная система
Для мультипроцессорной системы характерно наличие общей памяти, доступ к которой может получить любой процессор, входящий в ее состав. В подобной системе для общей памяти используют для обмена информацией между различными процессорами. Это увеличивает скорость обмена данными, но сама реализация общей памяти, которой будут одновременно пользоваться сотни и сотни различных процессоров, на практике куда более сложный и трудоемкий процесс, чем осуществление межпроцессорного взаимодействия через дополнительные модули [5].
Мультикомпьютерная система
В отличие от этого, мультикомпьютерная система не имеет общей памяти, зато каждый из процессоров (обозначим их Р) имеет небольшой участок локальной памяти (М), где и происходит хранение обрабатываемой и анализируемой им информации [6]. Подобная архитектура подразумевает, что ни один из процессоров не сможет получить непосредственного доступа к данным другого, и это несколько усложняет обмен информацией уже на этапе совмещения результатов работы. Для осуществления подобного трафика данных между процессами существует дополнительный элемент, так называемая подсистема «внутренней коммуникационной сети».
Несмотря на то, что мультикомпьютерная система несколько уступает в скорости обработки мультипроцессорной, реализация такой системы значительно проще и дешевле (при аналогичном числе используемых процессоров).
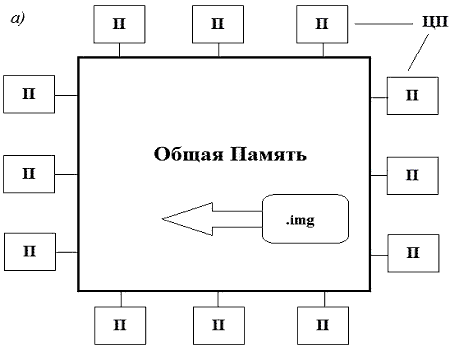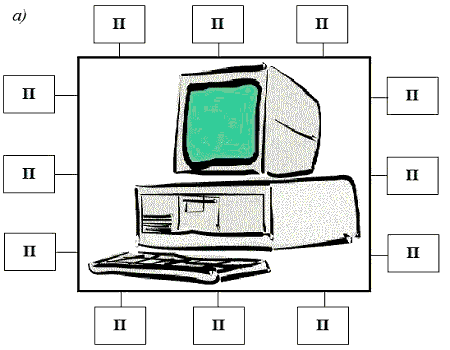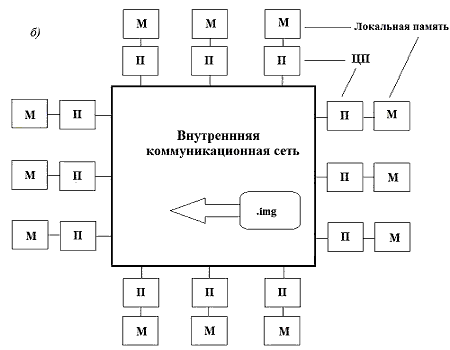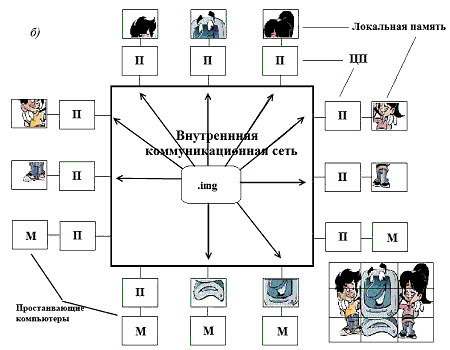
Рисунок 3. Различия в способах хранения и работы с данными в системах (5 кадров, 5 циклов повторения, 61,8 Кбайта):
а) мультипроцессорная система из 12 процессоров, использующих общую память;
б) мультикомпьютерная система из 12 процессоров, каждый из которых имеет собственную память.
