
Работа с текстовыми файлами
Содержание:

Введение
В наши дни Visual C++ лидирует среди продуктов для программирования в среде Windows. Почти все, что можно сделать в Windows, программируется на Visual C++. За годы своего развития Visual C++ превратился в комплект невероятно мощных инструментов для Windows – программирования.
Большинство компьютерных программ работают с файлами, и поэтому возникает необходимость создавать, удалять, записывать, читать, открывать файлы [1, с.24][1].
Visual C++ обладает всеми необходимыми средствами для выполнения действий над файлами любой структуры, в том числе и текстовыми.
Целью данной курсовой работы является изучение механизмов языка программирования Visual C++ для работы с текстовыми файлами.
В выполнения поставленной цели необходимо выполнить следующие задачи:
- Ознакомится с краткой историей языков программирования. Произвести обзор Visual C++.
- Рассмотреть механизмы Visual C++ для работы с текстовыми файлами.
- Реализовать полученные знания для реализации практической части.
В работе использовались труды следующих отечественных и зарубежных авторов: Страуструп Бьерн, Васильев А.Н., Довбуш Г.Ф. и другие.
Страуструп Бьерн. Программирование: принципы и практика с использованием C++ / Бьерн Страуструп. - М.: Вильямс, 2016. - 1328 c.
Книга представляет собой введение в программирование, включая объектно-ориентированное и обобщенное программирование. Одновременно она представляет собой введение в язык C++, один из широко применяющихся языков программирования в современном мире. Отпечатано в АО «Первая Образцовая типография». Филиал «Чеховский Печатный Двор». 142300, Московская область, г. Чехов, ул. Полиграфистов, д. 1. ООО “И. Д. Вильямс”, 127055, г. Москва, ул. Лесная, д. 43, стр. 1.
Васильев А.Н. Программирование на C++ в примерах и задачах / А.Н. Васильев. - М.: ЭКСМО, 2017. - 416 c.
Книга включает в себя полный набор сведений о языке С++, необходимых для успешного анализа и составления эффективных программных кодов. Отпечатано в ОАО «Можайский полиграфический комбинат» 143200, г. Можайск, ул. Мира, 93.
I. Теоретическая часть
Глава 1. Краткая история языков программирования. Обзор Visual C++
Первые языки программирования были машинными. Каждый центральный процессор (CPU) имел (и до сих пор имеет) фиксированный набор сравнительно простых команд, которые он умеет выполнять, например, сложить или перемножить два числа, скопировать значение из одной ячейки памяти в другую, проверить некоторое условие и в случае его выполнения осуществить переход к определенной инструкции и т.д. Программирование велось в машинных кодах, то есть по сути в числах, так как каждая команда кодировалась с помощью определенной последовательности нулей и единиц. Затем последовало первое «упрощение» языков – вместо чисел появились мнемонические названия команд. Например, для обозначения операции сложения двух чисел использовалась не соответствующая ей числовая комбинация, а слово ADD. Логически программы не стали проще, но теперь хотя бы вместо одной большой последовательности чисел программист видел перед собой набор более-менее читаемых команд. Так появились ассемблерные языки. Они взаимно-однозначно отображались в машинные, не несли в себе принципиально новых идей и по сути служили лишь для удобства работы с машинным языком, так как человекочитаемые названия команд ADD, MUL, SUB, MOV, JMP гораздо проще запомнить, чем их числовые эквиваленты [5, с. 260][2].
Затем задачи, решаемые с помощью компьютеров, еще больше усложнились, программы стали настолько большими и громоздкими, что эффективная работа с ними на ассемблерном уровне была практически невозможной. Начали появляться так называемые языки высокого уровня. Первый из них – Фортран – появился в 1957 году. Этот язык был создан группой программистов под руководством Джона Бэкуса из корпорации IBM. Название Fortran является сокращением от FORmula TRANslator (переводчик формул). Фортран широко используется в первую очередь для научных и инженерных вычислений.
Следующим языком был Лисп - 1958 год - функциональный язык, принципиально отличающийся своей парадигмой от структурированных языков программирования, с которыми мы, в основном, имеем дело сегодня, и к которым, в частности, относится язык Си.
В 1970 году появился Паскаль, ставший на то время одним из наиболее известных языков программирования. Паскаль использовался в основном для обучения программированию в старших классах школы и на первых курсах вузов.
В 1972 году сотрудник компании Bell Labs - Денис Ритчи создал специально для разработки операционной системы UNIX язык Си, поэтому он и по сей день является языком системного программирования.
По мере эволюционного развития всех этих и других языков начали возникать различные парадигмы программирования: структурированное, функциональное, объектно-ориентированное, событийное и т.д.
С 1960 по 1970 были разработаны все основные концепции языков программирования. Каждая новая парадигма все более и более «удаляет» нас от технических аспектов исполнителя и приближает к реальному миру. В идеале, компьютерные программы должны быть неотличимы от текстов на естественном языке. Примеры того, как это могло бы выглядеть на практике, мы уже видели в научно-фантастических фильмах [7, с.52][3]. Собственно, искусственный интеллект, изображаемый в подобных художественных фильмах, это и есть образ идеального интерпретатора естественного языка. Мы просто описываем компьютеру нашу задачу на русском (английском или любом другом) языке, и он ее решает для нас.
Для реализации материала для изучения была выбрана система программирования Visual Studio 2017, так как она предоставляет наиболее широкие возможности для программирования приложений ОС Windows.
Visual C++ – это продукт Microsoft для быстрого создания приложений. Высокопроизводительный инструмент визуального построения приложений включает в себя настоящий компилятор кода и предоставляет средства визуального программирования, несколько похожие на те, что можно обнаружить в Microsoft Visual Basic, или в других инструментах визуального проектирования [2, с.87][4].
Visual C++ производит небольшие по размерам (до 15-30 Кбайт) высокоэффективные исполняемые модули (.exe и .dll). С другой стороны, небольшие по размерам и быстро исполняемые модули означают, что требования к клиентским рабочим местам существенно снижаются – это имеет немаловажное значение и для конечных пользователей.
Преимущества Visual C++ по сравнению с аналогичными программными продуктами.
- быстрота разработки приложения;
- высокая производительность разработанного приложения;
- низкие требования разработанного приложения к ресурсам компьютера;
- наращиваемость за счет встраивания новых компонентов и инструментов в среду Visual C++;
- возможность разработки новых компонентов и инструментов собственными средствами Visual C++ (существующие компоненты и инструменты доступны в исходных кодах);
- удачная проработка иерархии объектов.
