
Методы кодирования данных (Понятие кодирования информации)
Содержание:

Введение
Обработка информации — это упорядоченный процесс преобразования информации в соответствии с алгоритмом решения задачи.
Воспринимая окружающий мир с помощью органов чувств, человек постоянно получает разнообразную информацию в виде слов, текстов, звуков, изображений, аудио-, видеофайлов, мультимедиа. Для осмысления информации необходимо ее определенным образом представить или зафиксировать. На помощь приходит процесс кодирования.
Фундаментальной чертой цивилизации является рост производства, потребления и накопления информации во всех отраслях человеческой деятельности. Вся жизнь человека, так или иначе, связана с получением, накоплением и обработкой информации. Чтобы человек не делал: читает ли он книгу, смотрит ли он телевизор, разговаривает, он постоянно и непрерывно получает и обрабатывает информацию.
Любой живой организм, в том числе человек, является носителем генетической информации, которая передаётся по наследству. Генетическая информация хранится во всех клетках организма, в молекулах ДНК (дезоксирибонуклеиновой кислоты). Молекула ДНК человека включает в себя около трёх миллиардов пар нуклеотидов, и в ней закодирована вся информация об организме человека: его внешность, здоровье или предрасположенность к болезням, способности и т.д.
Современное общество использует цифровой вид представления информации во многих сферах жизнедеятельности. Большой объем информации требует большой протяженности и пропускной способности каналов передачи данных. На данный момент развития информационной инфраструктуры, существующие каналы не справляются с требуемым трафиком. Следовательно, задача сжатия данных является актуальной во многих приложениях обработки и передачи информации.
Кодированием блока данных называется такое его описание, при котором создаваемый сжатый блок содержит меньше битов, чем исходный, но по нему возможно однозначное восстановление каждого бита исходного блока. Обратный процесс, восстановление по описанию, называется декодированием.
Цель исследования – проанализировать методы кодирования данных.
Задачи исследования:
1. Понятие кодирования информации.
2. Общая характеристика методов кодирования данных.
3. Метод кодирования Хаффмана.
4. Код Шеннона.
5. Алфавитный код Гилберта – Мура.
Объект исследования – методы кодирования данных.
Предмет исследования – методы кодирования Хаффмана, Шеннона, Гилберта – Мура
.
Глава 1 Теоретические аспекты исследования методов кодирования данных
1.1 Понятие кодирования информации
Для представления информации в вычислительной технике преимущественное распространение получило двоичное кодирование, при котором единицы вводимой в ЭВМ информации представляются средствами двоичной системы счисления, состоящей из 0 и 1.
Однако, для хранения сколько нибудь значащей информации необходимо больше символов, чем 0 и 1, которые может хранить минимальная ячейка информации. Чтобы сохранить число, большее, чем 0 и 1, ячейки информации объединяются в логические группы.
Группа ячеек, которая хранит логически единую информацию, называется регистром.
Размер регистра (количество битовых ячеек ) для каждой вычислительной системы зависит от ее архитектуры. Первые вычислительные машины оперировали восьмибитовыми регистрами, когда ячейки информации, которыми одновременно мог оперировать центральный процессор, имели размер только 8 бит. Потом наступила очередь 16-битных машин, потом 32-битных и т.д. [4, c. 34]
В литературе вместо термина "шестнадцатибитный" или подобных наименований обычно употребляется термин "шестнадцатиразрядный", 32-разрядный и т.д. Так как двоичная система хранения информации, точно также как и десятичная является позиционной (разрядной).
Размер регистра определяет, над каким объемом информации одновременно может совершить операцию центральных процессор компьютера. Это не значит, что 8-битный процессор не мог оперировать цифрами большими, чем 255 (максимальное число, которое можно записать с помощью 8 бит). Конечно, процессор может использовать несколько регистров одновременно и пользоваться информацией из памяти за пределами центрального процессора. Но единица одномоментно обрабатываемой информации - это размер регистра [2, c. 21].
Поскольку история вычислительной техники начиналась с восьмибитных компьютеров, то минимальной единицей информации является байт.
Байт - группа из восьми логически связанных между собой элементарных ячеек (битов).
Один бит - это ячейка, которая хранит ноль или единицу.
Байт же, состоящий из восьми битов (см. двоичная система счисления) может хранить число от 0 до 255.
Если сгруппировать два байта в один 16-битный регистр, то с их помощью можно записать число от 0 до 65 535.
