
Стандарты текстовой информации в ИС (Представление текстовой информации в компьютере)
Содержание:

Представление текстовой информации в компьютере
ЭВМ первых двух поколений могли обрабатывать только числовую информацию, полностью оправдывая свое название вычислительных машин. Лишь переход к третьему поколению принес изменения: к этому времени уже назрела настоятельная необходимость использования текстов.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже пробелы между словами. Пустое место в тексте тоже должно иметь свое обозначение.
Каждый символ хранится в виде двоичного кода, который является номером символа. Можно сказать, что компьютер имеет собственный алфавит, где весь набор символов строго упорядочен. Количество символов в алфавите также тесно связано с двоичным представлением и у всех ЭВМ равняется 256. Иными словами, каждый символ всегда кодируется 8 битами, т.е. занимает ровно один байт.
Хранится не начертание буквы, а ее номер. Именно по этому номеру воспроизводится вид символа на экране дисплея или на бумаге. Поскольку алфавиты в различных типах ЭВМ не полностью совпадают, при переносе с одной модели на другую может произойти превращение разумного текста в "абракадабру". Такой эффект иногда получается даже на одной машине в различных программных средах: например, русский текст, набранный в MS DOS, нельзя без специального преобразования прочитать в Windows.
Наиболее стабильное положение в алфавитах всех ЭВМ занимают латинские буквы, цифры и некоторые специальные знаки. Это связано с существованием международного стандарта ASCII (American Standard Code for Information Interchange - Американский стандартный код для обмена информацией). Русские же буквы не стандартизированы и могут иметь различную кодировку.
Каждый символ текста имеет свой числовой код, но не каждому коду соответствует отображаемый на экране символ. Речь идет о существовании так называемых УПРАВЛЯЮЩИХ КОДОВ, величина которых меньше шестнадцатеричного числа 20 (т.е. 32 в десятичной системе счисления). При получении этих кодов внешние устройства не изображают какого-либо символа, а выполняют те или иные управляющие действия.
|
Таблица Кодировки знаков |
|
|
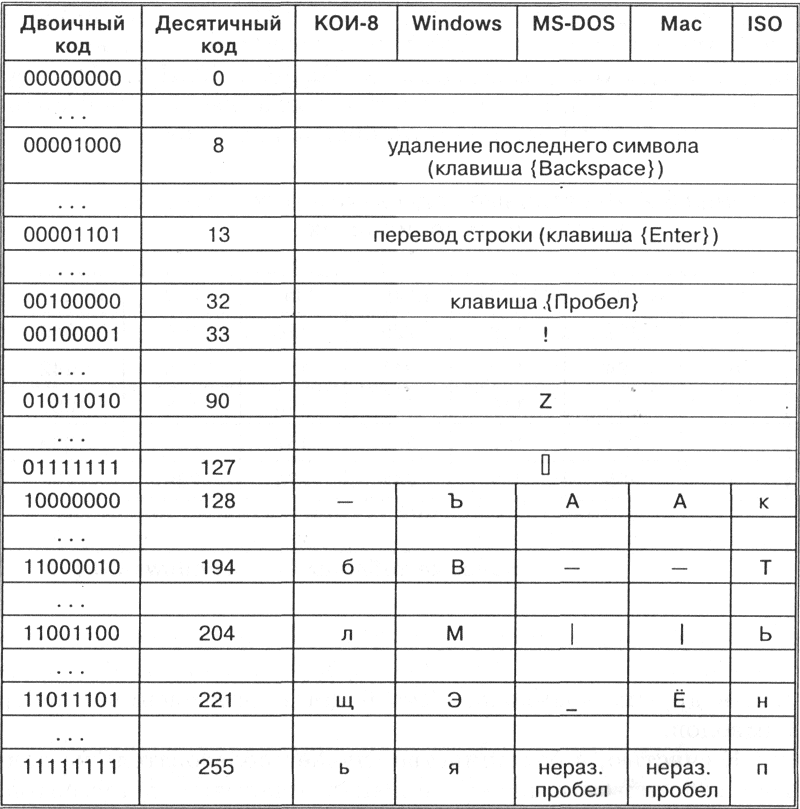
|
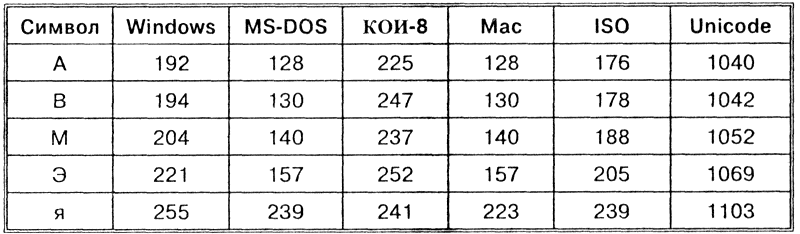
Таблица. Десятичные коды некоторых символов в различных кодировках |
|
|
Структура таблицы кодировки ASCII
|
Порядковый номер |
Код |
Символ |
|
0 - 31 |
00000000 - 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
|
32 - 127 |
0100000 - 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
|
128 - 255 |
10000000 - 11111111 |
Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |

- Категория времени и категория пространства в различных культурах
- Развитие торговли в регионах России
- Особенности использования техник тайм-менеджмента в своей профессиональной деятельности (Теоретические основы тайм - менеджмента)
- Системы автоматизации деловых процессов ( BPM-система)
- Роль ассортиментной политики в торговом деле (политика товарная)
- Достоинства и недостатки сравнительного подхода в оценке бизнеса (Общая характеристика сравнительного подхода)
- Ключевые факторы успеха (АНАЛИЗ КЛЮЧЕВЫХ ФАКТОРОВ УСПЕХА КОМПАНИИ ТОЙОТА)
- Творческое мышление и способы его активизации (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ТВОРЧЕСКОГО МЫШЛЕНИЯ)
- Основные принципы построения эффективной команды
- Опишите механизм воздействия экономических методов регулирования торговли (Механизм государственного регулирования экономики)
- Основные макроэкономические проблемы и их особенности в российской экономике (ОСНОВНЫЕ ПРОБЛЕМЫ МАКРОЭКОНОМИКИ)
- Информационные системы бизнес интеллекта