
Задача бинарной классификации
Содержание:

Введение
С развитием технологий растет востребованность на методы нахождения закономерностей в больших объемах данных и, в частности, алгоритмы машинного обучения на прецедентах. Большая часть таких алгоритмов позволяют учитывать лишь вещественные признаки для описания наблюдаемых объектов. Но на практике часто встречаются задачи с категориальными признаками, принимающими свои значения из конечного неупорядоченного множества. В настоящей работе проанализированы имеющиеся алгоритмы, учитывающие категориальные признаки, а также предложены новые методы. Работа всех описанных в данной курсовой работе была исследована и проверена на реальных наборах данных.
1. Постановка задачи
1.1 Основные понятия. Задача бинарной классификации
Задача обучения по прецедентам состоит в том, чтобы обучающийся научился восстанавливать зависимость, другими словами - построить решающую функцию, которая бы приближала целевую функцию, причем не только на объектах, помогающих в обучении, но и на остальных. Кроме того, решающая функция должна допускать компьютерную реализацию.
Каждый объект имеет определенные признаки. Допустим их n штук. Тогда каждому объекту соответствует вектор-признаковое описание. Благодаря этому обучающую выборку можно представить в виде матрицы.
-
-
- Оценка качества алгоритмов
-
Для субъективной оценки качества работы обученных алгоритмов используют различные функционалы. В реальной работе будет использована метрика AUC (площадь под ROC-кривой). Предположим, что есть истинный вектор меток y для n объектов и вектор y˜ предсказанных степеней принадлежности классу 1.
Pn Pn I [yi < yj] * I[y˜i < y˜j]
i=1 j=1
AUC (y, y) =͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟͟ ∈ [0,1].
(Pn I[yi = 0]) * (Pn I[yi – 1])
i=1 i=1
Чем ближе значение AUC к единице, тем выше качество алгоритма.
Метрика AUC обладает парой любопытных качеств. Например, когда она устойчива к монотонным преобразованиям предсказанных меток ответов. Поэтому при решении задач необходимо будет учитывать взаимных порядок объектов по предсказанным степеням принадлежности.
Обычно для более объективной оценки качества, алгоритм обучается на одной части выборки, а предсказание оценивается на другой. Но если разбить выборку на k равных непересекающихся частей (фолдов), то можно поочередно обучаться на k1 части и оценивать качество на оставшейся одной, а полученные в результате k оценок качества рассматривать как наблюдения случайной величины оценки качества. Такой подход называется «кроссвалидацией».
1.2 Постановка задач с категориальными признаками
Многие классические подходы машинного обучения предполагают, что все признаки Xj R. Однако в задачах признаки могут принимать значения из множеств, не совпадающих с множествами вещественных чисел. Признаки могут принимать значения из конечного неупорядоченного множества. К примеру, это может быть признак сайт со значениями из множества {ВКонтакте, Фейсбук, Твиттер, Инстаграм и др…}. Такие признаки будут называться категориальными.
Казалось бы, можно просто свести задачу с категориальными признаками к задаче с вещественными просто пронумеровав значения признаков. Например,
ВКонтакте → 1
Фейсбук → 2
Твиттер → 3
Инстраграм → 4
…
Но такой подход часто завершается крахом. Все из-за исходного множества значений, ведь они неупорядоченные, а на пронумерованном множестве задан порядок, который, скорее всего, будет учитывать алгоритм. К тому же, не совсем понятно, какую из нумераций использовать, ведь всего существует y! нумераций с различным взаимным порядком, где y количество неповторимых значений признака.
2. Примеры задач с категориальными признаками
В последнее время задачи с категориальными признаками приобретают все большую популярность.
Большая группа задач с категориальными признаками являются задачами, связанными с коллаборативной фильтрацией. В таких задачах каждый объект Оценка пользователя, представлен двумя категориальными признаками: Пользователь и Предмет. По обучающей выборке оценок пользователей необходимо научиться предсказывать оценки для еще неизвестных пар (Пользователь, Предмет). Основным толчком для изучения подобных задач стало трехлетнее соревнование Netflix’a.
Подобной задачей является тематическое моделирование. В ней объекты задаются двумя признаками Документ, Термин и частотами вхождения соответствующего термина в соответствующий документ. Однако по обучающей выборке нужно научиться не предсказывать частоты, а также выделять тематики в документах и их вероятностные распределения. Поэтому о тематическом моделировании чаще говорят, как о задаче обучения без участия учителя.