Группировка четырех байтов в 32-битный регистр даст нам возможность записи числа от 0 до 4 294 967 295.
То есть, теоретически, мы можем оперировать сколько угодно большими числами. Это зависит от внутренней организации процессора и системы вычислений. Поэтому, чтобы сравнивать информацию, хранимую, обрабатываемую и передаваемую разными типами вычислительных машин, используют именно байты.
Для больших объемов информации используют единицы измерения в килобайтах, мегабайтах, гигабайтах и терабайтах. Однако, для стандартных приставок кило-, мега-, тера и т.д. это не означает стандартного множителя 1000.
Следует помнить, что килобайт - это не 1000, а 1024 байта.
1 килобайт (Кб) = 210байт=1024 байт;
1 мегабайт (Мб) = 1024 Кб = 220байт = 1048576байт;
1 гигабайт (Гб) = 1024 Мб = 230байт = 1073741824байт;
1 терабайт (Тб) = 1024 Гб = 240байт = 1099511627776 байт и т.д. [3, c. 12].
Виды кодирования и декодирования [15]:
обратимые - обеспечивает возврат к исходной информации без каких-либо её потерь
необратимые - не восстанавливает исходного текста
Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи.
Примером необратимого кодирования может служить перевод с одного естественного языка на другой – обратный перевод.
Для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому рассмотрим только обратимое кодирование.
Кодирование предшествует передаче и хранению информации. При этом хранение связано с фиксацией некоторого состояния носителя информации, а передача – с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы называются элементарными сигналами – именно их совокупность и составляет вторичный алфавит.
В процессе преобразования информации из одной формы представления (знаковой системы) в другую осуществляется кодирование.
Средством кодирования служит таблица соответствия, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем. В процессе обмена информацией часто приходится производить операции кодирования и декодирования информации. При вводе знака алфавита в компьютер путем нажатия соответствующей клавиши на клавиатуре выполняется его кодирование, т. е. преобразование в компьютерный код. При выводе знака на экран монитора или принтер происходит обратный процесс - декодирование, когда из компьютерного кода знак преобразуется в графическое изображение.
1.2 Общая характеристика методов кодирования данных
Выбор способа кодирования информации зависит от цели, ради которой оно осуществляется: например, сокращение записи, засекречивание (шифровка) информации, удобство информационного обмена между субъектами; удобство хранения, обработки и представления информации, наглядности отображения, восприятия и др.
За долгую историю развития человечество разработало много способов кодирования информации. Например, из Древнего Вавилона пришло деление часа на 60 мин и угла на 360 градусов. К англосаксам (жителям Британских островов) восходит традиция счета дюжинами: в году 12 месяцев, в футе 12 дюймов, в сутках 24 ч (два периода по 12 ч). Римскими цифрами часто записываются номер века, числа в часах [10].
К кодированию числовой информации относятся системы счисления: позиционная (величина цифры зависит от позиции, занимаемой этой цифрой в записи числа, например, десятичная система счисления; непозиционная, в которой величина цифры не зависит от места, занимаемого этой цифрой, примером является римская система счисления, где для обозначения цифр используются латинские буквы: I, V, X, L, С, D, М, что соответствует 1, 5, 10, 50, 100, 500, 1000.
К ярким примерам кодирования информации можно отнести: метод Морзе (кодирование информации с помощью последовательности «точек» и «тире»), метод Бодо (5-битная система кодирования символов), метод Шеннона — Фано (алгоритм префиксного неоднородного кодирования), алгоритм Хаффмана (оптимальное кодирование), шрифт Брайля (рельефно-точечный тактильный шрифт, предназначенный для письма и чтения незрячими людьми), штрихкод(графическая информация об объекте в виде черных и белых полос), стенография (быстрый способ записи устной речи).
Основной системой счисления в компьютере является двоичная позиционная система счисления. Кодирование информации происходит в виде последовательности нулей и единиц.
Кодирование на двух нижних каналах характеризует метод представления информации сигналами, которые распространяются по среде транспортировки. Кодирование можно рассматривать как двухступенчатое. И ясно, что на принимающей стороне реализуется симметричное декодирование.
