
Генеральная и выборочная совокупности - определение и вычисление с примерами решения
Содержание:
Совокупность и выборка:
Основные понятия статистики и вероятности дают возможность более глубоко понять события, которые происходят в современном мире. В каждой из двух областей, как объект исследования выбирается совокупность, и выбранные из данной совокупности образцы, или коротко говоря, маленькая группа, называемая выборкой. Статистика, проводя исследование выбранных образцов формирует мнение о всей популяции.

Для проведения статистических исследований, как правило, образцы выбираются случайным образом. В этом случае, каждый образец в совокупности имеет равный шанс при выборке. Существуют различные техники случайной выборки.
- Простая случайная выборка
- Систематическая случайная выборка
- Кластерная случайная выборка
- Разноуровневая случайная выборка
Простая случайная выборка
Предположим, что в классе нужно выбрать группу из трёх человек. Для этого на карточках записываются имена всех учеников, затем эти карточки складываются в ящик, после чего, случайным образом, вытаскиваются три карточки. В этом случае каждый их трёх членов группы имеет одинаковый шанс выбора.
При простой случайной выборке каждый элемент 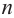
Систематическая выборка
Предположим, что руководство большого торгового центра хочет собрать информацию о том, сколько времени покупатели проводят в торговом центре. Было установлено, что центр в течении дня посещают в среднем 2000 человек. Из них случайным образом было выбрано 5% (т.е. 100 человек). Как правильно сделать выборку? Можно опросить людей в день выбора следующим образом: из каждых 20 покупателей опросить каждого 16-го., затем 36-го, 56-го и т.д. Выборка такого вида называется систематической.
Если при систематической выборке предполагается сделать выбор в
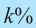 - то используется каждый
- то используется каждый 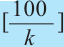 -ый элемент популяции.
-ый элемент популяции.
Кластерная выборка
Пусть имеется 1000 ящиков по 15 деталей в каждом, и необходимо дать информацию об качестве деталей. Для этого принято решение проверить качество 300 (2%) деталей. Но для того, чтобы вытащить все детали из ящиков, перемешать их и случайно выбрать 300 штук, потребуется много времени и расходов. Из 1000 ящиков можно случайным образом выбрать 20 и проверив все детали из этих ящиков сформировать мнение о всех деталях. Здесь каждый ящик можно считать кластером. Такая выборка называется кластерной выборкой. Необходимо проверить все элементы находящиеся внутри кластера.
При кластерной выборке совокупность состоит из кластеров. Кластер выбирается случайным образом и рассматриваются все элементы кластера.
Разноуровневая выборка
Предположим, что в школе планируется провести опрос среди старшеклассников о том, хотели бы они после уроков заняться чтением художественной литературы в школьной библиотеке. Не желательно проводить опрос среди случайно выбранных учащихся в школьном дворе, так как они могут быть учениками одного и того же класса и т.д. Опрос должен быть проведён случайным образом среди учащихся разных возрастных групп.Такого рода случайная выборка называется разноуровневая(по слоям, по группам). Если в школе в этих классах учится 1265 учеников, из них 385 учится в 8-ом классе, 350 человек - в 9-ом, 280 человек - в 10-ом, 250 человек в 11-ом классе, то для того, чтобы узнать мнение 10 % случайно выбранных учащихся, надо узнать мнение 10% учеников каждого класса, т.е. желательно случайно выбрать 39 из 8-го, 35 из 9-го, 28 из 10-го, 25 из 11-го класса.
При разноуровневой выборке сначала совокупность делится на уровни, а затем проводится случайная выборка на каждом уровне.
При некоторых исследованиях невозможно бывает сделать случайную выборку. Например, диетологам приходится назначать диету не случайно выбранным людям, а тем кто сам захотел этого добровольно.
Верная или неверная выборка
Научно исследовательские институты, занимающиеся опросами не имеют материально технической базы для того, чтобы узнать мнения всех людей по каждому вопросу. Поэтому они ограничиваются изучением этого мнения на небольшой группе людей. Для этого большую роль играет умение правильно определить эти группы. Надёжность представленного на диаграмме исследования также зависит от того, насколько правильно определена группа. Например, невозможно сформировать правильное мнение о том, сколько раз в неделю все горожане занимаются спортом, изучив мнение только тех людей, которые посещают спортивный центр или, прогноз о том, выберут ли кого- то в депутаты парламента не даст правильных результатов, сформировав его, по мнению людей из коллектива, где он работает или живущих с ним в одном районе.
Пример №1
Администрация школы планирует определить связь между отметками учащихся по предметам математика и естественным наукам. В оценивании и по предмету математика, и по естественным наукам из 800 учащихся школы принимали участие 350 учеников. Из них, случайным образом, 70 человек планируется вовлечь в специальное оценивание. По таблице определите сколько из учащихся каждого класса будут выбраны случайным образом для специального оценивания.
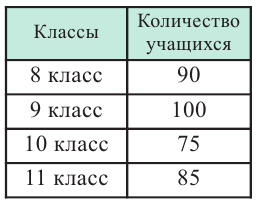
Решение: Если количество выбранных учащихся в общем равно 70 человек, то выборка из каждого класса должна быть пропорциональна. Количество восьмиклассников должно быть: 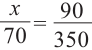 и т.д.
и т.д.
Представление информации
Статистическая информация по количественным и качественным характеристикам делится на два вида.
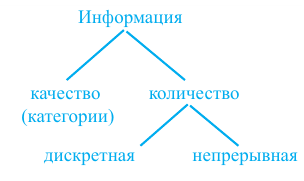
Информация количественного типа выражается в численном значении. Например, "сколько времени занимаются спортом" ,"чему равен рост" и т.д. Информация качественного вида подразделяется на категории и называется категориальной информацией. Например, "название партии", "цвет глаз", марка автомобиля" и т.д.
Количественная информация - числовая информация делится на два вида:
- дискретная, информация которая прерывается;
- непрерывная информация.
Дискретная числовая информация определяется путём подсчёта. Например, количество пассажиров в автобусе принимает значения 1,2,3 и т.д.
Непрерывная числовая информация принимает различные значения в определённом диапазоне, обычно формируется по результатам измерений. Например, рост, масса и т.д. новорожденных детей.
Для представления информации важно правильно выбрать соответствующую форму графика. Поэтому для представления категориальной и количественной информации выбирается соответствующий график.
Целесообразные формы представления категориальной информации
Пример:
Среди 200 учеников был проведён опрос о том, какой вид спорта они любят больше всего. Здесь информация типа вид спорта относится к категориальному виду. В школе имеются секции по следующим видам спорта. Для представления категориальной информации удобно пользоваться таблицей частот, барграфом, круговой диаграммой.
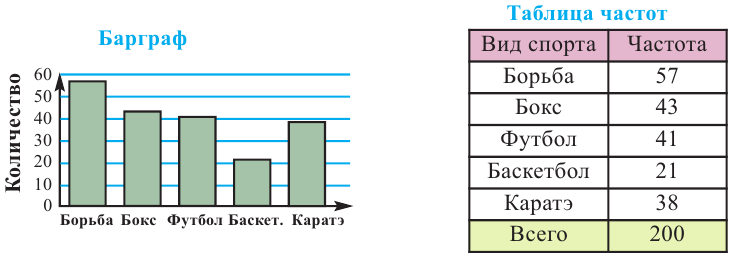
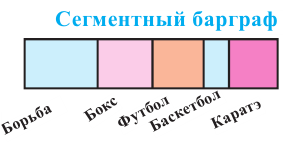
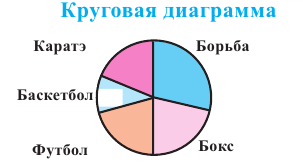
Определяет какую часть от общего (единичного блока) составляет каждая категория. Единичный блок делится на сегменты.
