
Алгоритмы сортировки данных
Содержание:

ВВЕДЕНИЕ
Сегодня новые информационные технологии являются неотъемлемой частью не только специализированных, но и повседневных сфер жизни. Практически любая область человеческой деятельности, будь то бизнес, менеджмент, торговля, образование и так далее, нуждается в технологиях, способных накапливать и обрабатывать информацию.
При обработке большого количества информации очень часто встает задача организации и структуризации данных. Для того, чтобы упростить и автоматизировать эти процессы, были разработаны определенные алгоритмы сортировки. Понимание принципов работы таких алгоритмов крайне необходимо при работе с данными любого типа, что обуславливает актуальность данного исследования.
Эта курсовая работа состоит из двух глав: в первой будут даны основные определения понятий “сортировки” и “алгоритма”, дополненные краткими характеристиками, а также будет прослежена эволюция различных алгоритмов сортировки данных; во второй главе будут приведены конкретные примеры наиболее часто встречающихся алгоритмов сортировки данных и будут отмечены достоинства и недостатки различных методов сортировки с практической точки зрения.
Целью данной курсовой работы является исследование и анализ наиболее часто использующихся алгоритмов сортировки. Для достижения данной цели необходимо выполнить следующие задачи:
- рассмотреть теоретическую базу, описывающую принципы работы основных алгоритмов сортировки данных;
- проследить эволюцию развития алгоритмов сортировки данных;
- определить критерии сравнения эффективности использования алгоритмов сортировки данных;
- сравнить алгоритмы сортировки друг с другом, определить достоинства и недостатки каждого, опираясь на сформированные нами критерии.
Глава 1. Алгоритмы сортировки данных с теоретической точки зрения
1.1. Введение основных теоретических понятий “алгоритм”, “сортировка” и их краткие характеристики
Перед тем, как приступить к исследованию вопросов, касающихся алгоритмов сортировки, необходимо ввести понятие “алгоритма” и дать ему краткую характеристику.
Алгоритм – это точно определенная последовательность действий, которую необходимо выполнить над исходными данными для достижения решения задачи.
По словам американского ученого в области информатики Дональда Кнута, ученые долгое время не могли найти истинное происхождение слова “алгоритм”. В своей книге “Искусство программирования”, он пишет, что “Языковеды того времени пытались объяснить его [слово “алгоритм”], комбинируя различные слова, например algiros (больной) и arithmos (число)...”[1] Однако позже выяснилась подлинная этимология интересующего нас слова. Слово «алгоритм» происходит от имени узбекского математика девятого века Аль-Харезми, написавшего книгу “Правила восстановления и преобразования”. Он также сформулировал правило четырёх арифметических действий над многозначными числами. В дальнейшем сфера употребления этого слова расширилась - оно стало применяться не только в математике. Теперь оно фактически описывает любую последовательность действий, приводящих к конечному результату, а каждое такое действие стало называться шагом алгоритма.
Алгоритм обладает рядом свойств, связанных с необходимостью выполнения определенных требований к процессу вычисления.
К этим свойствам относятся:
1) определенность;
2) массовость;
3) результативность;
4) дискретность.
Определенность алгоритма означает, что каждый шаг алгоритма должен быть точен, общепонятен, и исключать возможность различного толкования, другими словами алгоритм должен быть таким, чтобы его мог повторить любой пользователь.
Массовость заключается в том, что алгоритм предназначен для решения целого класса задач, которые отличаются только своими входными условиями.
Результативность означает, что пошаговый процесс решения задачи в соответствии с алгоритмом должен заканчиваться через определенное конечное число шагов.
Дискретность (прерывность, раздельность) означает, что алгоритм должен представлять процесс решения задачи как последовательное выполнение простых (или ранее определенных) шагов. Каждое действие, предусмотренное алгоритмом, исполняется только после того, как закончилось исполнение предыдущего.
Стоит отметить, что алгоритм может задаваться различными способами. Далее приведем распространенные формы представления алгоритма:
- Словесная форма;
- Словесно-аналитическая форма;
- В виде блок-схемы (графическое изображение алгоритма);
- В виде программы на алгоритмическом языке программирования.
Также существуют различные виды алгоритмических структур:
- Линейный алгоритм, в которой все команды выполняются последовательно одна за другой.
- Разветвляющийся, в которой в зависимости от условия выполнения либо одна серия команд, либо другая.
- Циклический, в которой многократно повторяется некоторый участок алгоритма.
Ознакомившись с понятием алгоритма, а также охарактеризовав основные свойства алгоритмов, можно перейти к более частному интересующему нас явлению - алгоритмам сортировки.
Экономико-математический словарь дает следующее определение: “Сортировка данных [data sorting, ordering] — один из этапов обработки данных, упорядочение элементарных данных в последовательности, определяемой значениями некоторых признаков, называемых ключами сортировки. Например, расположение записей сортируемого массива данных по возрастанию или уменьшению значений величин, содержащихся в массиве. Сортировка массивов данных существенно ускоряет их дальнейшую обработку.”
