
Операции, производимые с данными (Операции с данными)
Содержание:

Введение
На протяжении многих веков человечество должно накапливать знания, навыки, информацию о мире вокруг нас, другими словами, информация, собранная. Изначально информация была передана из поколения в поколение в виде рассказов и устных историй. Возникновение и развитие книги разрешено передавать и хранить информацию в более надежном письменном виде. Открытия в области электричества привели к появлению на телеграф, телефон, радио, телевидение - средство для быстрой передачи и хранения информации. Прогресс развития привело к резкому увеличению информации, и поэтому вопрос о его сохранности и переработки становится все более острой с каждым годом. С появлением компьютеров существенно упростило хранение и обработку информации. Развитие вычислительной техники, основанной на микропроцессорах приводит к улучшению компьютеров и программного обеспечения. Программы, которые могут обрабатывать большие потоки информации. Такие программы являются информационные системы. Целью любой информационной системы является обработка данных объектов и явлений реального мира и предоставление права на получение информации о них. С моей точки зрения, важно рассмотреть процесс преобразования данных в информационные ресурсы и представления данных.
Все это привело к цели: изучить основные операции с данными.
Для достижения этой цели необходимо решить следующие задачи:
- Для того, чтобы дать общее описание данных;
- Считать операцию питания;
изучение различных структур данных;
- Для того, чтобы выполнить заказ структур данных;
- Мы считаем, что кодирование данных.
Объектом исследования являются данные.
Исследования, опубликованные в Интернете и учебной литературы по исследуемой проблеме.
Структура состоит из введения, 4 глав, заключения, списка литературы.
1. Понятие «данные», их носители
Информатика рассматривает информацию как понятие, не связанной с ними информации, данных, концепций, изменяя наше понимание явления или объекта мира. В дополнение к информации, содержащейся в компьютере часто используется dannye.Dannye понятие можно рассматривать как признаки или письменные наблюдения, которые по каким-то причинам не используются, а только хранятся. В этом случае можно использовать эту информацию для уменьшения неопределенности о чем-то, данные преобразуются в информацию. Таким образом, можно утверждать, что информация используется данные.
Информация является представление реального мира с помощью информации (сообщений). Наряду с термином "информация" в плане компьютерной "данных". Это понятие более узкое, чем информация, поскольку она носит фрагментарный характер, не связаны информации. Тем не менее, компьютерные программы, чаще используют термин "данные".
Обработка можно выделить четыре этапа:
1. Формирование исходных данных - исходная информация о бизнес-операции, документы, содержащие правила, результаты экспериментов, например, параметры новой модели самолета или автомобиля, и т.д ...
2. Накопление и систематизация данных, то есть. E. Организация таких данных, которые позволили бы быстрый поиск и отбор необходимой информации, методического обновления, защиты от искажений и так далее. D.
3. Обработка данных - процессы, в которых на основе ранее накопленных данных, формирование новых типов данных - .. Синтез, аналитической, консультативной, прогноза и т.д. из этих вторичной переработки могут быть подвергнуты следующей обработке и вызвать более глубокое и точным обобщением.
4. Отображение данных - представление данных в форме, пригодной для человека. Эта гравюра, графика (иллюстрации, графики, диаграммы и т. Д.), звук и так далее. D.
Сообщения, сгенерированные на первом этапе может быть обычным бумажным документом, аудио, видео, цифровые данные на носитель. Как правило, основными носителями информации (материальных носителей, полученных от аналоговых устройств) бумаги, пластинки, кассеты, видеокассеты очень кратковременным.
Компьютерные технологии предлагает новый подход к цифровой (дискретной) представления информации о магнитных и лазерных носителей.
Через аппаратного и программного обеспечения компьютера первичные данные преобразуются в машинный код.
Итак, подводя итог, можно сказать, что данные. Критический - диалектическая часть информации. Эти сигналы записываются. Во время физической регистрации метод может быть любым из: механического движения физических тел, изменение их формы и качества поверхности параметров, изменение электрических, магнитных, оптических характеристик, химического состава и характера химических связей, изменение состояния электронной системы и многое другое. В соответствии со способом записи данных можно хранить и транспортировать на любом типе носителя.
Критический - диалектическая часть информации. Эти сигналы записываются. Во время физической регистрации метод может быть любым из: механического движения физических тел, изменение их формы и качества поверхности параметров, изменение электрических, магнитных, оптических характеристик, химического состава и характера химических связей, изменение состояния электронной системы и многое другое. В соответствии со способом записи данных можно хранить и транспортировать на любом типе носителя.
Наиболее распространенным устройством хранения данных, хотя и не самым экономичным, по-видимому, является бумага. На бумаге данные регистрируются путем изменения оптических характеристик поверхности. Изменение оптических свойств (изменение коэффициента отражения поверхности в определенном диапазоне длин волн) также используется в устройствах записи лазерного луча на пластик с покрытием с отражающим носителям (CD-ROM). В качестве носителей, используя магнитные свойства можно назвать ленты и диски. Регистрация путем изменения химического состава носителя веществ на поверхности, обычно используемых в области фотографии. На биохимическом уровне, накопления и передачи данных в дикой природе.
