
Кодирования информации ( Основы и основные понятия кодирования информации )
Содержание:

Введение
Кодирования информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблемы сжатие и шифровки информации.
Все алгоритмы кодирования оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт.
Кодирование Хаффмана является простым алгоритмом для построения кодов переменной длины, имеющих минимальную среднюю длину. Этот весьма популярный алгоритм служит основой многих компьютерных программ сжатия текстовой и графической информации. Некоторые из них используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса сжатия. Метод Хаффмана производит идеальное сжатие (то есть, сжимает данные до их энтропии), если вероятности символов точно равны отрицательным степеням числа 2. Алгоритм начинает строить кодовое дерево снизу вверх, затем скользит вниз по дереву, чтобы построить каждый индивидуальный код справа налево (от самого младшего бита к самому старшему). Начиная с работ Д. Хаффмана 1952 года, этот алгоритм являлся предметом многих исследований.
Коды Хаффмана преподаются во всех технических ВУЗах мира и, кроме того, входят в программу для углубленного изучения информатики в школе.
Поэтому изучение кодирования информации и методов кодирования, в частности метода кодирования Хаффмана является актуальным.
Объект исследования: кодирование и методы кодирования информации.
Предмет исследования: кодирование данных.
Целью данной работы является анализ методов кодирования данных. Данная цель обусловила выделение следующих задач:
- рассмотреть теоретические аспекты кодирования информации;
- провести анализ обеспечения секретности передачи данных в беспроводных сетях с сетевым кодированием.
Структура работы состоит из введения, основной части, заключения и списка литературы.
Теоретической и методологической базой данной работы послужили труды российских и зарубежных авторов в области информатики, материалы периодических изданий и сети Интернет.
Глава 1. Теоретические аспекты кодирования информации
1.1 Основы и основные понятия кодирования информации
Рассмотрим основные понятия, связанные с кодированием информации. Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении. Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями.
Кодирование - это преобразование сообщений в сигнал, т.е. преобразование сообщений в кодовые комбинации. Код - система соответствия между элементами сообщений и кодовыми комбинациями. Кодер - устройство, осуществляющее кодирование. Декодер - устройство, осуществляющее обратную операцию, т.е. преобразование кодовой комбинации в сообщение. Алфавит - множество возможных элементов кода, т.е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,..., m. Количество элементов кода - m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации - n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Цели кодирования:
1) Повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
2) Повышение помехоустойчивости при передаче данных.
В соответствии с этими целями теория кодирования развивается в двух основных направлениях:
1. Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи.
2. Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами.
Научные основы кодирования были описаны К. Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией.
Декодирование — процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке.
В более широком смысле декодирование — это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение — это декодирование.
Способ кодирования одного и того же сообщения может быть разным. Например, русский текст мы привыкли записывать с помощью русского алфавита. Но то же самое можно сделать, используя английский алфавит. Иногда так приходится поступать, посылая SMS по мобильному телефону, на котором нет русских букв, или отправляя электронное письмо на русском языке из-за границы, если на компьютере нет русифицированного программного обеспечения. Например, фразу: «Здравствуй, дорогой Саша!» приходится писать так: «Zdravstvui, dorogoi Sasha!».
Существуют и другие способы кодирования речи. Например, стенография — быстрый способ записи устной речи. Ею владеют лишь немногие специально обученные люди — стенографисты. Стенографист успевает записывать текст синхронно с речью говорящего человека. В стенограмме один значок обозначал целое слово или словосочетание. Расшифровать (декодировать) стенограмму может только стенографист.
Приведенные примеры иллюстрируют следующее важное правило: для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи — используем стенографию; если надо передать текст за границу — используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, — записываем его по правилам грамматики русского языка.
Еще одно важное обстоятельство: выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел — количественной информации. Используя русский алфавит, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, пишем: «35». Второй способ не только короче первого, но и удобнее для выполнения вычислений. Какая запись удобнее для выполнения расчетов: «тридцать пять умножить на сто двадцать семь» или «35 х 127»? Очевидно — вторая.
Однако если важно сохранить число без искажения, то его лучше записать в текстовой форме. Например, в денежных документах часто сумму записывают в текстовой форме: «триста семьдесят пять руб.» вместо «375 руб.». Во втором случае искажение одной цифры изменит все значение. При использовании текстовой формы даже грамматические ошибки могут не изменить смысла. Например, малограмотный человек написал: «Тристо семдесять пят руб.». Однако смысл сохранился.
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование — процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография.
