
Мультипроцессоры (Мультипроцессорная когерентность кэш – памяти )
Содержание:

Введение
На каждом этапе развития средств вычислительной техники возникают задачи, а порой и целые классы задач, требования которых к вычислительным мощностям превосходят существующие на данный момент. Это служит причиной того, что крупнейшие страны мира разрабатывают свои подходы и свои аппаратные решения для увеличения производительности вычислительных систем.
Производство суперкомпьютеров за последние 20 – 30 лет возросло на порядок за каждые 5 лет. Это достаточно легко отметить, наблюдая за количеством и качеством продуктов, будь то оптимизированные и программные пакеты или сверхмощные вычислительные станции, которые были произведены и были подвержены активному обсуждению в эти годы.
Наряду с развитием суперкомпьютеров, а в связи с этим и технологий параллельных вычислений, так же наблюдается рост и усложнение задач, решение которых невозможно без систем, производительность которых сильно превышает ту, которую могут предоставить домашние и офисные ЭВМ.
Начиная с 1980 года, идея того, что несколько процессоров смогут разделять доступ к одной и той же памяти, подкрепленная широким распространением микропроцессоров, стимулировала многих разработчиков на создание мультипроцессоров, в которых несколько процессоров разделяют одну физическую память, соединенную с ними с помощью разделяемой шины. Такие машины стали исключительно эффективными по стоимости. Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы является основой ускорения основных операций. Для увеличения производительности в состав вычислительной системы вводится несколько процессоров, способных функционировать параллельно во времени и независимо друг от друга и наряду с тем взаимодействовать между собой и с другим оборудованием системы.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология машины типа SIMD (Single Instruction Multiple Data), состоящие из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD (Multiple Instruction Multiple Data). Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе учета соотношения стоимость/производительность. При наличии у процессоров кэш-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Поскольку имеется единственная память с одним и тем же временем доступа, эти машины иногда называются UMA (Uniform Memory Access). Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является очень эффективным и представляет собой популярный объект исследования. Именно такая многопроцессорная система и будет являться объектом исследования данной курсовой работы.
Целью данной работы является рассмотрение мультипроцессорных систем с общей памятью, проведение сравнительного анализа производительности этой системы и решение тематической задачи с помощью компьютерного (имитационного) моделирования.
Задачи : получение программы реализующей работу мультипроцессорной системы с общей памятью по обработке различного количества заявок, а также различного количества процессоров. Заявки поступают случайным образом.
Объект исследования:
В процессе работы программа должна обработать очереди из 100 и 1000 заявок длинной 1-8 и 3-6; каждая очередь должна быть обработана в системе, содержащей 2, 5 и 10 процессоров.
Предмет исследования:
Сумма длин всех заявок данной очереди;
Время, необходимое для обработки данной очереди заданий при наличии 2-х, 5-ти и 10-ти процессоров;
Среднее время простоя процессоров;
Среднее время выполнения 1 заявки.
Все полученные данные должны быть занесены в таблицу.
1. Классификация вычислительных систем
В течении всего времени развития компьютерных технологий люди пытались изобрести такую общую классификацию, которая бы описывала все возможные пути развития вычислительных архитектур. Но ни одна из разработанных классификаций не могла охватить весь спектр создаваемых вычислительных и архитектурных решений и не выдерживала испытание временем. Но, несмотря на это, в научных кругах закрепились часто употребляемые термины, которые, при нынешнем развитии технологий и проникании их в повседневную жизнь, полезно знать не только специалистам в данной области, но и пользователям компьютеров.
Любая вычислительная система, будь то суперкомпьютер или компьютер, стоящий у большинства людей дома, достигает своей максимальной производительности благодаря новейшим технологиям в разработке аппаратных компонентов, а также параллельному выполнению огромного числа операций. Как раз параллельная работа разных устройств системы и даёт ускорение основных операций, также обеспечивает оптимизацию работы различных приложений даже в тот момент, когда пользователь совершенно об этом не думает.
Параллельные вычислительные системы часто подразделяют согласно таксономии Флинна, предложенной в 1966 году и расширенной в 1972. Выделяются два крупных класса ЭВМ: SIMD – машины (Single Instruction Multiple Data – один поток команд выполняет операции над множеством потоков данных) и MIMD (Multiple Instruction Multiple Data – большое количество потоков команд выполняют операции над множеством потоков данных) [5]. Данная классификация, как и любая другая, несовершенна, так как существуют ЭВМ прямо в неё не попадающие, а также ряд важных признаков не нашли в ней отражение. Как пример, векторные процессоры часто относят к ЭВМ типа SIMD, хотя высокая производительность данного типа машин обусловлена совсем другой формой параллелизма – конвейерной
обработкой данных. Многопроцессорные векторные системы, такие как CRAY EL, CRAY J90, CRAY T90 содержат в себе некоторое количество векторных процессоров и, благодаря этому, их можно выделить в класс MSIMD (Multiple SIMD) [2].
Так же таксономия Флинна не учитывает ещё некоторые достаточно важные для параллельных вычислительных моделей параметры. К таким параметрам можно отнести «зернистость» параллельных вычислений (крупнозернистые алгоритмы содержат в себе большие независимые задачи, которую можно решать параллельно, а мелкозернистые содержат задачи малые) и методы синхронизаций, используемых при решении тех или иных задач.
