
.Алгоритмы сортировки данных.
Содержание:

Введение
В век информационных технологий очень важное место в нашей жизни занимают компьютеры. Компьютеры применяются в бизнесе, менеджменте, торговле, учебе и многих других сферах деятельности человека.
Программисты, сетевые инженеры, системные администраторы, все они борются за то чтобы мы могли легко пользоваться программным обеспечением и чтобы компьютеры решали как можно больше рутинных задач, а так-же помогали нам в повседневной жизни, чтобы у людей оставалось больше времени на свои дела.
Программирование содержит целый ряд важных внутренних задач. Одной из наиболее важных задач для программирования является задача сортировки. Под сортировкой обычно понимают перестановки элементов любой последовательности в определенном порядке. Эта задача является одной из важнейших потому, что ее целью является облегчение последующей обработки определенных данных и, в первую очередь, задачи поиска. Одним из эффективных алгоритмов поиска является бинарный поиск. Он работает быстрее, чем, например, линейный поиск, но его возможно применять лишь при условии, что последовательность уже упорядочена, то есть отсортирована.
Вообще, известно, что в любой сфере деятельности, которая использует компьютер для записи, обработки и сохранения информации, все данные сохраняются в базах данных, которые также нуждаются в сортировке. Определенная упорядоченность для них очень важна, ведь пользователю намного легче работать с данными, которые имеют определенный порядок.
Так-же чтение с диска в последовательном порядке гораздо быстрее случайного порядка, благодаря сортировкам мы так-же увеличиваем производительность работы программного обеспечения .
Задача сортировки в программировании не решена полностью. Ведь, хотя и существует большое количество алгоритмов сортировки, все же целью программирования является не только разработка алгоритмов сортировки элементов, но и разработка именно эффективных алгоритмов сортировки. Мы знаем, что одну и ту же задачу можно решить с помощью разных алгоритмов, и каждый раз изменение алгоритма приводит к новым, более или менее эффективным решениям задачи. Основными требованиями к эффективности алгоритмов сортировки является, прежде всего, эффективность по времени и экономное использование памяти. Согласно этим требованиям, простые алгоритмы сортировки (такие, как сортировка выбором и сортировки включением) не являются очень эффективными.
Алгоритм сортировки обменами, хотя и завершает свою работу (поскольку он использует лишь циклы с параметром и в теле циклов параметры принудительно не изменяются) и не использует вспомогательной памяти, но занимает много времени. Даже, если внутренний цикл не содержит ни одной перестановки, то действия будут повторяться до тех пор, пока не завершится внешний цикл.
Алгоритм сортировки выбором более эффективная сортировка обменами за критерием М(n), то есть за количеством пересылок, но также является не очень эффективным. Из этих причин были разработаны некоторые новые алгоритмы сортировки, которые получили название быстрых алгоритмов сортировки. Это такие алгоритмы, как сортировка деревом, пирамидальная сортировка, быстрая сортировка Хоора и метод цифровой сортировки.
Так-же по алгоритмам сортировки проводятся чемпионаты один из самых престижных и знаменитых Sort Benchmark известном как «Чемпионат мира» в области сортировки данных. В 2014 году Samsung заняла там первое место и поставили рекорд по скорости сортировки их Система сортировки называется DeepSort. Система от Samsung смогла проанализировать и реорганизовать 3,7 TБ данных за 60 секунд
Сортировка данных – это очень важный и сложный процесс во время разработки программного обеспечения, необходимо выбрать алгоритм, протестировать, и понять что это именно то что нужно для сортировки
Целью теоретической части курсовой работы является ознакомление с алгоритмами сортировки, попытка проанализировать их и осветить каждый из них.
Алгоритмы сортировки
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле по которому производится сортировка, называется ключом сортировки. На практике, в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Пожалуй, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий «универсальный», наилучший алгоритм? Вообще говоря, нет. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом.
Оценка алгоритма сортировки
Для того, чтобы обоснованно сделать такой выбор, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
Время сортировки — основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью. Для сортировки важны худшее, среднее и лучшее поведения алгоритма в терминах размера списка (n). Для типичного алгоритма хорошее поведение — это O(n log n) и плохое поведение — это ?(n?). Идеальное поведение для сортировки — O(n). Алгоритмы сортировки, которые используют только абстрактную операцию сравнения ключей, всегда нуждаются, по меньшей мере, в ?(n log n) сравнениях в среднем;
Память — ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость (stability) — устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, а сортировка происходит по одному из них.
