
Методы сортировки данных: эволюция и сравнительный анализ. Примеры использования ( Классы методов сортировки )
Содержание:

ВВЕДЕНИЕ
Актуальность темы. Базы данных могут содержать сотни и тысячи записей. Часто бывает необходимо их упорядочить, т. е. расположить в определенной последовательности. Упорядочение записей называется сортировкой. Сортировка записей производится по какому-либо полю базы данных. Значения, содержащиеся в этом поле, располагаются в порядке возрастания или убывания. В процессе сортировки целостность записей сохраняется, т. е. строки таблицы перемещаются целиком. Сортировка – один из важнейших аспектов обработки данных, позволяющий ускорить и упростить этот наиважнейший в области вычислительной техники процесс.
Цель курсовой работы – анализ сортировки данных.
Для достижения поставленной цели необходимо решить следующие задачи:
- рассмотретьосновные классы методов сортировки;
- исследоватьсортировку подсчетом;
- рассмотретьсортировку вставками;
- изучить обменную сортировку;
- представитьсортировку посредством выбора;
- рассмотреть шаблоны функций с++;
- представить теоретическое обоснование метода;
- реализовать алгоритм;
- провести тестирование алгоритма;
- представить итоги анализа алгоритма.
Создание системы сортировки данных в значительной степени сэкономит ресурсы ЭВМ, затрачиваемые на обработку данных, сделает более рациональным использование оперативной памяти при обращении к большим массивам данных.
1 . Классы методов сортировки
1.1 Основные классы методов сортировки
В настоящее время существует огромное количество самых различных способов сортировки. Все они являются методами внутренней или внешней сортировки. Внутренней сортировкой называется сортировка, при которой все количество сортируемых записей помещается в оперативной памяти, а внешней – когда в оперативной памяти невозможно разместить все записи. Внутренняя сортировка позволяет создавать более гибкие и, следственно более выгодные методы сортировки. Методы же внешней сортировки зачастую основаны на методах внутренней, с тем лишь различием, что в них внесены некоторые дополнительные шаги. Поэтому мы не будем останавливаться на внешней сортировке и рассмотрим основные классы методов внутренней сортировки.
Все методы можно разделить на четыре основных класса:
- Сортировка вставками;
- Сортировка подсчетом;
- Обменная сортировка;
- Сортировка посредством выбора. [5, с.76]
Эти классы включают в себя все множество методов внутренней сортировки, а также все множество всех известных на сегодняшний день их усовершенствований. Причем стоит отметить, что нельзя провести четкую грань между этими классами: методы сортировки очень тесно взаимосвязаны и похожи друг на друга, что создает определенные связи между классами методов. Остановимся более подробно на этих классах.
1.2 Сортировка подсчетом
При сортировке методом подсчета упорядоченная последовательность элементов создается на свободном участке памяти. Идея метода заключается в следующем: в отсортированной последовательности, элемент, занимающий позицию с номером К+1, превышает ровно К элементов, поэтому в процессе сортировки методом подсчета на каждом i-ом проходе мы попарно сравниваем i-й элемент со всеми элементами массива. Если установлено, что mass[i] > mass[j], то увеличиваем счетчик К на единицу (в начале К = 0). По окончании текущего прохода счетчик К указывает количество элементов, меньших, чем mass[i], поэтому элемент mass[i] занимает в отсортированной последовательности позицию К + 1 (sortedMass[k + 1] = mass[i])[3, с.84].
Внимание. Рассмотренный алгоритм можно использовать только для последовательностей, которые не содержат одинаковых элементов! Для сортировки последовательностей, содержащих одинаковые элементы, алгоритм необходимо модифицировать.
Приведем реализацию алгоритма сортировки методом подсчета на языке программирования Си. Необходимо учесть, что в языке Си нумерация элементов массива начинается с нуля.
//сортировкаметодомподсчета
void methodOfCalculation(int n, int mass[], int sortedMass[])
{
int k;
for (int i = 0; i < n; i++)
{
k = 0;
for (int j = 0; j < n; j++)
{
if (mass[i] > mass[j])
k++;
}
sortedMass[k] = mass[i];
}
}
Ниже находится пример консольной программы на языке программирования Си, которая считывает исходную последовательность, сортирует ее методом подсчета и выводит отсортированный массив на экран.