Пусть имеется сообщение, записанное при помощи некоторого «алфавита», содержащего п «букв». Требуется «закодировать» это сообщение, т.е. указать правило, сопоставляющее каждому такому сообщению определенную последовательность из т различных «элементарных сигналов», составляющих «алфавит» передачи. Мы будем считать кодирование тем более выгодным, чем меньше элементарных сигналов приходится затратить на передачу сообщения. Если считать, что каждый из элементарных сигналов продолжается одно и то же время, то наиболее выгодный код позволит затратить на передачу сообщения меньше всего времени.
Главным свойством случайных событий является отсутствие полной уверенности в их наступлении, создающее известную неопределенность при выполнении связанных с этими событиями опытов. Однако совершенно ясно, что степень этой неопределенности в различных случаях будет совершенно разной. Для практики важно уметь численно оценивать степень неопределенности самых разнообразных опытов, чтобы иметь возможность сравнить их с этой стороны. Рассмотрим два независимых опыта  и
и а также сложный опыт
а также сложный опыт  , состоящий в одновременном выполнении опытов
, состоящий в одновременном выполнении опытов  и
и . Пусть опыт
. Пусть опыт  имеет k равновероятных исходов, а опыт
имеет k равновероятных исходов, а опыт  имеет l равновероятных исходов. Очевидно, что неопределенность опыта
имеет l равновероятных исходов. Очевидно, что неопределенность опыта  больше неопределенности опыта
больше неопределенности опыта , так как к неопределенности
, так как к неопределенности  здесь добавляется еще неопределенность исхода опыта
здесь добавляется еще неопределенность исхода опыта  . Естественно считать, что степень неопределенности опыта
. Естественно считать, что степень неопределенности опыта  равна сумме неопределенностей, характеризующих опыты
равна сумме неопределенностей, характеризующих опыты  и
и , т.е.
, т.е.
 .
.
Условиям:

 ,
, 
при  удовлетворяет только одна функция -
удовлетворяет только одна функция -  :
:
 .
.
Рассмотрим опыт А, состоящий из опытов  и имеющих вероятности
и имеющих вероятности  . Тогда общая неопределенность для опыта А будет равна:
. Тогда общая неопределенность для опыта А будет равна:

Это последнее число будем называть энтропией опыта  и обозначать через
и обозначать через  .
.
Если число букв в «алфавите» равно п, а число используемых элементарных сигналов равно т, то при любом методе кодирования среднее число элементарных сигналов, приходящихся на одну букву алфавита, не может быть меньше чем  ; однако он всегда может быть сделано сколь угодно близким к этому отношению, если только отдельные кодовые обозначения сопоставлять сразу достаточно длинными «блоками», состоящими из большого числа букв.
; однако он всегда может быть сделано сколь угодно близким к этому отношению, если только отдельные кодовые обозначения сопоставлять сразу достаточно длинными «блоками», состоящими из большого числа букв.
Мы рассмотрим здесь лишь простейший случай сообщений, записанных при помощи некоторых п «букв», частоты проявления которых на любом месте сообщения полностью характеризуется вероятностями р1, р2, … …, рп, где, разумеется, р1 + р2 + … + рп = 1, при котором вероятность pi проявления i-й буквы на любом месте сообщения предполагается одной и той же, вне зависимости от того, какие буквы стояли на всех предыдущих местах, т.е. последовательные буквы сообщения независимы друг от друга. На самом деле в реальных сообщениях это чаще бывает не так; в частности, в русском языке вероятность появления той или иной буквы существенно зависит от предыдущей буквы. Однако строгий учет взаимной зависимости букв сделал бы все дельнейшие рассмотрения очень сложными, но никак не изменит будущие результаты.
Мы будем пока рассматривать двоичные коды; обобщение полученных при этом результатов на коды, использующие произвольное число т элементарных сигналов, является, как всегда, крайне простым. Начнем с простейшего случая кодов, сопоставляющих отдельное кодовое обозначение – последовательность цифр 0 и 1 – каждой «букве» сообщения. Каждому двоичному коду для п-буквенного алфавита может быть сопоставлен некоторый метод отгадывания некоторого загаданного числа х, не превосходящего п, при помощи вопросов, на которые отвечается лишь «да» (1) или «нет» (0) , что и приводит нас к двоичному коду. При заданных вероятностях р1, р2, … …, рп отдельных букв передача многобуквенного сообщения наиболее экономный код будет тот, для которого при этих именно вероятностях п значений х среднее значение числа задаваемых вопросов (двоичных знаков: 0 и 1 или элементарных сигналов) оказывается наименьшим.