СМИ заинтересованы в нас не сами по себе, но в той степени, что информация свойства очень тесно связана со свойствами его носителей. Любой носитель может характеризоваться параметрами разрешений (объем данных, хранящихся в полученном носителе для единицы измерения) и динамический диапазон (логарифмическая отношение интенсивностей максимальных и минимальных амплитуд обнаруженного сигнала). Эти свойства часто зависят от свойств носителя такой информации, как полнота, доступность и надежность. Например, мы можем рассчитывать на то, что база данных, содержащихся на компакт-диске, то легче обеспечить полноту, чем в той же базе данных назначения, расположенной на дискете, поскольку плотность данных на единицу длины дорожки гораздо выше. Для среднего потребителя доступность информации в книге гораздо выше, чем та же информация на компакт-диске, потому что не все потребители имеют необходимое оборудование. Наконец, известно, что визуальный эффект просмотра слайд-проектор гораздо больше, чем один вид той же иллюстрации, напечатанные на бумаге, так как диапазон сигналов яркости прошедшего света на два-три порядка больше, чем отражено.
Данные задачи преобразования с целью замены носителя является одним из наиболее важных проблем в области информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных, работа со средствами массовой информации, до половины стоимости оборудования.
Превосходное устройство хранения данных и носитель информации является человеческий мозг, содержащий около (10-15) -109-нейрональных клеток, сочетающих логики и памяти функции обработки информации.
Объем мозга, в среднем на 1,5 дм3, массой 1,2 кг, потребляемая мощность около 2,5 Вт. лучшее современное электронное устройство хранения при той же мощности имеет емкость несколько м3 при массе в десятки и сотни килограммов, а потребление энергии до нескольких кВт.
Основанные на фактических данных прогнозы говорят о том, что совершенствование электронной техники и применение новых высокопроизводительных, носителях, в сочетании с широким использованием методов бионики для решения проблем, связанных с синтезом хранения, позволяют создавать воспоминания, аналогичные показатели человека Память.
2 Операции с данными
Они характеризуются их типа и множества операций на них. Данные в компьютере разделены на простые и сложные.
Примеры простых данных, что компьютер может обрабатывать:
Таблица 1 - Типы данных и операции
|
№ |
Типы данных |
Операции |
|
1 |
Числа (числовые данные) |
Все арифметические операции |
|
2 |
Тексты (символьные данные) |
Замещение, вставка, удаление символов, сравнение, конкатенация строк |
|
3 |
Логические (бинарные) данные |
Все логические операции (конъюнкция, дизъюнкция, отрицание и др.) |
|
4 |
Изображения: рисунки, графика, анимация (графические данные) |
Операции над пикселями, из которых состоит изображение: яркость, цвет, контрастность |
|
5 |
Видео данные |
Удаление фрагмента, вставка фрагмента, работа с кадрами |
|
6 |
Аудио данные |
Усиление, уменьшение, удаление фрагмента, вставка фрагмента |
Для сложных данных: массивы и списки (тот же тип), структуры, записи, таблицы (в разных видах). В ходе информационного процесса данные преобразуются из одного вида в другой с помощью методов. Обработка данных включает в себя множество различных операций. С развитием научно-технического прогресса и общего усложнения связей в человеческом обществе работу по обработке данных неуклонно возрастает. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Вторым фактором, который также вызывает общее увеличение объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств хранения и доставки.
В структуре возможных операций являются следующие:
• сбор данных - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация данных - приведение данных из разных источников к одинаковой форме, чтобы сделать их сопоставимыми друг с другом,
надо поднимать их уровень доступности;
• фильтрация данных — фильтрация "лишних" данных, в которых нет необходимости для принятия решений; это должно уменьшить шум, и достоверность и адекватность данных должны возрастать;
• организация сортировки данных в указанный симптом с целью удобства использования; повышает доступность информации;
• архивация данных — сохранение данных в удобной и легкодоступной форме; служит для снижения экономических затрат на хранение и повышает общую надежность информационного процесса в целом;
• защита данных - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• передача данных - передача и получение (доставка и поставка) данных между удаленными участниками информационного процесса; источник данных в информатике называется сервером, а потребителя-клиентом;
• преобразование данных — перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и micropathology.
Необходимость многократного преобразования данных также происходит во время транспортировки, особенно если она не предназначена для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства — телефонные модемы.
3 Кодирование данных
3.1 Кодирование данных двоичным
Чтобы автоматизировать данные, относящиеся к различным типам, важно, чтобы объединить их представление - это, как правило, используется кодирование приема, то есть один тип экспрессии данных через канал передачи данных другого типа. Естественные человеческие языки не что иное, как понятия системы кодирования, выражать свои мысли посредством речи. Он тесно связан языки алфавита (система кодирования компонентов языка с помощью графических символов). Истории интересные, хотя и безуспешные попытки создать «универсальные» языков и алфавитов. По-видимому, провал попыток реализовать их из-за того, что национальное и социальное образование, естественно, понятно, что изменение системы кодирования публичных данных неизбежно приводит к методам социальных перемен (то есть, верховенство закона и морали), и это может быть связано с социальными потрясениями.
То же самое универсальное кодирование означает, что проблема достаточно успешно реализуется в отдельных отраслях машиностроения, науки и культуры. В качестве примера системы записи математических выражений, телеграфный алфавит, флаг морской алфавит, системой Брайля для слепых, и многое другое.
