
Методы кодирования данных (Краткая история кодирования )
Содержание:

Введение
Для автоматизации работы с информацией различных типов, необходимо стандартизировать форму их представления – для чего, как правило, применяется прием кодирования, то есть выражения данных одного типа через данные другого типа. Естественные человеческие языки – как раз и являются системами кодирования понятий для выражения мыслей при помощи речи. С языками соседствуют азбуки (системы кодирования составляющих языка с помощью графических обозначений). История знает стоящие, хоть и напрасные попытки разработки «универсальных» языков и азбук.
Проблема универсального средства кодирования достаточно успешно реализуется в определенных отраслях техники, науки и культуры. Как пример можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых.
Актуальность этой курсовой работы обусловлена тем, что в современной информатике аккумулировано значительное количество материала о разных видах информации и возможности их кодирования и безопасной передачи. Этот значительный объем информации необходимо осмыслить, структурировать, обобщить и представить как совокупность знаний о методах кодирования данных.
Целью данной курсовой работы является рассмотрение различных методов кодирования данных.
Для достижения цели, необходимо решить следующие задачи:
- тщательно изучить тематическую литературу и данные сайтов сети Интернет;
- рассмотреть основные понятия, связанные с кодированием данных;
- рассмотреть как кодируются различные типы данных в электронно-вычислительных машинах;
- подробно рассмотреть различные методы кодирования данных.
Глава 1. Теоретические основы кодирования данных
1.1 Основные понятия и назначение кодирования данных
В связи с интенсивным развитием информационных технологий кодирование стало ведущим вопросом при решении разнообразных задач программирования, таких как:
- представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
- обеспечение помехоустойчивости при отправке данных по каналам связи;
- компрессия информации в базах данных.
Главными задачами кодирования являются:
- обеспечение экономичности отправки информации посредством ликвидации избыточности;
- обеспечение надежности (помехоустойчивости) передачи информации;
- согласование скорости отправки и получения данных с пропускной способностью канала.
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее известных понятий.
Знак – это элемент конечного множества отличающихся друг от друга элементов.
Длина кода – количество знаков, используемых для представления кодируемой информации.
Кодирование данных – это процесс формирования определенного представления информации. Буквально, под термином «кодирование» часто понимают трансформацию одной формы представления информации в другую, более пригодную для хранения, передачи или обработки.
Весь ряд символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера вся информация кодируется при помощи двоичного алфавита, содержащего всего 2 символа: ноль и единицу.
Всякий способ кодирования имеет в своем составе основу (алфавит, система координат, основание системы счисления и т.д.) и регламент создания информационных образов на этой основе. Кодирование числовых данных осуществляется с использованием системы счисления.
Компьютер может обрабатывать текстовую информацию. При вводе данных в компьютер каждая буква кодируется назначенным числом, а при выводе на внешние устройства (экран, печать) для понимания человеком по этим числам формируются изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Декодирование – процесс обратного преобразования кода в форму первоначальной символьной системы, по-другому говоря – получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке.
В широком смысле декодирование – это операция восстановления содержания закодированного сообщения. При этом подходе процесс записи текста с помощью английского алфавита является кодированием, а его чтение – декодированием.
Операции кодирования и декодирования считаются обратимыми, если их пошаговое применение гарантирует возврат к первоначальной информации без какой-либо утраты этой информации.
Человечество применяет кодирование текста с момента появления первой секретной информации. Ниже приведено несколько приёмов кодирования текста, изобретенных на различных этапах развития человеческой мысли:
- криптография – это тайнопись, система изменения письма в целях превратить понятный текст в непонятный для неосведомленных лиц;
- азбука Морзе, в которой каждая буква или знак являет собой сочетание коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
- сурдожесты – язык жестов, используемый людьми с расстройством слуха.
Одним из первых, вошедших в историю, методов шифрования стал шифр Юлия Цезаря. Он строится на замещении каждой буквы кодируемого текста, на иную, путем сдвига в алфавите исходной буквы на заданное количество символов, при этом алфавит просматривается по кругу, а именно - после буквы «я» следует буква «а». Так, например, «байт» при сдвиге на 2 символа вправо кодируется словом «гвлф». Чтобы расшифровать данное слово необходимо поменять каждую зашифрованную букву, на вторую слева от неё.
