
Методы кодирования данных (ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ КОДИРОВАНИЯ ДАННЫХ)
Содержание:

ВВЕДЕНИЕ
Кодирования информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
Все алгоритмы кодирования оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт.
Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации. Некоторые из них используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса сжатия. Метод Хаффмана производит идеальное сжатие (то есть, сжимает данные до их энтропии), если вероятности символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить каждый индивидуальный код справа налево (от самого младшего бита к самому старшему). Начиная с работ Д. Хаффмана 1952 года, этот алгоритм являлся предметом многих исследований.
Коды Хаффмана преподаются во всех технических ВУЗах мира и, кроме того, входят в программу для углубленного изучения информатики в школе.
Поэтому изучение кодирования информации и методов кодирования, в частности метода кодирования Хаффмана является актуальным.
Объект исследования: кодирование и методы кодирования информации.
Предмет исследования: программное приложение, показывающие основные принципы кодирования на примере метода кодирования Хаффмана.
Целью курсовой работы является изучения методов кодирования информации в частности метод кодирования Хаффмана и применить их в процессе программной реализации этого метода. Данная цель обусловила выделение следующих задач:
1) рассмотреть основные понятия и принципы кодирования информации;
2) изучить метод кодирования Хаффмана,
3) рассмотреть практические примеры кодирования данных.
Объект исследования - кодирование.
Предмет исследования - методы кодирования данных.
Структура работы состоит из введения, основной части, заключения и списка литературы.
Теоретической и методологической базой данной работы послужили труды российских и зарубежных авторов в области информатики, материалы периодических изданий и сети Интернет.
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ КОДИРОВАНИЯ ДАННЫХ
1.1 Понятие кодирование
Кодирование на двух нижних каналах характеризует метод представления информации сигналами, которые распространяются по среде транспортировки. Кодирование можно рассматривать как двухступенчатое. И ясно, что на принимающей стороне реализуется симметричное декодирование.
Логическое кодирование данных изменяет поток бит созданного кадра МАС-уровня в последовательность символов, которые подлежат физическому кодированию для транспортировки по каналу связи. Для логического кодирования используют разные схемы:
- 4B/5B — каждые 4 бита входного потока кодируются 5-битным символом (табл 1). Получается двукратная избыточность, так как 24 = 16 входных комбинаций показываются символами из 25 = 32. Расходы по количеству битовых интервалов составляют: (5-4)/4 = 1/4 (25%). Такая избыточность разрешает определить ряд служебных символов, которые служат для синхронизации. Применяется в 100BaseFX/TX, FDDI
- 8B/10B — аналогичная схема (8 бит кодируются 10-битным символом) но уже избыточность равна 4 раза (256 входных в 1024 выходных).
- 5B/6B — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN
- 8B/6T — 8 бит входного потока кодируются шестью троичными (T = ternary) цифрами (-,0,+). К примеру: 00h: +-00+-; 01h: 0+-+=0; Код имеет избыточность 36/28 = 729/256 = 2,85. Скорость транспортировки символов в линию является ниже битовой скорости и их поступления на кодирования. Применяется в 100BaseT4.
- Вставка бит — такая схема работает на исключение недопустимых последовательностей бит. Ее работу объясним на реализации в протоколе HDLC. Тут входной поток смотрится как непрерывная последовательность бит, для которой цепочка из более чем пяти смежных 1 анализируется как служебный сигнал (пример: 01111110 является флагом-разделителем кадра). Если в транслируемом потоке встречается непрерывная последовательность из 1, то после каждой пятой в выходной поток передатчик вставляет 0. Приемник анализирует входящую цепочку, и если после цепочки 011111 он видит 0, то он его отбрасывает и последовательность 011111 присоединяет к остальному выходному потоку данных. Если принят бит 1, то последовательность 011111смотрится как служебный символ. Такая техника решает две задачи — исключать длинные монотонные последовательности, которые неудобные для самосинхронизации физического кодирования и разрешает опознание границ кадра и особых состояний в непрерывном битовом потоке.
Таблица 1 — Кодирование 4В/5В
|
Входной символ |
Выходной символ |
|
0000 (0) |
11110 |
|
0001 (1) |
01001 |
|
0010 (2) |
10100 |
|
0011 (3) |
10101 |
|
0100 (4) |
01010 |
|
0101 (5) |
01011 |
|
0110 (6) |
01110 |
|
0111 (7) |
01111 |
|
1000 (8) |
10010 |
|
1001 (9) |
10011 |
|
1010 (A) |
10110 |
|
1011 (B) |
10111 |
|
1100 (C) |
11010 |
|
1101 (D) |
11011 |
|
1110 (E) |
11100 |
|
1111 (F) |
11101 |
|
Служебный символ |
Выходной символ |
|
Idle |
11111 |
|
J |
11000 |
|
K |
10001 |
|
T |
01101 |
|
R |
11001 |
|
S |
11001 |
|
Quiet |
00000 |
|
Halt |
00100 |
Избыточность логического кодирования разрешает облегчить задачи физического кодирования — исключить неудобные битовые последовательности, улучшить спектральные характеристики физического сигнала и др. Физическое/сигнальное кодирование пишет правила представления дискретных символов, результат логического кодирования в результат физические сигналы линии. Физические сигналы могут иметь непрерывную (аналоговую) форму — бесконечное число значений, из которого выбирают допустимое распознаваемое множество. На уровне физических сигналов вместо битовой скорости (бит/с) используют понятие скорость изменения сигнала в линии которая измеряется в бодах (baud). Под таким определением определяют число изменений различных состояний линии за единицу времени. На физическом уровне проходит синхронизация приемника и передатчика. Внешнюю синхронизацию не используют из-за дороговизны реализации еще одного канала. Много схем физического кодирования являются самосинхронизирующимися — они разрешают выделить синхросигнал из принимаемой последовательности состояний канала.
