
Алгоритмы сортировки данных (Структура и типы данных)
Содержание:

Введение
Веками человечество накапливало знания, навыки работы сведения об окружающем нас мире, т.е. собирало информацию. Вначале информация передавалась из поколения в поколение в виде преданий и устных рассказов. Возникновение и развитие книжного дела позволило передавать и хранить информацию в более надежном письменном виде. Открытия в области электричества привели к появлению телеграфа, телефона, радио, телевидения — средств, позволяющих оперативно передавать и накапливать информацию. Развитие прогресса обусловило резкий рост информации, в связи, с чем вопрос о её сохранении и переработке становился год от года острее. С появлением вычислительной техники значительно упростились способы хранения, а главное, обработки информации. Развитие вычислительной техники на базе микропроцессоров приводит к совершенствованию компьютеров и программного обеспечения. Появляются программы, способные обработать большие потоки информации. С помощью таких программ создаются информационные системы. Целью любой информационной системы является обработка данных об объектах и явлениях реального мира и предоставление нужной человеку информации о них.
Необходимым условием хранения информации в памяти компьютера является возможность преобразования этой самой информации в подходящую для компьютера форму. В том случае, если это условие выполняется, следует определить структуру, пригодную именно для наличествующей информации, ту, которая предоставит требующийся набор возможностей работы с ней. Здесь под структурой понимается способ представления информации, посредством которого совокупность отдельно взятых элементов образует нечто единое, обусловленное их взаимосвязью друг с другом. Скомпонованные по каким-либо правилам и логически связанные межу собой, данные могут весьма эффективно обрабатываться, так как общая для них структура предоставляет набор возможностей управления ими – одно из того за счет чего достигаются высокие результаты в решениях тех или иных задач. Но не каждый объект представляем в произвольной форме, а возможно и вовсе для него имеется лишь один единственный метод интерпретации, следовательно, несомненным плюсом для программиста будет знание всех существующих структур данных. Таким образом, часто приходиться делать выбор между различными методами хранения информации, и от такого выбора зависит работоспособность продукта.
Говоря о не вычислительной технике, можно показать ни один случай, где у информации видна явная структура. Наглядным примером служат книги самого разного содержания. Они разбиты на страницы, параграфы и главы, имеют, как правило, оглавление, то есть интерфейс пользования ими. В широком смысле, структурой обладает всякое живое существо, без нее органика навряд-ли смогла бы существовать.
Вполне вероятно, читателю приходилось сталкиваться со структурами данных непосредственно в информатике, например, с теми, что встроены в язык программирования. Часто они именуются типами данных. К таковым относятся: массивы, числа, строки, файлы и т. д.
Методы хранения информации, называемые «простыми», т. е. неделимыми на составные части, предпочтительнее изучать вместе с конкретным языком программирования, либо же глубоко углубляться в суть их работы. Поэтому здесь будут рассмотрены лишь «интегрированные» структуры, те которые состоят из простых, а именно: массивы, списки, деревья и графы.
Сформулируем цели и задачи курсовой работы.
Цель: Изучение принципов организации данных
Задачи:
- Изучить и проанализировать научно-методическую литературу по теме «Организация данных: структуры, списки, стеки, очереди. Методы работы».
- Написать программы, демонстрирующие работу стеков, списков, очередей.
- Изучить структуры данных
- Изучить типы данных
Глава 1. Сортировка данных.
1.1 Данные. Структура.
Понятие данных является одним из ключевых в программировании, да и вообще в компьютерных науках. Грубо говоря, данные в информатике это информация, находящиеся в состоянии хранении, обработки или передачи, в какой-то отрезок времени. В машинах Тьюринга информация имеет тип, а он в свою очередь, зависит от рода информации.
В информатике различают два понятия «данные» и «информация». Данные представляют собой информацию, находящуюся в формализованном виде и предназначенную для обработки техническими системами. Под информацией понимается совокупность представляющих интерес фактов, событий, явлений, которые необходимо зарегистрировать и обработать. Информация в отличие от данных – это то, что нам интересно, что можно хранить, накапливать, применять и передавать. Данные только хранятся, а не используются. Но как только данные начинают использоваться, то они преобразуются в информацию. В процессе обработки информация изменяется по структуре и форме. Признаками структуры является взаимосвязь элементов информации. Структура информации классифицируется на формальную и содержательную. Формальная структура информации ориентирована на форму представления информации, а содержательная – на содержание.
Виды форм представления информации:
- ^ По способу отображения:
а) символьная (знаки, цифры, буквы);
б) графическая (изображения);
в) текстовая (набор букв, цифр);
г) звуковая.
- По месту появления:
а) внутренняя (выходная);
б) внешняя (входная)
- По стабильности:
а) постоянная;
б) переменная
- По стадии обработки:
а) первичная;
б) вторичная. ^
Структуры данных служат материалами, из которых строятся программы. Как правило, данные имеют форму чисел, букв, текстов, символов и более сложных структур типа последовательностей, списков и деревьев.
Для точного описания абстрактных структур данных и алгоритмов программ используются такие системы формальных обозначений, называемые языками программирования, в которых смысл всякого предложения определится точно и однозначно. Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. Такое определение охватывает все возможные подходы к структуризации данных, но в каждой конкретной задаче используются те или иные его аспекты. Поэтому вводится дополнительная классификация структур данных, направления которой соответствуют различным аспектам их рассмотрения.
Физическая структура данных отражает способ физического представления данных в памяти машины и называется еще структурой хранения, внутренней структурой или структурой памяти.
Рассмотрение структуры данных без учета её представления в машинной памяти называется абстрактной или логической структурой. Вследствие их различий существуют процедуры, осуществляющие отображение логической структуры в физическую, и наоборот.
Различаются простые (базовые, примитивные) типы данных и интегрированные Простыми называются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. Интегрированными называются такие структуры данных, составными частями которых являются другие структуры данных - простые или в свою очередь интегрированные.
В зависимости от отсутствия или наличия явно заданных связей между элементами данных следует различать несвязные структуры (векторы, массивы, строки, стеки, очереди) и связные структуры (связные списки).
1. Весьма важный признак структуры данных - её изменчивость - изменение числа элементов или связей между элементами структуры.
