
Тестирования производительности программ: подходы в зависимости от категорий приложений
Содержание:

Введение
Платформа Android в последние годы является лидером рынка операционных систем, занимая по состоянию на 2015 год 59 % рынка операционных систем и 89,4 % рынка мобильных платформ по всему миру. Соответственно, все больше компаний, стремясь увеличить количество пользователей своих сервисов, уделяют особое внимание именно этой платформе. Именно открытость исходного кода ОС Android позволила этой платформе завоевать такие позиции на рынке. Однако, разнообразие устройств приводит к печальным последствиям в плане поддержки этих устройств, а также программного обеспечения на них. Производитель не может позволить себе обновлять устаревшее устройство до последней версии ОС ввиду экономических причин, и, как это часто бывает, для побуждения пользователя купить новое устройство с новейшей версией ОС и техническими характеристиками. Разработчики ПО так же не поддерживают все устройства на всех версиях ОС, но разрабатывают приложения под нужды, в первую очередь, устройств,занимающих лидирующие позиции на рынке.
Вышеперечисленные причины, наряду с ошибками в программировании, неизбежно приводят к нежелательным последствиям, таким как падение спроса на тот или иной сервис и ухудшение «пользовательского опыта». Именно поэтому необходимо тестирование всего ПО, выпускаемого в широкие массы пользователей.
На сегодняшний день существующие методы тестирования не позволяют однозначно и полностью выявить все дефекты и установить корректность функционирования анализируемой программы. Поэтому существующие методы тестирования действуют в рамках формального процесса тестирования, который может доказать, что дефекты отсутствуют с точки зрения используемого метода.
Объектом исследования в курсовой работе является программное обеспечение.
Предметом исследования – процесс тестирования программного обеспечения на примере мобильных приложений.
Целью исследования является выявление особенностей процесс тестирования программного обеспечения на примере мобильных приложений.
Для достижения поставленной цели сформулированы следующие задачи:
- изучить теоретические аспекты тестирования программного обеспечения;
- проанализировать факторы, влияющие на процесс тестирования мобильных приложений.
Методологической основой исследования являются учебная и методическая литература, статьи в периодической печати и Интернет-ресурсы.
Теоретические аспекты тестирования программного обеспечения
Сущность и необходимость тестирования программного обеспечения
Процесс тестирования играет важную роль в проектах, связанных с разработкой программного обеспечения (ПО). Руководители консалтинговых компаний, которые занимаются созданием и внедрением новых информационных продуктов, заинтересованы в обеспечении качественного выполнения этого вида работ. Несмотря на то, что успех проекта зависит от многих факторов, правильная организация процесса тестирования существенно влияет на подготовку качественного программного обеспечения. [2, с.102; 3, с.16]
Время проведения тестирования зависит от выбранной модели жизненного цикла (ЖЦ) программного обеспечения. Как правило, исключая водопадную модель ЖЦ ПО, планирование тестирования начинается в самом начале IT-проекта, когда совместно с заказчиком уже определены требования к будущему ПО. Готовится план тестирования и, согласно требованиям, тест кейсы, по которым будет проводиться проверка программного обеспечения. Специалисты пришли к выводу, что информация обо всех найденных ошибках обязательно должна быть сохранена, это значительно облегчает работу команды тестирования. Несмотря на продолжающиеся дискуссии о возможности применении других средств, обычно в компаниях используют багтрекинговую систему для создания, хранения, просмотра и модификации сведений о багах. От выбора функционального и удобного багтрекера зависит уровень взаимодействия команды тестирования и разработчиков, а также качество исполнения процесса тестирования. В данном случае рассматривалась система трекинга багов (СТБ) для среднестатистической небольшой компании. Таких фирм достаточно много на российском рынке, чаще всего, они параллельно занимаются несколькими проектами и осуществляют техническую поддержку. В ходе работы использовался алгоритм выбора программного обеспечения, его основные этапы показаны на рисунке 1. [5, с. 177]
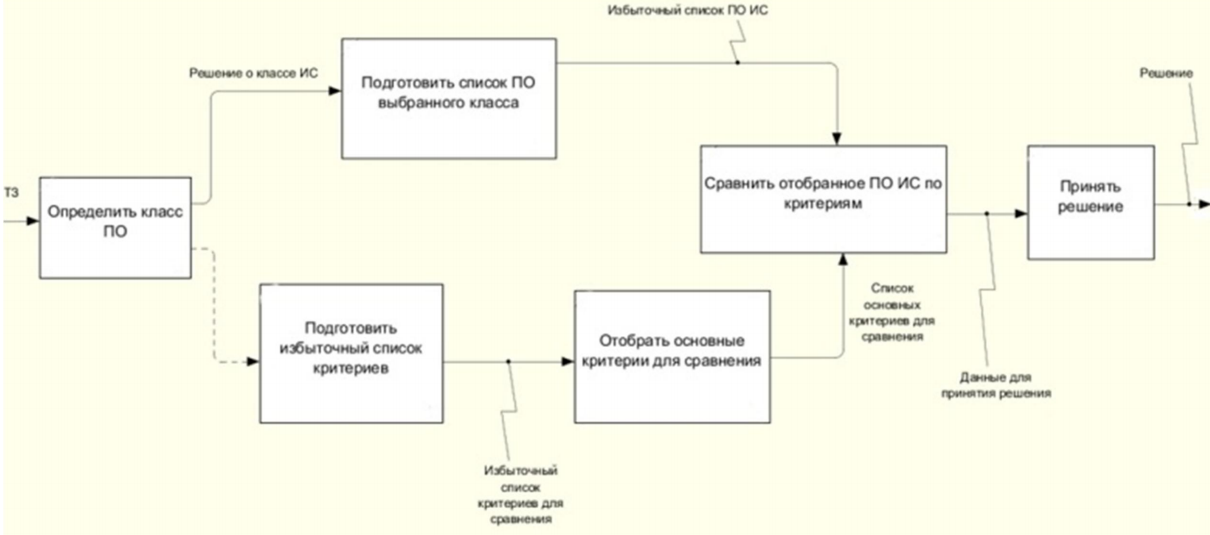
Рисунок 1. Алгоритм выбора ПО
Таким образом, решалась задача многокритериального вывода, применялась методика MuSCoW для выделения более значимых показателей. Эта консалтинговая методика подразумевает, что есть 4 вида критериев – обязательные (must have), менее важные, но желательные показатели (should have, would have), а также показатели, которых не должно быть (won’t have). [6, с.213; 7, с.174]
Список программного обеспечения и его оценка по выделенным критериям проводилась с помощью экспертов в области тестирования. При подведении итогов применялся метод взвешенной оценки, учитывающий важность каждого показателя. Наиболее весомым и значимыми специалисты признали «Usability» и «Простоту освоения». Дело в том, что во время проекта возможна частичная или полная смена коллектива, как тестировщиков, так и разработчиков. Новый сотрудник должен легко освоить функционал багтрекера, чтобы как можно быстрее начать выполнять свои обязанности. Критерий «Простота освоения» важен для сотрудников, которые совмещают роли на проекте. Например, в целях оптимизации, консультанты могут быть задействованы в процессе тестирования. Поэтому, чем логичнее и проще устроена система трекинга багов, тем меньше сроки ее изучения. Следующим критерием была названа «Полнота функционала», в это понятие входит весь набор необходимых work items, то есть таких рабочих элементов, как user story, task, bag, test case, test suite. А также 120 наличие статусов, приоритетов и других показателей, которые необходимы для эффективной работы с дефектами ПО. «Надежность» – достаточно важный показатель, который критичен для любых реально работающих систем, в том числе и багтрекинговых. «Требования к аппаратному обеспечению (АО)» достаточно средние, больших ресурсов не требуется. «Поддержка работы с несколькими проектами» – выделяется особенно, так как компании чаще всего ведут работу по большому количеству проектов и всю информацию по дефектам необходимо хранить в багтрекере. «Учет рабочего времени» – отражает количество временных ресурсов затраченных на ту или иную ошибку. «Генерация отчетов» довольно важный показатель, так как для test lead, менеджера проекта, высшего руководства необходимо иметь полные и исчерпывающие сведения о процессе тестирования. Языковой барьер нередко является большой проблемой в ходе проекта, поэтому лучше иметь СТБ с функцией поддержки нескольких языков. «Наличие интеграции с email, мессенджерами» – для команды проекта важно иметь постоянный доступ к информации, ресурсам системы, так как успешное завершение проекта зависит, в том числе, и от оперативности реагирования персонала на то или иное событие. «Методическое обеспечение» также играет не последнюю роль, качественное описание структуры и наличие правил работы с багтрекером значительно упростит его освоение пользователями. «Поддержка и применение в РФ» – это залог обеспечения ее работоспособности системы, возможность технической поддержки. Затем нами были рассмотрены представленные на рынке, как opensource, так и проприетарные решения. Изначально стоимость, то есть финансовый критерий не определен, важно выбрать программное обеспечение, которое более всего соответствует названным показателям. Приобретение платной системы или использование СТБ с открытым кодом зависит от политики и финансовых возможностей компании. На рынке представлено большое количество программного обеспечения в области тестирования, нами были оценены Bugzilla от компании Mozilla Foundation, Trac от Edgewall Software, Atlassian JIRA компании Atlassian Software Systems, Test Rail Gurock Software, MantisBP от Mantis, Redmine разработчика JeanPhilippe Lang. Итоги сравнения приведены в таблице 1.
