
Методы кодирования данных ( Кодирование целых И действительных чисел)
Содержание:

Введение
Изучение дисциплины «Технологии программирования» является одним из основных моментов в процессе подготовки специалистов по разработке программного обеспечения для компьютерных систем. Это связано с тем, что первичная задача программиста заключается в применении решения о форме представления данных и выборе алгоритмов для обработки этих данных. И лишь затем выбранные структуры программы и данных реализуется на конкретном языке программирования. В связи с этим знание классических методов и приемов обработки данных позволяет избежать ошибок, которые могут возникать при чисто интуитивной разработке программ.
Так же важнейшей частью информатики как науки является теория информации, которая занимается изучением информации как таковой, ее появлением, развитием и уничтожением. К этой науке близко примыкает теория кодирования, в задачу которой входит изучение форм представления информации при ее передаче по различным каналам связи, а также при хранении и обработке.
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, которые заложили фундамент для дальнейших исследований в этой области.
Кодирование – способ представления информации в удобном для хранения и передачи виде. В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования, таких как:
-
- представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
- обеспечение помехоустойчивости при передаче данных по каналам связи;
- сжатие информации в базах данных.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов:
Источник
Шум
Приемник
Кодер
источника
Кодер
канала
Декодер
канала
Декодер
источника
Канал
Рисунок 1 Модель системы передачи сигналов
Начальным звеном в приведенной выше модели является источник информации. Здесь рассматриваются дискретные источники без памяти, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 33 русских букв, пробела и знаков препинания.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Код — это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении. Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями. Кодирование - это преобразование сообщений в сигнал, т.е. преобразование сообщений в кодовые комбинации. Код - система соответствия между элементами сообщений и кодовыми комбинациями. Кодер - устройство, осуществляющее кодирование. Декодер - устройство, осуществляющее обратную операцию, т.е. преобразование кодовой комбинации в сообщение. Алфавит - множество возможных элементов кода, т.е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,..., m. Количество элементов кода - m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации – n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Если N0 - число сообщений источника, то N ³ N0. Множество состояний кода должно покрывать множество состояний объекта. Полный равномерный n - значный код с основанием m содержит N = mn кодовых комбинаций. Такой код называется примитивным.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Целые числа кодируются двоичным кодом достаточно просто — достаточно взять, целое число и делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанная справа налево вместе с последним остатком, и образует двоичный аналог десятичного числа.
19:2 = 9+1
9:2 = 4+1
4:2 = 2+0
2:2 = 1
Таким образом, 1910 = 10112
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 8-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 × 101
300 000 = 0,3 × 106
123 456 789 = 0,123456789 × 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 8 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком).
Для того, чтобы записать в памяти ЭВМ действительное число, сначала его необходимо преобразовать в экспоненциальную форму. Посмотрим на примере, как это происходит.
Возьмем действительное число 184,525. В информатике принято отделять целую часть от дробной не десятичной запятой, а точкой. В соответствии с этим правилом, перепишем: 184.525.
Экспоненциальная форма предполагает такой способ записи действительного числа, при котором выделяется мантисса и порядок. Тогда число принимает следующий вид:
0.184525Е+3,
где 184525 — мантисса, 3 — порядок, Е заменяет десятичное основание степени.
Действительное число может быть как положительным, так и отрицательным. Значит, в экспоненциальном виде и мантисса, и порядок могут иметь как положительные, так и отрицательные знаки. Поэтому, при записи действительного числа в память ЭВМ, это необходимо учитывать.
Таким образом, в общем виде экспоненциальная форма записи действительного числа имеет следующий вид:
± 0.ХХХХХЕ ± XX.
Такая форма записи позволяет увидеть, что мантисса и порядок отделены друг от друга. Поэтому хранить их в памяти ЭВМ можно отдельно друг от друга.
Кодирование буквенно-цифровой и символьной информации
Помимо целых и действительных чисел, в памяти ЭВМ находится буквенно-цифровая и символьная информация, посредством которой формируются тексты различного содержания. Это могут быть буквы латинского, русского или какого-либо другого алфавита, цифры (не путать с числами!), формулы, а также различные другие символы.
Обратимся к тому факту, что один байт состоит из восьми битов. Это означает, что количество возможных комбинаций, состоящих из восьми нулей и единиц, составляет 28=256. Это, в свою очередь, обозначает возможность закодировать 256 различных символов.
Такого количества оказывается достаточно, чтобы закодировать буквы латинского алфавита — их всего 52 буквы (26 строчных и 26 заглавных); десятичные цифры 0....9; знаки препинания; арифметические знаки и другие символы.
Информация называется закодированной, если каждая ее элементарная частица представлена в виде двоичного кода.
Если в печатной продукции текстовая информация представляет собой набор напечатанных букв, то в памяти ЭВМ информация представлена в виде последовательности кодов букв. Иначе говоря, вместо каждой буквы текста хранится ее номер кода. И только при выводе на внешние устройства, например, дисплей или принтер, происходит формирование изображения привычных нашему восприятию букв в соответствии с их кодами.
Существует несколько вариантов кодировки. Наиболее распространенным считается ASCII (American national Standard Code for Information Interchange), что переводится на русский как американский стандартный код обмена информацией. В качестве примера приведем коды нескольких букв латинского алфавита:
А 01000001, а 01100001,
В 01000010, b 01100010,
С 01000011, с 01100011;
десятичных цифр:
0 00110000,
1 00110001,
2 00110010,
Существуют и другие, менее распространенные кодировки, такие как, КОИ-7 (код обмена информацией, семизначный), КОИ-8 (код обмена информации, восьмизначный), кодировка символов русского языка — Windows-1251 и UNICODE — универсальная, основанная на 16-разрядном кодировании символов.