Скремблирование на физическом уровне разрешает подавить очень сильные спектральные характеристики сигнала, размазывая их по некоторой полосе спектра. Очень сильные помеха искажают соседние каналы передачи. При разговоре о физическом кодирировании, возможное использование следующие термины:
- Транзитное кодирование — информативным есть переход из одного состояния в другое
- Потенциальное кодирование — информативным есть уровень сигнала в конкретные моменты времени
- Полярное — сигнал одной полярности реализуется для представления одного значения, сигнал другой полярности для — другого. При оптоволоконное транспортировке вместо полярности используют амплитуды импульса
- Униполярное — сигнал одной полярности реализуется для представления одного значения, нулевой сигнал — для другого
- Биполярное — используется отрицательное, положительное и нулевое значения для представления трех состояний
- Двухфазное — в каждом битовом интервале присутствует переход из одного состояния в другое, что используется для выделения синхросигнала.
1.2 Популярные схемы кодирования, которые применяются в локальных сетях
AMI — Alternate Mark Inversion или же ABP — Alternate bipolare, биполярная схема, которая использует значения +V, 0V и -V. Все нулевые биты имеют значения 0V, единичные — чередующимися значениями +V, -V (рис.1). Применяется в DSx (DS1 — DS4), ISDN. Такая схема не есть полностью самосинхронизирующейся — длинная цепочка нулей приведет к потере синхронизации.
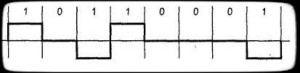
Рисунок 1 – MAMI
MAMI — Modified Alternate Mark Inversion, или же ASI — модифицированная схема AMI, импульсами чередующейся полярности кодируется 0, а 1 — нулевым потенциалом. Применяется в ISDN (S/T — интерфейсы).
B8ZS — Bipolar with 8 Zero Substitution, схема аналогичная AMI, но для синхронизации исключает цепочки 8 и более нулей ( за счет вставки бит).
HDB3 — High Density Bipolar 3, схема аналогичная AMI, но не допускает передачи цепочки более трех нулей. Вместо последовательности из четырех нулей вставляется один из четырех биполярных кодов. (Рис.2)

Рисунок — 2 Манчестерское кодирование
Manchester encoding — двухфазное полярное/униполярное самосинхронизирующееся кодирование. Текущий бит узнается по направлению смены состояния в середине битового интервала: от -V к +V: 1. От +V к -V: 0. Переход в начале интервала может и не быть. Применяется в Ethernet. (В начальных версиях — униполярное). (рис.3)
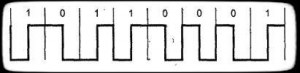 Рисунок — 3
Рисунок — 3
Дифференциальное манчестерское кодирование
Differential manchester encoding — двухфазное полярное/униполярное самосинхронизирующиеся код. Текущий бит узнается по наличию перехода в начале битового интервала (рис. 4.1), например 0 — есть переход (Вертикальный фрагмент), 1 — нет перехода (горизонтальный фрагмент). Можно и наоборот определять 0 и 1.В середине битового интервала переход есть всегда. Он нужен для синхронизации. В Token Ring применяется измененная версия такой схемы, где кроме бит 0 и 1 определенны также два бита j и k (Рис. 4.2). Здесь нет переходов в середине интервала. Бит К имеет переход в начале интервала, а j — нет.
 Рисунок — 4.1 и 4.2
Рисунок — 4.1 и 4.2
Трехуровневое кодирование со скремблированием который не самосинхронизуется. Используются уровни (+V, 0, -V) постоянные в линии каждого битового интервала. При передаче 0 значения не меняются, при передаче 1 — меняются на соседние по цепочке +V, 0, -V, 0, +V и тд. (рис. 5). Такая схема является усложнонным вариантом NRZI. Применяется в FDDI и 100BaseTX.
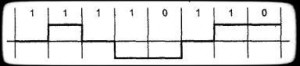
Рисунок — 5 NRZ и NRZI
NRZ — Non-return to zero (без возврата к нулю), биполярная нетранзиктивная схема (состояния меняются на границе), которая имеет 2 варианта. Первый вариант это недифференциальное NRZ (используется в RS-232) состояние напрямую отражает значение бита (рис. 6.а). В другом варианте — дифференциальном, NRZ состояние меняется в начале битового интервала для 1 и не меняется для 0. (рис.6.Б). Привязки 1 и 0 к определенному состоянию нету.