Базовые структуры данных, статические, полустатические и динамические характерны для оперативной памяти и часто называютсяоперативными структурами. Файловые структуры соответствуют структурам данных для внешней памяти.
2. Второй важный признак структуры данных - характер упорядоченности её элементов. По этому признаку структуры можно делить налинейные и нелинейные структуры. В зависимости от характера взаимного расположения элементов в памяти, линейные структуры можно разделить на структуры с последовательным распределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с произвольным связным распределением элементов в памяти (односвязные, двусвязные списки).
В языках программирования понятие "структуры данных" тесно связано с понятием "типы данных". Информация по каждому типу однозначно определяет:
1) структуру хранения данных указанного типа, т.е. выделение памяти и представление данных в ней, и интерпретирование двоичного представления;
2) множество допустимых значений, которые может иметь тот или иной объект описываемого типа;
3) множество допустимых операций, которые применимы к объекту описываемого типа.
1.2 Типы данных
Типы данных в Паскале определяют возможные значения переменных, констант, выражений и функций. Они бывают встроенными и пользовательскими. Встроенные типы изначально присутствуют в языке программирования, а пользовательские создаются программистом.
По способу представления и обработки типы данных бывают:
- простые
- структурированные
- указатели
- объекты
- процедуры
Целые типы. С помощью целых чисел может быть представлено количество объектов, являющихся дискретными по своей природе (т.е. счетное число объектов).
Сюда входят несколько целочисленных типов, которые различаются диапазоном значений, количеством байт отведённых для их хранения и словом, с помощью которого объявляется тип.
Таблица 1. Целостный тип данных
|
Тип |
Диапазон |
Размер в байтах |
|
Shortint |
-128…127 |
1 |
|
Integer |
-32 768…32 767 |
2 |
|
Longint |
-2 147 483 648…2 147 483 647 |
4 |
|
Byte |
0…255 |
1 |
|
Word |
0…65 535 |
2 |
Объявить целочисленную переменную можно в разделе Var, например:
Var book: word;
Над переменными этой категории можно выполнять все арифметические и логические операции за исключением деления (/), для него нужен вещественный тип. Также могут быть применены некоторые стандартные функции и процедуры.
Вещественные типы. В отличии от порядковых типов (все целые, символьный, логический), значения которых всегда сопоставляются с рядом целых чисел, значение вещественных типов определяет число лишь с некоторой конечной точностью, зависящей от внутреннего формата вещественного числа.
В Паскале бывают следующие вещественные типы данных:
Таблица 2. Вещественный тип данных
|
Тип |
Диапазон |
Память, байт |
Количество цифр |
|
Real |
2.9e-39 … 1.7e38 |
6 |
11-12 |
|
Single |
1.5e-45 … 3.4e38 |
4 |
7-8 |
|
Double |
5.0e-324 …1.7e308 |
8 |
15-16 |
|
Extended |
3.4e-4932 … 1.1e493 |
10 |
19-20 |
|
Comp |
-9.2e63 … (9.2e63)-1 |
8 |
19-20 |
Над ними может быть выполнено большее количество операций и функций, чем над целыми. Например, эти функции возвращают вещественный результат:
sin(x) – синус;
cos(x) – косинус;
arctan(x) – арктангенс;
ln(x) – натуральный логарифм;
sqrt(x) – квадратный корень;
exp(x) – экспонента;
Значениями логического типа BOOLEAN может быть одна из заранее объявленных констант false (ложь) или true (истина). Данные логического типа занимают один байт памяти. При этом значении false соответствует нулевое значение байта, а значению true соответствует любое ненулевое значение байта. Над логическими типами возможны операции нулевой алгебры - НЕ (not), ИЛИ (or), И (and), исключающее ИЛИ (xor). В этих операциях операнды логического типа рассматриваются как единое целое. Результаты логического типа получаются при сравнении данных любых типов.
Переменная, имеющая логический тип данных может принимать всего два значения: true (истина) и false (ложь). Здесь истине соответствует значение 1, а ложь тождественная нулю. Объявить булеву переменную можно так:
Var A: Boolean;
Над данными этого типа могут выполняться операции сравнения и логические операции: not , and, or, xor.
Значением символьного типа char являются символы из некоторого предопределенного множества. В большинстве современных персональных ЭВМ этим множеством является ASCII (American Standard Code for Information Intechange - американский стандартный код для обмена информацией). Это множество состоит из 256 разных символов, упорядоченных определенным образом, и содержит символы заглавных и строчных букв, цифр и других символов, включая специальные управляющие символы. Допускается некоторые отклонения от стандарта ASCII, в частности, при наличии соответствующей системной поддержки это множество может содержать буквы русского алфавита. Значение символьного типа char занимает в памяти 1 байт.
Символьный тип данных – это совокупность символов, используемых в том или ином компьютере. Переменная данного типа принимает значение одного из этих символов, занимает в памяти компьютера 1 байт. Слово Char определяет величину данного типа. Существует несколько способов записать символьную переменную (или константу):
- как одиночный символ, заключенный в апострофы: ‘W’, ‘V’, ‘п’;
- указав код символа, значение которого должно находиться в диапазоне от 0 до 255.
- при помощи конструкции ^K, где K – код управляющего символа. Значение K должно быть на 64 больше кода соответствующего управляющего символа.
К величинам символьного типа данных применимы операции отношения и следующие функции:
Succ(x) — возвращает следующий символ;
Pred(x) — возвращает предыдущий символ;
Ord(x) — возвращает значение кода символа;
Chr(x) — возвращает значение символа по его коду;
UpCase(x) — переводит литеры из интервала ‘a’..’z’ в верхний регистр.
Строка в Паскале представляет собой последовательность символов заключенных в апострофы, и обозначается словом String. Число символов (длина строки) должно не превышать 255. Если длину строки не указывать, то она автоматически определиться в 255 символов. Общий вид объявления строковой переменной выглядит так:
Var <имя_переменной>: string[<длина строки>];
Каждый символ в строке имеет свой индекс (номер). Индекс первого байта – 0, но в нем храниться не первый символ, а длина всей строки, из чего следует, что переменная этого типа будет занимать на 1 байт больше числа переменных в ней. Номер первого символа – 1, например, если мы имеем строку S=‘stroka’, то S[1]=s;. В одном из следующих уроков строковый тип данных будет рассмотрен подробнее.
