
Гипертекстовые и мультимедийные информационные технологии (Стандарты кодирования символов)
Содержание:

Введение
В наше время существует несколько широко используемых таблиц кодирования, одной из них является Unicode, в которой на данный момент более 140 000 символов и формат PDF, при помощи которого можно передавать разные документы на разные устройства, из-за его повсеместного использования. Но стоит и посмотреть на предыдущие кодировки, от которых пошло развитие этой сферы.
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти 32 символа входили только управляющие символы и строчные буквы английского алфавита. С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой 7-мибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение 256 символов: 128 основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов. Но для многих языков (например, арабского, японского, китайского) 256 символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Поэтому цель данного реферата, рассмотреть разные стандарты кодировок, их развитие и разные ответвления.
Стандарты кодирования символов
Кодировка ASCII и ее вариации.
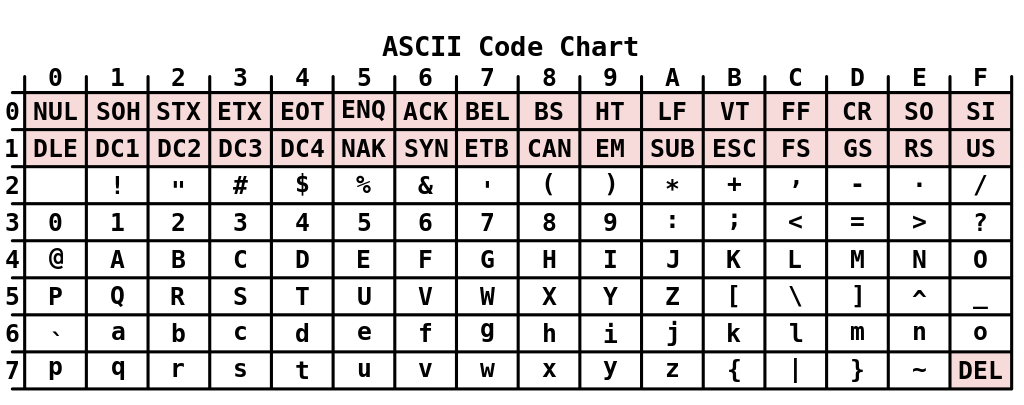
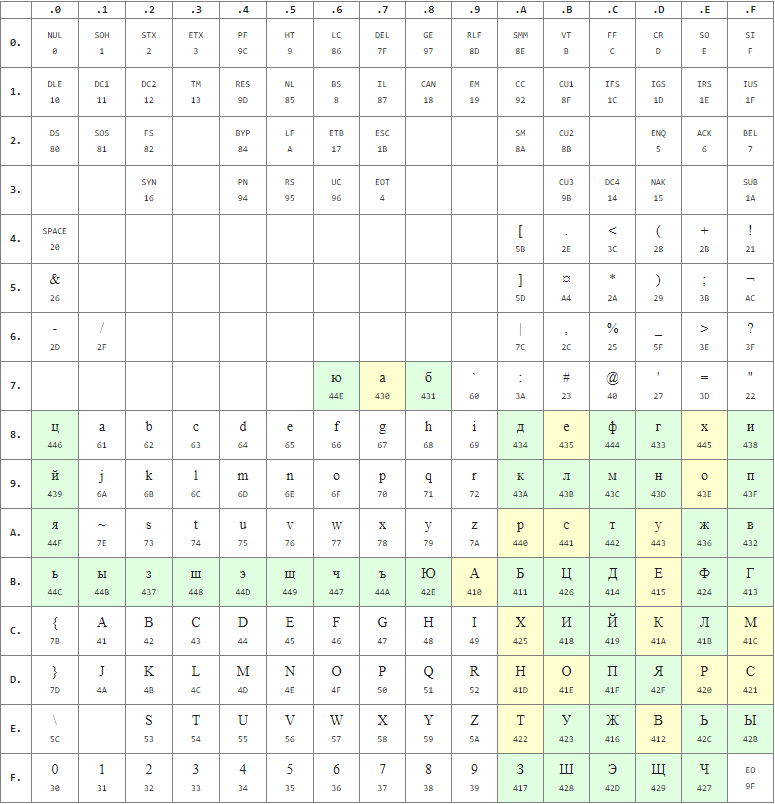
Стандарт ASCII (англ. American Standard Code for Information Interchange) (см. пр.1) появился в 1963 году и был разработан для кодирования символов, коды которых помещались в 7 бит, при этом старший 7 бит использовался для контроля ошибок, возникших при передаче данных. Изначально кодировались только заглавные буквы, полосы (группы по 16 символов) №6 и №7 были зарезервированы для дальнейшего расширения. Также велись споры как использовать эту область для строчных букв или управляющих символов.