NRZI — Non-return to zero Inverted, измененная схема NRZ (рис. 6.в). Тут состояния изменяются на противоположные в начале битового интервала 0, и не меняются при передаче 1. Возможна и обратная схема представления. Используются в FDDI, 100BaseFX.
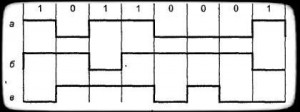
Рисунок — 6-а,б,в RZ
RZ — Return to zero (с возвратом к нулю), биполярная транзитивная самосинхронизирующаяся схема. Состояние в определенный момент битового интервала всегда возвращается к нулю. Имеет дифференциальный/недифференциальный варианты. В дифференциальном привязки 1 и 0 к состоянию нету. (рис. 7.а).
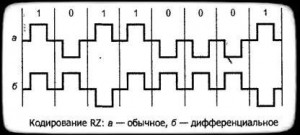
Рисунок — 7-а,б
FM 0 — Frequency Modulation 0 (частотная модуляция), самосинхронизирующийся полярный код. Меняется на противоположное на границе каждого битового интервала. При передаче 1 в течение битового интервала состояние неизменное. При передаче 0, в середине битового интервала состояние меняется на противоположное. (рис. 8). Используется в LocalTalk.

Рисунок — 8
PAM 5
PAM 5 — Pulse Amplitude Modulation, пятиуровневое биполярное кодирование, где пара бит в зависимости от предыстории оказывается одним из 5 уровней потенциала. Нужен неширокая полоса частот (вдвое ниже битовой скорости). Используется в 1000BaseT.
Здесь пара бит оказывается одним четверичным символом (Quater-nary symbol), где каждому соответствует один из 4 уровней сигнала. В таблице показано представление символов в сети ISDN.
Таблица 2 - Представление символов в сети ISDN.
|
Биты |
Четверичный символ |
Уровень, В |
|---|---|---|
|
00 |
-3 |
-2,5 |
|
01 |
-1 |
-0,883 |
|
10 |
+3 |
+2,5 |
|
11 |
+1 |
+0,883 |
4B3T — блок из 4 бит (16 состояний) кодируется тремя троичными символами (27 символов). Из множества возможных методов изменений рассмотрим MMS43, который используется в интерфейсе BRI сетей ISDN (таблица). Тут применяются специальные методы для исключения постоянной составляющей напряжения в линии, в следствии чего кодирования ряда комбинаций зависит от предыстории — состояния, где находится кодер. Пример: последовательность бит 1100 1101 будет представлена как: + + + — 0 -.
Таблица 3 - Специальные методы для исключения постоянной составляющей напряжения в линии
|
Двоичный код |
S1 |
Переход |
S2 |
Переход |
S3 |
Переход |
S4 |
Переход |
|---|---|---|---|---|---|---|---|---|
|
0001 |
0 — + |
S1 |
0 — + |
S2 |
0 — + |
S3 |
0 — + |
S4 |
|
0111 |
— 0 + |
S1 |
— 0 + |
S2 |
— 0 + |
S3 |
— 0 + |
S4 |
|
0100 |
— + 0 |
S1 |
— + 0 |
S2 |
— + 0 |
S3 |
— + 0 |
S4 |
|
0010 |
+ — 0 |
S1 |
+ — 0 |
S2 |
+ — 0 |
S3 |
+ — 0 |
S4 |
|
1011 |
+ 0 — |
S1 |
+ 0 — |
S2 |
+ 0 — |
S3 |
+ 0 — |
S4 |
|
1110 |
0 + — |
S1 |
0 + — |
S2 |
0 + — |
S3 |
0 + — |
S4 |
|
1001 |
+ — + |
S2 |
+ — + |
S3 |
+ — + |
S4 |
— — — |
S1 |
|
0011 |
0 0 + |
S2 |
0 0 + |
S3 |
0 0 + |
S4 |
— — 0 |
S2 |
|
1101 |
0 + 0 |
S2 |
0 + 0 |
S3 |
0 + 0 |
S4 |
— 0 — |
S2 |
|
1000 |
+ 0 0 |
S2 |
+ 0 0 |
S3 |
+ 0 0 |
S4 |
0 — — |
S2 |
|
0110 |
— + + |
S2 |
— + + |
S3 |
— — + |
S2 |
— — + |
S3 |
|
1010 |
+ + — |
S2 |
+ + — |
S3 |
+ — — |
S2 |
+ — — |
S3 |
|
1111 |
+ + 0 |
S3 |
0 0 — |
S1 |
0 0 — |
S1 |
0 0 — |
S3 |
|
0000 |
+ 0 + |
S3 |
0 — 0 |
S1 |
0 — 0 |
S2 |
0 — 0 |
S3 |
|
0101 |
0 + + |
S3 |
— 0 0 |
S1 |
— 0 0 |
S2 |
— 0 0 |
S3 |
|
1100 |
+ + + |
S4 |
— + — |
S1 |
— + — |
S2 |
— + — |
S3 |
Схемы, которые не являются самосинхронизирующими, вместе с логическим кодированием и определением фиксированной длительности битовых интервалов разрешают достигать синхронизации. Старт-бит и стоп-бит служат для синхронизации, а контрольный бит вводит избыточность для повышения достоверности приема.