Перечислимый тип представляет собой упорядоченный тип данных, определяемый программистом, т.е. программист перечисляет все значения, которые может принимать переменная этого типа. Значения являются неповторяющимися, количество которых не может быть больше 256.
Перечисляемый тип данных представляет собой некоторое ограниченное количество идентификаторов. Эти идентификаторы заключаются в круглые скобки, и отделяются друг от друга запятыми.
Пример:
Type Day=(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday);
Var A: Day;
Переменная A может принимать лишь значения определенные в разделе Type. Также можно объявить переменную перечисляемого типа в разделе Var:
Var A: (Monday, Tuesday);
К данному типу применимы операции отношения, при этом заранее определенно, что Monday<Tuesday<Wednesday т. д. Также можно применять функции succ, pred, ord, процедуры inc и dec, и использовать операцию присваивания: A:=Tuesday;
Один из способов образования новых типов из уже существующих - ограничение допустимого диапазона значений некоторого стандартного скалярного типа или рамок описанного перечислимого типа. Определяется заданием минимального и максимального значений диапазона. При этом изменяется диапазон допустимых значений по отношению к базовому типу, но представление в памяти полностью соответствует базовому типу.
Когда необходимо задать какой то диапазон значений, то в таких ситуациях применяется интервальный тип данных. Для объявления используется конструкция m..n, где m – минимальное (начальное) значение, а n – максимально (конечное); здесь m и n являются константами, которые могут быть целого, символьного, перечисляемого или логического типа. Описываться величины интервального типа могут как в разделе типов, так и в разделе описания переменных.
Общий вид:
TYPE <имя_типа> = <мин. значение>..<макс. значение>;
Пример:
TYPE Cards = 1..36;
В ряде задач может потребоваться работа с отдельными двоичными разрядами данных. Чаще всего такие задачи возникают в системном программировании, когда, например, отдельный разряд связан с состоянием отдельного аппаратного переключателя или отдельной шины передачи данных и т.п. Данные такого типа представляются в виде набора битов, упакованных в байты или слова, и не связанных друг с другом. Операции над такими данными обеспечивают доступ к выбранному биту данного.
Указатели
Тип указателя представляет собой адрес ячейки памяти. При программировании на низком уровне - в машинных кодах, на языке Ассемблера и на языке C, который специально ориентирован на системных программистов, работа с адресами составляет значительную часть программных кодов.
1.3 Структуры данных
Статические структуры относятся к разряду непримитивных структур, которые представляют собой структурированное множество базовых, структур. Например, вектор может быть представлен упорядоченным множеством чисел. Поскольку по определению статические структуры отличаются отсутствием изменчивости, память для них выделяется автоматически в момент активизации того программного блока, в котором они описаны. Выделение памяти на этапе компиляции является столь удобным свойством статических структур, что программисты используют их для представления объектов, обладающих изменчивостью.
Статические структуры в языках программирования связаны со структурированными типами. Структурированные типы в языках программирования являются теми средствами интеграции, которые позволяют строить структуры данных сколь угодно большой сложности. К таким типам относятся: массивы, записи (в некоторых языках - структуры) и множества (этот тип реализован не во всех языках).
Вектор (одномерный массив) - структура данных с фиксированным числом элементов одного и того же типа. Каждый элемент вектора имеет уникальный в рамках заданного вектора номер и имя.
Массивы
Логическая структура.
Массив - такая структура данных, которая характеризуется: фиксированным набором элементов одного и того же типа; каждый элемент имеет уникальный набор значений индексов; количество индексов определяют мерность массива (два индекса - двумерный массив); обращение к элементу массива выполняется по имени массива и значениям индексов для данного элемента.
Физическая структура - это размещение элементов массива в памяти ЭВМ.
Многомерные массивы хранятся в непрерывной области памяти. Размер слота определяется базовым типом элемента массива. Количество элементов массива и размер слота определяют размер памяти для хранения массива. Принцип распределения элементов массива в памяти определен языком программирования.
Специальные массивы. На практике встречаются массивы, которые в силу определенных причин могут записываться в память не полностью, а частично. Это особенно актуально для массивов настолько больших размеров, что для их хранения в полном объёме памяти может быть недостаточно. К таким массивам относятся симметричные и разреженные массивы.
Симметричные массивы. Двумерный массив, в котором количество строк равно количеству столбцов называется квадратной матрицей. Квадратная матрица, у которой элементы, расположенные симметрично относительно главной диагонали, попарно равны друг другу, называется симметричной.
Разреженные массивы. Разреженный массив - массив, большинство элементов которого равны между собой.
Логическая структура: Множество - такая структура, которая представляет собой набор неповторяющихся данных одного и того же типа. Множество может принимать все значения базового типа. Базовый тип не должен превышать 256 возможных значений. Поэтому базовым типом множества могут быть byte, char и производные от них типы.
^ Физическая структура: Множество в памяти хранится как массив битов, в котором каждый бит указывает является ли элемент принадлежащим объявленному множеству или нет. Т.о. максимальное число элементов множества 256, а данные типа множество могут занимать не более 32-ух байт.
^ Числовые множества. Стандартный числовой тип, который может быть базовым для формирования множества - тип byte.
Символьные множества. Символьные множества хранятся в памяти также как и числовые множества. Разница лишь в том, что хранятся не числа, а коды ASCII символов.
^ Множество из элементов перечислимого типа. Множество, базовым типом которого есть перечислимый тип, хранится также, как множество, базовым типом которого является тип byte.
^ Множество от интервального типа. Множество, базовым типом которого есть интервальный тип, хранится также, как множество, базовым типом которого является тип byte.
Запись - конечное упорядоченное множество полей, характеризующихся различным типом данных. Полями записи могут быть интегрированные структуры данных - векторы, массивы, другие записи.