Схожей является задача поискового ранжирования. В ней проводится предсказание релевантности для пары (Запрос, Документ). В реальных поисковых системах этой паре соответствует огромное число признаков, посчитанных по ним. Такие представления легко обобщаются на различные интересные и крайне полезные для промышленности случаи.
3. Используемые методы
3.1 Группировка значений признаков
При реальной работе часто будет использоваться прием группировки признаков. Он заключается в том, что натуральное число фиксируется и генерируется новые перекодированные описания объектов. Каждый такой признак также является категориальным и объединяет внутри себя информацию о наборе из x признаков исходной матрицы данных. Каждому новому признаку соответствует некоторый набор из x исходных признаков.
3.2 Метод q ближайших соседей
Предположим, некий признак принимает q значений {a1, … , aq}. Тогда для каждого объекта Хi можно заменить признак Xj на q-бинарные признаки следующим образом:
Zak = I[Xj = ak], k ∈ {1, ..., q},
i
i
i
Где I[A] индикатор события А, т.е.
I[A] = 1, если А верно,
0, если А неверно.
Такой способ называется dummy-кодированием. Если закодировать каждый признак исходной матрицы таким методом, то к полученным описаниям объектов Z1, … , Zn можно применять многие классические алгоритмы для работы с вещественными признаками.
Такой вид представления матрицы данных, несмотря на свои легкость и доступность в понимании, имеет недостатки. К примеру, подобная перекодировка признаков накладывает ограничения на структуру признакового описания объектов, которую не учитывает алгоритм, работающий с вещественными признаками. Ведь каждый признак перекодируется в несколько других. Новых признаков с одной единицей.
Также одним из минусов этого способа является сильно увеличивающаяся размерность пространства объектов. Большинство алгоритмов не способны обрабатывать полученные матрицы данных во многих реальных задачах. Из-за этого описание объектов приходится хранить в разреженном формате и использовать приспособленные методы, один из которых логистическая регрессия, большинство реализаций, которой дают возможность работать с разреженным представлением данных.
3.3 Произвольная перенумерация значений
Как уже было написано в разделе 2.2, обыкновенная нумерация значений признаков маловероятно приведет к качественному результату из-за того, что алгоритмы начинают учитывать не имеющую смысла упорядоченность значений признаков. Такие алгоритмы являются очень нестабильными к различным нумерациям значений признаков и показывают низкой уровень качества по отдельности. Однако, как показал Leo Braiman, схожие неустойчивые, но несмещенные алгоритмы можно максимально эффективно соединить в композиции, с помощью техники bagging. Таким образом можно обучать независимые слабые алгоритмы с произвольно пронумерованными признаками и в качестве финального предсказания брать усредненный ответ по всем ним. Такой подход позволяет увеличить качество композиции и сэкономить потраченное время в сравнении с каждым взятым отдельным базовым алгоритмом.
3.4 Наивный байесовский классификатор
Для решения задачи бинарной классификации можно использовать мультиномиальный наивный байесовский классификатор. Его главная задача заключается в предположении о вероятностной условной независимости признаков. В случае классификации будет предсказан следующий класс:
m
argymax p(y|X) = argymax p(y) Y p(Xj|y)
j=1
Для удобства расчетов было сделано следующее преобразование:
m m
Argymaxp(y) Y p(y = 1 Xj) |Y| p(y = 1cXj).
j=1 j=1
Поскольку все признаки принимают значения из дискретных неупорядоченных множеств, то по принципу максимума правдоподобия можно получить:
Pn I[yi = y] * I[Xj = Xj]
P(y|Xj)= ____________________
i=1
Pn I[Xj = Xj]
В данном случае использование принципа максимума правдоподобия имеет пару недочетов. Например, если в обучающей выборке не встречалось некоторого категориального значения признака j, то алгоритм не сможет вычислить p(yXj). Также такой подход никак не учитывает дисперсию оценки максимума правдоподобия. На практике зачастую в подобных случаях используют аддитивное сглаживание вероятностей, накладывающее априорные распределение Дирехле на параметры вероятностной модели.
На основе наивного байесовском классификатора можно строить и другие более подходящие для конкретных задач алгоритмы. Наиболее он подходит для задач регрессии.
Также можно использовать некий внешний мета-алгоритм f, который бы выражал искомую вероятность не просто произведением вероятностей, а более сложным аппроксиматором:
Prediction = f(p(y|x1), …, p(y|x1)).