В этом параграфе приведены некоторые теоремы о свойствах побуквенного кодирования.
Пусть даны алфавит источника , кодовый алфавит . Обозначим множество всевозможных последовательностей в алфавите А (В). Множество всех сообщений в алфавите А обозначим S. Кодирование может сопоставлять код всему сообщению из множества S как единому целому или строить код сообщения из кодов его частей (побуквенное кодирование).
Побуквенное кодирование задается таблицей кодовых слов: , , . Множество кодовых слов V={βi} называется множеством элементарных кодов. Используя побуквенное кодирование, можно закодировать любое сообщение следующим образом , т.е. общий код сообщения складывается из элементарных кодов символов входного алфавита.
Количество букв в слове α=α1…αk называется длиной слова. (Обозначение |α|=k) Пустое слово, т.е. слово, не содержащее ни одного символа обозначается Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
Побуквенный код называется разделимым (или однозначно декодируемым), если любое сообщение из символов алфавита источника, закодированное этим кодом, может быть однозначно декодировано, т.е. если βi1 …βik=βj1…βjt , то k=t и при любых s=1,…,k is=js . При разделимом кодировании любое кодовое слово единственным образом разлагается на элементарные коды.
Побуквенное кодирование задается таблицей кодовых слов: , ,. Множество кодовых словV={βi} называется множеством элементарных кодов. Используя побуквенное кодирование, можно закодировать любое сообщение следующим образом, т.е. общий код сообщения складывается из элементарных кодов символов входного алфавита.
Количество букв в слове α=α1…αk называется длиной слова. (Обозначение |α|=k) Пустое слово, т.е. слово, не содержащее ни одного символа обозначается Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
Побуквенный код называется разделимым (или однозначно декодируемым), если любое сообщение из символов алфавита источника, закодированное этим кодом, может быть однозначно декодировано, т.е. если βi1 …βik=βj1…βjt , то k=t и при любых s=1,…,k is=js . При разделимом кодировании любое кодовое слово единственным образом разлагается на элементарные коды.
При кодировании сообщений считается, что символы сообщения порождаются некоторым источником информации. Источник считается заданным полностью, если дано вероятностное описание процесса появления сообщений на выходе источника. Это означает, что в любой момент времени определена вероятность порождения источником любой последовательности символов Р(x1x2x3...xL), L≥1. Такой источник называется дискретным вероятностным источником.
Если вероятностный источник с алфавитом А={a1, a2, ..., an} порождает символы алфавита независимо друг от друга, т.е. знание предшествующих символов не влияет на вероятность последующих, то такой источник называется бернуллиевским. Тогда для любой последовательности x1x2...xL, L≥1, порождаемой источником, выполняется равенство:
P(x1x2...xL ) = P(x1)·P(x2)·...·P(xL),
где P(x) – вероятность появления символа х, Р(x1x2x3...xL) – вероятность появления последовательности x1x2x3...xL.
Для другого класса источников (марковских) существует статистическая взаимосвязь между порождаемыми символами. В дальнейшем мы будем рассматривать кодирование стационарных (с неизменным распределением вероятностей) бернуллиевских дискретных источников без памяти.
Пусть имеется дискретный вероятностный источник без памяти, порождающий символы алфавита А={a1,…,an} с вероятностями , . Основной характеристикой источника является энтропия, которая представляет собой среднее значение количества информации в сообщении источника и определяется выражением (для двоичного случая)
.
Энтропия характеризует меру неопределенности выбора для данного источника.
Метод оптимального побуквенного кодирования был разработан в 1952 г. Д. Хаффманом. Оптимальный код Хаффмана обладает минимальной средней длиной кодового слова среди всех побуквенных кодов для данного источника с алфавитом А={a1,…,an} и вероятностями pi =P(ai).
Рассмотрим алгоритм построения оптимального кода Хаффмана, который основывается на утверждениях лемм предыдущего параграфа.
- Упорядочим символы исходного алфавита А={a1,…,an} по убыванию их вероятностей p1≥p2≥…≥pn.
- Если А={a1,a2}, то a10, a21.
- Если А={a1,…,aj,…,an} и известны коды <aj bj >, j = 1,…,n, то для алфавита {a1,…aj/, aj//…,an} с новыми символами aj/ и aj// вместо aj, и вероятностями p(aj)=p(aj/)+ p(aj//), код символа aj заменяется на коды aj/ bj0, aj// bj1.
Код Хаффмана обычно строится и хранится в виде двоичного дерева, в листьях которого находятся символы алфавита, а на «ветвях» – 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 собираются в одну уникальную последовательность (рис. 2).
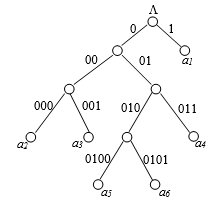
Рисунок 2 Кодовое дерево для кода Хаффмана
Рассмотрим несколько классических побуквенных кодов, у которых средняя длина кодового слова близка к оптимальной. Пусть имеется дискретный вероятностный источник, порождающий символы алфавита А={a1,…,an} с вероятностями pi = P(ai).
Код Шеннона позволяет построить почти оптимальный код с длинами кодовых слов . Тогда по теореме Шеннона из п. 5.1
.
