
Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования (Общие представления о методах сортировки)
Содержание:

Введение
Сегодня новые информационные технологии занимают важное место не только в специализированных, но и в повседневных сферах жизни. Компьютеры используются в бизнесе, управлении, торговле, школе и многих других сферах человеческой деятельности.
Компьютерные технологии очень удобны для выполнения различных задач, но в разных областях применения эти операции различны. Следовательно, каждой отдельной отрасли, которая использует специальные технические средства, нужны собственные программы, которые обеспечивают работу компьютеров.
Разработка программного обеспечения имеет дело с такой отраслью науки, как программирование. Это становится все более и более важным в последнее время, потому что с каждым днем компьютер становится все более и более необходимым, все более и более повседневным явлением нашей жизни. Ведь компьютерные технологии прошлых лет практически полностью себя исчерпали и не удовлетворяют потребности, которые предстают перед человечеством.
Таким образом, новые информационные технологии очень актуальны в наше время и требуют большего внимания для последующего развития и совершенствования. Наряду с этим большое значение имеет программирование, которое является одной из фундаментальных отраслей информатики и поэтому не может оставаться в стороне.
Программирование содержит ряд важных внутренних задач. Одной из важнейших задач программирования является задача сортировки.
Возможно, ни одна другая проблема не породила такого количества разнообразных решений, как проблема сортировки. Есть ли «универсальный», лучший алгоритм? В общем нет. Однако, имея приблизительные характеристики входных данных, вы можете выбрать метод, который работает оптимальным образом.
Существует много способов сортировки, каждый из которых имеет свои преимущества и недостатки. Алгоритмы сортировки имеют большое практическое значение, они интересны сами по себе. Эта довольно глубоко изученная область информатики используется в информационно-поисковых системах, в военной и банковской сферах.
Помимо общего научного интереса к алгоритмам сортировки, в каждом алгоритме интересно оценить его так называемую сложность.
Сложность заключается в максимальном количестве элементарных шагов алгоритма. Используя примеры сортировки, можно показать, как, усложняя алгоритм, хотя уже есть очевидные методы под рукой, вы можете добиться значительного увеличения эффективности.
При решении проблемы сортировки массивов обычно существует требование минимального использования дополнительной памяти, что подразумевает недопустимость использования дополнительных массивов.
Для оценки производительности алгоритмов различных методов сортировки, как правило, используются два показателя: количество назначений, количество сравнений.
Также важны такие показатели, как:
• Объем памяти. Ряд алгоритмов требует выделения дополнительной памяти для временного хранения данных. При оценке используемой памяти пространство, занимающее исходный массив, и затраты, не зависящие от последовательности ввода, например, для хранения программного кода, не будут учитываться.
• Стабильность. Стабильная сортировка не меняет взаимное расположение равных элементов. Такое свойство может быть очень полезным, если оно состоит из нескольких полей, и сортировка происходит по одному из них.
• естественное поведение. Эффективность метода в обработке уже отсортированных или частично отсортированных данных. Алгоритм ведет себя естественно, если он учитывает эту характеристику входной последовательности и работает лучше.
В этой курсовой работе я изучу в теоретической части алгоритмы сортировки, используемые в информатике, их эволюцию, а также рассмотрю проблему упорядочения данных с практической точки зрения: преимущества и недостатки различных методов сортировки, т.е. их эффективность.
Растущие требования к скорости сортировки алгоритмов и расширение круга задач, для которых они используются, приводит к тому, что задача сравнительного анализа алгоритмов сортировки: их эффективность и применимость остается важной и актуальной.
В этой курсовой работе мы обсудим эффективность различных методов сортировки данных.
Объект и предмет исследования - методы сортировки данных.
Целью исследования было сравнение преимуществ и недостатков наиболее распространенных алгоритмов сортировки данных.
Для достижения этой цели были поставлены и решены следующие задачи:
1. Рассмотрим наиболее распространенные алгоритмы сортировки данных;
2. Выявить достоинства и недостатки этих алгоритмов;
3. Проследить эволюцию алгоритмов сортировки данных от первых методов, используемых в компьютерной обработке информации, до настоящего времени, выделив основные этапы и направления их развития.
1. Общие представления о методах сортировки
В словарях слово «сортировка» определяется как «распределение, отбор по сортам; При делении на категории, оценки, категории программисты обычно используют это слово в более узком смысле, обозначая им перестановку элементов в определенном порядке. Этот процесс, возможно, следует называть не сортировкой, а упорядочением или ранжированием (сегментированием) [4]. Однако слово «сортировка» уже прочно вошло в повседневную жизнь программистов, поэтому мы будем продолжать использовать слово «сортировка» в узком смысле слова «сортировка по порядку». Теперь сформулируем определение «сортировка», которое мы будем использовать в будущем.
Сортировка - это процесс перегруппировки заданного набора объектов в определенном порядке.
Целью сортировки является облегчение поиска элементов в отсортированном наборе. В этом смысле сортирующие элементы присутствуют практически во всех задачах. Упорядоченные объекты содержатся в различных утверждениях, в каталогах, в телефонных книгах, в оглавлениях, в библиотеках, в словарях, на складах и почти везде, где их нужно искать [5].
Поэтому методы сортировки очень важны, особенно при обработке данных. Многие фундаментальные методы построения алгоритмов связаны с сортировкой, почти все такие методы встречаются в связи с алгоритмами сортировки. В частности, сортировка является идеальным примером огромного разнообразия алгоритмов, которые выполняют одну и ту же задачу, многие из которых являются в некотором смысле оптимальными, и большинство имеют некоторые преимущества перед другими. Поэтому, используя пример сортировки, мы убедились в необходимости сравнительного анализа алгоритмов.
Зависимость выбора алгоритмов от структуры данных настолько сильна, что методы сортировки обычно делятся на две категории: сортировка массивов и сортировка (последовательных) файлов. Эти два класса часто называют внутренней и внешней сортировкой [1].