ГЛАВА 2 АНАЛИЗ МЕТОДОВ КОДИРОВАНИЯ ДАННЫХ В РАЗЛИЧНЫХ СФЕРАХ ДЕЯТЕЛЬНОСТИ
2.1 Кодирование графической информации
Скорость работы любого интернет-ресурса определяется целым рядом факторов. Однако наиболее значимым из них является мультимедийный контент, в частности графические изображения.
Высокое качество изображений, полученных цифровой фотокамерой, характеризуется большим разрешением (порядка 4000 х 3000, т.е. 8 мегапикселей) и глубиной цвета 24 бита на пиксель. Технические характеристики профессиональных фотоаппаратов, которые набирают популярность среди рядовых потребителей, позволяют делать снимки с глубиной цвета 48 бит на пиксель, из-за чего размер фотоснимка может превышать 200 мегабайт. Таким образом, на первый план выходит проблема сжатия изображений. Основные форматы сжатия изображений имеют ряд недостатков[1], которые можно устранить за счет модификации существующих алгоритмов сжатия изображений.
Существующие методы сжатия изображений основаны на предположении об избыточности графических данных. Исходя из этого, сжатие графической информации достигается за счет поиска и преобразования избыточных данных[2]. Поток данных об изображении имеет существенное количество излишней информации, которая может быть устранена практически без заметных для глаза искажений.
Эта особенность обуславливает цель исследования: оптимизация скорости работы веб-ресурса за счет использования сжатых изображений. Основной задачей является модификация существующего алгоритма RLE для более эффективного сжатия изображений.
Существующие алгоритмы сжатия данных без потерь широко применяются сегодня в веб-программировании, однако имеют ряд недостатков.
Алгоритм Лемпеля-Зива (LZ-compression) является основой целого семейства алгоритмов словарного сжатия данных[3]. В его основе лежит упаковщик, который содержит в себе определенное число символов в буфере. Используя поиск по словарю, находят самую длинную подстроку входного потока, которая совпадает с одной из подстрок, находящихся в буфере, после чего выводят индекс подстроки, вычтенный из размера буфера. В случае отсутствия совпадений, в выходной поток символов копируется следующий символ и т.д.
Не смотря на простоту алгоритма, при поиске совпадений он подразумевает перебор всех символов, находящихся в буфере, за счет чего увеличивается время сжатия.
Стандарт сжатия изображений JPEG включает два способа сжатия: первый предназначен для сжатия без потерь, второй – сжатия с потерей качества. Метод сжатия без потерь, используемый в стандарте lossless JPEG основан на методе разностного (дифференциального) кодирования. Основная идея дифференциального кодирования состоит в следующем. Обычно изображения характеризуются сильной корреляцией между точками изображения. Этот факт учитывается при разностном кодировании, а именно, вместо сжатия последовательности точек изображения x1,x2,....xn, сжатию подвергается последовательность разностей yi=xi-xi-1, i=1,2,...N, x0=0. Числа yi называют ошибками предсказания xi. В стандарте losslessJPEG предусмотрено формирование ошибок предсказания с использованием предыдущих закодированных точек в текущей строке и\или в предыдущей строке. Lossless JPEG рекомендуется применять в тех приложениях, где необходимо побитовое соответствие исходного и разархивированного изображений.
Для текстовых файлов чаще других употребляется кодировка Хаффмана, заключающаяся в том, что символы текста заменяются цепочками бит разной длины. Методика Хаффмана гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву[4]. Применительно к сжатию изображений в основе такого метода лежит учет частоты появления одинаковых байт в изображении. При этом пикселям исходного изображения, которые встречаются большее число раз, сопоставляется код меньшей длины, а встречающимся редко - код большей длины (т.е. формируется префиксный код переменной длины). Для сбора статистики требуется два прохода по файлу - один для просмотра и сбора 16 статистической информации, второй - для кодирования. Коэффициенты сжатия: 1/8, 2/3, 1. При использовании такого метода требуется запись в файл и таблицы соответствия кодируемых пикселов и кодирующих цепочек. Такое кодирование применяется в качестве последнего этапа архивации в JPEG. Методы Хаффмана дают достаточно высокую скорость и умеренно хорошее качество сжатия. Основным недостатком данного метода является зависимость степени сжатия от близости вероятностей символов к величине 2-м, поскольку каждый символ кодируется целым числом бит. Так, при кодировании данных с двухсимвольным алфавитом сжатие всегда отсутствует, т.к. несмотря на различные вероятности появления символов во входном потоке алгоритм фактически сводит их до 1/2. Такой алгоритм реализован в формате TIFF.
Наиболее известный и простой алгоритм сжатия информации обратимым путем - это кодирование серий последовательностей (Run Length Encoding - RLE)[5]. Суть данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений. К положительным сторонам алгоритма, пожалуй, можно отнести только то, что он не требует дополнительной памяти при работе, и быстро выполняется. Данный метод, как правило, достаточно эффективен для сжатия растровых графических изображений (BMP, PCX, TIFF), т.к. последние содержат достаточно длинные серии повторяющихся последовательностей байтов.