Логическое кодирование данных изменяет поток бит созданного кадра МАС-уровня в последовательность символов, которые подлежат физическому кодированию для транспортировки по каналу связи. Для логического кодирования используют разные схемы:
4B/5B — каждые 4 бита входного потока кодируются 5-битным символом (табл 1.1). Получается двукратная избыточность, так как 24 = 16 входных комбинаций показываются символами из 25 = 32. Расходы по количеству битовых интервалов составляют: (5-4)/4 = 1/4 (25%). Такая избыточность разрешает определить ряд служебных символов, которые служат для синхронизации. Применяется в 100BaseFX/TX, FDDI
8B/10B — аналогичная схема (8 бит кодируются 10-битным символом) но уже избыточность равна 4 раза (256 входных в 1024 выходных) [7].
5B/6B — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN
8B/6T — 8 бит входного потока кодируются шестью троичными (T = ternary) цифрами (-,0,+). К примеру: 00h: +-00+-; 01h: 0+-+=0; Код имеет избыточность 36/28 = 729/256 = 2,85. Скорость транспортировки символов в линию является ниже битовой скорости и их поступления на кодирования. Применяется в 100BaseT4.
Вставка бит — такая схема работает на исключение недопустимых последовательностей бит. Ее работу объясним на реализации в протоколе HDLC. Тут входной поток смотрится как непрерывная последовательность бит, для которой цепочка из более чем пяти смежных 1 анализируется как служебный сигнал (пример: 01111110 является флагом-разделителем кадра). Если в транслируемом потоке встречается непрерывная последовательность из 1, то после каждой пятой в выходной поток передатчик вставляет 0. Приемник анализирует входящую цепочку, и если после цепочки 011111 он видит 0, то он его отбрасывает и последовательность 011111 присоединяет к остальному выходному потоку данных. Если принят бит 1, то последовательность 011111смотрится как служебный символ. Такая техника решает две задачи — исключать длинные монотонные последовательности, которые неудобные для самосинхронизации физического кодирования и разрешает опознание границ кадра и особых состояний в непрерывном битовом потоке.
Избыточность логического кодирования разрешает облегчить задачи физического кодирования — исключить неудобные битовые последовательности, улучшить спектральные характеристики физического сигнала и др. Физическое/сигнальное кодирование пишет правила представления дискретных символов, результат логического кодирования в результат физические сигналы линии. Физические сигналы могут иметь непрерывную (аналоговую) форму — бесконечное число значений, из которого выбирают допустимое распознаваемое множество. На уровне физических сигналов вместо битовой скорости (бит/с) используют понятие скорость изменения сигнала в линии которая измеряется в бодах (baud). Под таким определением определяют число изменений различных состояний линии за единицу времени. На физическом уровне проходит синхронизация приемника и передатчика. Внешнюю синхронизацию не используют из-за дороговизны реализации еще одного канала. Много схем физического кодирования являются самосинхронизирующимися — они разрешают выделить синхросигнал из принимаемой последовательности состояний канала [11, c. 34].
Скремблирование на физическом уровне разрешает подавить очень сильные спектральные характеристики сигнала, размазывая их по некоторой полосе спектра. Очень сильные помеха искажают соседние каналы передачи.
AMI — Alternate Mark Inversion или же ABP — Alternate bipolare, биполярная схема, которая использует значения +V, 0V и -V. Все нулевые биты имеют значения 0V, единичные — чередующимися значениями +V, -V (рис.1). Применяется в DSx (DS1 — DS4), ISDN. Такая схема не есть полностью самосинхронизирующейся — длинная цепочка нулей приведет к потере синхронизации.
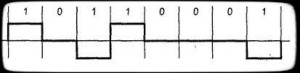
Рисунок 1 — AMI/ABP
MAMI — Modified Alternate Mark Inversion, или же ASI — модифицированная схема AMI, импульсами чередующейся полярности кодируется 0, а 1 — нулевым потенциалом. Применяется в ISDN (S/T — интерфейсы).
B8ZS
B8ZS — Bipolar with 8 Zero Substitution, схема аналогичная AMI, но для синхронизации исключает цепочки 8 и более нулей ( за счет вставки бит).
HDB3
HDB3 — High Density Bipolar 3, схема аналогичная AMI, но не допускает передачи цепочки более трех нулей. Вместо последовательности из четырех нулей вставляется один из четырех биполярных кодов. (Рис.2)

Рисунок 2 HDB3
Manchester encoding — двухфазное полярное/униполярное самосинхронизирующееся кодирование. Текущий бит узнается по направлению смены состояния в середине битового интервала: от -V к +V: 1. От +V к -V: 0. Переход в начале интервала может и не быть. Применяется в Ethernet. (В начальных версиях — униполярное). (рис.3)
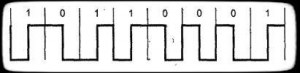
Рисунок 3 Manchester encoding
При разговоре о физическом кодирировании, возможное использование следующие термины [6]:
Транзитное кодирование — информативным есть переход из одного состояния в другое.
