
Распределенная технология обработка информации
Содержание:

Введение
Одним из важнейших направлений интеграции сетевых технологий является распределенная обработка данных, позволяющая повысить эффективность удовлетворения информационной потребности пользователя и обеспечить гибкость и оперативность принимаемых им решений.
Под распределенной обработкой информации понимается комплекс операций с информацией (традиционно описываемый термином «обработка информации»), проводимый на независимых, но связанных между собой вычислительных машинах, предназначенных для выполнения общих задач.
Системы распределенной обработки информации (или распределенные вычислительные системы) в виде многомашинных вычислительных комплексов и компьютерных сетей представляют собой одну из наиболее прогрессивных форм организации средств вычислительной техники.
Появление и широкое распространение систем распределенной обработки информации обусловлено, с одной стороны, ускоренным развитием микроэлектроники, снижением стоимости вычислительных средств, увеличением их производительности при уменьшении габаритов, а с другой стороны - повышением требований к производительности, надежности и эффективности вычислительных систем, предъявляемых сферами их применения. Важно отметить, что распределение (или разделение) не идентично параллелизму. Распределение видов обработки информации состоит в том, чтобы поручить их вычислительным машинам, наилучшим образом приспособленным к этому. Параллелизм же подразумевает понятие одновременности обработки информации. При этом распределение позволяет в ряде ситуаций проводить эффективную параллельную обработку информации при выполнении больших объемов параллельных вычислений. Таким образом, в общем случае распределение не подразумевает параллелизма, но возможность «распараллелить» распределенную обработку информации существует.
1.1. Основные определения
В общем случае при организации работы пользователей компьютерной сети с информационными ресурсами, что распределены по различным компьютерам, нужны 3 составляющие:
– программа, которая установлена на компьютере пользователя, что может осуществлять сетевые запросы с целью получения объектов, и предназначенная для обработки (к примеру, просмотра, изменения и печати документа);
– программа, что установлена, на компьютере, где расположен конкретный информационный объект, которая осуществляется по запросу поиск, пересылку объекта, упорядочивание доступа нескольких пользователей к нему;
– правила (протокол) для взаимодействия между такими программами.
Технология выполнения взаимодействия, в которой одна из программ запрашивает выполнение для какой-либо совокупности разных действий ("запрашивает услугу"), другая ее выполняет, является технологией "клиент-сервер".
Участники взаимодействия называются соответственно сервером и клиентом. Достаточно часто клиентом (сервером) называют компьютеры, на котором функционирует и то, и иное клиентское (серверное) программное обеспечение. [1]
Следует особо отметить, набор действий, понимаемых как специальная запрашиваемая услуга, – не обязательно чтение (или получение) объекта. В этом числе может быть сохранение (или запись), пересылки объекта и т.п.
При большом числе персональных компьютеров (десятки, сотни, тысячи) предприятия полагаются чаще всего на сети модели типа «клиент-сервер».
Упрощенно это можно считать, что отдельный компьютер в такой сети подключается к одному и нескольким мощным компьютерам, что называются серверами.
Сервером называется компьютер, или выполняющаяся программа на нём, которая предоставляет клиентам разный доступ к общим ресурсам или управляет этими ресурсами.
Клиентом называется пользователь (получатель) услуг или ресурсов, что предоставляет сервер (рисунок 1).
СЕРВЕР
Рисунок 1 – Структура «клиент-сервер»
В серверных сетях именно серверы оснащены мощными процессорами и сетевой ОС.
Роль серверов состоит также в обеспечение централизованного уровня защиты и управлении трафиком, в предоставление клиентам разных ресурсов: [11]
– информации;
– приложений;
– доступа к устройствам для совместного пользования (к примеру, принтерам).
В рассматриваемой среде в роли клиентов часто выступают настольные ПК (ПК, а не разные неинтеллектуальные терминалы) с управлением операционной системы типа Windows для настольных ПК.
Как правило, каждый клиент использует собственные мощности для вычислений и обработки информации, полученной с сервера, но полагается также на сервер в части использования необходимых данных или приложений. Такое распределение ролей при обработке информации носит имя клиентской и серверной обработки.
Наряду с успешным работы в собственной «родной» среде, сеть модели «клиент-сервер» может работать с микрокомпьютерами или мэйнфреймами. Именно такая гибкость в сочетании с достаточно низкой стоимостью и определяет привлекательность клиент-серверных сетей.
Выполняя работу в такой среде на ПК-клиенте, можно «вкушать плоды» 3-х разных методов по обработке информации:
– взаимодействия с иными ПК сети;
– автономной работы;
– подключения к серверу и мэйнфрейму для определения доступа к информации.
1.2. Характеристика технологии «клиент-сервер»
То, что ПК стоят на своих рабочих местах, местах возникновения и обработки данных, дало возможность распределять их ресурсы непосредственно по отдельным функциональным направлениям деятельности, а также изменять технологию обработки информации в направлении ее децентрализованной обработки.
На рисунке 2 показан принцип распределенной обработки информации:

Рисунок 2 – Принцип распределенной обработки информации
Распределенная обработка позволяет повысить эффективность для удовлетворения изменяющейся потребности в информации работника и, тем самым, обеспечивать гибкость принимаемых решений.
Основные преимущества такой распределенной обработки информации в следующем: [6]
– увеличении количества удаленных взаимодействующих пользователей, что выполняют функции обработки, сбора, хранения, передачи данных;
– снятии нагрузок с централизованной БД путем распределения нагрузки на другие ПК;
– обеспечении доступа пользователя к вычислительным ресурсам компьютерной сети;
– обеспечении процесса обмена данными для удаленных пользователей.
За время исследования технологий распределенной обработки информации выделены несколько технологий (рисунок 3).
Реальные распределенные АИС, как правило, строятся на основе сочетания всех указанных технологий.
Рисунок 3 – Типы технологий распределенной обработки
Системы на базе технологии «клиент-сервер» (рисунок 4) развились из самых первых централизованных АИС на основе мэйнфреймов, а также со временем получили наиболее широкое применение в корпоративных АИС. [18]
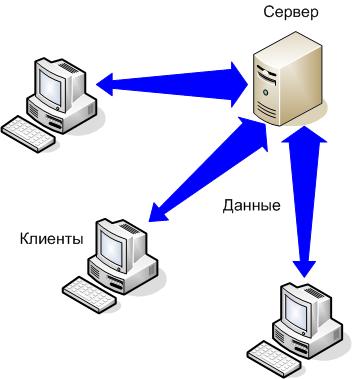
Рисунок 4 – Принцип технологии «клиент-сервер»
При реализации технологии отступают от принципа создания распределенных систем, а именно, отсутствия центрального узла системы.
