
Информатика и программирование
Содержание:

Введение
Тема курсовой работы «Алгоритмы сортировки данных» является очень актуальной на сегодняшний день. Мир информационных технологий постоянно растет и развивается, как и количество информации на всей планете. Информационные технологии решают такую задачу, как правильное, эффективное и удобное сохранение всех имеющейся информации на неких носителях. Для этого были созданы дискеты, диски, флэш-карты, винчестеры, базы данных, которые сохраняют информацию непосредственно в памяти ЭВМ. Кроме этого, теперь, всю необходимую информацию, пользователи, также могут сохранять и в сетях Всемирной паутины (Интернет). Но просто сохранить всю имеющуюся информацию недостаточно, ее необходимо организовать таким образом, чтобы искать необходимые, данные было просто и легко. Именно поэтому, изучение алгоритмов сортировок и поиска очень популярно в настоящее время.
Работа алгоритмов сортировки и поиска взаимосвязана, ведь в неупорядоченном множестве очень трудно найти некий элемент. Взять, к примеру, современные базы данных. Если вся имеющаяся в ней информация и поступающая новая информация не будут между собой отсортированы, логически связанны, то это приведет к хаосу в базе, и поиск в такой базе данных будет совершенно бессмысленным, пользователь только потратит массу времени и не получить нужного результата.
Также, для поиска информации, в сети Интернет (а эти сети содержат неимоверно огромное количество информации), используется некое программное обеспечение, которое включают в свой состав поисковые программы, такие как Google, Yandex, Rambler и так далее. Эти программы, для того чтобы быстро и эффективно найти по запросу пользователя некую информацию, используют два алгоритма:
- Алгоритм сортировки, с помощью которого происходит процесс упорядочивания, перегруппировки всей имеющейся информации;
- Алгоритм поиска, направленный на нахождение в упорядоченном множестве, искомой информации.
Алгоритмов сортировки и поиска существует огромное множество, и время, в результате которого произойдет нахождение некоей информации в указанном множестве, будет зависеть от того, как именно выполняют свою работы эти алгоритмы. Если принцип работы алгоритма сортировки очень быстр и легок, следовательно, и поиск в упорядоченном множестве произойдет быстро. Но не всегда бывает так, что скорость остается итоговым критерием при выборе того или иного алгоритма. Бывает такое что алгоритмы работают очень медленно, но качественно. Таким образом, только пользователь может решить каким именно алгоритмом он захочет пользоваться, а в данной курсовой работе будет рассмотрены самые популярные алгоритмы поиска и сортировки данных.
В данной курсовой работе в качестве объекта исследования выступают «Структуры и алгоритмы обработки данных», а предметом исследования являются «Алгоритмы сортировки данных».
В данной курсовой работе была поставлена цель, изучить наиболее удобные и популярные алгоритмы сортировки и поиска данных. Основной задачей для изучения, в данной курсовой работе является – изучить то, как именно пользоваться алгоритмами сортировки и поиска данных на примере языка программирования Pascal. Будет дано точное определение понятиям «алгоритм сортировки» и «алгоритм поиска». В данной курсовой работе, будет проведена оценка всех рассматриваемых алгоритмов сортировки и поиска. Также, внимание будет уделено самому языку программирования Pascal.
Обзор источников. Рассмотрим основные используемые источники.
В своем известном произведении «Искусство программирования», известный программист Дональд Эдвин Кнут высказал, такую мысль, что сортировка и поиск играют важную роль в программировании.[11] автор уделяет особое внимание тому, как происходит работа отдельно взятого алгоритма, и, с помощью примеров, объясняет, насколько они важны в настоящее время.
В своем произведении автор Ивановский С.А. «Структуры и алгоритмы обработки данных» уделяет особое внимание важности алгоритмам сортировки и поиска данных, рассматривает детально работу каждого из них. Автор приводит множество примеров и иллюстраций, что помогает более явно понять данную тему. [8]
Глава 1 Структура и алгоритмы обработки данных
Как уже было сказано, мир информационных технологий не стоит на месте и постоянно развивается, и вместе с ним появляется все большее количество информации. Информационные технологии помогают всю эту информацию сохранить и упорядочить (сортировать) так, чтобы это было удобно пользователям. Все данные, которые сохранены в памяти ЭВМ, представлены в ней в виде двоичных разрядов (битов), которые получили название структуры данных.[2]
Для того, чтобы организовать работу пользователя и компьютера необходим специальный язык с помощью которого пользователь сможет давать компьютеру некие задания. Сначала это был машинный язык Assembler, который самостоятельно переводил значения, вводимые пользователем, в понятные для компьютера двоичные символы. Затем начали появляться усовершенствованные языки программирования, такие как С++, Fortran, Delphi, Pascal, Бейсик и многие другие. Такой язык программирования, как Бейсик очень легок в использовании, и применяется в основном для написания простейших программ, при обучении молодых и начинающих программистов. Ему на смену пришел следующий язык программирования Fortran, который также очень легок в использовании, но имеет небольшой недостаток – при работе с этим языком необходимо придерживаться строгих правил написания кода. Следующее поколение языков программирования – это языки С++ и Pascal. С++, как и машинный язык переводит символы пользователя в машинные символы, и имеет много других удобных функций. Язык программирования Pascal требует очень точного и четкого написания кодов, следовательно, с его помощью, пользователь может сделать как можно меньше ошибок. При работе с Pascal использует команды, которые схожи со словами английского языка, следовательно, он очень понятен и удобен в использовании. В данной курсовой работе будет рассмотрен именно этот язык программирования[1].
Этот язык программирования очень легок для обучения молодых программистов и с его помощью можно создавать простые и легкие программы, с помощью которых программисты получат свой первый опыт работы. С помощью специального алфавита (набор символов) пользователь может прописывать текст создаваемых им программ. Язык программирования Pascal имеет свой синтаксис, который определяет, как правильно создавать конструкции текста.[4]
При написании программы с помощью языка программирования Pascal используются специальные зарезервированные слова, которые очень схожи со словами английского языка. Они используются для того, чтобы обозначить операторов, разделов языка и так далее. На рисунке 1 приведена таблица зарезервированных слов языка программирования Pascal:
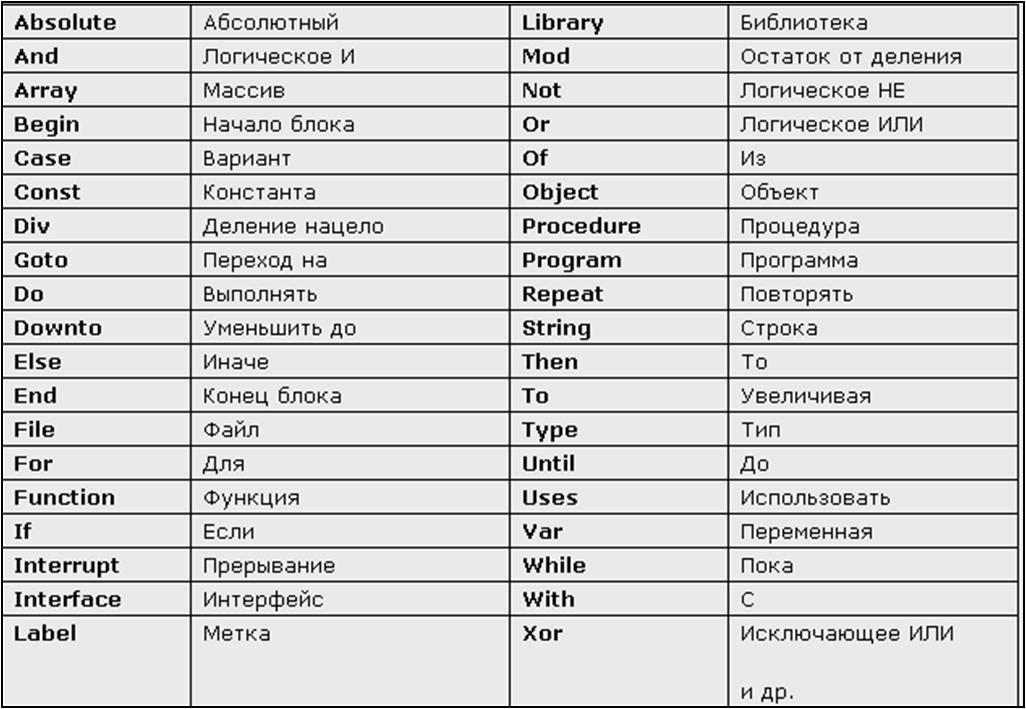
Рис.1. Таблица зарезервированных слов в языке Паскаль
Также, при написании кода программы с помощью языка программирования Pascal используются знаки пунктуации, которые также несут в себе некоторый смысл. Эти знаки пунктуации рассмотрим на рисунке 2:

Рис.2. Таблица знаков пунктуации в языке Паскаль
Рассмотрим, что такое алгоритм. Алгоритм - точное предписание исполнителю совершить некую последовательность, для того, чтобы достигнуть некую цель, за конкретно определенное количество шагов.
Понятие «точное предписание» является скорее абстрактным понятием, так как пользователь не всегда знает, что именно ему необходимо выяснить с помощью алгоритма. Поэтому, были сформулированы основные свойства алгоритмов, которые их характеризуют.
Первое свойство – это последовательность (дискретность). Это свойство говорит о том, что алгоритм представляет собой процесс последовательных, поэтапных действий, и каждое следующее действие начнется только после того, как закончиться предыдущее.
Второе свойство – это определенность. Все действия алгоритма всегда четкие и однозначные.