Код Шеннона, удовлетворяющий этому соотношению, строится следующим образом:
- Упорядочим символы исходного алфавита А={a1,a2,…,an} по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
- Вычислим величины Qi:, которые называются кумулятивные вероятности
Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, … , Qn=1.
- Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые знаков после запятой.
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения
, .
Метод Фано построения префиксного почти оптимального кода, для которого , заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на две части так, чтобы суммы вероятностей букв, входящих в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве.
Е. Н. Гилбертом и Э. Ф. Муром был предложен метод построения алфавитного кода, для которого .
Пусть символы алфавита некоторым образом упорядочены, например, a1≤a2≤…≤an. Код называется алфавитным, если кодовые слова лексикографически упорядочены, т.е. .
Процесс построения кода происходит следующим образом.
- Вычислим величины Qi, i=1,n:
Q1=p1/2,
Q2=p1+p2/2,
Q3=p1+p2+p3/2,
…
Qn=p1+p2+…+pn-1+pn/2.
- Представим суммы Qi в двоичном виде.
- В качестве кодовых слов возьмем младших бит в двоичном представлении Qi, .
Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 8.
Таблица 8 Код Гилберта-Мура
|
ai |
Pi |
Qi |
Li |
кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
1/23≤0.18 1/23≤0.18<1/22 1/22≤0.36<1/21 1/24≤0.07 1/24≤0.09 1/24≤0.12 |
0.09 0.27 0.54 0.755 0.835 0.94 |
4 4 3 5 5 5 |
0001 0100 100 11000 11010 11110 |
Средняя длина кодового слова не превышает значения энтропии плюс 2. Действительно,
Lср=4.0.18+4.0.18+3.0.36+5.0.07+5.0.09+5.0.12=3.92<2.37+2
Идея арифметического кодирования была впервые предложена П. Элиасом. В арифметическом коде кодируемое сообщение разбивается на блоки постоянной длины, которые затем кодируются отдельно. При этом при увеличении длины блока средняя длина кодового слова стремится к энтропии, однако возрастает сложность реализации алгоритма и уменьшается скорость кодирования и декодирования. Таким образом, арифметическое кодирование позволяет получить произвольно малую избыточность при кодировании достаточно больших блоков входного сообщения.
Рассмотрим общую идею арифметического кодирования. Пусть дан источник, порождающий буквы из алфавита А={a1,a2,…,an} с вероятностями pi=P(ai), . Необходимо закодировать последовательность символов данного источника Х=х1х2х3х4.
- Вычислим кумулятивные вероятности Q0 ,Q1,…,Qn:
Q0=0
Q1=p1
Q2=p1+p2
Q3=p1+p2+p3
...
Qn=p1+p2+…+pn=1
- Разобьем интервал [Q0,Qn) (т.е. интервал [0,1)) так, чтобы каждой букве исходного алфавита соответствовал свой интервал, равный ее вероятности (см. рис. 3):
a1 [Q0,Q1)
a2 [Q1,Q2)
a3 [Q2,Q3)
a4 [Q3,Q4)
...
an [Qn-1,Qn)
-
- В процессе кодирования будем выбирать интервал, соответствующий текущей букве исходного сообщения, и снова разбивать его пропорционально вероятностям исходных букв алфавита. Постепенно происходит сужение интервала до тех пор, пока не будет закодирован последний символ кодируемого сообщения. Двоичное представление любой точки, расположенной внутри интервала, и будет кодом исходного сообщения.
На рисунке 3 показан этот процесс для кодирования последовательности а3а2а3…
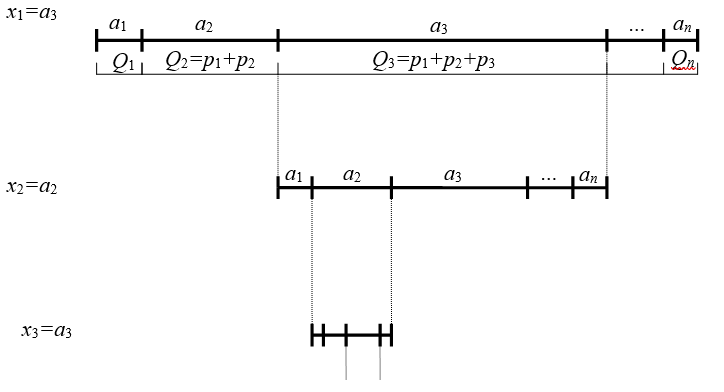
Рисунок 3 Схема арифметического кодирования
Для удобства вычислений введем следующие обозначения:
li нижняя граница отрезка, соответствующего i-той букве исходного сообщения;
hi верхняя граница этого отрезка;
ri длина отрезка [li, hi), т.е. ri = hi li.
Возьмем начальные значения этих величин
l0 = Q0=0, h0 = Qk=1, r0 = h0 l0=1
и далее будем вычислять границы интервала, соответствующего кодируемой букве по формулам:
, ,
где m порядковый номер кодируемой буквы в алфавите источника, m=1,...,n.
Таким образом, окончательная длина интервала равна произведению вероятностей всех встретившихся символов, а начало интервала зависит от порядка расположения символов в кодируемой последовательности.
Для однозначного декодирования исходной последовательности достаточно взять разрядов двоичной записи любой точки из интервала [li,hi), где rk длина интервала после кодирования k символов источника.
При решении реальных задач истинные значения вероятностей источника, как правило, неизвестны или могут изменяться с течением времени, поэтому для кодирования сообщений применяют адаптивные модификации методов кодирования.