Принцип централизации обработки и хранения данных является самым базовым принципом клиент-серверной технологии.
Можно выделить также следующие идеи, что лежат в основании клиент-серверной технологии:
– общие данные для всех пользователей, что располагаются на нескольких серверах;
– совокупность пользователей, которые осуществляют доступ к информации.
Важное значение для данной технологии имеют понятия клиента и сервера.
Под сервером понимается в широком смысле любая система, процесс, ПК, владеющие каким-то вычислительным ресурсом (временем процессора, памятью, файлами). [6]
Клиентом называется специальная система, процесс, ПК, пользователь, которые выполняют запрос к серверу для применения ресурса.
Одной из важнейших особенностей технологии клиент-сервер является значительное снижение сетевого трафика непосредственно при реализации запросов.
Каждый клиент посылает запрос на сервер на выборку информации, запрос обрабатывается определенным сервером, и клиенту сразу передается не полностью вся таблица, а только результат запроса.
Вторым преимуществом является возможность выполнения хранения бизнес-логики (к примеру, правил ссылочной целостности, а также ограничений на данные) на сервере, позволяющий избежать дублирования программного кода в различных приложениях, использующих одну и ту же базу данных.
Построение быстродействующих АИС обеспечивают технологии так называемой репликации данных.
Под репликой понимается копия БД, которая размещена на другом ПК сети для автономной обработки пользователями.
Основная идея заключается в процессе, когда пользователи работают полностью автономно с данными, растиражированными по базам данных, что размещены на локальных ПК.
Производительность работы повышается из-за специальных отсутствий необходимости обмена информации по сети.
При реализации технологии репликации ПО дополняется функциями тиражирования информации, их структуры, а также системной информации распределенной системы.
При этом, однако, возникают две проблемы реализации одного из принципов функционирования распределенных систем — принципа непрерывности согласованного состояния данных [14]:
• обеспечение согласованного состояния данных во всех репликах БД;
• обеспечение согласованного состояния структуры данных во всех репликах БД.
Обеспечение согласованного состояния данных, в свою очередь, основывается на реализации одного из двух принципов [14]:
• принципа непрерывного размножения обновлений;
• принципа отложенных обновлений (обновления реплик могут быть отложены до специальной команды или ситуации).
Принцип непрерывного размножения обновлений является основополагающим при построении так называемых систем реального времени (например, систем управления воздушным движением, систем бронирования билетов пассажирского транспорта и др.), где требуется непрерывное и точное соответствие реплик во всех узлах и компонентах распределенных систем в любой момент времени. Реализация этого принципа заключается в том, что любая транзакция считается успешно завершенной, если она успешно завершена на всех репликах системы. [2]
Унификация взаимодействия разного рода прикладных компонентов с определенным ядром ИС в виде серверов, позволила выработать аналогичные понятия и по интегрированию локальных разрозненных БД под управлением некоторых настольных СУБД.
Эта технология получила названием объектное связывание данных.
Технология объектного связывания решает задачу обеспечения полного доступа с одной локальной БД, которая открыта одним пользователем, к данным другой БД.
Технология объектного связывания основана на протоколе под названием ODBC, который является классическим стандартом доступа к информации БД клиент-серверных БД, а также к самым разным данным, что находятся под управлением СУБД.
В таком определении следует уточнить 2 отличительных архитектурных особенности.
Во-первых, система состоит из множества узлов для приема запросов и непустого множества для узлов данных.
Узлы данных обладают разными средствами для хранения информации, а узлы приема – нет. В узлах приема для запросов лишь выполняются все программы, реализующие пользовательский интерфейс с доступом к данным, хранящимся на узлах данных. [6]
Вторая особенность состоит в том, что все узлы логически представляют собой некоторые независимые компьютеры.
Также, у такого узла будет собственная основная или внешняя память, установлена также собственная операционная система (ОС) (может быть, одна для всех узлов, а возможно, и нет), также имеется возможность выполнять разные приложения.
Все узлы связаны в компьютерную сеть, а не входят в одну мультипроцессорную конфигурацию. Важно также подчеркнуть слабую связанность разных процессоров, которые обладают своими собственными операционными системами.
Система физически может распределяться по узлам данных уже на основе фрагментации или репликации данных.
При наличии схем распределенной системы каждое отношение фрагментируется в вертикальные или горизонтальные разделы.
Горизонтальная фрагментация также реализуется при использовании операции селекции, что направляет каждый кортеж определенного отношения в один с разделов, руководствуясь специальным предикатом фрагментации.
А при вертикальной фрагментации такое отношение делится на разные разделы при использовании операции проекции.
За счет выполнения фрагментации данные приближаются также к месту их самого интенсивного использования, что также потенциально снижает затраты их на пересылки; уменьшаются размеры отношений, что участвуют в пользовательских запросах.
Для ослабления отличительных особенностей каждой распределенной системы создается параллельная система. Не существует четкого и конкретного разграничения между распределенными и параллельными системами. В частности, все архитектуры параллельных систем без используемых совместно ресурсов, которые обсуждаются ниже, очень схожи со слабо распределенными связанными системами. [9]
В параллельных же используются самые новейшие многопроцессорные архитектуры, на основе такого подхода создаются разные высокопроизводительные серверы высокой доступности, стоимость для которых значительно ниже их эквивалентных систем с мэйнфреймами.
Параллельную систему также можно определять как СУБД, реализованные на мультипроцессорном ПК. Такое определение подразумевает в себе наличие множества альтернатив, для которых спектр варьируется от непосредственного использования существующих СУБД с переработкой только интерфейса к ОС до изощренных комбинаций разных алгоритмов параллельной обработки, функций БД, приводящих к новым архитектурам.
Решение также заключается в применении полномасштабного параллелизма, чтоб усилить мощность отдельных сетевых компонентов путем интеграции их в целостную систему на базе соответствующего программного обеспечения для параллельных БД.
Важное значение имеет и применение стандартных аппаратных компонентов, чтобы иметь возможность с самым минимальным отставанием использовать разные результаты постоянных технологических и современных усовершенствований. [8]
В ПО базы данных могут предусматриваться 3 вида параллелизма, присущие приложениям с интенсивной обработкой данных: [2]
– Межзапросный параллелизм предполагает выполнение одновременное множество запросов, относящихся к самым разным транзакциям.