2. Эволюция методов сортировки
Важная практическая проблема сортировки данных в больших массивах впервые появилась в США в середине XIX века. В 1840 году там было создано центральное бюро переписей, куда поступали первичные данные со всех штатов. В ходе переписи было опрошено 17 069 453 человека, каждая анкета состояла из 13 вопросов. Объем полученных данных был настолько велик, что обработка их традиционным ручным способом требовала непомерных трудовых и временных затрат. Ситуация усугублялась необходимостью постоянных сверок и перерасчетов из-за ошибок, допущенных при ручной сортировке. С каждой новой переписью, которая проводилась раз в десять лет, объем обрабатываемой информации, а вместе с ней стоимость и продолжительность обработки данных увеличивались. Таким образом, ручная обработка данных переписи 1880 года (50 189 209 человек) требовала участия сотен сотрудников и продолжалась семь с половиной лет [10].
Перед переписью 1890 года для решения проблемы сортировки данных по очень большим объемам информации по инициативе бюро переписей был проведен конкурс на лучшее электромеханическое сортировочное оборудование, которое сделало бы сортировку данных более эффективной - быстрее, точнее и дешевле. В конкурсе победил американский инженер и изобретатель немецкого происхождения Херман Холлерит, который разработал оборудование для перфокарт - электрическую систему табулирования, которая стала известной как система электронных табло Hollerith. Использование этого оборудования в ходе переписей США в 1890 и 1900 годах считалось очень успешным.
Вот как преимущества машины Холлерита были описаны в российском журнале «Вестник экспериментальной физики и элементарной математики» в 1895 году: «Преимущества машины Холлерита:
а) при значительном ускорении и удешевлении работы. С помощью ручного метода вы можете разложить и рассчитать не более 400 карт в час. Если предположить, что в Российской империи проживает 120 миллионов человек, то на изготовление сводной таблицы потребуется не менее ... 300 000 часов ... Машина сокращает работу почти в 5 раз.
б) более точные результаты ...
в) в большей легкости получения сложных сводных таблиц ... После нескольких проходов через машину всех карточек оценок, получаются полные и разнообразные таблицы, составление которых было почти немыслимо с помощью того же метода. [2].
Использование метода табулирования для сортировки данных оказалось настолько эффективным, что результаты переписи были всего за шесть недель, а полный статистический анализ данных занял два с половиной года. Таким образом, обработка данных с использованием машины Hollerith заняла в три раза меньше времени, чем вручную. Более того, точность сводных таблиц значительно возросла.
Таким образом, в конце 19-го века ручная сортировка данных в массивах была заменена сортировкой с использованием статистических табуляторов. В этом случае использовался алгоритм побитовой сортировки.
Следующий этап в разработке методов и алгоритмов сортировки начался в начале 1940-х годов с появлением первых электронных компьютеров. Потрясающая для тех времен скорость компьютеров вызвала рост интереса к новым алгоритмам сортировки, адаптированным для машинной обработки. В 1946 году была опубликована первая статья об алгоритмах сортировки данных. Его написал Джон Уильям Мочли, американский физик и инженер, один из основателей первого в мире электронного цифрового компьютера ENIAC. В статье рассмотрен ряд новых алгоритмов сортировки, в том числе метод двоичных вставок. До середины 1950-х годов наиболее распространенными модификациями были сортировка слиянием и вставки со сложностью O (n log n) для n элементов. Другим следствием перехода к сортировке данных с использованием компьютера стало разделение сортировки на два типа - внешние и внутренние, то есть использование и не использование данных, расположенных на периферийных устройствах.
В середине 1950-х годов, с развитием компьютеров второго поколения, началась активная разработка алгоритмов сортировки. Основными предпосылками для этого были, во-первых, значительное упрощение и ускорение написания программ для компьютеров в результате разработки первых языков программирования высокого уровня (Fortran, Algol, Kobol); во-вторых, значительное увеличение доступности компьютеров в результате резкого уменьшения их размеров и стоимости и, как следствие, их довольно широкого распространения; в-третьих, увеличение производительности компьютера до 30 тыс. операций в секунду.
В 1959 году Дональд Льюис Шелл предложил метод сортировки по убыванию (шеллсорт), в 1960 году - метод быстрой сортировки Чарльз Энтони Ричард Хоар (быстрая сортировка), а в 1964 году - метод Дж. У. Дж. Уильямса, метод heapsort. Многие алгоритмы, разработанные в этот период (например, быстрая сортировка Хоара), широко использовались до настоящего времени [4]. Результаты этого этапа активной разработки алгоритмов сортировки были обобщены в 1973 году Дональдом Эрвином Кнутом в третьем томе его фундаментальной монографии «Искусство программирования».
К началу 1970-х годов использовались следующие типы внутренних алгоритмов сортировки: сортировка по счету; сортировка по вставкам; биржевая сортировка; сортировка по выбору; сортировка слиянием; сортировка по распределению.
Наибольшее количество методов, разработанных к тому времени, было связано с сортировкой по вставкам (простой метод вставки, двоичные и двойные дорожки, метод Shell, вставка в список, сортировка с вычислением адреса и т. Д.), Сортировкой по обмену (пузырьковый метод и его модификации, дозатор параллельной сортировки). , быстрая сортировка, обмен побитовой сортировкой, асимптотические методы) и сортировка по выбору (выбор дерева, сортировка по пирамиде, метод исключения из наибольшего, метод очередей связанных родственных представлений).
Также активно развивались методы внешней сортировки, в том числе методы многолучевого слияния и выделения с подстановкой, многофазного слияния, каскадного слияния, осциллирующей сортировки, внешней побитовой сортировки и т.д.
Еще один всплеск интереса к алгоритмам сортировки произошел в середине 1970-х годов, когда крупные интегральные схемы стали элементной базой компьютеров, и стало возможным объединить мощь компьютеров, создав единые вычислительные центры, позволяющие работать с разделением времени [3].
В период с середины 1970-х до 1990-х годов был достигнут значительный успех в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их модификации или комбинирования. Например, голландский ученый Эдсгер Вибе Дейкстра в 1981 году предложил алгоритм плавной сортировки (Smoothsort), который является развитием пирамидальной сортировки (Heapsort). Вторым направлением совершенствования алгоритмов сортировки стал поиск оптимальных входных последовательностей для разных методов сортировки, что позволило значительно сократить его время. Третьим направлением, наиболее интенсивно развивающимся, было решение задачи сортировки в классе параллельных алгоритмов, для которого были обобщены не только ранее известные парадигмы, но и принципиально новые алгоритмы. Развитие этой области также стимулировалось расширением использования сортировочных сетей, а также многомерных вычислительных сеток [10].