Большинство адаптивных методов для учета изменений статистики исходных данных используют так называемое окно. Окном называют последовательность символов, предшествующих кодируемой букве, а длиной окна количество символов в окне.
Обычно окно имеет фиксированную длину и после кодирования каждой буквы текста окно передвигается на один символ вправо. Таким образом, код для очередной буквы строится с учетом информации, хранящейся в данный момент в окне (см. рис. 4).
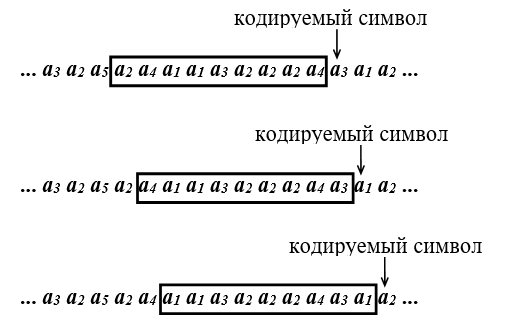
Рисунок 4 Схема перемещения окна при кодировании
При декодировании окно передвигается по тексту аналогичным образом. Информация, содержащаяся в окне, позволяет однозначно декодировать очередной символ.
Оценка избыточности при адаптивном кодировании является достаточно сложной математической задачей, поскольку общая избыточность складывается из двух составляющих: избыточность кодирования и избыточность, возникающая при оценке вероятностей появления символов. Поэтому эффективность методов адаптивного кодирования зачастую оценивают экспериментальным путем.
Однако для всех методов адаптивного кодирования, которые приводятся в этой главе, справедлива следующая теорема:
Теорема. Величина средней длины кодового слова при адаптивном кодировании удовлетворяет неравенству
,
где Н – энтропия источника информации, C – константа, зависящая от размера алфавита источника и длины окна.
В 1978 году Р. Галлагер предложил метод кодирования источников с неизвестной или меняющейся статистикой, основанный на коде Хаффмана, и поэтому названный адаптивным кодом Хаффмана.
Адаптивный код Хаффмана используется как составная часть во многих методах сжатия данных. В нем кодирование осуществляется на основе информации, содержащейся в окне длины W. Алгоритм такого кодирования заключается в выполнении следующих действий:
- Перед кодированием очередной буквы подсчитываются частоты появления в окне всех символов исходного алфавита А={a1, a2, ..., an}. Обозначим эти частоты как q(a1), q(a2), ..., q(an). Вероятности символов исходного алфавита оцениваются на основе значений частот символов в окне
P(a1)= q(a1)/W, P(a2) =q(a2)/W, ..., P(an)= q(an)/W.
- По полученному распределению вероятностей строится код Хаффмана для алфавита А.
- Очередная буква кодируется при помощи построенного кода.
- Окно передвигается на один символ вправо, вновь подсчитываются частоты встреч в окне букв алфавита, строится новый код для очередного символа, и так далее, пока не будет получен код всего сообщения.
Рассмотрим пример адаптивного кодирования с помощью метода Хаффмана для алфавита А={a1, a2, a3, a4} и длины окна W=6 (см. рис. 5).
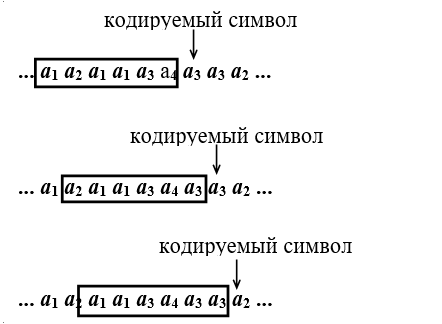
Рисунок 5 Кодирование адаптивным кодом Хаффмана
Рассмотрим подробно этапы кодирования сообщения.
При кодировании буквы a3 получаем следующие частоты встреч символов в окне: q(a1)=3, q(a2)=1, q(a3)=1, q(a4)=1. Тогда вероятности символов алфавита A оцениваются так
Строим код Хаффмана для полученного распределения вероятностей (см. рис. 6 (а)) и кодируем символ а3 кодовым символом 001.
a)
|
Символы |
Вероятности |
Построение кода |
Кодовые cлова |
|
а1 |
1/2 |
1 |
1 |
|
а2 |
1/6 |
1/2 0 |
01 |
|
а3 |
1/6 |
1/3 |
001 |
|
а4 |
1/6 |
000 |
б)
|
Символы |
Вероятности |
Построение кода |
Кодовые слова |
|
а1 |
1/3 |
1 |
1 |
|
а2 |
1/6 |
1/3 2/3 0 |
011 |
|
а3 |
1/3 |
00 |
|
|
а4 |
1/6 |
010 |
в)
|
Символы |
Вероятности |
Построение кода |
Кодовые слова |
|
а1 |
1/3 |
1/2 1 |
11 |
|
а2 |
0 |
1/6 0 |
101 |
|
а3 |
1/2 |
0 |
|
|
а4 |
1/6 |
100 |
Рисунок 6 Построение адаптивного кода Хаффмана
Далее передвигаем окно на один символ вправо и снова подсчитываем частоты встреч символов в окне q(a1)=2, q(a2)=1, q(a3)=2, q(a4)=1 и оцениваем вероятности:
Строим код на основе полученных оценок вероятностного распределения (см. рис. 6 (б)) и кодируем очередной символ а3 другим кодовым словом 00. В этом случае частота встречи в окне символа а3 увеличилась, соответственно уменьшилась длина его кодового слова.