– Под внутризапросным параллелизмом также понимается одновременное выполнение нескольких сразу операций (к примеру, операций выборки), что относятся к одному и тому запросу. Внутризапросный и межзапросный параллелизмы реализуются на основе разделения данных, аналогично горизонтальному фрагментированию.
Внутриоперационный параллелизм означает параллельное выполнение только одной операции в виде множества субопераций с использованием, в дополнение к некоторой фрагментации данных, также фрагментации функций.
Распределение (включая репликацию и фрагментацию) данных по множеству разных узлов невидимо для всех пользователей. Это свойство также называется прозрачностью.
Технологии распределенных/параллельных систем обработки данных распространяет основополагающую для управления концепцию независимости данных в среду, где данные эти распределены и реплицированы с помощью множества компьютеров, что связаны сетью.
Это также обеспечивается за счет разных видов прозрачности: [7]
– прозрачность сети;
– прозрачность репликации;
– прозрачность фрагментации.
Вопросы прозрачности также более критичны для распределенных, нежели для параллельных систем. Этому есть 2 причины:
– многопроцессорные системы, для которых и реализуются параллельные системы, могут функционировать под управлением одной единой операционной системы;
– разработки ПО на параллельных системах также поддерживаются языками для параллельного программирования, которые обеспечивают некоторую степень прозрачности.
В таких распределенных систем приложения и данные, которые осуществляют доступ к ним, также могут быть локализованы для одного и того же узла, благодаря чему исключается (сокращается) потребность в использовании удаленного доступа к данным, что характерна для систем телеобработки используемых данных в режиме выполнения разделения времени.
Поскольку на каждом из узлов выполняется меньше приложений, а также хранится меньшая порция БД, можно сократить также и конкуренцию при доступе к ресурсам.
Высокая производительность – это одна из самых важных целей, на достижение которой постоянно направлены технологии параллельных систем обработки данных. И, как правило, она часто обеспечивается за счет некоторого сочетания взаимно дополняющих решений, таких как использование операционных систем, что ориентированы на поддержку оптимизация, параллелизм, балансировка нагрузки.
Наличие ОС, "осведомленной" о специфических надобностях баз данных (к примеру, относительно управления буферами), значительно упрощает реализацию функций нижнего уровня и способствует значительному снижению их стоимости.
Распределенные и параллельные системы предоставляют ту функциональность, что централизованные, когда не считать того, что работают они в среде, где информация распределена по узлам компьютерной вычислительной сети или же многопроцессорной системы.
Как упоминалось, пользователи могут ничего не знать вообще о распределении данных.
Архитектуры параллельных систем также варьируются между двумя точками, называемыми архитектура без разделяемых ресурсов и архитектура с разделяемой памятью. Промежуточную позицию занимает также архитектура с разделяемыми дисками.
1.3.Понятия прикладных протоколов и стандартов в системах распределенной обработки данных
Необходимо различать также понятия сетевых приложений и специальных протоколов прикладного уровня, которые всегда используются в системах распределенной обработки данных.
Протокол прикладного уровня является частью (весьма большой) для сетевых приложений. Рассмотрим 2 примера.
Web является специальным сетевым приложением, что позволяет пользователям получать web-документы с помощью запроса и состоящим из разного множества компонентов, включая также стандарт формата документов (тип HTML), браузеры (Microsoft Internet Explorer и другие), web-серверы (к примеру, Apache, Microsoft и Netscape), протоколы прикладных уровней.
Протокол прикладного уровня для сервиса web носит название «протокол передачи гипертекста» (HTTP) и описывает форматы и порядок обмена разными сообщениями между сервером и клиентом. Таким образом, HTTP – это лишь часть web-приложения.
В качестве другого примера рассмотрим приложение для электронной почты. Такая почта Интернета состоит из множества компонентов: разных почтовых серверов, содержащих и почтовые ящики пользователей, и программы для просмотра, создания электронных писем, стандарты, описывающие структуры электронных писем, а также протоколов прикладного уровня, что регламентируют порядок обмена сообщениями между серверами и с оконечными совокупностями пользователей, а также и интерпретацию полей, с которых состоят все электронные письма.
Главным протоколом прикладного уровня электронной почты является протокол передачи сообщений (SMTP). Как видно, SMTP – лишь часть (хотя и большая) структуры приложений для электронной почты.
Протоколы прикладного уровня также определяют способ обмена разными сообщениями между 2-я процессами, выполняющимися с разными оконечными системами. Обычно протокол определяет такие элементы:
– типы используемых сообщений;
– синтаксис каждого с типов сообщений, что описывают поля сообщения;
– семантику полей, смысл информации, что содержится в каждом с полей сообщения;
– правила, которые описывают события, что вызывают генерацию сообщений.
Стоит отметить, что некоторые из протоколов для прикладного доступа (HTTP, SMTP) являются официально документированными. Это означает, что разработчик нового браузера также будет следовать стандарту, а браузер сможет получать все документы с разных web-серверов, построенных по этому стандарту.
Тем не менее также существует множество протоколов и прикладного уровня, что не стандартизированы и используются при этом для поддержки коммерческих проектов. В частности, это также характерно и для Интернет-телефонии.
В области интерфейсов для систем обработки данных для соединений типа клиент-сервер происходит процесс стандартизации.
Имея несколько альтернативных типов стандартов, организации, что внедряют в свои среды управления информацией технологию «клиент-сервер», могут выбрать те что решения, наиболее полно соответствуют их конкретным потребностям.
Процесс стандартизации для доступа к «клиент-сервер» приобрел наибольшую активность еще в конце 80-х – начале 90-х годов. В 1989 г. создана группа ученых SQL Access Group (SAG), которая представляет собой консорциум с 42 компаний, которые входят крупнейшие поставщики разных СУБД.
Одной из главных задач SAG было определение разных спецификаций форматов или протоколов (FAP) для коммуникаций в системах БД «клиент-сервер» на основании спецификаций Удаленного доступа к БД (RDA), разработанных Международной организацией для стандартизации.
Стандарт RDA также описан в документе ISO/IEC 9379, который состоит из 2-х частей:
– общая модель, сервис, протокол;
– специализация SQL.
Как раз вторая часть данного документа и стала базой спецификаций FAP, что предложена группой SAG.[3]
Спецификации FAP также включают описание структуры разных сообщений и протокола для управления информацией, что используются для связи между разными компонентами, обменивающимися информацией, к примеру, таких управляющих структур, что сообщают данному узлу то, что передается единица информации с указанным номером его блока, или подтверждают конечный прием сообщения с номером.