Исходя из уже введенных ранее определений, мы можем прийти к заключению, что под алгоритмом сортировки подразумевается определенный порядок действий, ведущий к упорядочению последовательности элементов данных.
1.2. Эволюция способов и алгоритмов сортировки данных в массивах
Сортировка данных в массиве является одной из наиболее распространенных задач в информатике. Но повышение эффективности алгоритмов сортировки очень важно не только по этой причине. Неослабевающий интерес к их оптимизации объясняется тем, что объемы информационных массивов непрерывно и стремительно растут, соответственно возрастают и требования к скорости сортировки.
В статье “Эволюция способов и алгоритмов сортировки данных в массивах”, написанной Александром Дупденко, выделены основные этапы эволюции методов сортировок. Автор пишет: “Нами была поставлена цель проследить эволюцию алгоритмов сортировки данных с первых методов, используемых при машинной обработке информации, до настоящего времени, выделив основные этапы и направления их развития”.[2]
Он выделяет всего пять этапов эволюции методов сортировки:
Впервые проблема сортировки была затронута в США в середине XIX века. “В 1840 году там был создан центральный офис переписи населения, куда стекались первичные данные из всех штатов. В ходе переписи было опрошено 17 069 453 человек, каждая анкета состояла из 13 вопросов. Объем полученных данных был столь велик, что их обработка традиционным ручным способом потребовала непомерных затрат труда и времени. Ситуация усугублялось необходимостью проведения постоянных сверок и пересчетов из-за допускаемых при ручной сортировке данных ошибок. С каждой новой переписью, которая проводилась раз в десять лет, объем обрабатываемой информации, а вместе с ним стоимость и длительность обработки данных возрастали. Так, ручная обработка данных переписи населения 1880 года (50 189 209 человек) потребовала привлечения сотен служащих и длилась семь с половиной лет.” [3]
Чтобы решить проблему сортировки данных, бюро переписи был проведен конкурс на лучшее электромеханическое сортировочное оборудование, которое сделало бы сортировку данных более эффективной — более быстрой, точной и дешевой. Тогда победу одержал американский инженер Герман Холлерит (Herman Hollerith), разработавший оборудование для работы с перфокартами — электрическую табулирующую систему, которая впоследствии стала известна под названием Hollerith Electric Tabulating System.
Плюсы машины Холлерита были описаны в журнале «Вестник Опытной Физики и Элементарной Математики» в 1895 году: «Преимущества машины Голлерита заключаются:
а) в значительном ускорении и удешевлении работы. При ручном способе можно разложить и подсчитать за час не более 400 карточек. Если принять, что в Российской Империи 120 миллионов жителей, то для изготовления одной только сводной таблицы потребуется не менее … 300 000 часов… Машина сокращает работу почти в 5 раз.
б) в большей точности результатов…
в) в большей легкости получения сложных сводных таблиц… После немногих пропусках через машину всех счетных карточек получаются столь полные и разнообразные таблицы, составление которых было почти немыслимо при прежнем способе.»[4]
Оказалось, что способ табулирования при сортировке данных является крайне эффективным, да настолько, что на то, чтобы подготовить предварительные результаты переписи, ушло всего шесть недель. В свою очередь, полный статистический анализ данных занял два с половиной года.
Таким образом, машина Холлерита сократила время, требуемое на обработку данных в три раза, причем точность сводных таблиц значительно возросла. В конце XIX века на смену ручной сортировке данных в массивах пришла сортировка с помощью статистических табуляторов. При этом использовался алгоритм поразрядной сортировки.
Следующий этап можно выделить в начале 1940-ых годов, когда появились первые вычислительные машины. В 1946 году под авторством Джона Уильяма Мочли, вышла первая статья об алгоритмах сортировки данных. В той статье рассматривался целый ряд новых алгоритмов сортировки, в том числе метод бинарных вставок. До середины 1950-х годов наиболее распространенными были модификации сортировки слиянием и вставками сложности O (n log n) для п элементов. Еще одним следствием перехода к сортировке данных с помощью ЭВМ стало разделение сортировки на два типа — внешнюю и внутреннюю, то есть на использующую и не использующую данные, расположенные на периферийных устройствах.
Третий этап происходил в рамках середины 1950-ых годов до середины 1970-ых годов. Для него было характерно активное развитие алгоритмов сортировки — внешней и внутренней, устойчивой и неустойчивой — многие из которых широко используются и в настоящее время. Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок, обменной сортировке и сортировке посредством выбора.