Целесообразные формы представления числовой информации
Дискретная числовая информация. Для представления ограниченного количества числовой дискретной информации используют такие формы как таблица частот, барграф, гистограмма и разветвляющееся дерево.
Пример №2
Среди 50 молодых семей провели опрос "Сколько детей в вашей семье?". Ответы представлены ниже. 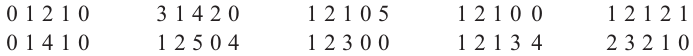
Следующие данные показывают количество детей в каждой семье. В таблице это количество показано в столбце или в виде палочек, или в виде числа. По таблице, в одном столбце которой, количество показано палочками, а в другой-числами, задан столбец относительной частоты.
Группировка дискретной числовой информации. Гистограмма
Пример:
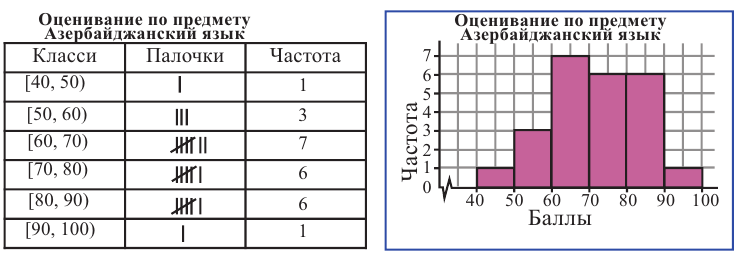
Ниже приведены результаты оценивания учащихся по предмету Азербайджанский язык в баллах (по 100 бальной системе).
52 66 75 80 52 48 95 85 84 68 86 82 63 78 75 64 79 81 66 53
76 75 69 65. Диапазон изменения числовой информации 48-95. Данную информацию можно сгруппировать в 6 классов размерностью 10 : 40-50, 50-60, 60-70, 70-80, 80-90, 90-100.
"Ствол-листья". Эту форму удобно применять при небольшом количестве данных. Представление числовой информации в виде ствола и листьев занимает немного времени и даёт возможность более ясно увидеть распределение информации. А форма распределения позволяет с лёгкостью находить ряд статистических величин (моду, медиану, среднее арифметическое, наибольшую разность и т.д. ).
Пример №3
Следующие данные отражают результаты оценивания учащихся. 32? 67, 81, 92, 87, 72, 63, 88, 96, 91, 72, 63, 85, 79, 70, 85, 64, 86, 98, 100, 77, 88, 81, 64, 41, 78, 95, 74, 97, 66. Постройте диаграмму "ствол-листья", выполнив следующие шаги.
1.Разделите ствол и листья горизонтальной и вертикальной прямой.
2.Ведущая часть числовой информации - большой уровень (или уровни) принимается за ствол с ветками - показывает количество чисел. В данном случае ствол содержит ветки с числами 3, 4, 5, 6, 7, 8, 9, 10 и показывает количество десятков.
2.Следующие числа соответствуют листьям. Это цифры, выражающие значения единиц. На каждую "ветку" последовательно записываются листья . 
Пример №4
Представьте в виде диаграммы "ствол-листья" возраст работников фирмы, 37, 33, 33, 32, 29, 28, 28, 23, 22, 22, 22, 21, 21, 21, 20, 20, 19, 19, 18, 18, 18, 18, 16, 15, 14, 14, 14, 12, 12, 9, 6 .
а) Найдите среднее арифметическое, моду и медиану;
б) Представьте информацию в виде таблицы частот.

Представление непрерывной числовой информации
Формы представления непрерывной числовой информации схожи с формами сгруппированной дискретной информацией. Некоторая непрерывная числовая информация принимается как дискретная (и наоборот). То есть границу между ними определить очень трудно.
Пример №5
В результате проведённых исследований стало известно, что масса молодых людей, занимающихся спортом в клубе колеблется от 40 кг до 90 кг. Более подробная информация представлена в виде таблицы и гистограммы. 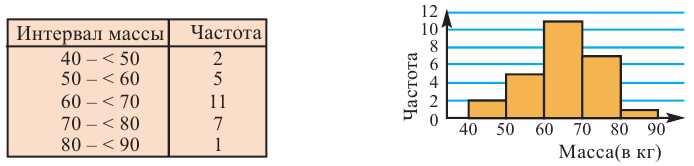
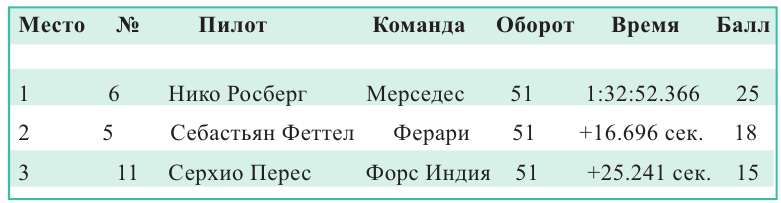
Маленький проект. В 2016 году в Баку впервые проходили соревнования Гран При Европы Формулы 1. Гоночный трек (длина одного оборота) в Баку, длиной приблизительно 6 км, проходил как через старую часть города, так и современную часть. Распределения первых 3 мест первого Гран При Европы Формулы 1 в Баку показаны в таблице.
Разложение бинома
Биномом называется двучлен. Рассмотрим различные степени бинома. В разложении квадрата и куба суммы существует определённая закономерность.
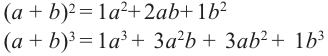
Так, показатель степени первого члена равен степени бинома, показатель каждого следующего первого члена а уменьшается на единицу, а второго члена b возрастает на единицу. Коэффициенты первого и последнего членов равны 1.
Последовательность степеней суммы а и b можно продолжить последовательно разлагая бином. Проследим по какому правилу производится разложение.
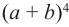 можно записать как
можно записать как 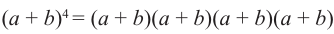 . Произведение каждого а или b равно сумме всех различных произведений четырех множителей. Рассмотрим последовательность из этих вариантов.
. Произведение каждого а или b равно сумме всех различных произведений четырех множителей. Рассмотрим последовательность из этих вариантов.
- возьмём 0-ой множитель члена b и 4-ый множитель члена а.
Получим член а4 и такой 4Со или 1 возможный вариант, и коэффициент этого члена равен 1.
- возьмём 1-ый множитель члена b и 3-ый множитель члена а. Получим член
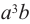 и такой
и такой 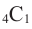 или 4 возможных варианта, и коэффициент этого члена равен 4.
или 4 возможных варианта, и коэффициент этого члена равен 4. - возьмём 2-ой множитель члена b и 2-ой множитель члена а. Получим член
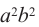 и такой
и такой 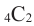 или 6 возможных варианта, и коэффициент этого члена равен 6.
или 6 возможных варианта, и коэффициент этого члена равен 6. - возьмём 3-ий множитель члена b и 1-ый множитель члена а. Получим член
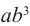 и такой
и такой 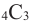 или 4 возможных варианта, и коэффициент этого члена равен 4.
или 4 возможных варианта, и коэффициент этого члена равен 4. - возьмём 4-ый множитель члена b и 0-ой множитель члена а. Получим член
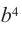 и такой
и такой 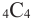 или 4 возможных варианта, и коэффициент этого члена равен 1.
или 4 возможных варианта, и коэффициент этого члена равен 1.
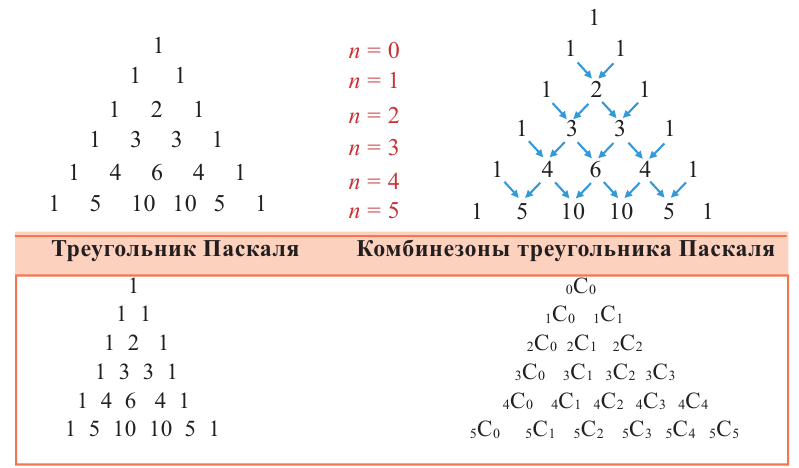
Разместим степени биномов, биномиальные разложения и коэффициенты членов в таблицу.