Примерно в это же время фирма IBM, единственный крупный поставщик для средств, не вошедший в группу SAG, вводит стандарт "Архитектура для распределенных реляционных БД", никак не согласуя с ISO RDA.
Исходной целью DRDA являлась интеграция БД в рамках системной архитектуры для приложений, предложенной IBM.
Но изначально SAA рассматривалась как основное средство интеграции для 4-х платформ IBM:[7]
– VM;
– OS/400;
– MVS;
– OS/2.
Используя SAA и DRDA, можно объединять менеджеры БД для этих платформ (SQL/DS, DB2, OS/400 Data Manager, OS/2) в единую модель типа «клиент-сервер».
В 1990 году IBM предложила архитектуру для хранилища информации, в которой DRDA отведена ключевая роль для интеграции баз данных типа «клиент-сервер», управляемых различными программными продуктами, а также ряд поставщиков средств БД объявили о своей поддержке стандарту DRDA.
Таким образом, уже в начале 1992 года в области стандартизации для доступа к БД «клиент-сервер» образовалось 2 "лагеря" – SAG, что опирался на стандарт RDA, а также сторонники DRDA, что был ориентирован на платформы IBM.
В 1992 г. возникли также сразу два конкурирующих стандарта – IDAPI и ODBC, они оба основаны на интерфейсе для уровня вызовов, предложенном SAG.
Первый – Открытый интерфейс доступа к БД (ODBC) был введен и продвигался компанией Microsoft. Основной целью Microsoft было использование приложениями Microsoft Windows доступа к БД, основанным на SQL, с помощью стандартизованного интерфейса «клиент-сервер» (рисунок 5).

Рисунок 5 – Архитектура ODBC
Главное назначение ODBC – это превратить SAG CLI с абстрактного обобщенного стандарта непосредственно в живую среду, где он может использоваться в приложениях на ПК.
Стандарт IDAPI сменил другой корпоративный стандарт компании Borland – ODAPI, который был частью специальной Компонентной объектной архитектуры фирмы Borland.
Стандарт IDAPI также обеспечивает поддержку серверов типа dBase (рисунок 6).
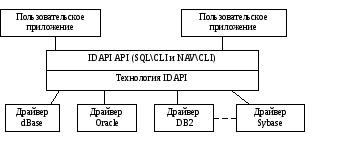
Рисунок 6 – Техническая архитектура IDAPI
1.4. Управление одновременным доступом
Если несколько пользователей осуществляет одновременно доступ (на запись и чтение) к совместно используемой системой обработки данных, то для поддержки такого согласованного состояния данных также требуется синхронизовать доступ.
Сама синхронизация достигается путем использования алгоритмов управления для одновременного доступа, что гарантируют следование критериям корректности.
Доступ пользователей к информации инкапсулируется в рамках транзакций, которые на нижнем уровне будут выглядеть как последовательности разных операций чтения или записи данных.
Алгоритмы по управлению одновременным доступом обеспечивают также соблюдение свойства изолированности для выполнения транзакций, которое также заключается в том, что все воздействия одной транзакции на конкретную систему обработки данных вовсе не будут зависеть (будут изолированы) от иных транзакций, пока первая транзакция не будет завершена.
Самые популярные алгоритмы управления для одновременного доступа основаны на использовании механизма блокировок. В таких системах всякий раз, когда пытается получить транзакция доступ к какой-то единице памяти (странице), на эту единицу также накладывается блокировка в одном с режимов – совместном или монопольном.
Блокировки накладываются также в соответствии с правилами совместимости блокировок, исключающими разные конфликты чтение-запись, запись-чтение, запись-запись.
Для распределенных систем часто возникает проблема распространения свойств сериализуемости и алгоритмов для управления одновременным доступом в распределенную среду.
В этих системах операции, относящиеся для одной транзакции, могут также выполняться на нескольких других узлах, где располагаются нужные данные.
В таком случае наибольшую сложность будут представлять принципы обеспечения сериализуемости. Эта сложность также связана с тем, что для разных узлов порядок сериализации одинаковых множеств транзакций может оказаться самыми различным. Поэтому выполнение такого множества распределенных транзакций является сериализуемым только тогда, когда выполнение данного множества транзакций в каждом узле является сериализуемым и порядок сериализации таких транзакций во всех узлах одинаковый.
Алгоритмы управления одновременным распределенным доступом поддерживают такое свойство, называемое глобальной сериализуемостью. В алгоритмах, которые основаны на блокировках, для этого используется один из 3 методов: [7]
– централизованное блокирование;
– блокирование первичных копий;
– распределенное блокирование.
Общий побочный эффект для всех алгоритмов управления доступом посредством блокирования – это возможность тупиковых ситуаций. Задача обнаружения или преодоления тупиков сложна особенно в распределенных системах.
В первом разделе курсовой работы рассмотрены основные понятия теории распределенной обработки информации, дана характеристика технологии «клиент-сервер», указаны ее положительные и отрицательные стороны, а также другие понятия, связанные с распределенностью обработки информации.
2. Практическое применение систем распределенной обработки данных на примере СУБД SQL Server
2.1. Описание СУБД SQL Server
СУБД SQL Server является семейством продуктов, которые разработаны для непосредственного сохранения данных и их обработки в системах для обслуживания коммерческих веб-компонентов.
SQL Server очень прост для использования, он также широко применяется для решения задач по обработке информации в сверхсложных системах.
Он также очень популярен для отдельных пользователей, которые применяют надежный сервер БД для разных личных задач.
Непосредственно в состав СУБД SQL Server входят такие 2 основные службы, что предназначены для применения на платформе .NET, а также систем с традиционной клиент-серверной структурой.
Первая служба является высокопроизводительным реляционным ядром для БД, которое дает возможность обеспечивать масштабируемость систем, которые созданы непосредственно на его основании. [2]
Вторая служба – это Server Analysis Services – инструмент, который предоставляет множество методов для реализации анализа данных, что имеются в хранилищах информации и разных системах для принятия решений.
Классическая архитектура «клиент-сервер» в базах данных состоит из таких двух компонентов:
– непосредственно СУБД;
– клиентское приложение.
Такая архитектура каждого клиентского приложения, предоставляет определенный пользовательский интерфейс с выполнением работы в СУБД SQL Server, а также является «толстым» клиентом.