В качестве такого мета-алгоритма можно использовать любой классификатор или регрессор в зависимости от задачи. Например, если обучать линейный мета-алгоритм с весами (w1, …, wm) на логарифмах факторизованных вероятностей, то получим приближение:
prediction = pwj(y|xj).
j=1
Подобный прием очень эффективен, но при условии его корректного использования.
3.5 Аппроксимация целевых меток с помощью взвешенных разреженных разложений матриц
В задачах коллаборативной фильтрации стандартным стал подход на основе взвешенного разложения разреженных матриц и тензоров. Взвешенность означает, что под разреженностью подразумеваются пропущенные значения, а не равные нулю.
Рассмотрим некоторую пару признаков j1 и j2, которые принимают уникальные значения {ak}q1 и {bl}q2, соответственно.
k=1 l=1
Тогда можно составить матрицу F размера q1 * q2 оценок значения метки для соответствующей значений пары признаков j1 и j2. Если в обучающей выборке не встречались прецеденты для некоторой пары значений, то значение матрицы считается неизвестным. Оценкой значения метки может служить, эмпирическое математическое ожидание значение метки.
Назовем латентным вектором значения ak признака j1 k-ю строчку матрицы G и H латентным вектором значения bl признака j2 1-й столбец матрицы Н. Вместо перекодировки исходных значений пар признаков восстановленными с помощью матричного разложения значений целевых меток можно перекодировать соответствующие латентные вектора, полученными из матриц G и H. При решении таким способом каждый признак будет перекодирован новыми 2r признаками. Такое решение может позволить внешним мета-алгоритмам находить более глубокие закономерности в данных.
Идентичные рассуждения можно использовать и для тензоров т.е. рассматривать не пары признаков, а наборы признаков произвольной длины. В таком случае нужно использовать разреженные тензорные разложения.
При решении задач данным методом есть вероятность возникновения сложности того, что некоторые пары (ak, bl) могли ни разу не встречаться в обучающей выборке и из-за этого невозможно будет провести перекодировку признаков на основе имеющегося разложения матрицы. В таком случае необходимо выполнить следующее: неизвестные значения (будь то ak или bl) кодировать с помощью взвешенного среднего среди всех латентных векторов для значений, встретившихся в обучении, с весами, пропорциональными количествам вхождений соответствующего значения признака в обучение.
3.6 Стекинг алгоритмов
Метод использования внешнего мета-алгоритма над результатами работы других базовых алгоритмов называется stacking.
Если обучать базовые алгоритмы и внешний мета-алгоритма на одной и той же выборке, то может произойти эффект переобучения из-за того, что на вход внешнему мета-алгоритму даются перекодированные с помощью базовых алгоритмов признаки. При этом обучение перекодировок происходило на тех же данных, на которых и выполняется перекодировка.
В таком случае необходимо разделять обучающую выборку на два раздела. В первом необходимо обучать базовые алгоритмы, кодирующие значения признаков, а на другом необходимо обучать внешний мета-алгоритм.
При использовании этого подхода появляются новые проблемы. Допустим, базовые алгоритмы и мета-алгоритм используют меньшие объемы данных для обучения и показывают более низкое качество, чем если бы обучались на всех данных. Также возникает вопрос о выборке оптимальной пропорции разбиения обучающего множества на две части. Для такого разделения можно использовать более сложные методы кроссвадилации, однако в данной курсовой я их не описываю.
Стоит отметить, что на вход внешнему мета-алгоритму можно подавать не только ответы базовых классификаторов, но и промежуточные вычисления в базовых алгоритмах. Это могут быть как латентные векторы, так и счетчики значений признаков, получающиеся в процессе работы алгоритмов на основе наивного байеса.
3.7 Использование частот совместных встречаемости значений признаков для их перекодировки
3.7.1 Перекодировка частотами встречаемости наборов значений
Каждую пару значений признаков j1 и j2 можно перекодировать частотой совместной встречаемости. Такая перекодировка дает возможность учесть генеративную природу данных.
Также нужно обратить внимание, что подобная перекодировка не требует знания истинных меток объектов. Поэтому, если помимо обучающей выборки заранее известна и тестовая, для которой нужно делать предсказания, как нередко бывает в конкурсах по анализу данных, то можно применять единую перекодировку как для обучения, так и для теста. Такой способ и использовался в экспериментах, описанных ниже. Если же тестовые данные заранее неизвестны, то перекодировку необходимо обучать лишь на обучающей выборке, поэтому на тестовой выборке может возникнуть проблема новых значений признаков. В этом случае можно использовать подход аналогичный описанному в разделе 3.6.