Для современного этапа разработки методов и методов сортировки характерно исследование задач сортировки по частично упорядоченным множествам: задачи распознавания частично упорядоченного множества M; задачи сортировки частично упорядоченного множества M с использованием результатов парных сравнений элементов, а также задачи определения порядка на множестве M без априорной информации. Актуальность этих задач обусловлена появлением и распространением компьютеров на суперкомплексных микропроцессорах с параллельно-векторной структурой, высокоэффективных сетевых компьютерных систем [3].
Таким образом, исследовав эволюцию методов и алгоритмов сортировки машинных данных в массивах, можно выделить следующие пять этапов.
Первый этап начался в 1870 году и продолжался до начала 1940-х годов. Отмечен переход от ручной сортировки к сортировке с использованием статистических табуляторов. В этом случае использовался алгоритм побитовой сортировки [4].
Второй этап - с начала 1940-х до середины 1950-х годов. Счетно-перфорационные машины были заменены компьютерами первого поколения, для которых был разработан ряд новых алгоритмов сортировки. Произошло разделение их внутреннего и внешнего. Наиболее распространенными в этот период были модификации сортировки слиянием и вставки сложности O (n log n).
Третий этап начался в середине 1950-х годов и продолжался до середины 1970-х годов. Для него было характерно активное развитие алгоритмов сортировки - внешних и внутренних, стабильных и нестабильных - многие из которых широко используются сегодня. Наибольшее количество разработанных к тому времени методов связано с сортировкой по вставкам, обменной сортировкой и сортировкой по выбору [10].
Четвертый этап длился с середины 1970-х до середины 1990-х годов. Появление компьютерных центров, сочетающих мощность отдельных компьютеров и позволяющих работать с разделением времени, потребовало разработки новых алгоритмов сортировки и модификации существующих. Началось изучение проблем сортировки в классе параллельных алгоритмов, достигнут значительный прогресс в увеличении скорости сортировки за счет повышения эффективности алгоритмов, уже известных к тому времени благодаря их уточнению или комбинации. В то же время был проведен поиск оптимальных входных последовательностей для разных методов сортировки, что позволило значительно сократить его время [3].
Пятый этап начался в середине 1990-х годов и продолжается по настоящее время. Особое значение имело изучение задач сортировки на частично упорядоченных множествах: задачи распознавания частично упорядоченного множества M; задачи сортировки частично упорядоченного множества M с использованием результатов парных сравнений элементов, а также задачи определения порядка на множестве M без априорной информации. Актуальность этих задач объясняется появлением и широким использованием компьютеров на суперкомплексных микропроцессорах с параллельно-векторной структурой, а также высокопроизводительных сетевых компьютерных систем.
3. Методы внутренней сортировки
При внутренней сортировке все отсортированные данные помещаются в оперативную память компьютера, где вы можете получить доступ к данным в любом порядке (то есть используется модель памяти с произвольным доступом). Внешняя сортировка применяется, когда объем данных, которые нужно упорядочить, слишком велик для того, чтобы все данные были помещены в основную память. Здесь узким местом является механизм перемещения больших блоков данных с внешних устройств хранения данных в основную память компьютера и наоборот. Тот факт, что физически непрерывные данные необходимы для удобного перемещения в виде блочной структуры, заставляет нас использовать различные методы внешней сортировки [1].
Рассмотрим основные базовые алгоритмы внутренней сортировки. Простейший из этих алгоритмов тратит время порядка O (n2). Другими словами, при сортировке массива, состоящего из n компонентов, такие алгоритмы будут выполнять действия c * n2, где c - некоторая константа. Потому что применимо только к небольшим наборам предметов. Один из самых популярных алгоритмов сортировки, так называемая быстрая сортировка, выполняется в среднем за время O (n log n). Быстрая сортировка хорошо работает в большинстве приложений, хотя в худшем случае она также имеет время выполнения O (n2). Существуют другие методы сортировки, такие как сортировка по пирамиде или сортировка по слиянию, которые в худшем случае дают время порядка O (n log n), но в среднем (в статистическом смысле) работают не лучше, чем быстрая сортировка. Отметим, что метод сортировки слиянием хорошо подходит для построения внешних алгоритмов сортировки [7].
Предположим, что сортируемые объекты являются записями, содержащими одно или несколько полей. Одно из полей, называемое ключом, имеет такой тип данных, что оно определяет отношение линейного порядка «<». Целые и действительные числа, символьные массивы являются типичными примерами таких типов данных, но, конечно, мы можем использовать ключи других типов данных, при условии, что они могут определять отношение «меньше» или «меньше или равно» [6].
Задача сортировки состоит в том, чтобы организовать последовательность записей так, чтобы значения ключевого поля были неубывающей последовательностью.
Существует несколько десятков вариантов реализации сортировки в теории алгоритмов. Рассмотрим наиболее известные из них: пузырьковая сортировка, сортировка вставкой, сортировка выбора, сортировка оболочки, сортировка кучи, сортировка кучи, быстрая сортировка. Все их можно разделить на простые и продвинутые методы сортировки.
3.1.Простые методы сортировки
3.1.1.Пузырьковая сортировка (метод обменной сортировки)
Самым простым и известным методом сортировки является так называемый метод пузырьковой сортировки. Основная идея этого метода заключается в том, что сортируемые данные хранятся в массиве, расположенном вертикально. Записи с небольшими значениями ключевого поля светлее и всплывают вверх, как пузырь [3]. Во время первого прохода по массиву, начиная переход снизу, берется первая запись массива, и ее ключ поочередно сравнивается с ключами последующих записей. Если есть запись с «более тяжелым» ключом, то эти записи меняются местами. При встрече записи с «светлым» ключом эта запись становится «эталоном» для сравнения, и все последующие записи сравниваются с этим новым, более светлым «ключом». В результате запись с наименьшим значением ключа будет находиться в самом верху массива. Во время второго прохода вдоль массива идет запись со вторым по величине ключом, которая помещается под записью, найденной во время первого прохода массива, то есть на втором месте с верхней позиции и т. Д. [1].
Демонстрация сортировки по неубыванию методом «пузыря» представлена в приложении [рис.1]
Bubblesorting использует метод сортировки обмена. Он основан на выполнении операций сравнения в цикле и, при необходимости, обмена соседними элементами. Его название обусловлено сходством процесса движения пузырьков в резервуаре с водой, когда каждый пузырь находит свой уровень [6].