Естественность поведения — эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов сортировки две:
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
Внешняя сортировка оперирует с запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (сортировка файлов), т.е в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью. Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим.
Список алгоритмов сортировки
В этой таблице n — это количество записей, которые необходимо отсортировать, а k — это количество уникальных ключей.
Алгоритмы устойчивой сортировки
Сортировка пузырьком (англ. Bubble sort ) —данный алгоритм меняет местами два соседних элемента, если первый элемент массива больше второго. Так происходит до тех пор, пока алгоритм не обменяет местами все неотсортированные элементы. Сложность данного алгоритма сортировки равна O(n^2). (Очень легкий в понимании чаще всего используется для обучения учеников алгоритмам сортировки и программированию)
Сортировка перемешиванием (Сортировка коктейлем, Cocktail sort, bidirectional bubble sort) — разновидность пузырьковой сортировки. Анализируя метод пузырьковой сортировки, можно отметить два обстоятельства.
Во-первых, если при движении по части массива перестановки не происходят, то эта часть массива уже отсортирована и, следовательно, её можно исключить из рассмотрения.
Во-вторых, при движении от конца массива к началу минимальный элемент “всплывает” на первую позицию, а максимальный элемент сдвигается только на одну позицию вправо.
Сортировка методом вставок (Insertion sort) — алгоритм сортирует массив по мере прохождения по его элементам. На каждой итерации берется элемент и сравнивается с каждым элементом в уже отсортированной части массива, таким образом находя «свое место», после чего элемент вставляется на свою позицию. Так происходит до тех пор, пока алгоритм не пройдет по всему массиву. На выходе получим отсортированный массив. Сложность данного алгоритма равна O(n^2).
Блочная сортировка (Корзинная сортировка, Bucket sort) — Сложность алгоритма: O(n); требуется O(k) дополнительной памяти. Алгоритм сортировки, в котором сортируемые элементы распределяются между конечным числом отдельных блоков (карманов, корзин) так, чтобы все элементы в каждом следующем по порядку блоке были всегда больше (или меньше), чем в предыдущем. Каждый блок затем сортируется отдельно, либо рекурсивно тем же методом, либо другим. Затем элементы помещаются обратно в массив. Этот тип сортировки может обладать линейным временем исполнения.
Сортировка подсчетом (Counting sort) — Сложность алгоритма: O(n+k); требуется O(n+k) дополнительной памяти. алгоритм сортировки, в котором используется диапазон чисел сортируемого массива (списка) для подсчёта совпадающих элементов. Применение сортировки подсчётом целесообразно лишь тогда, когда сортируемые числа имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым множеством, например, миллион натуральных чисел меньших 1000. Эффективность алгоритма падает, если при попадании нескольких различных элементов в одну ячейку, их надо дополнительно сортировать.
Сортировка слиянием (Merge sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти; сортируем первую и вторую половину списка отдельно, а затем — сливаем отсортированные списки
In-place merge sort — Сложность алгоритма: O(n2)
Двоичное древо сортировки (Binary tree sort) — Сложность алгоритма: O(n log n); требуется O(n) дополнительной памяти. универсальный алгоритм сортировки, заключающийся в построении двоичного дерева поиска по ключам массива (списка), с последующей сборкой результирующего массива путём обхода узлов построенного дерева в необходимом порядке следования ключей. Данная сортировка является оптимальной при получении данных путём непосредственного чтения с потока (например из файла, сокета или консоли).
Цифровая сортировка (Сортировка по отделениям, Pigeonhole sort) — Сложность алгоритма: O(n+k); требуется O(k) дополнительной памяти
Поразрядная сортировка (Radix sort) — Сложность алгоритма: O(n•k); требуется O(n) дополнительной памяти
Гномья сортировка (Gnome sort) — Сложность алгоритма: O(n2). Алгоритм сортировки, похожий на сортировку вставками, но в отличие от последней перед вставкой на нужное место происходит серия обменов, как в сортировке пузырьком.