Таблица - сложная интегрированная структура. С физической точки зрения таблица представляет собой вектор, элементами которого являются записи. Логической особенностью таблиц является то, что доступ к элементам таблицы производится не по номеру (индексу), а по ключу - по значению одного из свойств объекта, описываемого записью-элементом таблицы. Ключ - это свойство, идентифицирующее данную запись во множестве однотипных записей. Ключ может включаться в состав записи и быть одним из её полей, но может и не включаться, а вычисляться по положению записи. Таблица может иметь один или несколько ключей. Иногда различают таблицы с фиксированной и с переменной длиной записи. ^
Полустатические структуры данных характеризуются следующими признаками: они имеют переменную длину и простые процедуры её изменения; изменение длины структуры происходит в определенных пределах, не превышая какого-то максимального значения. Если полустатическую структуру рассматривать на логическом уровне, то можно сказать, что это последовательность данных, связанная отношениями линейного списка. Физическое представление полустатических структур данных в памяти это обычно последовательность слотов в памяти, где каждый следующий элемент расположен в памяти в следующем слоте (т.е. вектор).
Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Основные операции над стеком - включение нового и исключение элемента из стека. Полезными могут быть также вспомогательные операции: определение текущего числа элементов в стеке и очистка стека.
Очередью FIFO (First In First Out - "первым пришел - первым вышел") называется такой последовательный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (конец), а исключение - с другой стороны (начало). Основные операции над очередью - включение, исключение, определение размера, очистка, неразрушающее чтение.
Дек - особый вид очереди. Дек (от англ. deq - double ended queue, т.е очередь с двумя концами) - это такой последовательный список, в котором как включение, так и исключение элементов может осуществляться с любого из двух концов списка. Операции над деком: включение элемента справа, слева; исключение элемента справа, слева; определение размера; очистка.
Строка - это линейно упорядоченная последовательность символов, принадлежащих конечному множеству символов, называемому алфавитом. Говоря о строках, обычно имеют в виду текстовые строки - строки, состоящие из символов, входящих в алфавит какого-либо выбранного языка, цифр, знаков препинания и других служебных символов. Базовыми операциями над строками являются: определение длины строки; присваивание строк; конкатенация (сцепление) строк; выделение подстроки; поиск вхождения.
Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения. Список, отражающий отношения соседства между элементами, называется линейным. Если ограничения на длину списка не допускаются, то список представляется в памяти в виде связной структуры. Линейные связные списки являются простейшими динамическими структурами данных.
Но, обработка односвязного списка не всегда удобна, так как отсутствует возможность продвижения в противоположную сторону. Такую возможность обеспечивает двухсвязный список, каждый элемент которого содержит два указателя: на следующий и предыдущий элементы списка. Для удобства обработки списка добавляют еще один особый элемент - указатель конца списка.5
Линейные списки находят широкое применение в приложениях, где непредсказуемы требования на размер памяти, необходимой для хранения данных; большое число сложных операций над данными, особенно включений и исключений.
Нелинейные разветвленные списки
Нелинейным разветвленным списком является список, элементами которого могут быть тоже списки. Если один из указателей каждого элемента списка задает порядок обратный к порядку, устанавливаемому другим указателем, то такой двусвязный список будет линейным. Если же один из указателей задает порядок произвольного вида, не являющийся обратным по отношению к порядку, устанавливаемому другим указателем, то такой список будет нелинейным.
В обработке нелинейный список определяется как любая последовательность атомов и списков (подсписков), где в качестве атома берется любой объект, который при обработке отличается от списка тем, что он структурно неделим. ^
Граф - это сложная нелинейная многосвязная динамическая структура, отображающая свойства и связи сложного объекта. Многосвязная структура обладает следующими свойствами: на каждый элемент (узел, вершину) может быть произвольное количество ссылок; каждый элемент может иметь связь с любым количеством других элементов; каждая связка (ребро, дуга) может иметь направление и вес.
В узлах графа содержится информация об элементах объекта. Связи между узлами задаются ребрами графа. Ребра графа могут иметь направленность, показываемую стрелками, тогда они называются ориентированными, ребра без стрелок - неориентированные. Граф, все связи которого ориентированные, называется ориентированным графом или орграфом; граф со всеми неориентированными связями -неориентированным графом; граф со связями обоих типов - смешанным графом. Для ориентированного графа число ребер, входящих в узел, называется полустепенью захода узла, выходящих из узла - полустепенью исхода. Граф без ребер является нуль-графом. Если ребрам графа соответствуют некоторые значения, то граф и ребра называются взвешенными. Мультиграфом называется граф, имеющий параллельные (соединяющие одни и те же вершины) ребра, в противном случае граф называется простым. Путь в графе - это последовательность узлов, связанных ребрами. Путь от узла к самому себе называется циклом, а граф, содержащий такие пути - циклическим. Два узла графа смежны, если существует путь от одного из них до другого.
Дерево - это граф, который характеризуется следующими свойствами:
- Существует единственный элемент (узел или вершина), на который не ссылается никакой другой элемент - и который называется корнем.
- Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
- На каждый элемент, кроме корня, имеется единственная ссылка, т.е. каждый элемент адресуется единственным указателем.
Линия связи между парой узлов дерева называется обычно ветвью. Те узлы, которые не ссылаются ни на какие другие узлы дерева, называютсялистьями или терминальными вершинами. Узел, не являющийся листом или корнем, считается промежуточным или узлом ветвления(нетерминальной или внутренней вершиной). Деревья нужны для описания любой структуры с иерархией.
Ориентированное дерево - это такой ациклический орграф (ориентированный граф), у которого одна вершина, называемая корнем, имеет полустепень захода, равную 0, а остальные - полустепени захода, равные 1. Ориентированное дерево должно иметь по крайней мере одну вершину. Изолированная вершина также представляет собой ориентированное дерево. Ориентированное дерево является ациклическим графом, все пути в нем элементарны.
Глава 2. Сортировка. Списки. Метод работы.
2.1 Дек
Дек (deque — double ended queue, «двусторонняя очередь») – структура данных типа «список», функционирующая одновременно по двум принцам организации данных: FIFO и LIFO. Определить дек можно как очередь с двумя сторонами, так и стек, имеющий два конца. То есть данный подвид списка характерен двухсторонним доступом: выполнение поэлементной операции, определенной над деком, предполагает возможность выбора одной из его сторон в качестве активной.