При анализе любой сортировки определяется количество операций сравнения и обмена, выполненных в лучшем, среднем и худшем случаях. Для пузырьковой сортировки количество сравнений остается неизменным, поскольку два цикла всегда выполняются указанное количество раз, независимо от порядка в исходном массиве. Это означает, что при сортировке методом пузырьков всегда выполняются операции сравнения, где «n» указывает количество элементов, которые должны быть отсортированы массивом. Эта формула получена на основании того, что цикл сортировки внешнего цикла выполняется n-1 раз, а внутренний цикл - n / 2 раза. Их умножение даст указанную формулу. Количество операций обмена будет нулевым в лучшем случае, когда исходный массив уже отсортирован. Количество обменных транзакций для среднего случая будет равно, а для худшего случая оно будет равно временам. Можно отметить, что по мере ухудшения упорядочения исходного массива число неупорядоченных элементов приближается к числу сравнений (каждый неупорядоченный элемент требует трех операций обмена). Сортировка по пузырьковому методу называется квадратичным алгоритмом, поскольку время его выполнения пропорционально квадрату количества отсортированных элементов. Сортировка большого количества элементов с использованием пузырькового метода займет много времени, так как время выполнения сортировки находится в квадратичной зависимости от количества элементов массива [5].
3.1.2.Сортировка вставками
Сортировка вставок - это простой алгоритм сортировки, который заключается в анализе каждого конкретного элемента в отдельности, который затем помещается в нужное место среди других уже отсортированных элементов. Следует позаботиться о том, чтобы освободить место для вставленного элемента, сместив крупные элементы на одну позицию вправо, после чего вставленный элемент помещается в свободное пространство [3].
Хотя этот метод сортировки намного менее эффективен, чем более сложные алгоритмы (такие как быстрая сортировка), он имеет несколько преимуществ:
• прост в реализации
• эффективен для небольших наборов данных
• эффективен для наборов данных, которые уже частично отсортированы
• это надежный алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы)
• может сортировать список по мере его поступления
На каждом шаге алгоритма мы выбираем один из элементов входных данных и вставляем его в нужную позицию в уже отсортированном списке, пока набор входных данных не будет исчерпан. Выбор следующего элемента, выбранного из исходного массива, является произвольным; можно использовать практически любой алгоритм выбора. Количество перестановок для сортировки вставок в среднем точно такое же, как и для пузырькового алгоритма [2]. Демонстрация сортировки вкладышей представлена в приложении [Рис.2].
Сортировка вкладышей требует фиксированного количества проходов. Общее количество сравнений:
В отличие от других методов, сортировка вставок не использует обмен. Сложность алгоритма измеряется количеством сравнений и равна O (n2).
Положительной стороной метода является простота реализации, а также его эффективность на частично упорядоченных последовательностях и / или состоящих из небольшого количества элементов. Однако высокая вычислительная сложность не позволяет рекомендовать алгоритм для широкого использования. [4].
3.1.3.Сортировка методом выбора.
Сортировка выбором — это некий гибрид между пузырьковой сортировкой и сортировкой вставками [5].
Идея метода состоит в том, чтобы создавать отсортированную последовательность путем присоединения к ней одного элемента за другим в правильном порядке.
При данной сортировке из массива выбирается элемент с наименьшим значением и обменивается с первым элементом. Затем из оставшихсяn-1 элементов снова выбирается элемент с наименьшим ключом и обменивается со вторым элементом, и т.д. Демонстрация методом выбора представлена в приложении [рис. 3].
Как и в пузырьковой сортировке, внешний цикл выполняетсяn-1 раз, а внутренний – в среднем n/2 раз. Следовательно, сортировка методом простого выбора требует сравнений. Таким образом, это алгоритм порядка O(n2), из-за чего он считается слишком медленным для сортировки большого количества элементов.
Несмотря на то, что количество сравнений в пузырьковой сортировке и сортировке простым выбором одинаковое, в последней количество обменов в среднем случае намного меньше, чем в пузырьковой сортировке [4].
Сортировка выбором проста в реализации, и в некоторых ситуациях стоит предпочесть ее наиболее сложным и совершенным методам. Но в большинстве случаев данный алгоритм уступает в эффективности последним, так как в худшем, лучшем и среднем случае ей потребуется О (n2) времени.
3.2. Улучшенные (усовершенствованные) методы сортировки
В отличие от простых сортировок со сложностью O (n2), алгоритмы с общей сложностью O (n log n) относятся к числу улучшенных сортировок.
Следует отметить, однако, что для небольших наборов данных, которые должны быть отсортированы (n <100), эффективность быстрых сортировок не столь очевидна: усиление становится заметным только для больших n. Поэтому, если необходимо отсортировать небольшой набор данных, выгоднее выполнить одну из простых сортировок [2].
3.2.1. Сортировка Шелла (слияние с обменом)
В 1959 году Дональд Шелл отметил, что в алгоритме вставки наиболее неэффективным шагом является перенос текущего объекта в левую сторону через множество других объектов [6]. Shell предложила эффективный способ решения этой проблемы - последовательное применение так называемых частичных сортировок. Используя указанный механизм, алгоритм генерирует массив для сортировки по h, где h - это значение, на которое каждый элемент может отклоняться от своей целевой позиции в полностью отсортированном массиве данных. Таким образом, последовательно применяя частичную сортировку с уменьшением значения h, можно сортировать большой массив данных быстрее, чем классические алгоритмы сортировки. Однако слабым местом этого метода является сложность выбора последовательности частичных сортировок. От правильности этого выбора зависит конечная эффективность алгоритма. Обычная практика - последовательность, предложенная Дональдом Кнутом, математиком и ученым.: . [2].
Идея метода заключается в том, что выбирается интервал h между сравниваемыми элементами, который уменьшается после каждого прохода. Для последовательности интервалов выполняются условия:
- Таким образом, сначала сравниваются удаленные элементы (и, если необходимо, переставляются), а соседние элементы сравниваются на последнем проходе.