С появлением технических средств хранения и передачи данных возникли новые идеи и методы кодирования. Первейшим техническим средством отправки информации на дальнее расстояние стал телеграф, который в 1837 году изобрел американец Сэмюэль Морзе. Телеграфное сообщение – это череда электрических сигналов, переданная от одного телеграфного аппарата по линии к другому телеграфному аппарату. Этот момент навел С. Морзе на идею использования только 2 видов сигнала – короткого и длинного – для кодирования сообщения, передаваемого по линиям телеграфной связи.
Такой способ кодирования приобрел название азбуки Морзе. В ней каждая буква алфавита кодируется чередой коротких сигналов (точек) и длинных сигналов (тире). Буквы отделены друг от друга интервалами – отсутствием сигналов.
Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце девятнадцатого века. В нем применялось только два разных вида сигналов. Это два отличных друг от друга электрических сигнала. Длина кода всех символов одинакова и равняется пяти. В этом случае отсутствует проблема отделения букв друг от друга: каждая 5-ка сигналов – это знак текста. Благодаря этому пропуск не нужен.
Код Бодо – это первый в истории техники метод двоичного кодирования данных. При помощи этой концепции был сконструирован телеграфный аппарат, печатающий буквы и имеющий вид пишущей машинки. При нажатии на клавишу с какой-либо буквой вырабатывался соответствующий 5-импульсный сигнал, который отсылался по линии связи. Аппарат-приемник под воздействием этого сигнала отпечатывает ту же букву на бумажном носителе.
В нынешних компьютерах для кодирования текстов также используется равномерный двоичный код.
Кодирование данных двоичным кодом
В ЭВМ существует своя система, которая называется двоичным кодированием. Она основана на представлении данных посредством всего двух знаков: 0 и 1. Их называют двоичными цифрами или, по-английски, binary digit или сокращенно bit (бит).
С помощью одного бита можно сформулировать два понятия: 0 или 1 (да или нет, истина или ложь и прочее). Если число битов увеличить до двух, тогда можно выразить уже 4 разных понятия:
00 01 10 11
Три бита дают возможность закодировать 8 различных понятий:
000 001 010 011 100 101 110 111
То есть, увеличивая на 1 число разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое можно выразить в этой системе. Общая формула:
N = 2m
где N – число кодируемых значений;
m – разрядность двоичного кодирования, принятая в данной системе.
Более крупной единицей представления, а также измерения информации является байт.
8 бит – 1 байт
1024 байта – 1 Кбайт
1024 килобайта – 1 Мбайт
1024 мегабайта – 1 Гбайт
Основные типы данных, которые обрабатывает компьютер:
- целые и действительные числа;
- текстовые данные;
- графика;
- звук.
Кодирование целых и действительных чисел
Целые числа кодируют двоичным кодом очень простым способом – нужно взять целое число и делить его напополам до того момента, пока частное не станет равным 1. Остатки от каждого деления, записанные в ряд справа налево вместе с последним частным, и формируют двоичный аналог десятичного числа:
23:2=11 + 1
11:2=5+1
5:2=2+1
2:2=1+0
Получается, 2310 = 101112.
Для кодирования целых чисел от 0 до 255 необходимо иметь 8 разрядов двоичного кода (8 бит). 16 бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита – более 16,5 миллионов различных значений.
Для кодирования действительных чисел применяется 80-разрядное кодирование. Для начала число конвертируют в нормализованную форму:
3,1415926=0,31415926*101
300 000 = 0,3*106
123 456 789 = 0,123456789*1010
1-ая часть числа именуется мантиссой, а 2-ая – характеристикой. Преимущественную часть из 80 бит выделяют для хранения мантиссы (с учетом знака) и некое фиксированное число разрядов отводят для хранения характеристики (также со знаком).
1.2 Кодирование текстовых данных
В случае если с каждым символом алфавита соотнести определенное целое число (к примеру, порядковый номер), то при помощи двоичного кода можно закодировать и текстовые данные. 8 двоичных разрядов вполне хватит для кодирования 256 различных символов. Этого достаточно для того чтобы выразить разными сочетаниями 8 битов все символы английского и русского языков, как строчные, так и прописные, в том числе и знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например символ «§».
На первый взгляд это очень простая задача, но всегда существовали очень значимые организационные трудности. В начале развития вычислительной техники эти трудности были связаны с дефицитом нужных стандартов, а в наше время сложности порождены, наоборот, множеством одновременно действующих и противоречащих друг другу стандартов. Для того чтобы все одинаково кодировали текстовые данные, необходимы единые таблицы кодирования. Пока это невозможно из-за разногласий между символами национальных алфавитов, а также разногласий корпоративного характера.