#include <stdio.h>
#include <malloc.h>
#include <conio.h>
//сортировка методом подсчета
void methodOfCalculation(int n, int mass[], int sortedMass[])
{
int k;
for (int i = 0; i < n; i++)
{
k = 0;
for (int j = 0; j < n; j++)
{
if (mass[i] > mass[j])
k++;
}
sortedMass[k] = mass[i];
}
}
int main()
{
//ввод N
int N;
printf("Input N: ");
scanf_s("%d", &N);
//выделение памяти под массивы
int *mass, *sortedMass;
mass = (int *)malloc(N * sizeof(int));
sortedMass = (int *)malloc(N * sizeof(int));
//вводэлементовмассива
printf("Input the array elements:\n");
for (int i = 0; i < N; i++)
scanf_s("%d", &mass[i]);
//сортировкаметодомподсчета
methodOfCalculation(N, mass, sortedMass);
//вывод отсортированного массива на экран
printf("Sorted array:\n");
for (int i = 0; i < N; i++)
printf("%d ", sortedMass[i]);
printf("\n");
//освобождениепамяти
free(mass);
free(sortedMass);
_getch();
return 0;
}
Демонстрация работы программы приведена на скриншоте:
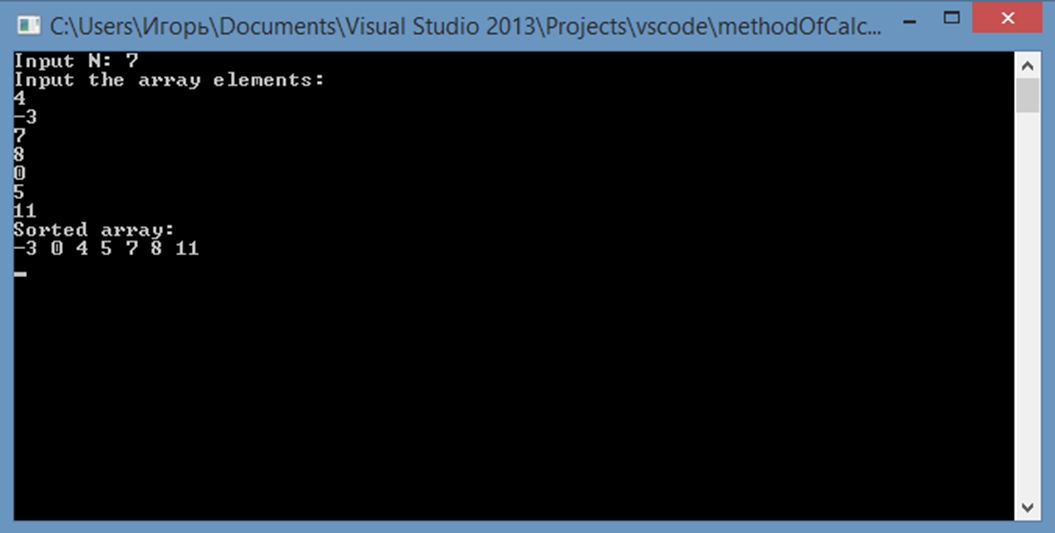
Рисунок 1 - Демонстрация работы программы
1.3 Сортировка вставками
Общая суть сортировок вставками такова:
- Перебираются элементы в неотсортированной части массива.
- Каждый элемент вставляется в отсортированную часть массива на то место, где он должен находиться[8, с.95].
То есть, сортировки вставками всегда делят массив на 2 части — отсортированную и неотсортированную. Из неотсортированной части извлекается любой элемент. Поскольку другая часть массива отсортирована, то в ней достаточно быстро можно найти своё место для этого извлечённого элемента. Элемент вставляется куда нужно, в результате чего отсортированная часть массива увеличивается, а неотсортированная уменьшается
Самое слабое место в этом подходе — вставка элемента в отсортированную часть массива. На самом деле это непросто и на какие только ухищрения не приходится идти, чтобы выполнить этот шаг[1, с.17]
Проходим по массиву слева направо и обрабатываем по очереди каждый элемент. Слева от очередного элемента наращиваем отсортированную часть массива, справа по мере процесса потихоньку испаряется неотсортированная. В отсортированной части массива ищется точка вставки для очередного элемента. Сам элемент отправляется в буфер, в результате чего в массиве появляется свободная ячейка — это позволяет сдвинуть элементы и освободить точку вставки.
definsertion(data):
for i in range(len(data)):
j = i - 1
key = data[i]
while data[j] > key and j >= 0:
data[j + 1] = data[j]
j -= 1
data[j + 1] = key
return data
На примере простых вставок показательно смотрится главное преимущество большинства сортировок вставками, а именно — очень быстрая обработка почти упорядоченных массивов:
При таком раскладе даже самая примитивная реализация сортировки вставкам, скорее всего, обгонит супер-оптимизированный алгоритм какой-нибудь быстрой сортировки, в том числе и на больших массивах.
Этому способствует сама основная идея этого класса — переброска элементов из неотсортированной части массива в отсортированную. При близком расположении близких по величине данных место вставки обычно находится близко к краю отсортированной части, что позволяет вставлять с наименьшими накладными расходами.
Нет ничего лучше для обработки почти упорядоченных массивов чем сортировки вставками. Когда где-то встречается информация, что лучшая временная сложность сортировки вставками равна O(n), то, скорее всего, имеются в виду ситуации с почти упорядоченными массивами.
Сортировка простыми вставками с бинарным поиском. Так как место для вставки ищется в отсортированной части массива, то идея использовать бинарный поиск напрашивается сама собой[9, с.43]. Другое дело, что поиск места вставки не является критичным для временно́й сложности алгоритма (главный пожиратель ресурсов — этап самой вставки элемента в найденную позицию), поэтому данная оптимизация здесь мало что даёт.