Система программирования Visual C++ рассчитана на программирование различных приложений и предоставляет большое количество компонентов для этого [6, с.121][5].
Глава 2. Основы файлового ввода-вывода. Чтение из файла
Файлы - источник жизни компьютера. Без них все результаты работы уничтожались бы при перезагрузке компьютера или закрытии приложения. Язык C++ позволяет выполнять чтение и запись в файлы. Операции над файлами называются файловым вводом-выводом [15, с.56][6].
Операции чтения и записи в файлы очень похожи на использование объектов cout и cin, однако cin и cout являются глобальными переменными, а для чтения и записи в файлы необходимо объявлять собственные объекты. Это означает, что необходимо знать фактические типы данных.
Двумя такими типами являются входящий файловый поток и исходящий файловый поток. Поток представляет собой набор данных, доступных для чтения и записи. Принцип действия этих типов в том, что они преобразуют файл в длинный поток данных, которые можно использовать так, как будто взаимодействуете с пользователем. Оба типа требуют включения в программу заголовочного файла fstream (сокращение от file stream - файловый поток) [3, с.236][7].
Рассмотрим считывание данных из файлов. Для этого воспользуемся типом ifstream. Экземпляр ifstream можно инициализировать по имени файла, из которого мы хотим считать данные:
int main ()
{
ifstream file_reader("myfile.txt");
}
Эта небольшая программа пытается открыть файл myfile.txt: она ищет его в том каталоге, где выполняется (это рабочий каталог программы). При необходимости можно указать полный путь к файлу, например с:\myfile.txt.
Нужно обратить внимание, что программа лишь делает попытку открыть файл: возможно, этот файл не существует. Можно проверить результат создания объекта ifstream и определить, был ли файл успешно открыт, с помощью метода is_open: [9, с.401][8].
int main ()
{
ifstream file_reader("myfile.txt");
if (! file_reader.is_open())
{
cout << "Could not open file!" << ‘\n’;
}
}
При работе с файлами нужно писать код, который обрабатывает возможные ошибки. Возможно, файлы не существуют, они могут быть повреждены или использоваться другим процессом системы. Во всех этих случаях операции над файлами завершаются неудачно.
Нужно быть готовым к разнообразным ошибкам, вызывающим проблемы при работе с файлом, таким как сбои диска, повреждения файлов, отключение питания, некорректные секторы диска и др. [10, с.463][9].
После открытия файла объект ifstream можно использовать так же, как cin. Следующий код считывает число из текстового файла:
int main ()
{
ifstream file_reader("myfile.txt");
if (! file_reader.is_open())
{
cout << "Could not open file!" << ‘\n’;
}
int number;
file_reader >> number;
}
Эта строка считывает цифры из файла так же, как если бы их вводил пользователь. Считывание продолжается до обнаружения пробела или другого разделителя. Например, если файл содержит текст
12 а b с
то после операции считывания значение переменной number становится равным 12.
При работе с файлами необходимо определять, не произошла ли ошибка. В C++ это можно сделать по значению, которое возвращает операция чтения:
int main ()
{
ifstream file_reader("myfile.txt");
if (! file_reader.is_open())
{
cout << "Could not open file!" << ‘\n’;
}
int number;
// здесь проверяем успешность считывания целого значения if (file_reader >> number)
{
cout << "The value is: " << number;
}
}
Проверяя результат вызова file_reader >> number, можно обнаруживать проблемы, связанные с дисковым накопителем и форматом считываемых данных. Необходимо помнить, что пользователь может ввести символ, там, где нужно ввести число. Данный метод позволяет защититься от подобных неприятностей [10, с.485][10]. Проверяем значение, возвращаемое функцией чтения: если оно истинно, операция прошла успешно и можно уверенно пользоваться данными; если ложно что-то пошло не так и это следует трактовать, как ошибку.
Глава 3. Форматы файлов
Запрашивая данные у пользователя, можно указать ему, какие значения хотим получить, и, если вводимые данные некорректны, инструктировать его, как их исправить. При считывании из файлов такой возможности нет. Файлы создаются заранее - возможно, еще до того, как была написана программа. Чтобы считать данные, нужно знать формат файла [8, с.142][11]. Формат файла представляет собой его структуру (необязательно сложную). Допустим, есть таблица рекордов, которую необходимо сохранять между запусками программы. Пример простого формата файла - это десять строк, каждая из которых содержит одно число:
1000
987
864
766
744
500
453
321
201
98
5
Ниже приведем пример кода, который считывает данный список:
#include <fstream>
#include <iostream>
#include <vector>
using namespace std;
int main ()
{
ifstream file_reader("highscores.txt");
if (! file_reader.is_open())
{
cout << “Could not open file!" << '\n';
}
vector<int> scores;
for (int i = 0; i < 10; i++)
{
int score;
file_reader >> score;
scores.push_back(score);
}
}
В этом коде нет ничего сложного: он просто открывает файл и считывает рекорды по одному за раз. Этот код даже не полагается на то, что рекорды разделены символами новой строки, - он работает с пробелами. Тем не менее это недостаток реализации, а не особенность формата файла. Другие программы, работающие с файлами такого формата, могут оказаться требовательнее к данным, которые считывают. Существует хороший принцип работы с форматами файлов, называемый законом Постела: «Будьте либеральны к данным, которые принимаете, и консервативны к данным, которые отправляете». Другими словами, код, создающий файл, должен очень тщательно следовать спецификации, а код, считывающий формат файла, должен быть терпимым к небольшим ошибкам программ, написанных не столь безупречно. В приведенном выше примере мы проявляем либеральность, принимая не только символы новой строки, но и пробелы.
Конец файла.
Этот код работает лишь с конкретным файловым форматом и не предусматривает никакой обработки ошибок. Например, если количество записей в файле меньше десяти, код не прекратит считывание, даже достигнув конца файла [12, с.198][12]. Ситуация, когда количество рекордов меньше десяти, вполне возможна - например, если в игру играли лишь дважды. Конец файла часто обозначается аббревиатурой EOF (end of file, конец файла).
Можно сделать код устойчивее (либеральнее по отношению к вводимым данным), если обрабатывать ситуации, в которых файл содержит меньше десяти элементов. Для этого можно еще раз проверить результат метода, который считывает данные.
