
ТЕХНОЛОГИЯ «КЛИЕНТ–СЕРВЕР» (Технология «клиент–сервер»)
Содержание:

ВВЕДЕНИЕ
В последние годы развития информационных и аппаратных технологий можно говорить об увеличенном внимании и частых попытках совершенствования приложений клиент–сервер. На сегодняшний день уже реализованы такие приложения, которые обеспечивают поддержку совместной работы нескольких пользователей, при этом источник данных в сети остается один.
Распространение технологии «клиент–сервер» стало повсеместным при начале общения пользователя с компьютером или с системой, также основанной на работе компьютера. Примерами ежедневного применения технологии «клиент–сервер» являются такие повсеместные действия, о которых мы даже не задумываемся, как телефонная связь или совершение покупок. Применяя автоматический кассовый аппарат, осуществляя считывание штрих–кода с товара, расплачиваясь за совершенную покупку,– мы взаимодействуем с системой компьютера «клиент–сервер».
Технология «клиент–сервер» представляет собой архитектуру взаимодействия, при которой одна программа отправляет запрос на выполнение определенного перечня действий, а другая программа реализует непосредственно выполнение этого перечня. Участниками подобного взаимодействия являются клиент и сервер. Зачастую в качестве клиента или сервера выступает компьютер, который обеспечивает функционирование того или иного программного обеспечения.
Для того чтобы подробнее разобраться в приведенной архитектуре, была определена цель выполнения работы – изучение технологии «клиент–сервер».
Объектом исследования будет выступать архитектура информационной системы. Предметом – сама технология «клиент–сервер».
Для достижения поставленной цели необходимо выполнить следующие задачи:
- рассмотреть основные характеристики архитектуры информационных систем;
- кратко охарактеризовать виды архитектуры информационных систем;
- описать архитектуру «клиент-сервер»;
- проанализировать программное обеспечение технологии «клиент–сервер».
В структуру работы включены такие элементы, как Введение, Заключение и Список литературы. Кроме того, работа содержит две главы, каждая из которых состоит из двух параграфов.
Основной теоретической и методологической базой исследования выступают работы современных авторов, рассматривающих архитектуру информационных систем, и в частности – технологию «клиент-сервер». В числе таких авторов – Ипатова Э. Р., Мельников В., Ярочкин В. и др.
Архитектура информационной системы
Основные характеристики архитектуры информационных систем
В рамках настоящего исследования, в первую очередь, целесообразно определить, что представляет собой информационная система. Под информационной системой будем понимать взаимосвязанную совокупность средств, методов и персонала, которые применяются для хранения, обработки и выдачи данных с определенной целью [1].
Современные информационные системы достаточно сложны и многообразны, и значительно варьируются в классификации согласно определенным признакам. Одним из таких признаков является архитектура, которая может быть разного уровня сложности. Справедливо будет отметить, что сегодня грамотно сконструированная, эффективная и оперативная информационная система является не менее ценным интеллектуальным продуктом, чем проект целого здания.
Рассмотрим определение «архитектуры информационной системы», которое дают различные источники:
Архитектура – это организационная структура системы [3].
Архитектура информационной системы – концепция, определяющая модель, структуру, выполняемые функции и взаимосвязь компонентов информационной системы [4].
Архитектура – это базовая организация системы, воплощенная в ее компонентах, их отношениях между собой и с окружением, а также принципы, определяющие проектирование и развитие системы [11].
Архитектура – это набор значимых решений по поводу организации системы программного обеспечения, набор структурных элементов и их интерфейсов, при помощи которых компонуется система, вместе с их поведением, определяемым во взаимодействии между этими элементами, компоновка элементов в постепенно укрупняющиеся подсистемы, а также стиль архитектуры, который направляет эту организацию – элементы и их интерфейсы, взаимодействия и компоновку [6].
Архитектура программы или компьютерной системы – это структура или структуры системы, которые включают элементы программы, видимые извне свойства этих элементов и связи между ними [9].
Архитектура – это структура организации и связанное с ней поведение системы [18]. Архитектуру можно рекурсивно разобрать на части, взаимодействующие посредством интерфейсов, связи, которые соединяют части, и условия сборки частей. Части, которые взаимодействуют через интерфейсы, включают классы, компоненты и подсистемы.