В середине 1950-х годов с разработкой ЭВМ второго поколения началось активное развитие алгоритмов сортировки. Основными предпосылками для этого стали, во-первых, значительное упрощение и ускорение написания программ для компьютеров в результате разработки первых языков программирования высокого уровня (Фортран, Алгол, Кобол); во-вторых, значительное повышение доступности компьютеров в результате резкого уменьшения их габаритов и стоимости и, как следствие, достаточно широкое их распространение; в-третьих, увеличение производительности компьютеров до 30 тысяч операций в секунду. В 1959 году Дональд Левис Шелл (Donald Lewis Shell) предложил метод сортировки с убывающим шагом (shellsort), в 1960 году Чарльз Энтони Ричард Хоар (Charles Antony Richard Hoare) — метод быстрой сортировки (quicksort), в 1964 году Дж. У. Дж. Уильямс (J. V. J. Williams) — метод пирамидальной сортировки (heapsort). Многие из разработанных в этот период алгоритмов (например, быстрая сортировка Хоара) широко используются до настоящего времени. Итоги этого этапа активного развития алгоритмов сортировки подвел в 1973 году Дональд Эрвин Кнут (Donald Ervin Knuth) в третьем томе своей фундаментальной монографии «Искусство программирования» («The Art of Computer Programming»). К началу 1970-х годов использовались следующие виды алгоритмов внутренней сортировки: сортировка посредством подсчета; сортировка путем вставок; обменная сортировка; сортировка посредством выбора; сортировка методом слияния; сортировка методом распределения. Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок (метод простых вставок, бинарные и двухпутевые вставки, метод Шелла, вставка в список, сортировка с вычислением адреса и др.), обменной сортировке (метод пузырька и его модификации, параллельная сортировка Бэтчера, быстрая сортировка, обменная поразрядная сортировка, асимптотические методы) и сортировке посредством выбора (выбор из дерева, пирамидальная сортировка, метод исключения наибольшего из включенных, метод связанного представления приоритетных очередей). Не менее активно разрабатывались и методы внешней сортировки, в том числе методы многопутевого слияния и выбора с замещением, многофазного слияния, каскадного слияния, осциллирующей сортировки, внешней поразрядной сортировки и т. д.[5]
Четвертый этап продолжался с середины 1970-х до середины 1990-х годов. Появление вычислительных центров, объединяющих мощности отдельных вычислительных машин и позволяющих работать с разделением времени потребовало разработки новых алгоритмов сортировки и модификации существующих. Началось исследование задач сортировки в классе параллельных алгоритмов, были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. Одновременно происходил поиск оптимальных входных последовательностей для разных методов сортировки, что позволяло значительно сократить ее время.
Пятый этап начался с середины 1990-х годов и продолжается по настоящее время. Особую актуальность получило исследование задач сортировки на частично упорядоченных множествах: задач распознавания частично упорядоченного множества М; задач сортировки частично упорядоченного множества М с использованием результатов попарных сравнений элементов, а также задач определения порядка на множестве М без априорной информации. Актуальность этих задач объясняется появлением и широким распространением компьютеров на сверхсложных микропроцессорах с параллельно-векторной структурой, а также высокоэффективных сетевых компьютерных систем.
Таким образом, после рассмотрения всех этапов эволюции алгоритмов сортировки данных, можно сделать вывод, что вместе с развитием технологий возрастали и потребности общества в совершенствовании этих технологий. В частности, новые алгоритмы сортировки данных позволяли ученым обрабатывать большие количества информации, но в то же время при возросшей возможности получать данные быстрее, появилась потребность обрабатывать все больше данных с большей скоростью и эффективностью.
Именно поэтому исследование различных алгоритмов сортировки данных так важно. Настоящие методы сортировки данных выполняют множество прикладных задач. Они достаточно изучены, но всегда возможны новые открытия, которые необходимы для продолжения процесса их совершенствования.
Глава 2. Алгоритмы сортировки: применение на практике и сравнение эффективности
2.1. Анализ основных алгоритмов сортировки данных
На сегодняшний день существует множество различных методов сортировки данных. В данной главе будут представлены и кратко описаны некоторые методы сортировки данных, которые часто используются для решения различных практических задач, а во втором параграфе текущей главы будут представлены исследования, в рамках которых сравнивались различные алгоритмы сортировки данных.
Итак, далее будут перечислены 10 основных алгоритмов сортировки данных.
Метод пузырька — простой алгоритм сортировки. Алгоритм состоит в повторяющихся проходах по сортируемому массиву. За каждый проход элементы последовательно сравниваются попарно и, если порядок в паре неверный, выполняется обмен элементов. Проходы по массиву повторяются до тех пор, пока на очередном проходе не окажется, что обмены больше не нужны, что означает — массив отсортирован. При проходе алгоритма, элемент, стоящий не на своём месте, «всплывает» до нужной позиции как пузырёк в воде, отсюда и название алгоритма. Сортировка методом пузырька имеет сложность O(n2). Для понимания и реализации это — простейший алгоритм сортировки, но эффективен он лишь для небольших массивов.