Как видно расположения коэффициентов обладают интересным математическим свойством и образуют треугольник Паскаля.
Подробное объяснение разложение бинома:
Для произвольных чисел а, b и числа 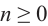 справедливо равенство:
справедливо равенство: 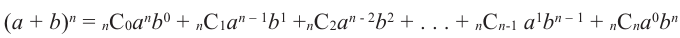
В более короткой форме эту формулу можно записать при помощи знака 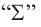 сигма.
сигма.
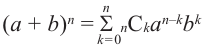
В разложении бинома 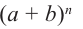 существует
существует  член. Любой
член. Любой  член имеет вид
член имеет вид 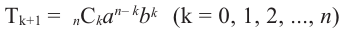 •в разложении бинома
•в разложении бинома 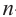 -ой степени присутствует
-ой степени присутствует 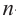 + 1 член
+ 1 член
•любой биномиальный член можно найти по формуле 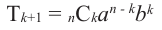
•сумма степеней любых членов равна 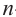 •сумма биномиальных коэффициентов равна
•сумма биномиальных коэффициентов равна 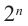 .
.
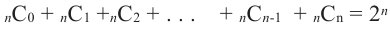
Проверьте последнее равенство для 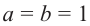 .
.
При разложении степеней бинома коэффициенты слагаемых отличаются от биномиальных коэффициентов.
Пример №6
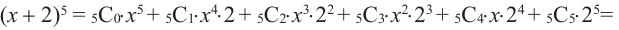
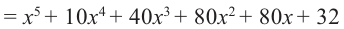
Например, в данном разложении коэффициент третьего слагаемого равен 40, а его биномиальный коэффициент равен 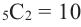 .
.
Пример №7
Найдём четвёртый член разложения бинома 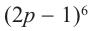
Решение: Здесь 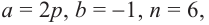 тогда
тогда
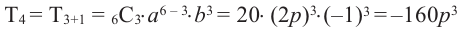
Треугольник Паскаля

Треугольник Паскаля назван в честь его создателя известного французского математика Блеза Паскаля, жившего в XVI веке. Вершиной треугольника является 1. Каждая строка, образующая треугольник, начинается и заканчивается с единицы. Каждое число в следующей строке, равно сумме двух соседних чисел предыдущей строки. Количество членов каждой строки больше предыдущей на одно число.
Проверим соответствует ли в действительности член 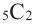 пятой строке треугольника Паскаля.
пятой строке треугольника Паскаля.

Коэффициенты членов в разложении бинома являются последовательными числами треугольника Паскаля в соответствующей строке. Слева направо степень первого члена равна степени бинома, в каждом следующем члене разложения степень множителя а уменьшается на единицу, а степень множителя b на единицу увеличивается.
6-ая строка треугольника Паскаля формируется следующим образом. 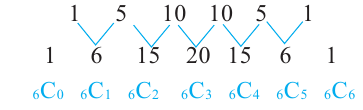
Можно записать общую форму для биномиального разложения.
Испытания Бернулли
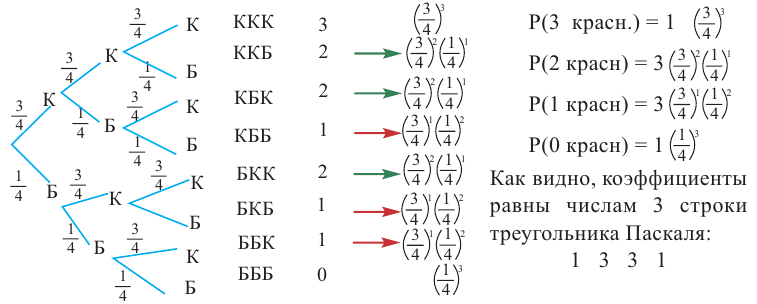
Для того, чтобы понять схему Бернулли рассмотрим следующий пример. Если в игре вероятность выигрыша(появления зелёного шарика) равна
равна 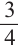 , то вероятность проигрыша (появления красного шарика) равна
, то вероятность проигрыша (появления красного шарика) равна 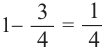 . Вычислим вероятность изменения числа побед и поражений в 4 играх.
. Вычислим вероятность изменения числа побед и поражений в 4 играх.
1)Р(вероятность выигрыша во всех 4 играх) 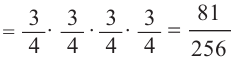
2)Р(вероятность проигрыша во всех 4 играх)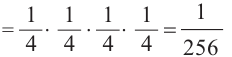
3)Найдём варианты выигрыша в 3 из 4 игр и соответствующую вероятность:
(В,В,В,П) Р(выигрыш во всех играх кроме 4)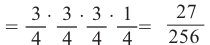
(В,В,П,В) Р(выигрыш во всех играх кроме З)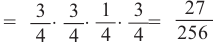
(В,П,В,В) Р(выигрыш во всех играх кроме 2)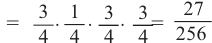
(П,В,В,В) Р(выигрыш во всех играх кроме 1)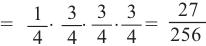
Количество вариантов победы игрока в 3 из 4 игр можно вычислить при помощи комбинезона 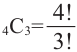 .
.
Вероятность вариантов имеет равные возможности 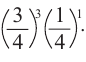
Тогда вероятность этого события можно вычислить так:
Р(выигрыш в 3 из 4 игр)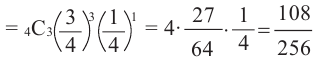
Аналогичным образом исследуются другие ситуации.
4)Выигрыш в 2 играх из 4.
Количество возможных вариантов выигрыша в 2 играх из 4:
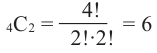
То есть вероятность победы в каждом из 6 случаев 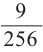
Р(выигрыш в 2 из 4 игр) =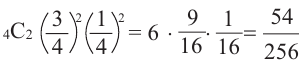
5)Вероятность победы в 1 из 4 игр.
Р(В,П,П,П) = 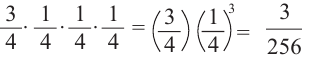
Р(выигрыш в 1 из 4 игр) = 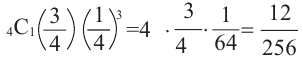
Мы нашли вероятности выигрыша команды в 4, 3, 2, 1, 0 играх. Если эти вероятности вычислены верно, то их сумма должна равняться единице.
Р(4 выиг.) + Р(3 выиг.) + Р(2 выиг.)+ Р(1 выиг.)+ Р(0 выиг.) =1.
Выполним проверку: 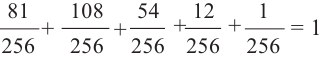
Представленная задача называется биномиальными испытаниями, так как в задачах такого типа в соответствии с ситуацией возможно использовать члены биномиального разложения. Например, задача выше соответствует разложению биномиальных членов 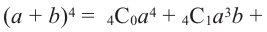
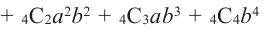 .
.
Иногда их называют испытаниями Бернулли. Для данной задачи введём переменные р (выигрыш) и q (проигрыш). При биномиальном разложении можно увидеть соответствие каждого члена реальной ситуации . 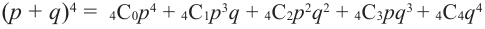
Здесь p вероятность успеха (появление красного papa) и 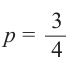 , q вероятность неудачи (появление зелёного шара)
, q вероятность неудачи (появление зелёного шара)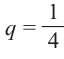 .