Таблица 1 - Матрица критериев по выбору системы трекинга багов
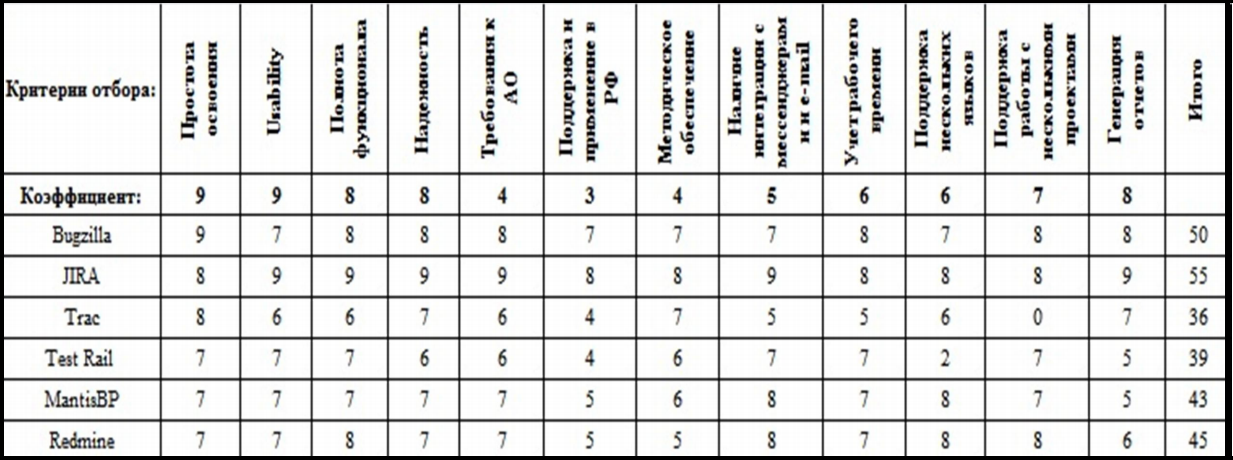
Исходя из полученных баллов, наилучшие показатели у ПО Atlassian JIRA. За ней следуют системы Bugzilla и Redmine. Несмотря на то, что Bugzilla опередила JIRA по критерию «Простота освоения», эта система значительно уступает по второму наиболее важному показателю «Usability». Redmine в целом была оценена ниже, чем две другие СТБ, в том числе и по двум значимым критериям. Система Trac, которая по сумме баллов находится на последнем месте, тем не менее, отмечена достаточно высоко по «Простоте освоения» и «Usability». Однако Trac проигрывает другим ПО в «Полноте функционала», а также не поддерживает работу с несколькими проектами. Названные критерии также учитываются при выборе багтрекера, им присвоены высокие коэффициенты. Именно поэтому эта система не была включена нами в список отобранных. Bugzilla и Redmine – open source решения, а Atlassian JIRA – проприетарное ПО, но на сайте разработчика представлен и тестовый вариант. Окончательное решение следует принимать исходя не только из финансовых возможностей компании. Необходимо провести экспериментальную проверку и сравнить лидирующее программное обеспечение, чтобы на практике убедиться в точности результатов исследования.
Характеристика процесса тестирования
Процесс тестирования начинается с того, что команде тестировщиков предоставляется ПО, которое следует протестировать, и требования к этому ПО. Как только разработчики подготовили программу, необходимо провести дымовое тестирование, по результатам которого делается вывод о возможности и целесообразности дальнейшего тестирования:
– если дымовое тестирование прошло неудачно, вы отправляете приложение на доработку;
– если же удачно, то вы переходите к следующему виду тестирования - регрессионное тестирование.
Открыв систему отслеживания ошибок, следует перепроверить дефекты, которые разработчики перевели в статус «Исправлено», «Отклонено», «Нет возможности воспроизвести» и т.д. Заметим, что статусы «Отклонено» и «Нет возможности воспроизвести» для вас самые неприятные - это явное свидетельство того, что либо вы недостаточно хорошо локализовали дефект, не очень понятно описали шаги для воспроизведения, либо разработчик поленился воспроизвести ситуацию. Покончив с закрытием и переоткрытием дефектов, идёт переход к основной работе - централизованному тестированию по тест кейсам. Когда все, что было запланировано, пройдено, тестировщик имеете результаты прогона тест кейсов, бaг репорты, вопросы к аналитикам и заметки на полях своих тетрадей. Основываясь на всем этом, составляется отчет по проведенному тестированию и отправляется на проектную группу. Подобный процесс проходит от версии к версии, и через какое-то время результаты тестирования сойдутся, с прописанными в плане тестирования критериями окончания тестирования. На этом основная работа, связанная непосредственно с тестированием, окончена [1, с.12].
Тестирование ПO является одной из технических способов контроля качества и включает в себя активности по планированию работ, проектированию тестов, выполнению тестирования и анализу полученных результатов [3, с.15]. Необходимое условие: тестирование не возможно без объекта тестирования, отсюда получаем первое условие: наличие объекта тестирования, доступного для проведения испытаний. Далее, чтобы тестирование все же состоялось, нам нужен исполнитель, значит, вторым необходимым условием будет наличие исполнителя, причем им может быть, человек или машина, или комбинация человек и машина.
Перейдем к определению достаточных условий. Так как не каждое действие, совершенное над программой, с целью получения ожидаемого поведения, является тестированием, встал вопрос о том, что сама по себе цель, а именно: тестирование, является одним из достаточных условий. Принимая за основу то, что наличие плана тестирования прямо указывает на намерение проведения тестирования, получаем, что тест план является одним из достаточных условий. При проведении тестирования, человек или машина должны будут выполнять какие-то действия для проверки реального и ожидаемого поведения программы. Значит, наличие тест кейсов/тестов также является достаточным условием.
Для подтверждения, что тестирование произошло, нам необходим отчет о результатах. Значит, для подтверждения того, что тестирование имело место быть, отчет о результатах тестирования должен быть сформирован.
Тестирование – это процесс, который заключается в проверке соответствия программного продукта заявленным характеристикам и требованиям, требованиям эксплуатации в различных окружениях, с различными нагрузками, требованиям по безопасности, требованиям по эргономике и удобству использования. Именно поэтому тестирование является неотъемлемым компонентом создания ПО.