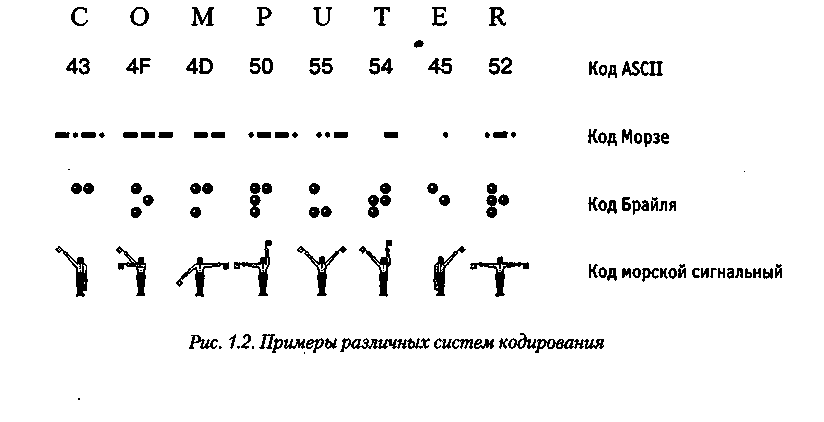
Рисунок 1 – Примеры различных систем кодирования
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит).
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11
Тремя битами можно закодировать восемь различных значений: 000 001 010 011 100 101 110 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
Т=2m
где N— количество независимых кодируемых значений;
m — разрядность двоичного кодирования, принятая в данной системе.
3.2 Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9 + 1
9:2=4+1
4 : 2 = 2 +-0
2:2=1+0
Таким образом, 19 10= 100112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 • 101 300 000 = 0,3 • 106
123 456 789 - 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
3.3 Кодирование текстовых данных
Если каждый символ алфавита соответствует определенное число (например, серийный номер), затем с помощью двоичного кода можно кодировать и текстовую информацию. Восемь битов достаточно для кодирования 256 различных символов. Этого достаточно, чтобы выразить различные комбинации восьми битов всех символов на английском и русском языках, причем оба строчных и заглавных букв и знаков препинания, символы, основные арифметические и некоторые наиболее часто встречающиеся специальные символы, такие как «§».
С технической точки зрения это выглядит очень просто, но всегда были достаточно сильны организационные сложности. В первые дни вычислений, они были связаны с отсутствием стандартов, и теперь называется, наоборот, обилие параллельных и противоречивых стандартов. Для того, чтобы во всем мире одни и те же кодированные текстовые данные, нам нужны общие таблицы кодирования, и это пока не представляется возможным из-за противоречий между символами национальных алфавитов, а также корпоративный характер противоречий.
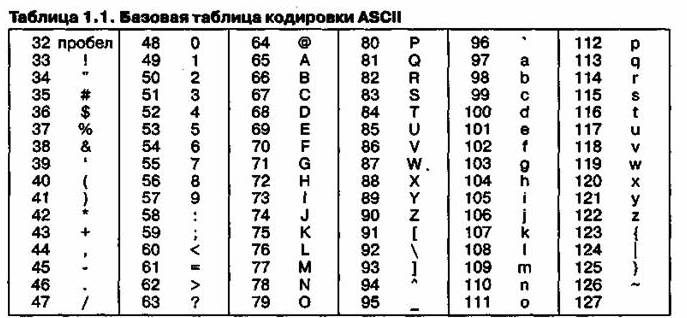
Для английского языка, де-факто захватили нишу международных средств связи, противоречия уже сняты. Американский институт стандартов (ANSI - Американский национальный институт стандартов) внедрило систему кодирования ASCII (Американский стандартный код для обмена информацией - стандартный код США для обмена информацией). Система ASCII фиксированной кодовой книги два - начального до продвинутого. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первый +0,32 основной кодовой таблицы, начиная с нуля, учитывая производители оборудования (особенно производителей компьютеров и принтеров). В этой области расположены так называемые управляющие коды, которые не соответствуют любые символы языков, и, следовательно, коды не выводятся на экран или печатающего устройства, но они могут управляться с помощью обоих режимов отображения других данных.
Начиная с кода 32 кода 127 кодов доступны английские символы, знаки препинания, цифры, арифметические и некоторые вспомогательные символы. Базовая таблица kodiuovki ASCII приведена в таблице 2. Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Например, в СССР в области кодирования системы работают кои-7 (обмен информацией код, семизначный). Тем не менее, поддержка аппаратного и программного обеспечения производителей привел американский код ASCII на уровне международных стандартов, а также национальных систем кодирования должны «отступление» ко второй, расширенной части системы кодирования, которая определяет значения кодов 128 255. отсутствие единого стандарта в этой области привело к множественности одновременно работающих кодировок. Только в России, можно указать три существующего стандарта кодирования и еще два устарели.
Таблица 2 – Базовая таблица кодировки ASCII
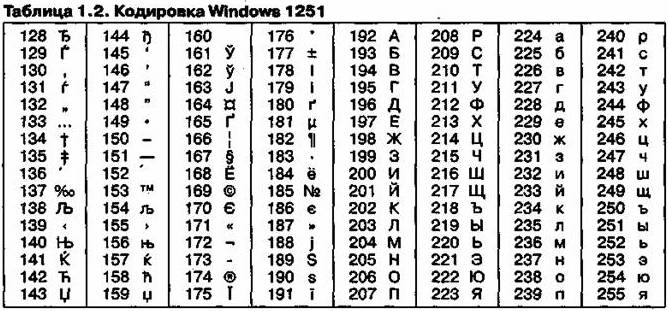
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 3). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Таблица 3 – Кодировка Windows 1251
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица 4). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернет».
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 5).