Для английского языка, фактически занявшего нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (American National Standard Institute) внедрил систему кодирования ASCII (American Standard Code for Information Interchange - стандартный код информационного обмена США). В данной системе ASCII существуют 2 таблицы кодирования – базовая и расширенная. В базовой таблице содержатся значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с 0, отводятся производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещены так называемые управляющие коды, которым не сопоставлены никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но с их помощью можно управлять тем, как происходит вывод прочих данных.
С кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII представлена на рисунке 1:
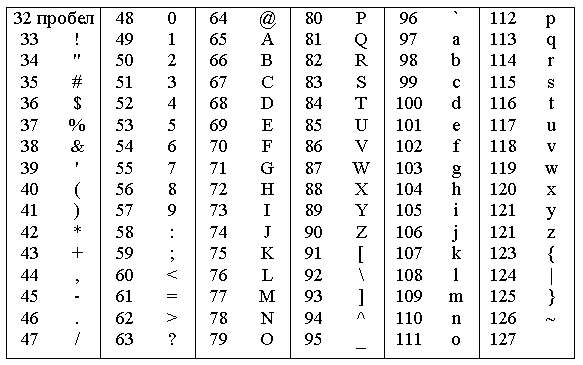
Рисунок 1. Базовая таблица кодировки ASCII
Подобные системы кодирования текстовых данных были созданы и в других странах. Например, в СССР действовала система кодирования КОИ-7 (код обмена информацией, 7-значный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальные системы кодирования вынуждены были «отступить» во вторую, расширенную часть системы кодирования, которая определяет значения кодов с 128 по 255. Неимение единого стандарта в этой области привело к появлению многочисленных одновременно действующих кодировок. Только в России можно указать 3 действующих стандарта кодировки и еще несколько устаревших.
К примеру, кодировка символов русского языка, известная под названием Windows-1251, была введена со стороны – компанией Microsoft, но, принимая во внимание массовое распространение операционных систем и иных продуктов этой компании в России, она всерьез укрепилась и нашла широкое распространение (рисунок 2). Эта кодировка применяется на большинстве локальных компьютеров, работающих на платформе Windows:
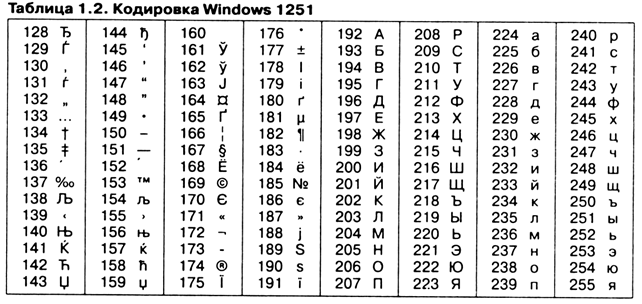
Рисунок 2. Кодировка Windows
Еще одна достаточно распространенная кодировка называется КОИ-8 (код обмена информацией, 8-значный) – ее возникновение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы. На сегодняшний день кодировка КОИ-8 широко распространена в компьютерных сетях на территории России и в российском секторе Интернета.
Международный стандарт, предусматривающий кодировку символов русского алфавита, называется кодировкой ISO (International Standard Organization – Международный институт стандартизации). Однако в практике эта кодировка применяется очень редко.
Для компьютеров, которые работают с операционными системами MS-DOS, могут применяться еще 2 кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая считалась устаревшей уже в первые годы появления персональных компьютеров, а вторая используется и в наше время.
Вследствие изобилия систем кодирования текстовых данных, действующих в России, появилась задача межсистемного преобразования данных – это одна из самых распространенных задач информатики.
1.3 Универсальная система кодирования текстовых данных
Рассматривая организационные трудности, которые связаны с созданием единой системы кодирования текстовых данных, можно сделать вывод, что они вызваны недостаточным набором кодов (256). При этом очевидно, что если, к примеру, кодировать символы не 8-разрядными двоичными числами, а числами с большим числом разрядов, то и охват допустимых значений кодов будет намного больше. Система, основанная на 16-разрядном кодировании символов, называется универсальной – UNICODE. 16 разрядов предоставляют уникальные коды для 65 536 разных символов – этого поля достаточно для расположения в одной таблице символов большей части языков мира.