Оно решает несколько основных задач:
– дает уверенность в качестве конечного продукта, подтверждает, что все заявленные функциональные требования реализованы, приложение им соответствует и не имеет ошибок в программном коде;
– подтверждает, что приложение способно выполняться во всех заявленных режимах и на всех поддерживаемых ОС или Web-браузерах корректно;
– гарантирует, что хранимые и обрабатываемые данные надежно защищены от постороннего доступа и "взлома";
– определяет, какая максимальная нагрузка на сервер, локальную сеть, БД может быть корректно обработана приложением;
– позволяет убедиться в том, что пользователь может "интуитивно" использовать продукт или услугу не путаясь в сложных переплетениях интерфейсов.
Уровни тестирования
Стандарт ISO / IEC 25010:2011 (ГОСТ Р ИСО / МЭК 25010 - 2015) определяет качество программного обеспечения как степень соответствия системе заявленных и подразумеваемых потребностей различных заинтересованных сторон. В соответствии со стандартом модель качества программного продукта включает восемь характеристик:
- функциональная пригодность;
- уровень производительности;
- совместимость;
- удобство пользования;
- надёжность;
- защищённость;
- сопровождаемость;
- переносимость (мобильность) [11].
Выделяют следующие уровни тестирования:
Модульное тестирование — тестируется минимально возможный для тестирования компонент, например, отдельный класс или функция. Обычно модульное тестирование осуществляется разработчиками программного обеспечения.
Интеграционное тестирование — тестируются интерфейсы между компонентами, подсистемами или системами. При наличии резерва времени на данной стадии тестирование ведётся итерационно, с постепенным подключением последующих подсистем.
Системное тестирование — тестируется интегрированная система на её соответствие требованиям.
Альфа - тестирование — имитация реальной работы с системой штатными разработчиками, либо реальная работа с системой потенциальными пользователями / заказчиком. Чаще всего альфа - тестирование проводится на ранней стадии разработки продукта, но в некоторых случаях может применяться для законченного продукта в качестве внутреннего приёмочного тестирования. Иногда альфа - тестирование выполняется под отладчиком или с использованием окружения, которое помогает быстро выявлять найденные ошибки. Обнаруженные ошибки могут быть переданы тестировщикам для дополнительного исследования в окружении, подобном тому, в котором будет использоваться программа.
Бета - тестирование — в некоторых случаях выполняется распространение предварительной версии (в случае проприетарного программного обеспечения иногда с ограничениями по функциональности или времени работы) для некоторой большей группы лиц с тем, чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда бета - тестирование выполняется для того, чтобы получить обратную связь о продукте от его будущих пользователей [11].
Часто для свободного и открытого программного обеспечения стадия альфа - тестирования характеризует функциональное наполнение кода, а стадия бета - тестирования — стадию исправления ошибок. При этом, как правило, на каждом этапе разработки промежуточные результаты работы доступны конечным пользователям [10].
Следует различать статическое и динамическое тестирование.
При статическом тестировании программный код не выполняется — анализ программы происходит на основе исходного кода, который вычитывается вручную, либо анализируется специальными инструментами. В некоторых случаях анализируется не исходный, а промежуточный код (такой как байт - код или код на MSIL) [10]. Статический анализ всегда быстрее всех остальных методов анализа.
Динамический анализ предполагает запуск реальной программы [9] и анализ функционирования программы и ее артефактов.
1.4 Генетические алгоритмы тестирования программ
Проблема качества остается главной для индустрии программного обеспечения (ПО). В программной инженерии рассматриваются все аспекты повышения качества программного обеспечения, начиная с подготовительных работ и заканчивая их изъятием из обращения. Тестирование является неотъемлемой составляющей программной инженерии, одним из методов улучшения качества разрабатываемого ПО посредством выявления его дефектов, не обнаруженных ранее другими видами проверок [1-3]. Известно, что тестирование программной системы является сложным, длительным и дорогостоящим видом деятельности, требующим около трети времени и почти половины общей стоимости разработки ПО [3-4]. Поднять качество ПО можно путем сокращения сроков и стоимости разработки, в частности, за счет повышения эффективности его тестирования. Для решения этой сложной проблемы предложены и частично автоматизированы различные способы генерации тестовых данных, такие как методы случайной, символической, динамической и т. п. генерации на основе структурного и функционального тестирования [2-4]. Однако этого явно недостаточно, генерация тестовых данных в значительной степени выполняется вручную. Поэтому в настоящее время идет активный поиск новых моделей (или развития и модификаций существующих). В последние годы при решении этой проблемы широко применяются методы искусственного интеллекта, прежде всего био-инспирированные алгоритмы (генетические, муравьиные, роевые и т. п. [5]). В частности, получены обнадеживающие результаты по использованию этих алгоритмов в тестировании ПО.
Для повышения эффективности, «интеллектуальности» и расширения функций автоматизации тестирования широко применяются методы искусственного интеллекта (ИИ). Эволюционные вычисления (Эв) [5] представляют один из наиболее перспективных подходов ИИ. Эв используют принципы и терминологию, заимствованные у биологической науки - генетики. В Эв каждая особь представляет потенциальное решение некоторой проблемы и кодируется специальным образом (в простейшем случае двоичным числом). Множество особей - потенциальных решений составляет популяцию. В Эв наиболее популярным (но не единственным) является генетический алгоритм (ГА), который хорошо показал себя при решении многих задач комбинаторной оптимизации [5], в частности, проблем тестирования как аппаратной части, так и программного обеспечения.
При решении конкретной задачи с помощью ГА необходимо определить особь, популяцию, эволюционные операторы и фитнесс-функцию. Потенциальное решение представляется хромосомой - некоторым кодом, состоящим из элементов-генов. Таким образом, ГА оперируют закодированными хромосомами (генотипами), а не решениями (фенотипами) проблемы. Поиск (суб)опти- мального решения проблемы в Эв выполняется в процессе искусственной эволюции популяции - последовательного преобразования одного конечного множества решений в другое с помощью генетических операторов репродукции, кроссинговера и мутации. В общем случае ГА может быть представлен следующей последовательностью операторов [5]:
- Создание начальной популяции.
- Оценка популяции.
- Выбор наилучших особей.
- Приемлемое решение найдено?
- Если да, то конец, поиск лучшего решения в полученной популяции.
- Создание новой популяции на основе текущей с применением генетических операторов. Перейти на шаг 2.
Напомним, что для того, чтобы применить генетический алгоритм для решения некоторой проблемы, необходимо прежде всего определить:
- Кодирование (представление потенциального решения).
- Для определенного кодирования выбрать или разработать генетические операторы кроссовера, мутации и репродукции.
- Фитнесс-функцию из условия задачи.
- Параметры ГА: число особей в популяции, значения вероятностей кроссовера Pc nPm ит. п.
Далее будет показано, что различные эволюционные методы тестирования ПО решают эти этапы по-разному.
После появления в 1995 году стандарта ISO/IEC 12207 [4], где все действия по созданию ПО систематизированы в виде отдельных процессов жизненного цикла, тестирование отнесено к основным процессам. Поэтому в настоящее время тестирование интегрировано с процессами разработки и рассматривается как непрерывная многоуровневая деятельность на протяжении всего жизненного цикла ПО независимо от его критичности.
Тестирование программного обеспечения является одним из основных методов, которые обеспечивают высокое качество программного обеспечения. Тестирование программного обеспечения выявляет наличие неисправностей, вызывающих отказ программного обеспечения. Отметим, что тестирование программного обеспечения занимает много времени и требует значительных ресурсов (около 50 %). Тестирование программного обеспечения также можно определить как процесс верификации и проверки (валидации) программного обеспечения для обеспечения того, чтобы оно отвечало ожидаемым как техническим, так и бизнес-требованиям. При этом верификация выполняется для проверки соответствия программного обеспечения спецификации и близка к структурному тестированию, тогда как валидация ближе к функциональному тестированию и выполняется путем выполнения тестируемого программного обеспечения.