Можно выделить четыре основных вида вычислительных параллельных архитектур.
1.1 Конвейерная и векторная обработка
В 60-х годах принцип векторной обработки уже стал появляться в универсальных ЭВМ. Но к суперкомпьютерам и большим вычислительным системам данный подход наиболее широко стал применяться только в 80-х –90-х годах. Но активно развивающаяся отрасль производства процессоров вытеснила применение векторных ПЭ. Но, как говорится, всё возвращается на круги своя, и в настоящее время разработчики программных продуктов, требующих от машин высокой производительности, снова вспомнили этот вид параллельной обработки и пытаются внедрить его в свои исходные коды.
Основой конвейерной обработки является разбиение операции над данными на несколько ступеней, зависимых друг от друга, с последующей передачей результата работы каждой предыдущей ступени следующей [3]. В данном случае будет расти производительность благодаря тому, что на различных этапах конвейера одновременно выполняются различные операции над различными наборами данных. Максимальная эффективность данного вида архитектуры будет достигнута в случае, если загрузка конвейера будет близка к полной, а скоростью добавления новых данных будет соответствовать максимальной производительности конвейера.
Как только скорость добавления начнёт значительно расходиться с производительностью конвейера произойдёт простой тех или иных его частей и общая эффективность проводимых вычислений снизится. Векторные команды наиболее часто дают возможность полностью загрузить конвейер данными.
Векторная команда обеспечивает выполнение одной и той же операции над всеми значениями вектора, а чаще всего, над значениями двух и более векторов. До того момента, как все ступени конвейера будут заполнены данными может пройти некоторое время, но после этого новые данные смогут поступать в конвейер с той скоростью, которую сможет обеспечить память вычислительной системы. В таком случае не происходит временных задержек ни из-за выбора нужной команды, ни из-за выбора ветви вычисления при использовании команд условных переходов. Можно сказать, что основным принципом работы векторных вычислительных систем является повторное выполнение одной или нескольких простейших операций над блоком данных, распределённых по векторам. В исходном коде программ такие операции чаще всего представлены компактными циклами.
1.2 Машины типа SIMD
Данный подход в построении вычислений был внедрён в процессоры общего назначения в начале 90-х годов. Первый набор SIMD инструкций для процессоров имел название SSE. Данный тип выделяется тем, что с момента его разработки усовершенствование идёт до сих пор. Последнее усовершенствование SIMD команд было в 2012 году и имело название AVX-512. Что интересно, машины с поддержкой AVX-512 появятся только в конце 2015 года.
ЭВМ данного типа содержат в себе большое количество абсолютно одинаковых процессорных элементов, которые, в свою очередь, имеют собственные модули памяти. В такой системе все процессорные элементы
будут выполнять одну и ту же программу. Конечно же, максимальную производительность подобные системы, состоящие из множества идентичных процессоров, будут показывать при решении задач, в которых каждый процессор сможет выполнять те же самые операции, что и остальные процессоры. Сам принцип вычислений SIMD – машин очень схож с принципом векторных систем: одна операция выполняется сразу над некоторым количеством данных.
Если сравнивать векторный процессор, с его ограничениями и тонкостями в организации конвейера, с процессором матричным, использующимся в SIMD – машинах, то последний является куда более гибким [10]. Для обработки матричных процессоров используются универсальные программируемые ЭВМ, в связи с чем решаемые задачи могут быть сложными и содержать в своих алгоритмах решения ветвления. Как правило, в исходном коде данная вычислительная модель представлена почти так же, как и векторные команды, с той лишь разницей, что в данном случае каждая итерация цикла над элементами массива выдаёт результаты, которые никак не будут использованы на последующих итерациях.
В связи с большой схожестью моделей вычисления на векторных и матричных процессорах зачастую данные ЭВМ считаются эквивалентными
будут выполнять одну и ту же программу. Конечно же, максимальную производительность подобные системы, состоящие из множества идентичных процессоров, будут показывать при решении задач, в которых каждый процессор сможет выполнять те же самые операции, что и остальные процессоры. Сам принцип вычислений SIMD – машин очень схож с принципом векторных систем: одна операция выполняется сразу над некоторым, как правило большим, количеством данных.
Если сравнивать векторный процессор, с его ограничениями и тонкостями в организации конвейера, с процессором матричным, использующимся в SIMD – машинах, то последний является куда более гибким [10]. Для обработки матричных процессоров используются универсальные программируемые ЭВМ, в связи с чем решаемые задачи могут быть сложными и содержать в своих алгоритмах решения ветвления. Как правило, в исходном коде данная вычислительная модель представлена почти так же, как и векторные команды, с той лишь разницей, что в данном случае каждая итерация цикла над элементами массива выдаёт результаты, которые никак не будут использованы на последующих итерациях.
В связи с большой схожестью моделей вычисления на векторных и матричных процессорах зачастую данные ЭВМ считаются эквивалентными.
1.3 Машины типа MIMD
Данный подход активно обсуждался с 2010 года и с тех пор началась подготовка условий для использования данного типа вычислений. И, начиная с 2013 года, большая часть суперкомпьютеров имела именно эту архитектуру.