- Усиление получается благодаря тому, что на каждом этапе сортировки задействовано относительно немного элементов, или эти элементы уже достаточно хорошо упорядочены, и требуется небольшое количество перестановок. Последнее представление сортировки Shell выполняется по тому же алгоритму, что и при сортировке челнока. Предыдущие представления аналогичны представлениям обработки челнока, но они сравнивают не смежные элементы, а элементы, которые отделены заданным расстоянием h. Большой шаг на начальных этапах сортировки позволяет сократить количество вторичных сравнений на более поздних этапах.
- При анализе этого алгоритма возникают довольно сложные математические проблемы, многие из которых еще не решены. Например, неизвестно, какая последовательность расстояний дает наилучшие результаты, хотя было обнаружено, что расстояния h1 не должны быть множителями друг друга. Мы можем порекомендовать следующие последовательности (они написаны в обратном порядке):
- 1, 4, 13, 40, 121, ... , где hk-1=3hk+1, hp=1 и p=log2n-1
- 1, 3, 7, 15, 31, ... , где hk-1=2hk+1, hp=1 и p=log2n-1
В приложении[рис.4] изображена демонстрация сортировки Шелла.
Общий метод, который использует сортировку включением, применяет принцип уменьшения расстояния между сравниваемыми элементами. Сначала сортируются все элементы, смещенные друг от друга на позиции. Затем сортируются все элементы, которые смещены на две позиции. И, наконец, упорядочиваются все соседние элементы [4].
Метод, предложенный Дональдом Л. Шеллом, является неустойчивой сортировкой. Эффективность метода Шелла объясняется тем, что сдвигаемые элементы быстро попадают на нужные места. Среднее время для сортировки Шелла равняется O(nlg2n) [1].
3.2.2. Пирамидальная сортировка
Этот алгоритм получил свое название благодаря тому, что используемое здесь частично упорядоченное дерево сортировки имеет форму «пирамиды». Отметим также, что в русском издании книги [3] этот метод сортировки называется «разновидностью дерева», то есть упорядочением по дереву сортировки [1].
Этот метод сортировки был предложен J.W.J. Уильямс и Р. У. Флойд в 1964 г.
Метод пирамидальной сортировки - это улучшение традиционной сортировки с помощью дерева [6].
Сортировка основана на использовании структуры данных - пирамиды (дерево сортировки, куча). Пирамида - это двоичное дерево, для которого выполняются условия:
1. Значение в любой вершине не меньше, чем значения ее потомков.
2. Глубина листьев (расстояние до корня) отличается не более чем на 1 слой.
3. Последний слой заполняется слева направо.
Наиболее наглядный способ построения пирамиды выглядит в виде дерева массива, показанного в приложении [рис. 5]. Массив представлен в виде двоичного дерева, корень которого соответствует элементу массива a [1]. На втором уровне находятся элементы a [2] и a [3]. На третьем - a [4], a [5], a [6], a [7] и т. Д. Как видно, для массива с нечетным числом элементов соответствующее дерево будет сбалансировано, а длямассив с четным числом элементов n, элемент a [n] будет единственным (самым левым) листом «почти» сбалансированного дерева [6].
На [рис. 6] приложение показывает, как сортировать, используя построенную пирамиду. Суть алгоритма заключается в следующем. Позвольте мне быть наибольшим индексом массива, для которого условия пирамиды являются значимыми. Затем, начиная с [1] до [i], выполняются следующие действия. На каждом шаге выбирается последний элемент пирамиды (в нашем случае элемент a [8] будет выбран первым). Его значение изменяется вместе со значением a [1], после чего a [1] просеивается. Более того, на каждом шаге число элементов в пирамиде уменьшается на 1 (после первого шага a [1], a [2], ..., a [n-1] рассматриваются как элементы пирамиды; a [1], a [2], ..., a [n-2] и т. Д., Пока один элемент не останется в пирамиде) [5].
Процедура сортировки по пирамиде требует выполнения ≈n log n шагов (логарифм является двоичным) в худшем случае, что делает его особенно привлекательным для сортировки больших массивов [8].
3.2.3.Сортировка методом Xoapa (быстрая сортировка)
Применение принципа «разделяй и властвуй» в сортировке приводит нас к одному алгоритму сортировки, который важен в информатике, с которым знаком каждый программист, к алгоритму, который мы имеем в виду, когда говорим о сортировке, без каких-либо мыслей об алгоритмах. Этот алгоритм называется быстрой сортировкой; он был разработан C.E.P. (Toni) Xoap в 1961 году [5].
Алгоритм быстрой сортировки, предложенный Хоар, снова использует тот факт, что для достижения наибольшей эффективности желательно выполнять обмен элементами на больших расстояниях.
Суть метода заключается в следующем. Мы найдем такой элемент массива, который разделит весь массив на два подмножества: те, которые меньше, чем разделяющий элемент, и те, которые не меньше его (то есть, сортируют один элемент по определение его конечного местоположения) [3].
Затем примените ту же процедуру к более коротким левому и правому подмножествам.
Таким образом, необходимо реализовать рекурсивный алгоритм, который сортирует элементы набора, начиная с элемента с индексом слева и заканчивая элементом с индексом справа. Условием завершения этого алгоритма является совпадение левой и правой границ подмножества (то есть, когда один элемент остается в подмножестве).
Точка разделения массива может быть определена следующим образом.
Введены два указателя i и j, и в начале i = слева, а j = вправо. I-й и j-й элементы сравниваются и, если обмен не требуется, тогда j = j + 1, и этот процесс повторяется, После первого обмена i увеличивается на единицу (i = i + 1), и сравнения продолжаются с увеличением i до следующего обмена. Затем снова уменьшайте j и т. Д. До тех пор, пока i = j. К моменту i = j элемент aj займет свою конечную позицию, так как не будет больше элементов слева и меньших элементов справа. Таким образом, проблема решена [6]. Демонстрация метода представлена на [рис. 7] в приложении.
Чтобы повысить эффективность быстрой сортировки, вы можете использовать следующую технику: без применения рекурсивной процедуры к подмножеству, которое стало коротким, для его сортировки переключитесь на другой метод, например, сортировку челноком. То есть рекурсивная процедура применяется только к массивам, длина которых не меньше определенного размера [6].
Общий анализ эффективности «быстрой» сортировки довольно сложен. Было бы лучше показать его вычислительную сложность, посчитав количество сравнений при некоторых идеальных допущениях. Предположим, что n является степенью двойки, n = 2k (k = log2n), и центральный элемент расположен точно посередине каждого списка и разбивает его на два подсписка примерно одинаковой длины [4].