Прежде всего, среднее число двоичных элементарных сигналов, приходящихся в закодированном сообщении на одну букву исходного сообщения, не может быть меньше Н, где Н = - p1 log p1 – p2 log p2 - … - pn log pn – энтропия опыта, состоящего в распознавании одной буквы текста (или, короче, просто энтропия одной буквы). Отсюда сразу следует, что при любом методе кодирования для записи длинного сообщения из М букв требуется не меньше чем МН двоичных знаков, и никак не может превосходить одного бита.
Если вероятности р1, р2, … …, рп не все равны между собой, то Н < log n; поэтому естественно думать, что учет статистических закономерностей сообщения может позволить построить код более экономичный, чем наилучший равномерный код, требующий не менее М log n двоичных знаков для записи текста из М букв.
1.2 Классификация назначения и способы представления кодов
Коды можно классифицировать по различным признакам:
1. По основанию (количеству символов в алфавите): бинарные (двоичные m=2) и не бинарные (m № 2).
2. По длине кодовых комбинаций (слов): равномерные, если все кодовые комбинации имеют одинаковую длину и неравномерные, если длина кодовой комбинации не постоянна.
3. По способам передачи: последовательные и параллельные; блочные - данные сначала помещаются в буфер, а потом передаются в канал и бинарные непрерывные.
4. По помехоустойчивости: простые (примитивные, полные) - для передачи информации используют все возможные кодовые комбинации (без избыточности); корректирующие (помехозащищенные) - для передачи сообщений используют не все, а только часть (разрешенных) кодовых комбинаций.
В зависимости от назначения и применения условно можно выделить следующие типы кодов:
Внутренние коды - это коды, используемые внутри устройств. Это машинные коды, а также коды, базирующиеся на использовании позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Наиболее распространенным кодом в ЭВМ является двоичный код, который позволяет просто реализовать аппаратное устройства для хранения, обработки и передачи данных в двоичном коде. Он обеспечивает высокую надежность устройств и простоту выполнения операций над данными в двоичном коде. Двоичные данные, объединенные в группы по 4, образуют шестнадцатеричный код, который хорошо согласуется с архитектурой ЭВМ, работающей с данными кратными байту (8 бит).
Коды для обмена данными и их передачи по каналам связи. Широкое распространение в ПК получил код ASCII (American Standard Code for Information Interchange). ASCII - это 7-битный код буквенно-цифровых и других символов. Поскольку ЭВМ работают с байтами, то 8-й разряд используется для синхронизации или проверки на четность, или расширения кода. В ЭВМ фирмы IBM используется расширенный двоично-десятичный код для обмена информацией EBCDIC (Extended Binary Coded Decimal Interchange Code). В каналах связи широко используется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модификации (МТК и др.).
При кодировании информации для передачи по каналам связи, в том числе внутри аппаратным трактам, используются коды, обеспечивающие максимальную скорость передачи информации, за счет ее сжатия и устранения избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие достоверность передачи данных, за счет введения избыточности в передаваемые сообщения (например: групповые коды, Хэмминга, циклические и их разновидности).
Коды для специальных применений - это коды, предназначенные для решения специальных задач передачи и обработки данных. Примерами таких кодов является циклический код Грея, который широко используется в АЦП угловых и линейных перемещений. Коды Фибоначчи используются для построения быстродействующих и помехоустойчивых АЦП.
В зависимости от применяемых методов кодирования, используют различные математические модели кодов, при этом наиболее часто применяется представление кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д. Рассмотрим основные способы представления кодов.
Матричное представление кодов. Используется для представления равномерных n - значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n - столбцов и 2n - строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n - столбцов (n = k+m, где k-число информационных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
Представление кодов в виде кодовых деревьев. Кодовое дерево - связной граф, не содержащий циклов. Связной граф - граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях. Для построения дерева равномерного двоичного кода выбирают вершину называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
1.3 Кодирование данных при беспроводной передачи информации
Основным отличием беспроводных сетей от проводных является то, что среда передачи данных совершенно открыта любому желающему, поэтому заинтересованному злоумышленнику ничего не стоит получить необходимую информацию, имея доступ к среде, в частности, он может узнать, какие узлы сети общаются между собой. Для обеспечения безопасности передачи было предложено и реализовано много подходов. Одним из самых известных сейчас, например, является протокол WPA2, позволяющий ограничивать доступ злоумышленника в Wi-Fi сеть путём создания секретного ключа и распространением его между легитимными пользователями сети. Однако в случае, когда злоумышленник завладел этим секретным ключом, безопасность передачи остаётся под угрозой. Далее мы будем рассматривать более узкую задачу — не секретность передачи информации в целом, а лишь обеспечение анонимности передачи.