Снова передвигаем окно на один символ вправо, подсчитываем частоты встреч символов в окне q(a1)=2, q(a2)=0, q(a3)=3, q(a4)=1 и оцениваем вероятности:
Строим код на основе полученных оценок вероятностного распределения (см. рис. 6 (в)) и кодируем очередной символ а2 кодовым словом 101. Таким образом, после кодирования символов a3a3a2 получаем кодовую последовательность 00100101.
Этот метод был предложен Б. Я. Рябко в 1980 году. Название метод получил по аналогии со стопкой книг, лежащей на столе. Обычно сверху стопки находятся книги, которые недавно использовались, а внизу стопки – книги, которые использовались давно, и после каждого обращения к стопке использованная книга кладется сверху стопки.
До начала кодирования буквы исходного алфавита упорядочены произвольным образом и каждой позиции в стопке присвоено свое кодовое слово, причем первой позиции стопки соответствует самое короткое кодовое слово, а последней позиции самое длинное кодовое слово. Очередной символ кодируется кодовым словом, соответствующим номеру его позиции в стопке, и переставляется на первую позицию в стопке.
Приведем описание кода на примере алфавита A={a1,a2,a3,a4}. Пусть кодируется сообщение а3а3а4а4а3…
- Символ а3 находится в третьей позиции стопки, кодируется кодовым словом 110 и перемещается на первую позицию в стопке, при этом символы а1 и а2 смещаются на одну позицию вниз.
- Следующий символ а3 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
- Символ а4 находится в последней позиции стопки, кодируется кодовым словом 111 и перемещается на первую позицию в стопке, при этом символы а1, а2, а3 смещаются на одну позицию вниз.
- Следующий символ а4 уже находится в первой позиции стопки, кодируется кодовым словом 0 и стопка не изменяется.
- Символ а3 находится во второй позиции стопки, кодируется кодовым словом 10 и перемещается на первую позицию в стопке, при этом символ а4 смещается на одну позицию вниз.
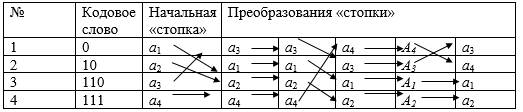
Рисунок 7 Кодирование методом «стопка книг»
Таким образом, закодированное сообщение имеет следующий вид:
110 0 111 0 10 …
а3 а3 а4 а4 a3
Рассмотренный метод сжимает сообщение за счет того, что часто встречающиеся символы будут находиться в верхних позициях «стопки книг» и кодироваться более короткими кодовыми словами. Эффективность метода особенно заметна при кодировании серий одинаковых символов. В этом случае все символы серии, начиная со второго, будут кодироваться самым коротким кодовым словом, соответствующим первой позиции «стопки книг».
При декодировании используется такая же «стопка книг», находящаяся первоначально в том же состоянии. Над «стопкой» проводятся такие же преобразования, что и при кодировании. Это гарантирует однозначное восстановление исходной последовательности.
Приведение описание данного алгоритма на псевдокоде.
Интервальный код был предложен П. Элиасом в 1987 году. В нем используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:

При кодировании символа xi определяется расстояние (интервал) до его предыдущей встречи в окне длины W. Обозначим это расстояние (xi). Если символ есть xi в окне, то значение (xi) равно номеру позиции символа в окне. Позиции в окне нумеруются справа налево. Если символа xi нет в окне, то (xi) присваивается значение W+1, а xi кодируется словом, состоящим из (xi) и самого символа xi. После кодирования очередного символа окно сдвигается вправо на один символ.
Возьмем описание кода для исходного алфавита A={a1,a2,a3,a4}, пусть длина окна W=3. Возьмем некоторый префиксный код для записи числа (Xi):
|
(хi) |
1 |
2 |
3 |
4 |
|
σi |
0 |
10 |
110 |
111 |
Пусть кодируется последовательность а1а1а2а3а2а2… (см. рис. 8)
- Сначала символа а1 нет в окне, поэтому на выход кодера передается 111 и восьмибитовый ASCII-код символа а1 Затем окно сдвигается на одну позицию вправо.
- При кодировании следующего символа а1 на выход кодера передается 0, так как теперь символ а1 находится в первой позиции окна. Далее окно снова сдвигается на одну позицию вправо.
- Следующий символ а2 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а2, так как символа а2 нет в окне. Окно снова сдвигается на одну позицию вправо.
- Следующий символ а3 кодируется комбинацией 111 и восьмибитовым ASCII-кодом символа а3 , так как символа а3 нет в окне. Окно снова сдвигается на одну позицию вправо.
- Следующий кодируемый символ а2 находим во второй позиции окна и поэтому кодируем комбинацией 10. Окно снова сдвигается на одну позицию вправо.
- И последний символ а2 находим во первой позиции окна и поэтому кодируем комбинацией 0. Таким образом, закодированное сообщение имеет следующий вид:
111 а1 0 111 а2 111 а3 10 0
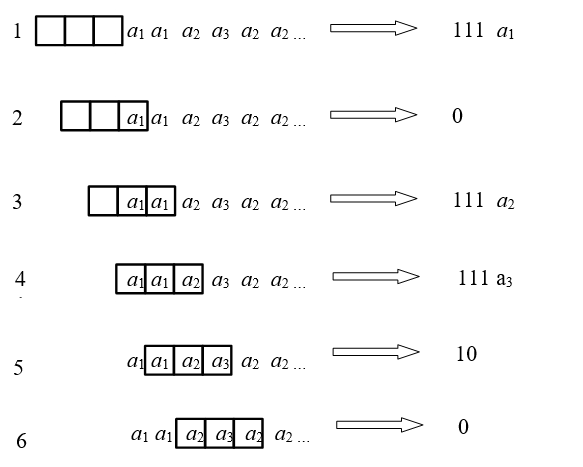
Рисунок 8 Кодирование интервальным кодом
При декодировании используется такое же окно, как и при кодировании. По принятому кодовому слову можно определить, в какой позиции окна находится данный символ. Если поступает код 111, то декодер считывает следующий за ним символ. Каждая декодированная буква полностью включается в окно.
