
Поиск информации с использованием компьютера. Программные поисковые сервисы
Содержание:

Основные сведения
Для поиска интересующей вас информации необходимо указать адрес Web-страницы, на которой она находится. Это самый быстрый и надежный вид поиска. Адреса Web-страниц приводятся в специальных справочниках, печатных изданиях, звучат в эфире популярных радиостанций и с экранов телевизора.
ФУНКЦИИ И ПОНЯТИЕ ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
Каждая поисковая система – это большая база
ключевых слов, связанных с Web
Поисковые системы
Поиско́вая систе́ма (англ. search engine) — алгоритмы и реализующая их совокупность компьютерных программ, предоставляющая пользователю возможность быстрого доступа к необходимой ему информации при помощи поиска в обширной коллекции доступных данных[1]. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации во Всемирной паутине. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Если вы не знаете адреса, то для поиска информации в сети Интернет существуют поисковые системы, которые содержат информацию о ресурсах Интернета.
-страницами, на которых они встретились. Для поиска адреса сервера с интересующей вас информацией надо ввести в поле поисковой системы ключевое слово, несколько слов или фразу. Тем самым вы посылаете поисковой системе запрос. Результаты поиска выдаются в виде списка адресов Web-страниц, на которых встретились эти слова.
Как правило, поисковые системы состоят из трех частей: робота, индекса и программы обработки запроса.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов или вследствие человеческого фактора[⇨]. По состоянию на 2020 год самой популярной поисковой системой в мире и, в частности, России является Google.
По методам поиска и обслуживания разделяют четыре типа поисковых систем: системы, использующие поисковых роботов, системы, управляемые человеком, гибридные системы и мета-системы[⇨]. В архитектуру поисковой системы обычно входят:
поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов;
индексатор, обеспечивающий быстрый поиск по накопленной информации;
поисковик — графический интерфейс для работы пользовател
Основные составляющие поисковой системы: поисковый робот, индексатор, поисковик.
наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц (User expectations[en]). Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работ
Как правило, системы работают поэтапно. Сначала поисковый робот получает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно.
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML-страниц. Поисковый робот (англ. Crawler) — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя.
Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая. Эта ситуация связана с потерей ссылок (англ. linkrot[en]) и дружественным по отношению к пользователю (юзабилити) подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип ает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска.
Когда пользователь вводит запрос в поисковую систему (обычно при помощи ключевых слов), система проверяет свой индекс и выдаёт список наиболее подходящих веб-страниц (отсортированный по какому-либо критерию), обычно с краткой аннотацией, содержащей заголовок документа и иногда части текста. Поисковый индекс строится по специальной методике на основе информации, извлечённой из веб-страниц. С 2007 года поисковик Google позволяет искать с учётом времени создания искомых документов (вызов меню «Инструменты поиска» и указание временно
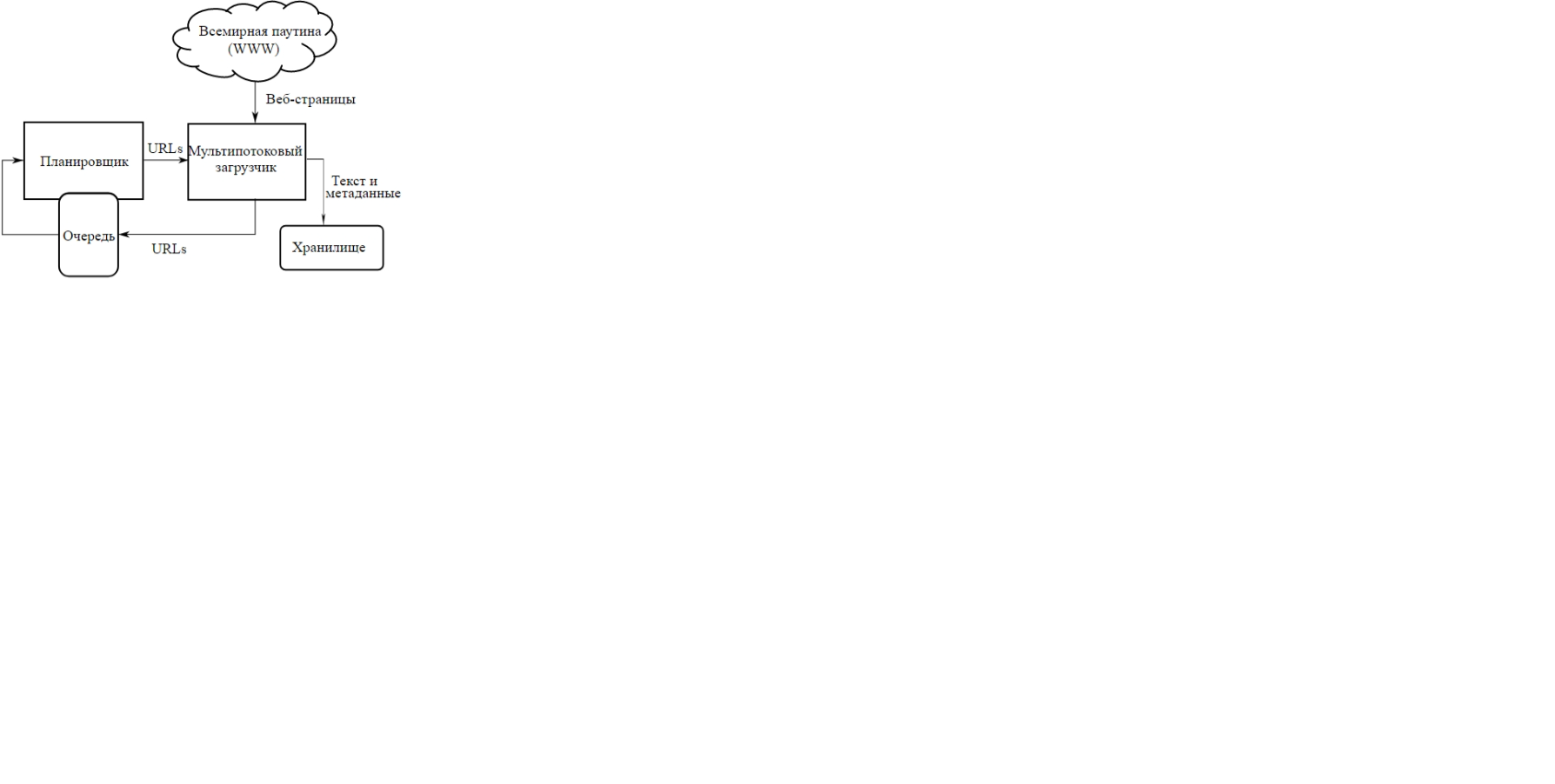
