
Модели представления знаний семантические сети

В настоящее время применяются семь классов моделей знаний : логические, продукционные, фреймовые, сетевые, объектно-ориентированные, специальные и комплексные.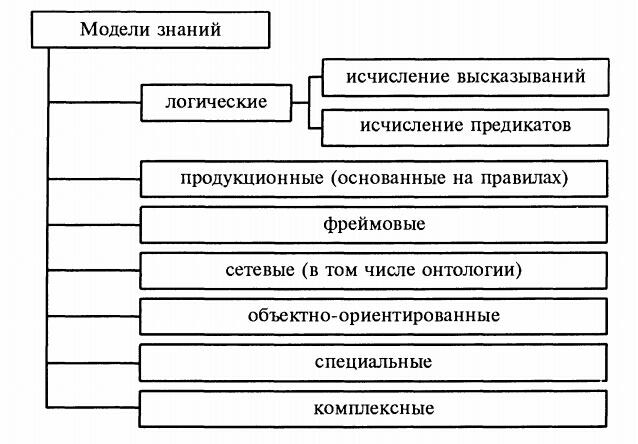 .
.
Наиболее общий способ представления знаний, при котором предметная область рассматривается как совокупность объектов и связывающих их отношений, реализован в сетевой модели знаний. В качестве носителя знаний в этой модели выступает семантическая сеть, вершины которой соответствуют объектам (понятиям), а дуги — отношениям между понятиями. Кроме того, и вершинам, и дугам присваиваются имена (идентификаторы) и описания, характеризующие семантику объектов и отношений предметной области. Типизация семантических сетей обусловливается смысловым содержанием образующих их отношений. Например, если дуги сети выражают родовидовые отношения, то такая сеть определяет классификацию объектов предметной области. Аналогично, наличие в сети причинно-следственных (каузальных) отношений позволяет интерпретировать ее как сценарий. Построение сети на ассоциативных отношениях формирует ассоциативную структуру понятий рассматриваемого фрагмента предметной области. Вообще при практическом использовании семантических сетей для представления знаний решающее значение имеют унификация типов объектов и выделение базовых видов отношений между ними Учет особенностей объектов и отношений, заданных их типами, обеспечивает возможность применения тех или иных классов выводов на сети. Поскольку фактически сетевая модель объединяет множество методов представления предметной области с помощью сетей, сопоставление данной модели с прочими способами представления знаний затруднительно. Очевидные достоинства сетевой модели заключаются в ее высокой общности, наглядности отображения системы знаний о предметной области, а также легкости понимания подобного представления. В то же время в семантической сети имеет место смешение групп знаний, относящихся к совершенно различным ситуациям при назначении дуг между вершинами, что усложняет интерпретацию знаний.
Другая проблема, присущая сетевой модели, состоит в трудности унификации процедур вывода и механизмов управления выводами на сети. Перспективным направлением повышения эффективности сетевого представления, развиваемым в настоящее время, является использование онтологии и параллельных выводов на семантических сетях [1].
Классификация семантических сетей
Для всех семантических сетей справедливо разделение по арности и количеству типов отношений.
По количеству типов отношений, сети могут быть однородными и неоднородными. Однородные сети обладают только одним типом отношений (стрелок), например, таковой является классификация биологических видов. В неоднородных сетях количество типов отношений больше двух. Классические иллюстрации данной модели представления знаний представляют именно такие сети. Неоднородные сети представляют больший интерес для практических целей, но и большую сложность для исследования.
По арности, типичными являются сети с бинарными отношениями (связывающими ровно два понятия). Бинарные отношения очень просты и удобно изображаются на графе в виде стрелки между двух концептов. Кроме того, они играют исключительную роль в математике. На практике, однако, могут понадобиться отношения, связывающие более двух объектов — N-арные. При этом возникает сложность — как изобразить подобную связь на графе, чтобы не запутаться. Концептуальные графы снимают это затруднение, представляя каждое отношение в виде отдельного узла. Помимо концептуальных графов существуют и другие модификации семантических сетей, это является ещё одной основой для классификации (по реализации).