Таблица 4- Кодировка КОИ-8
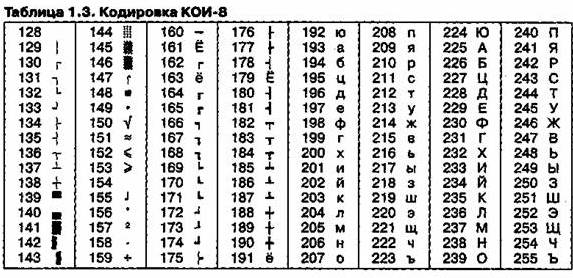
Таблица 5 – Кодировка ISO
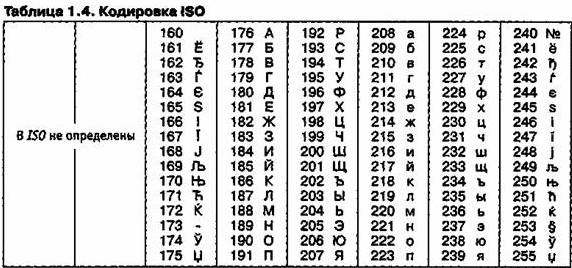
Таблица 6 – ГОСТ-альтеннативная кодировка

На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (таблица 6).
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
3.4 Универсальная система кодирования текстовых данных
Если проанализировать организационные проблемы, связанные с созданием единого sistemsh кодирования текстовых данных, то можно сделать вывод о том, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, например, Восьмибитовое кодированные символы представляют собой двоичные числа, числа с большим количеством битов, коды и диапазон возможных значений будет значительно больше. Такая система, основанная на 16-битной кодировке символов, называется универсальной - UNICODE. Unicode (Unicode или Unicode, английский Unicode.) - Стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Unicode имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Она была разработана как форма представления UTF-7 для семи каналов передачи битов, но из-за несовместимости с ASCII не получила широкого распространения и не входит в стандарт. В MicrosoftWindows NT и основанный на нем Windows 2000 и системы Windows XP, в основном используется форма UTF-16LE. В UNIX-подобных операционных систем GNU / Linux, BSD и Mac OS X принял форму UTF-8 для файлов и UTF-32 или UTF-8 символов в обработке памяти.
Стандарт, предложенный в 1991 году некоммерческая организация "Консорциум Unicode" (англ. Консорциум Unicode), которая объединяет крупнейших IT-корпораций. Применение этого стандарта позволяет закодировать очень большое число символов из разных сценариев: для документов Unicode могут сосуществовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, таким образом, становятся ненужными кодовой страницы.
Коды в стандарте Unicode разделены на несколько областей. Площадь коды U + 0000 до U + 007F содержит символы ASCII с соответствующими кодами. Далее расположены на отметках различных сценариев, знаки пунктуации и технические символы. Часть кода зарезервировано для будущего использования. Под символы кириллицы обозначаются кодом U + 0400 до U + 052F. Шестнадцать бит позволяют уникальные коды для 65536 различных символов - это поле достаточно, чтобы занять ту же таблицу символов большинства языков мира.
Хотя тривиального доказательства такого подхода, простой механический переход к этой системе уже давно сдерживается из-за ограниченных ресурсов компьютерной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся вдвое длиннее). Во второй половине 90-х годов технические средства достигли необходимого уровня доступности ресурсов, и сегодня мы наблюдаем постепенный перевод документов и программного обеспечения для универсальной системы кодирования. Для индивидуальных пользователей, это добавило больше забот, чтобы унифицировать документы, оформленные в различных системах кодирования с программным обеспечением, но следует понимать, как трудности переходного периода.
3.5 Кодирование данных изображения
Если вы посмотрите с увеличительным стеклом в черно-белом графическом изображении, который напечатан в газете или книге, мы видим, что она состоит из крошечных точек, образующих характерный узор, называемый растр (рис 2).

Рисунок 2 – Растр – метод кодирования графической информации, издавна принятый в полиграфии
Так как линейное положение и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что кодирование растровых изображений позволяет использовать двоичный код для представления графических данных. Общим сегодня считается черно-белое представление изображений в виде комбинаций точек с 256 оттенков серого, и, таким образом, чтобы закодировать яркость любой точки обычно достаточно восьми разрядного двоичного числа.
Для кодирования цветной графики и изображений, принцип разложения произвольного цвета на основные компоненты. В качестве таких компонентов с использованием трех основных цветов: красный (Red, R), зеленый (зеленый, G) и синий (голубой). Рассмотренные на практике (хотя и не теоретически), что любой цвет видимым человеческим глазом, могут быть получены путем механического смешивания трех основных цветов. Такая система называется система кодирования RGB в соответствии с первым буквам названий основных цветов.
При кодировании яркости каждого из основных компонентов, используемых для 256 значений (восемь бит), как это имеет место для полутоновое черно-белых изображений, цвет кодирования один момент вы должны потратить 24 бита. Система кодирования обеспечивает однозначное определение 16,5 млн различных цветов, что очень близко к чувствительности человеческого глаза. Просмотр цветной графики с использованием 24-битного полный цвет называется (истинный цвет).
Он может быть установлен на каждый из основных цветов в дополнительном подбора цвета, т. е. цвет, дополняющий основного цвета к белому. Легко видеть, что для каждого из основных цветов комплементарных пар цветов, образованных на сумму оставшихся первичных цветов. Соответственно, дополнительные цвета: синий (С), пурпурного (Magenta, M.) и желтый (желтый, у). Принцип разложения произвольной цветовых компонентов могут быть использованы не только для основных цветов, но и для других, то есть, любой цвет можно представить в виде суммы голубого, пурпурного и желтого цветов. Такой метод кодирования цвета принят в полиграфии, но и печать с использованием чернил четвертый - черный (черный, к). Таким образом, эта система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой, потому что письмо уже занята синим цветом), а также для представления цветной графики в этой системе должны иметь 32 бита. Этот режим также известен как полный цвет (истинный цвет).