Код на языке Pascal:
const
m = 10;
var
arr: array[1..m] of integer;
i, j, k: integer;
begin
randomize;
write ('Исходный массив: ');
for i := 1 to m do begin
arr[i] := random(256);
write (arr[i]:4);
end;
writeln; writeln;
for i := 1 to m-1 do
for j := 1 to m-i do
if arr[j] > arr[j+1] then begin
k := arr[j];
arr[j] := arr[j+1];
arr[j+1] := k
end;
write ('Отсортированный массив: ');
for i := 1 to m do
write (arr[i]:4);
writeln;
readln
end.
Сортировка перемешиванием — разновидность пузырьковой сортировки. Отличается тем, что просмотры элементов выполняются один за другим в противоположных направлениях, при этом большие элементы стремятся к концу массива, а маленькие — к началу. Лучший случай для этой сортировки — отсортированный массив (О(n)), худший — отсортированный в обратном порядке (O(n²)).
Код на языке Pascal:
k:= 25; {Индекс последнего изменения}
s:= 1; {Первый элемент массива}
e:= 25; {Последний элемент массива}
while e > s do
begin
for i:= e downto s+1 do if Arr[i] < Arr[i-1] then
begin
tmp := Arr[i];
Arr[i] := Arr[i-1];
Arr[i-1] := tmp;
k := i;
end;
s:=k;
for i:= s to e-1 do if Arr[i]>Arr[i+1] then
begin
tmp := Arr[i];
Arr[i] := Arr[i+1];
Arr[i+1] := tmp;
k := i;
end;
e:=k;
end;
Сортировка вставкой — Это изящный и простой для понимания метод. Вот в чем его суть: создается новый массив, в который мы последовательно вставляем элементы из исходного массива так, чтобы новый массив был упорядоченным. Вставка происходит следующим образом: в конце нового массива выделяется свободная ячейка, далее анализируется элемент, стоящий перед пустой ячейкой (если, конечно, пустая ячейка не стоит на первом месте), и если этот элемент больше вставляемого, то подвигаем элемент в свободную ячейку (при этом на том месте, где он стоял, образуется пустая ячейка) и сравниваем следующий элемент. Так мы прейдем к ситуации, когда элемент перед пустой ячейкой меньше вставляемого, или пустая ячейка стоит в начале массива. Помещаем вставляемый элемент в пустую ячейку.
Таким образом, по очереди вставляем все элементы исходного массива. Очевидно, что если до вставки элемента массив был упорядочен, то после вставки перед вставленным элементом расположены все элементы, меньшие его, а после - большие. Так как порядок элементов в новом массиве не меняется, то сформированный массив будет упорядоченным после каждой вставки. А значит, после последней вставки мы получим упорядоченный исходный массив.
Код данного алгоритма, написанного на языке Pascal, представлен ниже:
Program InsertionSort;
Var A,B : array[1..1000] of integer;
N,i,j : integer;
Begin
{Определение размера массива A (N) и его заполнение}
…
{сортировка данных}
for i:=1 to N do
begin
j:=i;
while (j>1) and (B[j-1]>A[i]) do
begin
B[j]:=B[j-1];
j:=j-1;
end;
B[j]:=A[i];
end;
{Вывод массива B}
…
End.
Это очень простой алгоритм сортировки. Этот метод сортировки уступает в эффективности более сложным алгоритмам. Однако, у него есть ряд своих преимуществ:
- прост в реализации;
- эффективен на небольших наборах данных;
- эффективен на наборах данных, которые уже частично отсортированы;
- это устойчивый алгоритм сортировки (не меняет порядок элементов, которые уже отсортированы);
- может сортировать список по мере его получения.
Анализ производительности данного метода: сортировка вставками имеет сложность n2, количество сравнений вычисляется по формуле n*(n-1)/2. То есть, при n=100 количество перестановок равно 4950, а не 10000 если бы мы высчитывали по формуле n2.
Таким образом, сортировка вставками наиболее эффективна когда массив уже частично отсортирован и когда элементов массива не много. Если же элементов меньше 10 то данный алгоритм является лучшим.
Сортировка подсчетом - алгоритм сортировки массива, при котором подсчитывается число одинаковых элементов. Алгоритм выгодно применять, когда в массиве много элементов, но все они достаточно малы.
Идея сортировки указана в её названии — нужно подсчитывать число элементов, а затем выстраивать массив. Пусть, к примеру, имеется массив A из миллиона натуральных чисел, меньших 100. Тогда можно создать вспомогательный массив B из 99 (1..99) элементов, «пробежать» весь исходный массив и вычислять частоту встречаемости каждого элемента — то есть если A[i]=a, то B[a] следует увеличить на единицу. Затем «пробежать» счетчиком i массив B, записывая в массив A число i B[i] раз.