В широком смысле методы тестирования включают функциональное (по методу черного ящика) и структурное тестирование (метод «белого ящика). Функциональное тестирование основано на функциональных требованиях, тогда как структурное тестирование базируется на выполнении самого кода. Тестирование по методу серого ящика представляет собой гибрид тестирования методом белого и черного ящика. Тестирование может выполняться вручную или автоматически, используя инструменты тестирования. Установлено, что автоматизированное программное обеспечение тестирования лучше, чем ручное тестирование. Однако очень мало инструментальных средств генерации тестовых данных, которые коммерчески доступны в настоящее время. Различные методы предложены для автоматической генерации тестовых данных или тестовых примеров [1-3]. В последнее время большая часть работ в этом направлении выполняется с использованием технологий мягких вычислений, таких как нечеткие системы, нейронные сети, генетические алгоритмы, генетическое программирование и эволюционные вычисления, которые дают новые возможности при решении проблем в области тестирования программного обеспечения. Эволюционное тестирование - это новая методология для автоматической генерации высококачественных тестовых данных [6].
Структурное тестирование может быть выполнено в виде тестирования потоков данных или тестирования путей. Последнее включает в себя создание набора путей, которые покрывают каждую ветвь в программе, и нахождение набора тестовых данных, которые реализуют каждый путь в этом наборе путей. При тестировании потока данных основное внимание уделяется точкам программ, в которых переменные получают значения (вычисляются), и точкам, в которых эти значения используются. Далее представлены некоторые подходы по применению ГА в тестировании программ по методу белого ящика. Прежде всего их можно разделить на две группы: 1) тестирование потока данных; 2) тестирование путей [6].
Предложен структурно ориентированный автоматический метод генерации тестовых данных на основе ГА, который использует зависимость потока данных в программе при выполнении универсального критерия [7]. Поток управления программой представляется здесь направленным графом с множеством узлов и множеством ребер. Каждый узел представляет группу последовательных операторов, которые вместе составляют основной блок. Тогда ребра графа могут передавать поток управления между узлами. Путь - это конечная последовательность узлов, соединенных ребрами. Полный путь - это путь, первым узлом которого является начальный узел и чей последний узел является выходным узлом. Анализ потока данных фокусирует внимание на взаимодействиях между определениями переменных (defs) и ссылками (uses использованием этих переменных) в программе. Переменные в тестируемой программе делятся на переменные, используемые в вычислениях (c-uses) и предикатах (p-uses). Переменные c-uses используются в вычислениях или в предикатах программы; в то время как переменные p-uses связаны с ребрами графа потоков управления. Цель анализа потока данных состоит в том, чтобы найти определение (defs) каждой переменной в программе и ее использование (uses), на которые могут повлиять эти defs, то есть найти def-use-ассоциации. Такие отношения потока данных могут быть представлены следующими двумя множествами: dcu (i) - множество всех определений переменных defs, для которых есть пути def-clear к их c-uses в узле i; dpu (i, j) - множество всех определений переменных defs, для которых есть def-clear пути к их p-uses ребра (i, j). Используя местоположение переменной defs и ее использования uses в тестируемой программе в сочетании с алгоритмом достижимости основного состояния, можно определить множества dcu (i) и dpu (i, j). С помощью алгоритма достижимости основного состояния определяются два множества: достижимости - reach (i) и влияния - avail (i), где достижимость reach (i) представляет собой множество всех переменных defs, которые достигаются из узла i, а влияния avail (i) являются множеством всех доступных переменных defs, влияющих на узел i. Таким образом, имеем объединение множества глобальных переменных defs, которые влияют на узел i, и множества всех переменных, достижимых из этого узла:
dcu(i): reach(i) n c - used(i) , dpu(i, j): avail(i) n p - used(i, j), где c-use (i) - множество переменных, для которого узел i содержит глобальные c-use, a p-use (i, j) - множество переменных, для которых ребро (i, j) содержит p-use. При оценке качества тестирования используется критерий всех использований (all-uses), который требует определения пути от каждого определения def переменной к каждому ее использованию (c-use и p-use) с той переменной, которую нужно пройти. Следует отметить, что этот критерий также покрывает другие критерии, которые применяются при тестировании потоков данных.
Потенциальным решением (одним тестовым набором) в данном случае является набор значений входных переменных. Например, если все входные переменные являются действительными, то это вектор действительных чисел. В общем случае переменные могут иметь различные типы (например, действительные и булевы), и тестовый набор может представлять более сложную структуру. Но при реализации ГА для представления значений каждой переменной можно использовать бинарное кодирование. Для одной переменной длина входного сигнала определяется доменом и необходимой точностью. Любой домен представляется D, = |д, Ь;], где каждая переменная в программе принимает значения из диапазона [а^, bi]. Каждая область (домен) D, должна быть разбита на (b1-a1)-10d1 диапазонов равных размеров, если необходима точность до d, десятичных разрядов. Если т, - целое число, обозначающее длину хромосомы или строки, такое, что (Ь - a ) -10^ < 2m -1, то двоичная строка длины т, обеспечивает требование по точности. Далее для отображения из двоичной строки i в действительное число из диапазона [а^ bi] выполняется стандартной стандартное преобразование [5]. В том случае, когда все входные переменные являются действительными числами, каждая хромо- k
сома (в качестве тестового набора) представляется двоичной строкой длины т{ = т{ . При этом i=1
первые mi бит представляют значение из диапазона [ai, bi] переменной хь следующая группа т2 битов отображает значение из диапазона [а2, Ь2] переменной х2 и т. д. Последняя группа mk бит отображает значение из диапазона [ak, bk] переменной хк. При формировании начальной популяции случайным образом генерируются m-битные строки размера pop_size. Соответствующее значение pop_size определяется экспериментально. Каждая хромосома преобразуется в к десятичных чисел, представ-ляющие значения к входных переменных хк.. ,,хк (то есть тестовый набор).
Центральной компонентой ГА является фитнесс-функция, которая позволяет оценивать каждый тестовый набор путем выполнения программы со значениями входных переменных, представляющий этот набор, и записи путей def-use в программе, покрываемых этим набором. Считается, что тестовый набор покрывает путь def-use, если он заставляет программу проходить путь, имеющий подпуть, который начинается в def-узле и заканчивается в узле c-use / p-use (def-use path). Значение фитнесс-функции eval (v;) для каждой хромосомы v; (i = 1,..., pop_size) рассчитывается следующим образом:
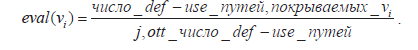
Тест V! эффективен, если для него значение фитнесс-функции eval (vi) > 0. Таким образом, каждый тест (хромосома) оценивается, выполняется программа для формирования def-use путей, которые покрываются тестами (используемыми в качестве их входных данных). Все тестовые наборы отбираются с эффективными eval (vi) или хорошими значениями фитнесс-функции. Отбор родительских особей производится пропорциональным методом (рулетки) [5] или случайного выбора. Эффективные тестовые наборы (значений входных переменных программы) формируют родительские особи новой популяции. Если ни один тестовый набор не эффективен (не покрывает минимального числа путей), то все особи текущей популяции рассматриваются в качестве родителей. В процессе отбора родителей ГА использует один из двух методов: рулетка или случайный выбор по выбору пользователя.
