
Реализация механизма многозадачности в многоядерных процессорах

Первые разработки в области создания многопроцессорных систем начались в 70-х годах. Длительное время производительность привычных одноядерных процессоров повышалась за счёт увеличения тактовой частоты (до 80% производительности определяла только тактовая частота) с одновременным увеличением числа транзисторов на кристалле. Фундаментальные законы физики остановили этот процесс: чипы стали перегреваться, технологический стал приближаться к размерам атомов кремния. Все эти факторы привели к тому, что:
- увеличились токи утечки, вследствие чего повысилось тепловыделение и потребляемая мощность.
- процессор стал намного «быстрее» памяти. Производительность снижалась из-за задержки обращения к оперативной памяти и загрузке данных в кэш.
- возникает такое понятие как «фон-нейманское узкое место». Оно означает неэффективность архитектуры процессора при выполнении какой-либо программы.
Многопроцессорные системы (как один из способов решения проблемы) не получили широко применения, так как требовали дорогостоящих и сложных в производстве многопроцессорных материнских плат. Исходя из этого, производительность повышалась иными путями. Эффективной оказалась концепция многопоточности – одновременная обработка нескольких потоков команд.
Hyper-Threading Technology (HTT) или технология сверхпоточной обработки данных, позволяющая процессору на одном ядре выполнять несколько программных потоков. Именно HTT по мнению многих специалистов стала предпосылкой для создания многоядерных процессоров. Выполнение процессором одновременно несколько программных потоков называется параллелизмом на уровне потоков (TLP –thread-level parallelism).
Для раскрытия потенциала многоядерного процессора исполняемая программа должна задействовать все вычислительные ядра, что не всегда достижимо. Старые последовательные программы, способные использовать лишь одно ядро, теперь уже не будут работать быстрее на новом поколении процессоров, поэтому в разработке новых микропроцессоров всё большее участие принимают программисты.
Последовательное программирование
Последовательное программирование ― проблема не столько самих потоков, сколько способа их использования приложением. Логическое понятие процесса ОС появилось на заре вычислительной техники для последовательного выполнения инструкций. Но мышление последовательного программирования по-прежнему сохраняется, даже несмотря на то, что с тех пор сложность некоторых процессов многократно увеличилась. По мере увеличения сложности возникли разные уровни системы (внутренний, промежуточный, внешний). Но в пределах одного уровня приложения все так же выполняются в последовательном порядке, с одним потоком, на который нанизана вся логика разнообразных компонентов.
Интегрирование функций
Интегрирование – это восстановление функции по её производной (обратное действие по отношению к дифференцированию).
Джилварри подчеркнул, что многоядерные процессоры в сочетании с технологией виртуализации дают возможность создать архитектуру на одной платформе, которая может интегрировать функции, встречающиеся в разных управляющих устройствах, таких, как программируемые контроллеры и логические PLC, контроллеры автоматики приводов, а также интерфейсы «человек-машина» (HMI). –Многоядерные процессоры компании Intel могут использоваться для консолидации на одной плате разнообразных функций, включающих предохранения, управление, визуализацию, а также безопасность сети. Кроме того, обычно такая консолидация может достигаться при минимальных изменениях программного обеспечения –заявил он.
− Среди многих применений многоядерные процессоры идеальны для введения автоматики привода и логической системы машины в одном процессоре − объяснил Джилварри. Это контрастирует с долго сохранявшимся убеждением производителей и поставщиков машин, что лучше всего решать эти машинные проблемы раздельно– будь то исполнение (1) с одним контроллером для каждой оси движения,обслуживающим также часть логической системы машины, (2) центральным программируемым логическим контроллером PLC с контроллером движения для каждой оси или (3) центральным программируемым логическим контроллером PLCдля логической системы и центральным контроллером движения для всех осей машины.
Такие решения имеют недостаткм, такие, как сложность синхронизации, наличие многих программ для удержания курса, разработка программ/устранение недочетов или в последнем случае, две программы с высокими требованиями в отношении коммуникации.