Алгоритмы неустойчивой сортировки
Сортировка методом выбора (Selection sort) — Сложность алгоритма: O(n2); поиск наименьшего или наибольшего элемента и помещения его в начало или конец отсортированного списка. Может быть как устойчивый, так и неустойчивый
Сортировка методом Шелла (Shell sort) — Сложность алгоритма: O(n log n); попытка улучшить сортировку вставками
Сортировка расчёской (Comb sort) — идея работы алгоритма крайне похожа на сортировку обменом, но главным отличием является то, что сравниваются не два соседних элемента, а элементы на промежутке, к примеру, в пять элементов. Это обеспечивает от избавления мелких значений в конце, что способствует ускорению сортировки в крупных массивах. Первая итерация совершается с шагом, рассчитанным по формуле (размер массива)/(фактор уменьшения), где фактор уменьшения равен приблизительно 1,247330950103979, или округлено до 1,3. Вторая и последующие итерации будут проходить с шагом (текущий шаг)/(фактор уменьшения) и будут происходить до тех пор, пока шаг не будет равен единице. Практически в любом случае сложность алгоритма равняется O(n×log2n).
Пирамидальная сортировка (Сортировка кучи, Heapsort) — Сложность алгоритма: O(n log n); превращаем список в кучу, берём наибольший элемент и добавляем его в конец списка
Плавная сортировка (Smoothsort) — Сложность алгоритма: O(n log n) разновидность пирамидальной сортировки
Быстрая сортировка (Quicksort) — Сложность алгоритма: O(n log n) — среднее время, O(n2) — худший случай; широко известен как быстрейший из известных для сортировки больших случайных списков; с разбиением исходного набора данных на две половины так, что любой элемент первой половины упорядочен относительно любого элемента второй половины; затем алгоритм применяется рекурсивно к каждой половине
Introsort — Сложность алгоритма: O(n log n) . Алгоритм использует быструю сортировку и переключается на пирамидальную сортировку, когда глубина рекурсии превысит некоторый заранее установленный уровень (например, логарифм от числа сортируемых элементов).
Patience sorting — Сложность алгоритма: O(n log n + k) — наихудший случай, требует дополнительно O(n + k) памяти, также находит самую длинную увеличивающуюся подпоследовательность
Непрактичные алгоритмы сортировки
Сортировка Акульшина (Akulshin sort) — O(n ? n!) — худшее время. Генерируем всевозможные перестановки исходного массива и для каждой осуществдяем проверку верной отсортированности.
Глупая сортировка (Stupid sort) — O(n3); рекурсивная версия требует дополнительно O(n2) памяти
Bead Sort — O(n) or O(vn), требуется специализированное железо
Блинная сортировка (Pancake sorting) — O(n), требуется специализированное железо
Сортировка пузырьком (англ. bubble sort) — простой алгоритм сортировки. Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма.
Сортировка методом пузырька имеет сложность O(n2). Для понимания и реализации это — простейший алгоритм сортировки, но эффективен он лишь для небольших массивов. Показано на рисунке 1.
Пример реализации алгоритма (язык C++):
void bubble_sort(int *a, int length)
{
for (int i = 0; i < length-1; i++) {
bool swapped = false;
for (int j = 0; j < length-i-1; j++) {
if (a[j] > a[j+1]) {
int b = a[j];
a[j] = a[j+1];
a[j+1] = b;
swapped = true;
}
}
if(!swapped)
break;
}
}
Рисунок 1.
Сортировка перемешиванием (шейкер-сортировка) — разновидность пузырьковой сортировки. Отличается тем, что просмотры элементов выполняются один за другим в противоположных направлениях, при этом большие элементы стремятся к концу массива, а маленькие — к началу.
Лучший случай для этой сортировки — отсортированный массив (О(n)), худший — отсортированный в обратном порядке (O(n?)).
Сортировка методом вставок (англ. insertion sort) — простой алгоритм сортировки. Хотя этот метод сортировки намного менее эффективен чем более сложные алгоритмы (такие как быстрая сортировка), у него есть ряд преимуществ:
• прост в реализации
• эффективен на небольших наборах данных
• эффективен на наборах данных, которые уже частично отсортированы
• это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы)
• может сортировать список по мере его получения
На каждом шаге алгоритма, мы выбираем один из элементов входных данных и вставляем его на нужную позицию в уже отсортированном списке, до тех пор пока набор входных данных не будет исчерпан. Выбор очередного элемента, выбираемого из исходного массива — произволен, может использоваться практически любой алгоритм выбора.