Так как термин «мультипроцессор» описывает большинство MIMD – систем (точно такая же ситуация и в случае векторных процессоров и SIMD – машин), то, зачастую он используется в качестве синонима при описании систем с MIMD архитектурой. В MIMD – системе каждый из процессорных элементов (ПЭ) обычно работает над своей задачей независимо от остальных процессоров. По причине того, что процессорам всё-таки необходимо иногда
связываться друг с другом необходимо ввести более подробную классификацию MIMD – машин. Мультипроцессоры с общей памятью имеют память данных и команд, доступную для всех процессорных элементов. Связь ПЭ с общей памятью осуществляется посредством общей шины данных и сети обмена. Противоположную структуру имеют многопроцессорные системы с локальной памятью. Для каждого ПЭ выделается свой блок памяти, и он доступен лишь ему [15]. При помощи сети обмена процессорные элементы связываются друг с другом, если возникает необходимость передачи данных между подзадачами.
Основной моделью вычислений на MIMD – мультипроцессорах обычно выделяют работу нескольких независимых друг от друга процессов, периодически выполняющих операции над разделяемыми данными. На данный момент существует достаточно много вариантов для такой модели. Одна из крайностей – вариант параллельных вычислений, при котором исходная задача разбивается на достаточно большое количество параллельных задач, содержащих, в свою очередь, некоторое количество подпрограмм. Другая же крайность заключается в потоковой модели расчётов, в которой каждая выполняемая операция может рассматриваться как отдельный процесс. Такая операция находится в режиме ожидания своих данных, которые должны передать другие процессоры. После получения всех нужных компонентов операция выполняется и пересылает результаты тем процессам, которые в них нуждаются.
1.4 Многопроцессорные машины с SIMD-процессорами
Большинство современных суперкомпьютеров является многопроцессорными вычислительными системами, использующими в качестве процессоров либо векторные процессоры, либо SIMD-процессоры. Данный тип машин выделяется в отдельный класс MSIMD.
Как правило, языки программирования высокого уровня и компиляторы, использующиеся при программировании MSIMD – машин предоставляют
программисту языковые конструкции, позволяющие явно указывать параллелизм отдельных участком алгоритма. В пределах отдельных задач компиляторы автоматически распараллеливают циклы, подходящие для этого. MSIMD – системы позволяют использовать наиболее подходящий метод декомпозиции: там где возможно применяются векторные инструкции, а в остальных частях программы применяются гибкие возможности MIMD – архитектуры.
За годы развития вычислительной техники многопроцессорные системы претерпели некоторое количество этапов своего развития. Исторически сложилось так, что технологию SIMD начали исследовать первой, что на мой взгляд, послужило причиной достаточно длительного перерыва в заинтересованности данной технологией. В настоящее время легко отслеживаемой является тенденция к разработке под MIMD – архитектуру. На данный момент интерес обусловлен двумя факторами:
1. Большая гибкость: MSIMD – система может работать как однопользовательская, осуществляя высокопроизводительную поддержку какой – либо задачи (для этого вида работы необходима специфическая настройка аппаратной части), как многозадачная, выполняющая несколько программ одновременно, и как некоторая комбинация этих двух типов работ. 2. Экономическая эффективность: многопроцессорные системы наиболее предсказуемо предоставляют производительность, исходя из соотношения цена/качество. На самом деле практически все современные MSIMD – системы используют процессоры, которые можно найти в обычных персональных компьютерах, рабочих станциях и т.п . Сеть обмена для связи ПЭ элементов друг с другом или с памятью является одной из отличительных особенностей MSIMD – систем. Одним из наиболее важных моментов при построении многопроцессорных вычислительных систем является модель обмена. О чём говорят характеристики производительности, выражаемые через соотношения времени, затраченного на вычисления ко времени, затраченного на передачу данных.
На основе этого было разработано две модели межпроцессорной связи, подходящих каждая для своего типа задач и аппаратного обеспечения: передача сообщений и использование общей памяти. В MSIMD – системах с общей памятью одни из процессоров записывает данные в ячейку памяти, а второй процесс считывает данные из этой же ячейки. Для обеспечения согласованности данных приходится применять синхронизацию процессов, обмен часто является взаимоисключающим: пока не записал первый процесс второму процессу остаётся только ждать освобождения ячейки памяти.
В случае использования локальной памяти в архитектуре вычислений непосредственное разбиение этой памяти невозможно. Вместо этого в данном случае реализуется передача сообщений по сети связи для межпроцессорного взаимодействия. Эффективность коммуникации зависит от канала обмена, пропускной способности памяти, протоколов передачи данных.
Зачастую, программисты не учитывают временные затраты на передачу данных в векторных системах и системах с общей памятью, так как это не показано в явном виде в процессе программирования, хотя не редко может получиться так, что проблема передачи скрадывает весь прирост ускорения при расчёте конкретной прикладной задачи. Конфликты шин, памяти и процессоров являются определяющими факторами при увеличении накладных расходов на межпроцессорное взаимодействие. Чем больше ПЭ было добавлено в систему, тем больше процессов вступают в борьбу за одни и те же данные и шины. Это приводит к состоянию насыщения. В связи с тем, что модель системы с общей памятью очень удобная для программирования её часто используют как средство оценки влияния качества обмена данных на работу всей системы в целом, даже если тестируемая система создана на базе модели локальной памяти и использует передачу сообщений как средство межпроцессорного взаимодействия.