Если сокращение числа битов, используемых для кодирования каждого цвета точки, то можно уменьшить объем данных, но диапазон цвет, закодированный заметно снижается. Кодирование цветной графики 16-разрядных двоичных чисел называется режимом High Color.
При кодировании информации о цвете с использованием восьми битов только 256 цветов может передавать данные. Этот метод кодирования называется индекс цвета. Смысл названия в том, что, так как 256 значений достаточно отлично передать весь диапазон цветов, доступных для человеческого глаза, каждый код точка не выражает сам цвет, а только его номер (индекс) в справочной таблице, называется палитра. Конечно, эта палитра должна быть применена к данным изображения, вы не можете использовать методы воспроизведения информации на экране или на бумаге (то есть, конечно, возможно, но из-за неполноты информации не будет адекватным : листья деревьев может быть красным, а небо зеленый).
3.6 Кодирование звуковой информации
Методы и приемы работы со звуковой информацией в компьютерной технологии пришли в прошлом. Кроме того, в отличие от цифрового символа, текстовых и графических данных, звук был, и как долго доказано кодирование истории. В результате, звуковую информацию с помощью двоичного кода методов кодирования далеки от стандартизации. Многие отдельные компании разработали свои собственные корпоративные стандарты, но, вообще говоря, две основные тенденции могут быть идентифицированы.
Метод FM (частотная модуляция) основана на том, что теоретически любой сложный звук можно разложить на последовательность простых гармонических сигналов различных частот, каждая из которых представляет собой обычный синусоида, и поэтому, может быть описана числовыми параметрами м. Е. Кодекс. В звуки природы имеют непрерывный спектр, то есть аналоговый. аналого-цифровых преобразователей (АЦП) - их разложения специальные устройства работают в гармоническом серии представлены в виде дискретных цифровых сигналов. Обратное преобразование для звукового воспроизведения закодирован числового кода, выполняют цифро-аналоговые преобразователи (ЦАП). Если такие преобразования неизбежны потери информации, связанной с методом кодирования, так что качество записи, как правило, не является удовлетворительным и соответствует качеству звучания простейших музыкальных инструментов в цветовой характеристике электронной музыки. В то же время, этот способ кодирования обеспечивает очень компактный код, и потому, что он нашел применение даже в те годы, когда ресурсы компьютерной техники недостаточно.
Табличный метод волны (волны таблица) синтеза лучше соответствует современному уровню технологического развития. Проще говоря, мы можем сказать, что где-то в предопределенных таблицах хранятся звуковые образцы для множества различных музыкальных инструментов (хотя и не только). Методика таких образцов называются образцы. Цифровые коды для обозначения типа прибора, его номер модели, высота, длина и интенсивность звука, динамику изменения, некоторые из параметров среды, в которой звук, а также другие параметры, характеризующие конкретный звук , Так как образцы используются "реальные" звуки, качество звука является результатом синтеза очень высока и близка к качеству звучания реальных музыкальных инструментов.
4 Основные структуры данных
Работа с большими наборами данных automatiseret проще, когда данные упорядочены, то есть, чтобы сформировать нужные структуры. Существует три основных типа структур данных: линейная, иерархическая и табличная. Их можно увидеть на примере обычных книг.
Если разбирать книгу на отдельные листы и перемешать их, книга потеряет свое назначение. Она будет представлять набор данных, но подобрать адекватный метод для получения из нее информации весьма непросто. (Даже хуже будет, если из книги вырезать каждую букву отдельно — в этом случае, вряд ли когда-нибудь адекватный способ для ее прочтения.) Если собрать все листы книги в правильной последовательности, мы получим простейшую структуру данных-линейную. Такую книгу уже можно читать, но чтобы найти необходимые данные он будет читать последовательно, начиная с самого начала .всегда удобно. Для быстрого поиска данных иерархическую структуру. Например, книга разделена на части, разделы, главы, параграфы и т. д. Элементы структуры низкого уровня являются элементами структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д. Для больших объемов данных поиск в иерархической структуре намного проще, чем в линейной, однако и здесь необходимо, navigaia, связанная с необходимостью просмотра. На практике задача облегчалась тем, что в большинстве книг есть дочерняя кросс-Таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой предназначен для последовательного чтения, это Таблица называется "оглавление" и в книгах со сложной структурой, позволяют выборочное чтение, это называется контент.
4.1 Линейные структуры (списки данных, векторы данных)
Линейные структуры-это хорошо известные списки. Список-это простая структура данных, где каждый элемент данных однозначно определяется своим номером в массиве. Мы записали цифры на отдельных страницах разбросаны книги, мы создаем структуру списка. Регулярное посещение занятий, например, имеет структуру списка, поскольку все студенты зарегистрированы под своими уникальными номерами. Мы назвали номер является уникальным, поскольку в одной группе не могут быть зарегистрированы два студента с одинаковым номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как найти необходимые элементы. В журнале посещаемости, например, это может быть решена следующим образом: каждый новый элемент списка делать - переходит на новую строку, то есть разделителем является конец строки. Затем нужный пункт вы можете найти по номеру строки.