При построении новых тестовых наборов используются стандартные генетические операторы кроссинговера и мутации. Во время кроссинговера двое родителей (хромосом) случайным образом обмениваются информацией подстрок (генетическим материалом) со случайной позиции, чтобы произвести две новые строки (потомство). Целью является построение лучшей популяции в процессе искусственной эволюции путем объединения генетического материала из пар текущей популяции. Кроссинговер выполняется с некоторой вероятностью рс . Мутация выполняется по битам путем инвертирования каждого бита с заранее определенной вероятностью мутации рт, что дает нам ожидаемое количество мутированных битов рт • т -pop_size. При традиционном подходе ГА популяция развивается, пока одна особь из популяции, которая представляет решение, будет найдена. В нашем случае это соответствует одной группе элементов данных, которая достигает максимального покрытия программы (то есть прохождения всех путей def-use программы). Хотя это возможно для некоторых программы, большинство программ не могут быть охвачены только одной группой данных элементов (то есть одним тестовым набором). Поэтому может потребоваться много групп и несколько запусков программы, чтобы достичь желаемого уровня тестирования. Итак, мы позволяем популяции развиваться до тех пор, пока объединенная подгруппа популяции достигает желаемого уровня покрытия. В результате эволюции для каждого включаемого тестового набора определяем множество путей, покрываемых этим набором, и путем объединения этих множеств для всех построенных тестовых наборов находим множество путей программы, покрываемых тестовой последовательностью. Этот процесс продолжается до тех пор, пока мы не построим последователь наборов, покрывающих все необходимые пути. Решением является эта последовательность тестовых наборов.
Предложенный генетический алгоритм принимает в качестве входных данных инструментальную версию программы для тестирования, список путей к def-use, количество входных данных переменных, а также область и точность каждой входной переменной. Кроме того, он принимает параметры ГА: численность популяции, максимальное количество поколений и значения вероятностей кроссинговера и мутации. Алгоритм выдает набор тестовых наборов, набор def-use путей, покрываемых каждым тестовым набором, и список непокрытых путей def-use, если таковые имеются. Алгоритм использует целочисленный вектор, называемый вектором покрытия def-use, для записи покрытых путей. В этом векторе каждый элемент (изначально ноль) соответствует пути def-use. Всякий раз, когда путь def-use покрыт, номер тестового набора, который покрывает этот путь, сохраняется в соответствующем элементе покрытия def-use вектора. Алгоритм отслеживает все сгенерированные тестовые наборы, покрывающие новые пути def-use. Эти тесты хранятся для последующего использования. Методика ГА, представленная в этом разделе, основана на зависимости в потоке данных программы для поиска тестовых данных соответственно критерия универсального использования. Такой подход может быть использован при генерации тестовых данных для программы без циклов и процедур. Проведены эксперименты по оценке эффективности предложенного ГА по сравнению с методом случайного тестирования для сравнения предложенного случайного метода выбора метода рулетки. Результаты этих экспериментов показали, что методика ГА превзошла метод случайного тестирования в 12 из 15 программ, использованных в эксперименте. В 10 из этих программ методики ГА требуется меньшее количество поколений, чем метод случайного тестирования для достижения того же процента покрытия по умолчанию. В двух программах ГА достиг более высокого процента покрытия в меньшем количестве поколений, чем метод случайного тестирования.
Для методов тестирования типа «белого ящика» одним из наиболее мощных критериев тестового покрытия является покрытие решений (decision coverage). Согласно этому критерию набор тестов должен обеспечить хотя бы однократное выполнение каждой ветви программы и каждого логического условия внутри нее. Для этого требуется выделение в графе потоков управления программы множества путей, содержащих все ее ветви, и формирование тестового набора, обеспечивающего максимально возможное (а в идеале - исчерпывающее) прохождение этих путей при заданных ограничениях на ресурсы тестирования. Известно, что в общем случае все пути протестировать невозможно по нескольким причинам. Во-первых, программа может содержать бесконечное количество путей, например, в случае наличия в ней циклов. Во-вторых, число путей в программе экспоненциально увеличивается с ростом количества ветвей в ней, и многие из этих путей могут быть невыполнимыми. В-третьих, количество возможных тестовых наборов слишком велико, так как каждый путь может быть охвачен несколькими тестовыми наборами. Поэтому проблема путевого тестирования реальных достаточно сложных программ является NP сложной проблемой, для которой покрытие всех возможных путей либо невозможно в принципе, либо же требует слишком больших вычислительных ресурсов. Поскольку охватить все пути в программном обеспечении невозможно, проблема путевого тестирования обычно сводится к эффективному выбору приоритетного подмножества путей для выполнения и тестовых данных, покрывающих эти пути. Отметим, что особую актуальность проблема путевого тестирования приобретает в связи с быстрым распространением практики разработки, управляемой тестами - test driven development. При этом вначале создаются модульные тесты, описывающие требования к ПО, а потом - код модулей, для которых эти тесты должны выполняться. Поэтому игнорирование критических ветвей при тестировании создает предпосылки для появления ошибок при их реализации в соответствующем коде.
В отличие от предыдущего, в рассматриваемом методе используется взвешенный граф потока управления, для которого существует некоторая функция (правило) f.E R (функция на множестве дуг со значениями на множестве вещественных чисел). Сама функцияf называется весовой, а ее значение на той или иной дуге называется весом этой дуги. Любой подграф данного графа и любой путь в данном графе имеют свой вес: это сумма весов дуг, входящих в этот подграф или в этот путь. В рассматриваемом методе [8, 9] при взвешивании графа предлагается использовать правило равенства сумм весов всех дуг, входящих в произвольную вершину, и всех дуг, исходящих из нее. При этом предполагается, что каждая вершина графа (исключением является вершина start) имеет свой входящий вес (сумма весов всех входящих в нее дуг). Поскольку вершина start не имеет явных входящих дуг, то ей присваивается фиктивный входящий вес w, который будем называть опорным весом графа потока управления. Он является регулируемым параметром. Обычно чем сложнее граф потока управления, тем больше следует брать его опорный вес. Входящий вес каждой вершины распределяется среди всех исходящих из нее дуг. Исключением является вершина end, не имеющая явных исходящих дуг. Заметим, что единого правила распределения входящего веса произвольной вершины у по ее исходящим дугам нет. Однако в подавляющем большинстве случаев большие веса целесообразно назначать так называемым критическим дугам, то есть дугам в составе путей, более подверженных ошибкам, ведущим к тяжелым последствиям. Предложено придерживаться следующего правила: fl процентов входящего веса вершины выделяется для дуг в последовательном пути (эти проценты затем делятся поровну между дугами, составляющими этот путь), а остальные 0 = 100 - fl процентов входящего веса резервируются для циклов и ветвей. Следует подчеркнуть, что fl < 50 % (часто полагают fl = 20 % ). В случае если некоторая вершина имеет только одну исходящую дугу, то весь ее входящий вес присваивается этой дуге. Тройка (G, w, fl), где G - граф потока управления, является одним из возможных представлений взвешенного графа потока управления. В этом случае пара (w, fl) задает правило взвешивания графа.
Путь, выполняемый тестируемой программой, однозначно определяется значениями входных данных. Этот набор и является хромосомой - потенциальным решением. Как и в предыдущем случае, каждая хромосома может быть закодирована в двоичном алфавите {0,1}. Например, закодированная хромосома (15,4) представляет собой битовую строку вида: 11110100. Качество каждой хромосомы оценивается фитнесс-функцией вида: 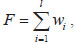 где w, - вес, назначенный i-u дуге соответствующего ;=1 хромосоме пути; l - количество дуг, образующих путь.
где w, - вес, назначенный i-u дуге соответствующего ;=1 хромосоме пути; l - количество дуг, образующих путь.