Невзирая на банальную ясность такого подхода, простой механический переход на такую систему кодирования длительное время затягивался из-за ограниченных ресурсов средств вычислительной техники (в системе UNICODE все текстовые документы автоматически становятся в 2 раза длиннее). Во второй половине 90-х годов технические средства приобрели нужный уровень оснащенности ресурсами, и в наше время отмечается поэтапный перевод документов и программных средств на универсальную систему кодирования. Частным пользователям добавилось проблем по согласованию документов, которые были выполнены в различных системах кодирования, с программными средствами.
1.3 Кодирование графических данных
Если разглядывать черно-белое графическое изображение, напечатанное в газете или книге, при помощи увеличительного стекла, можно увидеть, что оно складывается из крошечных точек, которые образуют характерный узор, который называют растром.
Поскольку линейные координаты и индивидуальные свойства каждой точки можно выразить при помощи целых чисел, то можно сказать, что растровое кодирование дает возможность использовать двоичный код для представления графических данных. Общепризнанным на сегодня считается представление черно-белых иллюстраций в виде сочетания точек с 256 градациями серого цвета, и, следовательно, для кодирования яркости любой точки достаточно 8-разрядного двоичного числа.
Для кодирования цветных графических изображений используется принцип расщепления произвольного цвета на основные составляющие. В качестве таких составляющих используют 3 основных цвета: красный (Red), зеленый (Green) и синий (Blue). На практике считается (однако теоретически это не совсем так), что любой цвет, который видит человеческий глаз, можно произвести путем смешивания этих 3 основных цветов. Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (8 двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн. разных цветов, что очень близко к чувствительности человеческого глаза. Режим представления цветной графики с применением 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно сопоставить дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Просто заметить, что для любого из основных цветов дополнительным будет цвет, который образован суммой пары остальных основных цветов. То есть, дополнительными цветами являются: голубой (Cyan), пурпурный (Magenta) и желтый (Yellow). Принцип расщепления произвольного цвета на составляющие компоненты можно использовать не только для основных цветов, но и для дополнительных, а это значит, что любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии применяется еще и 4-ая краска – черная (Black). Поэтому такая система кодирования обозначается 4-мя буквами CMYK (черный цвет обозначен буквой К, так как буква В уже занята синим цветом), и для представления цветной графики в этой системе нужно иметь 32 двоичных разряда.
Если уменьшить число двоичных разрядов, применяемых для кодирования цвета каждой точки, то можно уменьшить объем данных, но при этом диапазон кодируемых цветов значительно уменьшается. Кодирование цветной графики 16-разрядными двоичными числами называют режимом High Color.
При кодировании информации о цвете с помощью 8 бит данных можно передать только 256 цветовых оттенка. Этот метод кодирования цвета называют индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некой справочной таблице, называемой палитрой. Само собой, эта палитра должна прикладываться к графическим данным – без нее невозможно будет воспользоваться методами воспроизведения информации на экране или бумаге.
1.4 Кодирование звуковой информации
Приемы и методы обработки звуковой информацией появились в вычислительной технике позже всего. Кроме того, в противовес числовым, текстовым и графическим данным, у звукозаписей не было столь длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество различных компаний разработали свои корпоративные стандарты, однако, говоря обобщенно, можно выделить 2 главных направления.
Метод FM (Frequency Modulation) основан на том, что в теории любой сложный звук можно разложить на последовательный ряд простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях не миновать потерь информации, связанных с методом кодирования, поэтому качество звукозаписи обычно выходит не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки.
Метод таблично-волнового (Wave-Table) синтеза больше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов. В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Глава 2. Методы кодирования данных
2.1 Теория кодирования и теория информации
Теория кодирования и теория информации появились в начале 20 века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, заложивших основу для последующих исследований в этой области.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов (рисунок 3).
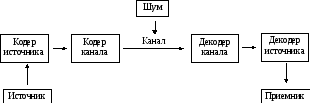
Рисунок 3. Модель системы передачи сигналов
Начальным звеном в приведенной выше модели является источник информации. Здесь рассматриваются дискретные источники без памяти, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 33 русских букв, пробела и знаков препинания.
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. К тому же, обычно символу исходного алфавита А ставится в соответствие не один, а группа символов алфавита В, которая называется кодовым словом. Кодовый алфавит – множество различных символов, используемых для записи кодовых слов. Кодом называется совокупность всех кодовых слов, применяемых для представления порождаемых источником символов.
