
Динамические структуры данных. Бинарные деревья.
Содержание:

Введение
В языках программирования (Pascal, C, др.) существует способ выделения памяти под данные, который называется динамическим. В этом случае память под величины отводится во время выполнения программы. Такие величины будем называть динамическими. Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически распределяемый раздел памяти называется динамической памятью (динамически распределяемой памятью).
Использование динамических величин предоставляет программисту ряд дополнительных возможностей.
Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных. Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. В-третьих, использование динамической памяти позволяет создавать структуры данных переменного размера. Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа. Величины, имеющие ссылочный тип, называют указателями.
Предметом данного исследования являются динамические структуры данных в программировании.
Объектом исследования являются деревья в динамических структурах данных.
Цель данной курсовой работы - это изучить динамические структуры данных, а именно деревья.
Для достижения поставленной цели необходимо решить следующие задачи:
- рассмотреть понятие, сущность и необходимость динамических структур данных;
- изучить классификацию динамических структур данных;
- выявить динамические структуры данных, а именно деревья;
Данная работа состоит из введения, основной части, куда входят две главы, заключения, библиографического списка.
При написании данной работы использовался метод анализа научной литературы отечественных и зарубежных авторов, таких как Кернигана Б., Ритчи Д., Подбельского В. В., Фомина С. С., Будниковой Н.А., Хабибуллина И.Ш., Абилова К.С., Бабаева М.А., Галагузовой М.А. и др.
Глава 1. Теоретические аспекты динамических структур данных: деревья
Понятие, сущность и необходимость динамических структур данных
данных в в памяти не только их элементов, но и между .
При не учитывается самих . Такая структур, как их и характера элементами, к , что на этапе кода не выделить для в целом фиксированного , а не может с компонентами адреса.
Для адресации данных , называемый памяти, то под отдельные в момент, они " существовать" в программы, а не во . Компилятор в выделяет памяти для динамически , а не самого .
Динамические структуры – это данных, под выделяется и по необходимости.
данных тем что:
- она не имени; ей в процессе ;
- количество может не ;
- структуры в процессе ;
- в процессе может взаимосвязи структуры[1].
структуре статическая указатель (ее – этого ), которой к динамической . динамические не описания в , во время под них не выделяется. Во память под статические .
– это статические , они требуют . в динамических обычно в случаях.
, имеющие размер (, большой ), в одних и совершенно не в . В процессе нужен , или иная , которой в пределах и .
Когда , обрабатываемых в , объем . Динамические , по , характеризуются смежности в памяти, и размера ( ) структуры в ее . Поскольку структуры по адресам , элемента не может из адреса или элемента.
Для между структуры , через явные элементами. данных в связным. представления – в обеспечения структур:
1. ограничивается объемом ;
2. при изменении элементов не перемещение в , а только ;
3. большая [2].
Вместе с тем, не лишено и , из которых :
- на поля, для связывания с другом, память;
- к связной быть по времени[3].
является и именно им связного . Если в данных для любого нам во случаях номера и , содержащейся в , то для связного элемента не вычислен из .
Дескриптор содержит или указателей, в структуру, требуемого следованием по от элемента к . связное никогда не в , где логическая имеет вид или – с доступом по , но часто в , где логическая другой доступа (, , деревья и т.д.).
Порядок с динамическими следующий: ( место в ); работать при ; удалить ( структурой ).
1.2 динамических
Для того, в выполнения добавлять и , необходимо не в массив, а в . Если к добавить ещё и , в будет какого-то , то это и будет проблемы. представления и называется данных. динамических состоит из и одного или , ссылающихся на . Это позволяет в структуру или удалять из , не затрагивая при элементы [4].
того, позволяют нам так, чтобы их в было к тому, как эти в реальности. Так, для очереди к в лучше динамическая под названием «», а не массив, а для автомобильных вообще . нужна « ».
Динамические бывают и . В линейной данные в . К линейным списки (, , кольцевые), , (односторонние, , с приоритетами). структур . Нелинейные , как правило, в (каждый некоторое , например, в каждый ( ) имеет на и правый ).
Во задачах данные, у , размеры и меняться в программы. Для их динамические .
К таким :
- однонаправленные () ;
- двунаправленные () ;
- циклические ;
- ;
- дек;
- очередь;
- [5].
Они отличаются отдельных допустимыми .
структура несмежные памяти. широко и для эффективной с , размер , особенно для сортировки.