Во время первого сканирования выполняется n-1 сравнение. В результате создаются два подсписка размером n / 2. На следующем этапе обработка каждого подсписка требует приблизительно n / 2 сравнений. Общее количество сравнений на этом этапе составляет 2 (n / 2) = n. На следующем этапе обрабатываются четыре подсписка, что требует 4 (n / 4) сравнений и т. Д. В конце процесс разделения заканчивается после k проходов, когда результирующие подсписки содержат по одному элементу за раз. Общее количество сравнений составляет примерно
n + 2 (n / 2) + 4 (n / 4) + ... + n (n / n) = n + n + ... + n = n * k = n * log2n
Для общего списка вычислительная сложность «быстрой» сортировки составляет O (n log2 n) [4].
Быстрая сортировка является наиболее эффективным алгоритмом из всех известных методов сортировки, но у всех улучшенных методов есть один общий недостаток - низкая скорость при малых значениях n.
3.2.4 Сравнение методов внутренней сортировки
Для простых методов сортировки, обсуждаемых в начале этой части, существуют точные формулы, вычисление которых дает минимальное, максимальное и среднее количество ключевых сравнений (C) и передач элементов массива (M). Таблица 1 в приложении содержит данные, приведенные в книге Никласа Вирта [2]
Нет точных формул для оценки сложности продвинутых методов сортировки. Известно только, что для сортировки по методу Шелла порядок C и M равен O (n (1.2)), а для методов быстрой сортировки, Heapsort и сортировки со слиянием - O (n log n). Тем не менее, результаты экспериментов показывают, что Quicksort показывает результаты, которые в 2-3 раза лучше, чем Heapsort (Таблица 2 показывает выборку результатов из таблицы, опубликованной в книге Wirth; результаты были получены при запуске программ, написанных на Modula-2) , По этой причине Quicksort обычно используется в стандартных утилитах сортировки (в частности, в утилите сортировки, поставляемой с операционной системой UNIX) [7].
4. Методы внешней сортировки
Обычно файлы сортировки, расположенные во внешней памяти, слишком велики, чтобы полностью перенести их в основную память и применить один из внутренних методов сортировки, описанных в предыдущем разделе. Чаще всего внешняя сортировка используется в системах управления базами данных при выполнении запросов, и производительность СУБД существенно зависит от эффективности используемых методов [1].
Следует уточнить, почему речь идет о последовательных файлах, то есть файлах, которые могут быть прочитаны запись за записью в последовательном режиме, и вы можете писать только после последней записи. Внешние методы сортировки появились, когда магнитные ленты были наиболее распространенными устройствами внешней памяти. Для лент чисто последовательный доступ был совершенно естественным. Когда произошел переход к устройствам хранения с магнитными дисками, обеспечивающими «прямой» доступ к любому блоку информации, казалось, что чисто последовательные файлы утратили свою актуальность. Однако это чувство было ошибочным [6].
Дело в том, что почти все используемые в настоящее время дисковые устройства оснащены подвижными магнитными головками. При замене с дисководом головки подаются в требуемый цилиндр, выбираются требуемые головки (дорожки), блок дисков прокручивается до начала требуемого блока и, наконец, блок считывается или записывается. Среди всех этих действий самое большое время - доставка голов. Это время определяет общее время операции. Единственный доступный метод оптимизации доступа к магнитным дискам - это «ближайшее» расположение на диске последовательно адресуемых файловых блоков. Но в этом случае движение головок будет минимизировано только тогда, когда файл будет прочитан или записан в чисто последовательном режиме. Именно с такими файлами современные СУБД работают с необходимостью сортировки [1].
Следует также отметить, что на самом деле скорость выполнения внешней сортировки зависит от размера буфера (или буферов) основной памяти, который можно использовать для этих целей. Рассмотрим основные методы внешней сортировки, работающие с минимальными затратами основной памяти [6].
4.1.Прямое слияние
Сортировка с слиянием, как правило, используется в тех случаях, когда требуется отсортировать последовательный файл, который не умещается полностью в основной памяти [3].
Предположим, что существует последовательный файл A, состоящий из записей a1, a2, ..., an (опять же, для простоты, предположим, что n - степень 2). Мы предполагаем, что каждая запись состоит только из одного элемента, который является ключом сортировки. Для сортировки используются два вспомогательных файла B и C (размер каждого из них будет n / 2).
Сортировка состоит из последовательности шагов, каждый из которых выполняет распределение состояния файла A по файлам B и C, а затем объединяет файлы B и C в файл A. На первом этапе файл A последовательно читается для распространения, и записи a1, a3, ..., a (n-1) записываются в файл B, а записи a2, a4, ..., an - в файл C (первоначальное распространение). Начальное объединение выполняется для пар (a1, a2), (a3, a4), ..., (a (n-1), an), и результат записывается в файл A. На втором этапе файл A снова читается последовательно, а файл B записывается последовательными парами с нечетными числами, а в файл C - с четными числами. При объединении упорядоченные четверки записей формируются и записываются в файл А. И так далее. Перед выполнением последнего шага файл A будет содержать две упорядоченные подпоследовательности размером n / 2 каждая. При распределении первый файл перейдет в файл B, а второй в файл C. После объединения файл A будет содержать полностью упорядоченную последовательность записей [5]. Таблица 3 в приложении показывает пример внешней сортировки путем простого слияния.
Обратите внимание, что для выполнения внешней сортировки с использованием метода прямого слияния необходимо разместить только две переменные в основной памяти - для размещения следующих записей из файлов B и C. Для файлов A, B и C будет O (logn) раз прочитал и столько раз написал [1].
4.2.Естественное слияние
При использовании метода прямого слияния не учитывается, что исходный файл может быть частично отсортирован, т.е. содержать упорядоченные подпоследовательности записей. Серия - это подпоследовательность записей a (i), a (i + 1), ..., a (j), такая, что a (k) <= a (k + 1) для всех i <= k <j, a (i) <a (i-1) и a (j)> a (j + 1). Метод естественного слияния основан на распознавании рядов при распределении и их использовании при последующем слиянии [1].