Существует несколько задач, объединяемых общим названием «обеспечением анонимности», среди них выделяют [1]:
• Обеспечение анонимности отправителя и получателя — данный вид анонимности не позволяет злоумышленнику определить, кто отправляет сообщение, а кто является конечным получателем, допуская, однако, видеть, как пакет перемещается от узла к узлу, а также видеть сам факт наличия пакета.
- Сокрытие маршрута передачи — данный вид анонимности не позволяет злоумышленнику определить маршрут конкретного пакета, т.е. список узлов, через которые он проходит, допуская тем не менее увидеть наличие такого пакета где-то в сети.
- Сокрытие факта передачи данных — данный вид анонимности не позволяет злоумышленнику определить наличие факта передачи, например, не давая отличить передачу реальных данных от белого шума.
В данном параграфе мы будем рассматривать подход к решению задачи первого типа. Для этого будем рассматривать метод COPE (Coding Opportunistically), центральной идеей которого является разбиение оригинального сообщения на части и передача его по частям через промежуточные узлы. Этот метод применялся для достижения более плотного использования полосы пропускания и повышение скорости передачи.
Мы же воспользуемся этим методом, модифицировав его таким образом, чтобы после разделения сообщения (включающего адрес получателя) на части, одна из частей была недоступна никому, кроме получателя. В этом случае сторонний наблюдатель (в том числе и злоумышленник) не сможет получить доступ к оригинальному сообщению (либо доступ будет значительно затруднён), а значит, и к указанию того, кому предназначался пакет. В данной работе рассматривается способ, в течение определённого времени обеспечивающий анонимность отправителя и получателя.
Глава 2 Анализ Обеспечения секретности передачи данных в беспроводных сетях с сетевым кодированием
2.1 Метод COPE
Метод COPE [2] использует три механизма для повышения эффективности использования среды:
- гибкое прослушивание (Opportunistic Listening) — механизм, обеспечивающий сохранение всех пакетов, которые проходили через данный узел или были «услышаны» узлом на сети, даже если они не предназначены ему, в специальный буфер в течение некоторого времени (время хранения по умолчанию — 0.5 c). Также каждый узел широковещательно рассылает отчёты о получении, содержащие информацию о том, какие пакеты были сохранены и подслушаны;
- определение состояния соседних узлов (Learning Neighbour State) — метод, осуществляющий определение списка пакетов, которые есть в буферах соседних узлов. Механизм определения состояния основан на вычислении метрики EXT [5], которая назначается каждой паре узлов и характеризует вероятность успешной передачи данных между ними. Таким образом, каждый узел хранит таблицу для каждого соседнего узла и заполняет её, занося в неё пакеты и вероятность успешного получения этих пакетов;
- гибкое кодирование (Opportunistic Coding) — метод, отвечающий за правильный выбор линейной комбинации пакетов на основании данных, полученных при помощи остальных механизмов.
Утверждение 1. Узел-источник может переслать п пакетов Р\,... ,Рп п соседним узлам п,... ,гп — каждый пакет своему получателю — в рамках одной передачи объединив пакеты, тогда и только тогда, когда любой rj уже имеет все пакеты, кроме Pj. [3]
Утверждение 1 характеризует принцип работы гибкого кодирования, согласно которому пакеты посылаются не поочерёдно, занимая ячейку времени на каждый пакет, а образуется линейная комбинация из нескольких пакетов, которая посылается широковещательно всем получателям, что позволяет передать ту же информацию за меньшее число передач, что позволяет уменьшить занятость канала.