Семантические отношения
Количество типов отношений в семантической сети определяется её создателем, исходя из конкретных целей. В реальном мире их число стремится к бесконечности. Каждое отношение является, по сути, предикатом, простым или составным. Скорость работы с базой знаний зависит от того, насколько эффективно реализованы программы обработки нужных отношений.
Иерархические
Наиболее часто возникает потребность в описании отношений между элементами, множествами и частями объектов. Отношение между объектом и множеством, обозначающим, что объект принадлежит этому множеству, называется отношением классификации (ISA). Говорят, что множество (класс) классифицирует свои экземпляры. Название произошло от английского «IS A» (наиболее точный русский перевод, используемый в основном в научных кругах — «суть», например, «все зайцы суть млекопитающие»). Иногда это отношение именуют также MemberOf, InstanceOf или подобным образом. Связь ISA предполагает, что свойства объекта наследуются от множества. Обратное к ISA отношение используется для обозначения примеров, поэтому так и называется — «Example», или по-русски, «Например».
Отношение между надмножеством и подмножеством называется AKO — «A Kind Of» («разновидность»). Элемент подмножества называется гипонимом, а надмножества — гиперонимом, а само отношение называется отношением гипонимии. Альтернативные названия — «SubsetOf» и «Подмножество». Это отношение определяет, что каждый элемент первого множества входит и во второе (выполняется ISA для каждого элемента), а также логическую связь между самими подмножествами: что первое не больше второго и свойства первого множества наследуются вторым.
Объект, как правило, состоит из нескольких частей, или элементов. Например, компьютер состоит из системного блока, монитора, клавиатуры, мыши и т. д. Важным отношением является HasPart, описывающее части/целые объекты (отношение меронимии). Мероним — это объект, являющийся частью для другого. Двигатель — это мероним для автомобиля. Холоним — это объект, который включает в себя другое. Например, у дома есть крыша. Дом — холоним для крыши. Компьютер — холоним для монитора. Мероним и холоним — противоположные понятия.
Часто в семантических сетях требуется определить отношения синонимии и антонимии. Эти связи либо дублируются явно в самой сети, либо в алгоритмической составляющей.
Вспомогательные
В семантических сетях часто используются также следующие отношения (Гаврилова):
функциональные связи (определяемые обычно глаголами «производит», «влияет»…);
количественные (больше меньше, равно…);
пространственные (далеко от, близко от, за, под, над…);
временные (раньше, позже, в течение…);
атрибутивные (иметь свойство, иметь значение);
логические (И, ИЛИ, НЕ);
лингвистические.
Этот список может сколь угодно продолжаться: в реальном мире количество отношений огромно. Например, между понятиями может использоваться отношение «совершенно разные вещи» или подобное: Не_имеют_отношения_друг_к_другу(Солнце, Кухонный_чайник) [4].
Практическое применение семантических сетей.
Существующая сеть WWW представляет собой гигантское количество информации в формате, приспособленном для человеческого восприятия. Пользователь может перескакивать с одной ссылки на другую, давать запросы различным поисковым системам или же находить сайты, просто вводя их адреса. И хотя веб-страницы весьма привлекательны для человека, для компьютерной программы же, обрабатывающей их содержимое, они не более чем строчки из случайных символов.
Компьютерная программа не способна, загрузив произвольный документ, будь то веб-страница или какой-то файл, понять его содержание. Она может сделать некие догадки, основываясь на HTML- или XML-тэгах, но всё равно требуется человек-программист, который должен разобраться в них и понять смысл, или семантику, каждого из тэгов. С точки зрения компьютера, существующая Сеть WWW — это полная неразбериха. К счастью, выход есть: это семантическая сеть.
Как представлял себе Тим Бернерс-Ли, семантическая сеть должна стать неким дополнением сети WWW, состоящим из понятной машинам информации. Реализация этой новой Сети станет возможна благодаря ряду новых стандартов, разрабатываемых WWW-Консорциумом (W3C). Когда семантическая сеть наберёт обороты, значительное число информационных ресурсов будут пригодными для использования как человеком, так и программными агентами. Другими словами, программные агенты наконец-то научаться читать Интернет.