Начальная популяция Х0 представляет собой множество из N случайно сгенерированных двоичных последовательностей, каждая из которых является закодированной хромосомой. Отбор лучших родителей популяции для участия в последующем воспроизводстве осуществляется с помощью пропорциональной селекции (рулетки). Тогда вероятность р. выбора хромосомы j находится по формуле:
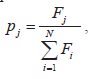 где N - начальный размер популяции. Кумулятивная вероятность k-й хромосомы Е F
где N - начальный размер популяции. Кумулятивная вероятность k-й хромосомы Е F
Ck вычисляется следующим образом: Ск = р. . При генерации потомков - новых тестовых наборов j=i
используется стандартный 1 -точечный кроссинговер рс = 0,9, производящий две новые хромосомы путем обмена правыми от точки разрыва частями. После получения всех хромосом потомков каждая из них подвергается также стандартной побитовой мутации с вероятностью рт = 0,3. На завершающем этапе каждого прогона алгоритма из хромосом текущей популяции, то есть родителей, и их потомков одним из известных методов сокращения популяции [5] формируется новая популяция. Если критерий завершения алгоритма не выполняется, то начинается следующий прогон алгоритма уже с новой популяцией. В целом применение данного подхода способствовует сокращению затрат на проведение тестирования и его стоимости. Но поскольку эксперименты были проведены для относительно небольших программ, дальнейшее усовершенствование предложенного подхода требует его апробации.
При функциональном тестировании по методу «черного ящика» программа рассматривается как функция, которая отображает значения из ее входной области значений в выходном диапазоне значений. Один из способов тестирования программ предполагает ее проверку на соответствие их формальным спецификациям при выполнении программы. К сожалению, на практике сложно убедить разработчиков написать формальные спецификации. Более реальным подходом является использование «искусственных спецификаций», генерируемых компьютером. Другой вариант использования - применение автоматического тестирования. Инструменты, такие как QuickCheck, Evosuite и ТЗ [10-12], способны генерировать тестовые входные данные, но если спецификация не указана, можно проверить только общие условия корректности, такие как отсутствие сбоев.
Использование искусственных спецификаций расширяет диапазон этого подхода. Хотя мы не можем ожидать, что компьютер сможет самостоятельно определять намерение (цель) программы, он может попытаться его угадать. Один из способов сделать это - наблюдение за некоторыми тренировочными запусками, чтобы предсказать общие свойства программы, например, в виде «инвариантов» (свойств состояния) [13], конечного автомата [14], или алгебраические свойства [15]. Эти подходы, однако, не могут охватить полную функциональность программы, к примеру, [13] может выводить только предопределенные семейства предикатов, многие из которых являются простыми предикатами, такими как o! = null and x + у > 0. Нейронные сети предлагают интересную альтернативу этому подходу, так как они могут быть обученными имитировать функцию [16]. Теоретически нейронную сеть можно обучить путем показа образцов выполнения программ, чтобы она действовала как искусственная спецификация для программы. На практике такое обучение осуществить очень тяжело. Программы часто оперируют с дискретными областями, для которых сложно различить шаблоны.
Компромисс использования искусственных спецификаций - это дополнительные издержки в отладке. Когда исполнение во время производства нарушает такую спецификацию, сбой может быть вызван ошибкой, вызванной выполнением, или ошибка в тренировочных запусках программы, которые были отражены в прогнозах, или из-за к неточности прогнозов. Первые два случая выявляют ошибки (хотя второй случай потребует больше усилий для отладки). Однако провал в последнем - случай ложной тревоги (ложное срабатывание). Так как мы не знаем заранее, если нарушение является реальной ошибкой или ложным срабатыванием, нам нужно исследовать ее (отладка), что довольно трудоемко. Если оказывается ложным положительным, - усилия потрачены впустую. Несмотря на перспективность, исследования по использованию нейронных сетей в качестве искусственного спецификации немногочисленны. В [16] предложено использовать нейронную сеть и ГА для функционального тестирования. Здесь первая применяется для построения модели тестируемой программы, которая далее используется вместо этой программы при оценке качества тестов. Отметим, что в этом случае тестовые наборы генерируются, прежде всего на основе выходных данных, а не входных, как это делается при тестировании по методу «белого ящика». Для модели используется многослойная нейронная сеть прямого распространения, при обучении которой применяется алгоритм обратного распространения. Нейронная сеть обучается путем моделирования тестируемой программы. Выходные сигналы обученной нейронной сети используются в ГА при оценке значений фитнесс-функции, которая определяет качество тестовых наборов. Таким образом, ГА в процессе искусственной эволюции ищет входные тестовые наборы, качество которых оценивается с помощью нейронной сети (модели тестируемой программы). Фитнесс-функция определяется следующим образом:
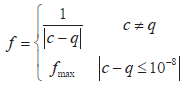 , где c - реальное значение, a g - целевое значение выходного сигнала тестируемой программы. Особи популяции (тестовые наборы) оцениваются с помощью указанной фитнесс-функции и порождают особи следующего поколения ГА с помощью генетических операторов репродукции, кроссовера и мутации. При этом используются следующие модификации арифметического кроссовера:
, где c - реальное значение, a g - целевое значение выходного сигнала тестируемой программы. Особи популяции (тестовые наборы) оцениваются с помощью указанной фитнесс-функции и порождают особи следующего поколения ГА с помощью генетических операторов репродукции, кроссовера и мутации. При этом используются следующие модификации арифметического кроссовера:
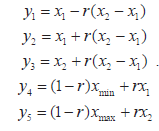
Здесь X; и x2 - родительские особи, отобранные с помощью оператора репродукции, ayby2, y3 - новые особи-потомки, полученные в результате выполнения генетического оператора кроссовера, и г является случайным числом, сгенерированным в диапазоне (0,1). Заметим, что переменные Xb x2 иуьy2,Уз принимают вещественные (не двоичные) значения, то есть используется вещественное кодирование значений входных переменных. Построенные ГА текущие особи включаются в тестовую последовательность, если для них значение фитнесс-функции достигает или превышает f,MX.
Разница между целевым значением и фактическим значением выхода тестируемой программы, которое определяется с использованием нейронной сети, используется для расчета фитнесс-значений особей в популяции. Если фитнесс-значение превышает или достигает максимального, то поиск останавливается и текущая особь принимается в качестве тестового набора для соответствующих выходов. Отметим, что тестовые наборы генерируются на основе значений выходных переменных.
Результаты показывают, что этот подход с высокой эффективностью может построить тестовую последовательность из выходных значений тестируемой программы. Эксперименты проводились только на небольших программах. Эффективность такого подхода может в дальнейшем оцениваться по более сложным программам. Выходные результаты модели на основе нейронной сети близки к реальным. Для минимизации этой разницы необходимо улучшить фитнесс-функцию.
В работе [17] для генерации тестовых наборов программы предложен подход на основе нечеткого расширения ГА (FAexGA), целью которого является поиск минимального множества тестовых наборов, которые могут обнаружить сбои при использовании видоизмененных версий оригинальной программы. При этом вероятность кроссовера варьируется с помощью нечетких контроллеров в соответствии с «возрастными интервалами», назначенными при жизни. Здесь вероятности кроссовера молодой и старой особи присваивается низкое значение, в то время как для другого возрастного интервала эта вероятность может быть высокой. Очень молодые потомки кроссовера имеют низкую вероятность того, что способствуют расширению пространства поиска. У старых потомков вероятность кроссовера также меньше и в конечном итоге вымирание помогает избежать преждевременной сходимости в локальном оптимуме или. С другой стороны, потомки среднего возраста часто используются при выполнении генетического оператора кроссовера.
Для определения вероятности кроссовера используется нечеткий логический контроллер (FLC). Переменные состояния FLC включают возраст и продолжительность жизни хромосом (родителей). Следует отметить, что высокое значение вероятности кроссовера способствует расширению пространства поиска, а низкое - улучшает сходимость. Хороший алгоритм обеспечивает баланс между этими характеристиками, который здесь достигается с помощью нечетких контроллеров путем назначения соответствующих значений вероятностей кроссовера.