Потенциальное кодирование — информативным есть уровень сигнала в конкретные моменты времени.
Полярное — сигнал одной полярности реализуется для представления одного значения, сигнал другой полярности для — другого. При оптоволоконное транспортировке вместо полярности используют амплитуды импульса.
Униполярное — сигнал одной полярности реализуется для представления одного значения, нулевой сигнал — для другого.
Биполярное — используется отрицательное, положительное и нулевое значения для представления трех состояний.
Двухфазное — в каждом битовом интервале присутствует переход из одного состояния в другое, что используется для выделения синхросигнала.
Глава 2 Анализ основных методов кодирования данных
2.1 Метод кодирования Хаффмана
Рассмотрим максимум, который может получен для различных разрядных комбинацй в оптимальном дереве; данное дерево является несимметричным.
Мы получим только:
4 – 2-х разрядных кода;
8 – 3-х разрядных кодов;
16 – 4-х разрядных кодов;
32 – 5-ти разрядных кодов;
64 – 6-ти разрядных кодов;
128 – 7-ми разрядных кодов;
Всего 252 кода различной длины. Для обеспечения кодирования всех 256 символов таблицы расширенного набора ASCII необходимо добавить еще 4 8-разрядных кода. Нетрудно подсчитать, что с помощью алгоритма Хаффмана, применяемого на уровне отдельного байта, можно получить сжатие текстового файла до 33%.
Отметим, что алгоритм Хаффмана требует обрабатывать сжимаемый файл в два этапа: 1) посчитать частоты вхождения символов; 2) выполнить само кодирование [18].
Кодирование Хаффмена, вероятно, самый известный метод сжатия данных. Простота и элегантность способа сделали его на долгое время академическим фаворитом. Но коды Хаффмена имеют и практическое применение; например, статические коды Хаффмена используются на последнем этапе сжатия JPEG. Стандарт сжатия данных для модемов MNP-5 (см. "4800 Bits, No Errors", BYTE, Июнь 1989) использует динамическое сжатие Хаффмена в качестве части его процесса. Наконец, кодирование Шеннона-Фано (Shannon-Fano), довольно близкое к кодированию Хаффмена, используется как один из этапов в мощном "imploding"-алгоритме программы PkZip.
Лучше всего проиллюстрировать этот алгоритм на простом примере. Имеется пять символов с вероятностями, заданными на рис. 2.1а.
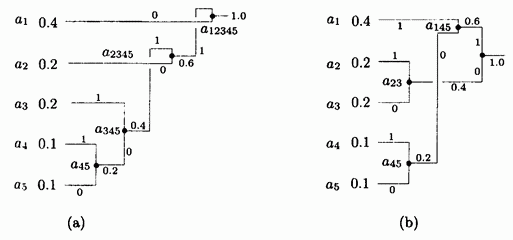
Рис. 2.1. Коды Хаффмана.
Символы объединяются в пары в следующем порядке:
1.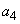 объединяется с
объединяется с 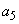 , и оба заменяются комбинированным символом
, и оба заменяются комбинированным символом 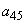 с вероятностью 0.2;
с вероятностью 0.2;
2. Осталось четыре символа, 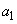 с вероятностью 0.4, а также
с вероятностью 0.4, а также 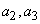 и
и 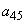 с вероятностями по 0.2. Произвольно выбираем
с вероятностями по 0.2. Произвольно выбираем 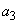 и
и 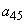 , объединяем их и заменяем вспомогательным символом
, объединяем их и заменяем вспомогательным символом 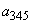 с вероятностью 0.4;
с вероятностью 0.4;
3. Теперь имеется три символа 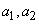 и
и 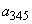 с вероятностями 0.4, 0.2 и 0.4, соответственно. Выбираем и объединяем символы
с вероятностями 0.4, 0.2 и 0.4, соответственно. Выбираем и объединяем символы 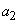 и
и 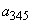 во вспомогательный символ
во вспомогательный символ 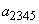 с вероятностью 0.6;
с вероятностью 0.6;
4. Наконец, объединяем два оставшихся символа 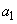 и
и 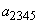 и заменяем на
и заменяем на 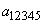 с вероятностью 1.
с вероятностью 1.