Третье свойство – это результативность. Работа алгоритма всегда должна быть закончена с некоторым результатом. Это результат может быть либо удачным, либо неудачным.
И четвертое правило – это массовость. При своей работе алгоритм оперирует большим количеством объектов.
Алгоритмы предоставляются несколькими способами.
- Формульно-словесный способ. Это способ основан на том, что при создании такого алгоритма, используется четко поставленные действия, совместно со словесными объяснениями;
- Способ алгоритмического языка. Такой способ включает в себя математические формулы или выражения, словесные пояснения, а также служебные слова;
- Графический способ (блок-схемы). В этом случае, работа алгоритма показана с помощью некоторых геометрических фигур, которые показаны на рисунке 3:
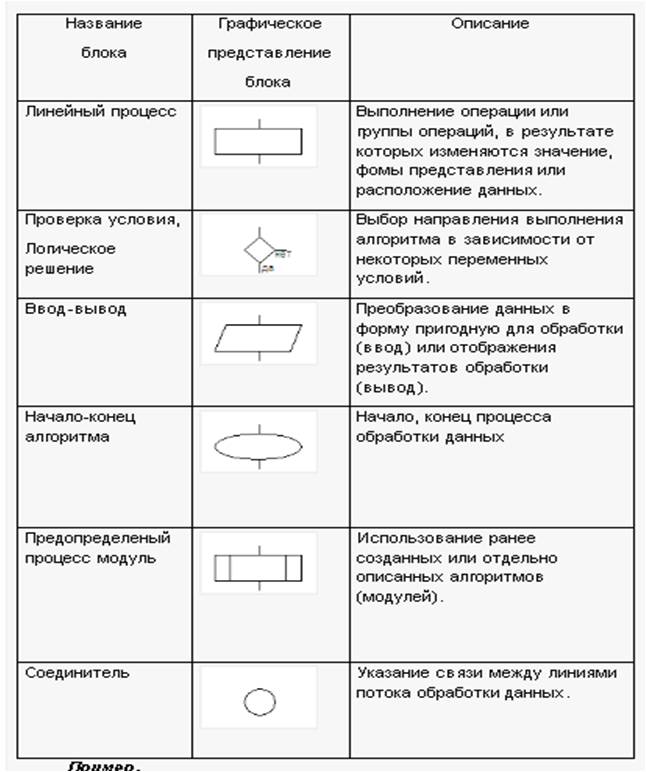
Рис.3. Графический способ предоставления алгоритмов
Рассмотрим пример: пользователю необходимо выяснить следующее: С=. Алгоритм необходимо представить в виде блок схемы:
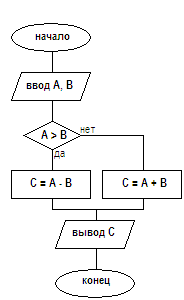
Рис. 4. Блок схема алгоритма
На рисунке видно, что начало алгоритма показано с помощью «овала», далее алгоритм вводит известные значения А и В. После этого, алгоритм выполняет действия по нахождению искомого результата «С». Конец работы алгоритма показан снова с помощью «овала».
Также необходимо уделить внимание и таким моментам в работе алгоритмов – это время выполнения работы, ее сложность и объем дополнительной памяти, который необходим во время выполнения его работы.
Для определения сложности разработаны некоторые критерии, которые показаны на рисунке 5:
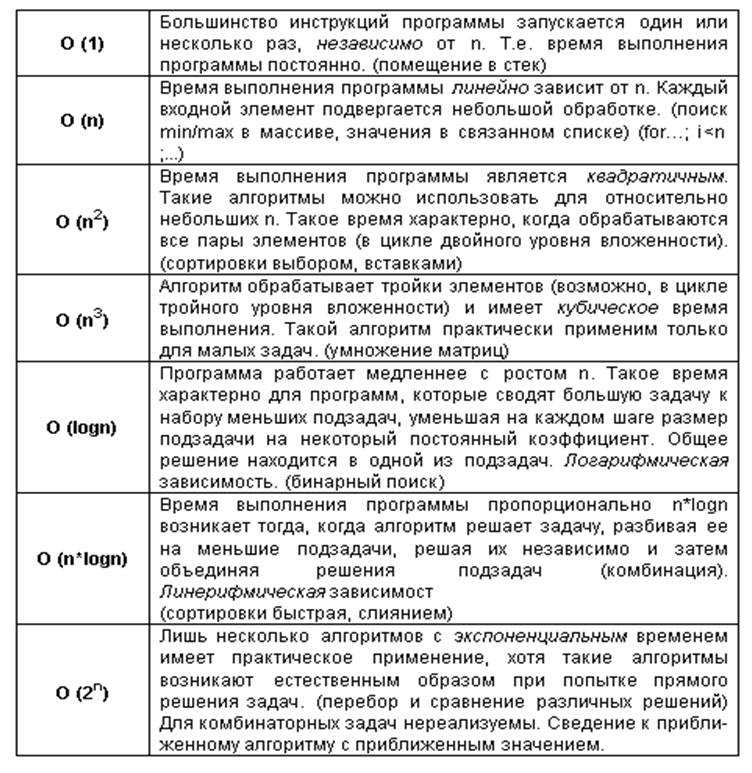
Рис. 5. Сложность работы алгоритмов
Некоторое множество данных, которые связаны между собой называются структурой данных. Структуры данных, которые представлены в памяти информационных технологий носят название физические структуры данных. Физические структуры данных имеют следующую классификацию:
- Внутренние структуры данных (данные, находящиеся в оперативной памяти ЭВМ);
- Внешние структуры данных (данные, находящиеся в памяти внешних устройств).
В данной курсовой работе будут рассмотрены алгоритмы сортировки и поиска. С такими алгоритмами пользователи сталкиваются очень часто. К примеру, всем известные информационные поисковые системы, такие как Google, Rambler, Yandex используют в своей работе 2 программы, от которых зависит искомый пользователем результат. Эти программы: сортировки и поиска, которые работают с помощью алгоритмов, которые будут изучены далее. От времени работы этих программ зависит и время, за которое пользователю будет предоставлена информация по его запросу.
В данной главе курсовой работы был изучен язык программирования Pascal. Было уделено особое внимание понятию «алгоритм». Были изучены его свойства, виды предоставления алгоритма, его сложность, время работы. Алгоритмы выполняют очень большой объем работы, и на современном этапе, без него очень тяжело обойтись. В следующих главах будут рассмотрены важные алгоритмы: сортировки и поиска.
Глава 2 Алгоритмы сортировки
Прежде чем начать изучение популярных алгоритмов сортировок, необходимо дать определение понятию «алгоритмы сортировок». Алгоритм сортировки – это такой процесс, в результате которого происходит перестановка, упорядочивание объектов некоторого множества, в таком порядке, который требуется пользователю. Алгоритмы сортировки упрощают дальнейший поиск некоторых данных.
Как уже было сказано, алгоритмы сортировки очень удобны, и с упорядоченными данными пользователи сталкиваются каждый день. Примером таких упорядоченных данных могут служить следующие: книжные полки в любой библиотеке, картотека в больнице, телефонные книги. Без сортировки данных жизнь каждого человека превратилась бы в хаос. Для того, чтобы найти необходимые для него данные, пользователю необходимо было бы потратить огромное количество времени на поиск.
Итак, сортировка встречается везде и без нее невозможно обойтись. Алгоритмов сортировок очень много, по некоторым данным, на сегодняшний день, имеется более 40 видов алгоритмов сортировок, и каждый день появляются новые и улучшенные.[12] Важным качеством любого алгоритма является скорость его работы. Ведь от него зависит время, которое может потратить пользователь на процесс упорядочивания данных, и то, как скоро он начнет поиск искомых данных. Эта скорость выполнения работы алгоритма зависит напрямую от количества перестановок и сравнения данных в массиве.
На рисунке 6 показаны известные и популярные алгоритмы сортировок, с указанием уровня сложности:
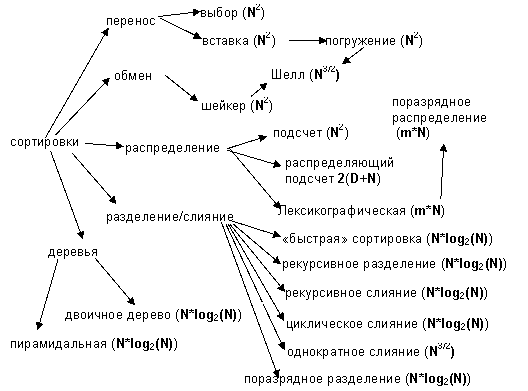
Рис. 6. Алгоритмы сортировок
Как видно по рисунку алгоритмов очень много, и все они работают по-разному. Следовательно, только пользователь может выбрать для себя удобный и оптимальный алгоритм сортировки.
Алгоритмы сортировки данных принято разделять на две категории:
- Внутренняя сортировка (сортировка файлов). Такая сортировка применяется для данных, которые находятся во внутренней памяти ЭВМ;
- Внешняя сортировка (сортировка массивов). Такая сортировка применяется для упорядочивания данных, которые сохранены на внешней памяти (магнитные ленты, флэшки, переносных винчестерах и так далее). Хотя, внешняя сортировка значительнее медленней внутренней, но все равно она пользуется популярностью у пользователей, которые заботятся об экономном использовании памяти компьютера.