3.7.2 Разложение матриц частот
Кроме напрямую посчитанных оценок частот можно использовать и приближения частот, полученные в результате матричных разложений соответствующих матриц. Рассмотрим на примере некоторых признаков j1 и j2, которые принимают уникальные значения {ak}q1 и {bl}q2, соответственно. Тогда можно составить матрицу F размера q1 * q2. В такой матрице все значения известны – это частоты вхождения соответствующей пары значений признаков в обучающую выборку. Делая разложения матрицы
l=1
k=1
F ≈ GH, G ∈ Rq1xr, H ∈ Rrxq2,
мы можем получить приблизительные значения частот встречаемости соответствующих признаков. Поскольку многие значения частот равняются нулю, то здесь можно также использовать разреженные матричные, но не в смысле пропущенных значений, а в смысле нулевых значений. Вместо приближенных значений частот можно использовать перекодировку значений признаков соответствующими латентными векторами:
Zj1j2 = (Gj, Hj) 2
Такое кодирование будет содержать в себе информацию о совместной встречаемости значений признаков. Уже на матрице Z можно обучать мета-алгоритм. Также нужно обратить внимание, что этот метод выполняется без учителя и, соответственно, не требует дополнительного разбиения данных на несколько частей, как требовалось в некоторых подходах выше.
Появляется вопрос, что именно подразумевается под приближением одной матрицы P с помощью другой Q? В качестве метрики качества приближения можно использовать Фробениусову норму:
D2 (P,Q) = kP – Qk2 = X (Pij – Oij)
i j
Однако куда более естественный смысл при аппроксимации частот имеет неотрицательное матричное разложение и обобщенная KL-дивергенция) в качестве меры качества разложения:
Pij
DKL(P k Q) = X (Pij * log --- - Pij + Qij)
Q
Эти меры сходства являются частным случаем так называемой β-дивергенции:
Pij β-1 – Qij β-1 Q ij β
D β (Pij k Q) = X (Pij * _______________ = ____
β – 1 β
Действительно, при β = 1, имеем:
D β (P kQ) → DKL (P k Q)
а при β = 2
D β (P k Q) = D2 (P, Q)
Стоит обратить внимание, что β-дивергенция, как, впрочем, и KL-дивергенция, в общем случае является несимметричной мерой сходства.
Также мы можем рассматривать не пары признаков, а наборы признаков большой длины. В данном методе все остается аналогичным, за исключением использования тензорного разложения вместо матричного. При реальной работе подобные тензорные подходы не рассматривались.
- Данные
Для опытов в своей курсовой работе я выбрал два современных набора реальных данных с категориальными признаками. В данном разделе приведен краткий обзор этих наборов.
-
-
- Обзор набора данных
-
Первый набор данных был опубликован на международном соревновании по анализу данных Amazon.com – Employee Access Challenge, проводимом в 2013 году. Далее в курсовой для краткости этот набор данных будет называть Amazon.
Необходимо решить задачу бинарной классификации. Всего в выборке 32769 объектов, из них классу 1 принадлежат 94% объектов. Каждый объект описывается девятью категориальными признаками. Количество уникальных значений по каждому из признаков приведено в таблице 1.
|
Номер признака |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
Уникальных значений |
7518 |
4243 |
128 |
177 |
449 |
343 |
2358 |
67 |
343 |
Таблица 1. Количество уникальных значений по каждому из признаков в наборе данных Amazon.
4. Выбор способа тестирования алгоритмов
Для проведения всех экспериментов и более точного сравнения результатов работы различных алгоритмов было принято решение зафиксировать единую конфигурацию тестирования для всех алгоритмов. Использование произвольных разбиений на обучение и контроль (в различных пропорциях) давало большее отклонение оценки качества, нежели кроссвадилация. На рис.1 показан график зависимости оценки качества ее 2σ-доверительный интервал в зависимости от количества фолдов в случае алгоритмов из принципиально разных семейств: логистической регрессии с dummy-кодированием и наивным байесовским классификаторов. В качестве σ2 бралась эмпирическая несмещенная оценка дисперсии в каждой точке. В дальнейшем в работе везде будут использоваться несмещенные σ2 доверительные интервалы, если не обговорено обратное.
Видно, что при количестве фолдов, равном семи, оценка качества ведет себя уже довольно стабильно. Выбор большего числа фолдов влечет за собой больший вычислительный расход. В связи с этим было решено использовать фиксированное разбиение на 7 фолдов.