Дерево построено. Оно изображено на рис. 1.3а, «лежа на боку», с корнем справа и пятью листьями слева. Для назначения кодов мы произвольно приписываем бит 1 верхней ветке и бит 0 нижней ветке дерева для каждой пары. В результате получаем следующие коды: 0, 10, 111, 1101 и 1100. Распределение битов по краям – произвольное [7, c. 34].
Средняя длина этого кода равна 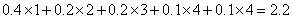 бит/символ. Очень важно то, что кодов Хаффмана бывает много. Некоторые шаги алгоритма выбирались произвольным образом, поскольку было больше символов с минимальной вероятностью. На рис. 1.3b показано, как можно объединить символы по-другому и получить иной код Хаффмана (11, 01, 00, 101 и 100). Средняя длина равна
бит/символ. Очень важно то, что кодов Хаффмана бывает много. Некоторые шаги алгоритма выбирались произвольным образом, поскольку было больше символов с минимальной вероятностью. На рис. 1.3b показано, как можно объединить символы по-другому и получить иной код Хаффмана (11, 01, 00, 101 и 100). Средняя длина равна 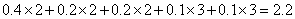 бит/символ как и у предыдущего кода.
бит/символ как и у предыдущего кода.
Мощное развитие современных методов кодирования информации конечно началось с момента опубликования основополагающих работ К.Шеннона [25, 59, 89], в которых формулируются задачи помехоустойчивой передачи информации с любой наперед заданной точностью и секретной передачи информации, предлагают в качестве решения этих задач использовать принцип случайности используемых сигналов. Эти две работы явились первыми в создаваемой их автором теории информации.
Шенноном для помехоустойчивой передачи информации предложено использовать случайные (n,k)-коды, образованные путем случайного выбора из 2n возможных двоичных комбинаций длиной n=2k комбинаций, каждая из которых отождествляется с одной из информационных комбинаций длиной k. Используя эту модель сигналов для передачи по каналу связи К.Шеннон доказал теорему о возможности передачи по каналу связи информации с вероятностью ошибки, зависящей от параметров n и k и которая может быть сделана как угодно мала путем выбора соответствующих значений этих параметров. Доказательство этой теоремы имело фундаментальное значение для создания теории помехоустойчивого кодирования, хотя не давало конструктивных предложений о реализации такой возможности [3].
Шеннону принадлежит первая серьёзная математическая работа по криптографии" и криптоанализу «Теория связи в секретных системах" ("The Communication Theory of Secrecy Systems"), выполненная в 1945 г. и опубликованная в 1949 году в журнале Bell System Technical Journal (после снятия грифа секретности). Шенноном было доказано, что путем преобразования передаваемой информации в случайную (квазислучайную) последовательность, поступающую в канал связи, можно обеспечить сколь угодно высокую степень секретности передаваемой информации, когда количество информации в криптограмме о передаваемом сообщении зависит от степени случайности передаваемых сигналов.
Появление этих работ Шеннона в то время вызвало настоящую эйфорию среди ученых и инженеров, так как казалось, что практическое решение этих задач будет так же просто и понятно, как Шеннон сделал это математически. Однако эйфория быстро прошла, так практического решения в прямой постановке Шеннона найти не удалось. В тоже время, сделанные Шенноном постановки задачи и доказательство фундаментальных теорем теории информации дали толчок для поиска решения задач с использованием детерминированных (неслучайных) сигналов и алгебраических методов помехоустойчивого кодирования защиты от помех и шифрования для обеспечения секретности информации.
Отметим, что в классической постановке упомянутые две задачи, несмотря на использование в обоих случайных сигналов, не могут решаться одновременно, главным образом по той причине, что в канале связи последовательность передаваемых сигналов не является случайной.
Коды, способные корректировать ошибки (в каналах связи и в цифровых вычислительных машинах и т. п.) при обработке сигналов, впервые были предложены американским математиком Р.У.Хэммингом (1915-1998 гг.) еще до 1948 г. Следует отметить, что пример корректирующего ошибки кода, приведенный в упомянутой статье Шеннона, инициировал исследование другого американского ученого, М. Голея (Golay, Marcel J. E.) [83], открывшего независимо от Хэмминга коды, корректирующие одиночные ошибки. Голей рассмотрел не только бинарные коды, но и коды общего вида, комбинации которых принадлежат конечному полю (математическому множеству элементов с определенными операциями сложения, вычитания, деления и умножения) с р n элементами (р – простое, а n – целое число), называемому полем Галуа [14].