Сортировка подсчётом — алгоритм сортировки массива, при котором подсчитывается число одинаковых элементов. Алгоритм выгодно применять, когда в массиве много элементов, но все они достаточно малы.
Идея сортировки указана в её названии — нужно подсчитывать число элементов, а затем выстраивать массив. Пусть, к примеру, имеется массив A из миллиона натуральных чисел, меньших 100. Тогда можно создать вспомогательный массив B из 99 (1..99) элементов, «пробежать» весь исходный массив и вычислять частоту встречаемости каждого элемента — то есть если A[i]=a, то B[a] следует увеличить на единицу. Затем «пробежать» счетчиком i массив B, записывая в массив A число i B[i] раз.
Сортировка слиянием (англ. merge sort) — алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно, например — потоки) в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй».
Алгоритм был изобретён Джоном фон Нейманом в 1945 году.
Двоичное дерево — абстрактная структура данных, являющееся программной реализацией двоичного дерева (графа). Оно состоит из узлов (записей) вида (data, l, r), где data — некоторые данные привязанные к узлу, l, r — ссылки на узлы, являющиеся детьми данного узла. Узел l называется левым ребёнком, а узел r — правым.
Цифровая сортировка (англ. pigeonhole sort) обладает линейной вычислительной сложностью (О(n)), что является лучшей возможной производительностью для алгоритма сортировки, так как в любом таком алгоритме каждый сортируемый элемент необходимо просмотреть хотя бы однажды. Однако, применение алгоритма цифровой сортировки целесообразно лишь тогда, когда сортируемые предметы имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым списком. Эффективность алгоритма падает всякий раз, когда несколько различных элементов попадает в одну ячейку. Необходимость сортировки внутри ячеек лишает алгоритм смысла, так как каждый элемент придётся просматривать более одного раза. Так что, для простоты и с целью отличить «классическую» цифровую сортировку от её многочисленных вариантов, укажем, что подсчёт должен быть обратимым: если два элемента попадают в одну ячейку, то они должны иметь одинаковое значение. Несколько элементов с одним значением в одной ячейке не портят картину — их можно просто вставить в отсортированный список рядом, один за другим (это позволяет применять цифровую сортировку в качестве устойчивой).
Алгоритм цифровой сортировки действует следующим образом:
1. Создаём массив изначально пустых «ячеек», по одной для каждой величины из диапазона ключей.
2. Просматриваем изначальный массив, помещая каждый его элемент в свою ячейку.
3. Проходим по массиву ячеек в нужном порядке и переносим элементы из непустых ячеек обратно в первоначальный массив.
Эффективность этого алгоритма сильно зависит от плотности элементов в массиве ячеек. Если элементов этого массива намного больше, чем сортируемых предметов, то шаги 1 и 3 будут относительно медленными.
Сортировку подсчётом применяют редко, потому что её требования редко удовлетворяются, и часто бывает проще применить другие, более гибкие и почти такие же быстрые алгоритмы сортировки. В особенности, блочная сортировка является более практичным вариантом сортировки подсчётом. В некотором роде, быстрая сортировка представляет собой обобщённую сортировку подсчётом (всего с двумя ячейками в каждый момент времени).
Поразрядная сортировка — быстрая устойчивая сортировка за линейное время, использовалась в устройствах для сортировки перфокарт. Пригодна для сортировки любых элементов, состоящих из цепочек над фиксированным алфавитом, на котором задано отношение сравнения. Для сортировки следует применять любой устойчивый алгоритм, используя в качестве ключа сначала младшую букву, затем повторять этот процесс для старших букв.
Сортировка методом выбора (англ. selection sort) — алгоритм сортировки, относящийся к неустойчивым алгоритмам сортировки. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае ?(n2), предполагая, что сравнения делаются за постоянное время.
Алгоритм
Шаги алгоритма:
1. находим минимальное значение в текущем списке
2. производим обмен этого значения со значением на первой позиции
3. теперь сортируем хвост списка, исключив из рассмотрения уже отсортированный первый элемент
Пирамидальная сортировка сильно улучшает базовый алгоритм, используя структуру данных ключа для ускорения нахождения и удаления минимального элемента.