Рисунок1.Высокоуровневая архитектура стандартного краулера
Типы поисковых систем
Существует четыре типа поисковых систем: с поисковыми роботами, управляемые человеком, гибридные и мета-системы.
системы, использующие поисковые роботы. Состоят из трёх частей: краулер («бот», «робот» или «паук»), индекс и программное обеспечение поисковой системы. Краулер нужен для обхода сети и создания списков веб-страниц. Индекс — большой архив копий веб-страниц. Цель программного обеспечения — оценивать результаты поиска. Благодаря тому, что поисковый робот в этом механизме постоянно исследует сеть, информация в большей степени актуальна. Большинство современных поисковых систем являются системами данного типа.
системы, управляемые человеком (каталоги ресурсов). Эти поисковые системы получают списки веб-страниц. Каталог содержит адрес, заголовок и краткое описание сайта. Каталог ресурсов ищет результаты только из описаний страницы, представленных ему веб-мастерами. Достоинство каталогов в том, что все ресурсы проверяются вручную, следовательно, и качество контента будет лучше по сравнению с результатами, полученными системой первого типа автоматически. Но есть и недостаток — обновление данных каталогов выполняется вручную и может существенно отставать от реального положения дел. Ранжирование страниц не может мгновенно меняться. В качестве примеров таких систем можно привести каталог Yahoo[en], dmoz и Galaxy.
гибридные системы. Такие поисковые системы, как Yahoo, Google, MSN, сочетают в себе функции систем, использующие поисковых роботов, и систем, управляемых человеком.
мета-системы. Метапоисковые системы объединяют и ранжируют результаты сразу нескольких поисковиков. Эти поисковые системы были полезны, когда у каждой поисковой системы был уникальный индекс, и поисковые системы были менее «умными». Поскольку сейчас поиск намного улучшился, потребность в них уменьшилась. Примеры: MetaCrawler[en] и MSN Search.
Россия и русскоязычные поисковые системы
Поисковой системой Google пользуются 50,3 % пользователей в России, Яндексом — 47,9 %[23].
Согласно данным LiveInternet в декабре 2017 года об охвате русскоязычных поисковых запросов[24]:
Всеязычные:
Google (42,9 %)
Bing (0,3 %)
Yahoo! (0,0 %) и принадлежащие этой компании поисковые машины: Inktomi[en], AltaVista, Alltheweb[en]
Англоязычные и международные:
AskJeeves[en] (механизм Teoma)
Русскоязычные — большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском, татарском и других. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что, в основном, индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык, или другими способами ограничивают своих роботов русскоязычными сайтами.
Яндекс (60,4 %)
Mail.ru (3,5 %)
|
Поисковая система |
Доля рынка в июле 2014 |
Доля рынка в октябре 2014 |
Доля рынка в сентябре 2017 |
Доля рынка в сентябре 2020[20] |
|
Excite |
0,22 % |
0,00 % |
0,00 % |
|
|
Ask |
0,13 % |
0,10 % |
0,24 % |
|
|
AOL |
0,13 % |
0,21 % |
1,11 % |
|
|
Yahoo! |
6,74 % |
4,01 % |
5,19 % |
1,52 % |
|
Baidu |
6,22 % |
8,01 % |
6,48 % |
1,14 % |
|
Bing |
17,17 % |
29,06 % |
12,26 % |
2,88 % |
|
|
68,69 % |
58,01 % |
69,24 % |
92,16 |
Рисунок 2. Количественные данные поисковой системы
Число пользователей Интернета и поисковых систем и требований пользователей к этим системам постоянно растёт. Для увеличений скорости поиска нужной информации крупные поисковые системы содержат большое количество серверов. Сервера обычно группируют в серверные центры (дата-центры). У популярных поисковых систем серверные центры разбросаны по всему миру.