А в случае почти отсортированного массива бинарный поиск может работать даже медленнее, поскольку он начинает с середины отсортированного участка, который, скорее всего, будет находиться слишком далеко от точки вставки (а на обычный перебор от позиции элемента до точки вставки уйдёт меньше шагов, если данные в массиве в целом упорядочены).
definsertion_binary(data):
for i in range(len(data)):
key = data[i]
lo, hi = 0, i - 1
while lo < hi:
mid = lo + (hi - lo) // 2
if key < data[mid]:
hi = mid
else:
lo = mid + 1
for j in range(i, lo + 1, -1):
data[j] = data[j - 1]
data[lo] = key
return data
В защиту бинарного поиска отмечу, что он может сказать решающее слово в эффективности других сортировок вставками. Благодаря ему, в частности, на среднюю сложность по времени O(n log n)выходят такие алгоритмы как сортировка библиотекаря и пасьянсная сортировка.
Парная сортировка простыми вставками. Модификация простых вставок, разработанная в тайных лабораториях корпорации Oracle. Эта сортировка входит в пакет JDK, является составной частью Dual-Pivot Quicksort. Используется для сортировки малых массивов (до 47 элементов) и сортировки небольших участков крупных массивов[9, с.44]
В буфер отправляются не один, а сразу два рядом стоящих элемента. Сначала вставляется больший элемент из пары и сразу после него метод простой вставки применяется к меньшему элементу из пары.Что это даёт? Экономию для обработки меньшего элемента из пары. Для него поиск точки вставки и сама вставка осуществляются только на той отсортированной части массива, в которую не входит отсортированная область, задействованная для обработки большего элемента из пары. Это становится возможным, поскольку больший и меньший элементы обрабатываются сразу друг за другом в одном проходе внешнего цикла[3, с.101]
На среднюю сложность по времени это не влияет (она так и остаётся равной O(n2)), однако парные вставки работают чуть быстрее чем обычные.
Алгоритмы иллюстрируем на Python, но тут приведу первоисточник (видоизменённый в целях читабельности) на Java:
for (int k = left; ++left <= right; k = ++left) {
//Очередную пару рядом стоя́щих элементов
//заносим в пару буферных переменных
int a1 = a[k], a2 = a[left];
if (a1 < a2) {
a2 = a1; a1 = a[left];
}
//Вставляем больший элемент из пары
while (a1 < a[--k]) {
a[k + 2] = a[k];
}
a[++k + 1] = a1;
//Вставляем меньший элемент из пары
while (a2 < a[--k]) {
a[k + 1] = a[k];
}
a[k + 1] = a2;
}
//Граничный случай, если в массиве нечётное количество элементов
//Для последнего элемента применяем сортировку простыми вставками
int last = a[right];
while (last < a[--right]) {
a[right + 1] = a[right];
}
a[right + 1] = last;
1.4 Обменная сортировка
Если описать в паре предложений по какому принципу работают сортировки обменами, то:
1. Попарно сравниваются элементы массива
2. Если элемент слева больше элемента справа, то элементы меняются местами
3. Повторяем пункты 1-2 до тех пор, пока массив не отсортируется.
Традиционно к «обменникам» относят сортировки, в которых элементы меняются (псевдо)случайным образом (bogosort, bozosort, permsort и т.п.).
defstooge_rec(data, i = 0, j = None):
if j isNone:
j = len(data) - 1
if data[j] < data[i]:
data[i], data[j] = data[j], data[i]
if j - i >1:
t = (j - i + 1) // 3
stooge_rec(data, i, j - t)
stooge_rec(data, i + t, j)
stooge_rec(data, i, j - t)
return data
defstooge(data):
return stooge_rec(data, 0, len(data) - 1)
Еще один весьма привлекательных метод обменной сортировки был предложен в 1964 году К.Э. Бэтчером. Его метод далеко не очевиден. В сравнение с методом пузырька он направлен на то, чтобы избежать, казалось бы, неизбежного, а именно того, чтобы число сравнений в алгоритме было равно числу инверсий в исходном файле. Для этого Бетчером был предложен алгоритм поиска возможных сравнений. По сути, этот алгоритм производит сортировку отдельных подпоследовательностей и дальнейшее их слияние. Поэтому такой метод получил название обменной сортировкой со слиянием. С одной стороны, эффективность этого алгоритма не велика, но все недостатки компенсируются одним аспектом – этот алгоритм позволяет извлекать большую выгоду на машинах, позволяющих проводить параллельные вычисления. То есть можно параллельно отсортировать несколько подфайлов, а затем выполнить слияние. Поэтому этот метод также известен как алгоритм параллельной сортировки Бутчера.
1.5 Сортировка посредством выбора
Наконец рассмотрим еще один важный класс методов внутренней сортировки. Идея методов этого класса основана на многократном выборе одного элемента. Простейший алгоритм метода сортировки посредством выбора очевидно представить таким образом:
1. Выбрать наименьший элемент, переслать его в область вывода и заменить значение его ключа на ∞ (значение большее всех имеющихся ключей)
2. Повторять шаг 1 до тех пор, пока все элементы не будут выбраны.