Во время работы алгоритма сортировки, функция упорядочивая данных, не рассчитывается по некоему установленному правилу, а содержится в виде явной компоненты (по другому - поля). Значение такой компоненты носит название ключа алгоритма сортировки, и он используется для определения элемента.[20]
Рассмотрим, в первую очередь, алгоритмы внутренней сортировки данных. Как уже было сказано, алгоритмы внутренней сортировки работают только с данными, которые находятся во внутренней памяти ЭВМ. И именно поэтому, при выборе рассматриваемых алгоритмов сортировки данных отдается предпочтение тем алгоритмам, которые экономят эту память, то есть в первую очередь, рассматривается эффективность алгоритма.[9] Эту эффективность можно определить при подсчете количества сравнений ключей и пересылок сортируемых элементов.
Для начала, необходимо рассмотреть простые алгоритмы внутренней сортировки данных, так как они очень легки в использовании и в обучении. Программы, которые создаются при помощи этих простых алгоритмов сортировки, работают лишь в массивах с малым количеством элементов, но они очень быстры и эффективны в своей работе, следовательно, с их помощью молодые начинающие программисты легко получат неисчерпаемый багаж знаний, и затем, научатся работать с более сложными алгоритмами сортировки. Простыми алгоритмами внутренней сортировки данных считаются: сортировка обменом (метод пузырька), сортировка выбором, сортировка включением. Рассмотрим их подробно.
2.1 Сортировка методом пузырька (обменом)
Как уже было сказано, сортировка методом пузырька считается наиболее простым алгоритмом сортировки. Для лучшего понятия определения этого алгоритма можно представить себе сосуд, наполненный газированной водой. Самые тяжелые пузырьки воздуха всплывают наверх сосуда, а самые легкие остаются на дне. Так и алгоритм сортировки работает таким образом, что «тяжелые» элементы оказываются наверху массива, а «легкие» остаются внизу.[14] Каждый элемент массива сравнивается с другим элементом, и если один из них окажется «тяжелее» другого, то они меняются местами. Если в массиве будет найден самый большой элемент, то он будет считаться главным элементом, и все остальные элементы будут сравниваться с ним. Это сравнение будет происходить до тех пор, пока этот «тяжелый» элемент не окажется на вершине массива.
Рассмотрим, на примере, как работает данные алгоритм внутренней сортировки данных:
|
2 |
2 |
2 |
2 |
2 |
|
8 |
8 |
8 |
8 |
8 |
|
16 |
5 |
5 |
5 |
5 |
|
5 |
16 |
7 |
7 |
7 |
|
7 |
7 |
16 |
10 |
10 |
|
10 |
10 |
10 |
16 |
3 |
|
3 |
3 |
3 |
3 |
16 |
Как уже известно, суть данного алгоритма заключается в том, чтобы максимальный элемент массива оказался в конце массива. Работа алгоритма начинается в том, что он разбивает массив на группы элементов и сравнивает их поочередно между собой. Как видно, первая пара элементов не требует перестановки, также как и второй элемент не является больше третьего. Далее сравниваются элементы «16» и «5». Четвертый элемент меньше элемента «16», следовательно, их необходимо поменять местами. Следующий элемент «7» меньше – меняем местами, «10» меняем местами с «16», и последний шаг – элемент «3» требует смены позиций с элементом «16». По итогу всей работы алгоритма максимальный элемент «16» оказался в конце рассматриваемого массива.
На рисунке 7 показана блок схема работы алгоритма сортировки методом пузырька:
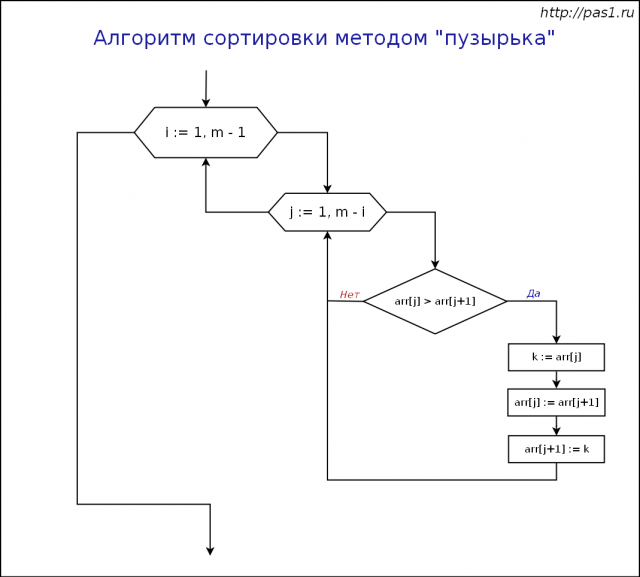
Рис. 7. Блок схема алгоритма
Приведем пример программы для сортировки методом пузырька на рисунке 8:
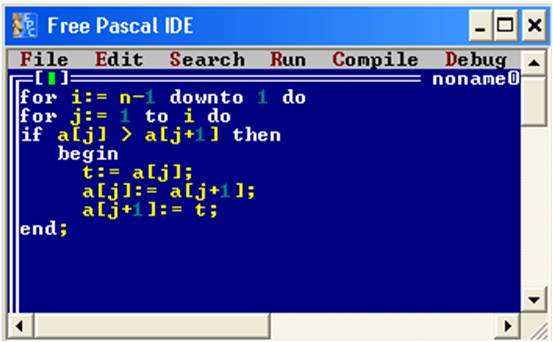
Рис. 8. Листинг алгоритма сортировки методом пузырька
У данного метода сортировки есть один существенный недостаток – массив, над которым проводилась работа, в конечном итоге оказывается не до конца отсортированным. Максимальный элемент массива оказывается в конце, но остальные элементы не считаются упорядоченными. При сортировке массивов с малым количеством элементов этот недостаток может оказаться незамеченным, но в больших массивах это может привести к затруднениям для пользователей. Для решения этой проблемы программисты усовершенствовали данный метод, и назвали его алгоритмом шейкер-сортировки. Этот алгоритм в процессе своей работы не только добивается того, что максимальный элемент оказывается в конце массива, но и сортирует остальные элементы в порядке возрастания, что очень удобно для пользователей.[15] По итогу своей работы он упорядочивает элементы массива следующим образом:
|
2 |
3 |
5 |
7 |
8 |
10 |
16 |
Программа в Pascal для шейкер-сортировки:
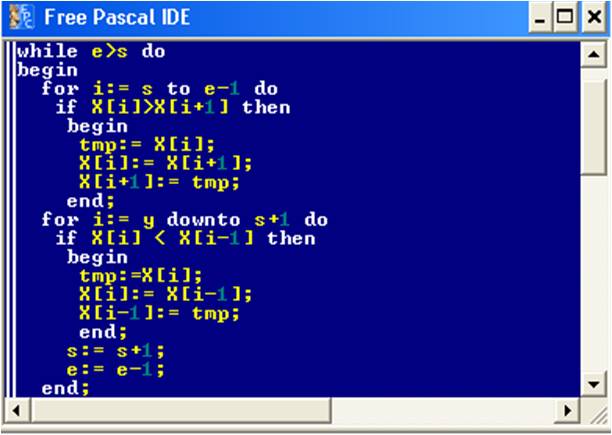
Рис. 9. Листинг шейкер-сортировки
Алгоритм шейкер-сортировки считается доработанным вариантом алгоритма сортировки методом пузырька.
2.2. Сортировка с помощью выбора
Сортировка с помощью выбора очень удобна в использовании, и в конце ее работы самый «большой» элемент массива окажется в конце массива. Данный алгоритм выбирает в массиве элемент с наименьшим значением, и производит его перестановку с элементом, который находится в начале массива, следовательно, сортировка с помощью данного алгоритма происходит по возрастанию. Рассмотрим по таблице, пример того, как происходит этот процесс перестановки элементов:
|
4 |
1 |
1 |
1 |
|
6 |
6 |
4 |
4 |
|
14 |
14 |
14 |
6 |
|
7 |
7 |
7 |
7 |
|
8 |
8 |
8 |
8 |
|
12 |
12 |
12 |
12 |
|
1 |
4 |
6 |
14 |
Как видно на таблице, массив отсортирован в порядке возрастания, но у данного алгоритма есть один существенный недостаток – в связи с тем, что в результате своей работы алгоритм выполняет несколько проходов по всему массиву, в поисках элемента с наименьшим значением, он затрачивает на это много времени, следовательно, он выполняет свою работу гораздо медленнее рассмотренного выше алгоритма сортировки. [5]
На рисунке 10 показана блок схема алгоритма внутренней сортировки выбором:
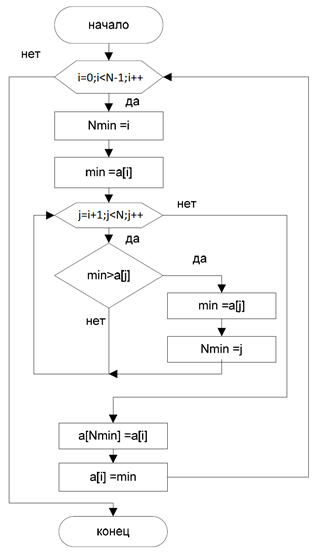
Рис. 10. Алгоритм сортировки выбором
Для лучшего понимания работы алгоритма сортировки выбором необходимо привести пример программного листинга алгоритма:
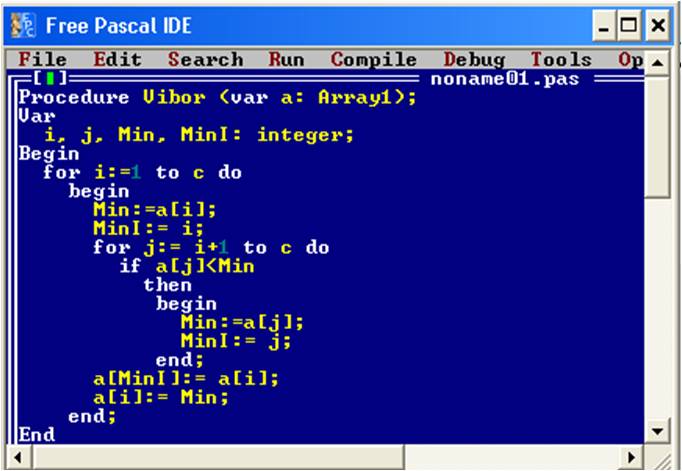
Рис.11. Листинг программы
Итак, данный алгоритм сортировки очень эффективен при работе с массивами, которые имеют малое количество элементов.