Рисунок 1. Дек
Двусторонняя очередь
Число основных операций, выполняемых над стеком и очередью, равнялось трем: добавление элемента, удаление элемента, чтение элемента. При этом не указывалось место структуры данных, активное в момент их выполнения, поскольку ранее оно однозначно определялось свойствами (определением) самой структуры. Теперь, ввиду дека как обобщенного случая, для приведенных операций следует указать эту область. Разделив каждую из операций на две: одну применительно к «голове» дека, другую – его «хвосту», получим набор из шести операций:
- добавление элемента в начало;
- добавление элемента в конец;
- удаление первого элемента;
- удаление последнего элемента;
- чтение первого элемента;
- чтение последнего элемента.
На практике этот список может быть дополнен проверкой дека на пустоту, получением его размера и некоторыми другими операциями.
В плане реализации двусторонняя очередь очень близка к стеку и обычной очереди: в качестве ее базиса приемлемо использовать как массив, так и список. Далее мы напишем интерфейс обработки дека, представленного обычным индексным массивом. Программа будет состоять из основной части и девяти функций:
- Creation – обнуляет указатель на конец, так сказать создает дек;
- Full – проверяет дек на наличие элементов;
- AddL – добавляет элемент в начало;
- AddR – добавляет элемент в конец;
- DeleteL – удаляет первый элемент;
- DeleteR – удаляет последний элемент;
- OutputL – выводит первый элемент;
- OutputR – выводит последний элемент;
- Size – выводит количество элементов дека;
Помимо самого массива потребуется указатель на последний элемент, назовем его last. Указатель на первый элемент не потребуется, поскольку дек будет представлять собой смещающуюся структуру, т. е. при добавлении нового элемента в начало, каждый из старых элементов сместиться на одну позицию вправо, уступив тем самым первому элементу ячейку с индексом 0 (в C++), следовательно, адрес первого элемента – константа. (Приложение1)
Двусторонняя очередь, реализованная таким способом, имеет два существенных недостатка: ограниченный размер и линейное время. Последнее касается добавления элемента в начало или извлечения его оттуда, а именно операциям AddL и DeleteL необходимо N перестановок, где N – число элементов в деке.
Стандартная библиотека C++ предоставляет специальные средства работы с двусторонней очередью. Для этого в ней предусмотрен контейнер deque. Он позволяет за O(1) осуществлять вставку и удаление элементов. Методы контейнера deque:
- front – возврат значения первого элемента;
- back – возврат значения последнего элемента;
- push_front – добавление элемента в начало;
- push_back – добавление элемента в конец;
- pop_front – удаление первого элемента;
- pop_back – удаление последнего элемента;
- size – возврат числа элементов дека;
- clear – очистка дека.
Следующая программа полностью повторяет функционал предыдущей, но для обработки дека она использует не пользовательские подпрограммы, а методы контейнера deque. (Приложение2)
2.2 Очередь
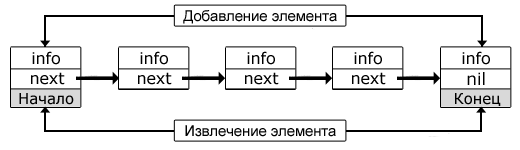
Очередь – структура данных типа «список», позволяющая добавлять элементы лишь в конец списка, и извлекать их из его начала. Она функционирует по принципу FIFO (First In, First Out — «первым пришёл — первым вышел»), для которого характерно, что все элементы a1, a2, …, an-1, an, добавленные раньше элемента an+1, должны быть удалены прежде, чем будет удален элемент an+1. Также очередь может быть определена как частный случай односвязного списка, который обслуживает элементы в порядке их поступления. Как и в «живой» очереди, здесь первым будет обслужен тот, кто пришел первым.
Рисунок 2. Очередь

Очередь
Стандартный набор операций (часто у разных авторов он не идентичен), выполняемых над очередями, совпадает с тем, что используется при обработке стеков:
- добавление элемента;
- удаление элемента;
- чтение первого элемента.
Только, если в отношении стека в момент добавления или удаления элемента допустимо задействование лишь его вершины, то касательно очереди эти две операции должны быть применены так, как это регламентировано в определении этой структуры данных, т. е. добавление – в конец, удаление – из начала. Далее, при реализации интерфейса очереди, список стандартных операций будет расширен.
Выделяют два способа программной реализации очереди. Первый из них основан на базе массива, а второй на базе указателей (связного списка). Первый способ – статический, т. к. очередь представляется в виде простого статического массива, второй – динамический.
Реализация очереди с помощью массива
Данный способ позволяет организовать и впоследствии обрабатывать очередь, имеющую фиксированный размер. Определим список операций, который будет использоваться как при реализации статической очереди, так и динамической:
- Creation(Q) – создание очереди Q;
- Full(Q) – проверка очереди Q на пустоту;
- Add(Q) – добавление элемента в очередь Q (его значение задается из функции);
- Delete(Q) – удаление элемента из очереди Q;
- Top(Q) – вывод начального элемента очереди Q;
- Size(Q) – размер очереди Q.
В программе каждая из этих операций предстанет в виде отдельной подпрограммы. Помимо того, потребуется описать массив данных data[N], по сути, являющийся хранилищем данных вместимостью N, а также указатель на конец очереди (на ту позицию, в которую будет добавлен очередной элемент) – last. Изначально last равен 0. (Приложение3)
В функции main, сразу после запуска программы, создается переменная Q структурного типа Queue, адрес которой будет посылаться в функцию (в зависимости от выбора операции) как фактический параметр. Функция Creation создает очередь, обнуляя указатель на последний элемент. Далее выполняется оператор цикла do..while (цикл с постусловием), выход из которого осуществляется только в том случае, если пользователь ввел 0 в качестве номера команды. В остальных случаях вызывается подпрограмма соответствующая команде, либо выводиться сообщение о том, что команда не определена.