– В случае всех этих решений возможности логической системы ограничивают показатели машины. Также сложная коммуникация между логической системой и системой движения ограничивают гибкость машины и требуют огромных усилий для проведения тонкой диагностики, – констатировал Джилварри. – Это случаи, в которых многоядерная технология позволяет исключить программируемые логические контроллеры PLC, а также интегрировать системы движения,логическую систему и другие функциональные системы в одну систему управления.
Предложение многоядерных процессоров компании Intel включает две модели из новейшего семейства процессоров Atom, а также процессор Core 2 Duo (каждый с двумя ядрами); процессор Core 2 Quad с четырьмя ядрами и некоторые процессоры поколения Core i7 с шестью ядрами.
Высокопроизводительные вычисления. Параллелизм
Создание высокопроизводительных вычислительных систем – одна из самых сложных научно-технических задач. При том, что скорость вычислений технических средств выросла всего лишь в несколько миллионов раз, общая скорость вычислений выросла в триллионы раз. Этот эффект достигнут за счёт применения параллелизма на всех стадиях вычислений. Параллельные вычисления требуют поиска рационального распределения памяти, надёжных способов передачи информации и координации вычислительных процессов.
одна критическая проблема параллелизма на основе потоков заключается в усилиях по синхронизации ввиду изменчивости объектов, совместно используемых несколькими потоками
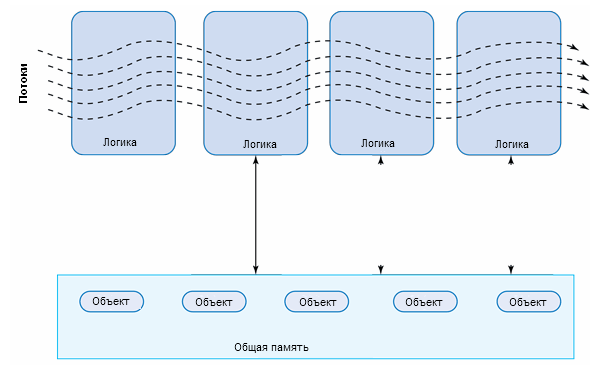
Симметрическая мультипроцессорность
Symmetric Multiprocessing (сокращённо SMP) или симметрическое мультипроцессирование – это особая архитектура мультипроцессорных систем, в которой несколько процессоров имеют доступ к общей памяти. Это очень распространённая архитектура, достаточно широко используемая в последнее время.
При применении SMP в компьютере работает сразу несколько процессоров, каждый над своей задачей. SMP система при качественной операционной системе рационально распределяет задачи между процессорами, обеспечивая равномерную нагрузку на каждый из них. Однако возникает проблема к обращению памяти, ведь даже однопроцессорным системам требуется на это относительно большое время. Таким образом, обращение к оперативной памяти в SMP происходит последовательно: сначала один процессор, затем второй.
В силу перечисленных выше особенностей, SMP-системы применяется исключительно в научной сфере, промышленности, бизнесе, крайне редко в рабочих офисах. Кроме высокой стоимости аппаратной реализации, такие системы нуждаются в очень дорогом и качественном программном обеспечении, обеспечивающем многопоточное выполнение задач. Обычные программы (игры, текстовые редакторы) не будут эффективно работать в SMP-системах, так как в них не предусмотрена такая степень распараллеливания. Если адаптировать какую-либо программу для SMP-системы, то она станет крайне неэффективно работать на однопроцессорных системах, что приводит к необходимости создание нескольких версий одной и той же программы для разных систем. Исключение составляет, например, программа ABLETON LIVE (предназначена для создания музыки и подготовка Dj-сетов), имеющая поддержку мультипроцессорных систем. Если запустить обычную программу на мультипроцессорной системе, она всё же станет работать немного быстрее, чем в однопроцессорной. Это связано с так называемым аппаратным прерыванием (остановка программы для обработки ядром), которое выполняется на другом свободном процессоре.
 SMP-система (как и любая другая, основанная на параллельных вычислениях) предъявляет повышенные требования к такому параметру памяти, как полоса пропускания шины памяти. Это зачастую ограничивает количество процессоров в системе (современные SMP- системы эффективно работают вплоть до 16 процессоров).