2.3. Алгоритм сортировки включением
Последний из простых алгоритмов сортировки – это сортировка простым включением. Идея данной сортировки заключается в том, что элемент сравниваются между собой, можно сказать в логической последовательности, например, сначала сравнивается первая пара элементов, после их упорядочения с ними сравнивается третий элемент массива. [17] В итоге, каждый элемент массива занимает свое место, и сортировка происходит по возрастанию. Для лучшего понимания данного определения необходимо рассмотреть следующую таблицу:
|
3 |
3 |
3 |
3 |
2 |
|
7 |
5 |
5 |
5 |
3 |
|
15 |
7 |
7 |
7 |
5 |
|
5 |
15 |
9 |
9 |
7 |
|
9 |
9 |
15 |
11 |
9 |
|
11 |
11 |
11 |
15 |
11 |
|
2 |
2 |
2 |
2 |
15 |
Как видно в таблице, данный алгоритм сортировки данных очень эффективен в упорядочивании элементов массива, но такой алгоритм работает очень быстро в уже практически отсортированном массиве данных. Чем меньше количество проходов в массиве, тем быстрее данный алгоритм выполняет свою работу. Но как уже было сказано, простые алгоритмы сортировок данных, эффективны только в массивах с малым количеством элементов. В массивах с большим количеством элементов они будут работать очень долго, потребуют выделения дополнительной памяти и многое другие неприятные для пользователя ситуации. Но, как уже было сказано, на их основе созданы усовершенствованные алгоритмы внутренней сортировки, которые быстро и легко справляются с большими массивами данных.
На рисунке 12 показана блок схема алгоритма сортировки включением:
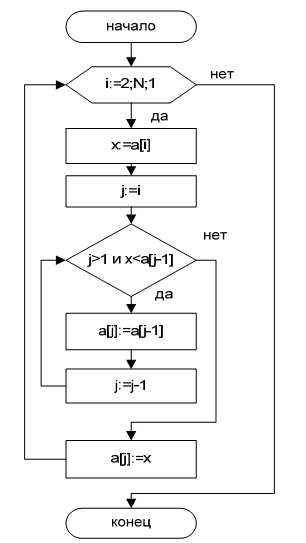
Рис.12. Блок схема алгорима сортировки включением
Для того, чтобы более ясно понять как именно производит свою работу алгоритм сортировки включением необходимо рассмотреть листинг программы данной сортировки:
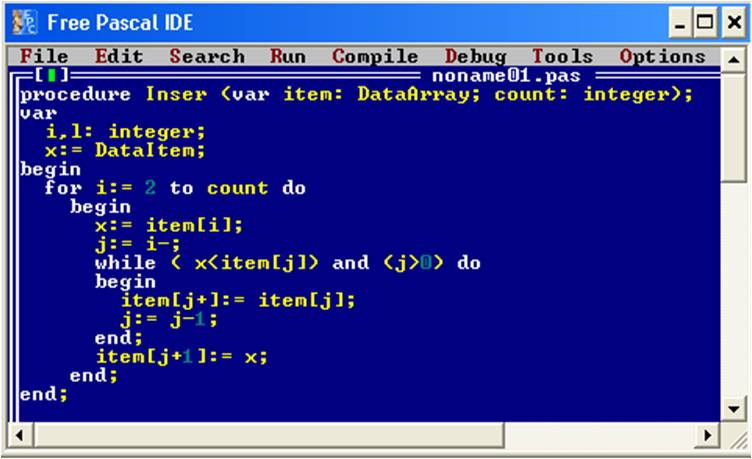
Рис. 13. Листинг сортировки включением
2.4. Сортировка Шелла
Рассматриваемый алгоритм сортировки был изобретен программистом Дональдом Шеллом в 1959 году, и получил свое название в честь своего изобретателя.[7] этот алгоритм выполняет свою работу в несколько проходов. Сначала он сравнивает элементы, которые находятся друг от друга на расстоянии, предположим, 8 позиций, затем, при втором проходе сравниваются элементы, которые располагаются друг от друга на расстоянии, например, 4 позиции. На последнем проходе, данный алгоритм просто упорядочивает оставшиеся неотсортированные элементы между собой. Для лучшего понятия работы данного алгоритма сортировки, рассмотрим следующий пример:
|
7 |
4 |
2 |
2 |
|
5 |
3 |
3 |
3 |
|
2 |
2 |
4 |
4 |
|
4 |
7 |
6 |
5 |
|
3 |
5 |
5 |
6 |
|
6 |
6 |
7 |
7 |
На данной таблице видно, что алгоритм сортировки методом Шелла выполнил свою работу за три прохода по массиву. Зрительно можно сказать, что алгоритм разбивает массив на группы. В данном случае группа «7 и 5» произвела смену мест с группой «4 и 3». Массив уже выглядит упорядоченным, следующий шаг, смена мест между собой элементов «4» и «2», а также элементов «7» и «6». На последнем шаге, алгоритм лишь произвел смену мест двух элементов, которые находились не на своем месте – это элементы «6» и «5».
Эффективность данного алгоритма сортировки данных заключается в том, что он не манипулирует в процессе своей работы всем элементами массива, а упорядочивает их группами, на некотором определенном шаге. Пользователям может показаться, что в этом случае данный алгоритм работает медленнее рассмотренных выше алгоритмов сортировок, но на самом деле он работает достаточно быстро, так как массив упорядочивается на каждом проходе алгоритма.
На рисунке 14 показана блок схема алгоритма сортировки методом Шелла:

Рис.14. Сортировка методом Шелла
Для лучшего представления того, как именно работает данный алгоритм необходимо рассмотреть листинг программы его работы:
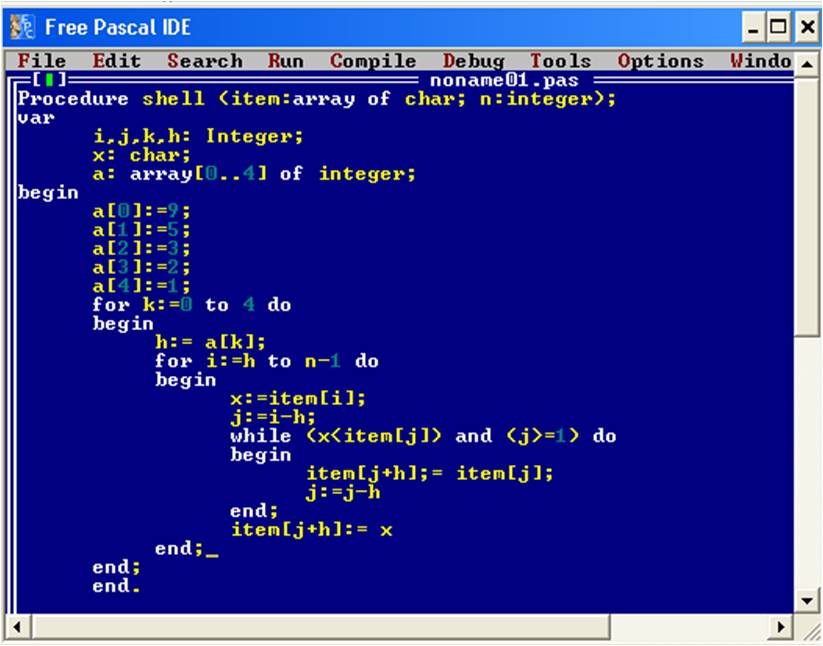
Рис.15. Листинг алгоритма сортировки методом Шелла
Итак, данный алгоритм внутренней сортировки данных очень эффективен, при сортировке больших массивов данных, так как она очень быстро выполняет свою работу, но в некоторых случаях требует выделения дополнительной памяти в процессе своих действий.
2.5. Сортировка разделением
Данный алгоритм сортировки имеет несколько названий – сортировка разделением, сортировка методом Хоара (названа так в честь программиста К.Хоара, который ее изобрел в 1962 году), а также быстрая сортировка. Алгоритм сортировки разделением считается, на сегодняшний день, считается наиболее универсальным алгоритмом, и работает очень быстро, поэтому и получил такое название.
Смысл данной сортировки заключается в том, что в массиве выбирается некий элемент с максимальным значением, и этот элемент сравнивается с другими элементами. И, все минимальные элементы отсортировываются в начало массива, а максимальные в конец массива. [18] Это продолжается в несколько проходов по массиву, и каждый раз, в массиве, выбирается один опорный элемент, с которым происходит сравнение других элементов массива, пока весь массив не будет упорядочен. Для того, чтобы лучше понять данное определение, рассмотрим таблицу:
|
9 |
7 |
7 |
7 |
7 |
2 |
2 |
2 |
|
6 |
6 |
6 |
6 |
6 |
6 |
6 |
3 |
|
3 |
3 |
3 |
3 |
3 |
3 |
3 |
4 |
|
4 |
4 |
4 |
4 |
4 |
4 |
4 |
6 |
|
10 |
10 |
9 |
8 |
8 |
8 |
7 |
7 |
|
8 |
8 |
8 |
9 |
2 |
7 |
8 |
2 |
|
2 |
2 |
2 |
2 |
9 |
9 |
9 |
9 |
|
7 |
9 |
10 |
10 |
10 |
10 |
10 |
10 |
Как видно по таблице, данный массив был отсортирован за 8 проходов. При первом проходе в качестве опорного элемента был принят элемент «9», он поменялся местами со стоящим в конце массива элементом «7» во втором проходе. Далее, при проведении своей работы алгоритм сравнил элемент «9» с элементом «10», и так как 10>9, то они поменялись местами. Затем, элемент «9» произвел смену мест с элементами «8» и «2». Конец массива упорядочен, теперь в качестве главного элемента выступает элемент «7». Работа алгоритма производилась аналогично описанным выше процедурам, и в результате данный массив был отсортирован по возрастанию.