#include <fstream>
#include <iostream>
#include <vector>
using namespace std;
int main ()
{
ifstream file_reader("highscores.txt");
if (! file_reader.is_open())
{
cout << “Could not open file!" << '\n';
}
vector<int> scores;
for (int i = 0; i < 10; i++)
{
int score;
if(! (file_reader >> score))
{
breack;
}
scores.push_back(score);
}
}
Обрабатывая файл менее чем с десятью записями, код прекращает чтение, достигнув конца файла. Воспользовавшись вектором вместо массива с фиксированной длиной, мы можем легко обрабатывать короткие файлы. Вектор сохранит ровно столько данных, сколько было считано. Если мы сделаем, то же с массивом, придется отслеживать количество хранимых в нем записей, поскольку мы не знаем, заполнен ли массив целиком.
Иногда требуется считывать из файла все данные. В таких случаях необходимо отличать ошибки чтения, обусловленные достижением конца файла, от ошибок, вызванных некорректностью файла. Метод eof определяет, достигнут ли конец файла. Можно написать цикл, который считывает максимально возможное количество данных и проверяет результат чтения, пока не происходит ошибка. Затем следует проверить значение, возвращаемое методом eof: если оно равно true, находимся в конце файла, в противном случае произошла ошибка. Выяснить причину ошибки можно с помощью метода fail, который возвращает true, если введенные данные некорректны или возникла проблема считывания данных с устройства. После того как конец файла достигнут, нужно вызвать метод clear, чтобы продолжить выполнение операций над файлом [13, с.361][13].
Существует еще одно важное различие между ситуациями, когда данные считываются из файлов и когда их вводит пользователь. Что произойдет, если мы включим в список рекордов не только количество очков, но и имя игрока? Нам потребуется считать из файла как количество очков, так и имя игрока, а для этого необходимо соответствующим образом изменить код. Предыдущие версии программы не смогут считывать файл нового формата. Если много пользователей, изменение формата файла может повлечь серьезные проблемы. Существуют методы обеспечения будущей совместимости файла, которые основаны на использовании в файле дополнительных полей или игнорировании новых элементов формата в устаревших версиях программы. Изучение этих методов не относится к теме этого исследования, просто нужно иметь в виду, что определение формата файла является гораздо важнее определения базового интерфейса [14, с.59][14].
Глава 4. Запись в файлы. Позиция в файле
Для записи в файлы применяется тип ofstream (сокращение от output file stream - исходящий файловый поток). Этот тип почти идентичен типу ifstream с единственным исключением: он используется аналогично не объекту cin, а объекту cout.
Рассмотрим простую программу, которая выводит числа от 0 до 9 в файл highscores.txt (этот код в дальнейшем создаст нам нечто более похожее на таблицу рекордов).
#include <fstream>
#include <iostream>
#include <cstdlib>
using namespace std;
int main ()
{
ofstream file_writer("highscores.txt");
if (! file_writer.is_open())
{
cout << "Could not open file!” << *\n';
return 0;
}
// поскольку у нас нет реальных рекордов, мы выведем
// числа от 10 до 1
for (int i = 0; i < 10; i++)
{
file_writer << 10 - i << '\n';
}
}
Здесь не нужно беспокоиться о том, что мы достигли конца файла. Когда при записи в файл вы попадаете в его конец, объект ofstream расширяет файл. Эта операция называется добавлением в конец файла.
Создание нового файла.
Когда для записи в файл мы используем объект ofstream, по умолчанию он создает этот файл, если он не существует, или перезаписывает содержимое существующего файла. При работе со списком рекордов, скорее всего, перезапись файла при каждом сохранении вполне допустима, поскольку мы возвращаем в него все нужные данные. Тем не менее если мы ведем журнал и регистрируем в нем дату и время каждого запуска программы, периодически перезаписывать его, безусловно, нельзя.
Конструктор типа ofstream принимает второй аргумент, который определяет метод обработки файла (табл. 1):
Таблица 1 – Методы обработки файла
|
Аргумент |
Метод |
|
ios::app |
Добавляет данные в конец файла; после каждой операции записи текущая позиция устанавливается в конец файла |
|
ios::ate |
Устанавливает текущую позицию в конец файла |
|
ios::trunc |
Удаляет все содержимое файла |
|
ios::out |
Разрешает вывод в файл |
|
ios::binary |
Разрешает выполнение двоичных операций над потоком |
Чтобы воспользоваться несколькими методами одновременно, можно объединять их с помощью вертикальной черты (|):
ofstream a_file(“test.txt”, ios::app | ios::binary);
Этот код открывает файл, при этом не уничтожая его текущее содержимое, и позволяет добавлять двоичные данные в конец файла.
Когда программа читает файл или записывает в него, код ввода-вывода должен знать, в каком месте файла следует выполнить соответствующую операцию. Позиция в файле аналогична курсору на экране, который указывает, где будет отображен следующий введенный символ.
При выполнении базовых операций нет необходимости уделять особое внимание позиции в файле: код может просто считывать или записывать очередной фрагмент данных. Тем не менее можно изменять позицию в файле, не выполняя операцию чтения. Это часто необходимо при работе с файлами, которые хранят сложные структуры данных, например, ZIP или PDF, и с файлами, считывание каждого байта из которых занимает много времени или невозможно (например, при реализации базы данных) [11, с.265][15].
Фактически в файле существуют две позиции, одна из которых определяет место для следующей операции чтения, а другая - для следующей операции записи. Узнать текущую позицию для чтения можно с помощью метода tellg (g означает get - получение, чтение данных), а текущую позицию для записи - с помощью метода tellp (р означает put - размещение, запись данных).
Новую позицию в файле также можно задать, перемещаясь от текущей позиции с помощью методов seekp и seekg. Перемещение по файлу называется поиском (это отражено в названиях методов, которые происходят от слова seek - искать). При поиске в файле позиция чтения или записи перемещается на новое место. Оба указанных метода принимают два параметра: расстояние и начало поиска. Расстояние измеряется в байтах, а началом поиска является текущая позиция, начало или конец файла. После поиска мы можем считывать или записывать данные в файл, начиная с новой позиции. Изменение одной позиции с помощью операции поиска не влияет на другую позицию.