Сортировка слиянием — алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно, например — потоки) в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй».
Цифровая сортировка - обладает линейной вычислительной сложностью (О(n)), что является лучшей возможной производительностью для алгоритма сортировки, так как в любом таком алгоритме каждый сортируемый элемент необходимо просмотреть хотя бы однажды. Однако, применение алгоритма цифровой сортировки целесообразно лишь тогда, когда сортируемые предметы имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым списком. Эффективность алгоритма падает всякий раз, когда несколько различных элементов попадает в одну ячейку. Необходимость сортировки внутри ячеек лишает алгоритм смысла, так как каждый элемент придётся просматривать более одного раза. Так что, для простоты и с целью отличить «классическую» цифровую сортировку от её многочисленных вариантов, укажем, что подсчёт должен быть обратимым: если два элемента попадают в одну ячейку, то они должны иметь одинаковое значение. Несколько элементов с одним значением в одной ячейке не портят картину — их можно просто вставить в отсортированный список рядом, один за другим (это позволяет применять цифровую сортировку в качестве устойчивой).
Алгоритм цифровой сортировки действует следующим образом:
- Создаём массив изначально пустых «ячеек», по одной для каждой величины из диапазона ключей.
- Просматриваем изначальный массив, помещая каждый его элемент в свою ячейку.
- Проходим по массиву ячеек в нужном порядке и переносим элементы из непустых ячеек обратно в первоначальный массив.
Эффективность этого алгоритма сильно зависит от плотности элементов в массиве ячеек. Если элементов этого массива намного больше, чем сортируемых предметов, то шаги 1 и 3 будут относительно медленными.
Поразрядная сортировка — быстрая устойчивая сортировка за линейное время, использовалась в устройствах для сортировки перфокарт. Пригодна для сортировки любых элементов, состоящих из цепочек над фиксированным алфавитом, на котором задано отношение сравнения. Для сортировки следует применять любой устойчивый алгоритм, используя в качестве ключа сначала младшую букву, затем повторять этот процесс для старших букв.
Сортировка методом выбора — алгоритм сортировки, относящийся к неустойчивым алгоритмам сортировки. На массиве из n элементов имеет время выполнения в худшем, среднем и лучшем случае Θ(n2), предполагая, что сравнения делаются за постоянное время.
Шаги алгоритма:
- находим минимальное значение в текущем списке
- производим обмен этого значения со значением на первой позиции
- теперь сортируем хвост списка, исключив из рассмотрения уже отсортированный первый элемент.
Пирамидальная сортировка сильно улучшает базовый алгоритм, используя структуру данных ключа для ускорения нахождения и удаления минимального элемента.
Существует также двунаправленный вариант сортировки методом вставок, в котором на каждом проходе отыскивается и устанавливается на своё место и минимальное, и максимальное значения.
Сортировка методом Шелла - Идея алгоритма состоит в обмене элементов, расположенных не только рядом, как в сортировке методом вставок, но и далеко друг от друга, что значительно сокращает общее число операций перемещения элементов.
Для примера возьмем файл из 16 элементов. Сначала просматриваются пары с шагом 8. Это пары элементов 1-9, 2-10, 3-11, 4-12, 5-13, 6-14, 7-15, 8-16. Если значения элементов в паре не упорядочены по возрастанию, то элементы меняются местами. Назовем этот этап 8-сортировкой. Следующий этап — 4-сортировка, на котором элементы в файле делятся на четверки: 1-5-9-13, 2-6-10-14, 3-7-11-15, 4-8-12-16. Выполняется сортировка в каждой четверке.
Следующий этап — 2-сортировка, когда элементы в файле делятся на 2 группы по 8: 1-3-5-7-9-11-13-15 и 2-4-6-8-10-12-14-16. Выполняется сортировка в каждой восьмерке. Наконец весь файл упорядочивается методом вставок. Поскольку дальние элементы уже переместились на свое место или находятся вблизи от него, этот этап будет значительно менее трудоемким, чем при сортировке вставками без предварительных «дальних» обменов.
Пирамидальная сортировка - алгоритм сортировки, работающий в худшем, в среднем и в лучшем случае (т.е. гарантированно) за О(n log n) операций при сортировке n элементов. Сортировка пирамидой использует сортирующее дерево. Сортирующее дерево – это такое двоичное дерево, у которого выполнены условия:
- Каждый лист имеет глубину либо d либо d-1;
- Значение в любой вершине больше, чем значения ее потомков.
Удобная структура данных для сортирующего дерева – такой массив Array, что Array[1] – элемент в корне, а потомки элемента Array[i] - Array[2i] и Array[2i+1].
Быстрая сортировка — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром. Даёт в среднем O(n log n) сравнений при сортировке n элементов. В худшем случае, однако, получается O(n2) сравнений. Обычно на практике быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(n log n), по причине того, что внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре, и на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Интересно, что Хоар разработал этот метод применительно к машинному переводу: дело в том, что в то время словарь хранился на магнитной ленте, и если отсортировать все слова в тексте, их переводы можно получить за один прогон ленты.