Как и в случае прямого слияния, сортировка выполняется в несколько этапов, каждый из которых сначала распределяет файл A в файлы B и C, а затем объединяет B и C в файл A. Распределение распознает первую серию записей и перезаписывает ее в файл B, второй находится в файле C и т. д. При слиянии первая серия записей файла B объединяется с первой серией файла C, вторая серия B - со второй серией C и так далее. Если просмотр одного файла заканчивается раньше, чем просмотр другого (из-за разного количества эпизодов), то оставшаяся часть незапрошенного файла копируется в конец файла A. Процесс заканчивается, когда в файле A остается только одна серия [3]. Пример сортировки файлов показан на [рисунках 8 и 9] в приложении.
Очевидно, что число операций чтения / перезаписи файлов с использованием этого метода будет не хуже, чем с помощью метода прямого слияния, и в среднем будет лучше. С другой стороны, число сравнений увеличивается за счет тех, которые необходимы для распознавания концов ряда. Кроме того, поскольку длина ряда может быть произвольной, максимальный размер файлов B и C может быть близок к размеру файла A [4].
4.3.Улучшение эффективности внешней сортировки за счет использования основной памяти
Понятно, что чем дольше серия содержит файл до начала применения внешней сортировки, тем меньше требуется слияний и тем быстрее заканчивается сортировка. Поэтому, прежде чем применять какой-либо из внешних методов сортировки, основанных на серии, исходный файл считывается по частям в основную память, один из наиболее эффективных алгоритмов внутренней сортировки (обычно Quicksort или Heapsort) применяется к каждой части и сортируется, части (образующие серию) записываются в новый файл (в старом не могут, потому что он чисто последовательный) [6].
Кроме того, конечно, при выполнении выделений и слияний используется буферизация блоков файла (ов) в основной памяти. Возможный прирост производительности зависит от наличия достаточного количества буферов достаточного размера [6].
Заключение
Проблема сортировки в программировании не решена полностью. Хотя существует большое количество алгоритмов сортировки, целью программирования является не только разработка алгоритмов сортировки элементов, но и разработка наиболее эффективных алгоритмов сортировки.
Рассмотренные в данной курсовой работе методы сортировки имеют как достоинства, так и недостатки. Выбор алгоритма сортировки зависит от конкретной задачи.
Таким образом, сортировка большого количества элементов пузырьковым методом, методом вставки или выделения займет много времени, поскольку время выполнения сортировки находится в квадратичной зависимости от количества элементов массива. Для больших объемов данных эти сортировки будут медленными, и, начиная с определенного значения, они будут слишком медленными для использования на практике. Тем не менее, они идеально подходят для сортировки небольшого количества предметов. Кроме того, сортировка по вкладышу имеет два преимущества. Во-первых, он имеет естественное поведение, то есть он работает быстрее для упорядоченного массива и длится дольше всего, когда массив упорядочен в противоположном направлении. Это делает сортировку вставками полезной для упорядочивания почти отсортированных массивов. Во-вторых, элементы с одинаковыми ключами не переставляются: если список элементов отсортирован с использованием двух ключей, то после завершения сортировки путем вставки он все равно будет упорядочен по двум ключам.
Наконец, некоторые из простых методов могут быть расширены до лучших методов или использованы для улучшения более сложных. Например, такой как метод Hoare и метод Shell.
Библиография
Книги:
-
Ахо, Альфред, В., Хопкрофт, Джон, Ульман, Джеффри, Д., Структура данных и алгоритмы: Пер. с англ.: Учебное пособие – М.: Издательский дом «Вильямс», 2000 г. – 384 с., илл.
-
Вирт Никлаус,Алгоритмы и структуры данных: Пер. с англ. – М.: Издательство ДМК пресс», 2013 г. – 272 с., илл.
-
Кнут Д. Э., Искусство программирования. Том 1. Основные алгоритмы. — СПб.: Вильямс, 2015. — 720 с.
-
Кнут Д. Э. Искусство программирования, Том 3. Сортировка и поиск. — М.: Издательский дом «Вильямс», 2010.
-
Луридас, Панос, Алгоритмы для начинающих: теория и практика для разработчика – М., Издательство ЭКСМО», 2018 г. – 608 с., илл.
-
Томас, X. Кормен, Чарльз И. Лейзерсон, Алгоритмы. Построение и анализ. — СПб.: Вильямс, 2016. — 1328 с.
Статьи:
- Антонова И. И., Карих О. А. Оценка эффективности параллельных алгоритмов задачи сортировки данных // Промышленные АСУ и контроллеры. — 2010. — № 3. — С. 23—25.
- Дупленко A. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — № 8. — С. 50-53.
- Мартынов В.А., Миронов В.В. Параллельные алгоритмы сортировки данных с использованием технологии MPI // Вестник Сыктывкарского университета. Серия 1: Математика. Механика. Информатика. — 2012. — № 16. — С. 130-135.
- Никитин Ю. Б. Сложность алгоритмов сортировки на частично упорядоченных множествах: автореферат дис.... канд. физ.-мат. наук: 01.01.09 / Никитин Юрий Борисович. — Москва, 2001. — 80 с.