Сжатие данных интервальным кодом достигается за счет малых расстояний между встречами более вероятных букв, что позволяет получить более короткие кодовые слова.
В 1990 году Б. Я. Рябко предложил алгоритм кодирования, использующий алфавитный код Гилберта-Мура, и названный частотным. Частотный код относится к адаптивным методам сжатия с постоянной избыточностью. Средняя длина кодового слова для этого метода определяется только длиной окна, по которому оценивается статистика кодируемых данных, к тому же частотный код имеет достаточно высокую скорость кодирования и декодирования.
Рассмотрим алгоритм построения частотного кода для источника с алфавитом А={a1, a2, ..., an}. Пусть используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:
Возьмем размер окна такой, что W=(2r 1)·n, где n=2k размер исходного алфавита, r, k целые числа.
Порядок построения кодовой последовательности, следующий:
- Сначала оценивается число встреч в окне xi-W...xi-1 всех букв исходного алфавита. Обозначим эти величины через P(aj), j=1,…,n
- P(aj) увеличивается на единицу и обозначается как
- Вычисляются суммы Qi , i=1,…,n
…
- Для кодового слова символа аj берется k знаков от двоичного разложения Qj, где .
- Далее окно сдвигается на один символ вправо и для кодирования следующего символа алгоритм вновь повторяется.
- словарные коды класса Lz
Словарные коды класса LZ широко используются в практических задачах. На их основе реализовано множество программ-архиваторов. Эти методы также используются при сжатии изображений в модемах и других цифровых устройствах передачи и хранения информации.
Словарные методы сжатия данных позволяют эффективно кодировать источники с неизвестной или меняющейся статистикой. Важными свойствами этих методов являются высокая скорость кодирования и декодирования, а также относительно небольшая сложность реализации. Кроме того, LZ-методы обладают способностью быстро адаптироваться к изменению статистической структуры сообщений.
Словарные коды интенсивно исследуются и конструируются, начиная с 1977 года, когда появилось описание первого алгоритма, предложенного А. Лемпелом и Я. Зивом. В настоящее время существует множество методов, объединенных в класс LZ-кодов, которые представляют собой различные модификации метода Лемпела-Зива.
Общая схема кодирования, используемая в LZ-методах, заключается в следующем. При кодировании сообщение разбивается на слова переменной длины. При обработке очередного слова ведется поиск ему подобного в ранее закодированной части сообщения. Если слово найдено, то передается соответствующий ему код. Если слово не найдено, то передается специальный символ, обозначающий его отсутствие, и новое обозначение этого слова. Каждое новое слово, не встречавшееся ранее, запоминается, и ему присваивается индивидуальный код.
При декодировании по принятому коду определяется закодированное слово. В случае получения специального символа, сигнализирующего о передаче нового слова, принятое слово запоминается, и ему присваивается такой же, как и при кодировании, код. Таким образом, декодирование является однозначным, т.к. каждому слову соответствует свой собственный код.
По способу организации хранения и поиска слов словарные методы можно разделить на две большие группы:
- алгоритмы, осуществляющие поиск слов в какой-либо части ранее закодированного текста, называемой окном;
- алгоритмы, использующие адаптивный словарь, который включает ранее встретившиеся слова. Если словарь заполняется до окончания процесса кодирования, то в некоторых методах он обновляется (на место ранее встретившихся слов записываются новые), а в некоторых кодирование продолжается без обновления словаря.
Алгоритмы класса LZ отличаются размерами окна, способами кодирования слов, алгоритмами обновления словаря и т.п. Все указанные факторы влияют и на характеристики этих методов: скорость кодирования, объем требуемой памяти и степень сжатия данных, различные для разных алгоритмов. Однако в целом методы из класса LZ представляют значительный практический интерес и позволяют достаточно эффективно сжимать данные с неизвестной статистикой.
Рассмотрим основные этапы кодирования сообщения Х=х1х2х3х4…, которое порождается некоторым источником информации с алфавитом А. Пусть используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:
Сначала осуществляется поиск в окне символа х1. Если символ не найден, то в качестве кода передается 0 как признак того, что этого символа нет в окне и двоичное представление х1.
Если символ х1 найден, то осуществляется поиск в окне слова х1х2, начинающегося с этого символа. Если слово х1х2 есть в окне, то производится поиск слова х1х2х3 , затем х1х2х3х4 и так далее, пока не будет найдено слово, состоящее из наибольшего количества входных символов в порядке их поступления. В этом случае в качестве кода передается 1 и пара чисел (i, j), указывающая положение найденного слова в окне (i – номер позиции окна, с которой начинается это слово, j – длина этого слова, позиции в окне нумеруются справа налево). Затем окно сдвигается на j символов вправо по тексту и кодирование продолжается.
Для кодирования чисел (i, j) могут быть использованы рассмотренные ранее коды целых чисел.