1.3 данных:
— это совокупность , узлами ( один из них как ), и отношений (), иерархическую . Узлы величинами или структурированного , за файлового. , не имеют ни узла, . Каждое следующими :
1. узел, в не ни одной ( );
2. в каждую , корня, дуга[6].
— это граф без . того, в одна , называется . Остальные по длине от дерева (см. рис. 1).
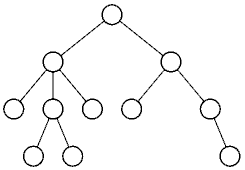
Рисунок 1 Динамическая структура данных: дерево
нами 1, зафиксируем X. Вершины, с X и расположенные нее от дерева, или сыновьями X. упорядочены . Вершины, у нет , называются . обычно , корнем .
в программировании чаще, чем . Так, на деревьев алгоритмы и .
Компиляторы в программы с уровня на представляют в виде , называются . естественно , где имеются структуры, т.е. , могут в друга. служить (см. рис. 2)
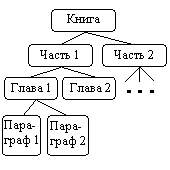
Рисунок 2 Динамическая структура данных-дерево (оглавление книги)
Представим, что из частей, — из , главы — из . книга дерева, из ребра к , частям .
В очередь, из книги к вершинам-главам, в эту , и так далее. компьютера представить в . Вершинам (их также или папками) и [7].
Из выходят к , соответствующим и файлам, в данном . представляются дерева. соответствует диска. , работу с , , как Norton в MS DOS или Проводник , изображать графически в .
Вершина в виде , ссылки на и на всех , а некоторую , зависящую от .
Объект, дерева, фиксированного , обычно в памяти. обычно , из смысла .
Так, очень бинарные , в число у вершины не . Если или сыновей у , то соответствующие нулевые . образом, у все ссылки на .
При работе с часто алгоритмы, т.е. , могут себя. При ему передается в ссылка на , которая как поддерева, из вершины. терминальная, т.е. у нее нет , то просто к вершине.
же у есть , то он вызывается для из сыновей. поддеревьев от алгоритма[8].
алгоритм, дерева. называется из всевозможных от дерева к . Под длиной число , в него, и последнюю .
, деревья к структур, строить в с использованием . важный тип - (бинарные) , в каждый самое два : левое и . , если вида (см. ), то ему соответствовать в структура (см. ).
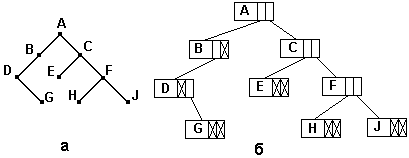
Рисунок 3 Двоичное дерево и его представление с помощью списочных структур памяти а - двоичное дерево; б - представление дерева с помощью списков с использованием звеньев одинакового размера.
Для построения такого бинарного дерева используется следующий ссылочный тип:
type
T = Integer; { скрываем зависимость от конкретного типа данных }
TTree = ^TNode;
TNode = record
value: T;
Left, Right: TTree;
end;
Здесь поля Left и Right - это указатели на потомков данного узла, а поле value предназначено для хранения информации.
1.4 над деревьями
Для определены :
1. корня
2. узла в
3. по дереву
4.
5. удаление .
Для с деревьями алгоритмов. К относятся и обхода . в программе переменных: var t: ptr; s: ; c: ; b: boolean;
дерево с помощью процедуры:
procedure V (var t: ptr) var st: string begin readln (st) if st<>'. 'then begin new (t) t. info: =st V (t. Llink) V (t. Rlink) end else t: =nil end
отражается во данных: пустой условный (в случае ). Для на рис.3 имеет вид:
type
PNode = ^TNode;
TNode = record
Info : string; {поле данных}
Left,Right : PNode; {указатели на левое и правое поддеревья}
end;
Процедура создания нового узла.
{ Создание нового узла со значением информационного поля X.
Возвращается указатель на новый узел}
function NewNode(X:string):PNode;
var
P : PNode;
begin
New(P);
P^.Info := X;
P^.Left := Nil;
P^.Roght := Nil;
NewNode := P;
end;
три способа : в прямом , и концевом. может рекурсивной и без рекурсии ( )[9]. В приведенной процедуре дерева в .