Платформа .NET является распределенной средой, где разнообразные и слабо связанные программируемые интернет-сервисы выполняются на различных серверах.
Стоит отметить, что для такой распределенной вычислительной системы все клиентские приложения являются в данном случае «тонкими» клиентами, что обеспечивают доступ к информации СУБД SQL Server посредством вспомогательных веб-сервисов, к примеру, с помощью Internet Information Services.
Классическим примером «тонкого» клиента являются веб-браузеры, которые установлены на ПК клиентов.
На рисунке 7 показан доступ клиентов к серверу:
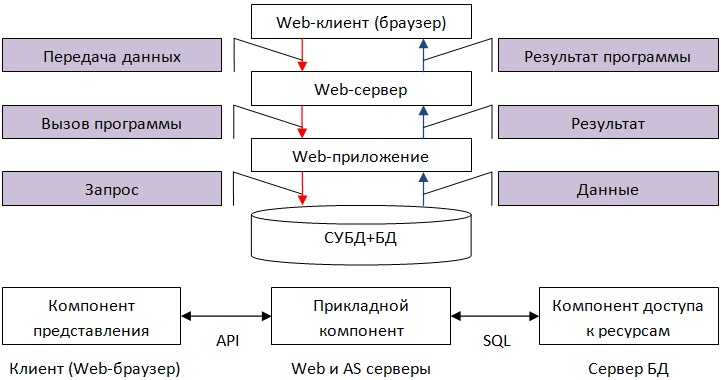
Рисунок 7 – Архитектура СУБД SQL Server
Реляционным ядром SQL Server считается реляционная СУБД, которая имеет возможность хранить и осуществлять управление данными прямо в реляционных таблицах. [8]
Несколько БД не могут применять одновременно операции с сервера. Но, при выполнении оптимизации производительности можно добиться значительного повышения отказоустойчивости для всех файлов данных, а также файлов журнала, как правило, размещаемых на разных дисках с данными.
Для размещения информации и данных используемого журнала используется RAID-массив.
При физическом размещении информации, а также индексов в СУБД SQL Server резервируется дисковое пространство, что занято файлом данных – отдельными ячейками размером 64 Кб.
Такие блоки являются экстентами. Все экстенты состоят с восьми специальных страниц, расположенных последовательно объемом каждая в 8 Кб.
Экстенты бывают следующих видов (рисунок 8):
Рисунок 8 – Типы экстендов
Однородные – это экстенты, которые принадлежат одному объекту, смешанные – принадлежат многим объектам.
Страницей является минимальный объем дискового пространства, выделяемого SQL Server для непосредственного хранения данных. [9]
Отметим, что одна страница в размере занимает 8 кб. Как правило, эта информация располагается в виде строк, что размещены по несколько пар в странице.
При этом все строки могут содержать информацию объемом до 8060 байт. Порядок размещения информации прежде всего может зависеть от того, как определяется в таблице индекс.
MS SQL Server является реляционной СУБД. То есть, все данные в базах хранятся в плоских 2-мерных таблицах.
В основании реляционных систем лежит математический аппарат – алгебра отношений.
Важной особенностью всех БД является тот факт, что в БД помимо самой информации хранятся и описания данных – так называемые метаданные базы данных.
Данный факт позволяет уменьшить общую зависимость программ от информации на логическом уровне.
Самым главным объектом реляционных БД являются таблицы.
Таблица в себе содержит произвольное число строк или записей, в которой и хранятся данные. [6]
Фактически число строк в таблице будет ограничиваться объемом внешней памяти, которая доступна для хранения информации базы данных в постоянной памяти.
Также, разумеется таблица может являться и пустой, то есть не содержать информации.
Стоит отметить, что в рассматриваемой СУБД есть возможность структуризации таблиц.
То есть, разбивать таблицу по некоторому критерию с объединением информации в новые массивы (рисунок 9):

Рисунок 9 – Пример структуризации БД
Соответственно реляционной модели данных каждая строка одной таблицы имеет одинаковую структуру.
Все они состоят с столбцов, которые иногда называются полями. Таблица должна в себе содержать как минимум 1 столбец.[3]
Данные таблицы выбираются при использовании оператора SELECT, который является основным в языке структурированных запросов.
Как правило, выбираются с таблица далеко не все строки, а только те, что соответствуют критерию, заданному в данном операторе. На логическом уровне – те данные с таблицы, что реально нужны клиенту для решения им задачи.
С помощью оператора SELECT есть возможность выбрать данные не лишь из одной таблицы, а и с нескольких таблиц, применяя операцию соединения.
Результат такой выборки называют набором данных.
Самой основной характеристикой столбца таблицы БД является его тип. Тип данных в языке SQL имеет определенное имя. Такие типы данных могут предварительно быть определенными в системе, а также их иногда считают системными.
Это также могут являться данные, определенные некоторым пользователем по аналогии с пользовательскими типами данных в языках программирования.
В некоторых системах используют еще один термин пользовательских форматов данных – домен.
Типы данных – это числовые (дробные, целочисленные с фиксированной точкой), логические, строковые, типы данных, а также форматы даты и времени.
В нынешнее время существует формат данных, обычно называемый бинарным большим объектом, который позволяет хранить большие по объему используемой памяти данные –изображения, звук, форматированные тексты, видео.
Непосредственно по мере развития отрасли программирования в мире ПО появляются новые форматы данных, к примеру, XML, или пространственные типы.
Все они поддерживаются в СУБД MS SQL Server.
Формат данных в программировании часто определяет множество значений и множество операций для столбца, вообще для всех элементов данных в программной среде.[16]
К примеру, для целочисленных форматов множеством допустимых значений считают множество целых чисел для определенного диапазона. Диапазон представления таких чисел определяется числом байтов, отводимых под хранения целого числа.
Множеством допустимых операций, которые используются для всех числовых форматов данных: целочисленных и дробных, считаются четыре арифметические операции:
– умножение;
– деление;
– сложение;
– вычитание.
Для строковых форматов данных множеством значений являются так называемые произвольные строки. К таким строкам применяется только одна допустимая операция, которая имеет название конкатенация, а именно, соединение в одну нескольких строк. [12]
Такие строковые форматы данных определенного типа могут хранить и строки формата Unicode, который имеет возможность задавать более 65 тыс. символов.
Для выполнения работы со строковыми форматами данных существует целое множество полезных функций:
– удаление пробелов;
– выделение подстроки;
– поиск значения и многие другие.