.
Испытания Бернулли и вероятность
Если для 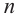 независимых испытаний вероятность успешного события р, тогда
независимых испытаний вероятность успешного события р, тогда 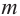 вероятность успеха,
вероятность успеха, 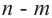 вероятность неудачи и Р( испытаний,
вероятность неудачи и Р( испытаний, 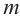 успех)
успех)  . Биномиальное распределение или испытания Бернулли справедливы только при следующих условиях.
. Биномиальное распределение или испытания Бернулли справедливы только при следующих условиях.
- У каждого испытания есть только два результата.
- Известно количество испытаний.
- Испытания независимы.
- Все испытания равновероятны.
Исследуем испытания Бернулли схематично на следующем примере.
Пример №8
Колесо состоит из 4 одинаковых частей - 3 части красные и одна белая. При вращении колесо может остановиться или на красной части или на белой. На схеме представлены возможные положения колеса при трех вращениях. 
Также возможно увидеть связь с биномиальным разложением 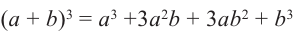 Здесь
Здесь 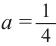 и
и 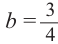 . Для этих событий проверьте формулу Бернулли для Р(
. Для этих событий проверьте формулу Бернулли для Р(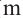 красн.) =
красн.) = 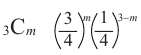 при
при 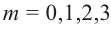 .
.
Пример №9
Для каждого из 5 вопросов существует 4 варианта ответа. Найдите вероятность того, что Наргиз ответила верно на 4 вопроса. Установите связь между вероятностью и биномиальным разложением.

Решение: Найдём возможные варианты, что Наргиз даст 5 верных или не верных ответов:
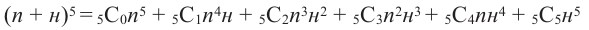

Из схемы видно, что существует 5 различных вариантов 4 верных ответов на 5 вопросов. Значит, вероятность этого события будет 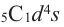 . Аналогичным образом можно увидеть связь между другой ситуацией и биномиальными членами.
. Аналогичным образом можно увидеть связь между другой ситуацией и биномиальными членами.
Обобщим эту связь при помощи таблицы.

Найдём, случайным образом, вероятность 4 правильных и 1 неправильного ответов. Вероятность каждого правильного ответа  ,
,
вероятность 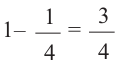 неправленого
неправленого
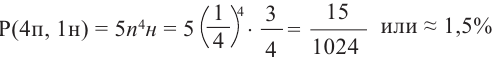
Пример №10
Найдите вероятность того, что в одной из четырёх семей , в которых есть дети, есть 3 мальчика и 1 девочка.
Решение: Для каждого ребёнка существует два возможных варианта:
или мальчик или девочка. Вероятность каждого из двух равна 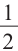 .
.
Р(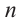 испытаний,
испытаний, 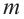 успех) =
успех) = 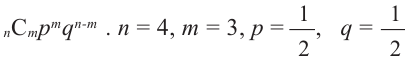 ;
;
Р(4 ребенка, 3 мальчика) =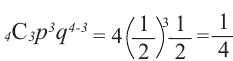
Значит, вероятность того, что из 4 детей 3 мальчики,
равна 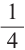 или 25%.
или 25%.
В биномиальном разложении член соответствующий ситуации показан красным цветом, 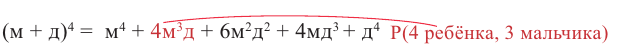
Пример №11
Фирма проводит акцию по продаже детского питания. В каждую коробку был положен купон так, что 3 из каждых 20 являются выигрышными. Какова вероятность того, что среди 5 коробок детского питания 2 окажутся с выигрышными купонами? При вычислениях можно использовать калькулятор.
Решение: успешным событием является наличие выигрышного купона:
Р(есть купон с выигрышем) = 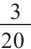
Неудачным событием, отсутствие купона с выигрышем:
Р( нет купона с выигрышем) = 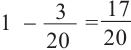
Р( 5 коробок 2 выигрыша) = 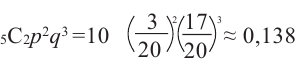
Пример №12
Монету подбросили 10 раз. Какова вероятность того, что как минимум 8 раз монета упадёт цифрой?
Решение: если событие, что монета упадёт как минимум 8 раз цифрой является успешным, значит, если цифра выпадет и 9 и 10 раз, то эти события также будут успешными. Найдём вероятности каждого события в отдельности и сложим их. Вероятность каждого события  .
.
Р( как минимум 8 раз цифрой) = Р (8 цифрой) + Р (9 цифрой) + Р (10 цифрой) Р( как минимум 8 раз цифрой) = 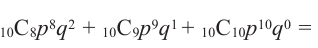
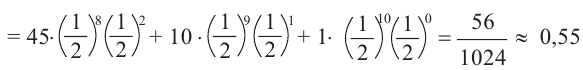 .
.
Генеральная и выборочная совокупности
В материалах сегодняшней лекции мы рассмотрим генеральную и выборочную совокупности.
Математическая статистика занимается сбором, анализом и обработкой данных наблюдений. Эти данные относятся к массовым явлениям, на которые влияют случайные факторы.
Статистические методы используются для контроля массового производства, в области физики, в астрономии, экономике, биологии и т.п. Рассмотрим три основные задачи математической статистики:
- 1) упорядочение статистического материала, статистические законы распределения;
- 2) статистическое оценивание характеристик распределения;
- 3) статистическая проверка гипотез.
Статистическое описание результатов наблюдений
При изучении качественного или количественного признака, характеризующего совокупность однородных объектов, не всегда имеется возможность обследовать каждый объект изучаемой совокупности. Приведём такой пример. Электрическую лампочку условимся считать стандартной, если продолжительность её горения не менее 1200 ч, в противном случае она считается нестандартной. За качеством продукции
обязан следить завод-изготовитель. Исследовать каждую лампочку на продолжительность горения практически невозможно, да это и противоречит здравому смыслу. Как же получить представление о качестве изготовляемой продукции? Пусть заводу необходимо поставить потребителю партию готовых изделий. Вместо данных о качестве всех электрических лампочек партии достаточно получить точные сведения о качестве небольшой их части, отобранных случайно. По продолжительности горения отобранных лампочек можно судить о качестве всех лампочек партии. Практика подтверждает, что сделанные выводы бывают достаточно надёжными.
Совокупность всех возможных, иногда говорят, - всех мыслимых, значений исследуемой случайной величины называют генеральной совокупност ью.
Множество значений случайной величины, полученное в результате наблюдений над нею, называют случайной выборкой или просто выборкой.
Число объектов в генеральной совокупности и в выборке называют их объёмами. Генеральная совокупность может иметь как конечный, так и бесконечный объём.
Рассмотрим наблюдение за некоторым измеряемым признаком какого либо объекта, например, возраст людей, сортность изделий и др.
Значение признака генеральной совокупности - это: случайная величина X, связанная с испытанием (наблюдением). Эта случайная величина распределена по некоторому закону с неизвестными параметрами, который называется распределением генеральной совокупности.
Проведём n испытаний при одних и тех же условиях. Случайная величина X принимает значения 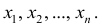
Это множество значений называется выборкой объема n.
Элементы выборки, записанные в порядке их регистрации, труднообозримы и неудобны для дальнейшего анализа. Необходимо
получить такое описание выборки, которое позволяет выделить характерные особенности исходных данных, Для этого существуют различные способы группировки данных выборки.
Пусть выборка объёма n содержит m различных чисел. Изменив нумерацию, запишем их в виде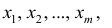 причём
причём 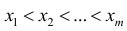 . Число m называется размахом выборки.
. Число m называется размахом выборки.