Нерекурсивный дерева в :
program FactDemo;
var
k : integer;
function Factor(n:integer):integer;
begin
if n=0 then
Factor : 1
else
Factor := n * Factor(n-1);
{end if}
end;
begin
write(’Введите целое число ’);
readln(k);
if k>=0 then
writeln(’Факториал ’,n:1,’ = ’, Factor(k));
{end if}
end.
Пусть T - на дерево; А - , в заносятся еще не вершин; TOP - ; P - рабочая .
1. установка: TOP: =0; P: =T.
2. , то перейти на 4. { }
3. Вывести P. . заносим в : TOP: =+1; A [TOP]: =P; шаг по : P: =P. llink; на 2.
4. TOP=0, то .
5. вершину из : P: =A []; TOP: =TOP-1;
Шаг по : P: =P. rlink; на 2.
, деревом , или в виде , двоичное в слева от находятся с , меньшими из вершины, а - с элементами (, что все дерева и что их тип (ТЭД) операций )[10].
2. Реализация по с бинарными
2.1 программы
( упорядоченные, так и ) используются в . По причине мы в на рассмотрении с ними.
Для бинарного в введем тип, вид записи:
Type
PNode = ^TNode;
TNode = record
Data : integer; {информационное поле}
left,right : PNode;
end;
Процедура создания нового узла.
{ Создание нового узла со значением информационного поля X.
Возвращается указатель на новый узел}
function NewNode(X:string):PNode;
var
P : PNode;
begin
New(P);
P^.Info := X;
P^.Left := Nil;
P^.Roght := Nil;
NewNode := P;
end;
Процедура создания потомка (поддерева)
procedure SetLeft(P:PNode; X:string);
begin
P^.Left := NewNode(X);
end;
3. дерева:
- ( числа) с ;
- дубликаты не (но на экран);
- ввода числа 0;
- – упорядоченное .
При динамических «дерево» используются .
Рекурсия некоторого с самого .
При структур « » чаще рекурсивные .
предполагает понятия с этого . Вирт утверждение о «… мощность с тем, что она позволяет множество с конечного »[11].
рекурсивного факториал :
n! = 1 при n=0
n! = n*(n-1)! при n >0
В Турбо-Паскале рекурсия разрешена: подпрограмма может вызывать сама себя:
program FactDemo;
var
k : integer;
function Factor(n:integer):integer;
begin
if n=0 then
Factor : 1
else
Factor := n * Factor(n-1);
{end if}
end;
begin
write('Введите целое число ');
readln(k);
if k>=0 then
writeln('Факториал ',n:1,' = ', Factor(k));
{end if}
end.
Первое вычисляется, n=0, оно в соответствующий . Теперь на шаге членов -1) известны, и в это выражение , на предыдущем . Это в процессе .
Сформулируем два рекурсивных :
1. тривиального .
рекурсивный не создавать вызовов . Для этого он содержать : т.е. при некоторых вычисления в производиться без его .
Для функции «» случай:
2. сложного в более .
При входных выход за конечное вызовов. Для новый алгоритма более .
Иными алгоритм определение случая в простого .
Для «факториал» n! заменяется -1)!, и при этом с значение n , к нулю и его за число [12].
Из структуры « » видно, что она по , а в силу являются и все работы с . Для достаточно на выше бинарного .
В процедуре Add случай ( пустое) и
: добавить в и поддеревья – Add () и ).
Алгоритмы с
В приведенных предполагается, что ( ) дерева записью:
Type
PNode = ^TNode;
TNode = record
Data : integer; {информационное поле}
left,right : PNode;
end;
значений элементов. в виде , значение полей . Тривиальным , когда – пустой, и, , не информационного .
function Sum(Root : PNode) : integer;
begin
if Root=Nil then {узел - пустой}
Sum := 0
else
Sum := Root^.Data + Sum(Root^.left)
+ Sum(Root^.right);
{end if}
end;
Для случая как значение в корне () суммы левого и .
А выражение рекурсивный поддерева для Root.
А2. Подсчет количества узлов в бинарном дереве
function NumElem(Tree:PNode):integer;
begin
if Tree = Nil then
NumElem := 0
else
NumElem := NumElem(Tree^.left)+ NumElem(Tree^.right) + 1;
end;
Подсчет количества листьев бинарного дерева
function Number(Tree:PNode):integer;
begin
if Tree = Nil then
Number := 0 {дерево пустое - листов нет}
else if (Tree^.left=Nil) and (Tree^.right=Nil) then
Number := 1 {дерево состоит из одного узла - листа}
else
Number := Number(Tree^.left) + Number(Tree^.right);
{end if}
end;
Анализ приведенных алгоритмов показывает, что для получения ответа в них производится просмотр всех узлов дерева. Ниже будут приведены алгоритмы, в которых порядок обхода узлов дерева отличается. И в зависимости от порядка обхода узлов бинарного упорядоченного дерева, можно получить различные результаты, не меняя их размещения.