В связи с возрастанием требований к сети передачи данных при коммутации каналов и пакетов возникает возможность перегрузки сети. Для предотвращения данной проблемы становится необходимым переработка форматов и количества передаваемых данных, декомпозиция задачи, а так же грамотная модель распределения задач.
В связи с вышеперечисленным MSIMD – машины подразделяются на два основных класса в зависимости от используемых процессоров, модели организации памяти и методики их соединения.
Первый класс образуют системы с общей памятью, содержащие, как правило, несколько десятков ПЭ, но по причине аппаратных ограничений, обычно их количество не превышает 32. Из-за относительно небольшого количества используемых процессоров появляется возможность выделить общую область памяти и соединить с ней процессорные элементы одной общей шиной. Современные процессоры имеют достаточный объём кэш-памяти для того, чтобы шина с большой пропускной способностью и общая память могли удовлетворить одновременное обращение к памяти нескольких процессоров. По причине того, что существует память с одним и тем же временем доступа такие системы называют UMA (Uniform Memory Access). При относительно небольшом объёме общей памяти и таком подходе к организации памяти эти системы в последние годы очень популярны. Структуры подобной системы можно представить в виде рисунка 1:
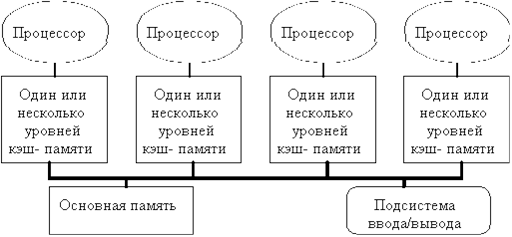
Рис. 1. Типовая архитектура MSIMD системы с общей памятью.
Второй класс машин образуют крупномасштабные системы с распределённой памятью. По причине использования очень большого количества процессоров при использовании модели одновременного обращения к памяти несколькими ПЭ может возникнуть ситуация, при которой пропускной способности шины может не хватить для выполнения всех запросов. По этой причине необходимо делить память между процессорами. И, что логично, при подобной организации вычислений необходимо реализовать связь между ПЭ.
На рисунке 2 изображена структура такой системы:
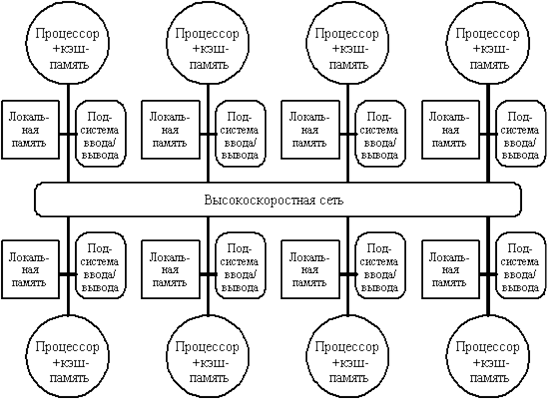
Рис. 2. Типовая архитектура машины с распределенной памятью
С ростом количества процессоров невозможно не заметить потребность в разработке модели с распределённой памятью, обладающей высокоскоростной сетью передачи данных. Со стремительным развитием мощности процессоров и, как следствие, ужесточением требований по увеличению пропускной способности памяти, количество ПЭ в системе, для которой необходима реализация модели с распределённой памятью, уменьшается. То же происходит и в случае уменьшения количества
процессоров, которые удаётся удержать на общей шине при модели с общей памятью.
Распределение памяти между различными узлами обладает рядом преимуществ, главными из которых выделаются следующие два. Первый – это экономически эффективное увеличение пропускной способности памяти, поскольку обращения к локальной памяти могут происходить параллельно в каждом узле системы. Второе – уменьшение времени задержки при обращении ПЭ к локальной области памяти. Указанные преимущества в свою очередь ещё сокращают количество процессорных элементов в системе, для которых модель распределённой памяти будет эффективной.
Как правило, устройства ввода/вывода так же, как и память распределены по вычислительным узлам. Это означает, что каждый узел в свою очередь может содержать относительно небольшое количество процессоров, соединённых другим способом. Такой подход к кластеризации процессоров достаточно экономически и качественно эффективен и является в настоящее время одним из самых популярных подходов при развёртывании высокопроизводительных вычислительных систем.
2. Многопроцессорные системы с общей памятью
Вычислительная система, содержащая несколько процессоров, связанных между собой и с общим для них комплектом внешних устройств, называются мультипроцессорными системами (МПС).
Производительность МПС увеличивается по сравнению с однопроцессорной системой за счет того, что мультипроцессорная организация создает возможность для одновременной обработки нескольких задач или параллельной обработки различных частей одной задачи. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов.
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. По способу связи между процессорами и памятью системы МПС разделяются на МПС с памятью общей (полнодоступной) и индивидуальной (раздельной). В мультипроцессорах с общей памятью имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. Структура МПС с общей памятью наиболее универсальна, любая информация, хранимая в памяти системы, в равной степени доступна любому процессору и каналу ввода/вывода. Отрицательное свойство МПС с общей памятью - большие затраты оборудования в коммутаторах.