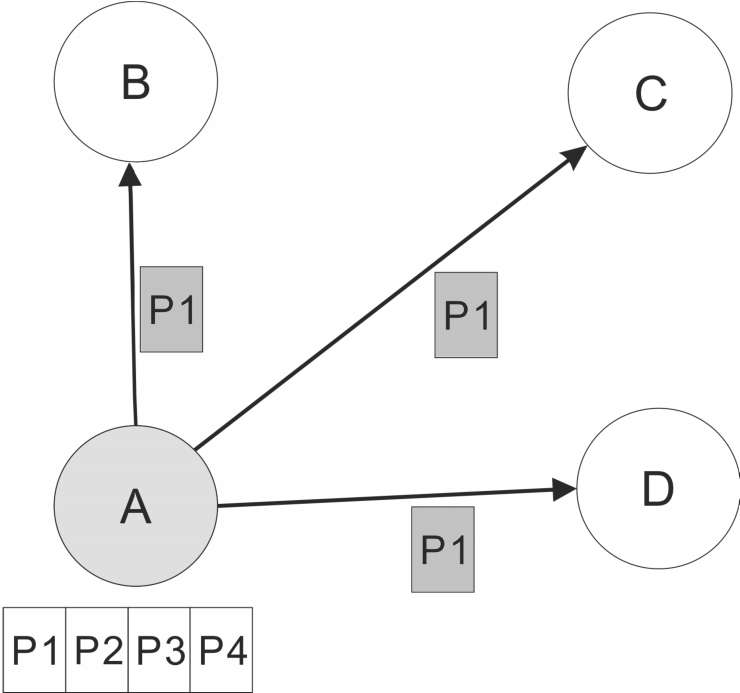
Рис. 2.1. Иллюстрация передачи пакетов по методу COPE: начальное состояние сети
Рассмотрим сеть, структура которой изображена на рис. 2.1.
На схеме изображен источник А и три получателя — В, С и D. На источнике содержится четыре пакета Р1 ,Р2,Р3,Р4, подлежащих пересылке. Рассмотрим задачу, в которой цель А — передать все пакеты на узел В и D. Рассмотрим процедуру передачи по шагам.
На первом шаге, изображенном на рис. 2.1, узел A пытается передать пакет P1 узду В. При этом, несмотря на то, что основной получатель этого пакета — узел В, узлы С и D также находится в зоне передачи и способны подслушать передаваемые данные, используя гибкое прослушивание. Пусть в процессе передачи произошла ошибка, и узел С не смог корректно принять Р1. После окончания передачи пакета Р1, узлы В и D рассылают подтверждение получения пакета, что даёт А возможность понять, что до С пакет не дошел.
Согласно методике COPE, подверждения получения пакета рассылаются каждым узлом асинхронно либо в момент передачи им какого-то пакета, либо, если узел не передаёт информацию, регулярными отдельными пакетами. При этом для уменьшения избыточности передачи подтверждений используется следующий подход: в заголовок каждого пакета вставляются дополнительные поля, содержащие идентификатор последнего полученного пакета и битовую карту, содержащую информацию о предыдущих полученных пакетах. Так, например, заголовок {Р4, 011} содержит информацию о том, что последним был получен пакет Р4, до него были получены пакеты Р1 и Р2, а пакет Р3 получен не был. Такой подход обеспечивает возможность подтверждать пакеты несколько раз без больших накладных расходов, таким образом обеспечивая защиту от возможных потерь пакетов с подтверждениями.
Второй шаг передачи изображен на рис. 2а. Теперь узел А передаёт очередной пакет — Р2 узлу D. При этом, как и на первом шаге, узлы В и D находятся в зоне передачи и могут подслушать передаваемый пакет. На этот раз ошибка случается при приёме пакета узлом D — отправитель узнал об этом, не получив подтверждение получения за определённое время. Аналогичным образом происходит передача пакета Р3 узлу В на рис. 2б — за исключением того, что на этот раз узел В не смог принять пакет.
Далее, на четвёртом шаге (рис. 3а) отправитель А, воспользовавшись утвеждением 1, применяет гибкое кодирование, чтобы передать недостающие пакеты всем трём узлам одновременно. Действительно, для передачи 3 пакетов Р1, Р2, Р3 получателям B,C,D необходимо и достаточно, чтобы каждый из получателей имел ровно два пакета из списка передаваемых — что выполняется, поэтому, создав линейную комбинацию Р1 0 Р2 0 Р3, отправитель может за одну трансмиссию передать сразу три пакета трём получателям, каждый из которых сможем успешно декодировать нужный пакет. После получения пакета, каждый узел, как и ранее, передаёт подтверждение получения.