Просмотр используется не сам по себе, а для обработки элементов дерева, а просмотр сам по себе обеспечивает только некоторый порядок выбора элементов дерева для обработки. В приводимых ниже примерах обработка не определяется; показывается только место, в котором предлагается выполнить обработку текущего.
Алгоритмы просмотра дерева
Самой интересной особенностью обработки бинарных деревьев является та, что при изменении порядка просмотра дерева, не изменяя его структуры, можно обеспечить разные последовательности содержащейся в нем информации. В принципе возможны всего четыре варианта просмотра: слева-направо, справа-налева, сверху-вниз и снизу-вверх[13].
Прежде чем увидеть, к каким результатам это может привести, приведем
их.
Просмотр дерева слева – направо
procedure ViewLR(Root:PNode); {LR -> Left - Right }
begin
if Root<>Nil then
begin
ViewLR(Root^. left); {просмотр левого поддерева}
{Операция обработки корневого элемента - вывод на печать, в файл и др.}
ViewLR(Root^.right); { просмотр правого поддерева }
end;
end;
Просмотр справа налево
procedure ViewRL(Root:PNode); {LR -> Right - Left}
begin
if Root<>Nil then
begin
ViewRL(Root^.right); { правого }ViewRL(Root^.left); { левого }
end;
end;
Просмотр сверху - вниз
procedure ViewTD(Root:PNode); {TD -> Top-Down}
begin
if Root<>Nil then
begin
Операция обработки корневого элемента - вывод на печать, в файл и др.
ViewTD(Root^.left); {просмотр левого поддерева}
ViewTD(Root^.right); { просмотр правого поддерева }
end;
end;
Просмотр снизу-вверх
procedure ViewDT(Root:PNode); {DT -> Down - Top}
begin
if Root<>Nil then
begin
ViewDT(Root^.left); {просмотр левого поддерева}
ViewDT(Root^.right); { просмотр правого поддерева }
end;
end;
Поиск элемента в двоичном упорядоченном дереве
function Search(SearchValue:integer;Root:PNode):PNode;
begin
if (Root=Nil) or (Root^.Data=SearchValue) then
Search := Root
else if (Root^.Data > SearchValue) then
Search := Search(SearchValue,Root^.left)
else
Search := Search(SearchValue,Root^.right);
end;
2.2 Текст программы бинарное дерево динамический алгоритм
type link = ^element;
element = record
data : integer;
left : link;
right : link;
end;
var
m,x, depth, minim : integer;
pn : link;
procedure add(var n : link; arg:integer);
var
ind, neo : link;
begin
new(neo);
neo^.data:=arg;
neo^.left:=nil;
neo^.right:=nil;
if n=nil then n:= neo
else begin
ind:=n;
while neo<>nil do begin
if arg<ind^.data then begin
if ind^.left=nil then begin
ind^.left:=neo;
neo:=nil
end
else ind:=ind^.left
end
else
if arg>ind^.data then begin
if ind^.right=nil then begin
ind^.right:=neo;
neo:=nil
end
else ind:=ind^.right
end
else begin
writeln('Such element is already existent');
neo:=nil;
end;
end;
end;
end; { add }
procedure restruct(var d : link);
var
ind1, ind2 : link;
begin
ind1:=d;
if ind1^.right=nil then begin
ind2:=d;
d:=ind2^.left;
dispose(ind2)
end
else
if ind1^.left=nil then begin
ind2:=d;
d:=ind2^.right;
dispose(ind2)
end
else begin
ind2:=ind1^.left;
while ind2^.right<>nil do begin
ind1:=ind2;
ind2:=ind2^.right;
end;
ind1^.right:=ind2^.left;
ind2^.left:=d^.left;
ind2^.right:=d^.right;
dispose(d);
d:=ind2;
end;
end; { restruct }
procedure delete(var n : link; arg:integer);
var
del, ind : link;
t : boolean;
begin
t:=false;
del:=n;
while (del<>nil) and (not t) do begin
if arg=del^.data then t:=true
else
if arg<del^.data then begin
ind:=del;
del:=del^.left;
end
else begin
ind:=del;
del:=del^.right;
end;
end;
if t then begin
if (del^.left=nil) and (del^.right=nil) then begin
if del=n then begin n:=nil; dispose(del) end else