В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Отрицательным последствием разделения памяти между процессорами является потеря ресурсов быстродействия в процессе обмена информацией между модулями памяти и общей памятью системы. Потери возникают, во-первых, из-за возможных приостановок работы процессоров для ожидания моментов окончания обмена данными с общей памятью и, во-вторых, из-за дополнительной загрузки модулей памяти операциями обмена.
В МПС с общей памятью каждый из процессоров имеет доступ к любому модулю памяти, которые могут функционировать независимо друг от друга и в каждый момент времени может выполняться одновременные обращения с целью записи или чтения слова информации, число которых определяется числом модулей. Конфликтные ситуации (обращение к одному и тому же модулю памяти) разрешаются коммутатором, начинающим обслуживать первым устройство с наибольшим приоритетом, например, процессор с наименьшим номером. Каждый из процессоров может инициировать работу любого канала ввода/вывода.
Пусть в МПС используются одинаковые процессоры, т.е. МПС - однородная система. Наличие общей оперативной памяти, в которой размещается вся необходимая информация, и однородность системы позволяют выполнять любую программу на любом процессоре, т.е. любой процессор может принять на обслуживание любую заявку. Режим работы МПС, при котором каждый из процессоров может обслуживать любую заявку, называется режимом разделения нагрузки. При этом режиме каждый из N процессоров принимает на обслуживание N-ю часть заявок, т.е. N-ю часть общей нагрузки. Процесс обслуживания заявок в режиме разделения нагрузки можно рассматривать как процесс функционирования одной многоканальной системы массового обслуживания с интенсивностью l входящего потока, общей очередью О, заявки из которой выбираются в порядке поступления их в систему, и средней длительностью обслуживания заявки каждым из процессоров Пр1,…, ПрN равной J.
Заявка, поступающая в систему, содержащую N процессоров, при наличии хотя бы одного свободного процессора немедленно принимается последним на обслуживание. Если все процессоры заняты обслуживанием ранее поступивших заявок, поступающая заявка размещается в очереди.
Пусть в МПС поступает М потоков с интенсивностями l1,...,lM. Обслуживание заявок сводится к выполнению соответствующих программ, средние трудоемкости которых равны Q1,…,QM операций в расчете на один прогон программы. Примем, что обслуживание заявок выполняется на основе дисциплины FIFO. В таком случае можно считать, что система обслуживает однородный поток заявок, поступающих с интенсивностью  =
= i
i
Для обслуживания любой заявки из суммарного потока требуется в среднем процессорных операций  . На каждый из процессоров поступает N-я доля заявок и, следовательно, отдельный процессор обслуживает поток с интенсивностью
. На каждый из процессоров поступает N-я доля заявок и, следовательно, отдельный процессор обслуживает поток с интенсивностью  /N .
/N .
Среднее время простоя процессоров можно получить, приняв ti за время простоя i-того процессора, тогда среднее время простоя 1 процессора вычисляется по формуле:
T= i /N,
i /N,
где N- количество процессоров.
Требования, которые в настоящее время предъявляются современными процессорными элементами к пропускной способности памяти, возможно обойти добавлением больших многоуровневых кэшей. При таком подходе несколько процессоров будут иметь возможность разделять доступ к одной и той же области памяти. Данная идея, подкреплённая большим количеством микропроцессоров на рынке, в 1980 году стимулировала различных разработчиков к созданию мультипроцессоров. В данных схемах несколько ПЭ разделяли бы одну физическую память, которая соединена с ними разделяемой шиной данных. Из-за всё уменьшающегося размера процессоров и увеличения полосы пропускания памяти, достигнутой за счёт возможности реализации большого размера кэш-памяти, такие системы стали очень экономически эффективными . В самом начале разработки технический процесс позволил расположить процессор и кэш-память на одной плате, которая, в дальнейшем, закреплялась на панели, реализующей шинную архитектуру связи. В настоящее время технологии позволяют разместить на одной плате до четырёх ПЭ. На рисунке 1 изображена именно такая схема.
В данном виде ЭВМ такие кэши могут содержать как общие данные, так и частные. Частные данные представляют собой ячейки памяти, к которым могут обращаться только конкретные процессоры, а общие данные, в свою очередь, доступны для всех, или части, процессоров. Общие данные в подобной архитектуре представляют собой инструмент для взаимодействия между процессорами. Когда происходит кэширование частных данных, они загружаются в кэш для сокращения среднего времени доступа, а также увеличения полосы пропускания. Так как к таким данным имеет доступ только один процесс, то сама операция кэширования частных данных ничем не отличается от подобной операции в однопроцессорных домашних системах. Когда происходит кэширование общих данных, то загружаемое значение может дублироваться сразу в несколько кэшей. Такой подход не только сокращает время доступа к данным, увеличивает полосу пропускания, но также сокращает накладные расходы на взаимодействие между процессорами и передачу данных. Несмотря на все положительные моменты использования кэша могут возникнуть проблемы когерентности, а другими словами целостности, общих данных, хранящихся в отдельных кэшах.