Во всех современных учебниках этот класс кодов называют кодами Хэмминга, а изложение теории кодирования обычно начинают с описания их конструкции. Коды были разработаны Хэммингом еще до указанной публикации К.Шеннона, содержащей ссылку на Хэмминга. Надо отметить, что ряд основополагающих идей теории связи был известен в качестве частных математических результатов ещѐ до того, как их начали применять учёные, решающие проблемы передачи сообщений по каналам связи. К их числу относится известный американский математик Р. А. Фишер, который связал рассматриваемую проблему с математической теорией групп. Результат, сформулированный В. А. Котельниковым в качестве известной теоремы, может быть также непосредственно получен из одного из результатов теории интерполяции функции, разработанной в начале ХХ века известными английскими математиками Э.Т.Уиттекером (Whittaker E.) и Дж. Н. Ватсоном (Watson G.) [6]. Однако упомянутые ученые, конечно, не связывали свои результаты с актуальнейшими для современного мира проблемами передачи информации по каналам связи.
Пример.Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 2.
Таблица 2 Код Шеннона
|
ai |
Pi |
Qi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5a6 |
1/22≤0.36<1/2 1/23≤0.18<1/22 1/23≤0.18<1/22 1/24≤0.12<1/23 1/24≤0.09<1/231/24≤0.07<1/23 |
0.36 0.54 0.72 0.84 0.93 |
Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмана в п. 5.2 (H = 2.37), сравним его со значением средней длины кодового слова кода Шеннона
Lср= 0.36.2+(0.18+0.18).3+(0.12+0.09+0.07).4=2.92< 2.37+1,
2.3 Алфавитный код Гилберта – Мура
Е. Н. Гилбертом и Э. Ф. Муром был предложен метод построения алфавитного кода, для которого 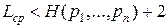 .
.
Пусть символы алфавита некоторым образом упорядочены, например, a1≤a2≤…≤an. Код  называется алфавитным, если кодовые слова лексикографически упорядочены, т.е.
называется алфавитным, если кодовые слова лексикографически упорядочены, т.е. 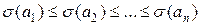 .
.
Рассмотрим источник с алфавитом А={a1,a2,…,an} и вероятностями p1,…pn. Пусть символы алфавита некоторым образом упорядочены, например, a1≤a2≤…≤an. Алфавитным называется код, в котором кодовые слова лексико-графически упорядочены, т.е. φ(a1)≤φ(a2)≤…≤φ(an).
Е.Н. Гилбертом и Э.Ф. Муром предложили метод построения алфавитного кода, для которого Lср < H+2. Процесс построения происходит следующим образом.
1. Составим суммы Qi, i=1,n, вычисленные следующим образом:
Q1=p1/2, Q2=p1+p2/2, Q3=p1+p2+p3/2,…, Qn=p1+p2+…+pn-1+pn/2.
2. Представим суммы Qi в двоичном виде.
3. В качестве кодовых слов возьмем é-log2più +1 младших бит в двоичном представлении Qi.
Пример. Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице.
Таблица 2 Код Гилберта-Мура
|
ai |
Pi |
Qi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
1/23≤0.18 1/23≤0.18<1/22 1/22≤0.36<1/21 1/24≤0.07 1/24≤0.09 1/24≤0.12 |
0.09 0.27 0.54 0.755 0.835 0.94 |
4 4 3 5 5 5 |
0001 0100 100 11000 11010 11110 |
Средняя длина кодового слова не превышает значения энтропии плюс 2
Заключение
Код — совокупность знаков (символов) и система определенных правил, при помощи которых информация может быть представлена (закодирована) в виде набора из таких символов для передачи, обработки и хранения.
Кодирование — это процесс присвоения условных обозначений объектам и классификационным группам по соответствующей системе кодирования.
Одну и ту же информацию можно выразить разными способами, например с помощью крика, предупреждающего знака, мимики или жестов. По сути, любая форма представления информации определяется как закодированная.
Соответственно необходимо знать правила, по которым можно отобразить информацию, условно назовем это кодом. Кодирование информации представляет собой переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Восстановление информации в первичном варианте но полученному коду называется декодирование. Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Кодирование часто соотносят с понятием «шифрование». Однако отличие заключается в том, что в шифрах информация может быть прочитана только пользователем, обладающим соответствующим ключом для расшифровки содержимого.
Выбор способа кодирования информации зависит от цели, ради которой оно осуществляется: например, сокращение записи, засекречивание (шифровка) информации, удобство информационного обмена между субъектами; удобство хранения, обработки и представления информации, наглядности отображения, восприятия и др.