N П/П Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
2 Бобров Борис
3 Воробьева Валентина Владимировна
27 Сорокин Сергей Семенович
Разделитель может быть любой специальный символ. Мы хорошо известны разделители между слов-пробел. В русском и многих европейских языках, обычный разделитель это точка. В рассмотренном примере классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ"*". Тогда наш список будет выглядеть так:
Аистов Александр Александрович * Бобров Борис Борисович * Воробьева Валентина Владимировна *... * Сорокин Сергей Семенович
В этом случае для поиска элемента с номером га надо просмотреть список начиная с самого начала и посчитайте разделители встречаются. Когда будут подсчитаны, я-1 разделителей, начнется нужный элемент. Она закончится, когда будет получен следующий разделитель.
Еще проще можно действовать, если все элементы списка имеют равную длину. В этом случае разделители в списке не нужны. Для поиска элемента с номером п надо просмотреть список с самого начала и граф(га-1), где а — длина одного элемента. Следующие символы, начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить не трудно. Такие упрощенные списки, состоящие из элементов равной длины, называют векторами данных. На работу с ними особенно удобной.Таким образом, линейные структуры данных (списки) - это упорядоченная структура, в которой адрес элемента однозначно определяется его номером.
4.2 Структура таблицы (таблицы данных, матрицы данных)
С таблицами данных мы тоже знакомы достаточно вспомнить известную таблицу умножения. Табличные структуры отличаются от списка, какие элементы данных определяется адрес ячейки, который состоит не из одного параметра, как в списках, но несколько. Для таблицы умножения, например, адрес ячейки определяется номером строки и столбца. Требуемая ячейка находится на их пересечении, а элемент выбирается из ячейки. При сохранении данных Таблица количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, если Таблица печатается в книгах, строки и столбцы разделяют графическими элементами — линиями вертикальной и горизонтальной разметки (рис. 3)
|
Планета |
Расстояние до Солнца, а.е. |
Относительная масса |
Количество спутников |
|
Меркурий |
0,39 |
0,056 |
0 |
|
Венера |
0,67 |
0,88 |
0 |
|
Земля |
1.0 |
1,0 |
1 |
|
Марс |
1,51 |
0,1 |
2 |
|
Юпитер |
5,2 |
318 |
16 |
В двумерных таблицах, которые печатают в книгах, применяется два типа разделителей — вертикальные и горизонтальные
Если вы хотите сохранить таблицу в виде длинных строк символов, используйте один символ-разделитель между элементами, принадлежащими к одной линии, и другой разделитель строк, вот так:
Ртуть*0,39*0,056*0#Венера*0167*0,88*0#Земля*110*1,0*1#Марс*1,51*0,1*2#...
Для поиска элемента с адрес ячейки (т, s), надо просмотреть набор данных с самого начала и пересчитать внешние разделители. Когда будет засчитано ТП-1 разделитель, надо преобразовать внутренние перегородки. После того как вы нашли п-\ разделитель, начнется нужный элемент. Она закончится, когда он встретит любой обычный сепаратор.
Даже легче, вы можете работать, если все элементы таблицы имеют равную длину. Такие таблицы называются матрицами. В данном случае разделители не нужны, поскольку все элементы имеют равную длину и их количество известно. Для поиска элемента с адресом (т, п) в матрице, имеющей М строк и N столбцов, надо смотреть его с самого начала и посчитать [Н(м -1) + (п -1)] символом, где а-длина одного элемента. Следующие символы, начнется нужный элемент. Его длина тоже равна а, поэтому его конец определить не трудно.Таким образом, структура табличных данных (матрицы) - это упорядоченная структура, в которой адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент.
Многомерной таблицы. Выше мы рассматривали пример таблицы с два измерения (строка и столбец), но в жизни часто приходится иметь дело с таблицами, у которых число измерений больше. Вот пример таблицы, которой может быть организован учет студентов.
Номер факультета: 3
Номер курса (кафедры): 2
Номер специальности (в год): 2
Номер группы в потоке одной специальности: 1
Номер студенческой группы: 19
Размерность этой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
4.3 Иерархические структуры данных
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами, мы очень хорошо знакомы в повседневной жизни. Иерархическая структура имеет систему почтовых адресов. Эти структуры также широко используется в научной систематизации и классификации различных (рис. 4).
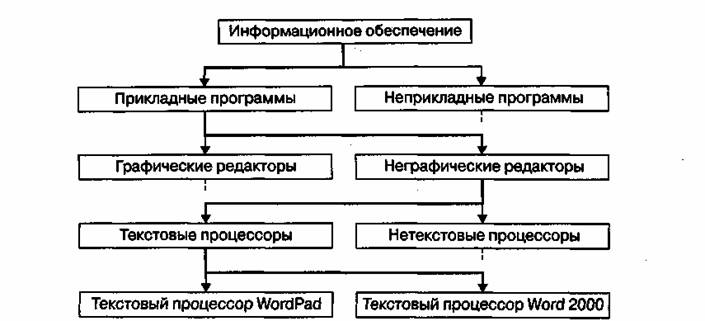
Рисунок 4 -Пример иерархической структуры данных
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows 98):
Пуск > Программы > Стандартные > Калькулятор.
Дихотомия данных. Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии. Его суть понятна из примера, представленного на (рисунок 5).
В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к текстовому процессору Word 2000 выразится следующим двоичным числом: 1010.