2.1 Мультипроцессорная когерентность кэш – памяти
Проблема целостности общих данных заключается в том факте, что процессоры имеют представление об этих данных только благодаря своему кэшу. Но может возникнуть ситуация, при которой один из процессоров эти данные может изменить. В таком случае, в кэше остальных процессоров будут находиться устаревшие данные, что может привести к некорректному результату расчётов. Данная проблема так же важна, как и описываемая выше проблема синхронизации работы с ячейкой памяти. По своей сути данную проблему так же можно охарактеризовать как проблему синхронизации. И так же, как и прошлая, эта проблема в явном виде скрыта от глаз программиста. На рисунке 3 показан простой пример, иллюстрирующий данную проблему.
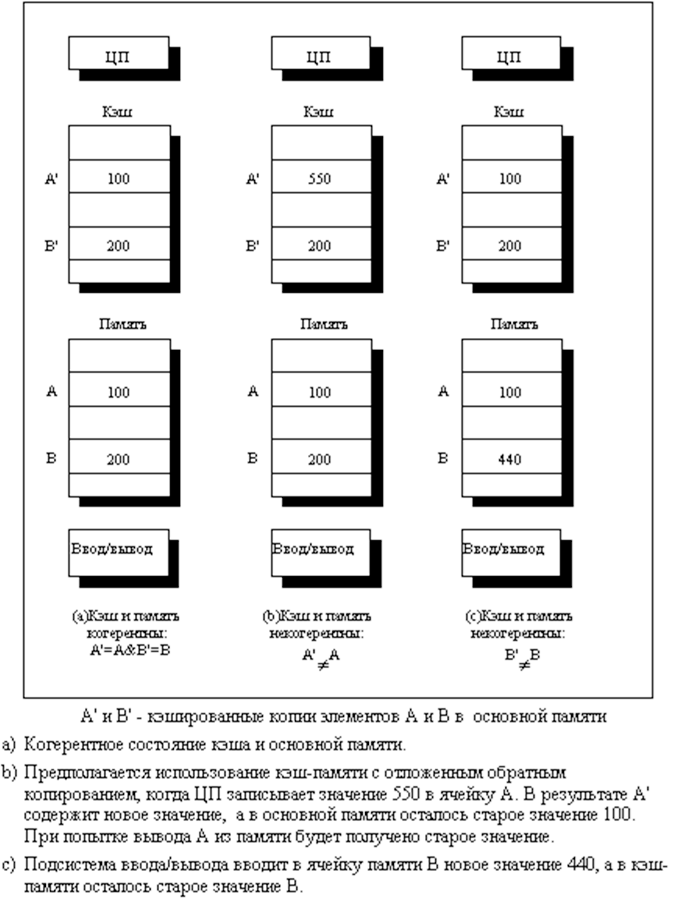
Рис. 3. Иллюстрация проблемы когерентности кэш-памяти
Проблема когерентности памяти для мультипроцессоров, а также для устройств ввода/вывода содержит большое количество аспектов. В небольших мультипроцессорных системах имеется аппаратное решение данной проблемы, называемое протоколом когерентности кэш – памяти. Такие протоколы делятся на два основных типа:
1) Протоколы на основе справочника (directory based). Вся информацию о состоянии физической памяти содержится в одном месте, называемом справочником. В то же время сам справочник физически может находится частично на различных узлах вычислительной системы.
2) Протоколы наблюдения (snooping). Каждый кэш содержит определённое количество ячеек памяти, а также служебную информацию о состоянии этого блока. Централизованно информация обо всей физической памяти нигде не содержится, но все кэши связаны с памятью одной общей шиной и «слушают» её, чтобы не упустить момент, когда какой – либо из процессоров не изменит тот блок общей памяти, который находится в кэше «слушающего» процессора. Это позволяет сохранять информацию в каждом из кэшей актуальной.
В мультипроцессорных системах, использующих ПЭ с кэш – памятью, большое распространение получили протоколы наблюдения. В случае подключения этих процессоров общей шиной не возникает проблем в опросе состояний кэшей, так как инфраструктура для передачи данных уже в системе присутствует в виде той самой общей шины памяти.
Проблема когерентности, простыми словами, заключается в том, что необходимо гарантировать, что в любой момент времени любой процессор, считывая данные из общей памяти, считает актуальные данные, записанные в эту память последними по времени. Такое описание проблемы не совсем корректно, так как нельзя требовать, чтобы операция считывания данных мгновенно видела данные, которые были записаны в эту ячейку другим процессором. Если операция считывания данных из ячейки памяти происходит после операции записи данных в туже самую ячейку памяти, в очень короткий период времени, то невозможно точно сказать, будут ли считанные данные теми данными, которые записывал предыдущий процессор, так как на самом деле, в конкретный момент времени эти данные процессор могли даже не покинуть. Вопрос о том, в какой именно момент данные должны быть доступны для чтения от выбранной модели согласования общей памяти и от реализации синхронизации памяти в параллельных вычислениях. Поэтому при обсуждении данного вопроса обычно принимают что данные, записанные операцией записи должны быть видны для операции чтения, выполняющейся немного позже операции записи и, данные изменяются согласно порядку выполнения операций.