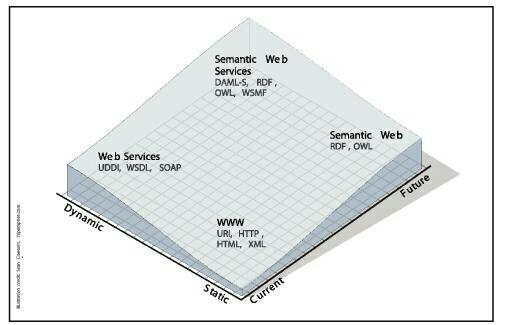 Подобно тому, как семантическая сеть является расширением обычной сети WWW, семантические веб-сервисы (SW-сервисы или SWS) расширяют понятие обычных веб-сервисов
Подобно тому, как семантическая сеть является расширением обычной сети WWW, семантические веб-сервисы (SW-сервисы или SWS) расширяют понятие обычных веб-сервисов
В настоящее время создаются программы, способные искать нужные им порты и регистры, такие как UDDI-сервер, который является перечнем доступных веб-сервисов. И хотя программа может найти некий веб-сервис без помощи человека, она не в состоянии понять, как именно им пользоваться и даже просто для чего он предназначен. Язык описания веб-сервисов (WSDL) даёт нам инструмент для описания того, каким образом взаимодействовать с тем или иным веб-сервисом, тогда как семантическая разметка снабжает нас информацией о том, что и как делает данный сервис.
Чтобы SW-сервисы стали реальностью, язык разметки должен быть достаточно информативным с тем, чтобы компьютер был способен самостоятельно понимать смысл записанных на нём выражений. Ниже приводятся требования, которым должен отвечать такой язык:
Необходимость поиска сервисов (обнаружение — discovery)
Программы должны иметь возможность самостоятельно находить (или обнаруживать) требуемые им веб-сервисы. Ни WSDL, ни UDDI не позволяют программе понять, для чего именно с точки зрения клиента служит тот или иной веб-сервис. Семантический же веб-сервис сможет предъявить описание своих свойств и возможностей с тем, чтобы программы могли сами распознавать его предназначение.
Необходимость запускать сервисы (запуск — invocation)
Программы должны уметь самостоятельно узнавать, каким образом запускать и исполнять данный сервис. Например, если выполнение сервиса представляет собой многошаговую процедуру, то программе требуется знать, как ей следует взаимодействовать с сервисом, чтобы требуемая последовательность шагов осуществилась. SW-сервис предъявляет исчерпывающий перечень того, что должен уметь агент для запуска и выполнения данного сервиса. Сюда же следует отнести описание входных и выходных данных этого сервиса.
Необходимость использования вместе нескольких сервисов (композиция)
Программы должны уметь отбирать нужные им веб-сервисы и комбинировать их для достижения своих целей. Сервисам необходимо будет тесно взаимодействовать друг с другом, так чтобы получающийся в результате их комбинирования результат был приемлемым решением поставленной задачи. Таким образом, программные агенты смогут строить совершенно новые сервисы, комбинируя сервисы, уже имеющиеся в Сети.
Необходимость узнавать, что происходит после запуска сервиса (мониторинг)
Программный агент должен уметь определять свойства данного сервиса и следить за его выполнением. Некоторым сервисам может требоваться определённое время для исполнения работы, и агенты должны быть в состоянии следить за ходом выполнения сервиса.
Снабдив агентов возможностями самостоятельно обнаруживать, запускать, комбинировать и следить за исполнением сервисов без участия человека, можно будет создать новые достаточно функциональные приложения. Представим себе некую Интегрированную Среду Разработки (IDE — Integrated Developer Environment), которая не только содержит перечень доступных сервисов, но также предлагает подходящие их комбинации, удовлетворяющие требованиям, сформулированным нами на языке высокого уровня. Вместо того, чтобы пролистывать длинные списки сервисов в поисках того, входные параметры которого соответствуют нашему приложению, можно просто обращаетиться к среде IDE, которая предложит сервисы, в точности подходящие для наших целей.