Архитектура программного обеспечения системы или набора систем состоит из всех важных проектных решений по поводу структур программы и взаимодействий между этими структурами, которые составляют системы [9]. Проектные решения обеспечивают желаемый набор свойств, которые должна поддерживать система, чтобы быть успешной. Проектные решения предоставляют концептуальную основу для разработки системы, ее поддержки и обслуживания.
Несмотря на то, что большинство определений отличаются, основная суть остается сходной. Так, большая часть приведенных трактовок указывает на связь архитектуры со структурой и поведением всей системы, а также ее соответствие определенному архитектурному стилю. Кроме того, обобщая определения, можно сказать, что архитектура информационной системы находится под влиянием заинтересованных лиц и окружения, и она всегда воплощает в себе решения, основанные на логических выводах.
Под архитектурой программных систем будем понимать совокупность решений относительно [1, 10]:
- организации программной системы;
- выбора структурных элементов, составляющих систему и их интерфейсов;
- поведения этих элементов во взаимодействии с другими элементами;
- объединение этих элементов в подсистемы;
- архитектурного стиля, определяющего логическую и физическую организацию системы: статические и динамические элементы, их интерфейсы и способы их объединения.
Архитектура программной системы охватывает не только ее структурные и поведенческие аспекты, но и правила ее использования и интеграции с другими системами, функциональность, производительность, гибкость, надежность, возможность повторного применения, полноту, экономические и технологические ограничения, а также вопрос пользовательского интерфейса.
По мере развития программных систем все большее значение приобретает их интеграция друг с другом с целью построения единого информационного пространства предприятия. Как можно видеть из вышеприведенных определений интеграция является важнейшим элементом архитектуры.
Для того чтобы построить правильную и надежную архитектуру и грамотно спроектировать интеграцию программных систем необходимо четко следовать современным стандартам в этих областях. Без этого велика вероятность создать архитектуру, которая неспособна развиваться и удовлетворять растущим потребностям пользователей ИТ. В качестве законодателей стандартов в этой области выступают такие международные организации как SEI (Software Engineering Institute), WWW (консорциум World Wide Web), OMG (Object Management Group), организация разработчиков Java – JCP (Java Community Process), IEEE (Institute of Electrical and Electronics Engineers) и другие [15].
Виды архитектуры информационных систем
Рассмотрим классификацию программных систем по их архитектуре:
- Централизованная архитектура;
- Архитектура «файл–сервер»;
- Двухзвенная архитектура «клиент–сервер»;
- Многозвенная архитектура «клиент–сервер»;
- Архитектура распределенных систем;
- Архитектура Веб–приложений;
- Сервис–ориентированная архитектура [1].
Следует заметить, что, как и любая классификация, данная классификация архитектур информационных систем не является абсолютно жесткой. В архитектуре любой конкретной информационной системы часто можно найти влияния нескольких общих архитектурных решений.
Далее подробно рассмотрим особенности наиболее распространенных видов архитектуры.
Централизованная архитектура вычислительных систем была распространена в 70–х и 80–х годах и реализовывалась на базе мейнфреймов (например, IBM–360/370 или их отечественных аналогов серии ЕС ЭВМ), либо на базе мини–ЭВМ (например, PDP–11 или их отечественного аналога СМ–4) [11]. Характерная особенность такой архитектуры – полная «неинтеллектуальность» терминалов. Их работой управляет хост–ЭВМ.
Достоинства такой архитектуры [11, 12]:
- пользователи совместно используют дорогие ресурсы ЭВМ и дорогие периферийные устройства;
- централизация ресурсов и оборудования облегчает обслуживание и эксплуатацию вычислительной системы;
- отсутствует необходимость администрирования рабочих мест пользователей.
Главным недостатком для пользователя является то, что он полностью зависит от администратора хост–ЭВМ. Пользователь не может настроить рабочую среду под свои потребности – все используемое программное обеспечение является коллективным.
Использование такой архитектуры является оправданным, если хост–ЭВМ очень дорогая, например, супер–ЭВМ.
Классическое представление централизованной архитектуры показано на рис. 1 [3].