3.2 Распределенные системы
Распределенной вычислительной системой (РВС) можно считать набор соединенных каналами связи независимых компьютеров, которые для постороннего пользователя являются единым целым [2]. РВС можно представить, как несколько отдельных персональных компьютеров или серверов, объединенных в единую систему с помощью сети Интернет. Естественно, сообщение данными через Интернет, как и сами способы организации подобного сообщения (обмен пакетами, маршрутизация и др. аспекты) между машинами, находящимися в различных частях земного шара (физически), нельзя назвать стабильным и определенно быстрым, а потому временные показатели подобных систем довольно низки. Однако РВС отличаются высокой надежностью, в виду того, что выход из строя одного элемента или узла сети не играет особой роли в ее работоспособности. К тому же, они обладают практически неограниченным потенциалом в плане наращивания производительности – чем больше компьютеров будет объединено этой структурой, тем выше будет их общая вычислительная мощность.
|
|
|
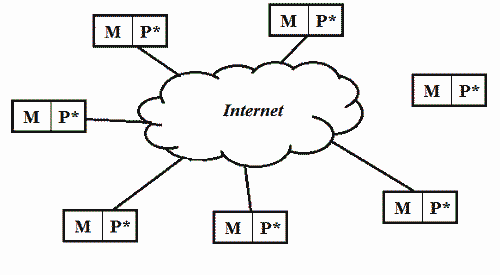
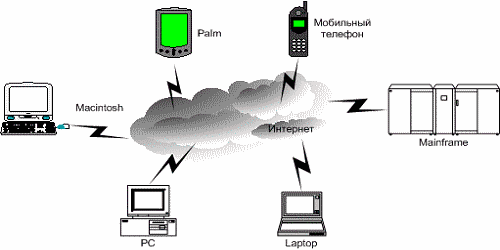
Рисунок 4. Общее представление распределенной сети (системы)
4. Обзор существующих классических методов планирования в различных вычислительных системах
4.1 Различные характеристики планировщиков задач
Способ решения вопроса о планировании задач существенно зависит от того, независимы или зависимы (связаны друг с другом) процессы в списке, а потому их можно в целом разбить на две большие категории:
- планирование независимых процессов;
- планирование зависимых процессов.
На данный момент существует множество различных алгоритмов планирования процессов, преследующих различные цели и обеспечивающих различное качество мультипроцессорной обработки внутри системы. Среди этого множества алгоритмов рассмотрим подробнее две группы наиболее часто встречающихся алгоритмов: алгоритмы, основанные на квантовании, и алгоритмы, основанные на приоритетах.
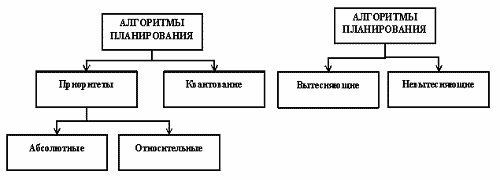
Рисунок 5. Базовая классификация алгоритмов планирования
Алгоритмы, основанные на идеи квантования, осуществляют смену активного процесса, если происходит одно из следующего:
- процесс завершился и покинул систему,
- произошла ошибка,
- процесс перешел в состояние ОЖИДАНИЕ,
- исчерпан квант процессорного времени, отведенный данному процессу.
Процесс, который исчерпал свой квант, переводится в состояние ГОТОВНОСТЬ и ожидает, когда ему будет предоставлен новый квант процессорного времени, а на выполнение в соответствии с определенным правилом выбирается новый процесс из очереди готовых. Таким образом, ни один процесс не занимает процессор надолго, поэтому квантование широко используется в системах разделения времени.
Сами кванты могут отличаться для различных процессов или же вообще изменяться с течением времени. Процессы, которые не полностью использовали выделенное им для работы время (например, из-за ухода на выполнение операций ввода-вывода), зачастую получают в системе дополнительные привилегии при последующем обслуживании. По-разному может быть организована и сама очередь готовых процессов: циклически, по правилу «первый пришел - первый обслужился» (FIFO), «последний пришел - первый обслужился» (LIFO) или при помощи другого, более сложного метода.
Другим способом классификации алгоритмов планирования можно считать разделение их на вытесняющие и невытесняющие.
Non-preemptive multitasking (невытесняющая многозадачность) - это способ планирования процессов, при котором активный процесс выполняется до тех пор, пока он сам, по собственной инициативе, не отдаст управление планировщику для того, чтобы тот выбрал из очереди другой, готовый к выполнению процесс.
Preemptive multitasking (вытесняющая многозадачность) - это такой способ, при котором решение о переключении процессора с выполнения одного процесса на выполнение другого процесса принимается планировщиком, а не самой активной задачей.