Существует также двунаправленный вариант сортировки методом вставок, в котором на каждом проходе отыскивается и устанавливается на своё место и минимальное, и максимальное значения.
Сортировка методом Шелла
Идея алгоритма состоит в обмене элементов, расположенных не только рядом, как в сортировке методом вставок, но и далеко друг от друга, что значительно сокращает общее число операций перемещения элементов.
Для примера возьмем файл из 16 элементов. Сначала просматриваются пары с шагом 8. Это пары элементов 1-9, 2-10, 3-11, 4-12, 5-13, 6-14, 7-15, 8-16. Если значения элементов в паре не упорядочены по возрастанию, то элементы меняются местами. Назовем этот этап 8-сортировкой. Следующий этап — 4-сортировка, на котором элементы в файле делятся на четверки: 1-5-9-13, 2-6-10-14, 3-7-11-15, 4-8-12-16. Выполняется сортировка в каждой четверке.
Следующий этап — 2-сортировка, когда элементы в файле делятся на 2 группы по 8: 1-3-5-7-9-11-13-15 и 2-4-6-8-10-12-14-16. Выполняется сортировка в каждой восьмерке. Наконец весь файл упорядочивается методом вставок. Поскольку дальние элементы уже переместились на свое место или находятся вблизи от него, этот этап будет значительно менее трудоемким, чем при сортировке вставками без предварительных «дальних» обменов.
Анализ алгоритма сортировки Шелла
Время выполнения сортировки пропорционально n1.2. Эта зависимость значительно лучше квадратичной зависимости n2, которой подчиняется большинство простых алгоритмов сортировки.
Пример кода сортировки Шелла изображен на рисунке 2.
Пример реализации (Язык Cи)
// BaseType - любой перечисляемый тип
// typedef int BaseType - пример
void ShellsSort(BaseType *A, unsigned N)
{
BaseType t;
for(unsigned k = N/2; k > 0; k /= 2)
for(unsigned i = k; i < N; i += 1)
{
t = A[i];
unsigned j;
for(j = i; j >= k; j -= k)
{
if(t < A[j-k])
A[j] = A[j-k];
else
break;
}
A[j] = t;
}
}
Рисунок 2.
Пирамидальная сортировка
Пирамидальная сортировка — алгоритм сортировки, работающий в худшем, в среднем и в лучшем случае (т.е. гарантированно) за О(n log n) операций при сортировке n элементов.
Алгоритм
Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево – это такое двоичное дерево, у которого выполнены условия:
1. Каждый лист имеет глубину либо d либо d-1
2. Значение в любой вершине больше, чем значения ее потомков.
Удобная структура данных для сортирующего дерева – такой массив Array, что Array[1] – элемент в корне, а потомки элемента Array[i] - Array[2i] и Array[2i+1].
Алгоритм сортировки будет состоять из двух основных шагов:
1. Выстраиваем элементы массива в виде сортирующего дерева:
Этот шаг требует О(n) операций.
2. Будем удалять элементы из корня по одному за раз и перестраивать дерево. Т.е. на первом шаге обмениваем Array[1] и Array[n], преобразовываем Array[1], Array[2], ... , Array[n-1] в сортирующее дерево. Затем переставляем Array[1] и Array[n-1], преобразовываем Array[1], Array[2], ... , Array[n-2] в сортирующее дерево. Процесс продолжается до тех пор, пока в сортирующем дереве не останется один элемент. Тогда Array[1], Array[2], ... , Array[n] - упорядоченная последовательность.
Этот шаг требует О(n log n) операций.
Быстрая сортировка
Быстрая сортировка (англ. quicksort) — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром. Даёт в среднем O(n log n) сравнений при сортировке n элементов. В худшем случае, однако, получается O(n2) сравнений. Обычно на практике быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(n log n), по причине того, что внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре, и на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Интересно, что Хоар разработал этот метод применительно к машинному переводу: дело в том, что в то время словарь хранился на магнитной ленте, и если отсортировать все слова в тексте, их переводы можно получить за один прогон ленты.
Алгоритм
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
1. Выбираем в массиве некоторый элемент, который будем называть опорным элементом.
2. Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него.
3. Рекурсивно сортируем подсписки, лежащие слева и справа от опорного элемента.