Очевидно, для реализации такого алгоритма требуется присутствие всех сортируемых элементов в области видимости, предварительный поиск максимального ключа, а также дополнительную область памяти для вывода. Но есть очевидный способ упростить описанный алгоритм без использования ∞ и выделения дополнительной области в памяти для последовательного вывода выбранных элементов: для этого выбранный элемент можно переставить в начальную позицию, а элемент из начальной позиции на позицию выбранного[9, с.19]. Таким образом, с каждым шагом необходимо уменьшать рассматриваемую последовательность, отделяя от нее первый элемент. Рассмотрим теперь алгоритм сортировки посредством простого выбора, описанный выше:
D_1. [цикл по j] Выполнить шаги D_2, D_3 при j = 1 .. N
D_2. Найти наименьший из ключей, пусть это будет
D_3. Взаимозаменить и
Скорость работы этого алгоритма можно представить формулой.
 (1)
(1)
Как видно, она лишь немного меньше скорости выполнения алгоритма простых вставок. Этот алгоритм отличает его простота и очевидность, а также то, что способы его усовершенствовать весьма ограничены. Конечно, существует весьма простой способ улучшения алгоритма простого выбора: разбить сортируемый массив на несколько частей. Мы еще поговорим об этом в главе 2.
1.6 Шаблоны функций с++
Механизм шаблонов в С++ позволяет избежать те препятствия, которые создает сильная типизация этого языка при создании функций и классов, которые применимы к различным типам параметров. В нашем случае необходимо рассмотреть использование шаблонов функций, которое понадобиться нам для реализации выбранного нами алгоритма сортировки.
Создание шаблона функции – это создание алгоритма, который автоматически генерирует различные экземпляры функций для различных типов параметров. Для этого программист должен параметризировать те типы параметров и возвращаемых значений, которые должны изменяться. При этом тело функции остается неизменным. Очевидно, что на роль шаблона лучше всего подходит функция, реализация которой остается инвариантной на некотором множестве экземпляров, различающихся типами данных[6, с.87]. Таквыглядитобъявлениешаблона.
template <class Type>
Type [function name] (Type [parametr1].. [parametrN]) {body}
В данном случае введен тип-параметр Type. Компилятор, в зависимости от того, параметры какого типа будут подставлены в функцию, интерпретирует ее так или иначе. Шаблон может быть конкретизирован или, как иногда говорят инстанцирован, для любого встроенного или определенного пользователем типа. Имя типа-параметра, использованное программистом в объявлении шаблона, может быть использовано как имя обычного типа, например, для объявления переменных.
Для реализации алгоритма сортировки будем использовать шаблон функции, принимающий в качестве параметров адрес первого элемента сортируемого массива, а также размер этого массива в качестве параметра-константы.
template<class TypeName, int size >
void sort( TypeName (&array)[size] ){ // телофункции }
Недостатком такого подхода будет то, что для двух массивов из элементов одного и того же типа, но разных размеров, при подстановке этих массивов в нашу функцию компилятором будут сгенерированы различные экземпляры этой функции. Но тем не менее механизм шаблонов в С++ не имеет альтернативы в использовании для обобщения функций с несколькими параметрами.
2 . Анализ выбранного метода
2.1 Теоретическое обоснование метода
Вновь возвращаемся к алгоритму D, рассмотренному в разделе 1.5:
D_1. [цикл по j] Выполнить шаги D_2, D_3 при j = 1 .. N
D_2. Найти наименьший из ключей  , пусть это будет
, пусть это будет 
D_3. Взаимозаменить  и
и 
Очевидно, время выполнения этого алгоритма зависит от числа элементов N, числа сравнений C, и числа «правосторонних минимумов» M. Число сравнений в данном алгоритме не зависит от значений ключей и равно:
 (2.1)
(2.1)
Число М будет переменной величиной:
 (2.2)
(2.2)
Исходя из этого среднее время выполнения такого алгоритма:
 (2.3)
(2.3)
Иначе можно ссылаться на порядок числа пересылок. В худшем случае оно равно  , в то время как средний порядок числа пересылок равен
, в то время как средний порядок числа пересылок равен . Это показывает, что метод простого выбора выгоден, несмотря на свою неизысканность, что выделяет его из ряда прочих методов внутренней сортировки.
. Это показывает, что метод простого выбора выгоден, несмотря на свою неизысканность, что выделяет его из ряда прочих методов внутренней сортировки.
Далее рассмотрим способы усовершенствования метода простого выбора. Обратимся снова к алгоритму D. Рассмотрим для начала его второй шаг. Можно ли каким-либо образом усовершенствовать способ поиска минимума? В общем – нет. В любом алгоритме поиска минимума, основанном на сравнении пар, необходимо выполнить как минимум n-1 сравнений. Значит ли это, что скорость выполнения алгоритма, основанного на сравнении пар, будет пропорциональна  ? В общем – нет. По крайней мере, в нашем алгоритме имеется еще и вторая часть. И даже простое ее усовершенствование приведет к ощутимому результату. Рассмотрим, например, последовательность из 16 чисел, которую необходимо отсортировать (рис. 1).
? В общем – нет. По крайней мере, в нашем алгоритме имеется еще и вторая часть. И даже простое ее усовершенствование приведет к ощутимому результату. Рассмотрим, например, последовательность из 16 чисел, которую необходимо отсортировать (рис. 1).