Недостатком метода RLE является достаточно низкая степень сжатия или стоимость кодирования файлов с малым числом серий и, что еще хуже - с малым числом повторяющихся байтов в сериях. Проблема всех аналогичных методов заключается лишь в определении способа, при помощи которого распаковывающий алгоритм мог бы отличить в результирующем потоке байтов кодированную серию от других - некодированных последовательностей байтов.
Для повышения эффективности работы RLE-алгоритма предлагается использовать реализацию классического решения, основанную на простановке меток (служебных байт) вначале кодированных цепочек. Один бит выделяется под тип последовательности (одиночный символ или серия), а в оставшихся 7 битах хранится длина последовательности. Таким образом, максимальная длина кодируемой последовательности – 127 байт. Однако есть два важных момента, на которые стоит обратить внимание. Не может быть последовательностей с нулевой длиной. Для решения этой проблемы можно увеличить максимальную длину до 128 байт, отнимая от длины единицу при кодировании и прибавляя при декодировании. Второе, что можно заметить – не бывает последовательностей одинаковых элементов единичной длины[6]. Поэтому, от значения длины таких последовательностей при кодировании мы будем отнимать ещё единичку, увеличив тем самым их максимальную длину до 129 (максимальная длина цепочки одиночных элементов по-прежнему равна 128). Таким образом, цепочки одинаковых элементов могут иметь длину от 2 до 129.
При кодировании изображений с большими одноцветными областями (а значит с большими последовательностями повторяющихся байт) возможным улучшением может являться использование цепочек переменной длины (Рис. 1).
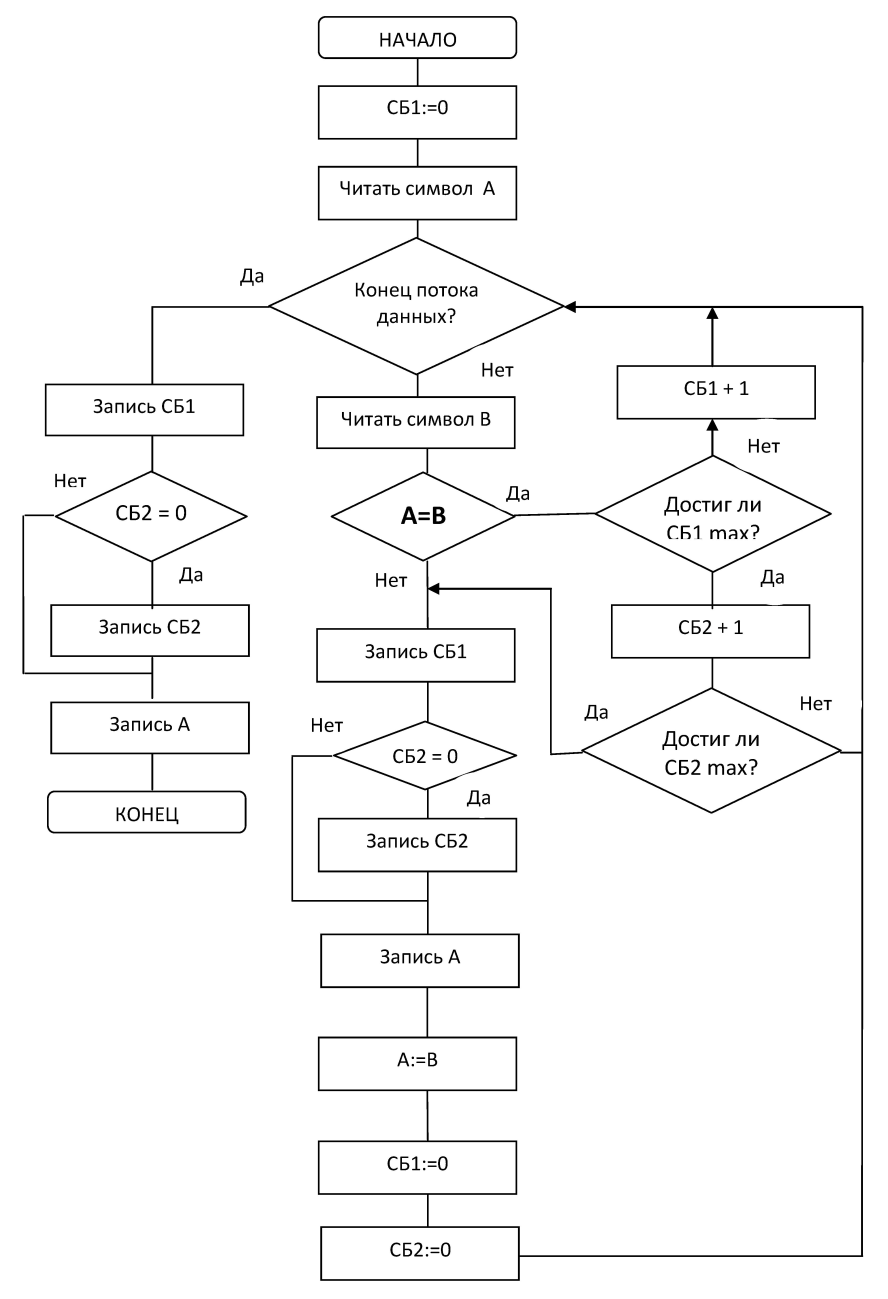
Рис. 1. Схема модифицированного RLE-алгоритма
На битовом уровне в служебном байте СБ1 (Рис.1) выделяется ещё один бит под индикацию длинной цепочки. Если индикатор выставлен в единицу, то добавляется ещё один служебный байт СБ2, который хранит в себе длину цепочки. Таким образом, уменьшается длина коротких цепочек (65 элементов вместо 129), однако появляется возможность всего тремя байтами закодировать цепочки длиною до 16386 элементов (214 + 2).