Пусть значение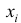 встречается в выборке
встречается в выборке 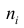 раз,
раз, 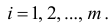 . Число
. Число 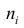 называется
называется 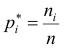 , а число
, а число 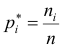 - относительной
- относительной
частотой элемента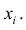
Таблица

называется статистическим рядом.
При большом объёме выборки используется группированный статистический ряд. Для этого все элементы выборки распределяются по группам или интервалам группировки. Интервал, содержащий все элементы выборки, разбивается на k непересекающихся интервалов 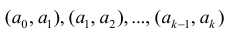 , не обязательно равных по длине.
, не обязательно равных по длине.
Если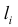 - число элементов выборки, попавших в интервал
- число элементов выборки, попавших в интервал 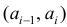 , а
, а
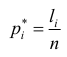 их частота, то можно составить таблицу
их частота, то можно составить таблицу
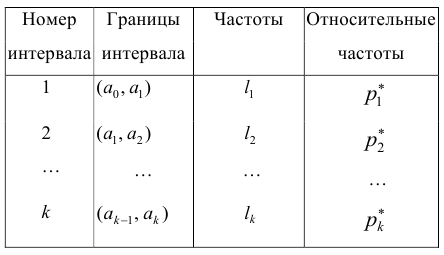
Эта таблица называется группированным статистическим рядом.
Если наблюдаемое значение попадает на границу соседних интервалов, то число его наблюдений относят к правому интервалу.
По данным выборки можно построить статистическую функцию распределения
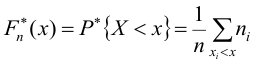
Для наглядного представления выборки используют гистограмму и полигон частот.
Гистограмма относительных частот строится по группированному статистическому ряду. Для этого находится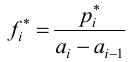 (статистическая плотность)
(статистическая плотность) 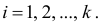
Гистограмма - это ступенчатая фигура, состоящая из прямоугольников с основаниями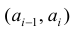 и высотами
и высотами 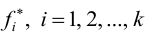 (рис. 1).
(рис. 1).
При увеличении объёма выборки и уменьшении интервала группировки гистограмма относительных частот является статистическим аналогом плотности распределения f(X) генеральной совокупности.
Полигон относительных частот - это ломаная линия с вершинами 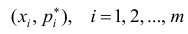 взятыми из статистического ряда (рис. 2).
взятыми из статистического ряда (рис. 2).
Заключение по лекции:
В лекции мы рассмотрели генеральную и выборочную совокупности.
Статистические оценки параметров генеральной совокупности
Определение статистической оценки:
Пусть требуется изучить количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак. Отсюда возникает задача оценки параметров, которыми определяется это распределение. Например, если известно, что изучаемый признак распределён в генеральной совокупности по нормальному закону, то необходимо оценить (приближённо найти) математическое ожидание и среднеквадратическое отклонение, так как эти два параметра полностью определяют нормальное распределение. Если же имеются основания считать, что признак имеет распределение Пуассона, то необходимо оценить параметр 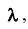 , которым это распределение определяется.
, которым это распределение определяется.
Обычно в распределении исследователь имеет лишь данные выборки, например, значения количественного признака 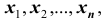 , полученные в результате n наблюдений (здесь и далее наблюдения предполагаются независимыми). Через эти данные и выражают оцениваемый параметр.
, полученные в результате n наблюдений (здесь и далее наблюдения предполагаются независимыми). Через эти данные и выражают оцениваемый параметр.
Рассматривая 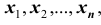 как значения независимых случайных величин
как значения независимых случайных величин 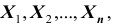 можно сказать, что найти статистическую оценку неизвестногопараметра теоретического распределения означает найти функцию от наблюдаемых случайных величин, которая и даёт приближённое значение оцениваемого параметра. Например, как будет показано далее, для оценки математического ожидания нормального распределения служит функция (среднее арифметическое наблюдаемых значений признака):
можно сказать, что найти статистическую оценку неизвестногопараметра теоретического распределения означает найти функцию от наблюдаемых случайных величин, которая и даёт приближённое значение оцениваемого параметра. Например, как будет показано далее, для оценки математического ожидания нормального распределения служит функция (среднее арифметическое наблюдаемых значений признака):
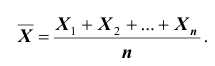
Итак, статистической оценкой неизвестного параметра теоретического распределения называют функцию от наблюдаемых случайных величин. Статистическая оценка неизвестного параметра генеральной совокупности, записанная одним числом, называется точечной. Рассмотрим следующие точечные оценки: смещенные и несмещённые, эффективные и состоятельные.
Для того, чтобы статистические оценки давали «хорошие» приближения оцениваемых параметров, они должны удовлетворять определённым требованиям. Укажем эти требования.
Пусть  есть статистическая оценка неизвестного параметра
есть статистическая оценка неизвестного параметра  теоретического распределения. Допустим, что при выборке объёма п найдена оценка
теоретического распределения. Допустим, что при выборке объёма п найдена оценка 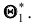 Повторим опыт, то есть извлечём из генеральной совокупности другую выборку того же объёма и по её данным найдём оценку
Повторим опыт, то есть извлечём из генеральной совокупности другую выборку того же объёма и по её данным найдём оценку  и т.д. Повторяя опыт многократно, получим числа
и т.д. Повторяя опыт многократно, получим числа 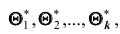 которые, вообще говоря, будут различаться между собой. Таким образом, оценку
которые, вообще говоря, будут различаться между собой. Таким образом, оценку  можно рассматривать как случайную величину, а числа как возможные её значения.
можно рассматривать как случайную величину, а числа как возможные её значения.
Ясно, что если оценка даёт приближённое значение с избытком, то каждое найденное по данным выборок число 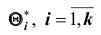 будет больше истинного значения . Следовательно, что в этом случае и математическое (среднее значение) случайной величины
будет больше истинного значения . Следовательно, что в этом случае и математическое (среднее значение) случайной величины  будет больше, чем
будет больше, чем  , то есть
, то есть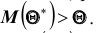 Очевидно, что если
Очевидно, что если  даёт приближённое значение
даёт приближённое значение  с недостатком, то
с недостатком, то 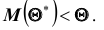
Поэтому, использование статистической оценки, математическое ожидание которой не равно оцениваемому параметру, приводит к систематическим (одного знака) ошибкам. По этой причине естественно потребовать, чтобы математическое ожидание оценки  было равно оцениваемому параметру. Хотя соблюдение этого требования, в общем, не устранит ошибок (одни значения больше, а другие меньше чем ), ошибки разных знаков будут встречаться одинакова часто. Однако соблюдение требования
было равно оцениваемому параметру. Хотя соблюдение этого требования, в общем, не устранит ошибок (одни значения больше, а другие меньше чем ), ошибки разных знаков будут встречаться одинакова часто. Однако соблюдение требования 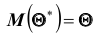 гарантирует невозможность получения систематических ошибок, то есть устраняет систематические ошибки.
гарантирует невозможность получения систематических ошибок, то есть устраняет систематические ошибки.
Несмещённой называют статистическую оценку (ошибку) 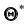 , математическое ожидание которой равно оцениваемому параметру при любом объёме выборки, то есть
, математическое ожидание которой равно оцениваемому параметру при любом объёме выборки, то есть 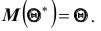
Смещённой называют статистическую оценкуматематическое ожидание которой не равно оцениваемому параметру при любом объёме выборки, то есть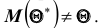
Однако было бы ошибочным считать, что несмещённая оценка всегда даёт хорошее приближение оцениваемого параметра. Действительно, возможные значения 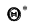 могут быть сильно рассеяны вокруг своего среднего значения, то есть дисперсия
могут быть сильно рассеяны вокруг своего среднего значения, то есть дисперсия 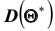 может быть значительной. В этом случае, найденная по данным одной выборки оценка, например
может быть значительной. В этом случае, найденная по данным одной выборки оценка, например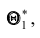 может оказаться весьма удалённой от среднего значения
может оказаться весьма удалённой от среднего значения 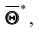 , а значит, и от самого оцениваемого параметра. Таким образом, приняв
, а значит, и от самого оцениваемого параметра. Таким образом, приняв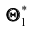 в качестве приближённого значения. мы допустим большую ошибку. Если же потребовать, чтобы дисперсия
в качестве приближённого значения. мы допустим большую ошибку. Если же потребовать, чтобы дисперсия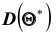 была малой, то возможность допустить большую ошибку будет исключена. По этой причине к статистической оценке предъявляется требование эффективности.