В октябре 2012 года Google запустила проект «Где живёт Интернет», где пользователям предоставляется возможность познакомиться с центрами обработки данных этой компании[25].
Суммарная мощность всех дата-центров Google, по состоянию на 2011 год, оценивалась в 220 МВт.
Когда в 2008 году Google планировала открыть в Орегоне новый комплекс, состоящий из трёх зданий общей площадью 6,5 млн м², в журнале Harper’s Magazine подсчитали, что такой большой комплекс потребляет свыше 100 МВт электроэнергии, что сравнимо с потреблением энергии города с населением 300 000 человек.
Ориентировочное число серверов Google в 2012 году — 1 млн.
Расходы Google на дата-центры составили в 2006 году — 1,9 млрд $, а в 2007 году — 2,4 млрд $.
Размер всемирной паутины, проиндексированной Google на декабрь 2014 года, составляет примерно 4,36 миллиарда страниц[27].
Поисковые системы, учитывающие религиозные запреты
Глобальное распространение Интернета и увеличение популярности электронных устройств в арабском и мусульманском мире, в частности, в странах Ближнего Востока и Индийского субконтинента, способствовало развитию локальных поисковых систем, учитывающих исламские традиции. Такие поисковые системы содержат специальные фильтры, которые помогают пользователям не попадать на запрещённые сайты, например, сайты с порнографией, и позволяют им пользоваться только теми сайтами, содержимое которых не противоречит исламской вере.
Незадолго до мусульманского месяца Рамадан, в июле 2013 года, миру был представлен Halalgoogling[en] — система, выдающая пользователям только халяльные «правильные» ссылки[28], фильтруя результаты поиска, полученные от других поисковых систем, таких как Google и Bing. Двумя годами ранее, в сентябре 2011 года, был запущен поисковый движок I’mHalal, предназначенный для обслуживания пользователей Ближнего Востока. Однако этот поисковый сервис пришлось вскоре закрыть, по сообщению владельца, из-за отсутствия финансирования[29].
Отсутствие инвестиций и медленный темп распространения технологий в мусульманском мире препятствовали прогрессу и мешали успеху серьёзного исламского поисковика. Очевиден провал огромных инвестиций в веб-проекты мусульманского образа жизни, одним из которых был Muxlim[en]. Он получил миллионы долларов от инвесторов, таких как Rite Internet Ventures, и теперь — в соответствии с последним сообщением от I’mHalal перед его закрытием — выступает с сомнительной идеей о том, что «следующий Facebook или Google могут появиться только в странах Ближнего Востока, если вы поддержите нашу блестящую молодёжь»[источник не указан 58 дней].
Тем не менее исламские эксперты в области Интернета в течение многих лет занимаются определением того, что соответствует или не соответствует шариату, и классифицируют веб-сайты как «халяль» или «харам». Все бывшие и настоящие исламские поисковые системы представляют собой просто специальным образом проиндексированный набор данных либо это главные поисковые системы, такие как Google, Yahoo и Bing, с определённой системой фильтрации, использующейся для того, чтобы пользователи не могли получить доступ к харам-сайтам, таким как сайты о наготе, ЛГБТ, азартных играх и каким-либо другим, тематика которых считается антиисламской[источник не указан 58 дней].
Среди других религиозно-ориентированных поисковых систем распространёнными являются Jewogle — еврейская версия Google и SeekFind.org — христианский сайт, включающий в себя фильтры, оберегающие пользователей от контента, который может подорвать или ослабить их веру[30].
Содержание
1 История
1.1 Поиск информации на русском языке
2 Как работает поисковая система
3 Типы поисковых систем
4 Рынок поисковых систем
4.1 Азия
4.2 Россия и русскоязычные поисковые системы
4.3 Количественные данные поисковой системы Google
5 Поисковые системы, учитывающие религиозные запреты
6 Персональные результаты и пузыри фильтров
7 Предвзятость поисковых систем
го диапазона).
МОСКВА 2020 г.

- ТЕХНОЛОГИИ ЭЛЕКТРОННОГО ДОКУМЕНТООБОРОТА
- Микроклимат в жилых помещениях, его влияние на организм человека
- Понятие амортизации и её роль в воспроизводственном процессе
- Правовые акты управления: понятие, функции и формы
- Субъекты административного права (Право)
- Недобросовестная конкуренция и ее виды
- Электронный документ
- Принципы создания холдинговых объединений
- Применение редактора Corel в дизайне и рекламе
- Использование информационных технологий в деятельности федеральных органов государственной власти
- Страховые случаи и их разрешение
- Modern multimedia technologies