Пусть алфавит источника А={а, b, с}, длина окна W=6. Необходимо закодировать исходное сообщение bababaabacabac. (см. рис. 9)
После кодирования первых шести букв окно будет иметь вид bababa.
- Далее проверяем наличие в окне буквы а. Она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Этого слова нет в окне, тогда кодируем aba кодовой комбинацией (1,3,3), где 1– признак того, что слово есть в «окне», 3– номер позиции в окне, с которой начинается это слово, 3– длина этого слова.
- Далее окно сдвигаем на 3 символа вправо и ищем в окне букву с. Ее нет в окне, поэтому кодируем комбинацией (0, «с»), где 0– признак того, что буквы нет в окне, «с»– двоичное представление буквы. Окно сдвигаем на 1 символ вправо.
- Ищем в окне букву а, она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Это слово есть в окне, тогда кодируем abaс кодовой комбинацией (1,4,4), где 1 – признак того, что слово есть в окне, 4 –номер позиции в окне, с которой начинается это слово, 4 – длина этого слова.
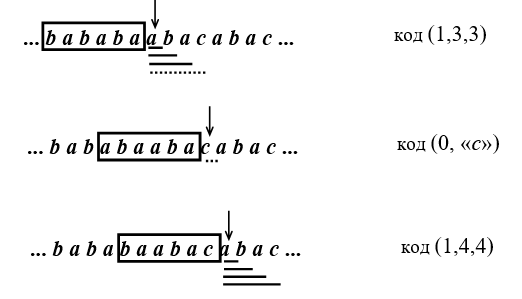
Рисунок 9 Кодирование последовательности bababaabacabac
В этих словарных методах для хранения слов используется адаптивный словарь, заполняющийся в процессе кодирования. Перед началом кодирования в словарь включаются все символы алфавита источника. При кодировании сообщения Х=х1х2х3х4… сначала читаются два символа х1х2, поскольку это слово отсутствует в словаре, то передается код символа х1 (обычно это номер строки, содержащей найденный символ или слово). В свободную строку таблицы записывается слово х1х2, далее читается символ х3 и осуществляется поиск в словаре слова х2х3. Если это слово есть в словаре, то проверяется наличие слова х2х3х4 и так далее. Таким образом, слово из наибольшего количества входных символов, найденное в словаре, кодируется как номер строки, его содержащей.
Пусть алфавит источника А={а, b, с}, размер словаря V=8. Необходимо закодировать исходное сообщение abababaabacabac.
- Запишем символы алфавита А в словарь, каждому символу припишем кодовое слово длины L = log2V = log28 =3.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
– |
|
|
4 |
– |
|
|
5 |
– |
|
|
6 |
– |
|
|
7 |
– |
- Читаем первые две буквы ab, ищем слово ab в словаре. Этого слова нет, поэтому поместим слово ab в свободную 3-ю строку словаря, а букву а закодируем кодом 000.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
– |
|
|
5 |
– |
|
|
6 |
– |
|
|
7 |
– |
- Далее читаем букву a и ищем в словаре слово ba. Этого слова нет, поэтому запишем в 4-ю строку словаря слово ba, букву b закодируем кодом 001.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
ba |
100 |
|
5 |
– |
|
|
6 |
– |
|
|
7 |
– |
- Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba, его нет в словаре. Запишем слово aba в 5-ю строку словаря, и закодируем ab кодом 011.
- Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву а, получим слово abaа, его нет в словаре. Запишем слово abaа в 6-ю строку словаря, и закодируем abа кодом 101.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
ba |
100 |
|
5 |
aba |
011 |
|
6 |
abaа |
101 |
|
7 |
– |
- Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву с, получим слово abaс, его нет в словаре. Запишем слово abaс в 7-ю строку словаря, и закодируем abа кодом 101. Если словарь заполняется до окончания кодирования, то можно записывать новые слова в словарь, начиная со строки с наибольшим номером, удаляя ранее записанные там слова.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
ba |
100 |
|
5 |
aba |
101 |
|
6 |
abaа |
110 |
|
7 |
abaс |
111 |
- Читаем букву а, ищем в словаре слово са. Этого слова нет в словаре, поэтому запишем слово са в 7-ю строку словаря, удалив слово abас, и закодируем букву с кодом 010.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
ba |
100 |
|
5 |
aba |
101 |
|
6 |
abaа |
110 |
|
7 |
|
111 |
- Читаем букву b, ищем в словаре слово ab. Это слово есть в словаре в строке 3. Читаем следующую букву а, получим слово aba. Это слово есть в словаре в строке 5. Читаем букву с, получим слово abaс, его нет в словаре. Запишем слово abaс в 6-ю строку словаря, и закодируем abа кодом 101.
|
Номер строки |
Слово |
Код |
|
0 |
a |
000 |
|
1 |
b |
001 |
|
2 |
c |
010 |
|
3 |
ab |
011 |
|
4 |
ba |
100 |
|
5 |
aba |
101 |
|
6 |
|
110 |
|
7 |
са |
111 |
- Закодируем букву с кодом 010. Конец входной последовательности.
Таким образом, входное сообщение будет закодировано так
Вход кодера: a b ab aba aba c aba c
Выход кодера: 000 001 011 101 101 010 101 010
Рассмотрим теперь на примере ранее закодированного сообщения abababaabacabac (алфавит источника А={а, b, с}, размер словаря V=8) процесс декодирования. Закодированная последовательность имела такой вид
000001011101101010101010
- Запишем символы алфавита А в словарь, каждому символу припишем кодовое слово длины L = log2V = log28 = 3. (Процесс заполнения словаря будет таким же, как и при кодировании.)