За долгую историю развития человечество разработало много способов кодирования информации. Например, из Древнего Вавилона пришло деление часа на 60 мин и угла на 360 градусов. К англосаксам (жителям Британских островов) восходит традиция счета дюжинами: в году 12 месяцев, в футе 12 дюймов, в сутках 24 ч (два периода по 12 ч). Римскими цифрами часто записываются номер века, числа в часах.
К кодированию числовой информации относятся системы счисления: позиционная (величина цифры зависит от позиции, занимаемой этой цифрой в записи числа, например, десятичная система счисления; непозиционная, в которой величина цифры не зависит от места, занимаемого этой цифрой, примером является римская система счисления, где для обозначения цифр используются латинские буквы: I, V, X, L, С, D, М, что соответствует 1, 5, 10, 50, 100, 500, 1000.
К ярким примерам кодирования информации можно отнести: метод Морзе (кодирование информации с помощью последовательности «точек» и «тире»), метод Бодо (5-битная система кодирования символов), метод Шеннона — Фано (алгоритм префиксного неоднородного кодирования), алгоритм Хаффмана (оптимальное кодирование), шрифт Брайля (рельефно-точечный тактильный шрифт, предназначенный для письма и чтения незрячими людьми), штрихкод(графическая информация об объекте в виде черных и белых полос), стенография (быстрый способ записи устной речи).
Основной системой счисления в компьютере является двоичная позиционная система счисления. Кодирование информации происходит в виде последовательности нулей и единиц.
Алгоритм метода Шеннона-Фано — один из первых алгоритмов сжатия, который впервые сформулировали американские учёные Шеннон и Фано, и он имеет большое сходство с алгоритмом Хаффмана. Алгоритм основан на частоте повторения. Так, часто встречающийся символ кодируется кодом меньшей длины, а редко встречающийся — кодом большей длины.
В свою очередь, коды, полученные при кодировании, префиксные. Это и позволяет однозначно декодировать любую последовательность кодовых слов. Но все это вступление.
Для работы оба алгоритма должны иметь таблицу частот элементов алфавита.
Итак, алгоритм Хаффмана работает следующим образом:
На вход приходят упорядоченные по невозрастанию частот данные.
Выбираются две наименьших по частоте буквы алфавита, и создается родитель (сумма двух частот этих «листков»).
Потомки удаляются и вместо них записывается родитель, «ветви» родителя нумеруются: левой ветви ставится в соответствие «1», правой «0».
Шаг два повторяется до тех пор, пока не будет найден главный родитель — «корень».
Алгоритм Шеннона-Фано работает следующим образом:
На вход приходят упорядоченные по невозрастанию частот данные.
Находится середина, которая делит алфавит примерно на две части. Эти части (суммы частот алфавита) примерно равны. Для левой части присваивается «1», для правой «0», таким образом мы получим листья дерева
Шаг 2 повторяется до тех пор, пока мы не получим единственный элемент последовательности, т.е. листок
Таким образом, видно, что алгоритм Хаффмана как бы движется от листьев к корню, а алгоритм Шеннона-Фано, используя деление, движется от корня к листям.
Список литературы
1. Баззел, Р.Д. Информация и риск в маркетинге / Р.Д. Баззел, Д.Ф. Кокс, Р.В. Браун. - М.: Финстатинформ, 2015. - 758 c.
2. Белоногов, Г.Г. Автоматизация процессов накопления, поиска и обобщения информации / Г.Г. Белоногов, А.П. Новоселов. - М.: Наука, 2017. - 256 c.
3. Берлекэмп, Э. Алгебраическая теория кодирования / Э. Берлекэмп. - М.: [не указано], 2017. - 575 c.
4. Берновский, Ю.Н. Классификация и кодирование промышленной и сельскохозяйственной продукции / Ю.Н. Берновский, В.А. Захаров, Р.А. Сергиевский, и др.. - М.: Стандартов, 2015. - 183 c.
5. Верещагин, Н. К. Информация, кодирование и предсказание / Н.К. Верещагин, Е.В. Щепин. - М.: ФМОП, МЦНМО, 2016. - 240 c.
6. Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. Кодирование Шеннона-Фано. 2002.
7. Галицкий, А.В. Защита информации в сети - анализ технологий и синтез решений / А.В. Галицкий, С.Д. Рябко, В.Ф. Шаньгин. - М.: ДМК Пресс, 2013. - 615 c.