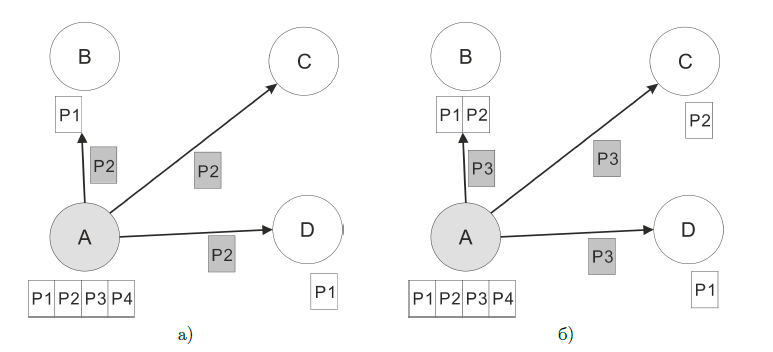
Рис. 2.2. Иллюстрация передачи пакетов по методу COPE: продолжение

Рис. 2.3. Иллюстрация передачи пакетов по методу COPE: окончание передачи
И, наконец, на последнем шаге (рис. 3б), передаёт пакет Р4 узлу D, который также будет услышан узлами D и С. На этот раз передача прошла успешно для каждого узла и после окончания этой передачи узлы В и D будут обладать пакетами Р1 ,Р2,Р3,Р4, а значит, отправитель достиг своей цели.
Таким образом, используя на каждом шаге вышеописанные механизмы, отправитель способен более плотно использовать среду, что приводит к увеличению пропускной способности канала. Однако в силу открытости передачи данных пассивный злоумышленник, заняв любой узел, может беспрепятственно прослушивать передачи в сети и понимать отправителя и получателя сообщений.
2.2 Сетевое кодирование
Теперь перейдём к изменениям, которые позволят нам воспользоваться рассмотренным методом для обеспечения анонимности. Для этого адрес получателя помещается внутрь сообщения, и оно разбивается на п частей, каждая из которых затем будет передаваться по отдельности, однако одна из частей не будет передаваться по сети. В дальнейшем будем называть эту часть «секретной частью» или «секретным пакетом».
В данной работе рассматривается способ выбора «секретной» части таким образом, чтобы её можно было независимо сгенерировать как на узле-отправителе, так и на узле- приёмнике, однако генерация этой части на любом другом узле представляет большую вычислительную сложность. Тогда, в силу того, что адрес получателя находится в теле сообщения, разбитого на несколько частей, злоумышленник, не имея полного пакета, не сможет выделить интересующую его информацию.
Рассмотрим два способа разбиения сообщения на части.
В первом способе будем считать, что передаваемое сообщение есть подпространство в расширенном поле GF(рп). В таком случае это сообщение представимо как набор из к базисных векторов подпространства, а значит, представимо в матричном виде в простом поле GFp, где каждая строка является представлением базисного вектора. Далее отправитель транспонирует получившуюся матрицу P [4]. Тогда мы можем записать её в следующем виде:
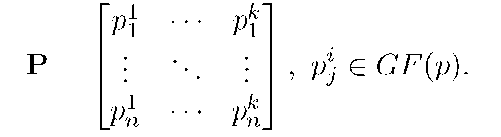
В дальнейшем будем рассматривать каждую строку получившейся транспонированной матрицы как отдельный пакет и будем рассылать их независимо. Перед началом рассылки создадим секретный пакет po и «зашумим» передаваемые пакеты следующим образом:
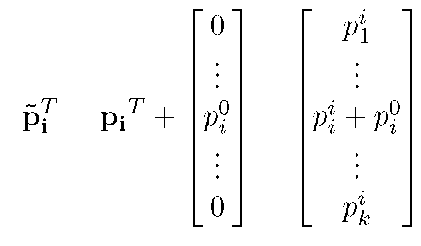
Таким образом, передаваемые пакеты представляют собой строчки матрицы pi, каждая из которых содержит привнесенную ошибку, что не позволяет без дополнительных действия получить исходную матрицу и подпространство. Передача данных столбцов по отдельности может перемешать их порядок на приёмной стороне, что не позволит корректно восстановить его при помощи секретного пакета. Эта проблема решается при помощи указания правильной последовательности пакетов в заголовке, что позволяет при получении пакетов восстановить передаваемую матрицу по их идентификаторам.
В связи с этим возникает вопрос — как получить секретный пакет так, чтобы его содержимое могли восстановить только отправитель и получатель. Этому вопросу посвящен следующий параграф данной работы, а пока будем считать, что содержимое секретного пакета есть какого-то рода функция от адреса получателя. Тогда легитимный получатель, зная свой адрес, сможет восстановить секретный пакет, а злоумышленник не сможет этого сделать, поскольку адрес получателя является неизвестной ему информацией.
После этой процедуры становится возможным передавать части сообщения (кроме секретной) независимо, до тех пор, пока узел-получатель не соберёт в своём буфере п линейно независимых векторов. При их накоплении получатель может восстановить оригинальное сообщение, получив все векторы pi и вычислив вектор ро, равный тому, что использовал отправитель при отправке. Согласно предположению, остальные узлы не могут вычислить тот же вектор ро, что и отправитель, поэтому, даже получив п векторов, они не могут восстановить оригинальное сообщение.