За счет описанной модификации коэффициент сжатия классического RLE алгоритма может быть увеличен в 128 раз, что повышает эффективность сжатия изображений и скорость работы интернет-ресурса. Предложенная реализация алгоритма RLE применима к изображениям с длинными последовательностями повторяющихся байтов (с большими областями, заполненными одним цветом): чертежам, схемам, диаграммам, рекламной и деловой графике.
2.2 Применение циклического кодирования
Циклические коды нашли свое применение при передаче информации по каналам связи. Стандартами международных организаций ITU-T и МОС установлено, что вероятность ошибки при телеграфной связи не должна превышать 3*10-5 на знак, а при передаче данных – 10-6 на единичный элемент, бит. На практике допустимая вероятность ошибки при передаче данных может быть еще меньше – 10-9. Однако возможности каналов связи часто не соответствуют требованиям, предъявляемым к верности принимаемой информации. Каналы связи, особенно проводные каналы большой протяженности и радиоканалы, обеспечивают вероятность ошибки на уровне 10-3...10-4 даже при использовании устройств, улучшающих качество каналов связи.
Одним из способов снижения вероятности ошибок при приеме является введение избыточности в передаваемую информацию. В системах передачи информации без обратной связи этот способ реализуется в виде многократной передачи информации, одновременной передачи информации по нескольким параллельно работающим каналам или помехоустойчивого кодирования. Помехоустойчивое кодирование позволяет обойтись меньшей избыточностью, за счет чего повышается скорость передачи информации.
Помехоустойчивый код характеризуется тройкой чисел ( n, k, d0 ), где n – общее число разрядов в передаваемом сообщении, включая проверочные, k – число информационных разрядов, d0 – минимальное кодовое расстояние между разрешенными кодовыми комбинациями. Число обнаруживаемых и/или исправляемых ошибок связано с минимальным кодовым расстоянием соотношениями:
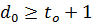 (1)
(1)
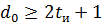 (2)
(2)
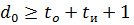 (3)
(3)
где: tо – число обнаруживаемых ошибок,
tи – число исправляемых ошибок.
Циклические коды – это подкласс линейных кодов, коды которого удовлетворяют следующим циклическим свойствам: если 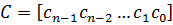 - кодовое слово кода, тогда
- кодовое слово кода, тогда 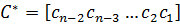 полученное циклическим сдвигом элементов кода C, также являются кодовым словом. Все циклические сдвиги слова С образуют кодовые слова.
полученное циклическим сдвигом элементов кода C, также являются кодовым словом. Все циклические сдвиги слова С образуют кодовые слова.
Благодаря циклическим свойствам, циклические коды являются достаточно легко реализуемыми технически. И потому они нашли широкое применение.
Алгоритм контрольного суммирования
Алгоритм контрольного суммирования CRC -Cyclic redundancy check- предназначается для контроля целостности данных. Он широко используется в проводных и беспроводных сетях, в устройствах хранения данных, для проверки информации на подлинность и защиты от несанкционированного изменения. В универсальной последовательной шине USB каждый пакет имеет поля CRC, позволяющие обнаруживать все однократные и двукратные битовые ошибки.
CRC предназначен не для исправления ошибок, а для их обнаружения.
Результатом контрольного суммирования CRC является остаток от деления многочлена, соответствующего исходным данным, на порождающий многочлен фиксированной длины. Порождающий многочлен g(x) задаёт конкретный код CRC.
На основе теории кодирования, а также многочисленных исследований были найдены различные порождающие многочлены для CRC. Причем существуют различные полиномы одной разрядности.
Примеры использования наиболее популярных порождающих многочленов алгоритма CRC:
CRC-8: x8 + x7 + x6 + x4 + x2 + 1 – используется формой Dallas Semiconductor в устройствах низкоскоростной связи.
CRC-16-IBM (CRC-16 или CRC-16-ANSI): x16 + x15 + x2 + 1 – используется в ANSI X3.28, в интерфейсах USB, ModBus и других линиях связи.
CRC-32: x32 + x26 + x23 + x22 + x16 + x12 + x11 + x10 + x8 + x7 + x5 + x4 + x2 + x + 1 – используется при кодировании видео и аудио сигналов с использованием стандарта MPEG-2, при кодировании растровых изображений в формате PNG и во многих других случаях.