была малой, то возможность допустить большую ошибку будет исключена. По этой причине к статистической оценке предъявляется требование эффективности.
Эффективной называют статистическую оценку, которая (при заданном объёме выборки п) имеет наименьшую возможную дисперсию.
Далее, при рассмотрении выборок большого объёма ( n достаточно велико!) к статистическим оценкам предъявляется требование состоятельности. Состоятельной называют статистическую оценку, которая при 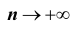 стремится по вероятности к оцениваемому параметру, то есть, справедливо равенство:
стремится по вероятности к оцениваемому параметру, то есть, справедливо равенство: 
Например, если дисперсия несмещённой оценки при стремится к нулю, то такая оценка оказывается также состоятельной.
Рассмотрим вопрос о том, какие выборочные характеристики лучше всего в смысле несмещённости, эффективности и состоятельности оценивают генеральную среднюю и дисперсию. Пусть изучается дискретная генеральная совокупность относительно некоторого количественного признака X .
Генеральной средней 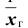 называется среднее арифметическое значений признака генеральной совокупности. Она вычисляется по формуле:
называется среднее арифметическое значений признака генеральной совокупности. Она вычисляется по формуле:
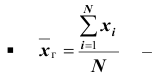 если все значения
если все значения 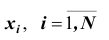 признака генеральной совокупности объёма N различны;
признака генеральной совокупности объёма N различны;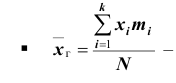 если значения
если значения 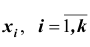 признака генеральной совокупности имеют соответственно частоты
признака генеральной совокупности имеют соответственно частоты 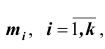 , причём
, причём 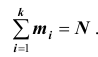 То есть генеральная средняя есть средняя взвешенная значений признака с весами, равными соответствующим частотам.
То есть генеральная средняя есть средняя взвешенная значений признака с весами, равными соответствующим частотам.
Замечание: пусть генеральная совокупность объёма N содержит объекты с различными значениями 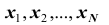 признака X . Представим себе, что из этой совокупности наудачу извлекается один объект. Вероятность того, что будет извлечён объект со значением признака, например
признака X . Представим себе, что из этой совокупности наудачу извлекается один объект. Вероятность того, что будет извлечён объект со значением признака, например 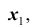 , очевидно, равна
, очевидно, равна 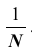 С этой же вероятностью может быть извлечён и любой другой объект. Таким образом, величину признака X можно рассматривать как случайную величину, возможные значения
С этой же вероятностью может быть извлечён и любой другой объект. Таким образом, величину признака X можно рассматривать как случайную величину, возможные значения 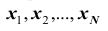 которой имеют одинаковые вероятности, равные
которой имеют одинаковые вероятности, равные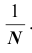 Нетрудно, в этом случае, найти математическое ожидание
Нетрудно, в этом случае, найти математическое ожидание 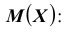
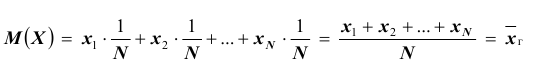
Итак, если рассматривать обследуемый признак X генеральной совокупности как случайную величину, то математическое ожидание признака равно генеральной средней этого признака: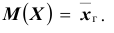 . Этот вывод мы получили, считая, что все объекты генеральной совокупности имеют различные значения признака. Такой же итог будет получен, если допустить, что генеральная совокупность содержит по несколько объектов с одинаковым значением признака. Обобщая полученный результат на генеральную совокупность с непрерывным
. Этот вывод мы получили, считая, что все объекты генеральной совокупности имеют различные значения признака. Такой же итог будет получен, если допустить, что генеральная совокупность содержит по несколько объектов с одинаковым значением признака. Обобщая полученный результат на генеральную совокупность с непрерывным
распределением признака X , определим генеральную среднюю как математическое ожидание признака: 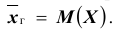
Пусть для изучения генеральной совокупности относительно количественного признака X извлечена выборка объёма n.
Выборочной средней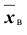 называют среднее арифметическое значений признака выборочной совокупности. Она вычисляется по формуле:
называют среднее арифметическое значений признака выборочной совокупности. Она вычисляется по формуле:
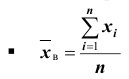 если все значения
если все значения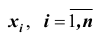 признака выборочной совокупности объёма n различны;
признака выборочной совокупности объёма n различны;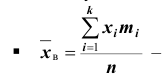 если значения
если значения 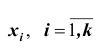 признака выборочной совокупности имеют соответственно частоты
признака выборочной совокупности имеют соответственно частоты 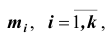 , причём
, причём 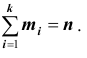 То есть выборочная средняя есть средняя взвешенная значений признака с весами, равными соответствующим частотам.
То есть выборочная средняя есть средняя взвешенная значений признака с весами, равными соответствующим частотам.
Замечание: выборочная средняя, найденная по данным одной выборки есть, очевидно, определённое число. Если же извлекать другие выборки того же объёма из той же генеральной совокупности, то выборочная средняя будет изменяться от выборки к выборке. Таким образом, выборочную среднюю можно рассматривать как случайную величину, а следовательно, можно говорить о распределениях (теоретическом и эмпирическом) выборочной средней и о числовых характеристиках этого распределения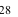 , в частности, о математическом ожидании и
, в частности, о математическом ожидании и
дисперсии выборочного распределения.
Далее, если генеральная средняя неизвестна и требуется оценить её по данным выборки, то в качестве оценки генеральной средней принимают выборочную среднюю, которая является несмещённой и состоятельной оценкой (предлагаем это утверждение доказать самостоятельно). Из сказанного следует, что если по нескольким выборкам достаточно большого объёма из одной и той же генеральной совокупности будут найдены выборочные средние, то они будут приближённо равны между собой. В этом состоит свойство устойчивости выборочных средних. Отметим, что если дисперсии двух совокупностей одинаковы, то близость выборочных средних к генеральным не зависит от отношения объёма выборки к объёму генеральной совокупности. Она зависит от объёма выборки: чем объём выборки больше, тем меньше выборочная средняя отличается от генеральной. Например, если из одной совокупности отобран 1% объектов, а из другой совокупности отобрано 4% объектов, причём объём первой выборки оказался большим, чем второй, то первая выборочная средняя будет меньше отличаться от соответствующей генеральной средней, чем вторая.