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
- Выбираем в массиве некоторый элемент, который будем называть опорным элементом.
- Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него.
- Рекурсивно сортируем подсписки, лежащие слева и справа от опорного элемента.
Базой рекурсии являются списки, состоящие из одного или двух элементов, которые уже отсортированы. Алгоритм всегда завершается, поскольку за каждую итерацию он ставит по крайней мере один элемент на его окончательное место.
2.2. Сравнение эффективности применения различных алгоритмов сортировки данных в массивах
Сегодня объемы массивов данных достигают таких размеров, о каких еще десятилетие назад никто не мог и подумать. Чем большими становятся объемы перерабатываемых данных, тем актуальнее становится задача оптимизации используемых алгоритмов, в том числе и сортировки.
Существует огромное количество различных методов сортировки данных. Универсального, наилучшего алгоритма сортировки на данный момент не существует. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом. Для этого необходимо знать параметры, по которым будет производиться оценка алгоритмов[6].
Время сортировки – основной параметр, характеризующий быстродействие алгоритма.
Память – один из параметров, который характеризуется тем, что ряд алгоритмов сортировки требуют выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив данных и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость – это параметр, который отвечает за то, что сортировка не меняет взаимного расположения равных элементов.
Естественность поведения – параметр, которой указывает на эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Для того, чтобы определить, какой метод сортировки данных является наиболее оптимальным для той или иной задачи, проводилось множество различных исследований.
В своей статье “Сравнительный анализ алгоритмов сортировки данных в массивах” А. Дупленко проводит колоссальную работу, сравнивая различные методы сортировки. [7]
Исследователем была выбрана следующая классификация:
1. Алгоритмы устойчивой сортировки. При использовании алгоритмов устойчивой (стабильной) сортировки при наличии в наборе данных нескольких равных элементов в отсортированном наборе они сохраняются в том же порядке, в котором были в исходном наборе.
Таким образом, устойчивая сортировка не меняет относительный порядок сортируемых элементов, имеющих одинаковые ключи. К числу алгоритмов устойчивой сортировки относятся сортировка пузырьком (Bubble sort), сортировка перемешиванием (шейкерная, Cocktail sort, Bidirectional bubble sort), гномья сортировка (Gnome sort), сортировка вставками (Insertion sort), сортировка слиянием (Merge sort), сортировка с помощью двоичного дерева (Tree sort), алгоритм сортировки Тима Петерса (Timsort), сортировка подсчётом (Counting sort), блочная сортировка (корзинная сортировка, Bucket sort) и ряд других. К числу общих преимуществ алгоритмов устойчивой сортировки относится то, что сохранение взаимного расположения равных элементов важно при сортировке по одному полю данных, состоящих из нескольких полей. Следует отметить, однако, что этого можно добиться и путем удлинения исходных ключей за счёт дополнительной информации об их первоначальном порядке. Общим недостатком алгоритмов устойчивой сортировки является то, что они не гарантируют, что для обеспечения устойчивости практически всегда необходимы дополнительная память и время (таблица 1).
2. Алгоритмы неустойчивой сортировки. При использовании алгоритмов неустойчивой сортировки могут меняться местами данные с одинаковыми значениями. Это является недостатком в том случае, когда при сортировке по одному полю данных, состоящих из нескольких полей, важно сохранение взаимного расположения равных элементов важно при сортировке по одному полю данных. В то же время большинство алгоритмов неустойчивой сортировки требуют меньшей памяти и времени, чем алгоритмы устойчивой сортировки. Наиболее известными алгоритмами неустойчивой сортировки являются сортировка Шелла (Shell sort), сортировка расчёской (Comb sort), пирамидальная сортировка (сортировка кучи, Heapsort), плавная сортировка (Smoothsort), быстрая сортировка (Quicksort), интроспективная сортировка (Introsort), терпеливая сортировка (Patience sorting), сортировка по частям (блуждающая сортировка, Stooge sort) и поразрядная сортировка (цифровая сортировка, Radix sort).
3. Непрактичные алгоритмы сортировки. Наиболее известными непрактичными алгоритмами сортировки являются алгоритмы, представленные в таблице 2.
Таким образом, недостатки непрактичных сортировок очевидны и видны уже из их названия. Их достоинства заключаются в том, что они могут быть использованы для определенных целей, чаще образовательных.