Для логического формата данных множеством значений в обычных ЯП являются 2 значения:
– TRUE;
– FALSE.
В реляционных БД используется также еще значение – NULL, которое можно трактовать, как неизвестное значение.
Тут применяется не обычная двухзначная, а уже трехзначная логика.
Для логического формата данных в реляционных БД применяются 3 логические операции:
– операция НЕ;
– логическое ИЛИ;
– логическое И.
Использование рассматриваемой трехзначной логики в обработке реляционных БД связано с присутствием в значениях столбцов и неизвестного значения NULL.[8]
При создании таблиц с помощью рассматриваемой СУБД в БД можно для каждого из столбцов описать подробно все характеристики:
– значение по умолчанию;
– тип данных;
– допустимые значения и другие.
Характеристики можно задать также и в созданном типе данных пользователя, а затем ссылаться при определении столбцов таблицы на это описание.
2.3. Понятие практической разработки БД
Существуют разные подходы к процессу проектированию БД. В любом случае для проектировании разрабатывается БД не сама по себе, а с учетом задач, для разрешения которых будет она использоваться.[4]
Одним с наиболее применяемых подходов является так называемое трехуровневое проектирование хранилища данных и, соответственно, самой базы данных.
На первом, так называемом концептуальном уровне, осуществляется процесс анализа предметной области непосредственно для решения задач, что решаются в системе обработки данных или базе данных.
При этом выявляются, описываются объекты и сущности предметной области, основные их свойства, атрибуты, определяются связи, отношения между сущностями, а также определяется перечень задач по обработке данных, также фиксируются требования к разного рода характеристикам системы.
В результате этого анализа создается содержательная модель БД.
В данной модели используется концептуальная терминология с предметной области. На данном этапе определяются реквизиты, которые однозначно могут идентифицировать выделенные объекты и сущности. Большая вероятность, что на дальнейшем этапе именно данные реквизиты могут входить в состав ключевых полей в соответствующих таблицах, сто будут использованы при хранении данных об этих объектах.[13]
На втором уровне создается логическая структура базы данных. Тут происходит детализация выполненной содержательной модели с применением основных принципов реляционных БД.
Каждый объект рассматриваемой области представляется как одна или более таблиц.
В каждой таблице описывается ее структура, при чем помимо основных характеристик определяются и ключевые реквизиты.
Это внешние и первичные ключи, что позволяют однозначно выполнить идентификацию конкретный элемент объекта и задавать связи между таблицами.[15]
Результатом этого является логическая МД, которая описывается в терминологии реляционной СУБД.
На физическом уровне также осуществляется окончательное формирование всех характеристик объектов БД. Здесь задаются основные физические характеристики для практически всех объектов:
– уточнение применяемых типов данных;
– число и физические характеристики компонентов базы данных;
– размеры полей таблиц.
При необходимости также создаются дополнительные компоненты базы данных:
– триггеры;
– представления;
– хранимые процедуры;
– для таблиц создаются разные индексы, которые позволяют повысить производительность СУБД.
SQL Server предоставляет инструменты тонкой настройки для физических характеристик БД, позволяя при этом для одной БД создавать несколько файлов с данными, файловые группы, также указывая, какие именно данные в каком именно порядке должны быть размещены в отдельных группах файлов.
Можно также создавать секционированные таблицы, которые дают возможность повышать производительность системы и ее отказоустойчивость.[10]
На практике при создании отдельных систем для обработки данных по причине дефицита времени или врожденной лености разработчики часто опускают фиксацию формальных результатов концептуального проектирования, при этом ограничиваясь только общим описанием требований к системе и к обрабатываемым данным.
В результате надо сказать, что для большинства случаев это и является оправданным, так как разработчики оперируют в деятельности понятиями логического уровня и результаты их разработки удовлетворяют все требования непосредственно к системе. [5]
2.4. Описание создания БД при использовании SQL Server
Рассмотрим полную последовательность разработки базы данных для автомастерской с помощью утилиты под названием Management Studio.
Создаваемая БД будет хранить в себе такие таблицы, которые связаны с деятельностью автомобильной мастерской и отображать основные параметры ее функционирования.
Для создания базы надо выбрать раздел «Создать базу» и откроется окно, которое показано на рисунке 10:
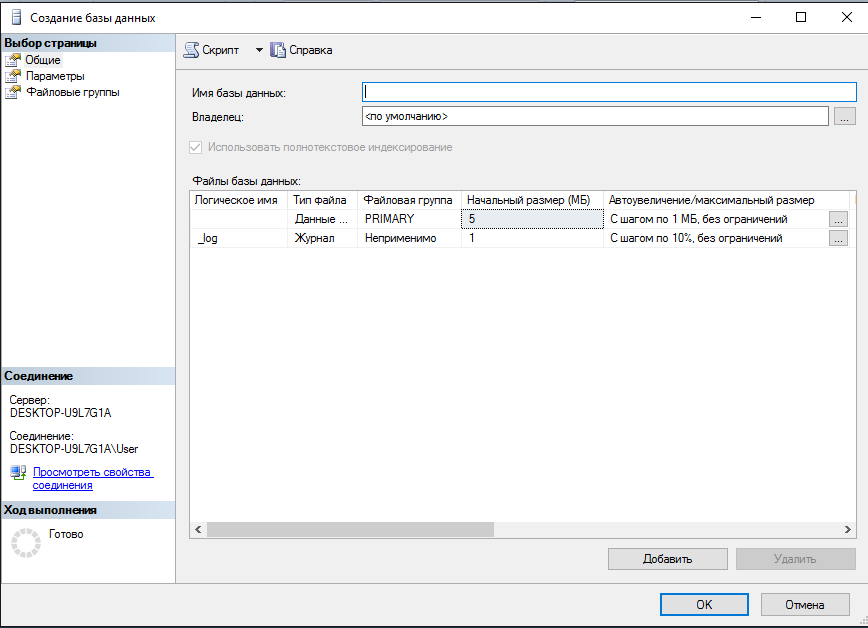
Рисунок 10 – Описание имени БД
На данном этапе разработки БД есть возможность выполнять такие действия:
– ввод названия БД;
– указать путь по которому будет хранится вспомогательная информация БД;
– приблизительные размеры БД;
– ограничения на поля БД;
– максимальный объем информации.