Приложения

Рис.1. Демонстрация сортировки по неубыванию методом «пузырька»
|
До |
После |
Описание шага |
|
Первый проход (проталкиваем второй элемент — 2) |
||
|
5 2 4 3 1 |
2 5 4 3 1 |
Алгоритм сравнивает второй элемент с первым и меняет их местами. |
|
Второй проход (проталкиваем третий элемент — 4) |
||
|
2 5 4 3 1 |
2 4 5 3 1 |
Сравнивает третий со вторым и меняет местами |
|
2 4 5 3 1 |
2 4 5 3 1 |
Второй и первый отсортированы, обмен не требуется |
|
Третий проход (проталкиваем четвертый — 3) |
||
|
2 4 5 3 1 |
2 4 3 5 1 |
Меняет четвертый и третий местами |
|
2 4 3 5 1 |
2 3 4 5 1 |
Меняет третий и второй местами |
|
2 3 4 5 1 |
2 3 4 5 1 |
Второй и первый отсортированы, обмен не требуется |
|
Четвертый проход (проталкиваем пятый элемент — 1) |
||
|
2 3 4 5 1 |
2 3 4 1 5 |
Меняет пятый и четвертый местами |
|
2 3 4 1 5 |
2 3 1 4 5 |
Меняет четвертый и третий местами |
|
2 3 1 4 5 |
2 1 3 4 5 |
Меняет третий и второй местами |
|
2 1 3 4 5 |
1 2 3 4 5 |
Меняет второй и первый местами. Массив отсортирован. |
Рис.2. Демонстрация сортировки вставками по неубываниюдля массива [5,2,4,3,1]

Рис.3. Демонстрация сортировки по неубыванию методом простого выбора
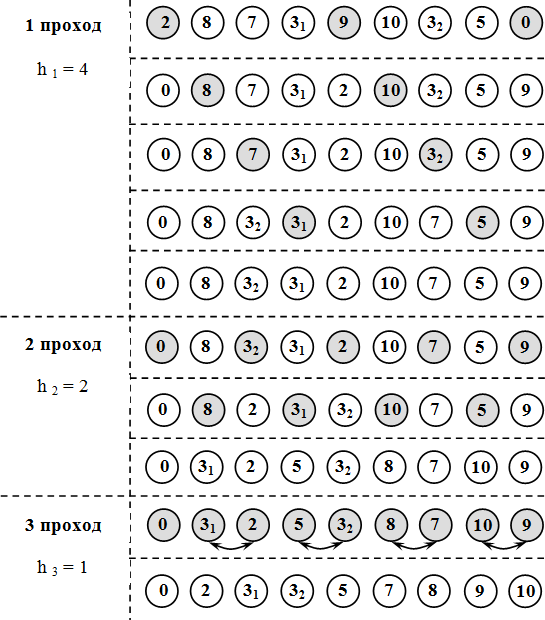
Рис.4. Демонстрация сортировки по неубыванию методом Шелла
Рис.5. Древовидное представление массива
Рис.6. Сортировка с помощью пирамиды
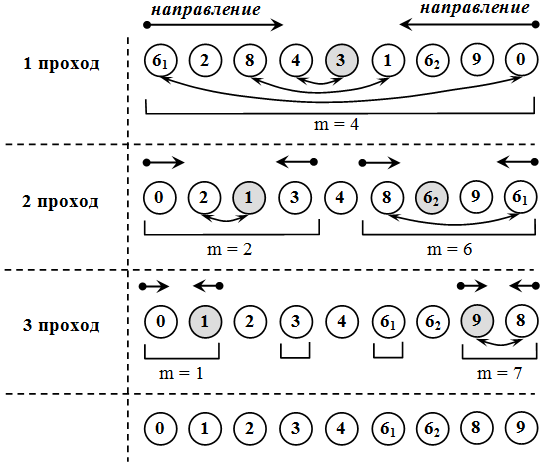
Рис.7. Демонстрация быстрой сортировки Хоара по неубыванию
|
Min |
Avg |
Max |
|
|
Прямое включение |
C = n-1 M = 2x(n-1) |
(n2 + n - 2)/4 (n2 - 9n - 10)/4 |
(n2 -n)/2 - 1 (n2 -3n - 4)/2 |
|
Прямой выбор |
C = (n2 - n)/2 M = 3x(n-1) |
(n2 - n)/2 nx(ln n + 0.57) |
(n2 - n)/2 n2/4 + 3x(n-1) |
|
Прямой обмен |
C = (n2 - n)/2 M = 0 |
(n2 - n)/2 (n2 - n)x0.75 |
(n2 - n)/2 (n2 - n)x1.5 |
Таблица 1. Характеристики простых методов сортировки
|
Метод сортировки |
Упорядоченный массив |
Случайный массив |
В обратном порядке |
|
n = 256 |
|||
|
Heapsort Quicksort Сортировка со слиянием |
0.20 0.20 0.20 |
0.08 0.12 0.08 |
0.18 0.18 0.18 |
|
n = 2048 |
|||
|
Heapsort Quicksort Сортировка со слиянием |
2.32 2.22 2.12 |
0.72 1.22 0.76 |
1.98 2.06 1.98 |
Таблица 2. Время работы программ сортировки
|
Начальное состояние файла A |
8 23 5 65 44 33 1 6 |
|
Первый шаг Распределение Файл B Файл C Слияние: файл A |
8 5 44 1 23 65 33 6 8 23 5 65 33 44 1 6 |
|
Второй шаг Распределение Файл B Файл C Слияние: файл A |
8 23 33 44 5 65 1 6 5 8 23 65 1 6 33 44 |
|
Третий шаг Распределение Файл B Файл C Слияние: файл A |
5 8 23 65 1 6 33 44 1 5 6 8 23 33 44 65 |
Таблица 3. Пример внешней сортировки прямым слиянием
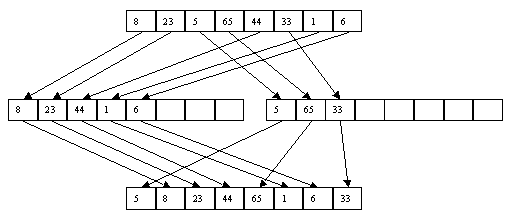
Рис.8. Первый шаг
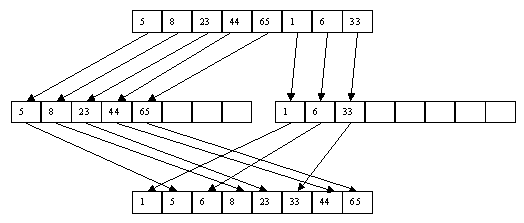
Рис.9. Второй шаг

- «Американизмы в английском языке» (Американский английский как исторически сложившаяся языковая система)
- Алгоритмы сортировки данных (Теоретические основы алгоритмов сортировки данных)
- «Органы государственного управления» (Государственный механизм реализации принципа разделения властей)
- Изменение и расторжение договора
- Стили руководства организацией
- «Легальность и легитимность» (Легальность и легитимность в теории государства и права)
- Счета и двойная запись ( Система счетов бухгалтерского учета как способ классификации первичной информации)
- Учет поступления основных средств (Теоретические основы учета основных средств организации)
- Сравнительный анализ особенностей систем мотивации различных категорий персонала в российских и зарубежных компаниях. (Мотивация труда как элемент процесса управления персоналом на предприятии)
- Формы и системы оплаты труда на предприятии (Трактовка заработной платы)
- Оценка готовности детей к школе (Общение ребенка со сверстниками)
- «Адаптация ребенка к школе» (Проблема адаптации детей к школе в психолого-педагогической литературе)