Отметим, что приведенные порождающие многочлены не являются единственными для CRC-8, CRC-16, CRC-32. Разные полиномы для одних и тех же CRC используются для разных технологий и в разных стандартах.
Коды Боуза-Чоудхури-Хоквингема (БЧХ).
Перспективными с точки зрения аппаратурной реализации представляются коды БЧХ. Коды БЧХ длины примерно до n=1023 оптимальны или близки к оптимальным кодам. БЧХ-коды представляют большой класс циклических кодов как с двоичным, так и с недвоичным алфавитами.
Этот класс двоичных кодов позволяет исправлять ошибки. Причем метод построения этих кодов задан явно.
Коды БЧХ отличается возможностью построения кода с заранее определёнными корректирующими свойствами, а также предоставляет разработчику систем связи широкий выбор длин блока и скоростей кода. БЧХ-коды могут исправлять произвольное количество ошибок. Однако с ростом кратности ошибки значительно возрастает длина кода, что ведет к уменьшению скорости передачи и усложнению приемно-передающей аппаратуры.
БЧХ-код можно задать порождающим полиномом. Для его нахождения в необходимо заранее определить длину кода n и требуемое минимальное расстояние 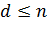 .
.
Порождающие полиномы для БЧХ кодов можно конструировать из множителей полинома 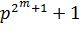 .
.
Общий список порождающих полиномов для БЧХ кодов дан Питерсоном и Уэлдоном, которые дали таблицы множителей полиномов 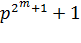 для
для 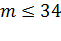 .
.
БЧХ-коды уже нашли практическое применение в цифровых системах записи звука, речи и музыки. При этом предусматривается исправление обнаруженных ошибок.
Коды Рида-Соломона
Частным случаем БЧХ-кода являются коды Рида-Соломона.
Коды Рида-Соломона – это недвоичные циклические коды, предназначенные для исправления пачек ошибок.
Коды Рида-Соломона применяются в сфере цифровых коммуникаций, а также при построении запоминающих устройств. Например, эти коды используются в помехоустойчивом кодировании, в беспроводных или мобильных коммуникациях, спутниковых коммуникациях, в цифровом телевидении, при создании архивов с информацией для восстановления в случае повреждений.
Благодаря кодам Рида-Соломона можно прочитать компакт-диск с множеством царапин. Для компакт-диска избыточность кода в среднем составляет примерно 25 %. Восстанавливаемое количество данных равно половине избыточных. Так, если емкость диска 700 Мб, то количество избыточных данных составит 175 Мб. Таким образом, теоретически можно восстановить до 87,5 Мб из 700 Мб. При этом нам не обязательно знать, какой именно символ передан с ошибкой.
ЗАКЛЮЧЕНИЕ
В результате исследования по теме «Метолы кодирования данных» был проведен анализ литературы, статьей по исследуемой теме, изучена нормативная документация, спроектировано и реализовано программное приложение.
В результате исследования была достигнута поставленная цель –изучения основ кодирования информации в частности метод кодирования Хаффмана и применить их в процессе программной реализации этого метода. Цель курсовой работы достигнута за счёт выполнения следующих задач.
Рассмотрены основные понятия и принципы кодирования информации;
Изучен метод кодирования Хаффмана.
Изучены алгоритмы кодирования информации для реализации программного продукта «Код Хаффмана», с использованием современной технологии программирования;
После выполнения целей и задач курсовой работы были сделаны следующие выводы.
Проблема кодирования информации, имеет достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
До появления работ Шеннона, Фано а позже и Хаффмана, кодирование символов алфавита при передаче сообщения по каналам связи осуществлялось одинаковым количеством бит, получаемым по формуле Хартли. С появлением этих работ начали появляться способы, кодирующие символы разным числом бит в зависимости от вероятности появления их в тексте, то есть более вероятные символы кодируются короткими кодами, а редко встречающиеся символы - длинными (длиннее среднего).
Преимуществами данных методов являются их очевидная простота реализации и, как следствие этого, высокая скорость кодирования и декодирования. Основным недостатком является их не оптимальность в общем случае.
Таким образом, поставленные цели и задачи работы достигнуты, однако данная работа может быть усовершенствована и продолжена в других аспектах.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Алгоритмы LZW, LZ77 и LZ78 [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/?oldid= 68967235.- (Дата обращения: 10.02.2017).
- Алгоритмы сжатия RLE и LZ77 [Электронный ресурс]. – Режим доступа: http://habrahabr.ru/post/141827/. - (Дата обращения: 09.02.2017).
- Бернард Скляр. Цифровая связь. Теоретические основы и практическое применение. Изд. 2-е, испр.: Пер. с англ. – М.: Издательский дом «Вильямс», 2013. – 1104 с., ил. – Парал. тит. англ.
- Вильям Столлингс. Компьютерные системы передачи данных, 6-е издание. : Пер. с англ. – М.: Издательский дом «Вильямс», 2016. – 928 с., ил. – Парал. тит. англ.