Для разработки новых таблиц, имеющею самую основную информацию по предметной области нужно выбрать «Создать таблицу», ввести структуру таблиц (рисунок 11):
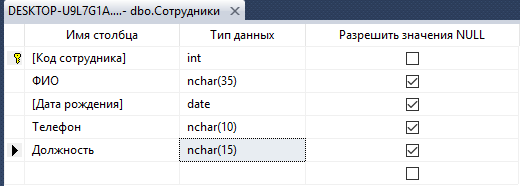
Рисунок 12 – Архитектура «Сотрудники»
Далее рассмотрим уже сформированные структуры для других таблиц (рисунки 13 – 15):[7]
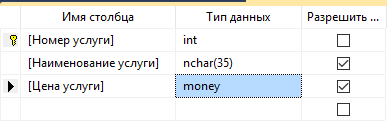
Рисунок 13 – Архитектура «Услуги сотрудники»

Рисунок 14 – Архитектура «Клиенты»
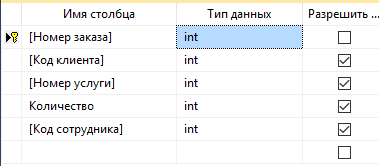
Рисунок 15 – Архитектура «Заказы»
Далее для создания в рассматриваемой СУБД диаграммы связей откроем пункт «Диаграмма».
Он имеет возможность добавить самые разные таблицы, а потом установить связи.
Получим (рисунок 16):
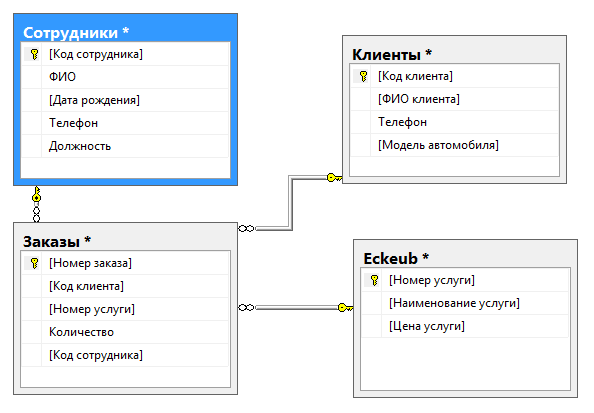
Рисунок 16 – Диаграмма БД
Введем данные в таблицы:
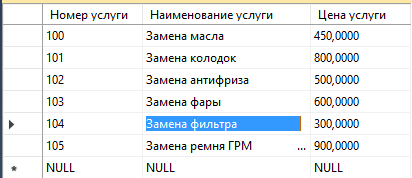
Рисунок 17 – Услуги
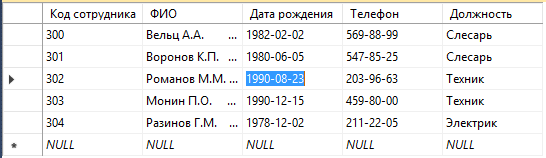
Рисунок 18 – Сотрудники
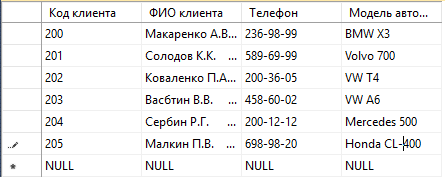
Рисунок 19 – Клиенты
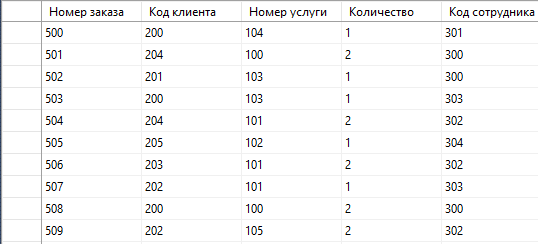
Рисунок 20 – Заказы
2.5.Обеспечение защиты данных в системах распределенной обработки информации на примере SQL Server
Рассмотрим описание некоторых средств СУБД SQL Server, которые встроены для обеспечения безопасности.
Заметим, что SQL Server использует разные сервисы безопасности с ОС Windows, поскольку СУБД может также настраиваться на работу в режимах безопасности ОС (рисунок 21):[11]
– Интегрированный режим применяют разнообразные механизмы аутентификации методами Windows.
В указанном случае при выполнении входов в SQL Server нужен использовать логин и пароль, перенаправленный через драйвер ODBC. [12]
– Стандартный режим предполагает, что полное описание в SQL Server разных самостоятельных имен пользователей, а также соответствующие им пароли.
Рисунок 21 – Режимы безопасности
– Смешанный режим использует в себе интегрированную модель при установке соединений по именованным блокам, а также мультипротоколу.[4]
SQL Server часто имеет возможность обеспечивать многоуровневую проверку самых разных привилегий при реализации загрузки данных на свтроенный сервер.
Максимальными правами по обеспечению процессов, направленных на поднятие безопасности обладает только один сотрудник, а именно – системный администратор БД.
Непосредственно для доступа к БД все пользователи, обращающиеся на сервер, должны владеть именем пользователя и специальными правами доступа.
В СУБД возможность в отображении сразу нескольких логинов при работе одного пользователя базы, объединять нескольких разных пользователей для групп при удобстве их администрирования и назначения перечня привилегий. [16]
По отношению к объектам БД каждому с пользователей могут определяться права на:
– декларативную ссылочную целостность;
– изменение;
– чтение;
– удаление;
– добавление;
– описание хранимых процедур, а также права на доступ для полей, определенных администратором.
В случае, если рассмотренного функционала недостаточно, то можно также применить разные представлений, для которых уже описанные методы будут оставаться справедливыми.
Все права на применение команд (по созданию таблиц, баз, правил, представлений, умолчаний, процедур, резервного копирования БД, журналирования транзакций) вовсе не бывают объектными или же специфичными, они определены только системным администратором сервера, а также владельцем БД при обработке ее структуры.
Администрирование пользовательских привилегий в качестве уровня безопасности часто ведется в среде Management Studio, хотя в языке Transact-SQL также часто применяются хранимые процедуры (sp_revokelogin, sp_addlogin, sp_password, sp_addalias) и некоторые операторы (REVOKE), что позволяют осуществить разные действия для определения перечня пользователей БД.
Непосредственно вся имеющаяся система безопасности для СУБД SQL Server использует такое уровни безопасности:[17]
– объект БД;
– ОС;
– SQL Server;
– БД.
С иной стороны механизмы реализации безопасности предполагают применение таких 4 классов пользователей:[12]
– системный администратор (неограниченный доступ);
– владелец базы (полные права);
– владелец объектов БД;
– пользователи, получившие отдельные разрешение доступа.