Позже появился стандарт ISO 646 (ECMA-6), который предусматривал возможность размещения в ASCII национальных символов. Для этого предлагается заменять символы «@», «[», «\», «]», «^», «`», «{», «|», «}», «~». Также на месте знака решётки «#» может быть размещён символ фунта «£», а на месте символа доллара «$» — знак национальной валюты. Такая система хорошо подходила для европейских языков, так как в них используются символы латинского алфавита и лишь несколько дополнительных символов. Вариант ASCII, не содержащий национальных символов, называется «US-ASCII» или «international reference version».
Для некоторых языков (с нелатинской письменностью: русский, греческий, арабский, иврит и др.) существовали более радикальные модификации ASCII. В одной из таких модификаций — на месте строчных латинских букв размещались национальные символы (для русского и греческого — заглавные буквы). В другой модификации — предусматривалось переключение между US-ASCII и национальным вариантом; переключение осуществлялось «на лету»: с помощью символов «SO» (англ. shift out) и «SI» (англ. shift in); в этом случае — в национальном варианте можно было полностью заменить латинские буквы на национальные символы (например, КОИ-7).
Со временем кодировка была расширена до 256 символов, коды первых 128 символов не изменились. ASCII стала восприниматься как половина 8-битной кодировки, а «расширенной ASCII» называли ASCII с задействованным 8-м битом (например, КОИ-8).
Кодировки КОИ-7 и КОИ-8.
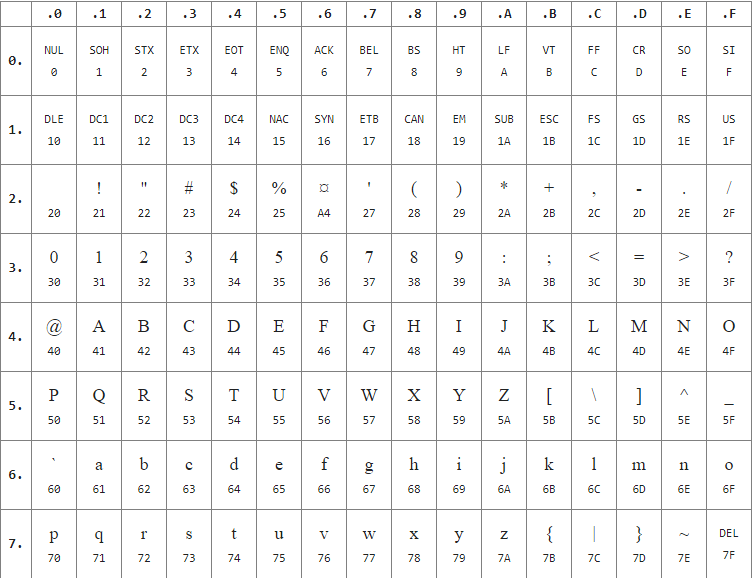
КОИ-7 (руск. Код Обмена Информацией, 7 бит) — 7-битная кодировка для русского языка и обмена информацией, основанная на ASCII. КОИ-7 описана в ГОСТ 13052-67, 13052-74 и 27463-87. КОИ-7 включает в себя 3 «набора» — Н0, Н1, Н2.
Н0 — это просто US-ASCII, однако символ доллара $ заменён на символ национальной валюты (см. пр.2); в Н1 все латинские буквы заменены на русские (см. пр.3); в Н2 заглавные латинские буквы оставлены, а строчные заменены на заглавные русские (см. пр.4).
На практике использовался либо набор КОИ-7 Н2 сам по себе, либо КОИ-7 Н0/Н1 с переключением: для перехода в русский режим (КОИ-7 Н1) использовался управляющий символ 0xE (SO, РУС), а для возврата в латинский (КОИ-7 Н0) — символ 0xF (SI, ЛАТ). Иногда смена набора, используемого устройством, осуществлялась ручным переключателем.
Чтобы избежать проблем с DELETE (0x7F) отсутствовала заглавная буква «Ъ», также не было буквы «Ё». Но так как русские буквы были размещены на позициях аналогичных латинским, текст оставался более-менее читаемым даже при неправильно выбранном режиме.