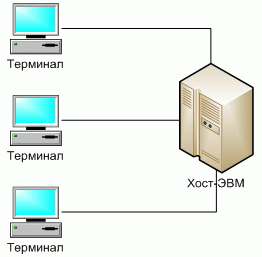
Рис. 1. Классическое представление централизованной архитектуры
Центральная ЭВМ должна иметь большую память и высокую производительность, чтобы обеспечивать комфортную работу большого числа пользователей.
Все приложения, работающие в такой архитектуре, полностью находятся в основной памяти хост–ЭВМ. Терминалы являются лишь устройствами ввода–вывода и таким образом в минимальной степени поддерживают интерфейс пользователя.
Файл–серверные приложения – приложения, схожие по своей структуре с локальными приложениями и использующие сетевой ресурс для хранения программы и данных [13].
Функции сервера: хранения данных и кода программы.
Функции клиента: обработка данных происходит исключительно на стороне клиента.
Классическое представление информационной системы в архитектуре «файл–сервер» представлено на рис. 2 [3].
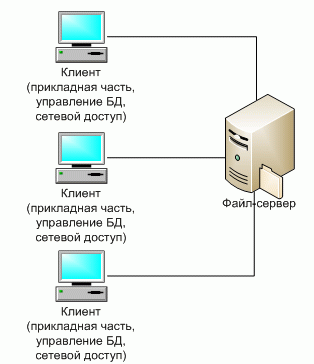
Рис. 2. Классическое представление архитектуры «файл–сервер»
Организация информационных систем на основе использования выделенных файл–серверов все еще является распространенной в связи с наличием большого количества персональных компьютеров разного уровня развитости и сравнительной дешевизны связывания PC в локальные сети [14].
Конечно, основным достоинством данной архитектуры является простота организации. Проектировщики и разработчики информационной системы находятся в привычных и комфортных условиях IBM PC в среде MS–DOS, Windows или какого–либо облегченного варианта Windows Server. Имеются удобные и развитые средства разработки графического пользовательского интерфейса, простые в использовании средства разработки систем баз данных и/или СУБД.
Достоинства такой архитектуры [12, 13, 14]:
- многопользовательский режим работы с данными;
- удобство централизованного управления доступом;
- низкая стоимость разработки;
- высокая скорость разработки;
- невысокая стоимость обновления и изменения ПО.
Недостатки [12, 13, 14]:
- проблемы многопользовательской работы с данными: последовательный доступ, отсутствие гарантии целостности;
- низкая производительность (зависит от производительности сети, сервера, клиента);
- плохая возможность подключения новых клиентов;
- ненадежность системы.
Простое, работающее с небольшими объемами информации и рассчитанное на применение в однопользовательском режиме, файл–серверное приложение можно спроектировать, разработать и отладить очень быстро [14]. Очень часто для небольшой компании для ведения, например, кадрового учета достаточно иметь изолированную систему, работающую на отдельно стоящем PC. Однако, в уже ненамного более сложных случаях (например, при организации информационной системы поддержки проекта, выполняемого группой) файл–серверные архитектуры становятся недостаточными.
Клиент–сервер (Client–server) – вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг (сервисов), называемых серверами, и заказчиками услуг, называемых клиентами [15]. Нередко клиенты и серверы взаимодействуют через компьютерную сеть и могут быть как различными физическими устройствами, так и программным обеспечением.
Первоначально системы такого уровня базировались на классической двухуровневой клиент–серверной архитектуре (Two–tier architecture). Под клиент–серверным приложением в этом случае понимается информационная система, основанная на использовании серверов баз данных.
Схематически такую архитектуру можно представить, как показано на рис. 3 [3].
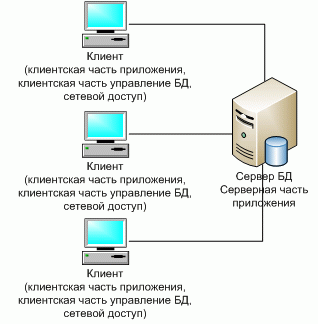
Рис.3. Классическое представление архитектуры «клиент–сервер»
На стороне клиента выполняется код приложения, в который обязательно входят компоненты, поддерживающие интерфейс с конечным пользователем, производящие отчеты, выполняющие другие специфичные для приложения функции.