4. Алгоритмы, не основанные на сравнениях. Алгоритмы, не основанные на сравнениях, как следует из самого их названия, совсем не используют сравнений сортируемых элементов. Наиболее известными из данных алгоритмов являются блочная сортировка (корзинная сортировка, Bucket sort), лексикографическая сортировка (поразрядная сортировка, Radix sort) и сортировка подсчётом (Counting sort). При блочной сортировке требуются знания о природе сортируемых данных, выходящих за рамки функций «сравнить» и «поменять местами», достаточных для сортировки с использованием других элементов. Лексикографическая сортировка пригодна для сортировки любых элементов, состоящих из цепочек над фиксированным алфавитом, на котором задано отношение сравнения. При сортировке подсчетом используется диапазон чисел сортируемого массива для подсчёта совпадающих элементов. Достоинством алгоритмов, не основанных на сравнениях, является их быстрота при условии использования подходящего типа входных данных. Если массив входных данных не соответствует предъявляемым требованиям, эффективность данных методов значительно снижается.
5. Алгоритмы топологической сортировки. Алгоритмы топологической сортировки включают алгоритмы, которые нельзя отнести ни к одной другой группе. К ним относятся алгоритм Демукрона, алгоритм сортировки для представления графа в виде нескольких уровней, а также алгоритм топологической сортировки с помощью обхода в глубину. Все они основаны на упорядочивании вершин бесконтурного ориентированного графа согласно частичному порядку, заданному ребрами орграфа на множестве его вершин. Достоинством топологической сортировки является то, что при ее помощи строится корректная последовательность выполнения действий, всякое из которых может зависеть от другого. Недостаток — сравнительно узкая сфера использования.
Для сравнения алгоритмов сортировки удобно использовать матричный метод, который предполагает сравнение по двум параметрам. Так, в зависимости от устойчивости и скорости алгоритмы сортировки можно разделить на шесть групп.
Среди рассмотренных нами алгоритмов сортировки большинство входит в три группы, которые условно можно назвать «Быстрая устойчивая сортировка» (сортировка слиянием и алгоритм сортировки Тима Петерса), «Быстрая неустойчивая сортировка» (сортировка Шелла, быстрая сортировка, пирамидальная сортировка, интроспективная сортировка, терпеливая сортировка, плавная сортировка), а также «Медленная устойчивая сортировка» (сортировка пузырьковым методом, сортировка вставками, сортировка выбором, сортировка перемешиванием, гномья сортировка).
Таким образом, существующие алгоритмы сортировки массивов значительно различаются по уровню сложности, скорости, устойчивости, требованиям к памяти и другим параметрам. Однако практически каждый алгоритм оказывается наиболее удобным в какой-либо конкретной ситуации. Востребованными являются даже очень медленные алгоритмы, которые из-за своей простоты находят применение в образовательных целях. Если сравнивать алгоритмы сортировки по скорости и устойчивости, то для большинства устойчивых алгоритмов характерно среднее число операций n2, а большинство алгоритмов неустойчивой сортировки являются более быстрыми.
ЗАКЛЮЧЕНИЕ
В рамках данной курсовой работы было проведено исследование и анализ наиболее часто использующихся алгоритмов сортировки. Для достижения данной цели были выполнены следующие задачи:
- была рассмотрена теоретическая база, описывающая принципы работы основных алгоритмов сортировки данных;
- была показана эволюцию развития алгоритмов сортировки данных;
- были определены критерии сравнения эффективности использования алгоритмов сортировки данных;
- было проведено сравнение алгоритмов сортировки друг с другом, в ходе которого были выявлены достоинства и недостатки каждого.
В данной курсовой работе мы пришли к выводу, что несмотря на то, что в результате длительной истории развития, на сегодняшний день было сформировано множество различных алгоритмов сортировки данных, различающихся по уровню сложности, скорости, устойчивости, требованиям к памяти и другим параметрам. Однако практически каждый алгоритм может быть использован для выполнения той или иной задачи.
Если же выбрать главным критерием скорость и устойчивость, то можно утверждать, что для большинства устойчивых алгоритмов характерно среднее число операций n2, а большинство алгоритмов неустойчивой сортировки являются более быстрыми.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Дональд Кнут. Искусство программирования, том 1. Основные алгоритмы = The Art of Computer Programming, vol.1. Fundamental Algorithms. — 3-е изд. — М.: «Вильямс», 2006. — С. 720.
- Дональд Кнут. Искусство программирования, т.3. Сортировка и поиск. — М.: Издательский дом «Вильямс», 2010
- Дупленко А. Г. Эволюция способов и алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №9. — С. 17-19. — URL https://moluch.ru/archive/56/7702/
- Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №8. — С. 50-53. — URL https://moluch.ru/archive/55/7474/
- Коварцев А. Н., Попова-Коварцева Д. А. Структурная оптимизация управляющего графа на основе алгоритма топологической сортировки // Программная инженерия. — 2013. — № 5.
- Мартынов В. А., Миронов В. В. Параллельные алгоритмы сортировки данных с использованием технологии MPI // Вестник Сыктывкарского университета. Серия 1: Математика. Механика. Информатика. — 2012. — № 16. — С. 130–135.