0.87 0.800
Logistic Regression
Naive bayes
Logistic Regression Naive bayes
AUC mean
0.86 0.795
0.85 0.790
0.84 0.785
0.83 0.780
0.82 0.775
0.81 0.770
2 3 4 5 6 7 8 9 10 2 3 4 5 6 7 8 9 10
Рис. 1. Среднее качество предсказания в зависимости фолдов и 2σ-доверительная трубка на данных Amazon.
Рис. 2. Среднее качество предсказания в зависимости фолдов и 2σ-доверительная трубка на данных Movie Lens.
-
- Movie Lens
4.1 Обзор набора данных
Второй набор данных был опубликован компанией Movie Lens и называется Movie Lens 100K. В дальнейшем буду писать его просто Movie Lens.
Данные представляют из себя 100000 оценок пользователей некоторому набру кинофильмов. Каждый объект обучающей выборки является оценкой пользователя. Категориальные признаки номер пользователя, номер объекта, социальная информация о пользователе, категориальная информация о жанре соответствующего фильма. Изначально в вышеописанном наборе данных каждый из жанров был закодирован бинарным признаком, показывающим отношение фильма к соответствующему жанру (жанры могли пересекаться). Для дальнейших опытов все жанровые признаки были мной объединены в один жанровый признак со значениями, соответствующими каждой уникальной комбинации жанров. В качестве меток использовались бинарные метки, показывающие, была ли поставлена оценка 5.
Необходимо решить задачу бинарной классификации. Всего в выборке 100000 объектов из них классу 1 принадлежат 64% объектов. Каждый объект описается шестью категориальными признаками. Количество уникальных значений по каждому из признаков приведено в таблице 2.
|
Номер признака |
1 |
2 |
3 |
4 |
5 |
6 |
|
Уникальных значений |
943 |
1682 |
2 |
21 |
795 |
216 |
Таблица 2. Количество уникальных значений по каждому из признаков в наборе данных Movie Lens.
4.2.2 Выбор способа тестирования алгоритмов
Выбор конфигурации тестирования алгоритмов на этом наборе данных проводился аналогично подобной процедуре для набора Amazon. Графики зависимости и отклонения оценки качества в зависимости от количества фолдов показаны на рис. 2. Было решено использовать для всех экспериментов фиксированное разбиение на 5 фолдов.
- Эксперименты
- Используемая система для экспериментов
Все вычисления производились на ПК. Использовался Intel Core i5 7600 3.5 GHz, оперативная память 16 GB 2400MHz DDR4, операционная система Windows 10 x64 Максимальная.
Практически все эксперименты были запрограммированы на языке Python 3.8.6 с использованием библиотеки scikit-learn. Кроме этого были использованы Matlab и R 4.0.9.
-
- Метод ближайшего соседа
В качестве базового и самого простого алгоритма (бейзлайна) будем использовать метод k ближайших соседей с метрикой Хемминга. На рис.3 показаны зависимости качества от количества ближайших соседей для обоих наборов данных.
AUC
AUC
0.74 0.64
0.72 0.62
0.70 0.60
0.68 0.58
0.66 0.56
0.64 0.54
0 5 10 15 20 25 30 35 0 20 40 60 80 100
n_neighbors n_neighbors
Рис. 3. Зависимость качества предсказания метода ближайших соседей от количества соседей. Слева изображен график для данных Amazon, справа для данных Movie Lens.
Стоит заметить, что данный метод ближайших соседей показывает низкое качество не из-за принципиальных недостатков метода, а из-за наивной выборки метрики в пространстве объектов. При правильном выборе метрики, т.е. меры сходства между объектами, метод ближайших соседей может показывать очень высокие результаты, в том числе и в этих задачах.
-
- Наивный байесовский классификатор и его расширения
- Классический наивный байес
- Наивный байесовский классификатор и его расширения
В первую очередь мной были проведены эксперименты с обычным наивным байесовским классификатором. При аппроксимации вероятностей p(y Xj) значительную роль играет параметр аддитивного сглаживания α. На рис. 4 можно увидеть зависимость качества работы алгоритмов от параметра сглаживания. Графики приведены для оптимальных в соответствующей задаче значений степени группировки признаков p. Стоит отметить, что оптимальное значение α практически не меняется с увеличением p. Соответственно, можно подобрать α при фиксированном p и использовать его в дальнейших вычислениях.
AUC
0.91 0.79
AUC
0.90 0.78
0.89 0.77
0.88 0.76
0.87 0.75
0.86 0.74
0.85 0.73
0.84 0.72
10-3 10-2 10-1 100 10-3 10-2 10-1 100 101 102
alpha0 alpha0
Рис. 4. Зависимость качества работы наивного байеса от параметра сглаживания. Слева изображен график для данных Amazon в случае группировки признаков по четверкам (p = 4), справа для данных Movie Lens в случае группировки признаков попарно (p = 2).