2.2 Результаты исследования
Таблица 1: Результаты работы многопроцессорных систем, обрабатывающих очередь из 100 заданий
|
Кол-во процессоров |
Длина заявки 1-8 |
Длина заявки 3-6 |
||||
|
Сумма длин заявок 487 |
Сумма длин заявок 874 |
|||||
|
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
|
|
2 |
278 |
6,0 |
2,8 |
249 |
2,0 |
2,5 |
|
5 |
113 |
7,3 |
1,1 |
103 |
3,2 |
1,0 |
|
10 |
59 |
5,6 |
0,6 |
54 |
3,3 |
0,4 |
Таблица 2: Результаты работы многопроцессорных систем, обрабатывающих очередь из 1000 заданий
|
Кол-во процессоров |
Длина заявки 1-8 |
Длина заявки 3-6 |
||||
|
Сумма длин заявок 4456 |
Сумма длин заявок 8461 |
|||||
|
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
Время работы системы |
Среднее время простоя |
Среднее время выполнения 1 заявки |
|
|
2 |
2736 |
6,2 |
2,7 |
2519 |
1,6 |
2,5 |
|
5 |
1098 |
5,5 |
1,1 |
1010 |
3,0 |
1,0 |
|
10 |
554 |
6,0 |
0,6 |
512 |
3,1 |
0,5 |
2.3 Описание процедур, используемых в программе
Глобальные переменные
procc: array [1..10] of integer- массив процессоров системы
c: integer - переменная для подсчета количества простаивавших процессоров;
k: integer - переменная для подсчета общего времени простоя процессоров;
cz: integer - переменная для хранения текущего числа заданий(100 или 1000);
na: integer - переменная для хранения суммы длин заданий;
max: integer - переменная для хранения количества времени , которое проработает система после того, как ей будет передано последнее задание на обработку; Процедуры
Procedure mass (chzad: integer; proc: integer) - процедура, имитирующая работу многопроцессорной системы с общей памятью, выполняет обработку массива, состоящего из cz заданий, в системе с pr процессорами. В качестве параметров получает количество заданий chzad и количество процессоров proc в системе;
s:integer - переменная для подсчета времени, в течении которого будут выполняться chzad заданий;
f:Boolean - переменная для проверки передано ли очередное задание свободному процессору;
procedure vizov - процедура создает массив заданий длинной 1-8 и 3-6 и отправляет его на обработку 2-х, 5-ти и 10-ти процессорной системе при помощи вызова процедуры mass. Процедура вызывается в основной программе для 100 и 1000 заданий отдельно;
pr:integer - переменная для хранения количества процессоров системы;
мультипроцессорный память заявка архитектура.
Заключение
В результате выполнения курсовой работы были получены такие характеристики работы мультипроцессорных систем с общей памятью, как общее время, необходимое для выполнения 100 и 1000 заданий различной длинны, среднее время простоя процессоров и среднее время, необходимое для выполнения одной заявки.
Полученные данные показали прямую зависимость общей производительности системы от количества процессоров, т.е. с ростом числа процессоров в системе растет и общая производительность системы. Как видно из Таблицы 1. для обработки одной и той же очереди заявок общей длинной 487 системе с 2-мя процессорами требуется почти в 2,5 раза больше времени, чем системе с 5-ю процессорами и в 4,7 раза больше, чем системе с 10-тью процессорами.
Как видно из Таблиц 3.1 и 3.2 на производительность многопроцессорной системы с общей памятью влияет и диапазон длин заявок очереди. Для обработки очереди длинной 487, состоящей из 100 заявок, длина которых изменяется от 1 до 8, потребовалось почти столько же времени, сколько и для обработки такой же очереди общей длинной 874(что почти в 2 раза больше предыдущей), заявки которой имеют длину 3-6. Это обусловлено тем, что при обработке первой очереди встречаются как очень короткие (длинной 1-4), так и длинные заявки, на обработку которых требуется больше времени. В связи с этим растет и среднее время простоя процессоров, т.к. некоторые процессоры могли выполнить короткие заявки и завершить работу, в то время как остальные продолжали выполнять длинные заявки. При обработке очереди длинной 3-6 разница в длине заявки составляет 1-2, т.е. процессоры выполняют заявки практически одновременно, таким образом, сокращается время простоя процессоров.
Среднее время выполнения одной заявки так же находится в прямой зависимости от числа процессоров системы. Затраты времени на выполнение одной заявки значительно сокращаются с ростом количества процессоров, как видно из Таблиц 1 и 2 среднее время, необходимое на выполнение одной заявки системе с двумя процессорами, составило 2,6. Системе с пятью процессорами потребовалось примерно 1,1 системного времени, что в 2,4 раза больше, чем первой. Десятипроцессорная система выполняла дону заявку за 0,5, т.е. в 2 раза быстрее, чем предыдущая система.
Таким образом, можно сделать вывод, что производительность многопроцессорной системы зависит, прежде всего, от количества процессоров в системе, а так же от диапазона длин заявок очереди. Полученные результаты показали, что наибольшей производительности система достигает при наличии 10 процессоров и наименьшем диапазоне длин заявок очереди ( в данном случае 3-6).