Дадим строгое определение кодирования. Пусть даны алфавит источника 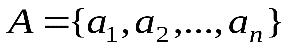 , кодовый алфавит
, кодовый алфавит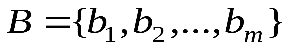 . Обозначим
. Обозначим 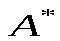
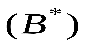 множество всевозможных последовательностей в алфавите А (В). Множество всех возможных сообщений в алфавите А обозначим S. Тогда отображение
множество всевозможных последовательностей в алфавите А (В). Множество всех возможных сообщений в алфавите А обозначим S. Тогда отображение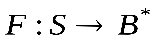 , которое преобразует множество сообщений в кодовые слова в алфавитеВ, называется кодированием. Если
, которое преобразует множество сообщений в кодовые слова в алфавитеВ, называется кодированием. Если 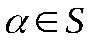 , то
, то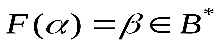 – кодовое слово. Обратное отображение
– кодовое слово. Обратное отображение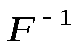 (если оно существует) называется декодированием.
(если оно существует) называется декодированием.
Задача кодирования сообщения ставится следующим образом. Требуется при заданных алфавитах А и В и множестве сообщений S найти кодирование F, обладающее определенными свойствами и оптимальное в некотором смысле. Свойства, которые требуются от кодирования, могут быть разными. Приведем некоторые из них:
- существование декодирования;
- помехоустойчивость или исправление ошибок при кодировании: декодирование обладает свойством
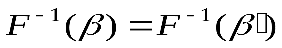 , β~β′ (эквивалентно β′с ошибкой);
, β~β′ (эквивалентно β′с ошибкой); - обладает заданной трудоемкостью (время, объем памяти).
Известны 2 класса методов кодирования дискретного источника информации: равномерное и неравномерное кодирование. Под равномерным кодированием понимается применение кодов со словами постоянной длины. Для того чтобы декодирование равномерного кода стало возможным, разным символам алфавита источника нужно поставить в соответствие разные кодовые слова. При этом длина кодового слова должна быть не меньше 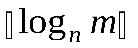 символов, где m – размер исходного алфавита, n – размер кодового алфавита.
символов, где m – размер исходного алфавита, n – размер кодового алфавита.
При неравномерном кодировании источника используются кодовые слова разной длины. Причем кодовые слова обычно строятся так, что часто встречающиеся символы кодируются более короткими кодовыми словами, а редкие символы – более длинными (за счет этого достигается «сжатие» данных).
Под сжатием данных понимается компактное представление данных, которое достигается за счет избыточности информации, содержащейся в сообщениях. Большое значение для практического использования имеет неискажающее сжатие, позволяющее полностью восстановить исходное сообщение. При неискажающем сжатии происходит кодирование сообщения перед началом передачи или хранения, а после окончания процесса сообщение однозначно декодируется (это соответствует модели канала без шума (помех)).
Методы сжатия данных можно разделить на 2 группы: статические методы и адаптивные методы. Статические методы сжатия данных предназначены для кодирования конкретных источников информации с известной статистической структурой, которые порождают определенное множество сообщений. Эти методы основаны на знании статистической структуры исходных данных. К наиболее известным статическим методам сжатия относятся коды Хаффмана, Шеннона, Фано, Гилберта-Мура, арифметический код и другие методы, использующие известные сведения о вероятностях порождения источником различных символов или их сочетаний.
Если статистика источника информации неизвестна или изменяется с течением времени, то для кодирования сообщений такого источника применяются адаптивные методы сжатия. В адаптивных методах при кодировании очередного символа текста используются сведения о ранее закодированной части сообщения для оценки вероятности появления очередного символа. В процессе кодирования адаптивные методы «настраиваются» на статистическую структуру кодируемых сообщений, т.е. коды символов меняются в зависимости от накопленной статистики данных. Это позволяет адаптивным методам эффективно и быстро кодировать сообщение за один просмотр.
Существует множество различных адаптивных методов сжатия данных. Наиболее известные из них – адаптивный код Хаффмана, код «стопка книг», интервальный и частотный коды, а также методы из класса Лемпела-Зива.
Рассмотрим несколько методов кодирования более подробно.
Метод оптимального побуквенного кодирования был создан в 1952 г. Д. Хаффманом. Оптимальный код Хаффмана обладает минимальной средней длиной кодового слова среди всех побуквенных кодов для данного источника с алфавитом А={a1,…,an} и вероятностями pi=P(ai).
Рассмотрим алгоритм построения оптимального кода Хаффмана:
- Привести в порядок символы исходного алфавита А={a1,…,an} - по убыванию их вероятностей p1≥p2≥…≥pn.
- Если А={a1,a2}, то a1→0, a2→1.