Базой рекурсии являются списки, состоящие из одного или двух элементов, которые уже отсортированы. Алгоритм всегда завершается, поскольку за каждую итерацию он ставит по крайней мере один элемент на его окончательное место.
Улучшения
При выборе опорного элемента из данного диапазона случайным образом, худший случай становится очень маловероятным и ожидаемое время выполнения алгоритма сортировки - O(n log n).
Тестирование алгоритмов сортировки:
Для начала представляются выбранные для тестирования алгоритмы с кратким описанием их работы, после чего производится непосредственно тестирование, результаты которого заносятся в таблицу и производятся окончательные выводы.
Алгоритмы сортировок очень широко применяются в программировании, но иногда программисты даже не задумываются какой алгоритм работает лучше всех (под понятием «лучше всех» имеется ввиду сочетание быстродействия и сложности как написания, так и выполнения).
В данной статье постараемся это выяснить. Для обеспечения наилучших результатов все представленные алгоритмы будут сортировать целочисленный массив из 200 элементов. Компьютер, на котором будет проводится тестирование имеет следующие характеристики: процессор AMD A6-3400M 4x1.4 GHz, оперативная память 8 GB, операционная система Windows 10 x64 build 10586.36.
Для проведения тестирования будет произведено по 5 запусков каждого алгоритма и выбрано наилучшее время. Наилучшее время и используемая при этом память будут занесены в таблицу. Также будет проведено тестирование скорости сортировки массива размером в 10, 50, 200 и 1000 элементов чтобы определить для каких задач предназначен конкретный алгоритм.
Полностью неотсортированный массив (данные показаны на рисунке 3.):
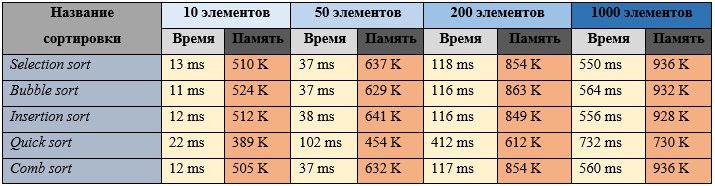
Рисунок 3.
Частично отсортированный массив (половина элементов упорядочена) (данные показаны на рисунке 4) :
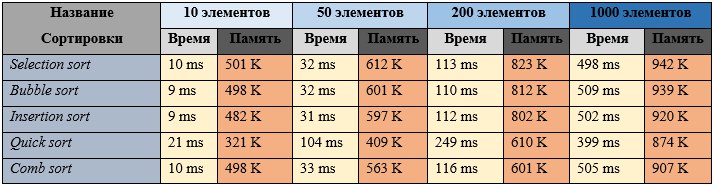
Рисунок 4.
Результаты, предоставленые в графиках (Рисунок 5. Рисунок 6):
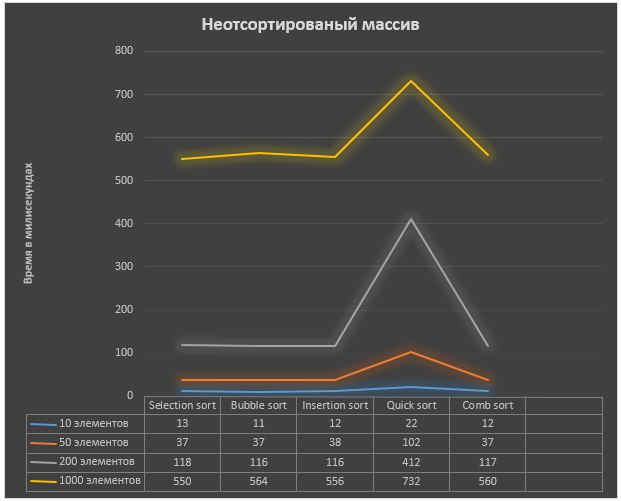
Рисунок 5.
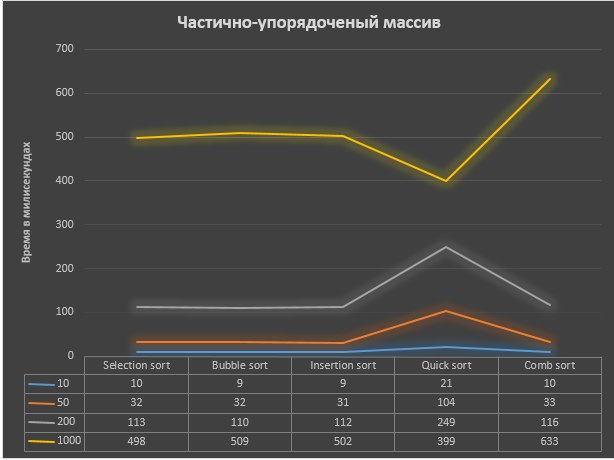
Рисунок 6.