На рисунке 16 показан пример блок схемы алгоритма быстрой сортировки данных:
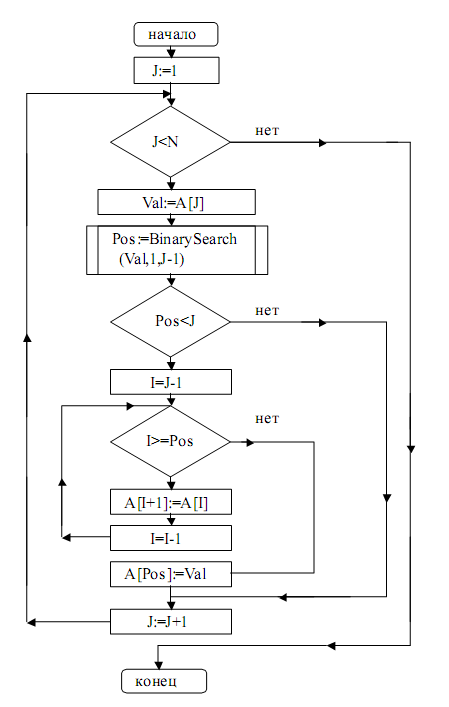
Рис. 16. Блок схема быстрой сортировки
Для лучшего понятия того, как именно происходит работа данного алгоритма сортировки, необходимо рассмотреть листинг программы:
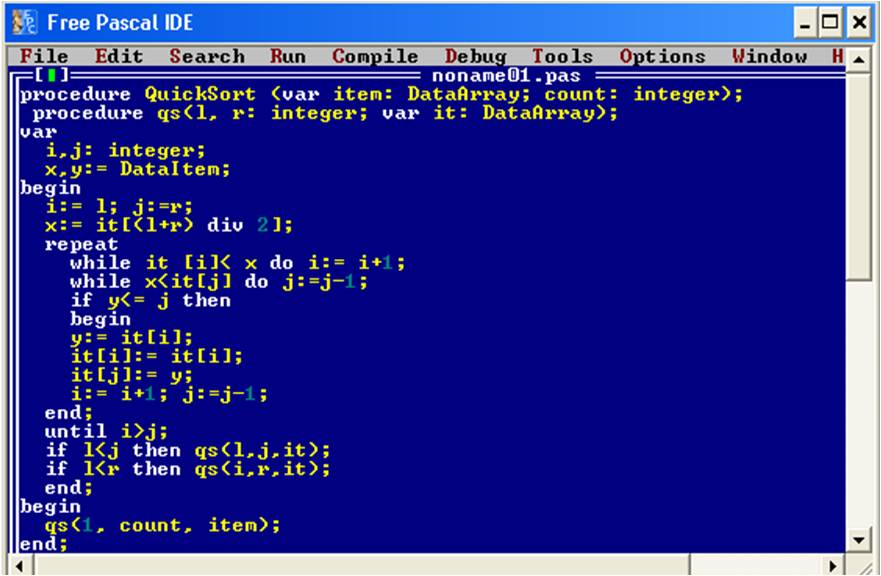
Рис. 17. Листинг быстрой сортировки
Но эта быстрота рассматриваемой сортировки скрывает за собой и неприятное свойство алгоритма – она требует, при своей работы, выделения дополнительной памяти ЭВМ, что очень неприятно для пользователей.
Итак, в данной главе курсовой работы было уделено внимание алгоритмам внутренней сортировки данных. Были рассмотрены простые способы сортировки, а также их усовершенствованные прототипы. Всех их отличает друг от друга то, что они по разному выполняют свою работу, каждый из них тратит определенный промежуток времени на выполнение своей работы. Простые алгоритмы сортировок очень быстры, но эффективно работают только в массивах с малым количеством элементов. Усовершенствованные алгоритмы сортировки быстро справляются и с большими массивами данных, но требуют выделения дополнительной памяти ЭВМ. Следовательно, какой алгоритм сортировки выбрать пользователю, определяется лично им самым. Алгоритмов сортировки очень много, значит и выбора у пользователя достаточно, он может легко остановить свой выбор на некоем алгоритме, опираясь лишь на собственные нужды в той или иной ситуации.
2.6. Внешняя сортировка
Внешняя сортировка применяется для упорядочивания данных, которые находятся на внешней памяти запоминающих устройств, как:
- Накопители на магнитных лентах;
- Накопители на жестких магнитных дисках;
- Накопители на гибких магнитных дисках;
- Накопители на оптических дисках;
- Флэш-память;
- Твердотелые накопители.
Устройства сохранения данных во внешней памяти позволяют сохранять большие объемы информации, которые при необходимости можно перенести во внутреннюю память ЭВМ. Обычно, внешняя сортировка применяется при работе с базами данных, и от качественной работы внешней сортировки зависит эффективность и производительность систем управления базами данных.
Алгоритмы внешней сортировки получили широкое распространение в период, когда пользователи использовали магнитные ленты, в качестве внешнего устройства сохранения информации. Пользователи могут получить только последовательный доступ к данным, сохраненным на магнитных лентах. И сегодня, при появлении современных и универсальных устройств с магнитными дисками, может показаться, что пользователь избавился от проблемы связанной с последовательным доступом. Но, сегодня все устройства внешней памяти имеют специальные магнитные головки, которые отвечают за прокрутку диска, за чтение, запись на диск и с диска и многие другие операции. И для того, чтобы, например, списать с диска некую информацию, пользователям необходимо подождать некоторое время, когда эта головка подойдет к нужному блоку устройства. Следовательно, пользователь тратит множество времени на ожидание действий магнитных устройств. Исправить эту ситуацию можно только в том случае, если располагать всю необходимую информацию ближе друг к другу, и записывать (или считывать) ее в последовательном режиме. Время, которое алгоритм тратит на выполнение своей работы, зависит от ходов головки между актами считывания или записи, от внутренней сортировки частей файла, от действий в памяти при слиянии упорядоченных частей. И самое главное, скорость алгоритма обусловлена размером внутренней памяти (буфера), которая используется во время сортировки данных.
В следующих главах будет уделено внимание таким популярным алгоритмам внешней сортировки, как прямое слияние, естественное слияние.
2.7 Прямое слияние
Сортировка слиянием считается наиболее простым алгоритмом внешней сортировки. Этот алгоритм работает очень быстро и эффективно, особенно с такими элементами массива, которые считываются или записываются последовательно. Алгоритм слияния был разработан Д. фон Нейманом в 1945 году.[6] Алгоритм сортировки слиянием работает в три этапа: сначала разбивает массив на две части, потом происходит сортировка каждой из этих частей, и в конце, алгоритм объединяет эти две отсортированные части, и производит конечную сортировку.
Для лучшего понимания работы рассматриваемого алгоритма, необходимо рассмотреть следующий пример.
|
1 |
№ 1 |
№2 |
1 |
|||
|
3 |
2 |
|||||
|
6 |
1 |
2 |
3 |
|||
|
7 |
3 |
3 |
3 |
|||
|
15 |
6 |
8 |
6 |
|||
|
2 |
7 |
12 |
7 |
|||
|
3 |
15 |
19 |
8 |
|||
|
8 |
12 |
|||||
|
12 |
15 |
|||||
|
19 |
19 |
Алгоритм внешней сортировки прямым слиянием имеет один существенный недостаток – она требует увеличения используемой памяти, так как при ее работе требуется разбивать алгорит на 2 части.
На рисунке 18 показан пример листинга программы сортировки простым слиянием:
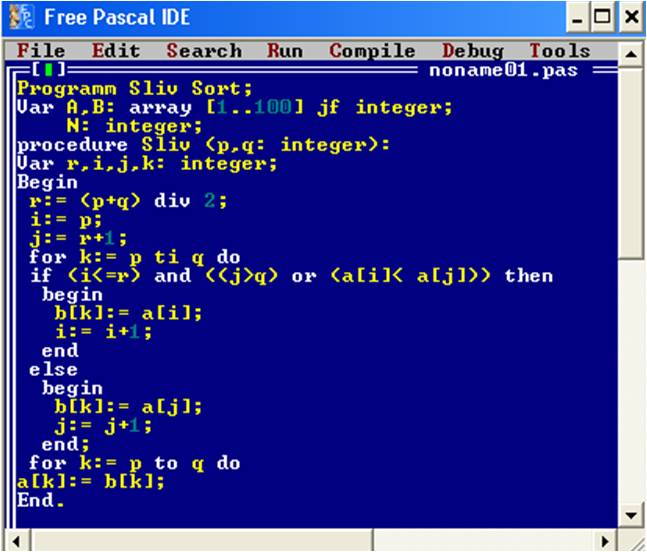
Рис.18. Листинг алгоритма прямого слияния
Итак, при сортировке простым слиянием происходит упорядочивание серий, установленной алгоритмом, длины. Эта сортировка очень удобна для упорядочивания данных, хранящихся во внешней памяти, и быстра в своей работе.