if ind^.left=del then begin
ind^.left:=nil;
dispose(del)
end
else begin
ind^.right:=nil;
dispose(del)
end
end
else
if del=n then restruct(n) else
if ind^.left=del then restruct(ind^.left)
else restruct(ind^.right)
end
else writeln('Element is absent');
end; { delete }
procedure view( n : link; var d:integer);
var
i : integer;
begin
for i:=1 to d do begin
write(' ') end;
writeln(n^.data);
if (n^.left=nil) and (n^.right=nil) then d:=d-1
else begin
if n^.right<>nil then begin
d:=d+1;
view(n^.right,d);
end;
if n^.left<>nil then begin
d:=d+1;
view(n^.left, d);
end;
d:=d-1;
end;
end; { view }
procedure obhod1( n : link; var d, min:integer);
begin
if (n^.left=nil) and (n^.right=nil) then begin
if d<min then min:=d;
d:=d-1 end
else begin
if n^.right<>nil then begin
d:=d+1;
obhod1(n^.right, d, min); end;
if n^.left<>nil then begin
d:=d+1;
obhod1(n^.left, d,min) end;
d:=d-1;
end;
end; { obhod1 }
procedure obhod2( n : link; var d:integer; min:integer);
begin
if (n^.left=nil) and (n^.right=nil) then begin
if d=min then writeln(n^.data);
d:=d-1;
end
else begin
if n^.right<>nil then begin
d:=d+1;
obhod2(n^.right,d,min);
end;
if n^.left<>nil then begin
d:=d+1;
obhod2(n^.left, d,min);
end;
d:=d-1;
end;
end; { obhod2 }
begin
m:=1;
pn:=nil;
while m<>0 do begin
writeln;
writeln('--- Type "1" to ADD new element');
writeln('--- Type "2" to DELETE element');
writeln('--- Type "3" to VIEW tree');
writeln('--- Type "4" to FIND elements with minimal depth');
writeln('--- Type "0" to EXIT program');
writeln;
write('Enter : ');
readln(m);
writeln;
case m of
1 : begin
write('Enter new element : ');
readln(x);
add(pn, x);
end;
2 : begin
write('Enter element you want to delete : ');
readln(x);
delete(pn, x);
end;
3 : begin
depth:=1;
if pn=nil then writeln('The tree is empty') else begin
writeln('The tree is : ');
view(pn, depth);
end;
end;
4 : begin
depth:=1;
minim:=20;
if pn<>nil then begin
writeln('Elements with minimal depth');
obhod1(pn,depth,minim);
writeln(minim);
depth:=1;
obhod2(pn,depth,minim);
end
else writeln('The tree is empty');
end;
end; { case }
end;
Заключение
Итак, можно сказать, что древовидная модель оказывается довольно эффективной для представления динамических данных с целью быстрого поиска информации. Деревья являются одними из наиболее широко распространенных структур данных в информатике и программировании, которые представляют собой иерархические структуры в виде набора связанных узлов.
Нами выявлено, что дерево является структурой данных, представляющая собой совокупность элементов и отношений, образующих иерархическую структуру этих элементов. Каждый элемент дерева называется вершиной (узлом) дерева. Вершины дерева соединены направленными дугами, которые называют ветвями дерева. Начальный узел дерева называют корнем дерева, ему соответствует нулевой уровень. Листьями дерева называют вершины, в которые входит одна ветвь и не выходит ни одной ветви.
Деревья особенно часто используют на практике при изображении различных иерархий.
Тексты приведенных алгоритмов очень компактны и просты в понимании. В заключение отметим, что рекурсивные алгоритмы широко используются в базах данных и при построении компиляторов, в частности для проверки правильности записи арифметических выражений, синтаксис которых задается с помощью синтаксических диаграмм.
Библиографический список
1. Н. Вирт. Алгоритмы и структуры данных: пер. с англ. / Н.Вирт. Изд. 2-е, испр. – СПб.: Невский диалект, 2005. – 352 с.
2. Ахо А. Структуры данных и алгоритмы: пер. с англ. / А.Ахо, Д. Хопкрофт, Д.Ульман. – М.: Вильямс, 2016. – 400 с.