Рис. 2. Пример сортировки улучшенным методом выбора
Проведем довольно простое усовершенствование: разобьем 16 чисел на четыре группы, по четыре числа в каждой. Теперь поиск минимума будет производиться для каждой группы. После этого поиск минимума происходит среди минимальных элементов каждой из групп. На следующем шаге цикла требуется повторить поиск минимума уже только в одной группе и сравнить его с уже имеющимися элементами из других групп; и так далее до того, пока не останется элементов для сравнения. Конечно, этот способ требует более сложного алгоритма и дополнительной памяти для области вывода. Но, если N – точный квадрат, то массив разбивается на √N групп, по √N элементов в каждой. Таким образом, каждый выбор (кроме первого) требует √N-1 сравнений, плюс √N-1 сравнений среди наименьших элементов групп. Тогда скорость работы алгоритма получается порядка O(N√N), что в сравнении с  гораздо предпочтительней.
гораздо предпочтительней.
Такой метод был назван метод квадратичного выбора и впервые был опубликован в 1956 году Э.Х. Френдом. Автор обобщил эту идею и описал возможность создания метода кубического выбора (массив делится на  групп, по
групп, по  подгрупп с
подгрупп с  элементами), выбора четвертой степени и т. д. Итак, Френд пришел к выбору n-ой степени, который отражается в методе выбора из бинарного дерева.
элементами), выбора четвертой степени и т. д. Итак, Френд пришел к выбору n-ой степени, который отражается в методе выбора из бинарного дерева.
Этот весьма любопытный метод напоминает систему турнира на выбывание. Для определения минимального элемента при представлении сортировки в виде дерева происходит за  сравнений. А для определений минимума из оставшихся с каждым шагом требуется не более
сравнений. А для определений минимума из оставшихся с каждым шагом требуется не более  сравнений. Итого суммарная скорость выполнения алгоритма будет равна приблизительно
сравнений. Итого суммарная скорость выполнения алгоритма будет равна приблизительно  . Но с другой стороны для реализации такого метода потребуется дополнительный массив с индексами вышедших вверх элементов после каждого круга сравнений, так как та запись, в которой он располагался до этого, будет заменена на бесконечность; к тому же потребуется и дополнительная область вывода. Таким образом, встает вопрос: можно ли обойтись без замены элементов на бесконечности и тем самым избежать довольно больших затрат памяти? Решением этого вопроса является метод, представленный ниже.
. Но с другой стороны для реализации такого метода потребуется дополнительный массив с индексами вышедших вверх элементов после каждого круга сравнений, так как та запись, в которой он располагался до этого, будет заменена на бесконечность; к тому же потребуется и дополнительная область вывода. Таким образом, встает вопрос: можно ли обойтись без замены элементов на бесконечности и тем самым избежать довольно больших затрат памяти? Решением этого вопроса является метод, представленный ниже.
Пирамидальная сортировка основана на последовательной перестройке исходного массива в пирамиду таким образом, что на вершине находится наибольший элемент. Сам метод был придуман Дж. У. Дж. Уильямсом в 1964 году. Эффективную его реализацию предложил Р. У. Флойд в том же году. Предложенный им алгоритм преобразует исходный файл в пирамиду, а затем многократно исключает вершину, расставляя элементы в соответствующем порядке. Этот алгоритм очень громоздок и в то же время довольно изыскан. Скорость его работы оценивается в среднем формулой (2.3):
 , (2.4)
, (2.4)
- что не лучше скорости алгоритмов Шелла и быстрой сортировки. Но в отличие от прочих быстрых алгоритмов, в которых худшее значенье скорости достигает  , скорость алгоритма пирамидальной сортировки всегда будет не больше
, скорость алгоритма пирамидальной сортировки всегда будет не больше  , что делает этот алгоритм очень выгодным для сортировки массивов с большим числом инверсий. На этом перейдем к реализации выбранного нами алгоритма сортировки.
, что делает этот алгоритм очень выгодным для сортировки массивов с большим числом инверсий. На этом перейдем к реализации выбранного нами алгоритма сортировки.
2.2 Реализация алгоритма
Для реализации алгоритма сортировки посредством простого выбора (алгоритм D) мы будем использовать язык программирования C++. Для этого составим блок-схему нашего алгоритма с использованием цикла с заданным числом повторений (рис 2). Данный алгоритм будет сортировать массив array, размера size в порядке неубывания. Для реализации алгоритма потребуется использовать один вложенный цикл, реализующий поиск минимума. Как видно на схеме этот цикл (блок 5) производит поиск минимума только среди элементов, которые еще не были выбраны – это позволяет избежать замены выбранных элементов на бесконечность. Блок 7 реализует перестановку выбранного минимума с первым элементом рассматриваемого подмассива. На следующем шаге главного цикла происходит установка счетчика count на элемент вперед и инициализация переменной min значением из подмассива, огражденного слева элементом массива с индексом, соответствующим значению счетчика.