Позиция в файле задается с помощью одного из трех флагов (табл. 2):
Таблица 2 – Флаги, задающие позицию в файле
|
Аргумент |
Метод |
|
ios_base::beg |
Поиск от начала файла |
|
ios_base::cur |
Поиск от текущей позиции |
|
ios_base::end |
Поиск от конца файла |
Например, чтобы переместить текущую позицию в начало файла перед тем, как начать запись в него, можно написать следующее:
file_writer.seekp(0, ios_base::beg);
Значение, возвращаемое методами tellp и tellg, представляет собой особый тип переменной - streampos, который определен в стандартной библиотеке. Значение можно преобразовать в целое число и обратно, однако использование streampos явно задает тип данных. Целое число можно использовать где угодно, а у типа streampos есть конкретное назначение. Переменные streampos хранят позиции внутри файлов и используются для установки указателя на эти позиции. Задавая переменным подходящий тип, мы четко указываем их назначение.
streampos pos = file_reader.tellg();
Иногда перемещать текущую позицию в файле не требуется: достаточно просто считать файл от начала до конца. Тем не менее многие форматы файлов оптимизированы для добавления в них новых данных. Новые данные добавляются в конец файла гораздо быстрее, чем в середину. Когда данные добавляются в середину файла, необходимо сдвигать все его содержимое, находящееся после места вставки, так же как при добавлении нового элемента в середину массива.
Дополним написанную ранее программу, которая работает с таблицей рекордов, возможностью добавления нового рекорда в файл. Поскольку для этого необходимо как считывать данные из файла, так и записывать их, мы воспользуемся классом fstream, который поддерживает обе операции (можно считать, что он объединяет возможности классов ofstream и ifstream). Сначала считаем новый рекорд, который вводит пользователь, а затем будем считывать каждую строку файла, пока не найдем рекорд меньше введенного. В этом месте вставим новый рекорд. Сохраним эту позицию и вернемся к ней, считав все оставшиеся строки файла в вектор. Запишем в файл новый рекорд, а затем все остальные рекорды, которые уже были в файле.
int main ()
{
fstream file (
"highscores.txt",
ios::in | ios::out
if (! file.is_open())
{
cout << “Could not open file!" << ‘\n’;
return 0;
}
int new_high_score;
cout << “Enter a new high score: ";
сin >> new_high_score;
streampos pre_score_pos = file.tellg();
int cur_score;
while (file >> cur_score)
{
if (cur_score < new_high_score)
{
break;
}
pre_score_pos = file.tellg();
}
if (file.fail() && ! file.eof())
{
cout << "Bad score/read--exiting";
return 0;
}
file.clear();
file.seekg(pre_score_pos);
vector<int> scores;
while (file >> cur_score)
{
scores.push_back(cur_score);
}
if (! file.eof())
{
cout << "Bad score/read--exiting";
return 0;
}
file.clear();
file.seekp(pre_score_pos);
if (pre_score_pos != std::streampos(0))
{
file << endl;
}
file << new_high_score << endl;
for (vector<int>::iterator itr - scores.begin();
itr != scores.end();
++itr)
{
file << *itr << endl;
}
}
II. Практическая часть
Глава 5. Применение механизмов Visual C++ для работы с текстовыми файлами на практике
Для выполнения практического задания реализуем описанный в предыдущих главах пример работы с файлом результатов соревнований в среде Visual Studio 2017.
Запустим Visual Studio 2017 и создадим проект консольного приложения в Visual C++ (рис. 1-2).
Рисунок 1 – Среда разработки Visual Studio 2017
Для создания проекта консольного приложения выберем пункт меню «Файл/Создать/Проект» и в диалоговом окне выберем «Консольное приложение Windows» [4, с.26][16].
В графе «Имя» зададим название приложения «HightScores».
В графе «Расположение» зададим путь к проекту «d:\Projects».
В графе «Имя решения» зададим наименование решения «HightScores».
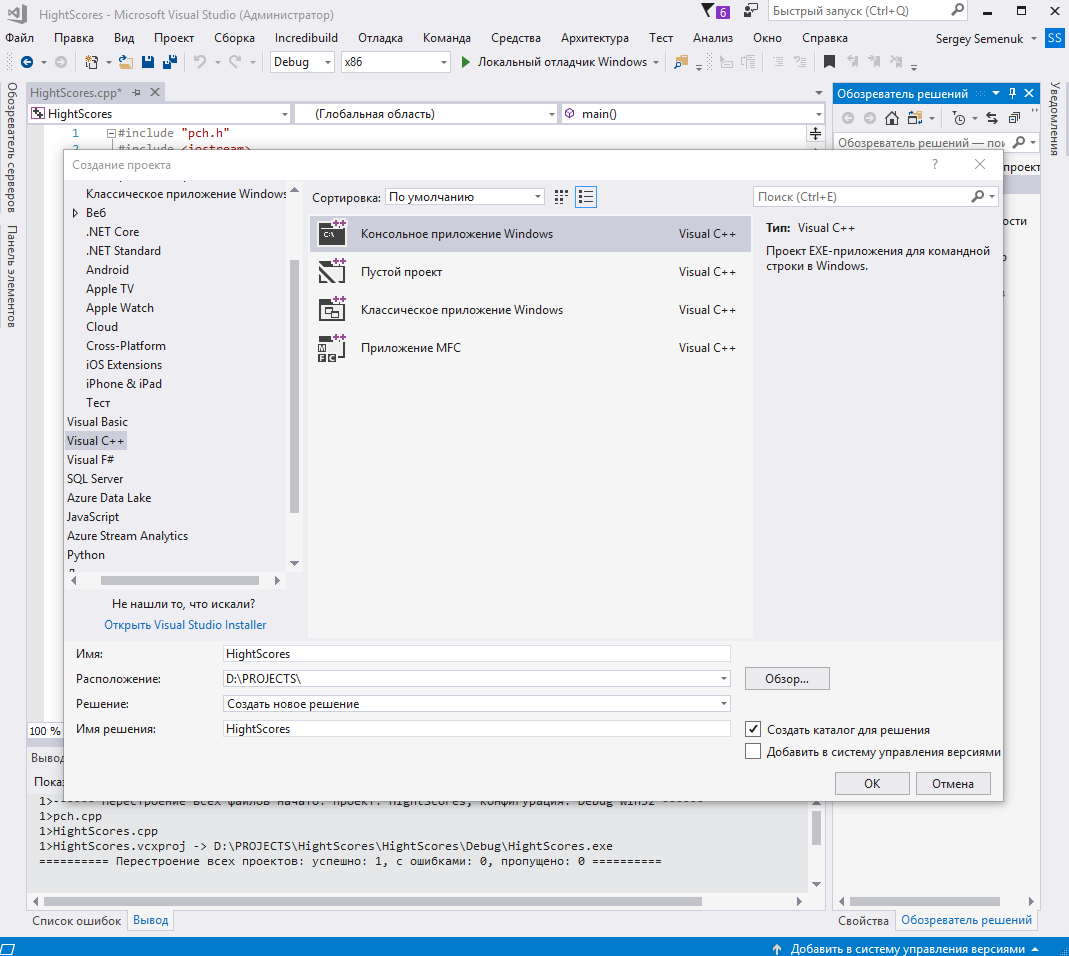
Рисунок 2 – Выбор консольного приложения
Для создания консольного приложения «HightScores» кликнем на кнопку «Ok» диалогового окна. Созданный проект отобразится в редакторе кода (рис. 3).