- Если А={a1,…,aj,…,an} и известны коды <aj→bj >,j= 1,…,n, то для алфавита {a1,…aj/, aj//…,an} с новыми символами aj/ и aj/ вместо aj, и вероятностями p(aj)=p(aj/)+ p(aj//), код символа aj заменяется на коды aj/→ bj0, aj//→bj1.
Пример. Пусть дан алфавит A={a1,a2,a3,a4,a5,a6} с вероятностями:
p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07
Здесь символы источника уже упорядочены в соответствии с их вероятностями. Будем складывать 2 наименьшие вероятности и включать суммарную вероятность на соответствующее место в упорядоченном списке вероятностей до тех пор, пока в списке не останется два символа. Тогда закодируем эти два символа 0 и 1. Далее кодовые слова достраиваются, как показано на рисунке 4.

Рисунок 4. Процесс построения кода Хаффмана
Таблица 1. Код Хаффмана
|
ai |
pi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
0.36 0.18 0.18 0.12 0.09 0.07 |
2 3 3 4 4 4 |
1 000 001 011 0100 0101 |
Посчитаем среднюю длину, построенного кода Хаффмана:
Lср(P)=1.0.36 + 3.0.18 + 3.0.18 + 3.0.12 + 4.0.09 + 4.0.07 =2.44,
при этом энтропия данного источника
H(p1,…,p6)= − 0.36.log0.36 − 2.0.18.log0.18 − 0.12.log0.12 − 0.09.log0.09 − 0.07log0.07=2.37
Код Хаффмана обычно строится и хранится в виде двоичного дерева, в листьях которого находятся символы алфавита, а на «ветвях» – 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 собираются в одну уникальную последовательность (рисунок 5).

Рисунок 5. Кодовое дерево для кода Хаффмана
Метод Фано построения префиксного почти оптимального кода, для которого 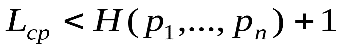 , заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на 2 части так, чтобы суммы вероятностей букв, которые входят в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по 1 букве.
, заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на 2 части так, чтобы суммы вероятностей букв, которые входят в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по 1 букве.
Пример. Пусть дан алфавит A={a1,a2,a3,a4,a5,a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 2 и на рисунке 6.
Таблица 2. Код Фано
|
ai |
Pi |
кодовое слово |
Li |
|||
|
a1 |
0.36 |
0 |
0 |
2 |
||
|
a2 |
0.18 |
0 |
1 |
2 |
||
|
a3 |
0.18 |
1 |
0 |
2 |
||
|
a4 |
0.12 |
1 |
1 |
0 |
3 |
|
|
a5 |
0.09 |
1 |
1 |
1 |
0 |
3 |
|
a6 |
0.07 |
1 |
1 |
1 |
1 |
4 |
Полученный код является префиксным и почти оптимальным со средней длиной кодового слова
Lср=0.36.2+0.18.2+0.18.2+0.12.3+0.09.4+0.07.4=2.44
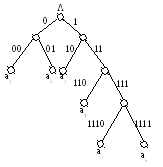
Рисунок 6. Кодовое дерево для кода Фано
Код Шеннона позволяет построить почти оптимальный код с длинами кодовых слов 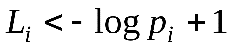 . Тогда по теореме Шеннона:
. Тогда по теореме Шеннона:
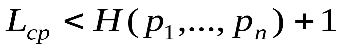 .
.
Код Шеннона, удовлетворяющий этому соотношению, строится следующим образом:
- Приведем в порядок символы исходного алфавита А={a1,a2,…,an} по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
- Вычислим величины Qi, называющиеся кумулятивными вероятностями
Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, … , Qn=1
- Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые
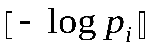 знаков после запятой.
знаков после запятой.
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения
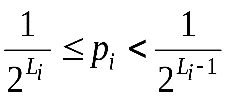 ,
, 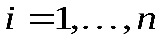 .
.
Пример. Пусть дан алфавит A={a1,a2,a3,a4,a5,a6} с вероятностями p1=0.36,p2=0.18,p3=0.18,p4=0.12,p5=0.09,p6=0.07. Построенный код приведен в таблице 3.
Таблица 3.Код Шеннона
|
ai |
Pi |
Qi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
1/22≤0.36<1/2 1/23≤0.18<1/22 1/23≤0.18<1/22 1/24≤0.12<1/23 1/24≤0.09<1/23 1/24≤0.07<1/23 |
0 0.36 0.54 0.72 0.84 0.93 |
2 3 3 4 4 4 |
00 010 100 1011 1101 1110 |
Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмана (H= 2.37), сравним его со значением средней длины кодового слова кода Шеннона
Lср= 0.36.2+(0.18+0.18).3+(0.12+0.09+0.07).4=2.92< 2.37+1,
что полностью соответствует утверждению теоремы Шеннона.