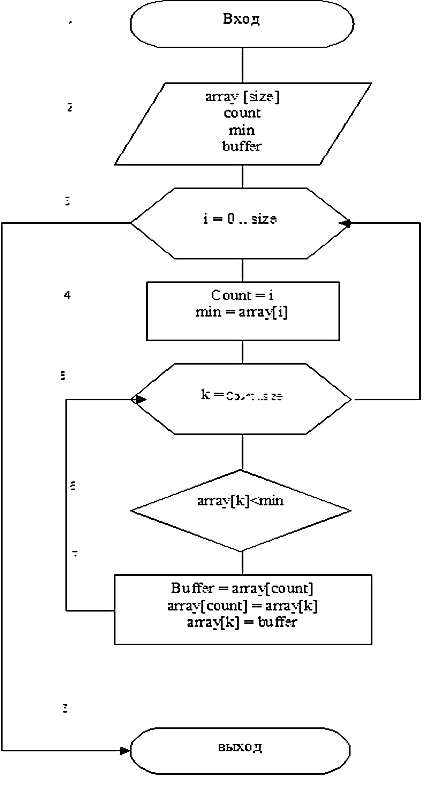
Рис.3. Блок-схема алгоритма сортировки посредством простого выбора
Теперь перейдем непосредственно к кодированию этого алгоритма на языке C++ с помощью компилятора C++Builder 6. Для реализации тестирования нашего алгоритма необходимо использовать шаблон функции С++. Реализация такого шаблона представлена в программе 1.
Программа 1.
#include<stdio.h> // подключение модулей
#include <dos.h> // ……………..
#include <time.h> // ……………..
template<class Type, int size >// объявлениешаблона
int sort( Type (&array)[size] ) // объявлениефункции
{
struct time t; // объявление переменной типа time
int t1, t2, ti; // объявление переменных для расчета времени
работы цикла 1
gettime( &t ); // возвращение системного времени
t1 = t.ti_hund; // запись сотых долей секунды системного времени в
переменную t1
int k = 0, j = 0; // объявление счетчика
Type min = array[0], buf; // объявление переменных для поиска
минимума и перестановки элементов
for( intx = 0; x<size; ++x ){ // цикл 1
k = x; // установка счетчика
min = array[x]; // установка нового значения минимума
for( int i = x+1; i < size; ++i ) // цикл 2 для поиска минимума в
массиве
if( min >= array[i] ){
min = array[i];
j = i; // запоминание позиции минимума в массиве
}
buf = array[k]; // перестановка минимума на позицию k
array[k] = array[j]; // ...................
array[j] = buf; // ...................
}
gettime( &t ); // получение системного времени
t2 = t.ti_hund; // запись сотых долей секунды
системного времени в переменную t2
ti = abs( t2 -t1 ); // вычисление времени выполнения цикла 1
return ti;
}
Как можно заметить, данная программа расходится с блок-схемой реализуемого алгоритма. Если внимательно рассмотреть блок-схему, то можно увидеть, что поиск минимума и его перестановка происходят во вложенном цикле. В нашей программе в этом цикле реализуется только поиск минимума, запоминание его значения и позиции. То есть выполняется не три операции присваивания, как в блок-схеме, а только две. При большом числе инверсий и количестве сортируемых элементов это может сильно повлиять на время сортировки.
Функция sort будет не только сортировать массив, но и возвращать время сортировки в формате сотых долей секунды. Поэтому для проведения тестирования алгоритма далее в программе 2 с помощью функции main будем конкретизировать шаблон.
Программа 2.
#include <iostream.h>
#include <string.h>
#include <math.h>
int main()
{
// задание переменных для вычисления среднего времени
intinttime[15];
floatavtime = 0;
// задание размера сортируемого массива
constintsize = 100;
// заполнение массива целых чисел
int ia[size];
for(int x = 0; x < size; ++x ){
randomize();
ia[x] = random( 100 );
}
// конкретизация шаблона для массива типа int
cout << "sort time for ia[" << size << "] { ";
for(int x = 0; x < 15; ++x ){
inttime[x] = sort( ia );
cout << inttime[x] << " ";
avtime = avtime + inttime[x];
}
cout << "} average time: " << avtime/15 << endl;
float fa[size];
for(int x = 0; x < size; ++x ){
randomize();
fa[x] = log( random( 100 ) + 1 );
}
// конкретизация шаблона для массива типа float
avtime = 0;
cout << "sort time for fa[" << size << "] { ";
for (int x = 0; x < 15; ++x ){
inttime[x] = sort( fa );
cout << inttime[x] << " ";
avtime = avtime + inttime[x];
}
cout << "} average time: " << avtime/15 << endl;
char ca[size];
for (int x = 0; x < size; ++x ){
randomize();
ca[x] = random( 64 ) + 62;
}
// конкретизация шаблона для массива типа char
avtime = 0;
cout << "sort time for ca[" << size << "] { ";
for (int x = 0; x < 15; ++x ){
inttime[x] = sort( ca );
cout << inttime[x] << " ";
avtime = avtime + inttime[x];
}
cout << "} average time: " << avtime/15 << endl;
string sa[size];
string samp = "deathisjustanotherpathonethatweallhavetotake";
int bag, fag;
string dag = "int";
for ( int x = 0; x < size; ++x ) {
bag = random( 44 );
fag = random( 44 );
sa[x] = dag + samp[bag] + samp[fag];
}
// конкретизация шаблона для массива типа string
avtime = 0;
cout << "sort time for sa[" << size << "] { ";
for (int x = 0; x < 15; ++x ){
inttime[x] = sort( sa );
cout << inttime[x] << " ";
avtime = avtime + inttime[x];
}
cout << "} average time: " << avtime/15 << endl;
cin.get();
return 0;
}
//---------------------------------------------------------------------------
2.3 Тестирование алгоритма
В данном разделе приступим к тестированию алгоритма. Для этого вновь обратимся к уже полученным формулам скорости выполнения алгоритма и попытаемся сопоставить полученные путем эксперимента данные с теоретическим обоснованием нашего алгоритма.