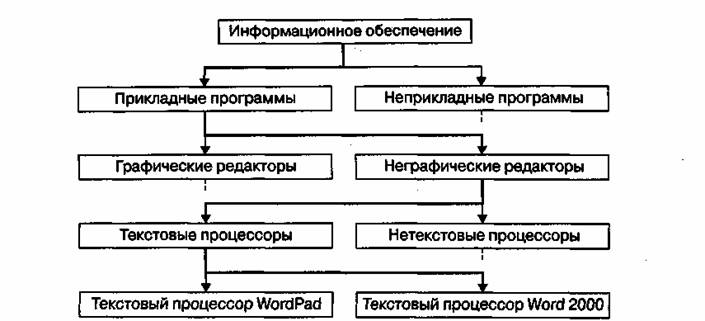
Рисунок 5 -Пример, поясняющий принцип действия метода дихотомии
4.4 Упорядочение структур данных
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например: по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток — их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов.
Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
Адресные данные. Если данные хранятся не как попало, а в организованной структуре (причем любой), то каждый элемент данных приобретает новое свойство (параметр), который можно назвать адресом. Конечно, работать с упорядоченными данными удобнее, но за это приходится платить их размножением, поскольку адреса элементов данных — это тоже данные, и их тоже надо хранить и обрабатывать.
Заключение
Таким образом, изучая темы исследований можно сделать следующие выводы.
Критический - диалектическая часть информации. Эти сигналы записываются. В то время как физический метод регистрации может быть любым: механическое перемещение физических тел, изменение электрических, магнитных, оптических характеристик, химического состава и характера химических связей, изменение состояния системы и многое другое.
В процессе информационного данные преобразуются из одной формы в другую с помощью методов. Обработка включает в себя множество различных операций. С развитием научно-технического прогресса и общей сложности отношений в человеческом обществе, работа по обработке данных неуклонно растет. Прежде всего, это связано с возрастающей сложностью производства и общественного контроля условий. Второй фактор, который также приводит к увеличению общего объема данных, подлежащих обработке, также связано с научно-техническим прогрессом, а именно быстрое появление и внедрение новых средств массовой информации для хранения, носителей информации и данных доставки. В структуре возможных операций являются следующие:
1. Сбор данных - накопление данных с целью обеспечения достаточной полноты информации для принятия решений;
2. Формализация данных - приведение данных из различных источников, в том же виде, чтобы сделать их сопоставимыми друг с другом, то есть, чтобы увеличить их доступность;
3. Фильтрация данных - Фильтрация "лишние" данные, в которых нет необходимости для принятия решений; Это должно снизить уровень шума, а также точность и адекватность данных должна возрастать;
данные 4. Сортировка данных заказа на основе определенных критериев с целью простоты использования; повышает доступность информации;
5. Группировка данных - объединение данных из данного симптома, с целью повышения простоты использования; повышает доступность информации;
6. Резервное копирование - сохранение данных в удобной и легкодоступной форме; Он служит для снижения экономических затрат на хранение и повышает общую надежность информационного процесса в целом;
7. Защита данных - комплекс мер, направленных на предотвращение утраты, воспроизведение и модификации данных;
8. Передача данных - передача и получение (отправка и доставка) данных между удаленными участниками информационного процесса; источник данных в компьютер называется сервером, а клиент пользователя;
Преобразование 9. Данные - передача данных из одной формы в другую, или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например книги можно хранить в оригинальной бумажной форме, но могут быть использованы для этой цели и в электронной форме, и micropathology. Необходимость многократного преобразования данных также имеет место во время транспортировки, особенно, если он не предназначен для этого вида транспорта данных. В качестве примера можно отметить, что для передачи цифровых потоков данных для телефонных сетей (которые изначально были направлены только на передачу аналоговых сигналов в узком диапазоне частот) должна преобразовывать цифровые данные в виде звуковых сигналов, и это занимаются специальные устройства - телефонные модемы.
Ниже приведен список типовых операций далека от завершения. Миллионы людей во всем мире занимаются созданием, обработкой, трансформации, передачи данных, и на каждой станции выполняет определенные операции, необходимые для управления социальными, экономическими, промышленных, научных и культурных процессов. Полный список возможных операций не может быть построена, и не нужно. Теперь у нас есть еще один важный вывод: работа информации может иметь большую интенсивность труда, и она должна быть автоматизирована.
Работа с большими наборами данных automatiseret проще, когда данные упорядочены, то есть, чтобы сформировать требуемую структуру. Существуют три основных типа структур данных: линейные, иерархические и табличной.
Линейная структура хорошо известные списки. Список это простая структура данных, в которой адрес каждого элемента однозначно определяется его номером. Он находится на отдельных страницах книги, мы создаем структуру списка, поскольку все студенты регистрируются под своими уникальными номерами. Мы назвали номер является уникальным, потому что в одной группе не могут быть зарегистрированы два студента с таким же номером.
Линейные структуры данных (списки) - это упорядоченная структура, в которой адрес элемента однозначно определяется его номером.
С помощью этих таблиц, мы тоже знакомы, чтобы запомнить таблицу умножения. Табличные структуры отличаются от списка элементов данных определяется адрес ячейки, который состоит не из одного параметра, как в списках, и многое другое. Для таблицы умножения, например, адрес ячейки определяется номером строки и столбца. Нужный ячейка находится на пересечении, а элемент, выбранный из клетки.
Структура данных таблицы (матрицы) - упорядоченной структурой, в которой адрес элемента определяется строки и столбца, который находится на пересечении ячейки, содержащей нужный элемент.
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто в виде иерархических структур. С такими структурами, мы очень хорошо знакомы в повседневной жизни. Иерархическая структура системы адресов электронной почты. Эти структуры также широко используются в научной систематизации и классификации различны.