Понятия preemptive и non-preemptive иногда отождествляются с понятиями приоритетных и бесприоритетных дисциплин, что совершенно неверно, а также с понятиями абсолютных и относительных приоритетов, что неверно отчасти. Вытесняющая и невытесняющая многозадачность - это более широкие понятия, чем типы приоритетности. Приоритеты задач могут как использоваться, так и не использоваться и при вытесняющих, и при невытесняющих способах планирования. Так в случае использования приоритетов дисциплина относительных приоритетов может быть отнесена к классу систем с невытесняющей многозадачностью, а дисциплина абсолютных приоритетов - к классу систем с вытесняющей многозадачностью. А бесприоритетная дисциплина планирования, основанная на выделении равных квантов времени для всех задач, относиться к вытесняющим алгоритмам.
Основным различием между preemptive и non-preemptive вариантами многозадачности является степень централизации механизма планирования задач. При вытесняющей многозадачности данный механизм целиком сосредоточен в вычислительной системе, и программист пишет свое приложение, не заботясь о том, как оно будет выполняться параллельно с другими задачами. При этом сама система выполняет следующие функции: определяет момент снятия с выполнения активной задачи, запоминает ее контекст, выбирает из очереди готовых задач следующую и запускает ее на выполнение, загружая ее контекст.
При невытесняющей многозадачности механизм планирования распределен между системой и прикладными программами. Прикладная программа, получив управление, сама определяет момент завершения своей очередной итерации и возвращает управление системе с помощью какого-либо системного вызова, а та, в свою очередь, формирует очереди задач и выбирает в соответствии с некоторым алгоритмом (например, с учетом приоритетов) следующую задачу на выполнение. Такой механизм создает проблемы как для пользователей, так и для разработчиков.
4.2 Планировщики мультипроцессорных систем
Планировщики мультипроцессорных вычислительных систем мало чем отличаются от планировщиков процессов, используемых в самой операционной системе компьютера. Они призваны решать две следующие задачи:
• какой из готовых к выполнению процессов нужно запустить в данный конкретный момент времени;
• на каком из процессоров нужно запустить выбранный процесс.
Основным алгоритмом планирования независимых процессов является алгоритм с использованием очередей заданий. Основная идея в том, что все готовые к исполнению процессы помещаются в очередь заданий. Освободившийся процессор получает готовый к исполнению процесс из этой очереди. По мере обработки данных появляются новые готовые к исполнению процессы, которые помещаются в очередь заданий. При наличии нескольких готовых к исполнению процессов возникает проблема формирования правил выделения процессов из очереди.
Все процессы, готовые к исполнению, образуют либо единую очередь, упорядоченную по приоритетам, либо несколько очередей для процессов с разными приоритетами (например, очередь процессов с высоким приоритетом и с обычным приоритетом). Переключение процессоров заключается в выборе самого приоритетного процесса из очереди, который находится в ее начале. Смена процессов может вызываться исчерпанием кванта времени, отведенного под его выполнение, или переходом процесса в другое состояние.
Рассмотренная схема планирования позволяет:
- Обеспечить процессорам режим разделения времени;
- Позволяет автоматически балансировать загрузку процессоров системы, исключая ситуацию, когда один из них простаивает, в то время как другие процессоры перегружены.
К недостаткам данной схемы можно отнести возможную конкуренцию процессов при доступе к указанным очередям. Кроме того, такая схема планирования не учитывает следующее обстоятельство. Если определенный процесс долгое время выполнялся на одном и том же процессоре, то кэш-память этого процессора содержит достаточно много данных, принадлежащих этому процессу. После прерывания данного процесса, его будет логично запускать на том же самом процессоре, что и раньше, поскольку его кэш-память может еще содержать всю необходимую информацию. Некоторые существующие системы даже выполняют планирование с учетом данного обстоятельства, однако это негативного влияет на равномерную загрузку всех процессоров.
Весьма распространенный алгоритм для связных процессов состоит в статическом разбиении всего множества доступных процессоров на подмножества и назначении каждому из них отдельной группы связных процессов. Например, имеется четыре группы связанных процессов Q1-Q3, Q4-Q7, Q8-Q13 и Q14-Q20. Тогда, в соответствии с данным алгоритмом, процессы первой группы должны быть назначены первому подмножеству процессоров (P1-P3), процессы второй группы - второму подмножеству процессоров (P4-P7), и т.д. (см. рис. 4).