Е.Н.Гилбертом и Э.Ф.Муром был предложен метод построения алфавитного кода, для которого 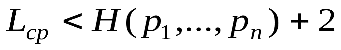 .
.
Пусть символы алфавита некоторым образом упорядочены, например, a1≤a2≤…≤an. Код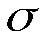 называется алфавитным, если кодовые слова лексикографически упорядочены, т.е.
называется алфавитным, если кодовые слова лексикографически упорядочены, т.е. 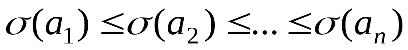 .
.
Процесс построения кода происходит следующим образом.
- Вычислим величины Qi, i=1,n:
Q1=p1/2,
Q2=p1+p2/2,
Q3=p1+p2+p3/2,
…
Qn=p1+p2+…+pn-1+pn/2.
- Представим суммы Qi в двоичном виде.
- В качестве кодовых слов возьмем
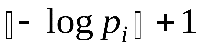 младших бит в двоичном представлении Qi,
младших бит в двоичном представлении Qi,  .
.
Пример. Пусть дан алфавит A={a1,a2,a3,a4,a5,a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 4.
Таблица 4. Код Гилберта-Мура
|
ai |
Pi |
Qi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
1/23≤0.18 1/23≤0.18<1/22 1/22≤0.36<1/21 1/24≤0.07 1/24≤0.09 1/24≤0.12 |
0.09 0.27 0.54 0.755 0.835 0.94 |
4 4 3 5 5 5 |
0001 0100 100 11000 11010 11110 |
Средняя длина кодового слова не превышает значения энтропии плюс 2. Действительно,
Lср=4.0.18+4.0.18+3.0.36+5.0.07+5.0.09+5.0.12=3.92<2.37+2
Этот метод был предложен Б.Я. Рябко в 1980 году. Название метод получил по подобию со стопкой книг, которая лежит на столе. Обычно сверху стопки лежат недавно использованные книги, а внизу стопки – книги, которые использовались давно, и после каждого обращения к стопке использованная книга кладется сверху стопки.
До начала кодирования буквы исходного алфавита упорядочены произвольным образом и каждой позиции в стопке присвоено свое кодовое слово, причем первой позиции стопки соответствует самое короткое кодовое слово, а последней позиции - самое длинное кодовое слово. Очередной символ кодируется кодовым словом, соответствующим номеру его позиции в стопке, и переставляется на первую позицию в стопке.
Пример. Приведем описание кода на примере алфавита A={a1,a2,a3,a4}. Пусть кодируется сообщение а3а3а4а4а3…
- символ а3 находится в 3 позиции стопки, кодируется кодовым словом 110 и перемещается на 1 позицию в стопке, при этом символы а1 и а2 смещаются на 1 позицию вниз;
- следующий символ а3 уже находится в 1 позиции стопки, кодируется кодовым словом 0 и стопка не изменяется;
- символ а4 находится в последней позиции стопки, кодируется кодовым словом 111 и перемещается на 1 позицию в стопке, при этом символы а1,а2,а3 смещаются на 1 позицию вниз;
- следующий символ а4 уже находится в 1 позиции стопки, кодируется кодовым словом 0 и стопка не изменяется;
- символ а3находится во 2 позиции стопки, кодируется кодовым словом 10 и перемещается на 1 позицию в стопке, при этом символ а4 смещается на одну позицию вниз.
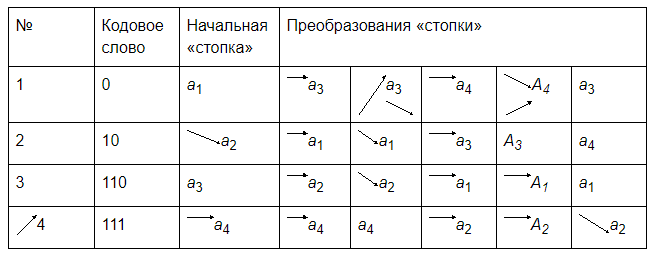
Рисунок 7. Кодирование методом «стопка книг»
Таким образом, закодированное сообщение имеет следующий вид:
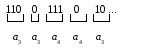
Рисунок 8. Результат кодирования методом «стопка книг»
Рассмотренный метод сжимает сообщение за счет того, что часто встречающиеся символы будут находиться в верхних позициях «стопки книг» и кодироваться более короткими кодовыми словами. Эффективность метода особо заметна при кодировании серий одинаковых символов. В этом случае все символы серии, начиная со второго, будут кодироваться самым коротким кодовым словом, соответствующим 1 позиции «стопки книг».