Упомянем также другой способ разбиения сообщения, который непосредственно следует из построений, использованных при разработке метода COPE. В данном случае сообщением является не подпространство, а двоичный вектор P. Он представим в виде двоичной суммы п слагаемых: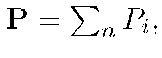 а также, без ограничения общности,
а также, без ограничения общности,
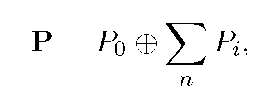
где Ро — специально подобранная секретная часть (двоичный вектор), а Pi выбраны произвольно, но так, чтобы выполнялось равенство (1).
В таком случае обеспечивается анонимность передачи данных, только для получения исходного сообщения вместо сбора линейно независимых векторов, достаточно сложить по модулю 2 все передаваемые части.
2.3 Работа с секретным пакетом
В предыдущем параграфе рассматривался метод передачи и сохранения пакета при условии наличия уже созданного секретного пакета. В этом параграфе мы изучим его более подробно и рассмотрим способы его конструирования.
Безусловно, существуют простые способы создать секретный пакет общий для двух лиц, начиная от шифр-блокнота, и заканчивая протоколом обмена ключей Диффи-Хеллмана, однако все они накладывают ограничения на общающихся лиц (например, наличие шифр- блокнота подразумевает встречу перед началом передачи данных — личную или через посредника).
В данной работе рассматривается способ создания секретного пакета без таких ограничений. Для этого используется код Рида-Соломона, в который искусственно внесены ошибки, предотвращающие нелегитимное декодирование секретного пакета. Входной точкой алгоритма является адрес получателя и случайное зерно. Для каждого сообщения создаётся своё случайное зерно, чтобы диверсифицировать секретные пакеты. Конкатенируя адрес получателя и выбранную последовательность, мы получаем секретный пакет:
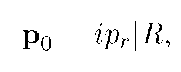
где грг — адрес получателя пакета, а R — случайная последовательность фиксированной длины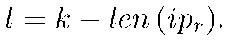
Далее необходимо передать получателю достаточно информации для восстановления секретного пакета. Для этого мы кодируем получившееся секретный пакет ро систематической формой кода Рида-Соломона с параметрами т, к, 21 = т — к, где т — длина кода, к — число информационных символов (равное длине одного пакета), а t — исправляемое кодом число ошибок, и допускаем t ошибок в проверочных символах. В результате получаем кодовое слово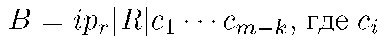 — проверочные символы. Далее из получившегося вектора В отрезается начальная часть, содержащая адрес получателя (т.к. кодирование систематическое, первые к символов кодового слова составляют информационные символы). Получившийся вектор (будем называть его «секретом») посылается в заголовке вместе с передаваемыми пакетами.
— проверочные символы. Далее из получившегося вектора В отрезается начальная часть, содержащая адрес получателя (т.к. кодирование систематическое, первые к символов кодового слова составляют информационные символы). Получившийся вектор (будем называть его «секретом») посылается в заголовке вместе с передаваемыми пакетами.
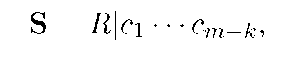
После получения секрета S легитимный получатель может дополнить его своим адресом и таким образом восстановить секретный пакет. Злоумышленнику же потребуется, во-первых, перебрать все возможные адреса в сети, а во-вторых, пытаться декодировать получившийся вектор, чтобы проверить догадку относительно конкретного узла. Несмотря на то, что в конце-концов злоумышленник может узнать получателя, это потребует от него порядка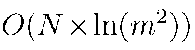 большей вычислительной сложности, что при достаточном количестве узлов в сети и длине кода, приводит к значительным увеличениям затрат как временных, так и ресурсных, что позволяет обеспечить необходимое время отсутствия компрометации передачи.
большей вычислительной сложности, что при достаточном количестве узлов в сети и длине кода, приводит к значительным увеличениям затрат как временных, так и ресурсных, что позволяет обеспечить необходимое время отсутствия компрометации передачи.
В параграфе рассмотрен метод, позволяющий обеспечить анонимность получателя в открытой беспроводной сети без использования криптосистемы с открытым ключем. Метод хотя не обеспечивает полной анонимности контактирующих сторон, значительно затрудняет процесс их раскрытия злоумышленником, позволяя обеспечивать анонимность в течение установленного времени.