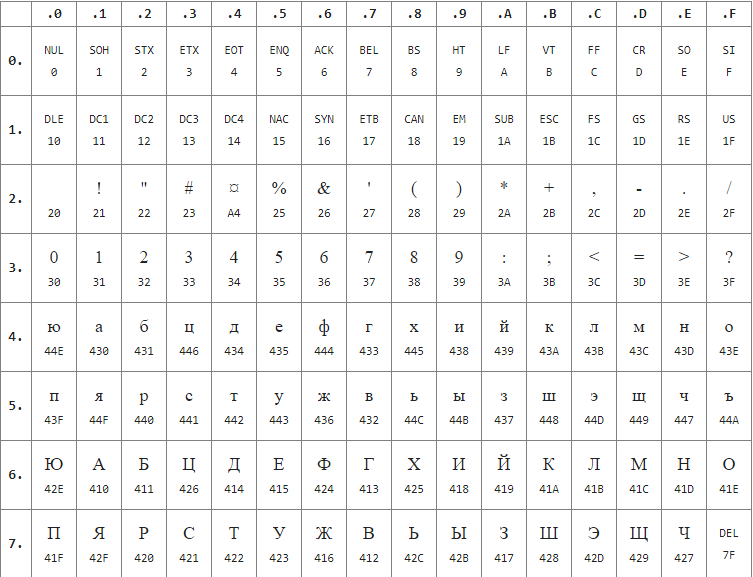
После расширения кодировки ASCII до 8 бит, на свет появился КОИ-8, которая была совместима с ASCII. Разработанная для кодирования букв кириллического алфавита, была распространена как основная русская кодировка в Unix-совместимых операционных системах и в электронной почте, но уже ближе к 2010 году, с распространением Unicode, постепенно стала выходить из использования.
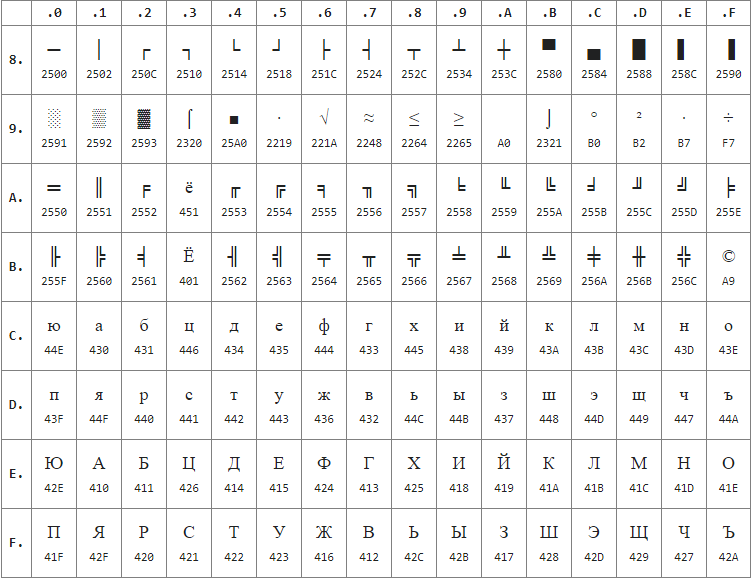
Так в нижней части располагались буквы латинского алфавита, а в верхней части кодовой таблицы КОИ-8 (см. пр.5) находились символы русского алфавита, не в алфавитном порядке, для того чтобы символы кириллицы соответствовали их фонетическим аналогам на латинском языке. Это было сделано для того, чтобы получить относительно читаемый текст, если от каждого символа убрать один бит слева (например, «Русский Текст» - «rUSSKIJ tEKST»).
Существует несколько вариантов кодировки КОИ-8 для разных кириллических алфавитов, расширяющие определённые коды. Так существует русский алфавит – KOI8-R, украинский – KOI8-U, таджикский - KOI8-T, центрально азиатская - KOI8-C, славянская и старая орфография - KOI8-O и KOI8-S.
Кодировки EBCDIC и ДКОИ-8
EBCDIC (англ. Extended Binary Coded Decimal Interchange Code — руск. расширенный двоично-десятичный код обмена информацией)— стандартный восьмибитный код, разработанный корпорацией IBM для использования на мэйнфреймах[1] собственного производства и совместимых с ними. EBCDIC кодирует буквы латинского алфавита, арабские цифры, некоторые знаки пунктуации и управляющие символы. Существовало по меньшей мере шесть версий EBCDIC, несовместимых между собой.