Прописываем заголовочные файлы и пространство имен.
Рисунок 3 – Созданный проект
Далее создаем файл «scores.txt» и записываем в него данные от 15 до 1 (рис. 4).
Листинг 1 – Код заполнения файла данными
// создаем файл и записываем в него данные от 1 до 15
ofstream file_writer("scores.txt");
if (!file_writer.is_open())
{
cout << "Could not open file!" << '\n';
return 0;
}
for (int i = 0; i < 15; i++)
{
file_writer << 15 - i << '\n';
}
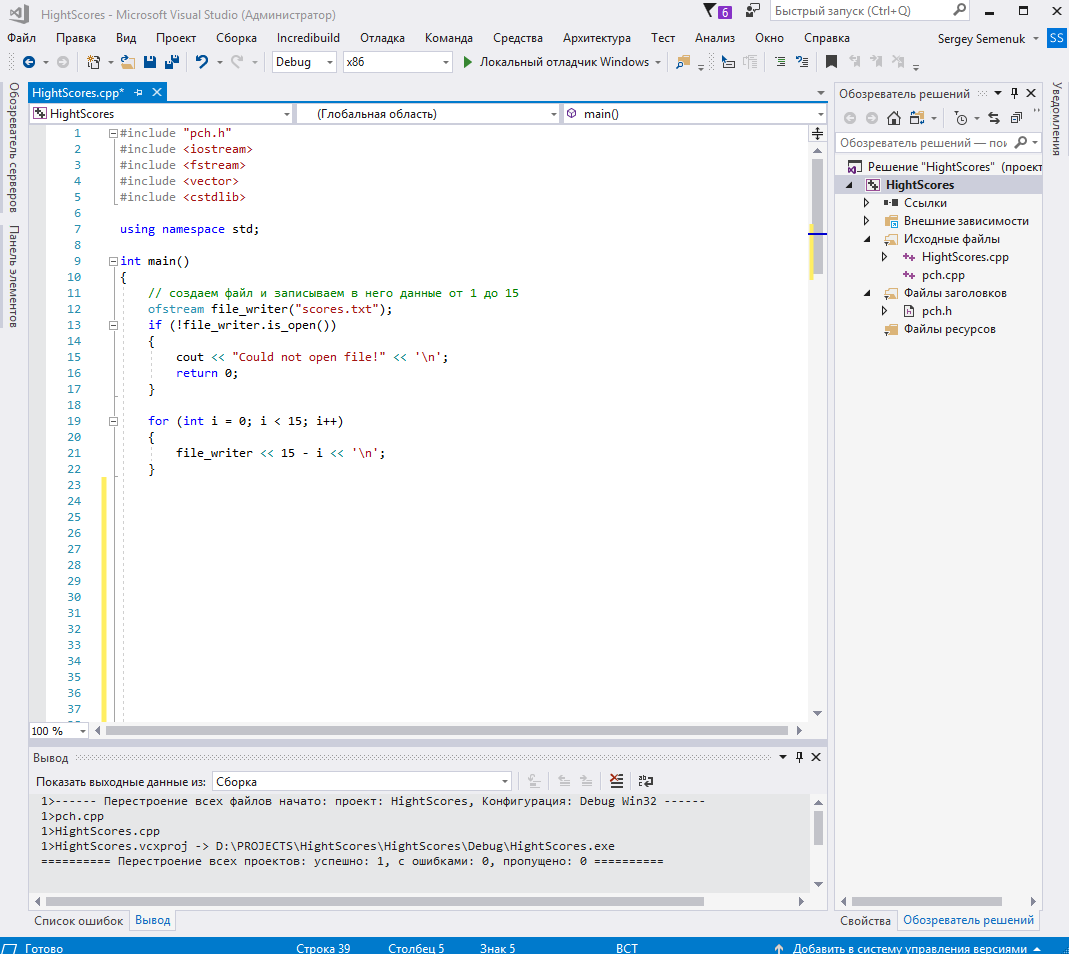
Рисунок 4 – Создание и заполнение файла
Далее, читаем данные из файла «scores.txt» (рис. 5).