Клиентская часть приложения взаимодействует с клиентской частью программного обеспечения управления базами данных, которая, фактически, является индивидуальным представителем СУБД для приложения.
Заметим, что интерфейс между клиентской частью приложения и клиентской частью сервера баз данных, как правило, основан на использовании языка SQL. Поэтому такие функции, как, например, предварительная обработка форм, предназначенных для запросов к базе данных, или формирование результирующих отчетов выполняются в коде приложения.
Наконец, клиентская часть сервера баз данных, используя средства сетевого доступа, обращается к серверу баз данных, передавая ему текст оператора языка SQL.
Посмотрим теперь, что же происходит на стороне сервера баз данных. В продуктах практически всех компаний сервер получает от клиента текст оператора на языке SQL.
Сервер производит компиляцию полученного оператора.
Далее (если компиляция завершилась успешно) происходит выполнение оператора.
Разработчики и пользователи информационных систем, основанных на архитектуре «клиент–сервер», часто бывают неудовлетворены постоянно существующими сетевыми накладными расходами, которые следуют из потребности обращаться от клиента к серверу с каждым очередным запросом. На практике распространена ситуация, когда для эффективной работы отдельной клиентской составляющей информационной системы в действительности требуется только небольшая часть общей базы данных. Это приводит к идее поддержки локального кэша общей базы данных на стороне каждого клиента [11].
Фактически, концепция локального кэширования базы данных является частным случаем концепции реплицированных баз данных. Как и в общем случае, для поддержки локального кэша базы данных программное обеспечение рабочих станций должно содержать компонент управления базами данных – упрощенный вариант сервера баз данных, который, например, может не обеспечивать многопользовательский режим доступа. Отдельной проблемой является обеспечение согласованности (когерентности) кэшей и общей базы данных. Здесь возможны различные решения – от автоматической поддержки согласованности за счет средств базового программного обеспечения управления базами данных до полного перекладывания этой задачи на прикладной уровень.
Преимуществами данной архитектуры являются [12, 15]:
- возможность, в большинстве случаев, распределить функции вычислительной системы между несколькими независимыми компьютерами в сети;
- все данные хранятся на сервере, который, как правило, защищен гораздо лучше большинства клиентов, а также на сервере проще обеспечить контроль полномочий, чтобы разрешать доступ к данным только клиентам с соответствующими правами доступа;
- поддержка многопользовательской работы;
- гарантия целостности данных.
Недостатки [12, 15]:
- неработоспособность сервера может сделать неработоспособной всю вычислительную сеть;
- администрирование данной системы требует квалифицированного профессионала;
- высокая стоимость оборудования;
- бизнес логика приложений осталась в клиентском ПО.
При проектировании информационной системы, основанной на архитектуре «клиент–сервер», большее внимание следует обращать на грамотность общих решений. Технические средства пилотной версии могут быть минимальными (например, в качестве аппаратной основы сервера баз данных может использоваться одна из рабочих станций). После создания пилотной версии нужно провести дополнительную исследовательскую работу, чтобы выяснить узкие места системы. Только после этого необходимо принимать решение о выборе аппаратуры сервера, которая будет использоваться на практике.
Увеличение масштабов информационной системы не порождает принципиальных проблем. Обычным решением является замена аппаратуры сервера (и, может быть, аппаратуры рабочих станций, если требуется переход к локальному кэшированию баз данных). В любом случае практически не затрагивается прикладная часть информационной системы. Также данный вид архитектуры называют архитектурой с «толстым» клиентом [7].
В первой главе данного исследования были рассмотрены основные характеристики архитектуры информационной системы – что понимается под информационной системой, что представляет собой архитектура информационной системы, и какие используются наиболее распространенные виды архитектуры информационных систем. Были кратко рассмотрены такие популярные технологии, как централизованная архитектура, архитектура «файл-сервер» и архитектура «клиент-сервер».
2 Технология «клиент–сервер»
2.1 Описание архитектуры «клиент–сервер»
Как правило, компьютеры и программы, входящие в состав информационной системы, не являются равноправными. Некоторые из них владеют ресурсами (файловая система, процессор, принтер, база данных и т.д.), другие имеют возможность обращаться к этим ресурсам. Компьютер (или программу), управляющий ресурсом, называют сервером этого ресурса (файл–сервер, сервер базы данных, вычислительный сервер и др.). Клиент и сервер какого–либо ресурса могут находится как в рамках одной вычислительной системы, так и на различных компьютерах, связанных сетью.