Как мы отмечали, среднее время выполнения такого алгоритма составляет порядка. Также мы ссылались на число пересылок и отмечали, что его максимальное значение может быть порядка. И будем опираться на то, что зависимость скорости выполнения практически всех простых алгоритмов внутренней сортировки, которые можно считать рациональными, при большом количестве сортируемых элементов стремиться к порядку.
Путем варьирования константы size будем получать различные значения функции sort. Определив константу size значение 100, получим выведенное на консоль среднее из пятнадцати значений время сортировки для массивов различного типа (рис 4).

Рис.4. Консоль вывода времени сортировки
Как видно 100 это слишком малое количество записей в массиве, поэтому в дальнейшем будем увеличивать это значение, начиная с 0 с шагом в 500. Запуская программу для каждого размера массива и выбирая среднее из полученных значений времени, получили следующую таблицу данных.
Таблица 1
Время сортировки массива
|
количество элементов в сортируемом массиве |
||||||||||||
|
тип данных |
0 |
100 |
500 |
1000 |
1500 |
2000 |
2500 |
3000 |
3500 |
4000 |
4500 |
5000 |
|
int |
0 |
0 |
0.06 |
0.4 |
0.86 |
1.53 |
2.4 |
3.46 |
4.6 |
6.2 |
7.1 |
7.5 |
|
float |
0 |
0 |
0.13 |
1.1 |
3 |
5.1 |
7.4 |
9.4 |
11.7 |
12.9 |
13.9 |
14.7 |
|
char |
0 |
0 |
0.06 |
0.4 |
0.9 |
2 |
3 |
4.1 |
5.6 |
7.3 |
8.4 |
9 |
|
string |
0 |
4.4 |
9.2 |
12.8 |
17 |
20.1 |
23.5 |
26.7 |
28.7 |
30 |
31.2 |
32 |
На основании данной таблицы можно вывести закономерности и составить график зависимость времени сортировки массива от размера этого массива для четырех типов данных (рис 4).
Рис.5. График зависимости времени сортировки от числа элементов
3 Итоги анализа алгоритма
Можно видеть, что полученная нами зависимость действительно не превосходит порядок  . Стоит отметить, что время работы нашего алгоритма рассчитывается без учета времени передачи массива, поэтому можно судить о том, что разница между зависимостями для различных типов данных обусловлена, главным образом, разницей во времени обращения к записям этих типов.
. Стоит отметить, что время работы нашего алгоритма рассчитывается без учета времени передачи массива, поэтому можно судить о том, что разница между зависимостями для различных типов данных обусловлена, главным образом, разницей во времени обращения к записям этих типов.
Очевидно, что рассматриваемый нами алгоритм простого выбора будет весьма эффективно сортировать массивы, состоящие из значений, типы которых позволяют выполнить ЭВМ наискорейший поиск минимума. Также стоит отметить, что данный алгоритм весьма рационален при использовании на ЭВМ, процессоры которых ориентированы на операции с массивами чисел и имеют встроенную операцию быстрого поиска минимума в массиве.
Отметим также, что использование такого способа реализации алгоритмов сортировки, как шаблоны функций С++ является очень выгодным. Данный способ позволяет быстро использовать созданную однажды и добавленную в библиотеку функцию, реализующую сортировку, в любой программе и для массивов любого размера и типа значений.
Недостатком данной реализации является большое время передачи сортируемого массива из программы в функцию и обратно. Для массивов больших размеров, состоящих из структурированных типов, оно может в несколько раз превышать время самой сортировки.
ЗАКЛЮЧЕНИЕ
Строки в таблице можно отсортировать согласно содержимому одного или нескольких столбцов. Для этого выберите поле, по которому будет осуществляться сортировка, и нажмите кнопку Сортировка по возрастанию или Сортировка по убыванию на панели инструментов.
Операция сортировки данных используется для удобства нахождения требуемой информации в таблице базы данных. Нужную строку большой таблицы найти гораздо проще, если строки этой таблицы упорядочены по какому-либо признаку (например, по алфавиту, по дате, по увеличению или уменьшению значений в столбцах, содержащих числа).