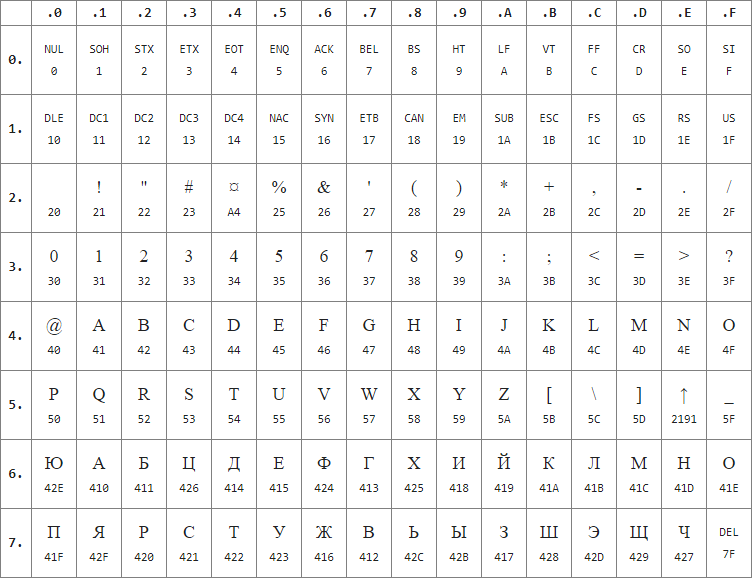
Также Госстандартом СССР был стандартизован в ГОСТ 19768-74, 8-битная кодовая страница ДКОИ-8 (руск. Двоичный Код Обработки Информации, 8 бит), которая использовалась на компьютерах серии ЕС ЭВМ, являющихся аналогом компьютеров IBM с EBDCIC.
Стандарт устанавливает две версии кодировки — К1 и К2. Во-втором варианте русские буквы, совпадающие по начертанию с латинскими (А, В, Е, К, М, Н, О, Р, С, Т, Х, а, е, о, р, с, у, х), не используются — вместо них латинские с тем же начертанием (см. пр.6). Также изначально в обоих вариантах отсутствовали буква Ёё и заглавный «твёрдый знак» Ъ. Позднее добавлены в ГОСТ 19768-93 в варианте К1.
Кодировка Unicode и его способы представления UTF-8, UTF-16 и UTF-32.
Стандарт Unicode был предложен в 1991 некоммерческой организацией «Unicord Consortium, Unicode inc.». Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет способы преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042). В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти. Punycode — другая форма кодирования последовательностей Unicode-символов в так называемые ACE-последовательности, которые состоят только из алфавитно-цифровых символов, как это разрешено в доменных именах.
UTF-8 — представление Юникода, обеспечивающее наибольшую компактность и обратную совместимость с 7-битной системой ASCII; текст, состоящий только из символов с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII и может быть отображён любой программой, работающей с ASCII; и наоборот, текст, закодированный 7-битной ASCII может быть отображён программой, предназначенной для работы с UTF-8. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байт, в которых первый байт всегда имеет маску 11xxxxxx, а остальные — 10xxxxxx. В UTF-8 не используются суррогатные пары. Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в ОС Plan 9. Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
UTF-16 — кодировка, позволяющая записывать символы Юникода в диапазонах U+0000...U+D7FF и U+E000...U+10FFFF (общим количеством 1 112 064). При этом каждый символ записывается одним или двумя словами (суррогатная пара). Кодировка UTF-16 описана в приложении Q к международному стандарту ISO/IEC 10646, а также ей посвящён документ IETF RFC 2781 под названием «UTF-16, an encoding of ISO 10646».
UTF-32 — способ представления Юникода, при котором каждый символ занимает ровно 4 байта. Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод в ней непосредственно индексируемы, поэтому найти символ по номеру его позиции в файле можно чрезвычайно быстро, и получение любого символа n-й позиции при этом является операцией, занимающей всегда одинаковое время. Это также делает замену символов в строках UTF-32 очень простой. Напротив, кодировки с переменной длиной требуют последовательного доступа к символу n-й позиции, что может быть очень затратной по времени операцией. Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения любого символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства, редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства, зачастую не оправдано.
На данный момент стандарт развивает и на момент последнего обновления (март 2020 года версия 13.0) всего было добавлено 154 письменности и 143 859 символов. А в последней версии добавлено хорезмийское письмо, письмо дивес акуру, малое киданьское письмо, езидское письмо, 4969 идеограмм ККЯ (включая 4939 Унифицированные идеограммы ККЯ — расширение G), а также 55 эмодзи, символы Creative Commons и символы для унаследованной вычислительной техники.