Непрерывное развитие производства процессорных элементов, и вычислительных систем в целом, заставляют разработчиков программных пакетов для высокопроизводительных вычислений постоянно «держать руку на пульсе» и быть готовыми в достаточно короткие сроки добавлять в свои исходные коды те или иные изменения для использования последних разработок.
Можно выделить несколько сложностей подобных разработок:
1) Малое количество примеров использования новых команд / технологий;
2) Не все задокументированные возможности новой разработки работают исправно;
3) Совместное использование новых и старых подходов не всегда возможно.
Но невозможно не выделить и плюсы активного развития суперкомпьютеров:
1) Повышение сложности решаемых задач;
2) Уменьшение физических размеров вычислительных систем;
3) Уменьшение потребления электропитания (в отдельных случаях);
В ближайшее время резких скачков в развитии высокопроизводительных систем не предвидится. Данный вывод можно сделать, наблюдая за тематиками докладов на международных конференциях, посвящённых суперкомпьютерам.
В целом после написания данной курсовой работы можно сделать следующие выводы:
Достоинства многопроцессорных систем (мультипроцессоров):
1. Производительность (очевидно несколько процессоров выполнят задачу быстрее чем один).
2. Надежность (относится к многопроцессорным системам с общей памятью. При реализации систем с разделенной памятью возникают некоторые проблемы).
3. Живучесть.
4. Устойчивость.
Недостатки мультипроцессоров:
1. ПО (приложения, языки, ОС) сложнее, чем для однопроцессорных ЭВМ.
2. Ограниченность при наращивании (физические размеры - близость к памяти, 64 процессора - максимально достигнуто).
А также то, что у мультипроцессорных систем с общей памятью производительность прямо пропорционально зависит от количества процессоров и быстродействия системы.
Список литературы
1. Беляев А.А. Векторные АЛУ и архитектура SIMD: два уровня параллелизма в архитектуре сигнальных процессоров / А.А. Беляев // Техника и технология. – 2011. - №2.
2. Баранов Л.Д. Технологии организации параллельных вычислений / Л.Д. Баранов, Г.Н. Петрова, М.И. Чельдиев // Вопросы радиоэлектроники. – 2010. - №2.
3. Фомин Э.С. Сравнение метода Верлет таблицы и метода связанных ячеек для последовательной, векторизованной и многопоточной реализаций / Э.С. Фомин // Вычислительные методы и программирование: новые вычислительные технологии. – 2010. – Т.11. - №1.
4. Андрианов Н.Г. Реализация адаптивного алгоритма временной фильтрации на массивно – параллельных вычислительных устройствах / Н.Г. Андрианов // Электромагнитные волны и электронные системы. – 2010. – Т. 15. - №12.
5. Кузьминский М.И. Архитектура для повышения производительности / М.И. Кузьминский // Открытые системы. СУБД. – 2012. - №1.
6. Кутепов В.П. Формы, языки представления, критерии и параметры сложности параллелизма / В.П. Кутепов, В.Н. Фальк // Программные продукты и системы. – 2010. - №3.
7. Новокрещенов А.А. Алгоритм поиска параллельности без синхронизации во вложенностях циклов / А.А. Новокрещенов // Вестник нижегородского университета им. Н.И. Лобачевского. – 2012. - №2-1.
8. Nepomniaschaya A.S. Decremental associative algorithm for updating the shortest paths tree / Nepomniaschaya A.S. // Bulletin of the Novosibirsk computing center. Series: computer science. – 2011. – Т. 32.
9. В.И. Лойко; Вычислительные системы и сети”; г. Краснодар, изд. КГАУ, 2000 г.
10. В.Л. Бройдо; Вычислительные системы, сети и телекоммуникации”; Санкт-Петербург, 2002 г.
11. Таненбаум Э., Стеен ван М., Распределенные системы / Э. Таненбаум, М. Ван Стеен. – Спб.: BHV, 2003.
12. Хомоненко А. Д., Базы данных / Под ред. проф. Хомоненко А.Д. – 6-е изд.
– М: БИНОМ-Пресс; Спб., КОРОНА, 2007.
13. Федоров А.Г. Delphi 2.0 для всех. - М.: ТОО фирма “Компьютер пресс”, 1997.
14. Култыгин О.П. -Распределенные системы обработки информации - Москва 2011.

- Процессор персонального компьютера . Назначение, функции, классификация процессора (Классификация)
- Применение процессного подхода для оптимизации бизнес-процессов (Способы описания бизнес-процессов)
- Процессор персонального компьютера . Назначение, функции, классификация процессора
- Россия на международном валютно - финансовом рынке
- Исполнение обязательств, связанных с осуществлением предпринимательской деятельности»
- Нотариальные действия (Понятие и сущность нотариата)
- Особенности профессиональной мотивации служащих организаций (Концепция Ф. Герцберга)
- Управление поведением в конфликтных ситуациях (ПАО «Газпром» )
- Управление поведением в конфликтных ситуациях («Газпром»)
- Государственная социальная помощь в Российской Федерации
- Органы местного самоуправления (Местное управление и самоуправление))
- Программа пенсионной реформы и пути ее реализации (ИСТОРИКО-ПРАВОВЫЕ АСПЕКТЫ СТАНОВЛЕНИЯ ПЕНСИОННОЙ СИСТЕМЫ В РОССИИ))