Иерархическая структура элемента адреса определяется доступом (маршрут), ведущий от верхней части структуры к данному элементу. Например, это выглядит как путь к команде, которая запускает программу-калькулятор (стандартную программу на компьютерах, работающих под управлением операционной системы Windows 98):
Список использованной литературы
1 Борисов Р.С. Информатика (базовый курс) [Электронный ресурс]: учебное пособие/ Борисов Р.С., Лобан А.В.— Электрон. текстовые данные.— М.: Российский государственный университет правосудия, 2014.— 304 c.— Режим доступа: http://www.iprbookshop.ru/34551
2 Выжигин А.Ю. Информатика и программирование [Электронный ресурс]: учебное пособие/ Выжигин А.Ю.— Электрон. текстовые данные.— М.: Московский гуманитарный университет, 2012.— 294 c.— Режим доступа: http://www.iprbookshop.ru/14517
3 Гарибов А.И. Информатика [Электронный ресурс]: учебное пособие/ Гарибов А.И., Куценко Д.А., Бондаренко Т.В.— Электрон. текстовые данные.— Белгород: Белгородский государственный технологический университет им. В.Г. Шухова, ЭБС АСВ, 2012.— 224 c.— Режим доступа: http://www.iprbookshop.ru/27282
4 Губарев В.В. Информатика. Прошлое, настоящее, будущее [Электронный ресурс]: учебник/ Губарев В.В.— Электрон. текстовые данные.— М.: Техносфера, 2011.— 432 c.— Режим доступа: http://www.iprbookshop.ru/13281.
5 Казиев В.М. Введение в математику и информатику [Электронный ресурс]: учебное пособие/ Казиев В.М.— Электрон. текстовые данные.— М.: БИНОМ. Лаборатория знаний, Интернет-Университет Информационных Технологий (ИНТУИТ), 2007.— 301 c.— Режим доступа: http://www.iprbookshop.ru/15850
6 Львович И.Я. Основы информатики [Электронный ресурс]: учебное пособие/ Львович И.Я., Преображенский Ю.П., Ермолова В.В.— Электрон. текстовые данные.— Воронеж: Воронежский институт высоких технологий, 2014.— 339 c.— Режим доступа: http://www.iprbookshop.ru/23359
7 Метелица Н.Т. Информатика. Часть 1 [Электронный ресурс]: учебное пособие/ Метелица Н.Т., Орлова Е.В.— Электрон. текстовые данные.— Краснодар: Южный институт менеджмента, 2009.— 114 c.— Режим доступа: http://www.iprbookshop.ru/955
8 Метелица Н.Т. Информатика. Часть 2 [Электронный ресурс]: учебное пособие/ Метелица Н.Т., Орлова Е.В.— Электрон. текстовые данные.— Краснодар: Южный институт менеджмента, 2009.— 99 c.— Режим доступа: http://www.iprbookshop.ru/9556
9 Метелица Н.Т. Основы информатики [Электронный ресурс]: учебное пособие/ Метелица Н.Т., Орлова Е.В.— Электрон. текстовые данные.— Краснодар: Южный институт менеджмента, 2012.— 113 c.— Режим доступа: http://www.iprbookshop.ru/9751
10 Основы общей теории и методики обучения информатике [Электронный ресурс]: учебное пособие/ А.А. Кузнецов [и др.].— Электрон. текстовые данные.— М.: БИНОМ. Лаборатория знаний, 2013.— 208 c.— Режим доступа: http://www.iprbookshop.ru/6542
11 Прохорова О.В. Информатика [Электронный ресурс]: учебник/ Прохорова О.В.— Электрон. текстовые данные.— Самара: Самарский государственный архитектурно-строительный университет, ЭБС АСВ, 2013.— 106 c.— Режим доступа: http://www.iprbookshop.ru/20465
12 Сальникова Н.А. Информатика. Основы информатики. Представление и кодирование информации. Часть 1 [Электронный ресурс]: учебное пособие/ Сальникова Н.А.— Электрон. текстовые данные.— Волгоград: Волгоградский институт бизнеса, Вузовское образование, 2009.— 94 c.— Режим доступа: http://www.iprbookshop.ru/11321
13 Тишин В.И. Информатика и математика. Часть 1 [Электронный ресурс]: решение задач комбинаторики и теории вероятностей/ Тишин В.И.— Электрон. текстовые данные.— М.: БИНОМ. Лаборатория знаний, 2013.— 240 c.— Режим доступа: http://www.iprbookshop.ru/20712.

- Разработка регламента выполнения процесса «Расчет заработной платы» (Предлагаемые мероприятия по улучшению бизнес-процессов)
- Операции, производимые с данными (Понятие «данные», их носители)
- Понятие и виды сроков в гражданском праве (Возникновение и развитие бухгалтерского учета)
- Функции налогового учета
- Процедуры несостоятельности (банкротства). Предупреждение банкротства
- Понятие и система источников гражданского права (Гражданское право в системе правовых отраслей)
- История становления и развития налоговых органов россии
- Определение, основные задачи, функции бухгалтерского учета (Бухгалтерский учет, его место в системе управления экономикой организации)
- Бренд как конкурентное преимущество компании (Влияние бренда на конкурентоспособность предприятия)
- Основные этапы формирования налогового учета в России .
- Определение, основные задачи, функции бухгалтерского учета..
- Средства разработки клиентских программ (Аспекты разработки клиентских программ в области систем мониторинга для сельского хозяйства)