Описание алгоритма выполнения практического задания
Используемое программное обеспечение:
- Visual Studio 2015
Используемый язык программирования:
- C++
Использования данных:
- Полностью неотсортированный массив из 10, 50, 200 и 1000 элементов
- Частично отсортированный массив 10, 50, 200 и 1000 элементов
Алгоритмы сортировок на писанных на C++:
- Selection sort (сортировка выбором)
- Bubble sort (сортировка пузырьком)
- Insertion sort (сортировка вставками)
- Quick sort (быстрая сортировка)
- Comb sort (сортировка расческой)
Алгоритм выполнения:
- Засекаем время начала (программным способом на С++)
- Последовательный запуск программ с разными наборов данных
- Засекаем время конца сортировки (программным способом на С++)
- Собираем данные в табличку
- По Таблице строим графики
- Делаем выводы
Заключение
Универсального алгоритма сортировки не существует
Алгоритмы сортировки сильно зависят от времени и используемой памяти
Сортировка данных это очень важный, трудный и полезный процесс оптимизации программного обеспечения
Даже чемпионат мира по сортировкам показывает что это очень важно и в этом направление работают всемирные гиганты такие как Samsung.
В результате проведенного исследования и полученных данных, для сортировки неотсортированного массива, наиболее оптимальным из представленных алгоритмов для сортировки массива является быстрая сортировка. Несмотря на более длительное время выполнения алгоритм потребляет меньше памяти, что может быть важным в крупных проектах. Однако такие алгоритмы как сортировка выбором, обменом и вставками могут лучше подойти для научных целей, например, в обучении, где не нужно обрабатывать огромное количество данных. При частично отсортированном массиве результаты не сильно отличаются, все алгоритмы сортировки показывают время примерно на 2-3 миллисекунды меньше. Однако при сортировке частично отсортированного массива быстрая сортировка срабатывает намного быстрее и потребляет меньшее количество памяти.
Список использованной литературы
Дональд Кнут. Искусство программирования, том 3. Сортировка и поиск = The Art of Computer Programming, vol.3. Sorting and Searching. — 2-е изд. — М.: «Вильямс», 2007. — С. 824. — ISBN 5-8459-0082-4.
Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. Алгоритмы: построение и анализ = INTRODUCTION TO ALGORITHMS. — 2-е изд. — М.: «Вильямс», 2006. — С. 1296. — ISBN 5-8459-0857-4.
Роберт Седжвик. Фундаментальные алгоритмы на C. Анализ/Структуры данных/Сортировка/Поиск = Algorithms in C. Fundamentals/Data Structures/Sorting/Searching. — СПб.: ДиаСофтЮП, 2003. — С. 672. — ISBN 5-93772-081-4.
Magnus Lie Hetland. Python Algorithms: Mastering Basic Algorithms in the Python Language. — Apress, 2010. — 336 с. — ISBN 978-1-4302-3237-7.
Wikipedia https://ru.wikipedia.org/wiki/Алгоритм_сортировки
https://habrahabr.ru/
http://prog-cpp.ru/algorithm-sort/
https://tproger.ru

- Обзор мировых и отечественных стандартов по управлению проектами
- Теоретические аспекты мотивации в организации
- .Процессы принятия решений в организации.
- Теоретические аспекты формирования основных нормативных документов, регулирующих ведение бухгалтерского учета в организациях
- ОРГАНИЗАЦИЯ РАБОТЫ СЛУЖБЫ ПИТАНИЯ В ГОСТИНИЦЕ
- Использование программ лояльности в сетевых ресторанах
- Графические планшеты (Теоретические основы графических планшетов)
- .Система защиты информации в зарубежных странах.
- Система стилей руководства
- Индивидуальное предпринимательство :
- Деятельность салона красоты «Салон красоты от DOMIX»
- Упрощенная система налогообложения субъектов малого и среднего бизнеса