SMP-система (как и любая другая, основанная на параллельных вычислениях) предъявляет повышенные требования к такому параметру памяти, как полоса пропускания шины памяти. Это зачастую ограничивает количество процессоров в системе (современные SMP- системы эффективно работают вплоть до 16 процессоров).
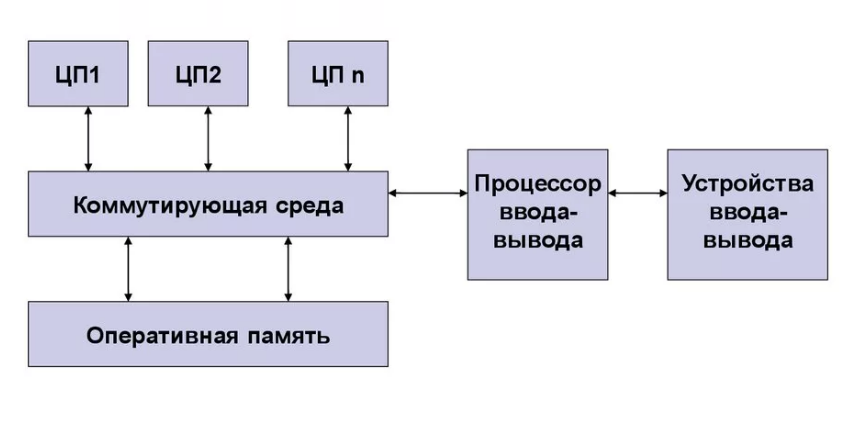
Так как у процессоров общая память, то возникает необходимость рационального её использования и согласования данных. В мультипроцессорной системе получается так, что несколько кэшей работают для разделяемого ресурса памяти. Сache coherence (когерентность кэша) – свойство кэша, обеспечивающее целостность данных, хранящихся в индивидуальных кэшах для разделяемого ресурса. Данное понятие – частный случай понятия когерентности памяти, где несколько ядер имеют доступ к общей памяти (повсеместно встречается в современных многоядерных системах)[4]. Если описать данные понятия в общих чертах, то картина будет следующей: один и тот же блок данных может быть загружен в разные кэши, где данные обрабатываются по-разному.
Если не будут использованы какие-либо уведомления об изменении данных, то возникнет ошибка. Когерентность кэша призвана для разрешения таких конфликтов и поддержки соответствия данных в кэшах.
SMP-системы являются подгруппой MIMD (multi in-struction multi data - вычислительная система со множественным потоком команд и множественным потоком данных) классификации вычислительных систем по Флинну (профессор Стэнфордского университета, сооснователь Palyn Associates). Согласно данной классификации, практически все разновидности параллельных систем можно отнести к MIMD.
Разделение многопроцессорных систем на типы происходит на основе разделения по принципу использования памяти. Этот подход позволил различить следующие важные типы
многопроцессорных систем – multiprocessors (мультипроцессорные системы с общей разделяемой памятью) и multicomputers (системы с раздельной памятью). Общие данные, используемы при параллельных вычислениях требуют синхронизации. Задача синхронизация данных – одна из самых важных проблем, и её решение при разработке многопроцессорных и многоядерных и, соответственно, необходимого программного обеспечения является приоритетной задачей инженеров и программистов. Общий доступ к данным может быть произведён при физическом распределении памяти. Этот подход называется неоднородным доступом к памяти (non-uniform memory access или NUMA).
Среди данных систем можно выделить:
- Системы, где только индивидуальная кэш-память процессоров используется для представления данных (cache-only memory architecture).
- Системы с обеспечением когерентности локальных кэшей для различных процессоров (cache-coherent NUMA).
- Системы с обеспечением общего доступа к индивидуальной памяти процессоров без реализации на аппаратном уровне когерентности кэша (non-cache coherent NUMA).
Упрощение проблемы создания мультипроцессорных систем достигается использованием распределённой общей памяти (distributed shared memory), однако этот способ приводит к ощутимому повышению сложности параллельного программирования.