Листинг 2 – Код чтения данных из файла и сохранение их в векторе
// чтение данных из файла
ifstream file_reader("scores.txt");
if (!file_reader.is_open())
{
cout << "Could not open file!" << '\n';
}
// сохраняем данные в вектор
vector<int> scores;
for (int i = 0; i < 15; i++)
{
int score;
if (!(file_reader >> score))
{
break;
}
scores.push_back(score);
}
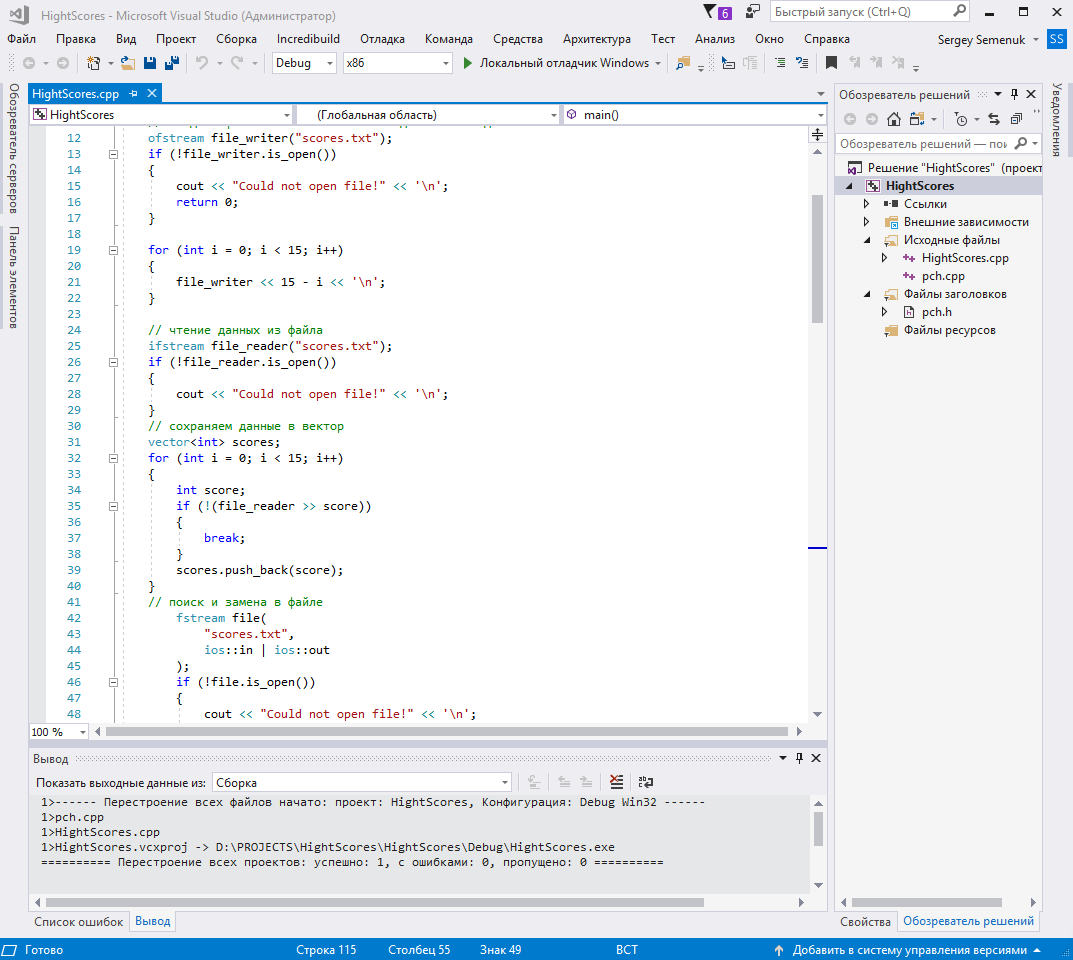
Рисунок 5 – Чтение из файла и заполнение вектора
Для проверки промежуточного результата, выполним сборку проекта (рис. 6) и выполним скомпилированный файл (рис. 7).
Рисунок 6 – Результат сборки
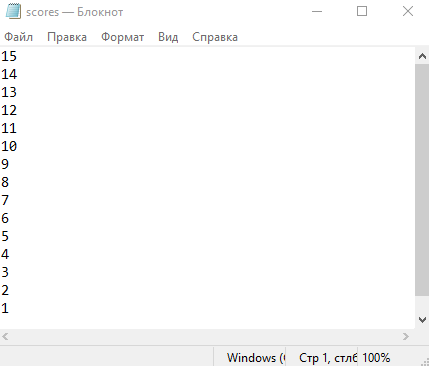
Рисунок 7 – Результат выполнения
Далее реализуем поиск и замену в файле рекордов «scores.txt» (рис. 8).
Листинг 3 – Код поиска и замены рекорда
// поиск и замена в файле
fstream file(
"scores.txt",
ios::in | ios::out
);
if (!file.is_open())
{
cout << "Could not open file!" << '\n';
return 0;
}
int new_high_score;
cout << "Enter a new high score: ";
cin >> new_high_score;
// Приведенный ниже цикл while выполняет поиск в файле,
// пока не найдет значение, меньшее
// текущего рекорда; после этого нужно вставить
// рекорд перед найденным значением.
// Чтобы определить требуемую позицию, мы следим
// за позицией, предшествующей текущему рекорду, -
// pre_score_pos
streampos pre_score_pos = file.tellg();
int cur_score;
while (file >> cur_score)
{
if (cur_score < new_high_score)
{
break;
}
pre_score_pos = file.tellg();
}
// если fail возвращает true и мы не находимся в конце файла,
// ввод некорректен
if (file.fail() && !file.eof())
{
cout << "Bad score / read--exiting";
return 0;
}
// если мы достигли конца файла, то
// не сможем вести запись в файл, не вызвав clear
file.clear();
// Возврат к точке перед последним считанным рекордом,
// чтобы считать все рекорды, меньшие нового,
// и сдвинуть их в файле на одну позицию
file.seekg(pre_score_pos);
// Теперь мы считаем все рекорды, начиная
// со считанного ранее
vector<int> scores;
while (file >> cur_score)
{
scores.push_back(cur_score);
}
// Этот цикл чтения должен выполняться до конца файла,
// поскольку мы хотим считать все рекорды,
// которые в нем хранятся
if (! file.eof())
{
cout << "Bad score/read--exiting";
return 0;
}
// Поскольку достигнут конец файла, нужно снова вызвать метод
// clear, чтобы продолжить запись в файл
file.clear();
// Возврат на позицию вставки
file.seekp(pre_score_pos);
// Записывая данные не в начало файла,
// мы должны указать символ новой строки; поскольку
// считывание числа заканчивается на первом разделителе,
// перед записью мы находимся в конце числа,
// а не в начале новой строки
if (pre_score_pos != std::streampos(0))
{
file << endl;
}
// запись нового рекорда
file << new_high_score << endl;
// циклическая запись всех оставшихся рекордов