Интерфейс фаззификации FLC включает переменные, определяющие возраст потомка. FLC присваивает каждому родительскому значению «молодой» (Young), «средний» (Medium) или «старый» (Old). Эти значения определяют принадлежность для каждого правила в базе правил FLC. В табл. 2 представлена нечеткая база правил, использованная в эксперименте. Каждая ячейка определяет одно нечеткое правило. Например, если родитель 1 и родитель 2 старые, то вероятность кроссовера низкая. При дефаззификации используется метод «центр тяжести» (COG), который вычисляет четкое значение для вероятности пересечения значения языковых меток, как показано в табл. 1.
Таблица 1
Нечеткие правила для вероятностей кроссовера
|
Parent 1 Parent2 |
“Young” |
“Middle-age” |
“old” |
|
“Young” |
Low |
Medium |
High |
|
“Middle-age” |
Medium |
High |
Medium |
|
“old” |
Low |
Medium |
Low |
Тестовые наборы соответствуют входам тестируемого программного обеспечения и представлены в виде вектора двоичных или непрерывных значений. Эти наборы инициализируются случайным образом в пространстве поиска возможных входных значений. Новые тестовые наборы генерируются с помощью генетических операторов и далее они оцениваются на основе способности обнаружения ошибок путем использования мутантов - искаженных версий исходной программы.
В качестве примера использовалось булево выражение, состоящее из 100 булевых атрибутов, и 3 логических оператора: И, ИЛИ и НЕ. Булево выражение строилось случайным образом, далее оценивался потенциальный тестовый набор путем генерации и проверки мутантов - искаженных булевых выражений. Каждый тестовый набор кодируется двоичной строкой длиной 100 бит. Для оценки качества тестовых наборов использовалась следующая фитнесс-функция:
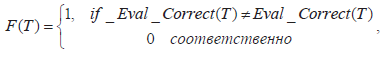
где T - 100-битная бинарная хромосома, представляющий один тестовый набор; Eval_Correct (Т) и Eval_Erroneous (Т) - булевы значения правильного и ошибочного выражения для данной двоичной строки Т. К сожалению, данный подход не апробирован для сложных реальных программ со входами, принимающими вещественные значения.
В целом генетические алгоритмы достаточно широко применяются при тестировании программного обеспечения как при структурном, так и при функциональном тестировании. Эксперименты показали, что генетические алгоритмы позволяют существенно повысить качество тестирования. Это направление, безусловно, является перспективным, но требует апробации на более сложных реальных программных проектах.
Анализ факторов, влияющих на процесс тестирования
Зависимость процесса тестирования от аппаратных характеристик устройства
Платформа Android является свободно - распространяемой бесплатной системой, и именно поэтому она завоевала такой большой процент рынка. Однако рынок занят не только «флагманскими» устройствами, но и устройствами более низких классов. Также, технологии в электронике и производстве постоянно совершенствуются, и поэтому мы видим ежегодное обновление линеек смартфонов всех производителей от корейского Samsung и тайваньского HTC до российского Highscreen и пакистанского QMobile. Оба этих фактора создают серьезную сегментацию на рынке устройств с фактически одной операционной системой, что создает дополнительные трудности в тестировании нативных Android - приложений, в отличие от того же iOS. Первым, на что стоит обратить внимание в процессе тестирования, являются аппаратные характеристики устройства, такие как:
1. Объем оперативной памяти RAM Низкий объем оперативной памяти, очевидно, может серьезно повлиять на скорость работы приложения. Но также полностью занятая RAM может привести к нестабильности приложения и нарушению его работы. Этот момент обязательно нужно учитывать в процессе тестирования, испытывая работу приложения в условиях занятой другими приложениями памяти. В этих случаях, помимо «вылетов» приложения, могут возникнуть проблемы функционального плана, ошибки и пропажа элементов пользовательского интерфейса, остановка фоновых сервисов приложения и т.д.
2. Объем внутренней памяти Этот параметр является довольно специфичным, поскольку внутренняя память в большом количестве требуется только для игровых и медиа - приложений. Однако, в случае, например, потокового воспроизведения аудио в условиях недостатка внутренней памяти, воспроизведение, очевидно, остановится, но в исходном коде приложения может быть не предусмотрен такой сценарий, и может возникнуть фатальная для приложения ошибка. Поэтому в тест - плане стоит предусмотреть такой вариант, выполняя тестирование с памятью, предварительно заполненной любой информацией.
3. Размер и разрешение экрана Важнейший параметр для любого приложения. От размера экрана зависит размер и положение элементов пользовательского интерфейса, поэтому надо уделить особое внимание устройствам с минимальными и максимальными параметрами экрана. На устройствах с минимальными параметрами экрана (для нынешнего рынка это порядка 3.5 дюймов и VGA - разрешение) возможны наложения элементов друг на друга, что делает невозможным использование этих элементов. На больших же экранах и разрешениях (для рынка сейчас это 12 дюймов и QHD - разрешение) элементы могут быть настолько малы, что пользователь просто не будет способен попасть по ним пальцем. Поэтому в процессе обеспечения качества ПО стоит учитывать эти параметры, и создавать элементы с динамическими размерами, которые подстраиваются под любые размеры и разрешения экрана.
4. Скорость и тип Интернет – соединения. Если в исходном коде приложения предусмотрено время отсечки запроса, приложение может просто не дождаться приходящей информации. Если скорость соединения чересчур мала, элементы интерфейса попросту не успеют загрузиться в отведенное время, что может привести к непредсказуемым последствиям, среди которых остановка приложения или невозможность использования приложения ввиду отсутствия части (или всех) элементов интерфейса. Тип соединения влияет в первую очередь на функционал приложения, предусматривающего загрузку пользовательской информации. Некоторые приложения позволяют пользователям запретить загрузку или фоновое обновление данных посредством мобильной сети, и это обязательно должно проверяться в процессе тестирования, поскольку от этого потенциально зависят расходы пользователя и, в конечном итоге, удовлетворение пользователя работой приложения.
5. Наличие дополнительных датчиков Самым важным из дополнительных датчиков смартфона является акселерометр, измеряющий ускорение свободного падения по трем осям, и из показаний вычисляющий ориентацию устройства в пространстве. Именно с помощью акселерометра интерфейс устройства меняется с портретного на ландшафтный при перевороте его на бок. Это устройство стоит учитывать в тестировании, если приложение имеет обе ориентации интерфейса, однако в данном случае акселерометр не играет ключевой роли, в отличие от самого процесса смены ориентации и вращения интерфейса, о котором речь пойдет ниже.
Остальные датчики – приближения, освещения, сердцебиения, гироскоп, барометр, термометр, устанавливаемые в современные смартфоны, используются в очень узкоспециализированных приложениях, и процесс их тестирования должен проходить в первую очередь на заводе - изготовителе данных датчиков.
Зависимость процесса тестирования и документирования ошибок от использования аппаратных и программных средств управления устройством
Можно выделить несколько действий, которые довольно распространены в процессе использования смартфона, и которые сам пользователь регулярно совершает.
- Сворачивание приложения.
Это очень распространенный случай возникновения ошибок, если приложение должно работать в фоновом режиме. При сворачивании оно может прекратить работу, или же работать неправильно.
- Выгрузка приложения.
Редкий случай возникновения ошибок, однако бывают случаи, когда при выгрузке приложение фактически продолжает работу, например, воспроизведение звука на выключенном плеере.
- Смена ориентации.
Типичной ошибкой является смещение элементов UI, выход их за рамки дисплея, и пр.
Во всех перечисленных случаях, если ошибка была найдена в конкретном месте и стабильно воспроизводится, в документации к ошибке в багтрекере обязательно указываются условия возникновения этой ошибки, помимо традиционного пути ее воспроизведения.
Взаимодействие приложения с ОС и другими приложениями. Особенности воспроизведения критических ошибок
Рассмотрим взаимодействие тестового приложения с ОС и другими приложениями на примере аудиоплеера, который использует стандартный звуковой сервис Android.