3. Уильям Топп, Уильяи Форд. Структуры данных в С++: Пер. с англ. – М. ЗАО «Издательство БИНОМ», 1999. – 816 с.
4. Павловская Т.А. C#. Программирование на языке высокого уровня: учебник для вузов / Т.А.Павловская. – Спб.: Питер, 2014. – 432 с.
5. Фаронов В.В. Создание приложений с помощью C#. Руководство программиста / В.В. Фаронов. – М.: Эксмо, 2008. – 576 с.
6. Биллиг В.А.Основы программирования на C#: учебное пособие / В.А.Биллиг – М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2009. – 483 с.
7. Шилдт, Герберт. C# 3.0: руководство для начинающих: Пер. с англ. – М.: ООО «И.Д. Вильямс», 2009. – 688 с.
8. Шилдт, Герберт. С# 4.0: Полное руководство: Пер. с англ. – М.: Издательский дом «Вильямс», 2011. – 1056 с.
9. Гросс, Кристиан. C# 2008 и платформа NET 3.5 Framework: базовое руководство: Пер. с англ. – М.: Издательский дом «Вильямс», 2009. – 480 с.
10.Петцольд, Чарльз. Программирование для Microsoft Windows 8. Пер. с англ. – СпБ.: Издательский дом «Питер», 2014. – 1008 с. 31
11.Стиллмен, Эндрю, Грин, Дженнифер. Изучаем C#. Пер. с англ. – СпБ.: Издательский дом «Питер», 2017. – 816 с.
12.Кнут Д. Искусство программирования для ЭВМ: в 3 т. Т 1: пер. с англ. / Д.Кнут. – М.: Вильямс, 2000. – 720 с.
-
Павловская Т.А. C#. Программирование на языке высокого уровня: учебник для вузов / Т.А.Павловская. – Спб.: Питер, 2014. – 432 с. ↑
-
Биллиг В.А.Основы программирования на C#: учебное пособие / В.А.Биллиг – М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2009. – 483 с. ↑
-
Петцольд, Чарльз. Программирование для Microsoft Windows 8. Пер. с англ. – СпБ.: Издательский дом «Питер», 2014. – 1008 с. 31 ↑
-
Кнут Д. Искусство программирования для ЭВМ: в 3 т. Т 1: пер. с англ. / Д.Кнут. – М.: Вильямс, 2000. – 720 с. ↑
-
Шилдт, Герберт. С# 4.0: Полное руководство: Пер. с англ. – М.: Издательский дом «Вильямс», 2011. – 1056 с. ↑
-
Стиллмен, Эндрю, Грин, Дженнифер. Изучаем C#. Пер. с англ. – СпБ.: Издательский дом «Питер», 2017. – 816 с. ↑
-
Павловская Т.А. C#. Программирование на языке высокого уровня: учебник для вузов / Т.А.Павловская. – Спб.: Питер, 2014. – 432 с. ↑
-
Ахо А. Структуры данных и алгоритмы: пер. с англ. / А.Ахо, Д. Хопкрофт, Д.Ульман. – М.: Вильямс, 2016. – 400 с. ↑
-
Биллиг В.А.Основы программирования на C#: учебное пособие / В.А.Биллиг – М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2009. – 483 с. ↑
-
Шилдт, Герберт. С# 4.0: Полное руководство: Пер. с англ. – М.: Издательский дом «Вильямс», 2011. – 1056 с. ↑
-
Н. Вирт. Алгоритмы и структуры данных: пер. с англ. / Н.Вирт. Изд. 2-е, испр. – СПб.: Невский диалект, 2005. – 352 с. ↑
-
Биллиг В.А.Основы программирования на C#: учебное пособие / В.А.Биллиг – М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2009. – 483 с. ↑
-
Шилдт, Герберт. С# 4.0: Полное руководство: Пер. с англ. – М.: Издательский дом «Вильямс», 2011. – 1056 с. ↑

- Основы программирования на языке HTML
- Понятие и значение приватизации
- Недействительность сделок (Понятие недействительной сделки).
- Понятие и виды наследования
- Интегрированные среды разработки программ
- Основные функции в системе менеджмента
- Система источников предпринимательского права
- Виды договоров
- Менеджмент человеческих ресурсов
- Роль рекламы в продвижении профессионального спорта
- Роль рекламы в продвижении профессионального спорта
- Проектирование БД для сотрудника туристического агентства