for (vector<int>::iterator itr = scores.begin();
itr != scores.end();
++itr)
{
file << *itr << endl;
}
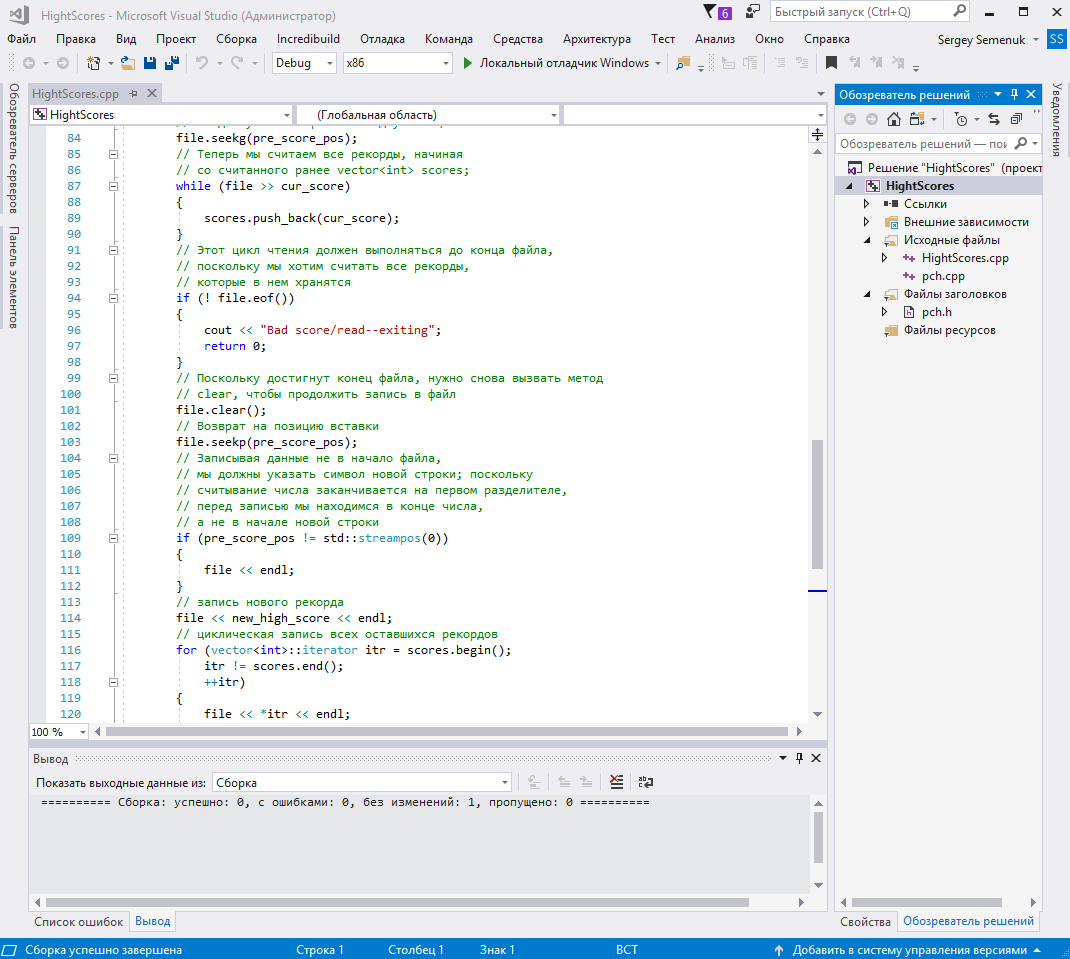
Рисунок 8 – Поиск и замена в файле
Собираем проект (рис. 9) и запускаем на выполнение (рис. 10).
Рисунок 9 – Сборка проекта
Рисунок 10 – Ввод нового рекорда
Для тестирование вводим значение 20.
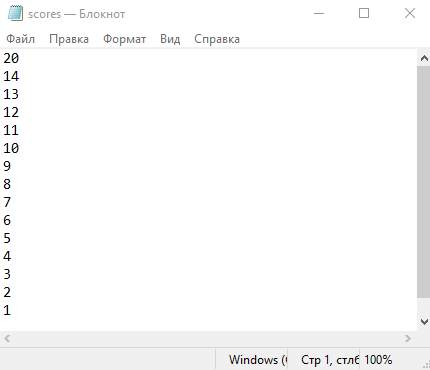
Рисунок 11 – Результат работы программы
Таким образом, в данном разделе мы создали приложение, демонстрирующее работу языка программирования C++ с текстовыми файлами. В данной программе реализовано: создание текстового файла, заполнение данными, чтение из файла, поиск и замена данных в файле.
Заключение
В ходе выполнения курсовой работы выполнены следующие задачи:
- Выполнен краткий обзор истории языков программирования.
- Произведен обзор возможностей Visual C++.
- Рассмотрены механизмы Visual C++ для работы с текстовыми файлами.
- Реализовано приложение, демонстрирующее механизмы языка C++ для работы с текстовыми файлами.
Созданное приложение, демонстрирующее механизмы языка C++ для работы с текстовыми файлами протестировано, и показало хорошие результаты.
Библиография
- Альфред В. Компиляторы. Принципы, технологии и инструментарий / В Альфред. – М.: Высшая школа, 2015. - 882 c.
- Страуструп Бьерн. Программирование: принципы и практика с использованием C++ / Бьерн Страуструп. - М.: Вильямс, 2016. - 1328 c.
- Васильев А.Н. Программирование на C++ в примерах и задачах / А.Н. Васильев. - М.: ЭКСМО, 2017. - 416 c.
- Довбуш Г.Ф. Visual C++ на примерах / Г.Ф. Довбуш, А.Д. Хомоненко. - М.: БХВ-Петербург, 2012. - 528 c.
- Карпов Б. C++: специальный справочник / Б. Карпов, Т. Баранова. - М.: СПб: Питер, 2016. - 480 c.
- Кениг Э. Эффективное программирование на C++. Практическое программирование на примерах. Т. 2 / Э. Кениг, Б.Э. Му. - М.: Вильямс, 2016. – 368 c.
- Панюкова Т.А. Языки и методы программирования. Создание простых GUI-приложений с помощью Visual С++. Учебное пособие / Т.А. Панюкова, А.В. Панюков. - Москва: Мир, 2015. - 144 c.
- Пахомов Борис С/С++ и MS Visual C++ 2012 для начинающих / Борис Пахомов. - М.: БХВ-Петербург, 2015. - 463 c.
- Полубенцева М.И. C/C++. Процедурное программирование / М.И. Полубенцева. - СПб: BHV, 2008. - 448 c.
- Секунов Н.Ю. Самоучитель Visual C++ 6.0 / Н.Ю. Секунов. - М.: СПб: BHV, 2014. - 960 c.
- Страуструп Бьерн. Дизайн и эволюция С++ / Бьерн Страуструп. - М.: ДМК Пресс, 2016. - 446 c.
- Фленов М.Е. Программирование на C++ глазами хакера. / М.Е. Фленов. - СПб: BHV, 2012. - 352 c.
- Хенкеманс Д. Программирование на C++ / Д. Хенкеманс, М. Ли. - СПб: Символ-плюс, 2015. - 416 c.
- Хусаинов И.Г. Решение задач на ЭВМ. Структурное программирование - Стерлитамак: БашГУ, 2014 - 110 с.
- Чиртик А.А. Программирование на C++. Трюки и эффекты. / А.А. Чиртик. - СПб: Питер, 2011. - 96 c.