2.8. Естественное слияние
Данный алгоритм сортировки – это такой алгоритм, при котором не происходит установление длины серий файла, а сама сортировка определяет количество элементов и упорядоченных подпоследовательностей, выделяемых на каждом шаге сортировки.[19]
Алгоритм сортировки естественным слиянием не происходит в некоем определенном порядке, она сначала анализирует все имеющиеся в файле элементы, затем разбивает их на группы, где они упорядочиваются, и затем производит объединение всех элементов файла путем сдваивания.
Для того, чтобы лучше понять данное определение рассмотрим рисунок 19, на котором показан пример работы данного алгоритма сортировки:
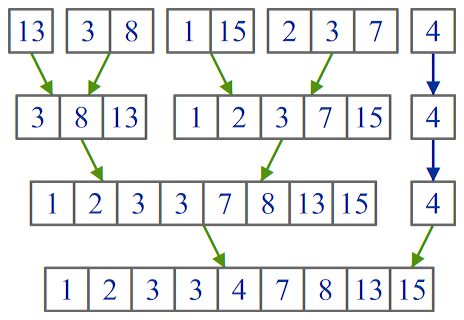
Рис. 19. Алгоритм сортировки естественным слиянием
Как видно на рисунке один единый неотсортированный файл был разбит на несколько упорядоченных групп, и сортировка поэтапно, собирает эти группы в единый отсортированный файл. Работа самого алгоритма происходит в четыре прохода по файлу.
На рисунке 20 показан пример листинга программы данного алгоритма сортировки:
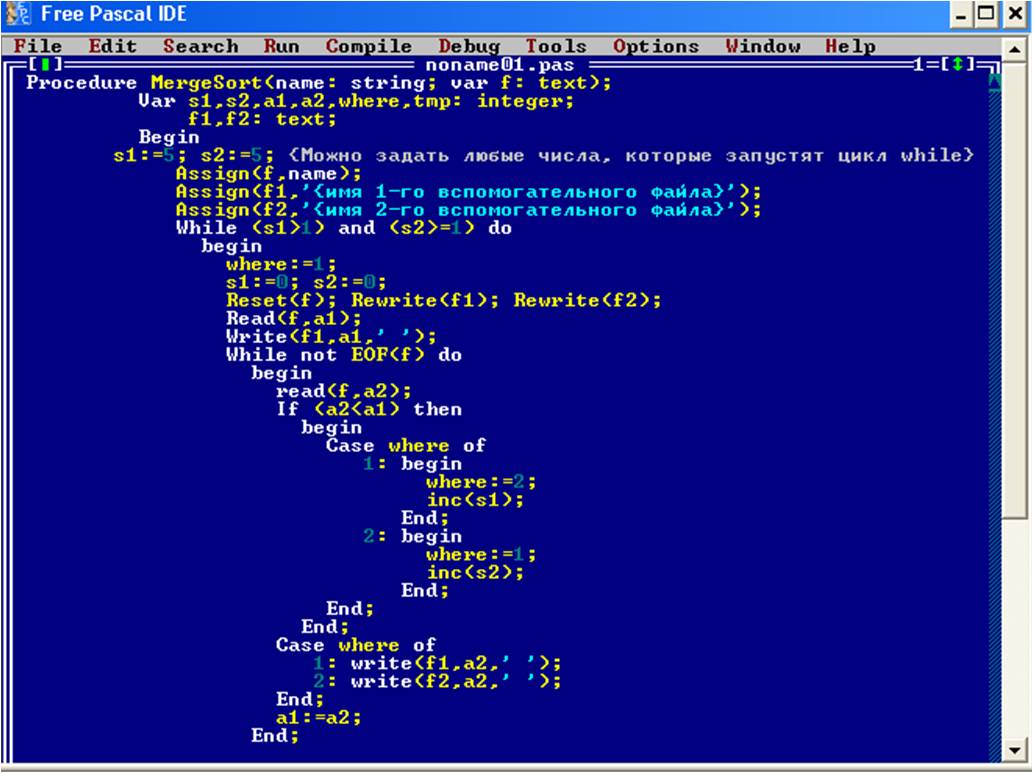
Рис. 20. Листинг программы алгоритма естественного слияния
Итак, данный алгоритм сортировки работает достаточно эффективно и быстро. Данный алгоритм сортировки не требует выделения дополнительно памяти, так как он сравнивает поочередно 2 или 3 элемента файла, следовательно, остальные элементы файла остаются нетронутыми до некоего определенного момента времени.
Итак, в данной главе курсовой работы были рассмотрены наиболее популярные алгоритмы сортировок, как внешние, так и внутренние. Для того, чтобы понять, какой алгоритм сортировки самый лучший, можно рассмотреть следующую таблицу:
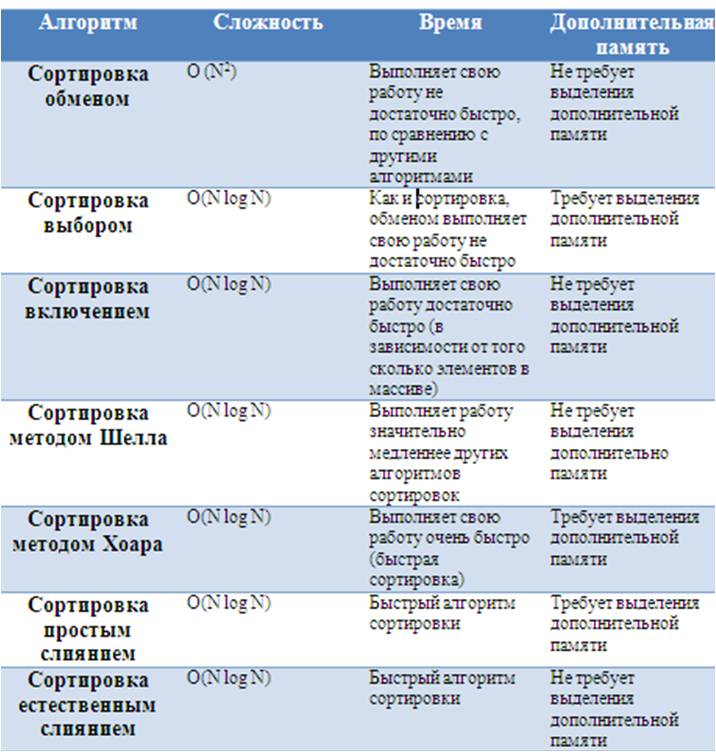
Как видно, что тут выбор остается только за пользователем.
Как было выяснено, этих алгоритмов очень большое количество, и все они работают по разному, но цель работу у этих алгоритмов сортировок одна – отсортировать массив или файл так, чтобы облегчить дальнейший поиск по нему. А, какой алгоритм выбрать, решает только пользователь. В следующей главе курсовой работы, будут рассмотрены основные алгоритмы поиска данных.
Глава 3 Алгоритмы поиска
С быстрым ростом информации и информационных технологий, с каждым днем, перед людьми встает задача - научиться эффективно работать с большим объемом информации, упорядочивать ее, и среди всего этого многообразия быстро находить интересующие его данные.
Процесс поиска – это такой процесс, в результате которого, в некотором множестве находится один (или несколько) искомый элемент. Поиск происходит после того, как пользователь задаст программе некие критерии искомого элемента. [13]
Методы поиска принято разделять:
- Статические;
- Динамические.
При статическом поиске, элементы массива остаются без изменения, а при динамическом, элементы могут перестаиваться в массиве и изменяться.
С поиском человечество сталкивается каждый день. Например, ученики на занятиях немецкого языка, постоянно сталкиваются с тем, что обращаются к словарю, для того, чтобы найти перевод того или иного слова. Этот случай является ярким примером динамического поиска информации, так как слова в словаре не могут изменить своего положения и всегда остаются на своих местах. В качестве примера динамического поиска можно привести такой случай: при работе с новой поступающей корреспонденцией, работники почтового отделения, постоянно сортируют письма по получателям, а потом ищут этих людей, в некоем городе, для того чтобы получатель получил свое сообщение.
В следующих главах курсовой работ, будет уделено особое внимание популярным алгоритмам поиска данных.
3.1. Алгоритм линейного поиска
Данный алгоритм поиска данных считается наиболее простым алгоритмом, так как он очень прост и удобен в реализации. Этот алгоритм выполняет свою работу следующим образом: он производит проход по массиву от начала и до конца. Если, искомое значение было найдено, то алгоритм заканчивает успешно свою работу, но, если искомого значения не оказалось в массиве, то алгоритм заканчивает свою работу неудачей.
Как простейший алгоритм поиска, этот алгоритм эффективно работает только в массивах, которые содержат лишь малое количество элементов. Но преимущество данного алгоритма следующее – при своей работе он не требует выделения дополнительной памяти.
Как уже было сказано, работа линейного поиска оканчивается только с двумя значениями – «успех» и «неудача».