Заключение
Таким образом, в результате решения выше стоящих задач, были получены следующие выводы:
1.Представление кодов в виде кодовых деревьев. Кодовое дерево - связной граф, не содержащий циклов. Связной граф - граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях. Для построения дерева равномерного двоичного кода выбирают вершину называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
2. Используя на каждом шаге вышеописанные механизмы, отправитель способен более плотно использовать среду, что приводит к увеличению пропускной способности канала. Однако в силу открытости передачи данных пассивный злоумышленник, заняв любой узел, может беспрепятственно прослушивать передачи в сети и понимать отправителя и получателя сообщений.
3. Метод, позволяющий обеспечить анонимность получателя в открытой беспроводной сети без использования криптосистемы с открытым ключем. Метод хотя не обеспечивает полной анонимности контактирующих сторон, значительно затрудняет процесс их раскрытия злоумышленником, позволяя обеспечивать анонимность в течение установленного времени.
Список литературы
-
- Гашков С.Б., Применко Э.А., Черепнев М.А. Криптографические методы защиты информации. – М.: Академия, 2015. – 304 с.
- Грибунин В.Г., Чудовский В.В. Комплексная система защиты информации на предприятии. – М.: Академия, 2012. – 416 с.
- Гришина Н.В. Комплексная система защиты информации на предприятии. – М.: Форум, 2015. – 240 с.
- Емельянова Н.З., Партыка Т.Л., Попов И.И. Защита информации в персональном компьютере. – М.: Форум, 2012. – 368 с.
- Защита информации в системах мобильной связи. Учебное пособие. – М.: Горячая Линия - Телеком, 2015. – 176 с.
- Комплексная система защиты информации на предприятии. Часть 1. – М.: Московская Финансово-Юридическая Академия, 2012. – 124 с.
- Корнеев И.К, Степанов Е.А. Защита информации в офисе. – М.: ТК Велби, Проспект, 2014. – 336 с.
- Максименко В.Н., Афанасьев, В.В. Волков Н.В. Защита информации в сетях сотовой подвижной связи. – М.: Горячая Линия - Телеком, 2014. – 360 с.
- Малюк А.А, Пазизин С.В, Погожин Н.С. Введение в защиту информации в автоматизированных системах. – М.: Горячая Линия - Телеком, 2011. – 146 с.
- Малюк А.А. Информационная безопасность. Концептуальные и методологические основы защиты информации. Учебное пособие. – М.: Горячая Линия - Телеком, 2014. – 280 с.
- Маньков В.Д, Заграничный С.Ф. Методические рекомендации по изучению "Инструкции по применению и испытанию средств защиты, используемых в электроустановках". – М.: НОУ ДПО "УМИТЦ "Электро Сервис", 2011. – 132 с.
- Петраков А.В. Основы практической защиты информации. Учебное пособие. – М.: Солон-Пресс, 2015. – 384 с.
- Северин В.А. Комплексная защита информации на предприятии. – М.: Городец, 2012. – 368 с.
- Сурис М.А., Липовских В.М. Защита трубопроводов тепловых сетей от наружной коррозии. – М.: Энергоатомиздат, 2013. – 216 с.
- Хорев П.Б. Методы и средства защиты информации в компьютерных системах. – М.: Академия, 2012. – 256 с.
- Хорев П.Б. Программно-аппаратная защита информации. – М.: Форум, 2012. – 352 с.
- Шаньгин В.Ф. Комплексная защита информации в корпоративных системах. – М.: Форум, Инфра-М, 2015. – 592 с.

- Технико-экономическая характеристика предметной области и предприятия.
- «Кадровое обеспечение органов местного самоуправления: состояние и пути оптимизации»
- Анализ факторов внешней среды предприятия ООО «Новотех»
- Анализ технологий материальной и нематериальной мотивации труда в ГО УМЧС
- Технико-экономическая характеристика предметной области и предприятия
- Понятие и значение информационного права
- Антикризисное управление: цели и проблемы (на примере современной организации) ( Управление персоналом организации в условиях кризиса )
- Анализ денежных средств предприятия (на примере ПАО «Симферопольский консервный завод им. С.М. Кирова»)
- Бухгалтерский баланс организации и порядок его составления ( Понятие, виды, содержание и структура бухгалтерского баланса )
- Внеоборотные активы предприятия (на примере ООО «Дело техники»).
- Внеоборотные активы предприятия (на примере ООО Дело техники).
- Учет затрат на ремонт