Основной принцип технологии «клиент–сервер» заключается в разделении функций приложения на три группы:
- ввод и отображение данных (взаимодействие с пользователем);
- прикладные функции, характерные для данной предметной области;
- функции управления ресурсами (файловой системой, базой данных и т.д.)
Поэтому, в любом приложении выделяются следующие компоненты:
- компонент представления данных;
- прикладной компонент;
- компонент управления ресурсом [6].
Связь между компонентами осуществляется по определенным правилам, которые называют «протокол взаимодействия».
Компанией Gartner Group, специализирующейся в области исследования информационных технологий, предложена следующая классификация двухзвенных моделей взаимодействия клиент–сервер (двухзвенными эти модели называются потому, что три компонента приложения различным образом распределяются между двумя узлами) (рис. 4) [15]:
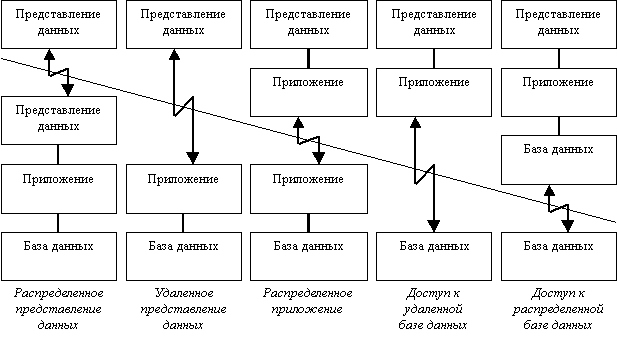
Рис. 4 Классификация двухзвенных моделей взаимодействия клиент–сервер
Исторически первой появилась модель распределенного представления данных, которая реализовывалась на универсальной ЭВМ с подключенными к ней неинтеллектуальными терминалами. Управление данными и взаимодействие с пользователем при этом объединялись в одной программе, на терминал передавалась только «картинка», сформированная на центральном компьютере.
Затем, с появлением персональных компьютеров (ПК) и локальных сетей, были реализованы модели доступа к удаленной базе данных. Некоторое время базовой для сетей ПК была архитектура файлового сервера. При этом один из компьютеров является файловым сервером, на клиентах выполняются приложения, в которых совмещены компонент представления и прикладной компонент (СУБД и прикладная программма). Протокол обмена при этом представляет набор низкоуровненых вызовов операций файловой системы. Такая архитектура, реализуемая, как правило, с помощью персональных СУБД, имеет очевидные недостатки – высокий сетевой трафик и отсутствие унифицированного доступа к ресурсам.
С появлением первых специализированных серверов баз данных появилась возможность другой реализации модели доступа к удаленной базе данных. В этом случае ядро СУБД функционирует на сервере, протокол обмена обеспечивается с помощью языка SQL. Такой подход по сравнению с файловым сервером ведет к уменьшению загрузки сети и унификации интерфейса «клиент–сервер». Однако, сетевой трафик остается достаточно высоким, кроме того, по прежнему невозможно удовлетворительное администрирование приложений, поскольку в одной программе совмещаются различные функции [20].
Позже была разработана концепция активного сервера, который использовал механизм хранимых процедур. Это позволило часть прикладного компонента перенести на сервер (модель распределенного приложения). Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, что и SQL–сервер. Преимущества такого подхода: возможно централизованное администрирование прикладных функций, значительно снижается сетевой трафик (т.к. передаются не SQL–запросы, а вызовы хранимых процедур). Недостаток – ограниченность средств разработки хранимых процедур по сравнению с языками общего назначения (C и Pascal).
На практике сейчас обычно используются смешанный подход:
- простейшие прикладные функции выполняются хранимыми процедурами на сервере;
- более сложные реализуются на клиенте непосредственно в прикладной программе [20].
Сейчас ряд поставщиков коммерческих СУБД объявило о планах реализации механизмов выполнения хранимых процедур с использованием языка Java. Это соответствует концепции «тонкого клиента», функцией которого остается только отображение данных (модель удаленного представления данных).