- Овчинникова И. Г., Сахнова Т. Н. Алгоритмы сортировки при решении задач по программированию // Информатика и образование. — 2011. — № 2. — С. 53–56.
- Экономико-математический словарь: Словарь современной экономической науки. — М.: Дело. Л. И. Лопатников. 2003.
- Электрическая машина Голлерита для подсчета статистических данных // В. О. Ф.Э.М. — 1895. — № 225. — С. 193–201.
- United States Census // Sources of U. S. Census Data, from MIT Libraries, 2011. URL: http://libraries.mit.edu/guides/types/census/sources.html
- Интернет-ресурс studepedia.org. URL: http://studepedia.org/index.php?vol=1&post=60498
ПРИЛОЖЕНИЯ
Таблица 1
Сравнение преимуществ и недостатков основных видов алгоритмов сортировки
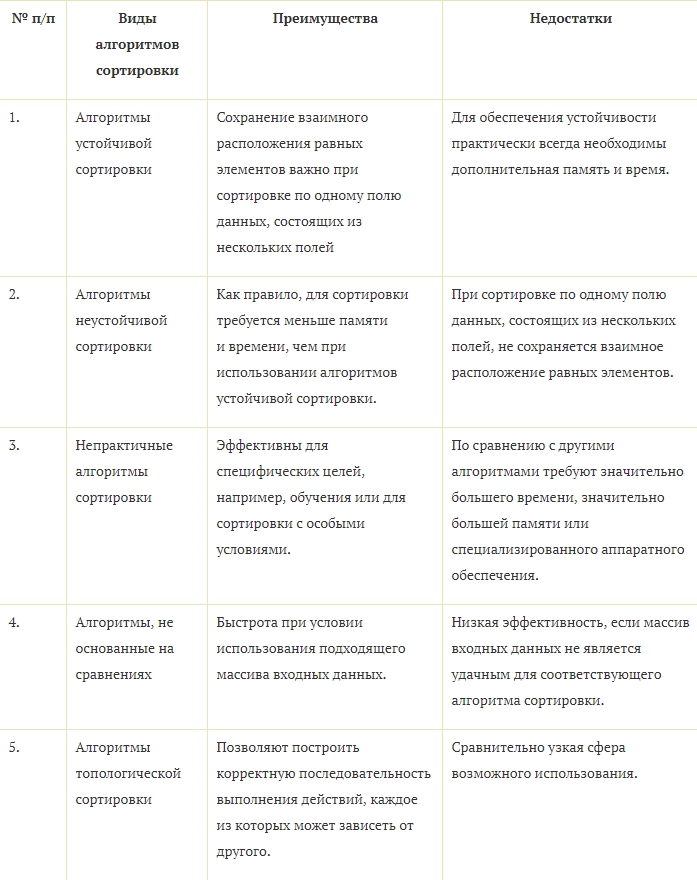
Таблица 2
Непрактичные алгоритмы сортировки

-
Дональд Кнут Искусство программирования, том 1. Основные алгоритмы = The Art of Computer Programming, vol.1. Fundamental Algorithms. — 3-е изд. — М.: «Вильямс», 2006. — С. 720. ↑
-
Дупленко А. Г. Эволюция способов и алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №9. — С. 17-19. — URL https://moluch.ru/archive/56/7702/ ↑
-
United States Census // Sources of U. S. Census Data, from MIT Libraries, 2011. URL: http://libraries.mit.edu/guides/types/census/sources.html ↑
-
. В. Электрическая машина Голлерита для подсчета статистических данных // В. О. Ф.Э.М. — 1895. — № 225. — С. 193–201. ↑
-
Кнут Д. Э. Искусство программирования, т.3. Сортировка и поиск. — М.: Издательский дом «Вильямс», 2010 ↑
-
Интернет-ресурс studepedia.org. URL: http://studepedia.org/index.php?vol=1&post=60498 ↑
-
Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах // Молодой ученый. — 2013. — №8. — С. 50-53. — URL https://moluch.ru/archive/55/7474/ ↑

- Управление поведением в конфликтных ситуациях (Конфликт: понятие, сущность, виды, функции)
- Организационная культура и ее роль в современных организациях
- Общая характеристика кадрового обеспечения муниципального управления
- Сущность ценовой дискриминации
- Анализ денежных потоков
- Современная семья в системе воспитания
- Состояние и развитие потребительской кооперации РФ, на ПРИМЕРЕ реально существующей организации
- Управление поведением в конфликтных ситуациях (Методы разрешения конфликтов )
- Управление рисками в проектной среде (Понятие и сущность риска в проектной среде)
- Бухгалтерский баланс организации: порядок составления и аналитические возможности (ООО «ЭЛИНА»)
- Принципы управленческого учета, отличие их от других видов учета.
- Эффективность менеджмента организации АО «ХЛЕБОПЕК»