Одновременная многопоточность
Исходя из всех вышеперечисленных недостатков симметрической мультипроцессорности, имеет смысл разработка и развитие других способов повышения производительности. Если проанализировать работу каждого отдельного транзистора в процессоре, можно обратить внимание на очень интересный факт – при выполнении большинства вычислительных операций задействуются далеко не все компоненты процессора (согласно последним исследованиям – около 30% всех транзисторов). Таким образом, если процессор выполняет, скажем, несложную арифметическую операцию, то большая часть процессора простаивает, следовательно, её можно использовать для других вычислений. Так, если в данный момент процессор выполняет вещественные операции, то в свободную часть можно загрузить целочисленную арифметическую операцию. Чтобы увеличить нагрузку на процессор, можно создать спекулятивное (или опережающее) выполнение операций, что требует большого усложнения аппаратной логики процессора. Если в программе заранее определить потоки (последовательности команд), которые могут выполняться независимо друг от друга, то это заметно упростит задачу (данный способ легко реализуется на аппаратном уровне). Эта идея, принадлежащая Дину Тулсену (разработана им в 1955 г в университете Вашингтона), получила название одновременной многопоточности (simul-taneous multithreading). Позднее она была развита компанией Intel под названием гиперпоточности (hyper threading). Так, один процессор, выполняющий множество потоков, воспринимается операционной системой Windows как несколько процессоров. Использование данной технологии опять-таки требует соответствующего уровня программного обеспечения. Максимальный эффект от применения технологии многопоточности составляет около 30%.
Hyper-threading
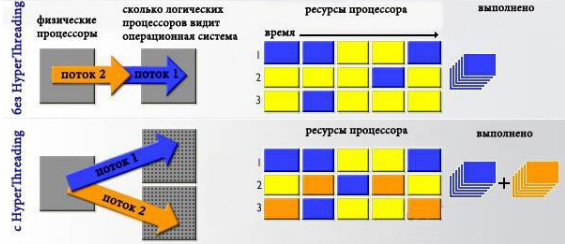
Ядра в многоядерных процессорах могут поддерживать технологию SMT, позволяющую исполнять несколько потоков вычислений и создавать на основе каждого ядра несколько логических процессоров. На процессорах, которые выпускает компания Intel, такая технология называется «Hyper-threading». Благодаря ей можно удваивать число логических процессоров по сравнению с числом физических чипов. В микропроцессорах, поддерживающих эту технологию, каждый физический процессор способен сохранять состояние двух потоков одновременно. Для операционной системы это будет выглядеть, как наличие двух логических процессоров. Если в работе одного из них возникает пауза (например, он ждет получения данных из памяти), другой логический процессор приступает к выполнению собственного потока.
Принцип работы
Большинство современных многоядерных процессоров работает по следующей схеме. Если запущенное приложение поддерживает многопоточность, оно может заставлять процессор выполнять несколько заданий одновременно. Например, если в компьютере используется 4-ядерный процессор с тактовой частотой 1.8 ГГц, программа может «загрузить» работой сразу все четыре ядра, при этом суммарная частота процессора будет составлять 7.2 ГГц. Если запущено сразу несколько программ, каждая из них может использовать часть ядер процессора, что тоже приводит к росту производительности компьютера.
Многие операционные системы поддерживают многопоточность, поэтому использование многоядерных процессоров позволяет ускорить работу компьютера даже в случае приложений, которые многопоточность не поддерживают. Если рассматривать работу только одного приложения, то использование многоядерных процессоров будет оправданным лишь в том случае, если это приложение оптимизировано под многопоточность. В противном случае, скорость работы многоядерного процессора не будет отличаться от скорости работы обычного процессора, а иногда он будет работать даже медленнее.