На рисунке 21 показана блок схема алгоритма линейного поиска

Рис.21. Блок схема алгоритма линейного поиска
Также, для лучшего понятию материала необходимо рассмотреть листинг программы алгоритма линейного поиска:
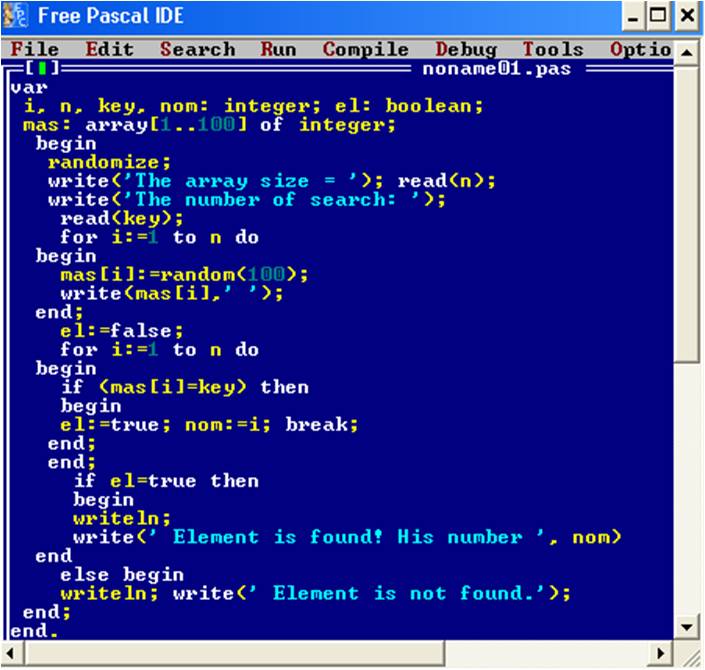
Рис. 22. Листинг программы
Рассматриваемый алгоритм сортировки имеет сложность O(N), что характеризует его как простейший алгоритм.
3.2. Поиск делением пополам
Поиск делением пополам наиболее усовершенствованный, чем линейный поиск и выполняет свою работу следующим образом: он разбивает массив, в котором произойдет поиска, на две части, и производит поиск искомого элемента в каждой из них. [16]
Как и линейный поиск, поиск делением пополам заканчивает свою работу только в двух случаях, если поиск закончился «удачей», либо «неудачей».
Для того, чтобы понять то, как именно работает данный алгоритм поиска данных, необходимо рассмотреть следующую блок схему:

Рис. 23. Блок схема алгоритма поиска делением пополам
По данной блок схеме видно, что работа алгоритма происходит только в уже упорядоченном массиве, и в данном массиве используется условие First < Last. Для того, чтобы найти искомое значение, алгоритм делит массив на две части. В том случае, если индекс Pos окажется равным первому элементу, то переменная отобразит ложное значение, и, следовательно, искомого значения не окажется в массиве. Ну, а если индекс Pos окажется равным (или меньше) последнего значения, то поиска делением пополам закончится «успешно».[3]
На рисунке 24 рассмотрим листинг программы алгоритм поиска делением пополам:

Рис. 24. Листинг программы
Рассматриваемый алгоритм поиска делением пополам очень быстр в своей работе, но имеет также недостаток – он работает, как уже было сказано только в упорядоченном массиве.
3.3. Прямой поиск строки
Еще один алгоритм поиска данных – это алгоритм прямого поиска строки. Алгоритм прямого поиска строки работает таким образом: поэтапно сравнивает первый символ искомого слова с первым и последующими символами слов, которые имеются в изучаемом тексте. В случае, если при сравнении первого символа искомого слова со вторым символом слова в тексте, совпадение не было зарегистрировано программой, то в этой ситуации, она производит сдвиг слова в тексте, и начинает сравнивать искомое слово со вторым словом в тексте. И это сравнение происходит до тех пор, пока совпадение не будет равно 100%, то есть слово будет найдено, либо поиск окончиться неудачей, то есть слово не найдено в искомом тексте.[10]
На рисунке 25 можно увидеть, как именно производит свою работу алгоритм прямого поиска строки:

Рис. 25. Поиск прямой строки
На рисунке видно, то происходит поиск слова «abaa» в тексте Т, и для того, чтобы программа зафиксировала совпадение, алгоритму необходимо было три раза произвести сдвиг слова.
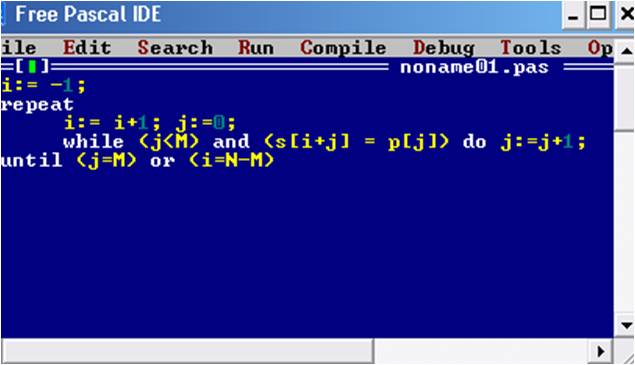
Рис. 26. Листинг алгоритма поиска прямой строки
Чем меньше алгоритму необходимо будет производить сдвиг слова, тем быстрее будет работать сам алгоритм.
3.4 Алгоритм Кнута, Мориса, Пратта
Рассматриваемый алгоритм поиска данных был разработан в 1970 году группой ученых Дональдом Кнутом, Морисом Д. и Пратт В. Второе название этого алгоритма КМП-алгоритм. Этот алгоритм работает следующим образом: алгоритм производит сравнение основной части искомого слова со словами в тексте, и при фиксировании совпадения нескольких символов, программа самостоятельно выполнит все необходимые сдвиги в тексте и сама найдет все оставшиеся символы в тексте. Следовательно, слово будет найдено, но если совпадений не будет обнаружено, то, значит, искомого слова в тексте не имеется.
Данный алгоритм работает лучше, чем прямой поиск строки, так как сдвиг в таком алгоритме происходит не на один символ, а сразу не насколько, следовательно, время работы алгоритма также уменьшается, то есть он работает очень быстро.[21]
На рисунке 27 показан пример работы КМП-алгоритма:

Рис.27. КМП-алгоритм
Также, для лучшего понятия КМП-алгоритма необходимо рассмотреть листинг алгоритма:
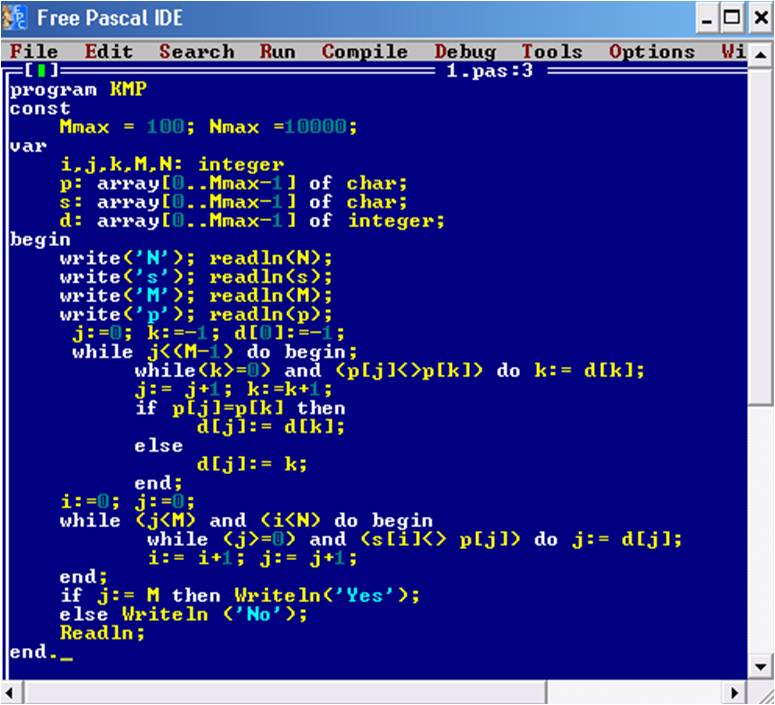
Рис. 28. Листинг алгоритма Кнута, Мориса, Пратта
Также, один существенный плюс данного алгоритма таков, что работа алгоритма будет успешна даже в том случае, если перед несовпадением символов текста, будет зафиксировано несколько совпадений. То есть, в случае, если в тексте будет некоторая орфографическая ошибка, искомое слово все равно было найдено.
3.5 Алгоритм Боуера-Мура
Алгоритм Боуера-Мура был разработан в 1975 году, в качестве улучшенного варианта КМП-алгоритма.
Представим, как работает алгоритм. В рассматриваемом алгоритме поиск происходит с конца слова. Для этого образно разобьем слово на составляющие. Допустим, что z из алфавита величина Rz – это расстояние от самого правого в слове вхождения z до правого конца слова. При прохождении текста алгоритм зафиксировал расхождение между искомым словом и текстом, которое равно z. И в данном случае, для того, чтобы символ искомого слова совпал с символом z в исследуемом тексте, алгоритм производит сдвиг символа до тех пор, пока они не совпадут.
Для того, чтобы лучше понять как именно работает данный алгоритм необходимо рассмотреть следующий рисунок:

Рис. 29. Алгоритм Боуера-Мура
Преимущество данного алгоритма заключается в том, что он эффективен даже в таких текстах, которые не были подвергнуты предварительной сортировке.