При декодировании используется такая же «стопка книг», находящаяся первоначально в том же состоянии. Над «стопкой» проводятся такие же преобразования, что и при кодировании. Это гарантирует однозначное восстановление исходной последовательности.
Заключение
За короткое время компьютер из вычислительного устройства превратился в устройство для обработки многих видов информации: текстовой, графической, звуковой. С помощью компьютера информация упаковывается и шифруется, путешествует по различным каналам связи и может быть доставлена в любой уголок мира. Современный человек уже не представляет свою деятельность без применения компьютера.
В ходе работы над курсовым проектом по теме «Методы кодирования данных» был проведен анализ литературы и Интернет-источников по исследуемой теме. В результате исследования была достигнута поставленная цель – изучены различные методы кодирования данных. Цель курсовой работы достигнута за счёт выполнения следующих задач.
- изучена тематическая литература и данные с сайтов сети Интернет;
- рассмотрены основные понятия, связанные с кодированием данных;
- рассмотрено кодирование различных типов данных в электронно-вычислительных машинах;
- подробно рассмотрены различные методы кодирования данных.
Список литературы
-
-
- Агеев В.М. Теория информации и кодирования: дискретизация и кодирование измерительной информации. – М.: МАИ, 1977. - 59 с.
- Березкин Е.Ф. Основы теории информации и кодирования: учебное пособие. – М.: НИЯУ МИФИ, 2010. – 312 с.
- Златопольский Д.М. Простейшие методы шифрования текста – М.: Чистые пруды, 2007. – 32 с.
- Котоусов А.С. Теория информации. Учебное пособие для вузов. – М.: Радио и связь, 2003.
- Кузьмин И.В, Кедрус В.А. Основы теории информации и кодирования: учебное пособие - К. "Вища школа", 1986. - 238 с.
- Курапова Е.В, Мачикина Е.П. Основные методы кодирования данных: Практикум. / СибГути. – Новосибирск, 2010. – 62 с.
- Литвинская О.С., Чернышев Н.И. Основы теории передачи информации: учебное пособие. – М.: КНОРУС, 2010.
- Панин В.В. Основы теории информации. Введение в теорию кодирования. – М.: МИФИ, ФГУП ИСС, 2004.
- Сидельников В.М. Теория кодирования. Справочник по принципам и методам кодирования. - Мех-мат, МГУ. - 2006. , 289 с.
- Цымбал В.П. Теория информации и кодирование: учебное пособие - К. "Вища школа", 1992. - 238 с.
- Шастова Г.А. Кодирование и помехоустойчивость передачи телемеханической информации. – М.: Энергия, 1966. – 454 с.
- Элиас П. Кодирование и декодирование // Лекции по теории систем связи / Под ред. К. Дж. Багдади. – М., 1964. – 317 с.
- Кодирование данных в ЭВМ. [Электронный ресурс] – Режим доступа: http://www.automationlab.ru/index.php/2014-08-25-13-20-03/428-3-
- Теория информации и кодирования. [Электронный ресурс] – Режим доступа: http://fs.onu.edu.ua/clients/client11/web11/metod/imem/teor_kod.pdf
-

- ПРОГРАММНЫЕ ПРОДУКТЫ ДЛЯ АВТОМАТИЗАЦИИ ПРОЕКТИРОВАНИЯ ИНФОРМАЦИОННЫХ СИСТЕМ
- Личные неимущественные права на объекты авторских прав
- ИНФОРМАЦИЯ В МАТЕРИАЛЬНОМ МИРЕ (Виды информации)
- Управление поведением в конфликтных ситуациях (Стратегия поведения в конфликте)
- Первичные учетные документы (Первичные учетные документы)
- Трудовая мотивация и адаптационный потенциал сотрудников организаций (Мотивационный процесс)
- Страхование и его роль в развитии экономики САО «ВСК»
- Понятие государства и его типология
- Понятие и виды наследования (Права наследования по закону)
- Понятие и виды наследования (Понятие и виды наследования )
- Психосемантика рекламы (Реклама как один из компонентов комплекса маркетинга)
- Анализ состояния налоговой системы РФ