Многоядерность
Технология многопоточности – реализация многоядерности на программном уровне. Дальнейшее увеличение производительности, как всегда, требует изменений в аппаратной части процессора. Усложнение систем и архитектур не всегда оказывается действенным. Существует обратное мнение: «всё гениальное – просто!». Действительно, чтобы повысить производительность процессора вовсе необязательно повышать его тактовую частоту, усложнять логическую и аппаратную составляющие, так как достаточно лишь провести рационализацию и доработку существующей технологии. Такой способ весьма выгоден – не нужно решать проблему повышения тепловыделения процессора, разработку нового дорогостоящего оборудования для производства микросхем. Данный подход и был реализован в рамках технологии многоядерности – реализация на одном кристалле нескольких вычислительных ядер. Если взять исходный процессор и сравнить прирост производительности при реализации нескольких способов повышения производительности, то очевидно, что применение технологии многоядерности является оптимальным вариантом.
Если сравнивать архитектуры симметричного мультипроцессора и многоядерного, то они окажутся практически идентичными. Кэш-память ядер может быть многоуровневой (локальной и общей, причём данные из оперативной памяти могут загружаться в кэш-память второго уровня напрямую). Исходя из рассмотренных достоинств многоядерной архитектуры процессоров, производители делают акцент именно на ней. Данная технология оказалась достаточно дешёвой в реализации и универсальной, что позволило вывести её на широкий рынок. Кроме того, данная архитектура внесла свои коррективы в закон Мура: «количество вычислительных ядер в процессоре будет удваиваться каждые 18 месяцев».
Если посмотреть на современный рынок компьютерной техники, то можно увидеть, что доминируют устройства с четырёх- и восьми- ядерными процессорами. Кроме того, производители процессоров заявляют, что в скором времени на рынке можно будет увидеть процессоры с сотнями вычислительных ядер. Как уже неоднократно говорилось ранее, весь потенциал многоядерной архитектуры раскрывается только при наличии качественного программного обеспечения. Таким образом, сфера производства компьютерного «железа» и программного обеспечения очень тесно связаны между собой.
Увеличение производительности за счёт многоядерности
Принцип увеличения производительности процессора за счёт нескольких ядер, заключается в разбиении выполнения потоков (различных задач) на несколько ядер. Обобщая, можно сказать, что практически каждый процесс, запущенный у вас в системе, имеет несколько потоков.

Например, антивирусная программа. Один поток у нас будет сканирование компьютера, другой – обновление антивирусной базы .
Вывод
Многопоточность ― отличный способ, для использования ресурсов центрального процессора. Разработчики приложений и OС распространяют многопоточность на параллелизм уровня приложения. Разработчики начали пользоваться программированием на основе потоков для последовательного выполнения логики в написании программ.
Для высокопроизводительных приложений, требуется параллелизм, в котором логика разбивается на отдельные части работы.
SMP система - архитектура многопроцессорных компьютеров, в которой два или более одинаковых процессора подключаются единообразно к общей памяти и выполняют одни и те же функции. Каждый процессор работает над своей задачей.
Hyper-threading – реализует идею одновременной мультипоточности.
одно физическое ядро определяется операционной системой как два отдельных логических ядра.
Преимуществами Hyper-threading считаются:
- возможность запуска нескольких потоков одновременно (многопоточный код);
- уменьшение времени отклика;
- увеличение числа пользователей, обслуживаемых сервером.
Источники:
- https://www.ibm.com/developerworks/ru/library/j-nothreads/
- https://studfiles.net/preview/2715079/
- https://studfiles.net/preview/2715079/
- https://yandex.ru/images/
- https://www.kakprosto.ru/kak-901137-mnogoyadernye-processory-principy-raboty-
- https://www.syl.ru/article/330403/tehnologiya-hyper-threading---chto-eto-takoe-kak-vklyuchit-i-ispolzovat

- Was Julia happy in marriage? How did her relationships with Michael change in course of time?
- Вклад Дугласа Мак-Грегора в теорию и практику менеджмента
- Корпоративные информационные ресурсы
- Противодействие актам саботажа со стороны сотрудников организации
- Инвестиции
- Покупательская ценность участников рынка
- Правовое положение иностранцев и лиц без гражданства
- Что такое электронная подпись?
- Нужен ли IT Менеджмент на современном предприятии
- Основные направления защиты предпринимательства
- Недобросовестная конкуренция и право предпринимателя на защиту
- Понятие и предмет международного частного права