В последнее время также наблюдается тенденция ко все большему использованию модели распределенного приложения. Характерной чертой таких приложений является логическое разделение приложения на две и более частей, каждая из которых может выполняться на отдельном компьютере. Выделенные части приложения взаимодействуют друг с другом, обмениваясь сообщениями в заранее согласованном формате. В этом случае двухзвенная архитектура клиент–сервер становится трехзвенной, а к некоторых случаях, она может включать и больше звеньев [19].

Рис. 5 Взаимодействие элементов архитектуры «клиент-сервер»
В том случае, когда информационная система объединяет достаточно большое количество различных информационных ресурсов и серверов приложений, встает вопрос об оптимальном управлении всеми ее компонентами. В этом случае используют специализированные средства – мониторы обработки транзакций (часто их называют просто «мониторы транзакций»). При этом понятие транзакции расширяется по сравнению с используемым в теории баз данных. В данном случае это не атомарное действие над базой данных, а любое действие в системе – выдача сообщения, запись в индексный файл, печать отчета и т.д.
Для общения прикладной программы с монитором транзакций используется специализированный API (Application Program Interface – интерфейс прикладного программмирования), который реализуется в виде библиотеки, содержащей вызовы основных функций (установить соединение, вызвать определенный сервис и т.д.). Серверы приложений (сервисы) также создаются с помощью этого API, каждому сервису присваивается уникальное имя. Монитор транзакций, получив запрос от прикладной программы, передает ее вызов соответствующему сервису (если тот не запущен, порождается необходимый процесс), после обработки запроса сервером приложений возвращает результаты клиенту. Для взаимодействия мониторов транзакций с серверами баз данных разработан протокол XA. Наличие такого унифицированного интерфейса позволяет использовать в рамках одного приложения несколько различных СУБД [8].
Использование мониторов транзакций в больших системах дает следующие преимущества:
- Концентрация всех прикладных функций на сервере приложений обеспечивает значительную независимость как от реализации интерфейса с пользователем, так и от конкретного способа управления ресурсами. При этом также обеспечивается централизованное администрирование приложений, поскольку все приложение находится в одном месте, а не «размазано» по сети по клиентским рабочим местам.
- Монитор транзакций в состоянии сам запускать и останавливать серверы приложений. В зависимости от загрузки сети и вычислительных ресурсов он может перенести или скопировать часть серверных процессов на другие узлы. Это обеспечивает достижение баланса загрузки.
- Обеспечивается динамическая конфигурация системы, т.е. без ее остановки может быть добавлен новый сервер ресурсов или сервер приложений.
- Повышается надежность системы, т.к. в случае сбоев сервер приложений может быть перемещен на резервный компьютер.
- Появляется возможность управления распределенными базами данных [3].
2.2 Программное обеспечение технологии «клиент–сервер»
Типичная архитектура «клиент–сервер» требует того, чтобы компьютеры–серверы были мощнее и производительнее компьютеров–клиентов. Это связано с большой нагрузкой на серверы, и с тем, что на них лежит обязанность решения более серьезных задач, например, администрирования, выполнения большого количества одновременных запросов, обеспечения защиты данных и т.п.
Для эффективного применения технологии «клиент–сервер» требуется использование соответствующего программного обеспечения, которое, в свою очередь, должно включать в себя серверную и клиентскую части.
Программное обеспечение, которое устанавливается на сервере с целью управления базой данных, при реагировании на запросы клиентов, осуществляет поиск данных. Будучи частью архитектуры «клиент–сервер», соответствующее программное обеспечение возвращает результаты поиска по запросу [13].
Обработка информации на сервере представляет собой совокупность таких операций, как сортировка, извлечение и отправка пользователю необходимой информации.
В первую очередь программное обеспечение сервера обеспечивает такие действия над информацией, как обновление, удаление, добавление, защита и так далее.
Кроме того, на сервере размещаются и хранятся процедуры, которые подлежат использованию посредством любого клиента. Процедуры, хранимые на сервере, обеспечивают содействие в обработке информации, посредством уменьшения длины кода и применяемого пространства на клиентском аппаратном обеспечении. Так, любая одна хранимая процедура может подлежать вызову со стороны множества клиентов. При этом есть очень удобная особенность – каждый раз включать код процедуры в программу нет необходимости.