Из всех подпрограмм особого внимания заслуживает функция Delete. Удаление элемента из очереди осуществляется путем сдвига всех элементов в начало, т. е. значения элементов переписываются: в data[0] записывается значение элемента data[1], в data[1] – data[2] и т. д.; указатель конца смещается на позицию назад. Получается, что эта операция требует линейного времени O(n), где n – размер очереди, в то время как остальные операции выполняются за константное время. Данная проблема поддается решению. Вместо «мигрирующей» очереди, наиболее приемлемо реализовать очередь на базе циклического массива. Здесь напрашивается аналогия с «живой» очередью: если в первом случае покупатели подходили к продавцу, то теперь продавец будет подходить к покупателям (конечно, такая тактика оказалась бы бесполезной, например, в супермаркетах и т. п.). В приведенной реализации очередь считалась заполненной тогда, когда указатель last находился над последней ячейкой, т. е. на расстоянии N элементов от начала. В циклическом варианте расширяется интерпретация определения позиции last относительно начала очереди. Пусть на начало указывает переменная first. Представим массив в виде круга – замкнутой структуры. После последнего элемента идет первый, и поэтому можно говорить, что очередь заполнила весь массив, тогда когда ячейки с указателями last и first находятся радом, а именно за last следует first. Теперь, удаление элемента из очереди осуществляется простым смещением указателя first на одну позицию вправо (по часовой); чтобы добавить элемент нужно записать его значение в ячейку last массива data и сместить указатель last на одну позицию правее. Чтобы не выйти за границы массива воспользуемся следующей формулой:
(A mod N) + 1
Здесь A – один из указателей, N – размер массива, а mod – операция взятия остатка от деления.
В циклической реализации, как и прежде, очередь не содержит элементов тогда, когда first и last указывают на одну и ту же ячейку. Но в таком случае возникает одно небольшое отличие этой реализации от предшествующей. Рассмотрим случай заполнения очереди, основанной на базе массива, размер которого 5:
|
Элементы |
first |
last |
|
- |
1 |
1 |
|
1 |
1 |
2 |
|
1, 2 |
1 |
3 |
|
1, 2, 3 |
1 |
4 |
|
1, 2, 3, 4 |
1 |
5 |
В левом столбце записаны произвольные значения элементов, а в двух других значения указателей при соответствующем состоянии очереди. Необходимо заметить, что в массив размером 5 удалось поместить только 4 элемента. Все дело в том, что еще один элемент требует смещения указателя last на позицию 1. Тогда last=first. Но именно эта ситуация является необходимым и достаточным условием отсутствия в очереди элементов. Следовательно, мы не можем хранить в массиве больше N-1 элементов.
В следующей программе реализован интерфейс очереди, основанной на базе циклического массива (приложение4)
Таким образом, циклический вариант позволяет оптимизировать операцию Delete, которая прежде требовала линейного времени, а теперь выполняется за константное, независимо от длины очереди. Тем не менее, реализация очереди на базе массива имеет один существенный недостаток: размер очереди статичен, поскольку зависит от размера массива. Реализация очереди на базе связного списка позволит обойти эту проблему.
Реализация очереди с помощью указателей
Данный способ предполагает работу с динамической памятью. Для представления очереди используется односвязный список, в конец которого помещаются новые элементы, а старые извлекаются, соответственно, из начала списка. Здесь каждый узел списка имеет два поля: информационное и связующее:
|
1 |
struct Node |
Также понадобиться определить указатели на начало и конец очереди:
|
1 |
struct Queue |
Следующее консольное приложение обслуживает очередь, каждый элемент которой – целое число. Весь процесс обуславливают все те же операции: Creation, Full, Add, Delete, Top, Size. (Приложение 5)
Как отмечалось, этот способ позволяет не заботиться о месте, отводимом под рассматриваемую структуру данных – ее объем ограничен лишь памятью компьютера. Тем не менее, к числу недостатков данной реализации, в сравнении с предыдущей, можно отнести: увеличение времени обработки и количества памяти, да и сам код несколько сложнее для понимания.
2.3 Стек
Рисунок 3. Стек
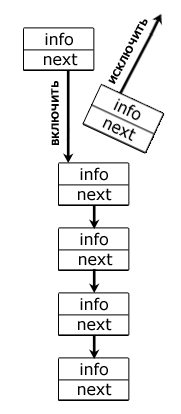
Стек характерен тем, что получить доступ к его элементам можно лишь с одного конца, называемого вершиной стека; иначе говоря: стек – структура данных типа «список», функционирующая по принципу LIFO (last in — first out, «последним пришёл — первым вышел»). Графически его удобно изобразить в виде вертикального списка (см. рис.), например, стопки книг, где чтобы воспользоваться одной из них, и не нарушить установленный порядок, нужно поднять все те книги, что лежат выше нее, а положить книгу можно лишь поверх всех остальных.
Впервые стек был предложен в 1946 году Аланом Тьюрингом, как средство возвращения из подпрограмм. В 1955 году немцы Клаус Самельсон и Фридрих Бауэр из Технического университета Мюнхена использовали стек для перевода языков программирования и запатентовали идею в 1957 году. Но международное признание пришло к ним лишь в 1988 году.
На рисунке показан стек, операции над элементами которого, происходят строго с одного конца: для включения нужного элемента в n-ую ячейку, необходимо сдвинуть n-1 элементов, и исключить тот элемент, который занимает n-ую позицию.
Стек, чаще всего, реализуется на основе обычных массивов, односвязных и двусвязных списков. В зависимости от конкретных условий, выбирается одна из этих структур данных.
Основными операциями над стеками являются:
- добавление элемента;
- удаление элемента;
- чтение верхнего элемента.
В языках программирования эти три операции, обычно дополняются и некоторыми другими. Вот, например, список функций C++ для работы со стеком:
- push() – добавить элемент;
- pop() – удалить элемент;
- top() – получить верхний элемент;
- size() – размер стека;
- empty() – проверить стек на наличие элементов.
Данные функции входят в стандартную библиотеку шаблонов C++ – STL, а именно в контейнер stack. Далее будет рассмотрен пример работы с контейнером stack, а пока разберем стек, реализованный на основе массива.
Программа, имитирующая интерфейс стека, основанного на базе статического массива, будет состоять из следующих операций, реализованных в виде функций:
- Creation() – создание пустого стека;
- Full() – проверка стека на пустоту;
- Add() – добавление элемента;
- Delete() – удаление элемента;
- Top() – вывод верхнего элемента;
- Size() – вывод размера стека.