- Взаимодействие плееров.
Во взаимодействии аудиоплееров существует два случая – если плееры используют один и тот же звуковой сервис, или же стороннее приложение использует свой собственный. В первом случае очень важно знать, что приложение оповещает ОС о том, что оно начало проигрывать звук. В этом случае при включении аудиоплеера во время воспроизведения звука другим плеером, первый плеер прекращает воспроизведение звука, ставит его на паузу и отдает фокус на второй плеер, только что начавший воспроизведение. Однако если приложение не сообщает этого, оба плеера могут проигрывать звук одновременно, и это является распространенной ошибкой. В ряде случаев подобная ошибка возникает по вине стороннего приложения, и правильно будет сообщить его разработчикам о подобной ошибке.
- Приложения по умолчанию.
Из всех стандартных приложений Android, использующих звуковой сервис, лучшим примером может служить приложение «Телефон». Основу взаимодействия телефона и аудиоплеера составляет переключение фокуса между звонком и проигрыванием звука. Приложение телефона сообщает ОС о том, что поступил звонок – значит приложение, проигрывающее звук в данный момент должно отдать фокус телефону для проигрывания мелодии звонка, и поставить на паузу собственный звук. Когда приложение телефона сообщает ОС о том, что звонок завершен – приложение забирает обратно фокус и продолжает воспроизведение с того момента, когда этот фокус был отдан телефону. Если условно принять, что приложение телефона не имеет ошибок, то все связанные с этим ошибки полностью находятся на стороне тестируемого приложения.
- Взаимодействие с уведомлениями приложения.
Если тестируемое приложение имеет функцию уведомлений, очень важно правильно настроить работу таких уведомлений. Если уведомление имеет интерактивные функции, например, управление воспроизведением звука без включения самого приложения, могут возникнуть ситуации, при которых не работают сами интерактивные органы управления, или же при нажатии на уведомление приложение не открывается на полный экран.
- Взаимодействие с уведомлениями сторонних приложений.
Если во время воспроизведения звука тестируемым приложением приходит уведомление от любого стороннего приложения, лучшим вариантом является приглушение звука без паузы в воспроизведении, или же короткая передача фокуса уведомлению с постановкой на паузу и обратно. Однако возникают случаи, когда приложение отдает фокус уведомлению, но не забирает обратно. Соответственно, воспроизведение ставится на паузу, что является весьма неудобным для пользователя.
Таким образом, тестирование нативных приложений на Android является достаточно трудо - и ресурсоемким процессом ввиду серьезной сегментации рынка, и требует скрупулезного подхода в тестировании. Однако, если выделить конкретную функциональность, в которой проявляется ошибка и использовать вспомогательные средства для сбора статистики, разработка и тестирование приложения становятся достаточно простыми для создания по - настоящему отличного приложения, которое принесет пользователям радость от использования. Для разработки мобильного ПО не требуются билд - серверы, собирающие приложения, какие используются для сборки веб - приложений, что сокращает количество посредников между программистом и пользователем и исключает возможные (и нередкие) ошибки в сборке. А ошибки в коде становятся лишь ситуациями, пригодными для оперативного обсуждения и исправления.
Существует множество различных методологий разработки программного обеспечения. Выбор определённой методологии зависит от различных факторов: сложности, объемности проекта, количества человек, участвующих в реализации проекта. Поэтому перед началом работы перед разработчиком встает вопрос о выборе техники разработки программного обеспечения. Среди методов создания программного продукта различают: Agile (XP, Lean, Scrum, FDD др.), Cleanroom, DSDM и др.
К перечисленным методам также относится разработка через тестирование (test - drivendevelopment, TDD). Изобретателем этой методологии считается Кент Бек. Его техника разработки программного обеспечения основывается на повторении коротких циклов разработки, в которых сначала пишется модульный тест, позволяющий покрыть желаемое изменение, затем пишется код, который выполняет действия, с помощью которых проходится данный тест. После успешного прохождения теста осуществляется доработка (рефакторинг) написанного кода
Таким образом, методология разработки программного обеспечения через тестирование имеет преобладающее количество преимуществ и, несмотря на наличие недостатков, намного повышает продуктивность работы. Благодаря отличительной особенности метода тестирования, которая позволяет с легкостью вносить изменения в программный код, программисты могут не бояться воплощать в жизнь свои идеи по улучшению программного продукта. Кроме того, использование данной техники значительно снижает плотность дефектов в разрабатываемом программном обеспечении.
Список использованных источников
- Абрамян, Г.В. Методология формирования и реализации систем интеллектуальной поддержки принятия решения при управлении предприятиями сферы финансов, экономики и образования / Г.В. Абрамян, Г.Р. Катасонова // Перспективы и пути развития образования в России и в мире: Материалы II Международной научно-практической конференции. Махачкала – 2013. - С. 14-21.
- Алексеев Д.М., Кутняк Н.А. // Защита программного обеспечения от несанкционированного использования // В сборнике: «Синтез науки и общества в решении глобальных проблем современности», часть 3, г. Пенза, 18 февраля 2016 г. С. 21 - 22.
- Калязина Д.М., Соколов Н.Е., Федорова А.Е., Обоснование выбора платформы для обучения студентов экономических вузов основам Business Process Management // Известия высших учебных заведений. Поволжский регион. Гуманитарные науки, 2014. № 4, С. 211-218.
- Калязина Д.М. Разработка подсистемы организационного обеспечения информационной системы управления бизнес-процессами (на примере ИС RUNA WFE) // Государство и бизнес. Современные проблемы экономики Материалы VII международной научно-практической конференции, РАНХиГС Северо-Западный институт управления. – СПб.: Издво «Стратегия будущего», 2015. – С. 173-176.
- Кокунов В.А., Соколов Н.Е., Методология и технология проектирования информационных систем / Н.Е. Соколов, В.А. Кокунов – СПб. – Издво «СкифияПринт». – 2014.
- Соколов Н.Е., Соколова Е.В. Возможности и ограничения информационных технологий обучения /Н.Е.Соколов, Е.В.Соколова // Новая наука: Современное состояние и пути развития. – 2015. № 42. – С. 101-103.
- Тестирование Дот Ком, или Пособие по жестокому обращению с багами в интернет - стартапах. / Р.Савин— М.: Дело, 2017. —312 с.
- Федорова А.Е. Архитектура информационных систем поддержки процесса повышения показателей публикационной активности в вузе // Государство и бизнес. Современные проблемы экономики Материалы VII международной научнопрактической конференции, РАНХиГС СевероЗападный институт управления. СПб. – Издво «Стратегия будущего», 2015. – С. 176-178.
- Тестирование программного обеспечения - [Электронный ресурс]: Режим доступа: https://ru.wikipedia.org/wiki/Тестирование _ программного _ обеспечения
- Тестирование программного обеспечения -основные понятия и определения - [Электронный ресурс]: Режим доступа: http://www.protesting.ru/testing/
- Introduction to Android [Электронный ресурс] / Google, inc., 2016 - Режим доступа: http: // developer.android.com / guide / index.htm

- Организационный стресс в условиях внедрения инноваций
- Анализ внешней и внутренней среды организации. Понятие анализа среды организации
- Рекурсивные и итерационные алгоритмы: особенности и примеры использования (Понятие алгоритма, итерационного, рекурсивного алгоритмов)
- История развития программирования в России (Возникновения программирования)
- Перевод реалий
- Употребление перфекта в английском языке
- Публичная власть
- Организация маркетинга на предприятии (теоретические аспекты)(Сущность маркетинговой деятельности: возникновение, цели, задачи, функции)
- Характеристики и типы мониторов для персональных компьютеров (История развития мониторов)
- Финансовые ресурсы фондов и ассоциаций
- Федеральные налоги с юридических лиц и их экономическое значение
- Понятие и виды государственных пенсий