Помимо некоторой обработки информации, хранимые процедуры также могут уменьшать сетевой трафик, что объясняется тем фактом, что единственное обращение клиента приводит к выполнению серии команд хранимой процедуры, каждая из которых потребовала бы отдельного запроса, и могут проводить контроль безопасности, чтобы предотвратить несанкционированный запуск пользователями некоторых процедур [6].
Инструментальные средства, приложения и утилиты для интерфейсной части дополняют возможности модели «Клиент–сервер». К ним относятся средства запросов, которые упрощают доступ к данным сервера, используя предопределенные запросы и встроенные возможности для построения отчетов, пользовательские приложения, которые могут работать в качестве интерфейсной части, предоставляя доступ к серверу базы данных. Другие приложения (такие, как Microsoft Access) имеют свой собственный SQL, который обеспечивает доступ к системам управления базами данных от разных производителей. Для реализации систем «Клиент–сервер» необходимы специально разработанные интерфейсные части. Средства разработки программ (например, Microsoft Visual Basic) значительно облегчают программистам и администраторам информационных систем создание приложений, которые отвечают за доступ к серверам базы данных.
Выбор подходящего программного обеспечения зависит от выбора операционной системы и задач, которые необходимо выполнить. Например, в случае, когда применяется операционная система Windows, то на компьютере – клиенте в подавляющем большинстве случаев будет применяться пакет продуктов Microsoft Office, наделенный большим количеством разнообразных прикладных продуктов.
В связи с успехом распространения пакета Microsoft Office корпорация Microsoft решила собрать комплекс программ для сервера –пакет MS BackOffice. В состав названного пакета входят Windows Server – сетевая операционная система, System Management Server – система администрирования сети, SQL Server – сервер управления базами данных, SNA Server – сервер для соединения с хост–компьютерами, Exchange Server – сервер системы электронной почты и Internet Information Server – сервер для работы с Internet.
Windows Server 2000/2003/2008 способна обеспечить совместное использование файлов, печатающих устройств, предоставить услуги по соединению с рабочими станциями (клиентскими компьютерами) и другой сервис.
В качестве сетевой операционной системы используют Windows 2000/2003/2008 Server, которую можно использоваться и на рабочей станции для реализации дополнительных возможностей.
Windows Server 2000/2003/2008 обеспечивает совместное использование не только множества процессов, но и ресурсов многими пользователями. Возможность соединения с удаленными сетями реализуется через сервис удаленного доступа – RAS (Remote Access Service), а также через средства связи с сетями других фирм (Novell, Digital Pathworks и Apple) [18].
System Management Server (SMS) позволяет сетевому администратору централизованно управлять всей сетью. При этом обеспечивается возможность администрирования каждого компьютера, подключенного к сети, включая установленное на нем программное обеспечение. SMS предоставляет различные виды сервиса, например управление сетевыми приложениями и инвентаризацией программного и аппаратного обеспечения. SMS включает в себя автоматизацию установки и распространения программного обеспечения, включая его обновление, удаленное устранение неисправностей и предоставление полного контроля администратору за устройствами ввода и экранами всех компьютеров в сети [18].
Во второй главе данной работы подробно рассмотрена непосредственно технология «клиент-сервер», ее основные характеристики, а также программное обеспечение, которое необходимо для успешной работы с данной технологией.
ЗАКЛЮЧЕНИЕ
В ходе выполнения работы была достигнута поставленная цель, а именно – изучена технология «клиент–сервер».
Для достижения данной цели были выполнены следующие задачи:
- рассмотрены основные характеристики архитектуры информационных систем;
- кратко охарактеризованы виды архитектуры информационных систем;
- описана архитектура «клиент-сервер»;
- проанализировано программное обеспечение технологии «клиент–сервер».
При выполнении работы было определено, что сегодня каждый рядовой пользователь компьютера, выполняя те или иные рутинные операции на персональном компьютере, становится частью взаимодействия технологии «клиент-сервер». Данная технология достаточно сложна и многогранна, обладает рядом преимуществ и недостатков. При этом, учитывая распространение технологии «клиент-сервер», можно сказать, что число ее преимуществ значительно превышает число недостатков.