Также существенно влияет на качество работы выбор параметра p степени группировки значений признаков. На рис. 5 показана зависимость качества предсказания от степени группировки признаков. Видно, что на данных Amazon увеличение p повышает качество, а на данных Movie Lens оптимальным оказывается p = 2, а большие значения существенно ухудшают результат.
AUC
0.91 0.79
AUC
0.90 0.78
0.89 0.77
0.88 0.76
0.87 0.75
0.86 0.74
0.85 0.73
0.84 0.72
0.83 0.71
0.82 0.70
1.0 1.5 2.0 2.5 3.0 3.5 4.0 1.0 1.5 2.0 2.5 3.0 3.5 4.0
Grouping degree (p) Grouping degree (p)
Рис.5 Зависимость качества работы наивного байеса от степени группировки признаков (параметра p). Слева изображен график для данных Amazon, справа для данных Movie Lens.
-
-
- Обучение внешнего мира-алгоритма
-
Как было описано в разделе 3.8, можно использовать перекодировку значений признаков аппроксимациями соответствующих вероятностей p(y Xj) (точнее их логарифмов) и над полученной матрицей данных обучать мта-алгоритм. В качестве мета-алгоритмов были выбраны логистическая регрессия и случайный лес. В таблице 3 показана информация о результатах использования различных мета-алгоритмов. Видно, что логистическая регрессия лучше показывает результат как в качестве, так и в скорости работы.
Отдельно стоит заметить, что оптимальное p в случае классического наивного байесовского классификатора без использования внешнего мета-алгоритма не является оптимальным при его использовании. Так, например, p = 4, будучи оптимальным в случае классического наивного байеса на данных Amazon показывает низкое качество при использовании мета-алгоритма (AUC = 0.8654 против AUC = 0.8721).
|
Мета-алгоритм |
Amazon |
Movie Lens |
|
Случайный лес |
AUC = 0.8658 |
AUC = 0.7655 |
|
Время обучения = 17.8 сек |
Время обучения = 23.5 сек |
|
|
Доля выборки = 40% |
Доля выборки = 30% |
|
|
p = 2 |
p = 2 |
|
|
Логистическая регрессия |
AUC = 0.8721 |
AUC = 0.7809 |
|
Время обучения = 83.1 сек |
Время обучения = 76.4 сек |
|
|
Доля выборки = 10% |
Доля выборки = 7% |
|
|
p = 2 |
p = 2 |
Таблица 3. Качество различных мета-алгоритмов, обучающихся над результатами работы наивного байеса.
На Рис. 6 показаны примеры зависимости качества от доли выборки, которая отходит на обучение мета-алгоритма.
Нужно обратить внимание, что применение линейного мета-алгоритма требует значительно меньшей части обучающей выборки нежели случайный лес и, как следствие, перекодировка признаков обучается на большой доле данных. Возможно, это является одной из причин того, что линейный мета-алгоритм показывает более высокое качество работы.
AUC
AUC
0.90 0.790
0.89 0.785
0.88 0.780
0.87 0.775
0.86 0.770
0.85 0.765
0.84 0.760
0.83 0.755
0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.0 0.1 0.2 0.3 0.4 0.5 0.6
model_split_size model_split_size
Рис. 6. Доля выборки, отходящая на обучение мета-классификатора. Слева изображен график для данных Amazon, справа для данных Movie Lens.
Также было проведено и множество других экспериментов. Например, были проведены попытки обучать мета-алгоритмы не на значениях logP(y|Xj), а на исходных p(y|Xj). Однако прироста в качестве это не дало.
Также было замечено, что чаще всего неправильные ответы мета-алгоритм выдает на объектах, в которых накоплена маленькая частотная статистика для вычисления p(y|xj. В связи с этим была испробована идея использовать
Pn I[yi = y] * I[xj = xj]
p(y|xj) =
Pn I[xj = xj]
в качестве признаков для мета-алгоритмов, а отдельно числитель и знаменатель дроби, с помощью которой он вычисляется, чтобы мета-алгоритм смог улавливать уверенность и неуверенность частотных оценок. Однако и такой подход давал падение качества.