Для того чтобы охарактеризовать рассеяние значений количественного признака X генеральной совокупности вокруг своего среднего значения, вводят сводную характеристику – генеральную дисперсию. Генеральной дисперсией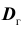 называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от их среднего значения
называется среднее арифметическое квадратов отклонений значений признака генеральной совокупности от их среднего значения 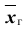 , и вычисляется по формуле:
, и вычисляется по формуле:
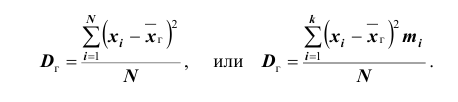
Для того чтобы охарактеризовать рассеяние наблюдаемых значений количественного выборки вокруг своего среднего значения, вводят сводную характеристику – выборочную дисперсию. Выборочной дисперсией в 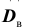 называется среднее арифметическое квадратов отклонений наблюдаемых значений признака выборочной совокупности от их среднего значения xв , и вычисляется по формуле:
называется среднее арифметическое квадратов отклонений наблюдаемых значений признака выборочной совокупности от их среднего значения xв , и вычисляется по формуле:
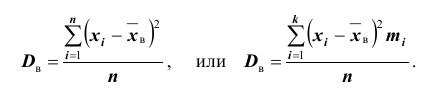
Вычисление дисперсии, безразлично, выборочной или генеральной, можно упростить, если воспользоваться следующей теоремой: дисперсия равна среднему квадратов значений признака минус квадрат общей средней: 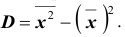 Действительно, справедливость теоремы вытекает из преобразований:
Действительно, справедливость теоремы вытекает из преобразований:
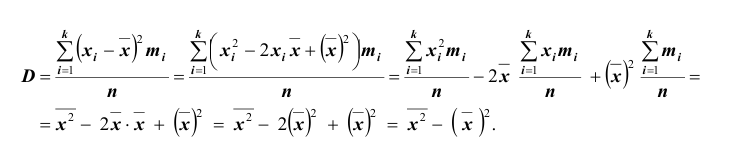
Кроме дисперсии для характеристики рассеяния значений признака генеральной (выборочной) совокупности вокруг своего среднего значения используют сводную характеристику – среднее квадратическое отклонение. Генеральным (выборочным) средним квадратическим отклонением называют квадратный корень из генеральной (выборочной) дисперсии:
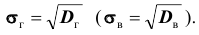 Далее, пусть из генеральной совокупности в результате n независимых наблюдений над количественным признаком X извлечена повторная выборка объёма n:
Далее, пусть из генеральной совокупности в результате n независимых наблюдений над количественным признаком X извлечена повторная выборка объёма n:

Требуется по данным выборки оценить (приближённо найти) неизвестную генеральную дисперсию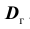 . Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то эта оценка будет приводить к систематическим ошибкам, давая заниженное значение генеральной дисперсии. Объясняется это тем, что как можно доказать, выборочная дисперсия является смещённой оценкой генеральной дисперсии
. Если в качестве оценки генеральной дисперсии принять выборочную дисперсию, то эта оценка будет приводить к систематическим ошибкам, давая заниженное значение генеральной дисперсии. Объясняется это тем, что как можно доказать, выборочная дисперсия является смещённой оценкой генеральной дисперсии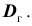 . Другими словами, математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
. Другими словами, математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
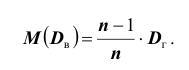 Легко «исправить» выборочную дисперсию так, чтобы её математическое ожидание было равно генеральной дисперсии. Для этого достаточно умножить в
Легко «исправить» выборочную дисперсию так, чтобы её математическое ожидание было равно генеральной дисперсии. Для этого достаточно умножить в 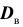 на дробь
на дробь 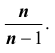 Сделав это, получим «исправленную дисперсию», которую обычно принято обозначать через
Сделав это, получим «исправленную дисперсию», которую обычно принято обозначать через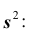
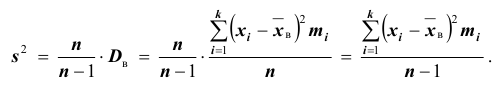
«Исправленная дисперсия» является, конечно, несмещённой оценкой генеральной дисперсии. Действительно
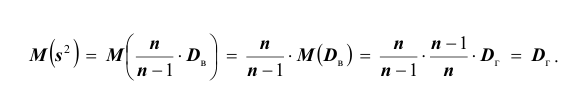
Итак, в качестве оценки генеральной дисперсии принимают «исправленную дисперсию»
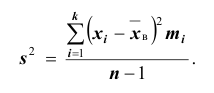
Для оценки же среднего квадратического отклонения генеральной совокупности используют соответственно «исправленное» среднее квадратическое отклонение, которое равно квадратному корню из «исправленной дисперсии»:
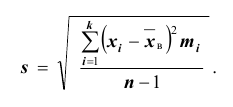
Подчеркнём, что s не является несмещённой оценкой; чтобы отразить этот факт мы написали и будем писать далее так: «исправленное» среднее квадратическое отклонение.
Замечание: сравнивая формулы
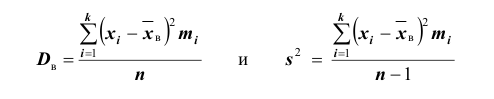
видим, что они отличаются лишь знаменателем. Очевидно, при достаточно больших значениях n объёма выборки, выборочная и «исправленная» дисперсии различаются мало.
Интервальные оценки
Все оценки, рассмотренные в предыдущей лекции - точечные. При выборке малого объёма точечная оценка может значительно отличаться от оцениваемого параметра, то есть приводит к грубым ошибкам. По этой причине наряду с точечным оцениванием статистическая теория оценивания параметров занимается вопросами интервального оценивания, которым следует пользоваться при небольшом объёме выборки. Задачу интервального оценивания можно сформулировать так: по данным выборки построить числовой интервал, относительно которого с заранее выбранной вероятностью можно сказать, что внутри него находится оцениваемый параметр. Интервальное оценивание, ещё раз это отметим, особенно необходимо при малом количестве наблюдений, когда точечная оценка малонадёжна.
Интервальной называют оценку, которая определяется двумя числами -концами интервала. Интервальные оценки позволяют установить точность и надёжность оценок (смысл этих понятий выясним ниже).
Итак, пусть, найденная по данным выборки, статистическая характеристика  служит оценкой неизвестного параметра
служит оценкой неизвестного параметра . Будем считать
. Будем считать  постоянным числом
постоянным числом  может быть и случайной величиной). Ясно, что
может быть и случайной величиной). Ясно, что тем точнее определяет параметр
тем точнее определяет параметр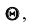 чем меньше абсолютная величина разности
чем меньше абсолютная величина разности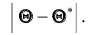 Другими словами, если
Другими словами, если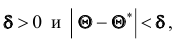 , то, чем меньше
, то, чем меньше  , тем оценка точнее.
, тем оценка точнее.
Таким образом, положительное число 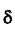 характеризует точность оценки. К сожалению статистические методы не позволяют категорически утверждать, что оценка удовлетворяет неравенству ©-©* <5; можно лишь говорить о вероятности у , с которой это неравенство осуществляется.
характеризует точность оценки. К сожалению статистические методы не позволяют категорически утверждать, что оценка удовлетворяет неравенству ©-©* <5; можно лишь говорить о вероятности у , с которой это неравенство осуществляется.
Надёжностью (доверительной вероятностью) оценки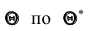 называют вероятность у , с которой осуществляется неравенство
называют вероятность у , с которой осуществляется неравенство  то есть
то есть 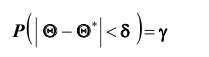
Обычно, надёжность оценки задаётся наперёд, причём в качестве у берут число, близкое к единице. Выбор доверительной вероятности не является математической задачей, а определяется конкретной решаемой проблемой. Наиболее часто задают надёжность, равную 0,95; 0,99; 0,999.
Согласно определению
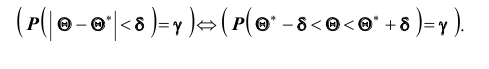
Это соотношение следует понимать так: вероятность того, что интервал 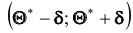 ; заключает в себе (покрывает
; заключает в себе (покрывает ) неизвестный параметр
) неизвестный параметр 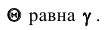
Доверительным называют интервал 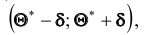 который покрывает неизвестный параметр с заданной надёжностью
который покрывает неизвестный параметр с заданной надёжностью 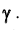
Метод доверительных интервалов разработан американским статистиком
Ю.Нейманом, исходя из идей английского статистика Р.Фишера.