- Читаем первые три бита кодовой последовательности (код 000), по коду найдем в словаре букву а.
- Читаем следующий код 001, по коду найдем в словаре букву b. Получим новое слово ab, которого нет в словаре, поместим слово ab в свободную 3-ю строку словаря. На выход декодера передаем букву а, букву b запоминаем.
- Читаем код 011, по коду находим в словаре слово ab. Добавляем первую букву а к предыдущему декодированному слову b, получим слово ba, его нет в словаре. Поместим слово ba в свободную 4-ю строку словаря. На выход декодера передаем букву b, слово ab запоминаем.
- Читаем код 101, такого кода нет в словаре. Тогда добавляем к слову ab
первую букву этой же последовательности – а, получим слово aba, его нет в словаре. Поместим слово aba в свободную 5-ю строку словаря. На выход декодера передаем слово ab, слово aba запоминаем.
- Читаем код 101, по коду находим в словаре слово aba, добавляем первую букву a к предыдущему декодированному слову aba, получим abaa. Добавим слово abaa в словарь в свободную 6-ю строку. На выход декодера передаем слово aba , и слово aba запоминаем.
- Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему декодированному слову aba, получим abac. Добавим слово abaс в словарь в свободную 7-ю строку. На выход декодера передаем слово aba , букву с запоминаем.
- Читаем код 101, по коду находим в словаре слово aba, добавляем первую букву а к предыдущей декодированной букве с, получим слово са.
Так как словарь заполнился до окончания декодирования, то будем записывать новые слова в словарь, начиная со строки с наибольшим номером, удаляя ранее записанные там слова. Добавим слово са в 7-ю строку словаря вместо слова abac. На выход декодера передаем букву с, слово aba запоминаем.
- Читаем код 010, по коду находим в словаре букву с, добавляем букву с к предыдущему декодированному слову aba, получим abac. Добавим слово abac в 6-ю строку словаря вместо слова abaа. На выход декодера передаем слово aba, букву с запоминаем.
- На выход декодера передаем букву с.
В результате декодирования получим исходное сообщение
Вход декодера: 000 001 011 101 101 010 101 010
Выход декодера: a b ab aba aba c aba c
ЗАКЛЮЧЕНИЕ
Любая информация, с которой работает современная вычислительная техника, преобразуется в числа в двоичной системе счисления. Дело в том, что физические устройства (регистры, ячейки памяти) могут находиться в двух состояниях, которым соотносят 0 или 1. Используя ряд подобных физических устройств, можно хранить в памяти компьютера почти любое число в двоичной системе счисления. Сколько физических ячеек, используемых для записи числа, столько и разрядное число можно записать. Если ячеек 8, то и число может состоять из 8 цифр. Кодирование в компьютере целых чисел, дробных и отрицательных, а также символов (букв и др.) имеет свои особенности для каждого вида. Например, для хранения целых чисел выделяется меньше памяти (меньше ячеек), чем для хранения дробных независимо от их значения. Однако, всегда следует помнить, что любая информация (числовая, текстовая, графическая, звуковая и др.) в памяти компьютера представляется в виде чисел в двоичной системе счисления (почти всегда). В общем смысле кодирование информации можно определить как перевод информации, представленной сообщением в первичном алфавите, в последовательность кодов. Надо понимать, что любые данные — это так или иначе закодированная информация. Информация может быть представлена в разных формах: в виде чисел, текста, рисунка и др. Перевод из одной формы в другую — это кодирование.
-
используемая ЛИТЕРАТУРА
- Ахо А., Хопкрофт Дж., Ульман Дж. Структуры данных и алгоритмы. - М.: Издательский дом "Вильямс", 2000. - 384 с.
- Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. – М.: «Диалог-МИФИ», 2002.
- Кричевский Р.Е. Сжатие и поиск информации. - М.: Радио и связь, 1989. - 168 с.
- Марченко А.И., Марченко Л.А. Программирование в среде Turbo PASCAL 7.0. Базовый курс. Киев: «ВЕК+», 2003.
- Панин В.В., Основы теории информации. Учебное пособие для ВУЗов. Бином, 2009.
- Нечта И. В. Построение меню при помощи алфавитного кода // Вестник
СИБГУТИ. 2015. №4. С. 40-46.
- Ленкин А.В., Лучанинов Д.В. Реализация алгоритма матричного
кодирования с помощью языка С++ // Постулат. 2016. №12. С. 13.
- Курапова Е.В. Мачикина Е.П. Основные методы кодирования данных.

- Проблема личности в социальной психологии ( Социализация личности)
- Процедура разработки и реализация логистической стратегии в компании
- Основные функции в системе менеджмента (Прогнозирование и планирование)
- Особенности управления организациями в современных условиях и пути его совершенствования (Менеджмент и его роль в современном мире)
- Повышение эффективности строительного процесса (Анализ состояния отрасли строительства России)
- Сотрудничество России с мировыми финансово-кредитными институтами (Перспективы дальнейшего сотрудничества России)
- Основные направления реформы государственной службы в России (Система государственной службы )
- Государственная служба в Российской Федерации: опыт, современное состояние и направления совершенствования (История и опыт государственной службы в Российской Федерации )
- Социальное страхование и его функции (Проблемы и перспективы развития)
- Тенденции развития международной валютной системы ( Понятие и сущность международной валютной системы)
- Особенности семейного воспитания(Семья – основа семейного воспитания)
- Методы кодирования данных (Кодирование целых И действительных чисел)