-
- Разреженная логистическая регрессия
Один и из самого успешного алгоритма – это логистическая регрессия на данных, закодированных с помощью dummy-кодирования. Ключевыми параметрами здесь являются p (степень группировки признаков) и параметр регуляризации С логистической регрессии. На рис. 7 можно увидеть графики зависимости качества от параметра регуляризации при p = 2.
AUC
0.92 0.805
AUC
0.91 0.800
0.90 0.795
0.89 0.790
0.88 0.785
0.87 0.780
0.86 0.775
0.85 0.770
0.84 0.765
10-1 100 101 10-1 100 101
Рис. 7. Доля выборки, отходящая на обучение мета-классификатора
Вычисление при p = 4 требует больших вычислительных ресурсов по памяти. В таблице 4 показаны результаты работы при различных p. Видно, что группировка большой степени не имеет смысла и ведет к переобучению.
|
Amazon |
Movie Lens |
|
|
p = 1 |
0.8691 |
0.7958 |
|
p = 2 |
0.8820 |
0.7951 |
|
p = 3 |
0.8802 |
0.7826 |
Таблица 4. Качество работы разреженной логистической регрессии при различных значениях степени группировки признаков p.
Анализируя обученные линейные модели, можно заметить, что большинство коэффициентов в ней близки к нулю. Этот эффект продемонстрирован на рис. 8. Это наводит на мысль об использовании модели с l1-регуляризацией или elastic net, ведь они ведут к автоматическому отбору признаков и приведению к нулю коэффициентов. Однако такие подходы прироста качества не дали.
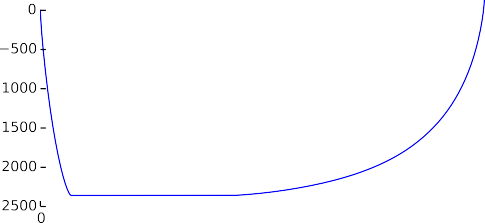
Рис. 8. Аккумулированные значения обученного и отсортированного вектора весов логистической регрессии на попарно сгруппированных данных Amazon.
-
- Произвольные перенумерации значений признаков
В этом разделе показаны результаты экспериментов с алгоритмами, которые были описанными в разделе 3.5. Несмотря на простоту и понятность идеи, подобный подход показывает неплохое качество. На рис. 9 показана зависимость качества прогноза от количества базовых аппроксиматоров Extremely Randomized Trees в случае сгруппированных попарно данных. Именно такие базовые аппроксиматоры показали себя лучше остальных опробованных.
Однако оно ниже, чем у некоторых других подходов: AUC = 0.8599 на данных Amazon и AUC = 0.7430 на данных Movie Lens. Да и время работы оставляет желать лучшего. Например, на данных Amazon оно превосходит 5 минут, что сильно ограничивает возможности экспериментов с данным методом. Кроме того, оценка качества работы данного метода очень неустойчива.
Помимо обычного усреднения ответа по все алгоритмам еще были проведены эксперименты с бустингом базовых алгоритмов, т.е. каждый следующий базовый алгоритм обучался так, чтобы выполнить ошибки предыдущих. Однако этот подход прироста не дал.
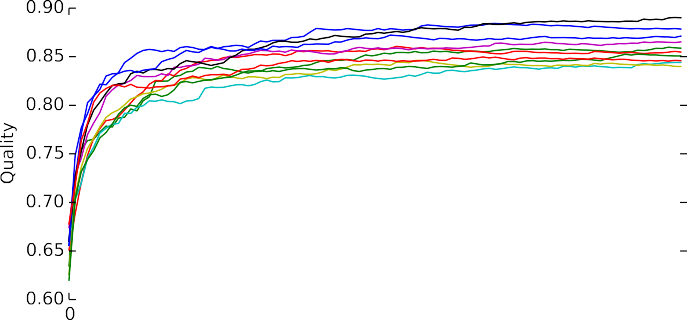

Рис. 9. Зависимость качества от количества базовых аппроксиматоров на попарно сгруппированных данных Amazon.
-
- Аппроксимация целевых меток с помощью матричных разложений
Также проведен эксперимент для алгоритмов, описанных в разделе 3.7. В качестве внешнего мета-алгоритма использовался случайный лес, он показал лучшее качество работы по сравнению с линейным классификатором. На наборе данных Amazon описанный метод достиг AUC = 0.8726, а на наборе Movie Lens AUC = 0.7816.
К сожалению, более гибкая настройка этого семейства методов в данном работе не проводилась, хотя алгоритм позволяет иметь множество настроек. Например, можно пробовать варьировать пропорцию разбиения обучающей выборки для обучения кодировки и мета-алгоритма, параметр аддитивного сглаживания α, а использующийся при вычислении средних значений целевых меток в известных клетках раскладывающейся матрицы, выбор оптимального количества компонент в разложении и т.п.