8. Гоппа, В.Д. Введение в алгебраическую теорию информации / В.Д. Гоппа. - М.: [не указано], 2013. - 434 c.
9. Гоппа, В.Д. Введение в алгебраическую теорию информации / В.Д. Гоппа. - М.: ФИЗМАТЛИТ, 2013. - 112 c.
10. Информация президиума правления всероссийского театрального общества (январь-апрель 1980 г.). - М.: Всероссийское театральное общество, 2017. - 269 c.
11. Кадомцев, Б.Б. Динамика и информация / Б.Б. Кадомцев. - М.: [не указано], 2016. - 856 c.
12. Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М.Я. Кельберт, Ю.М. Сухов. - М.: МЦНМО, 2014. - 568 c.
13. Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М.Я. Кельберт. - М.: МЦНМО, 2016. - 366 c.
14. Кошкин Г.М. Энтропия и информация // Соросовский образовательный журнал. Т.7. №11. 2001. С. 127.
15. Кузнецова, Е.Ю. Информатика. Информация. Кодирование и измерение / Е.Ю. Кузнецова. - М.: Бином. Лаборатория знаний, 2014. - 345 c.
16. Лазарев Информация и безопасность. Композиционная технология информационного моделирования сложных объектов принятия решений / Лазарев, Алексеевич Игорь. - М.: Московский городской центр научно-технической информации, 2017. - 336 c.
17. Мальцев, Ю.Н. Введение в дискретную математику. Элементы комбинаторики, теории графов и теории кодирования / Ю.Н. Мальцев, Е.П. Петров. - М.: [не указано], 2013. - 488 c.
18. Малюк, А.А. Введение в защиту информации в автоматизированных системах. Учебное пособие / А.А. Малюк. - М.: Горячая линия - Телеком, 2016. - 148 c.
19. Мельников Защита информации в компьютерных системах / Мельников, Викторович Виталий. - М.: Финансы и статистика; Электроинформ, 2014. - 368 c.
20. Соколов, А.В. Защита информации в распределенных корпоративных сетях и системах / А.В. Соколов, В.Ф. Шаньгин. - М.: ДМК Пресс, 2014. - 656 c.
21. Спесивцев, А.В. Защита информации в персональных ЭВМ / А.В. Спесивцев, В.А. Вегнер, А.Ю. Крутяков. - М.: Радио и связь, 2015. - 192 c.
22. Фомичев, А. И. Детерминированный хаос и кодирование информации / А.И. Фомичев. - М.: Университет, 2016. - 614 c.
23. Хазен, А.М. Введение меры информации в аксиоматическую базу механики / А.М. Хазен. - М.: [не указано], 2013. - 465 c.
24. Холево, А.С. Введение в квантовую теорию информации / А.С. Холево. - М.: [не указано], 2013. - 154 c.
25. Цымбал, В.П. Задачник по теории информации и кодированию / В.П. Цымбал. - Москва: Наука, 2014. - 307 c.
26. Чечета, С. И. Введение в дискретную теорию информации и кодирования. Учебное пособие / С.И. Чечета. - М.: МЦНМО, 2014. - 224 c.
27. Чечета, С.В. Введение в дискретную теорию информации и кодирования / С.В. Чечета. - М.: Московский центр непрерывного математического образования (МЦНМО), 2015. - 965 c.
28. Шаньгин, В.Ф. Защита компьютерной информации / В.Ф. Шаньгин. - М.: ДМК Пресс, 2014. - 544 c.

- Пространство политических коммуникаций региона: взаимодействие региональной власти и СМИ»
- Дидактическая игра как средство активизации познавательной̆ деятельности младших школьников.
- Роль игровой деятельности в развитии самооценки у детей дошкольного возраста
- Понятие и виды ценных бумаг (Правовая характеристика ценных бумаг по Российскому законодательству).
- Возмещение морального вреда (Понятие морального вреда).
- Бухгалтерская отчетность организации: порядок ее составления и анализ.
- Описание бизнес-процессов «TO-BE»
- Проблема оценивания учебной деятельности младших школьников»
- Основные направления реформирования местного самоуправления в Российской Федерации (Становление правовых основ организации местного самоуправления в Российской Федерации)
- Виды налогов. Классификация налогов. Налоговая система. Налоговая политика ( Понятие и виды налогов. Сущность налоговой системы и налоговой политики)
- Психолингвистические методы анализа деловой документации и переписки»
- ТЕХНОЛОГИЯ «КЛИЕНТ-СЕРВЕР».