Следует также отметить, что современные технологии продолжают развиваться, в связи с чем нельзя назвать проблему изученной на сто процентов – она может быть доработана в соответствии с изменяющимися и обновляющимися требованиями времени.
СПИСОК ЛИТЕРАТУРЫ
- Брюхов, Д. Интероперабельные информационные системы: архитектуры и технологии / Д. Брюхов, В. Задорожный, Л. Калиниченко. – СУБД, 4, 1995.
- Вескес, Л. Дж. Access и SQL Server. Руководство разработчика / Дж. Л. Вескес – Москва: Лори, 1997.
- Гвоздева, В. А. Основы построения автоматизированных информационных систем / В. А. Гвоздева, И. Ю. Лаврентьева. – СИНТЕГ – Москва, 2016. – 320 c.
- Дейт, К. Дж. Введение в системы баз данных / К. Дж. Дейт – Москва: ДМК, 2015.
- Дрога, А. А. Прокопенко А. Н. Информатика и математика / А. А. Дрога, П. Н. Жукова, Д. Н. Копонев. – Минск, 2018.
- Зегжда, Д. П. Основы безопасности информационных систем / Д. П. Зегжда, А. М. Ивашко. – Горячая линия – Телеком – М., 2015. – 452 c.
- Ипатова, Э. Р. Методологии и технологии системного проектирования информационных систем. Учебник / Э. Р. Ипатова. – Флинта – М., 2016. – 652 c.
- Карминский, А. М. Методология создания информационных систем / А. М. Карминский. – ИНФРА–М – М., 2018. – 282 c.
- Конноли, Т. Базы данных. Проектирование, реализация и сопровождение /Т. Конноли, К. Бегг. – Москва: Вильяме, 2014.
- Кравченко А. В. Методика оценки эффективности информационных систем / А. В. Кравченко. – Университет – М., 2015. – 178 c.
- Кузнецов, С. Д. Основы баз данных. – 1–е изд. – М.: «Интернет– университет информационных технологий – ИНТУИТ.ру» / С. Д. Кузнецов. – 2015.
- Мельников, В. Защита информации в компьютерных системах / В. Мельников. – М.: Финансы и статистика, Электронинформ, 1997
- Морозевич, А. Н. Информатика / А. Н. Морозевич, А. М. Зеневич. – Минск, 2018.
- Советов, Б. Я. Архитектура информационных систем / Б. Я. Советов. – Академия (Academia) – М., 2017. – 934 c.
- Титоренко, Г. А. Информационные технологии управления / Г. А. Титоренко. – М., Юнити: 2016.
- Хомоненко, А. Д. Базы данных /А. Д. Хомоненко, В. М. Цыганков – Санкт–Петербург: БХВ–Петербург, 2014.
- Шастова, Г. А. Выбор и оптимизация структуры информационных систем / Г. А. Шастова, А. И. Коёкин. – Энергия – М., 2014. – 256 c.
- Шелухин, О. И. Моделирование информационных систем / О. И. Шелухин. – СИНТЕГ – Москва, 2014. – 536 c.
- Юркевич, Е. В. Введение в теорию информационных систем / Е. В. Юркевич. – Группа ИДТ – М., 2015. – 840 c.
- Ярочкин, В. Безопасность информационных систем / В. Ярочкин. – Ось–89 – М., 2016. – 320 c.

- Основы программирования на языке Pascal (Общая характеристика языка Pascal)
- АНАЛИЗ ФИНАНСОВЫХ РЕЗУЛЬТАТОВ И РЕНТАБЕЛЬНОСТЬ ПРЕДПРИЯТИЯ
- Управление текущими издержками предприятия
- Классификация языков программирования высокого уровня (Понятие о языках программирования)
- оценка персонала (На примере ОАО «турист»)
- Методы управления инновационными проектами (Сущность и понятие инновационных проектов )
- Человеческий фактор в управлении организацией (Сущность человеческого фактора и форма его существования)
- Юридическая ответственность (Характеристика понятия «юридическая ответственность»)
- Юридичeская ответственнoсть (Характеристика понятия «юридическая ответственность»)
- Предмет, метод предпринимательского права и принципы предпринимательского права
- Физические и юридические лица (Система Российского (и не только Российского) права)
- Роль мотивации в поведении организации (Понятие, сущность и значение мотивации персонала)