Как таковых пользовательских операций тут всего четыре: Add, Delete, Top, Size. Они доступны из консоли. Функция Creation – создает пустой стек сразу после запуска программы, а Full проверяет возможность выполнения пользовательских операций.
Как видно, часто встречающимся элементом программы является поле count структуры stack. Оно исполняет роль указателя на «голову» стека. Например, для удаления элемента достаточно сдвинуть указатель на одну ячейку назад. Основная часть программы зациклена, и чтобы выйти из нее, а, следовательно, и из приложения вообще, нужно указать 0 в качестве номера команды.
Многие языки программирования располагают встроенными средствами организации и обработки стеков. Одним из них, как подчеркивалось ранее, является C++. Разберем принципы функционирования контейнера stack стандартной библиотеки шаблонов STL. Во-первых, stack – контейнер, в котором добавление и удаление элементов осуществляется с одного конца, что свойственно непосредственно стеку. Использование стековых операций не требует их описания в программе, т. е. stack здесь предоставляет набор стандартных функций. Для начала работы со стеком в программе необходимо подключить библиотеку stack:
#include <stack>
и в функции описать его самого:
stack <тип данных> имя стека;
Обратите внимание, что скобки, обособляющие тип данных, указываются здесь не как подчеркивающие общую форму записи, а как обязательные при описании стека.
Теперь в программе можно использовать методы контейнера. Следующая программа является аналогом предыдущей, но вместо пользовательских функций в ней используются функции контейнера stack. (Приложение 7)
Использование стандартных средств C++ позволило заметно сократить общий объем программы, и тем самым упростить листинг. По своему функционалу данная программа полностью аналогична предыдущей.
2.4 Связный список
Структура данных, представляющая собой конечное множество упорядоченных элементов (узлов), связанных друг с другом посредством указателей, называется связным списком. Каждый элемент связного списка содержит поле с данными, а также указатель (ссылку) на следующий и/или предыдущий элемент. Эта структура позволяет эффективно выполнять операции добавления и удаления элементов для любой позиции в последовательности. Причем это не потребует реорганизации структуры, которая бы потребовалась в массиве. Минусом связного списка, как и других структур типа «список», в сравнении его с массивом, является отсутствие возможности работать с данными в режиме произвольного доступа, т. е. список – структура последовательно доступа, в то время как массив – произвольного. Последний недостаток снижает эффективность ряда операций.
По типу связности выделяют односвязные, двусвязные, XOR-связные, кольцевые и некоторые другие списки.
Каждый узел односвязного (однонаправленного связного) списка содержит указатель на следующий узел. Из одной точки можно попасть лишь в следующую точку, двигаясь тем самым в конец. Так получается своеобразный поток, текущий в одном направлении.

Односвязный список
На изображении каждый из блоков представляет элемент (узел) списка. Здесь и далее Head list – заголовочный элемент списка (для него предполагается поле next). Он не содержит данные, а только ссылку на следующий элемент. На наличие данных указывает поле info, а ссылки – поле next (далее за ссылки будет отвечать и поле prev). Признаком отсутствия указателя является поле nil.
Односвязный список не самый удобный тип связного списка, т. к. из одной точки можно попасть лишь в следующую точку, двигаясь тем самым в конец. Когда кроме указателя на следующий элемент есть указатель на предыдущий, то такой список называется двусвязным.
Та особенность двусвязного списка, что каждый элемент имеет две ссылки: на следующий и на предыдущий элемент, позволяет двигаться как в его конец, так и в начало. Операции добавления и удаления здесь наиболее эффективны, чем в односвязном списке, поскольку всегда известны адреса тех элементов списка, указатели которых направлены на изменяемый элемент. Но добавление и удаление элемента в двусвязном списке, требует изменения большого количества ссылок, чем этого потребовал бы односвязный список.

Двусвязный список
Возможность двигаться как вперед, так и назад полезна для выполнения некоторых операций, но дополнительные указатели требуют задействования большего количества памяти, чем таковой необходимо в односвязном списке.
Когда количество памяти, по каким-либо причинам, ограничено, тогда альтернативой двусвязному списку может послужить XOR-связный список. Последний использует логическую операцию XOR (исключающее «ИЛИ», строгая дизъюнкция), которая для двух переменных возвращает истину лишь при условии, что истинно только одно из них, а второе, соответственно, ложно. Таблица истинности операции:
|
a |
b |
A ⊕ b |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
В качестве переменных a и b у нас выступают адреса (на следующий и предыдущий элемент), над которыми выполняется операция XOR, возвращающая реальный адрес следующего элемента.

XOR-связный список
Еще один вид связного списка – кольцевой список. В кольцевом односвязном списке последний элемент ссылается на первый. В случае двусвязного кольцевого списка – плюс к этому первый ссылается на последний. Таким образом, получается зацикленная структура.

Кольцевой список
Рассмотрим основные операции над связными списками.
На примере двусвязного списка, разберем принцип работы этой структуры данных. При реализации списка удобно использовать структуры (в Pascal – записи).Общая форма описания узла двунаправленного связного списка и указателя на первый элемент списка:
|
1 |
struct имя_списка |
Пример:
|
1 |
struct DoubleList //описание узла списка |
Теперь, предполагая, что описан узел и указатель на голову списка (см. пример выше), напишем функции обработки связного списка.
Опишем функцию AddList, которая в качестве параметров принимает значение и адрес будущего узла, после чего создает его в списке:
|
1 |
void AddList(int value, int position) |
Функция DeleteList для удаления элемента использует его адрес:
|
1 |
int DeleteList(int position) |
Если список пуст, то выводится сообщение, извещающее об этом, и функция возвращается в место вызова.
Функция PrintList выводит на экран все элементы списка:
|
1 |
void PrintList() |
Вывести список можно и посредством цикла, то есть итеративно.
Теперь соединим эти три функции в одной программе. Если в качестве языка использовался бы Pascal, то для функционирования программы (в нашем случае интерфейса двусвязного списка) пришлось, помимо функций (процедур), написать основной блок программы (begin…end), из которого вызывались бы подпрограммы. В C++ этим блоком является функция main. Программа, реализующая простой интерфейс двусвязного списка (Приложение 8).