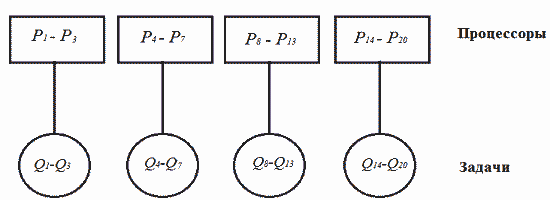
Рисунок 6. Планирование зависимых процессов.
Если в системе появляется новая группа связанных процессов, то проверяется, имеются ли необходимое для нее число процессоров. Если это так, то каждому процессу выделяется свой процессор. В противном же случае ни один из процессов этой группы не запускается до появления достаточного количества свободных процессоров. Процессор освобождается и поступает в пул свободных процессоров только после завершения назначенного ему процесса.
Достоинством этого алгоритма планирования в снижении накладных расходов на переключение контекста процессов. Недостаток - в потерях времени процессоров при блокировках. В связи с этим, развитием описанного метода стал алгоритм совместного планирования связных процессов, где группы связанных процессов также планируются как одно целое, однако выполняются в режиме разделения времени свободных процессоров. В начале каждого кванта времени производится перепланирование всех процессов.
4.3 Планировщики мультикомпьютерных систем
В мультикомпьютерах каждый процессор имеет собственный набор процессов (это чем-то напоминает описанный выше алгоритм). Поэтому этап планирования тут сводится к двум задачам:
- планирование процессов на каждом из процессоров с помощью локального алгоритма (аналогично планированию в однопроцессорной системе);
- распределение новых процессов по процессорам.
Последняя задача состоит в поиске такого алгоритма распределения процессов по процессорам, при котором эффективность системы максимальна (чаще всего под эффективностью системы понимаю «балансировку нагрузки» процессоров). После назначения процесса какому-либо ЦП этот процесс уже не может выполняться на другом. Основными алгоритмами для мультикомпьютерных систем можно считать следующие:
Детерминированный графовый алгоритм [3]. Если известны схемы обмена данными между процессами, то процессы назначаются ЦП таким образом, чтобы минимизировать сетевой трафик. Алгоритм: строится граф связей между процессами, затем разбивается на подграфы так, чтобы между ними было как можно меньше связей, следовательно, как можно меньше этапов обмена данными.
Распределенный эвристический алгоритм, инициируемый отправителем. Если создающий процесс ЦП перегружен, то он пытается случайным образом найти такой процессор, который перегружен меньше него, и передать ему процесс.
Распределенный эвристический алгоритм, инициируемый получателем. При завершении процесса анализируется загруженность данного процессора. Если он свободен, то ищет случайным образом загруженный процессор и запрашивает процесс из его очереди на выполнение [3].
Алгоритм «торгов». ЦП формирует «предложение». Каждому процессору назначается определенная «цена». При создании дочернего процесса, родительский анализирует рынок и выбирает самый дешевый процессор. Процесс отправляет заявку со своей ценой этому ЦП. Из всех заявок выбирается самый дорогой процессор, и выполнение процесса передается ему. Цена процессоров корректируется в течение времени.
Направление распределенных систем – это осуществление связи в глобальных сетях и предоставления доступа к ресурсам. Поэтому для них планируются не процессы, а предоставление им необходимых ресурсов. Аспектами планирования являются:
- определение исполнительных ресурсов для каждого задания;
- определение времени, в течение которого ресурсы отводятся заданию.
4.4 Планировщики распределенных систем
Для распределенных систем зачастую используют графовые алгоритмы, что в большей степени обусловлено самой структурой таких РВС. Из них можно выделить следующие большие группы алгоритмов:
Списочное планирование. Метод состоит в том, чтобы отсортировать и упорядочить вершины графа задач в список по какому-либо признаку, а затем последовательно формировать план для каждой отдельной задачи так, чтобы время начала ее выполнения было минимальным. Порядок задач в списке определяется их приоритетом. Вместо приоритета можно использовать топологический порядок задач в графе, верхний или нижний уровень вершины графа или их сумма (ВУ + НУ).