- Волков В.Б. Информатика / В.Б. Волков, Н.В. Макарова – СПб.: Питер, 2011 – 576с.
- Галисеев Г.В. Программирование в среде Delphi 7 / Г.В. Галисеев – М.: Вильямс, 2014. – 288с.
- Дж. Ирвин, Д. Харль. Передача данных в сетях: инженерный подход. Пер. с англ. – СПб.: БХВ – Петербург, 2013. – 448 с., ил.
- Иванова Г.С. Технология программирования / Г.С. Иванова – М.: Изд-во МГТУ им. Н.Э. Баумана, 2014. – 320с.
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений / С. Канер, Д. Фолк, Е.К Нгуен – Киев: ДиаСофт, 2015. – 544с.
- Карпенко А.С., Крысова И.В. Использование графического формата MNG для сжатия изображений в веб-программирвании. – Информационные технологии в науке и производстве : материалы молодежной науч.-техн. конф.– Омск : Изд-во ОмГТУ, 2015. С. 91-94.
- Майерс Г. Искусство тестирования программ / Г. Майерс, Т. Баджетт, К. Сандлер – М.: «Диалектика», 2012 – 272с.
- Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев – М.: Омега-Л, 2017 – 458с.
- Методы сжатия цифровой информации [Электронный ресурс]. - Режим доступа: http://eae-1.clan.su/informat/dist/lekcija.pdf.- (Дата обращения: 10.02.2017).
- Новиков Ю.В., Карпенко Д.Г. Аппаратура локальных сетей: функции, выбор, разработка. / Под общей редакцией Ю.В. Новикова. – М.: Издательство ЭКОМ, 2016.–288 с.,ил.
- Савельев Б.А. Повышение достоверности передачи и хранения информации в компьютерных сетях: Учебное пособие. – Пенза: Изд-во Пенз. гос. ун-та, 2016. – 80 с., ил.
- Тропченко А.Ю., Тропченко А.А. Методы сжатия изображений, аудиосигналов и видео. – СПб: СПбГУ ИТМО, 2009. – 108 с.
- Тропченко А.Ю., Тропченко А.А. Методы сжатия изображений, аудиосигналов и видео. – СПб: СПбГУ ИТМО, 2009. – 108 с.
-
Карпенко А.С., Крысова И.В. Использование графического формата MNG для сжатия изображений в веб-программирвании. – Информационные технологии в науке и производстве : материалы молодежной науч.-техн. конф.– Омск : Изд-во ОмГТУ, 2015. С. 91-94. ↑
-
Тропченко А.Ю., Тропченко А.А. Методы сжатия изображений, аудиосигналов и видео. – СПб: СПбГУ ИТМО, 2009. – 108 с. ↑
-
Алгоритмы LZW, LZ77 и LZ78 [Электронный ресурс]. — Режим доступа: http://ru.wikipedia.org/?oldid= 68967235.- (Дата обращения: 10.02.2017). ↑
-
Тропченко А.Ю., Тропченко А.А. Методы сжатия изображений, аудиосигналов и видео. – СПб: СПбГУ ИТМО, 2009. – 108 с. ↑
-
Методы сжатия цифровой информации [Электронный ресурс]. - Режим доступа: http://eae-1.clan.su/informat/dist/lekcija.pdf.- (Дата обращения: 10.02.2017). ↑
-
Алгоритмы сжатия RLE и LZ77 [Электронный ресурс]. – Режим доступа: http://habrahabr.ru/post/141827/. - (Дата обращения: 09.02.2017). ↑

- Разработка регламента выполнения процесса «Контроль поставок товара» (1. Аналитическая часть)
- Бренд как конкурентное преимущество компании (на примере ОАО «Хлебный дом»)
- Оборотные активы предприятия (ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ УПРАВЛЕНИЯ ОБОРОТНЫМИ АКТИВАМИ (1.1. Сущность оборотных активов и их значение для компании))
- Менеджмент человеческих ресурсов (Глава 1 Теоретические основы менеджмента человеческих ресурсов)
- Доходы и расходы бюджетов публичных образований (1 Теоретические аспекты финансирования бюджетов муниципальных образований)
- ПРОЕКТИРОВАНИЕ РЕАЛИЗАЦИИ ОПЕРАЦИЙ БИЗНЕС-ПРОЦЕССА «РЕАЛИЗАЦИЯ БИЛЕТОВ ЧЕРЕЗ РОЗНИЧНЫЕ КАССЫ» (1. Аналитическая часть)
- Изучение правил и методик выбора и формирования собственного предприятия, разработка бизнес-плана для успешного начала нового бизнеса
- Изучение особенностей управления организациями в современных условиях и нахождение путей его совершенствования
- Психологические основы бизнес-тренинга как метод профессионального обучения (Глава 1. Теоретические аспекты бизнес-тренинга)
- Процессы принятия решений в организации (Глава 1. Теоретические основы принятия решений в организации)
- Выбор стиля руководства в организации (1. Теоретические аспекты использования различных стилей руководства в организации)
- Средства разработки клиентских программ (ГЛАВА 1. АНАЛИЗ СУЩЕСТВУЮЩИХ РЕШЕНИЙ)