Приложения
Приложение А. Исходный код программы
#include "pch.h"
#include <iostream>
#include <fstream>
#include <vector>
#include <cstdlib>
using namespace std;
int main()
{
// создаем файл и записываем в него данные от 1 до 15
ofstream file_writer("scores.txt");
if (!file_writer.is_open())
{
cout << "Could not open file!" << '\n';
return 0;
}
for (int i = 0; i < 15; i++)
{
file_writer << 15 - i << '\n';
}
// чтение данных из файла
ifstream file_reader("scores.txt");
if (!file_reader.is_open())
{
cout << "Could not open file!" << '\n';
}
// сохраняем данные в вектор
vector<int> scores;
for (int i = 0; i < 15; i++)
{
int score;
if (!(file_reader >> score))
{
break;
}
scores.push_back(score);
}
// поиск и замена в файле
fstream file(
"scores.txt",
ios::in | ios::out
);
if (!file.is_open())
{
cout << "Could not open file!" << '\n';
return 0;
}
int new_high_score;
cout << "Enter a new high score: ";
cin >> new_high_score;
// Приведенный ниже цикл while выполняет поиск в файле,
// пока не найдет значение, меньшее
// текущего рекорда; после этого нужно вставить
// рекорд перед найденным значением.
// Чтобы определить требуемую позицию, мы следим
// за позицией, предшествующей текущему рекорду, -
// pre_score_pos
streampos pre_score_pos = file.tellg();
int cur_score;
while (file >> cur_score)
{
if (cur_score < new_high_score)
{
break;
}
pre_score_pos = file.tellg();
}
// если fail возвращает true и мы не находимся в конце файла,
// ввод некорректен
if (file.fail() && !file.eof())
{
cout << "Bad score / read--exiting";
return 0;
}
// если мы достигли конца файла, то
// не сможем вести запись в файл, не вызвав clear
file.clear();
// Возврат к точке перед последним считанным рекордом,
// чтобы считать все рекорды, меньшие нового,
// и сдвинуть их в файле на одну позицию
file.seekg(pre_score_pos);
// Теперь мы считаем все рекорды, начиная
// со считанного ранее vector<int> scores;
while (file >> cur_score)
{
scores.push_back(cur_score);
}
// Этот цикл чтения должен выполняться до конца файла,
// поскольку мы хотим считать все рекорды,
// которые в нем хранятся
if (! file.eof())
{
cout << "Bad score/read--exiting";
return 0;
}
// Поскольку достигнут конец файла, нужно снова вызвать метод
// clear, чтобы продолжить запись в файл
file.clear();
// Возврат на позицию вставки
file.seekp(pre_score_pos);
// Записывая данные не в начало файла,
// мы должны указать символ новой строки; поскольку
// считывание числа заканчивается на первом разделителе,
// перед записью мы находимся в конце числа,
// а не в начале новой строки
if (pre_score_pos != std::streampos(0))
{
file << endl;
}
// запись нового рекорда
file << new_high_score << endl;
// циклическая запись всех оставшихся рекордов
for (vector<int>::iterator itr = scores.begin();
itr != scores.end();
++itr)
{
file << *itr << endl;
}
}
-
Альфред В. Компиляторы. Принципы, технологии и инструментарий / В Альфред. – М.: Высшая школа, 2015. - С. 24 ↑
-
Карпов Б. C++: специальный справочник / Б. Карпов, Т. Баранова. - М.: СПб: Питер, 2016. - С. 260 ↑
-
Панюкова Т.А. Языки и методы программирования. Создание простых GUI-приложений с помощью Visual С++. Учебное пособие / Т.А. Панюкова, А.В. Панюков. - Москва: Мир, 2015. - С. 52 ↑
-
Страуструп Бьерн. Программирование: принципы и практика с использованием C++ / Бьерн Страуструп. - М.: Вильямс, 2016. - С. 87. ↑
-
Кениг Э. Эффективное программирование на C++. Практическое программирование на примерах. Т. 2 / Э. Кениг, Б.Э. Му. - М.: Вильямс, 2016. – С. 121 ↑
-
Чиртик А.А. Программирование на C++. Трюки и эффекты. / А.А. Чиртик. - СПб: Питер, 2011. - С. 56 ↑
-
Васильев А.Н. Программирование на C++ в примерах и задачах / А.Н. Васильев. - М.: ЭКСМО, 2017. - С, 236 ↑
-
Полубенцева М.И. C/C++. Процедурное программирование / М.И. Полубенцева. - СПб: BHV, 2008. - С. 401 ↑
-
Секунов Н.Ю. Самоучитель Visual C++ 6.0 / Н.Ю. Секунов. - М.: СПб: BHV, 2014. - С. 463 ↑
-
Секунов Н.Ю. Самоучитель Visual C++ 6.0 / Н.Ю. Секунов. - М.: СПб: BHV, 2014. - С. 485 ↑
-
Пахомов Борис С/С++ и MS Visual C++ 2012 для начинающих / Борис Пахомов. - М.: БХВ-Петербург, 2015. - С. 142 ↑
-
Фленов М.Е. Программирование на C++ глазами хакера. / М.Е. Фленов. - СПб: BHV, 2012. - С. 198 ↑
-
Хенкеманс Д. Программирование на C++ / Д. Хенкеманс, М. Ли. - СПб: Символ-плюс, 2015. - С. 361 ↑
-
Хусаинов И.Г. Решение задач на ЭВМ. Структурное программирование - Стерлитамак: БашГУ, 2014 - С. 59 ↑
-
Страуструп Бьерн. Дизайн и эволюция С++ / Бьерн Страуструп. - М.: ДМК Пресс, 2016. - С. 265 ↑
-
Довбуш Г.Ф. Visual C++ на примерах / Г.Ф. Довбуш, А.Д. Хомоненко. - М.: БХВ-Петербург, 2012. - С. 26 ↑

- «Право собственности граждан»
- Формирование ассортимента товаров на предприятиях торговли на примере ТОРГОВОГО ПРЕДПРИЯТИЯ ООО «ТЦ Комус»
- Общий порядок создания, реорганизации и ликвидации субъектов предпринимательского права (Сущность ликвидации юридических лиц)
- Нотариат в РФ (Понятие и система органов нотариата)
- Ответственность за нарушение договорных обязательств (Понятие обязательства по современному гражданскому законодательству)
- Учет наличных денежных средств в кассе предприятия (Кассовые операции на розничном предприятии)
- Возмещение морального вреда (основания для возмещения морального вреда)
- Расходы на производство и реализацию товаров, работ, услуг (Понятие, сущность расходов и затрат)
- "Международный финансовый учет"
- Понятие решения
- Свойства и методы работы с нейронными сетями
- «Склад»