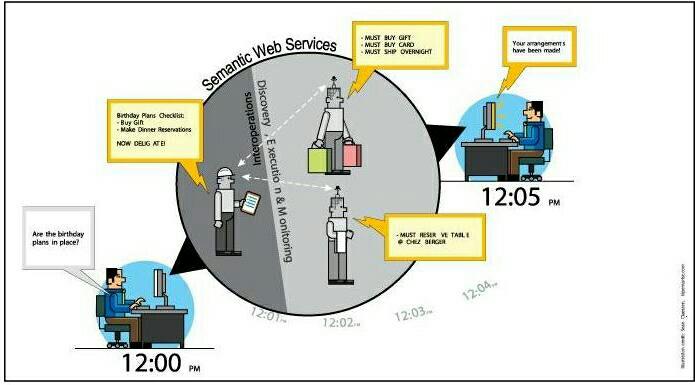 Можно будет также создать неких персональных агентов, чтобы употребить всю мощь Сети на пользу конечному пользователю. Например, такой персональный агент вполне мог бы провести подготовку к празднованию дня рождения, получив лишь минимальные входные данные от пользователя . Подобный агент мог бы скомбинировать сервисы по заказу товаров, их покупке и доставке самостоятельно, преследуя поставленную перед ним пользователем на языке высокого уровня цель — подготовку праздника. Когда такие вещи будут делаться автоматически, пользователь сможет экономить как время, так и деньги.
Можно будет также создать неких персональных агентов, чтобы употребить всю мощь Сети на пользу конечному пользователю. Например, такой персональный агент вполне мог бы провести подготовку к празднованию дня рождения, получив лишь минимальные входные данные от пользователя . Подобный агент мог бы скомбинировать сервисы по заказу товаров, их покупке и доставке самостоятельно, преследуя поставленную перед ним пользователем на языке высокого уровня цель — подготовку праздника. Когда такие вещи будут делаться автоматически, пользователь сможет экономить как время, так и деньги.
Превращению Интернета в семантическую сеть способствует и Военное научное агентство DARPA. Оно разрабатывает новый язык программирования DAML (DARPA Agent Markup Language), основанный на XML. Он предназначен для детального описания смысла хранимой на Web-странице информации. Рабочая версия DAML появится летом, и DARPA надеется, что консорциум утвердит W3C в качестве стандарта. Предполагается, что DAML послужит существенным стимулом для превращения Интернета из "свалки" информации в семантическую Сеть.
DAML позволит Web-агентам и поисковым системам комбинировать смысловое содержание нескольких страниц (например, учитывать в рубрикаторе все иерархические разделы, относящиеся к конкретному сайту), что позволит выполнять поиск предельно точно.
Другое преимущество DAML – возможность унификации жаргонных выражений, применяемых в разных областях промышленности и относящихся к одному и тому же технологическому элементу.
Вывод:
Проблема поиска решения в базе знаний типа семантической сети сводится к задаче поиска фрагмента сети, соответствующего некоторой подсети, соответствующей поставленному вопросу.
В семантических сетях существует возможность представлять знания более естественным и структурированным образом, чем в других формализмах.
Основным преимуществом является то, что она более других соответствует современным представлениям об организации долговременной памяти человека.
Недостатком этой модели является сложность организации процедуры поиска вывода на семантической сети.
Источники:
http://paulcowles.ulitzer.com/node/39631
http://ezolin.pisem.net/logic/ws_and_sw_rus
http://www.readwriteweb.com/archives/top_10_semantic_web_products_2008.php
http://ru.wikipedia.org/wiki/

- Классификация, назначение и возможности банковских ИС
- Классификация, назначение и возможности банковских ИС
- Организация хранения документов
- Международный договор - источник международного права
- Нравственные нормы делового общения
- Психологические трудности в общении и методы их регулирования
- History of hospitality
- Проблемы определения правового статуса физического лица в международном частном праве. Личный закон физического лица
- Оценка стоимости ценных бумаг
- Роль Генри Форда в становлении методов
- Применение экспертных методов в маркетинговых исследованиях
- Business