Матричные разложения производились с помощью библиотеки Divisi2 на Python для создания рекомендательных систем.
Результаты экспериментов показаны в таблице ниже.
|
Метод |
Amazon |
Movie Lens |
|
Аппроксимации меток + LR |
0.8032 |
0.7507 |
|
Аппроксимации меток + RF |
0.8593 |
0.7539 |
|
Латентные векторы по меткам + LR |
0.8697 |
0.7784 |
|
Латентные векторы по меткам + RF |
0.8726 |
0.7816 |
-
- Перекодировки частотами
- Выбор количества компонентов
- Перекодировки частотами
Также помимо основных опытов, были проведены эксперименты по определению оптимального количества компонента в таких разложениях. График зависимости качества от количества компонент на данных Amazon представлен на рис. 10. Видно, что увеличение количества компонента приводит к увеличению качества алгоритма. Переломный момент, когда большое количество компонентов ведет к переобучению обнаружено не было, однако он, с большей вероятностью, есть. Стоит отметить, что алгоритму удается достигнуть высокого результата, что подтверждает оправданность и эффективность частотных кодировок признаков с помощью латентных векторов.
0.92
AUC
0.90
0.88
0.86
0.84
0.82
0.80
0 1 2 3 4 5 6 7
Factors keeped
Рис. 10. Зависимость качества от количества компонентов
Помимо действий, описанных выше, были проведены схожие эксперименты, в которых производились разложения матриц количеств совместных встречаемости значений признаков и их видоизменений (например, логарифмов). Однако, подобные подходы не смогли улучшить качество.
Заключение
В данный период времени не существует общепринятого стандартного набора алгоритмов для решения задач машинного обучения с категориальными признаками. В реальной работе был проведен обзор существующих подходов, были представлены новые методы и сравнены эффективности их работы на реальных данных.
Стоит подчеркнуть, что в работе особое внимание уделялось алгоритмам по отдельности и не рассматривались объединения алгоритмов из разных семейств в композиции. Известно, что подобные техники дают возможность сильно улучшать итоговое качество работы систем машинного обучения, даже если базовые алгоритмы показывали не очень высокое качество.
Список литературы
- Среда программирования matlab. www.mathworks.com
- Библиотека matlab для неотрицательного матричного и тензорного разложения с оптимизацией β-дивергенции. www.mathworks.com/matlabcentral/fileexchange/38109-matrix-and-tensor-factorization--nmf--ntf-with-any-beta-diver
- Библиотека scikit-learn для машинного обучения на Python. www.scikit-learn.org
- Библиотека scikit-tensor для Python для разреженных тензорных разложений. www.github.com/mnick/scikit-tensor
- Библиотека divisi2 для Python для создания рекомендательных систем на основе взвешенных матричных разложений. www.github.com/commonsense/divisi2
- Международное соревнование Amazon Employee Access Challenge. www.kaggle.com/c/amazon-employee-access-challenge
- Международное соревнование Netflix prize. www.netflixprize.com
- Набор данных Movie Lens 100K. www.grouplens.org/datasets/movielens
- Язык программирования Python. www.python.org
- Язык программирования R. www.r-project.org
- Игорь Кураленок, Александр Щекалев, www.osp.ru/os/2013/08/13037858
- Алешин С. П., Ляхов А. Л. Нейросетевая оценка минерально-сырьевой базы региона по данным геофизического мониторинг 2011. № 1 (31). C. 39–43

- Профессиональный стресс управленческой деятельности
- Теория менеджмента. Менеджмент человеческих ресурсов..
- Система органов местного самоуправления (Полномочия субъектов РФ)
- Управление процессом реализации изменений и нововведений (ЗАО Международный Жилой комплекс «Росинка»)
- Управление рисками в проектной среде (Проект Smart Grid г.Белгорода )
- Гендерные различия проявления профессионального стресса ( Анализ гендерных различий)
- Барьеры на пути эффективных коммуникаций («НЕВСКИЕ ЗВЕЗДЫ»)
- Управление запасами (на примере АО «Хоневелл»)
- Роль мотивации в поведении организации
- История возникновения и развития языка программирования Си (С++) и Java(История и характеристика Java )
- Применение процессного подхода для оптимизации бизнес-процессов (ООО «Арсенал Авто»)
- История развития средств вычислительной техники (История развития информатики)