На рисунке 30 показан листинг программы алгоритма Боуера-Мура:
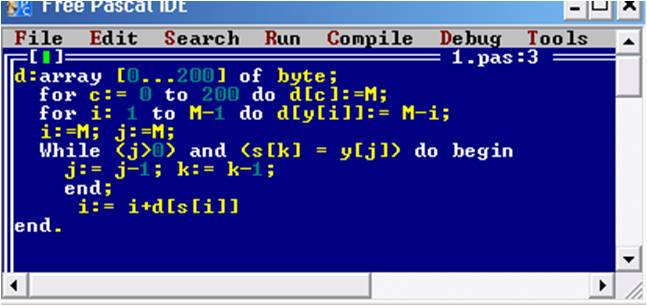
Рис. 30. Листинг алгоритма Боуера-Мура
Данная глава курсовой работы была посвящена алгоритмам поиска данных. Все они работают по-разному, но нацелены на нахождение искомого элемента в некотором массиве. Для того чтобы, понять какой из рассмотренных алгоритмов лучший необходимо рассмотреть следующую таблицу:
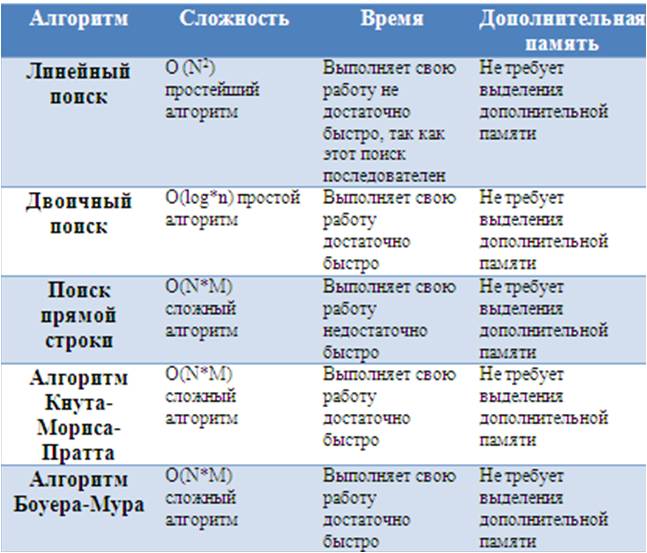
Следовательно, выбор остается только за пользователем, так как выбор алгоритмов у него очень обширен.
Заключение
Итак, мир информационных технологий не стоит на месте, а находится в постоянном развитии. Основная задача информационных технологий – как можно более эффективно и быстро работать с огромным количеством информации. Но для того чтобы с ней эффективно работать, информацию необходимо структурировать, то есть сортировать. В данной курсовой работе было рассмотрено понятие «сортировки данных», а также изучены наиболее популярные алгоритмы сортировки данных. Сортировка данных отвечает за удобное распределение данных в неком массиве или файле, для того, чтобы в конечном итоге, обеспечить быстрый поиск данных. Также в данной курсовой работе особое внимание было уделено алгоритмам поиска данных, которые также отвечают за быстрое нахождение пользователями всей интересующей их информации.
В данной курсовой работе все пример алгоритмов были рассмотрены на основе языка программирования Паскаль. Этот язык программирования высокого уровня очень легок в использовании, имеет удобный алфавит, с которым может справиться, любой, даже неопытный пользователь. Следовательно, этот язык очень хорош для обучения молодых начинающих программистов. Этот язык программирования был рассмотрен в первой главе курсовой работы, были изучены его преимущества, алфавит, зарезервированные слова, знаки пунктуации и многое другое. Также, в первой главе курсовой работы было уделено внимание термину «Алгоритмы», рассмотрены способы их представления, уделено внимание сложности работы алгоритма.
Во второй главе данной курсовой работы особое внимание было уделено алгоритмам сортировки – внутренней и внешней. Как было выяснено алгоритмов сортировок очень много, и перед каждым пользователь предоставлен широкий их выбор. В данной курсовой работе внимание было уделено таким алгоритмам внутренней сортировки, как сортировка обменом, выбором, методом Шелла, Хоара, вставкой. Все эти алгоритма работают по-разному, какие-то быстрее, какие-то медленнее, например, алгоритм сортировки обменом, работает очень медленно, но при своей работе он не требует выделения дополнительной памяти ЭВМ. Сортировка выбором и включением, работают быстро, но только в массивах с малым количеством элементов. На смену этим простым методам пришли более усовершенствованные алгоритмы сортировок, такие как сортировки методом Шелла и Хоара. Сортировка методом Шелла очень сложна в использовании, но очень эффективна. Скорость работы данного алгоритма, также мала. Наиболее оптимальным алгоритмом, на сегодняшний день, является сортировка методом Хоара, которая и работает очень быстро, легка в использовании.
Также, были рассмотрены алгоритмы внешней сортировки, такие как сортировка простым и естественным слиянием. Алгоритм сортировки простым слиянием очень прост в использовании, но для своей работы требует выделения дополнительной памяти. Ему на смену пришел более усовершенствованный алгоритм естественным слиянием, который работает очень быстро.
Алгоритмов поиска данных, также как и сортировок существует очень много. В данной курсовой работе были рассмотрены следующие алгоритмы: линейный поиска, поиск делением пополам, прямой поиск строки, КМП-алгоритм, алгоритм Боуера-Мура. Линейный поиск – это простейший алгоритм поиска данных, и работает он очень медленно. Ему на смену пришел алгоритм поиска делением пополам, который работает очень быстро, но только в упорядоченном массиве. Для того, чтобы решить все эти недочеты первых двух алгоритмов были разработаны КМП-алгоритм, Алгоритма Боуера-Мура, прямой поиск строки, которые работают очень эффективно.
Итак, по проделанной работе можно сделать следующий вывод – алгоритмов сортировки и поиска существует огромное количество, и все они работают по-разному. Сказать, какой алгоритм самый лучший невозможно, так как работа алгоритма зависит от тех условий, которые задает сам пользователь, и только он сам может сделать выбор в пользу того, или иного алгоритма.
Список использованной литературы
- Алексеев В.Е., Таланов В.А. Графы. Модели вычислений. Структуры данных: Учебник. – Нижний Новгород: Изд-во ННГУ, 2005. - 307 с.
- Ахо А., Хопкрофт Д., Ульман Д. Структуры данных и алгоритмы. – М.: Изд. дом “Вильямс”, 2001 г.- 384 с.
- Ахо А. В., Хопкрофт Д. Э., Ульман Д. Д. Построение и анализ вычислительных алгоритмов: Пер.с англ. – М.: Мир, 1979. 312 с.
- Вирт Н. Алгоритмы и структуры данных. М.: Мир, 1989. – 31 с.
- Вирт Н. Алгоритмы и структуры данных.- СПб.: Невский диалект, 2001. - 352 с.
- Голицына O.Л., Попов И.И. Основы алгоритмизации и программирования: учеб. Пособие - М: ФОРУМ, 2008 – с.16.
- Давыдов В.Г. Программирование и основы алгоритмизации: Учеб. пособие / - 2-е изд., стер. - М.: Высш. шк., 2005. - 447 с.
- Ивановский С.А. Структуры и алгоритмы обработки данных. Рабочая программа дисциплины. - СПб.: СПбГЭТУ, каф. МО ЭВМ, 2000. - с.79-94.
- Ключарев А.А., Матьяш В.А., Щекин С.В. Структуры и алгоритмы обработки данных: Учебное пособие - СПбГУАП. СПб,2003 – с. 172.
- Кищенко О.Н. Языки информационного обмена: материалы курса. - Новосибирск: НГТУ, 2007. – с.102.
- Кнут Д. Искусство программирования. Том 3: Поиск и сортировка. М.: “Вильямс”, 2000 – 240 c.
- Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы. Построение и анализ. М.: МЦНМО, 2000- 132 с.
- Лорин Г. Сортировка и системы сортировки. — М.: Изд-во Наука, Главная редакция физ.-мат. литературы, 1983 – с.16
- Окулов С.М. Основы программирования. “Информатика”, №23, 2001 – 112 c.
- Окулов С.M. Сортировка и поиск. “Информатика”, №33, 35, 2000 – 400 c.
- Ставровский А.Б, Карнаух Т.А. Самоучитель. Первые шаги в программировании. М.: Изд. дом “Вильямс”, 2006 – с 230.
- Царев Р.Ю. Учебное пособие по курсу «Структуры и алгоритмы обработки данных» - Красноярск: ИПЦ КГТУ, 2005. – с.30
- Кузнецов С.Д., ИСП РАН, Центр Инф. Технологий [Электронный ресурс] - URL: http://citforum.ru/programming/theory/sorting/sorting1.shtml (дата обращения 10.07.2013г.)
- Томас Ниман. Сортировка и поиск. Рецептурный справочник [Электронный ресурс] - URL: http://cs.mipt.ru/docs/comp/rus/programming/algorithms/niman_sort_poisk/main.pdf (дата обращения 12.07.2013г.)
- Учебный курс «Введение в программирование». Лабораторная работа №1: Упорядочивание (сортировка) массивов. [Электронный ресурс] - URL: http://infoscool.narod.ru/Lab1_sort.pdf (дата обращения 15.07.2013)
21. Сундукова Т.О., Ваныкина Г.В. Структура и алгоритмы компьютерной обработки данных. - 2010 [Электронный ресурс] - URL: http://www.intuit.ru/department/algorithms/staldata/38/2.html (дата обращения: 16.08.2013г.)

- Понятие проекта и проектного управления
- Классификация Internet Security Systems
- Разновидности планшетов
- Перевод научно-технического текста
- ФРАЗЕОЛОГИЗМЫ И ИХ ВИДЫ
- Управление поведением в конфликтных ситуациях (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ОРГАНИЗАЦИОННЫХ КОНФЛИКТОВ)
- Понятие, виды, принципы и функции социальной защиты в РФ
- Особенности общения в дошкольном возрасте
- Бухгалтерский баланс на 31 декабря 2016 года ООО Интеллект.
- Сущность договора, его заключение, изменение и расторжение
- Типы кадровой стратегии организации
- Прибыль как показатель эффективности хозяйственной деятельности и источник приращения капитала организации.