Модель безопасности рассматриваемой СУБД часто включает и следующие компоненты:
– пользователь базы;
– пользователь;
– классы подключения;
– роли.
При подключении к SQL Server поддерживается такие режимы безопасности:
– режим аутентификации (ОС Windows);
– смешанный метод.
В режиме аутентификации использована система безопасности для Windows, а также ее механизм учетных записей. Рассмотренный режим позволяет СУБД также применять логин и пароль, что определены и в Windows.
То есть, пользователи, что уже имеют действующую учетную запись ОС Windows, могут быть подключены без всяких проблем к рассматриваемой СУБД.
В случае, обращения пользователей в СУБД, последняя получит разные данные пользователя и пароле в ОС Windows.
При использования смешанного режима будут задействованы обе разработанные системы по аутентификации:
– Windows;
– SQL Server.
Производительность системы SQL Server можно также поднять к уровню, который необходим для реализации работы Интернет-порталов и разных больших проектов. Также, в механизме СУБД SQL Server есть разнообразная встроенная поддержка технологий XML, Web Assistant.
SQL Server также реализует поддержку аутентификации с ОС Windows, а это также позволяет СУБД применять разные учетные записи для SQL Server как доменные или пользовательские ОС Windows.[1]
Аутентификацию пользователей для подключения к компьютерной сети осуществляет непосредственно ОС Windows.
Соединение с СУБД, клиентское ПО запрашивает только уникальное доверенное соединение, что предоставленное только если все пользователи аутентифицированы в Windows.
Во втором разделе описаны основные понятия и приемы работы с распределенной системой обработки данных SQL Server. При это рассмотрены основные понятия о данной СУБД, рассмотрена технология обеспечения безопасности информации.
Заключение
Системы распределенной обработки информации в виде многомашинных вычислительных комплексов и компьютерных сетей представляют собой одну из наиболее прогрессивных форм организации средств вычислительной техники. Возможность взаимодействия вычислительных систем при реализации распределенной обработки информации определяют как их способность к совместному использованию данных или к совместной работе с использованием стандартных интерфейсов. Целью распределенной обработки информации является оптимизация использования ресурсов и упрощение работы пользователя.
Распределенная система позволяет скрыть от пользователя аспекты своей внутренней организации, физические места размещения ресурсов, вопросы реализации и взаимодействия процессов, обслуживающих запросы пользователя. Распределенная система способна увеличиваться в масштабах путем подключения к системе дополнительных компонентов без принципиального влияния на работу существующих приложений и пользователей.
Прикладное программное обеспечение в общем случае может быть представлено в виде композиции трех логических слоев: слоя логики представления, слоя бизнес-логики и слоя логики доступа к данным. Послойное разделение прикладного программного обеспечения минимизирует взаимодействие между составными элементами и служит основой для выделения компонентов, которые могут быть распределены для работы на нескольких вычислительных машинах.
Децентрализованная обработка информации основывается на архитектурной модели клиент/сервер, где клиентами считаются вычислительные машины, нуждающиеся в получении тех или иных услуг, а серверами - вычислительные машины, которые эти услуги предоставляют.
Список используемой литературы
- Гетц, Кен Технология «клиент-сервер». Киев: BHV, 2014. - 576 c.
- Голицына, О.Л. Базы данных; Форум; Инфра-М, 2013. - 399 c.
- Гринченко, Н.Н. Проектирование распределенных баз данных. Горячая Линия Телеком, 2012. - 613 c.
- Дейт, К.Дж. Введение в системы распределенных баз данных; К.: Диалектика; Издание 6-е, 2012. - 360 c.
- Дэвидсон, Луис Проектирование баз данных по технологии «клиент-сервер»; Бином, 2015. - 631 c.
- Дюваль, Поль М. Непрерывная интеграция; М.: Вильямс, 2016. - 497 c.
- Каратыгин, С.; Тихонов, А. Работа Технология «клиент-сервер»; М.: Бином, 2013. - 512 c.
- Каратыгин, Сергей Распределенные вычисления; М.: Лаборатория Базовых Знаний, 2012. - 376 c.
- Кауфельд, Джон Клиент-серверные технологии; М.: Диалектика, 2013. - 439 c.
- Каучмэн Джейсон; Подготовка администраторов баз данных; ЛОРИ, 2014. - 510 c.
- Луни К. DB Vista. Настольная книга администратора баз данных; М.: Лори, 2013. - 365 c.
- Мак-Федрис П. Технология «клиент-сервер»; М.: Вильямс, 2016. - 416 c.
- Наумов, А.Н. Распределенные системы обработки данных; М.: Финансы и статистика, 2015. - 352 c.
- Гринченко, Н.Н. Проектирование баз данных. СУБД Microsoft Access: Учебное пособие для вузов. / Н.Н. Гринченко и др. - М.: РиС, 2013. - 240 c.
- Диго, С.М. Базы данных / С.М. Диго. - М.: Финансы и статистика, 2015. - 592 c.
- Карпова, И.П. Базы данных: Учебное пособие / И.П. Карпова. - СПб.: Питер, 2013. - 240 c.
- Кириллов, В.В. Введение в реляционные базы данных. Введение в реляционные базы данных / В.В. Кириллов, Г.Ю. Громов. - СПб.: БХВ-Петербург, 2012. - 464 c.
- Крёнке, Д. Теория и практика построения баз данных/ Д. Крёнке. 8—е изд. – СПб.: Питер, 2013. – 800 с.

- Информация в материальном мире, понятие информации
- Учёт ремонтных работ жилищно-коммунального хозяйства
- мотивация и управленческая деятельность( Роль и значение системы мотивации персонала в развитии предприятия)
- Понятие оперативно розыскной деятельности.
- Процедуры банкротства, основные критерии
- Соотношение системы права и законодательства.
- ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ОПТОВОЙ ТОРГОВЛИ в системе хозяйственных связей рыночной экономики
- Анализ содержания профессиональной деятельности менеджеров по персоналу
- «Разработка конфигурации «Движение библиотечного фонда» в среде 1С:Предприятие 8.3.»
- Моделирование предметной области «Учет товаров» с помощью UML (Описание предметной области. Постановка задачи)
- Предмет, метод предпринимательского права и принципы предпринимательского права (Предпосылки появления предпринимательского права)
- Право собственности на землю (Понятие и формы права собственности на землю и земельные участки)