Можно утверждать, что залогом успешности информационной системы, которая нуждалась бы в использовании методов, проанализированных нами, является способность этой системы производить полноценный анализ оперируемых данных. Безусловно, рациональность использования различных методов сортировки обусловлена имеющимися данными о сортируемых элементах. На основе анализа различных алгоритмов сортировки можно выделить несколько факторов, на которые стоит обращать внимание, прибегая к использованию того или иного алгоритма.
- Среднее время выполнения алгоритма
- Наибольшее значение времени выполнения алгоритма
- Объем занимаемой оперативной памяти
- Скорость оперирования сортируемыми данными
- Специфичность области и среды применения алгоритма
Сопоставляя алгоритмы быстрой и пирамидальной сортировок, что при небольшом количестве сортируемых элементов один алгоритм явно выигрывает у другого, но при значительном увеличении числа элементов первый алгоритм проигрывает второму. Также необходимо учитывать то, что некоторые алгоритмы, такие как выбор из дерева или пирамидальная сортировка ввиду того, что оперируют большим количеством информации, будут работать быстрее, но при этом занимать гораздо больше оперативной памяти ЭВМ, что в ряде случаев может быть нерационально. С другой стороны, стоит подстраивать используемый алгоритм под соответствующую архитектуру ЭВМ, специфичность ее процессора и т. п.
Сделаем вывод, что актуальность задачи состоит не в усовершенствовании самих методов сортировки, а главным образом в совершенствовании методов их реализации и правильном использовании соответствующих методов и их реализаций, на основе имеющихся данных о сортируемых элементах информационной структуры.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Ашарина, И.В. Основы программирования на языках C и C++ / И.В. Ашарина. - М.: ГЛТ, 2012. - 208 c.
- Богачев, К.Ю. Основы параллельного программирования: Учебное пособие / К.Ю. Богачев. - М.: Бином, 2014. - 342 c.
- Биллиг, В. Основы программирования на C# / В. Биллиг. - М.: Бином. Лаборатория знаний, 2006. - 483 c.
- Гуриков, С.Р. Основы алгоритмизации и программирования на Python: Учебное пособие / С.Р. Гуриков. - М.: Форум, 2018. - 384 c.
- Голицына, О.Л. Основы алгоритмизации и программирования: Учебное пособи / О.Л. Голицына, И.И. Попов. - М.: Форум, 2013. - 205 c.
- Дорогов, В.Г. Основы программирования на языке С: Учебное пособие / В.Г. Дорогов, Е.Г. Дорогова. - М.: Форум, 2015. - 320 c.
- Колдаев, В.Д. Основы алгоритмизации и программирования: Учебное пособие / В.Д. Колдаев; Под ред. Л.Г. Гагарина. - М.: ИД ФОРУМ, ИНФРА-М, 2012. - 416 c.
- Колдаев, В.Д. Основы алгоритмизации и программирования: Учебное пособие / В.Д. Колдаев. - М.: Форум, 2015. - 352 c.
- Культин, Н.Б. Основы программирования в Turbo C++ / Н.Б. Культин. - СПб.: BHV, 2013. - 464 c.
- Серкова, Е.Г. Основы алгоритмизации и программирования (ОП.04): практикум / Е.Г. Серкова. - Рн/Д: Феникс, 2017. - 159 c.
- Семакин, И.Г. Основы алгоритмизации и программирования. Практикум: Учебное пос. для студ. учреждений сред. проф. образования / И.Г. Семакин, А.П. Шестаков. - М.: ИЦ Академия, 2013. - 144 c.
- Черпаков, И.В. Основы программирования: Учебник и практикум для прикладного бакалавриата / И.В. Черпаков. - Люберцы: Юрайт, 2016. - 219 c.
- Фридман, А.Л. Основы объектно-ориентированного программирования на языке Си++ / А.Л. Фридман. - М.: Гор. линия-Телеком, 2012. - 234 c.
ПРИЛОЖЕНИЕ
Разработанная программа


- Анализ методов сортировки одномерного массива
- Ссудный процент , его сущность и порядок исчисления
- Процессы принятия решений в организации (ТЕОРЕТИКО-МЕТОДОЛОГИЧЕСКИЕ ОСНОВЫ ПРИНЯТИЯ УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ )
- «Организационная культура и ее роль в современных организациях» (предприятие АО «РКЦ «Прогресс»)
- Выбор стиля руководства в организации (Теоретические аспекты выбора стиля руководства в организации )
- Основания для проведения оперативно-розыскных мероприятий (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ПОНЯТИЯ ОПЕРАТИВНО-РОЗЫСКНОЙ ДЕЯТЕЛЬНОСТИ )
- Государственные пособия гражданам, имеющим детей (общая характеристика, круг лиц, имеющих право на пособие, виды, порядок начисления и выплаты пособий)
- Процесс монополизации рынка в теории и на практике
- Определение, основные задачи, функции бухгалтерского учета
- Оценка качества товара (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ОЦЕНКИ КАЧЕСТВА СУХАРНЫХ ИЗДЕЛИЙ)
- Понятие менеджмента. Менеджер и предприниматель. (Понятие предпринимательства и менеджмента )
- Организация коммерческой деятельности (Теоретические основы планирования коммерческой деятельности))