Формат PDF и RTF
Portable Document Format (PDF) — межплатформенный открытый формат электронных документов, изначально разработанный фирмой Adobe Systems с использованием ряда возможностей языка PostScript. В первую очередь предназначен для представления полиграфической продукции в электронном виде. Для просмотра существует множество программ, а также официальная бесплатная программа Adobe Reader. Значительное количество современного профессионального печатного оборудования имеет аппаратную поддержку формата PDF, что позволяет производить печать документов в данном формате без использования какого-либо программного обеспечения. Традиционным способом создания PDF-документов является виртуальный принтер, то есть документ как таковой готовится в своей специализированной программе — графической программе или текстовом редакторе, САПР и т. д., а затем экспортируется в формат PDF для распространения в электронном виде, передачи в типографию и т. п.
PDF с 1 июля 2008 года является открытым стандартом ISO 32000. Формат PDF позволяет внедрять необходимые шрифты (построчный текст), векторные и растровые изображения, формы и мультимедиа-вставки. Поддерживает RGB, CMYK, Grayscale, Lab, Duotone, Bitmap, несколько типов сжатия растровой информации. Имеет собственные технические форматы для полиграфии: PDF/X-1a, PDF/X-3. Включает механизм электронных подписей для защиты и проверки подлинности документов. В этом формате распространяется большое количество сопутствующей документации.
Rich Text Format, RTF (англ. rich — богатый; «формат обогащённого текста») — проприетарный межплатформенный формат хранения текстовых документов с форматированием, предложенный группами программистов, основавшими компании Microsoft и Adobe, как мета-теговый формат для редактора Word в 1982 году. С тех пор спецификация формата несколько раз изменялась. После разрыва отношений с Microsoft компания Adobe продолжила самостоятельное развитие метатэгового языка, заложенного в основу RTF, создав в 1985 году язык PostScript.
Заключение
Сейчас Unicode является самой развитой и самой распространённой таблицей кодировки в мире, она сделала бесполезными кодировки по типу КОИ-8 и других национальных аналогов ASCII, так как большинство переходят на Юникод из-за его удобств. А такие форматы как PDF облегчает жизнь многим людям, ведь формат является мультиплатформенным и открывается чуть ли не в каждом браузере.
Считаю, что данная тема больше подходит для ознакомления с историей развития таблиц кодировок, их видами и форматами. Так как в настоящий момент создание какой-то новой кодировки не принесёт никакой пользы для развития этой сферы, и только развитие уже имеющихся является более оптимальным вариантом.
Список литературы
- https://ru.wikipedia.org/wiki/ASCII
- https://ru.wikipedia.org/wiki/EBCDIC
- https://ru.wikipedia.org/wiki/ДКОИ
- https://ru.wikipedia.org/wiki/КОИ-7
- https://ru.wikipedia.org/wiki/КОИ-8
- https://ru.wikipedia.org/wiki/Юникод
- https://ru.wikipedia.org/wiki/Portable_Document_Format
- https://ru.wikipedia.org/wiki/Rich_Text_Format
Приложения.
-
Мейнфре́йм (также мэйнфрейм, от англ. mainframe) — большой универсальный высокопроизводительный отказоустойчивый сервер со значительными ресурсами ввода-вывода, большим объёмом оперативной и внешней памяти, предназначенный для использования в критически важных системах (англ. mission-critical) с интенсивной пакетной и оперативной транзакционной обработкой. (материал Wikipedia) ↑

- Main objectives of the business meeting organization
- Концепции современного естествознания (наука как высшая форма знания, теоретического и эмпирического знания)
- Как настроиться на рабочий лад. Обзор эффективных техник самомотивации (Самомотивация и эффективные техники самомотивации)
- Беспроводной Интернет: особенности его функционирования.
- Гарантии конституционных прав и свобод в Российской Федерации
- Принцип разделения властей и его реализация в Российской Федерации
- Реформы Петра 1 и их роль в развитии физической культуры и спорта
- Ernest Hemingway
- Предмет микро- и макроэкономики, их взаимосвязь (по дисциплине “МАКРОЭКОНОМИКИ ”)
- Роль воображения в творческой деятельности (Воображение, его виды, функции и формы)
- Механизмы обеспечения безопасности радиолиний
- Игровая и виртуальная графика.