Нижний уровень вершины в графе – это длина наибольшего пути в графе, начинающегося с данной вершины. Верхний уровень вершины – это длина наибольшего пути в графе, оканчивающегося данной вершиной. В зависимости от типа приоритета, список вершин может формироваться один раз вначале выполнения алгоритма (статический приоритет) или же новая задача, подлежащая добавлению в план, будет заново вычисляться на каждой итерации (динамический приоритет).
Алгоритмы кластеризации задач [7]. Они направлены на минимизацию межпроцессорного взаимодействия. Это достигается за счет объединения сильно связанных между собой процессов в отдельные кластеры, которые затем отображаются на процессоры заданной вычислительной системы. Здесь на каждой итерации за основу берутся уже не вершины, а ребра графа задач.
В алгоритме линейной кластеризации из графа задач сразу выделяют критический путь и уже из него формируют отдельный кластер. Затем для всех оставшихся вершин эти итерация повторяется. В кластеризации по ребру на каждой итерации рассматривается одно ребро и определяется, приведет ли обнуление веса данного ребра к сокращению общей длины плана. Результат выполнения алгоритма кластеризации в общем случае еще нельзя считать искомым решением задачи планирования - получившиеся кластеры необходимо отобразить на процессоры целевой вычислительной системы.
Заключение
В процессе выполнения курсовой работы были описаны общие требования, предъявляемые к многопроцессорным системам; классификация систем параллельной обработки; модели связи и архитектура памяти; а также мультипроцессорные системы с общей и локальной памяти.
Создание качественного и эффективного алгоритма планирования процессов является залогом успешного функционирования любой вычислительной системы. Там где в подобном случае нельзя обойтись уже имеющимися универсальными наработками в этой области, необходимость создания нового или модификации существующего планировщика, без сомнений, принесет положительные результаты.
Список используемых источников
- Барский А.Б. Параллельные процессы в вычислительных системах. Планирование и организация / А.Б. Барский. — М.: Радио и связь,1990. 256 с.
- Таненбаум Э., ван Стеен М. Распределенные системы. Принципы и парадигмы. - СПб.: Питер, 2003. — 877 с.: ил. — (Серия «Классика Computer Science») — ISBN 5–272–00053–6.
- Таненбаум Э.: «Современные операционные системы», 3-е издание - СПб.: «Питер», 2011.- 1115 с.
- Морев Н. В. Сравнение алгоритмов планирования распределения задач для однородных распределенных вычислительных систем [Текст] / Н. В. Морев // Информационные технологии : Научно-технический и научно-производственный журнал. - 2010. - N 5. - С. 43-46
- Афраймович Л.Г. Модели и методы эффективного использования распределенных вычислительных систем [Учебно-методическое пособие] — Нижний Новгород, 2012 – 17 с.
- Принципы построения параллельных вычислительных систем. / Электронный ресурс. - Режим доступа: http://wiki.auditory.ru/Принципы_построения_параллельных_вычислительных_систем
- Воронцов К. В. Лекции по алгоритмам кластеризации и многомерного шкалирования. / Электронный ресурс. - Режим доступа: http://www.ccas.ru/voron/download/Clustering.pdf

- Разработка регламента выполнения процесса «Транспортная доставка заказов» (Описание предметной области. Постановка задачи.)
- Понятие переменной в программировании. Виды и типы переменных (Понятие переменных и их использование)
- Проблемы проведения организационных изменений, а так же, чтобы раскрыть сущности управления организационными изменениями
- Анализ конкурентов салона красоты «Елена»
- Управление оборотными средствами на предприятии( Теоретические аспекты управления оборотными средствами предприятия )
- Методы, используемые для финансового анализа деятельности предприятия
- Особенности влияния стрессовых ситуаций на поведение человека в профессиональной деятельности
- Анализ финансового состояния гостиничного предприятия «Пятый угол»
- Применение методов анализа внешней и внутренней среды в деятельности ООО «Максимум Авто»
- Влияние российского менталитета на корпоративную культуру
- Исследования франчайзингового рынка и разработка франчайзингового пакета
- Анализ структуры налоговых обязательств и налоговой нагрузки на примере ОАО «Балтийский Банк»