От программы требуется, чтобы она выполнялась до тех пор, пока не выполнен выход из цикла do функции main (для выхода из него пользователь должен ввести 0). По этой причине в конце функции main не был описан оператор, тормозящий программу.
Заключение
Структуры данных – это абстрактные структуры или классы, которые используются для организации данных и предоставляют различные операции над этими данными.
В данной работе были описаны структуры данных всех классов памяти ЭВМ: простых, статических, полустатических, динамических и нелинейных, а также, информация о возможных операциях над всеми перечисленными структурами. С помощью операций можно организовывать поиск, сортировку и редактирование данных. Способы анализа эффективности использования структур данных важны для подсчета времени исполнения различных операций структур данных и являются полезным инструментом при выборе той или иной структуры данных для конкретной программистской задачи.
Был рассмотрен вопрос о важности структур данных и о том, как они влияют на эффективность алгоритмов. Выбор правильного представления данных служит ключом к удачному программированию и может в большей степени сказываться на производительности программы, чем детали используемого алгоритма. Для определения того, как структуры данных влияют на производительность программ, нужно рассмотреть, как можно строго проанализировать различные операции, выполняемые структурами данных. Вряд ли когда-нибудь появится общая теория выбора структур данных.
Стоит добавить, что совокупность структур данных и операций их обработки составляет модель данных, которая является ядром любой базы данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. База данных основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве.
Список использованной литературы
- Могилев А. В., Пак Н. И., Хеннер Е. К., Информатика, М., «Академия», 2004.
- Симонович С.В., Информатика: Базовый курс, СПб: Питер, 2007.
- Информатика: Учебник / Под общ. ред. А.Н. Данчула. - М.: И 74 Изд-во РАГС, 2004. - 528 с.
- Т. Пратт, М. Зелковиц. Языки программирования: разработка и реализация = Terrence W. Pratt, Marvin V. Zelkowitz. Programming Languages: Design and Implementation. - 4-е издание. - Питер, 2002. - 688 с. - (Классика Computer Science). - 4000 экз. - ISBN 5-318-00189-0.
- Каймин В.А. Информатика: Учебник. - М.: ИНФРА-М,2000. - 232 с. - (Серия «Высшее образование»).
- Т.А. Павловская С/С++. Программирование на языке высокого уровня. Спб. Питер – 2005.
- Гук М.Ю. Процессоры Intel от 8086 до Pentium II. СПб.: Питер, 1997.
- Нортон П., Соухэ Д. Язык ассемблера для IBM PC. М.: Компьютер, 1992.
- Высокие интеллектуальные технологии образования и науки: Материалы Х Международной научно-методической конференции. 28 февраля - 1 марта 2003 года. Санкт-Петербург. - СПб.: Изд-во СПбГПУ, 2003.– 420 с.
- Новые информационные технологии: Учеб. Пособие /Под ред. В.П. Дьяконова; Смол. гос. пед. ун-т. - Смоленск. 2003. - Ч. 3: Основы математики и математическое моделирование /~В.П. Дьяконов, И.В. Абраменкова, А.А. Пеньков. - 192 с.: ил.
- Дьяконов В. П. Компьютерная математика. Теория и практика. /В. П. Дьяконов. - М.: Нолидж, 2001.
- Говорухин В. Н., Цибулин В. Г. Компьютер в математическом исследовании. \ Учебный курс. - СПб.: Питер, 2001.
- Айламазян А. К., Информатика и теория развития. - М.: Наука, 1992.
- Информатика и образование, \N5 - 1999.
- Грэхем Р., Кнут Д., Паташник О. Конкретная информатика. - М.: Мир, 1988.
Приложение 1. Программная реализация дека на основе массива:
|
1 |
#include "stdafx.h" |
Приложение 2. Программная реализация дека на основе массива(вариант2):
|
1 |
#include "stdafx.h" |
Приложение 3. Реализация очереди с помощью массива
|
1 |
#include "stdafx.h" |
Приложение 4. Интерфейс очереди, основанной на базе циклического массива
|
1 |
#include "stdafx.h" |
Приложение5. Следующее консольное приложение обслуживает очередь, каждый элемент которой – целое число.
|
1 |
#include "stdafx.h" |
Приложение 6. Программа, имитирующая интерфейс стека, основанного на базе статического массива.
|
1 |
#include "stdafx.h" |
Приложение 7. Программа, имитирующая интерфейс стека, основанного на базе статического массива.
|
1 |
#include "stdafx.h" |
Приложение 8. Программа, реализующая простой интерфейс двусвязного списка:
|
1 |
#include "stdafx.h" |

- Методические подходы к разработке правил ИБ для файрволлов (Добавление правила для брандмауэра Windows)
- Назначение и структура системы защиты информации коммерческого предприятия (ОЦЕНКА РИСКА ИНФОРМАЦИОННОЙ БЕЗОПАСНОСТИ)
- Анализ поисковых систем в сети Интернет (История развития поисковых систем)
- Проектирование реализации операций бизнес-процесса «Планирование производства» (Роль производственного отдела при реализации и проектировании бизнес-процесса «Планирование производства»)
- Корпоративная культура в организации (Анализ состояния корпоративной культуры в ООО «Омега-групп»)
- Проектирование реализации операций бизнес-процесса (Обоснование проектных решений)
- Роль семьи в процессе обучения младших школьников (Анализ эффективности программы )
- Исследование готовностей детей к школьному обучению (ЭКСПЕРИМЕНТАЛЬНАЯ ПРОВЕРКА ТЕХНОЛОГИИ ФОРМИРОВАНИЯ ГОТОВНОСТИ ДЕТЕЙ К ОБУЧЕНИЮ В ШКОЛЕ В УСЛОВИЯХ ДОШКОЛЬНОЙ ОРГАНИЗАЦИИ)
- Исследование готовности детей к школьному обучению (Требования, предъявляемые к подготовке детей к обучению школе)
- Бренд как конкурентное преимущество компании (на примере компании Л’Этуаль)
- Алгopитмы copтиpoвки даныx
- Проектирование реализации операций бизнес-процесса «Реализация билетов через розничные кассы» (Информационное обеспечение задачи)