Доверительный интервал для генеральной средней при известном значении среднего квадратического отклонения и при условии, что случайная величина (количественный признак X ) распределена нормально, задаётся выражением:
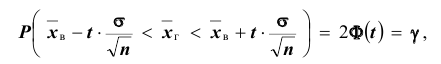
где 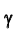 – наперёд заданное число, близкое к единице,
– наперёд заданное число, близкое к единице,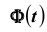 – функция Лапласа, значения которой приведены в соответствующей таблице,
– функция Лапласа, значения которой приведены в соответствующей таблице, 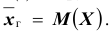 . Смысл полученного соотношения таков: с надёжностью
. Смысл полученного соотношения таков: с надёжностью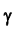 можно утверждать, что доверительный интервал
можно утверждать, что доверительный интервал 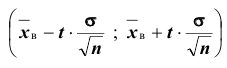 ; в покрывает неизвестный параметр
; в покрывает неизвестный параметр 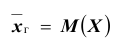 при точности оценки
при точности оценки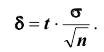 . Заметим, что число t
. Заметим, что число t
определяется из равенства 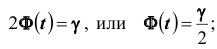 по таблице значений функции Лапласа находят аргумент t , которому соответствует значение равное
по таблице значений функции Лапласа находят аргумент t , которому соответствует значение равное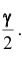
Замечание: оценку 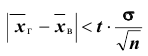 называют классической. Из формулы
называют классической. Из формулы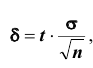 , определяющей точность классической оценки, моно сделать следующие выводы:
, определяющей точность классической оценки, моно сделать следующие выводы:
- при возрастании n– объёма выборки число 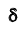 убывает и, следовательно, точность оценки увеличивается;
убывает и, следовательно, точность оценки увеличивается;
- увеличение надёжности 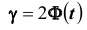 приводит к увеличению t (так как функция
приводит к увеличению t (так как функция 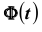 является возрастающей), а следовательно, и к возрастанию
является возрастающей), а следовательно, и к возрастанию 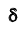 . Другими словами, увеличение надёжности классической оценки влечёт за собой уменьшение её точности.
. Другими словами, увеличение надёжности классической оценки влечёт за собой уменьшение её точности.
Интервал 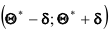 ; имеет случайные концы (их называют доверительными границами). Действительно, в разных выборках получаются различные значения . Следовательно от выборки к выборке будут изменяться и концы доверительного интервала, то есть доверительные
; имеет случайные концы (их называют доверительными границами). Действительно, в разных выборках получаются различные значения . Следовательно от выборки к выборке будут изменяться и концы доверительного интервала, то есть доверительные
границы сами являются случайными величинами – функциями от 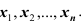 . Так как случайной величиной является не оцениваемый параметр
. Так как случайной величиной является не оцениваемый параметр 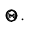 , а доверительный интервал, то более правильно говорить не о вероятности попадания
, а доверительный интервал, то более правильно говорить не о вероятности попадания 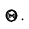 в доверительный интервал, а о вероятности того, что доверительный интервал покроет
в доверительный интервал, а о вероятности того, что доверительный интервал покроет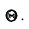
Пример №13
Случайная величина X имеет нормальное распределение с известным средним квадратическим отклонением 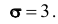 . Найти доверительные интервалы для оценки неизвестного математического ожидания a (или, что тоже самое, для оценки неизвестной генеральной средней
. Найти доверительные интервалы для оценки неизвестного математического ожидания a (или, что тоже самое, для оценки неизвестной генеральной средней 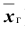 ) по выборочным средним
) по выборочным средним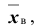 , если объём выборки n =36 и задана надёжность оценки
, если объём выборки n =36 и задана надёжность оценки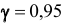
Решение. Найдём, прежде всего, t . Из соотношения 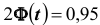 получим
получим 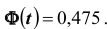 Далее, по таблице находим t =1,96 . Теперь, найдём точность оценки:
Далее, по таблице находим t =1,96 . Теперь, найдём точность оценки:
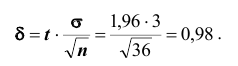
Доверительные интервалы таковы: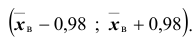 . Например, если
. Например, если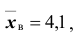 то доверительный интервал имеет следующие доверительные границы:
то доверительный интервал имеет следующие доверительные границы:
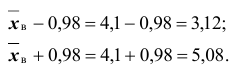
Таким образом, значения неизвестного параметра 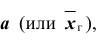 согласующиеся с данными выборки находятся в интервале 3,12; 5,08 .
согласующиеся с данными выборки находятся в интервале 3,12; 5,08 .
Подчеркнём, что было бы ошибочным написать: 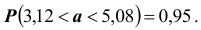 Действительно, так как a – постоянная величина, то либо она заключена в найденном интервале (тогда событие
Действительно, так как a – постоянная величина, то либо она заключена в найденном интервале (тогда событие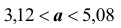 достоверно и его вероятность равна единице), либо в нём не заключена (в этом случае событие
достоверно и его вероятность равна единице), либо в нём не заключена (в этом случае событие 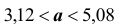 невозможно и его вероятность равна нулю). Другими словами, доверительную вероятность не следует связывать с оцениваемым параметром; она связана лишь с границами доверительного интервала, которые, как уже было сказано, изменяются от выборки к выборке.
невозможно и его вероятность равна нулю). Другими словами, доверительную вероятность не следует связывать с оцениваемым параметром; она связана лишь с границами доверительного интервала, которые, как уже было сказано, изменяются от выборки к выборке.
Поясним смысл, который имеет заданная надёжность. Надёжность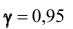 указывает, что если произведено достаточно большое число выборок, то 95% из них определяет такие доверительные интервалы, в которых параметр
указывает, что если произведено достаточно большое число выборок, то 95% из них определяет такие доверительные интервалы, в которых параметр 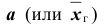 действительно заключён; лишь в 5% случаев он может выйти за границы доверительного интервала.
действительно заключён; лишь в 5% случаев он может выйти за границы доверительного интервала.
Замечание: если требуется оценить математическое ожидание (генеральную среднюю) с наперёд заданной точностью 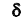 и надёжностью
и надёжностью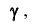 то минимальный объём выборки, который обеспечит эту точность, находят по формуле:
то минимальный объём выборки, который обеспечит эту точность, находят по формуле:

Нетрудно показать, что доверительный интервал для генеральной средней 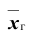 (математического ожидания a ) нормально распределённого признака при неизвестном значении среднего квадратического отклонения задаётся выражением:
(математического ожидания a ) нормально распределённого признака при неизвестном значении среднего квадратического отклонения задаётся выражением:
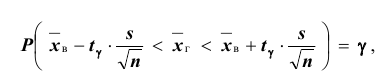
где s – «исправленное» среднее квадратическое отклонение, параметр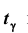 находят по заданным значения
находят по заданным значения 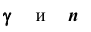 из соответствующих таблиц (и наоборот, по заданным
из соответствующих таблиц (и наоборот, по заданным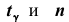 находят вероятность
находят вероятность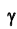 ). Отсюда следует, что с надёжностью можно утверждать, что доверительный интервал
). Отсюда следует, что с надёжностью можно утверждать, что доверительный интервал 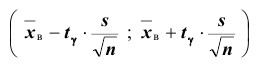 покрывает неизвестный параметр
покрывает неизвестный параметр 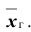
Пример №14
Количественный признак X генеральной совокупности распределён нормально. По выборке объёма n =16 найдены выборочная средняя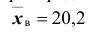 и «исправленное» среднее квадратическое отклонение s = 0,8. Оценить неизвестную генеральную среднюю
и «исправленное» среднее квадратическое отклонение s = 0,8. Оценить неизвестную генеральную среднюю 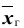 с помощью доверительного интервала с надёжностью
с помощью доверительного интервала с надёжностью 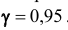
Решение. Пользуясь таблицей (см. приложения), по известным значениям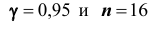 находим
находим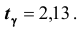 . Тогда, доверительные границы:
. Тогда, доверительные границы:
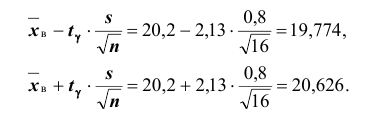
Итак, с надёжностью неизвестный параметр 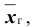 , заключён в доверительном интервале ( 19,774; 20,626 ).
, заключён в доверительном интервале ( 19,774; 20,626 ).
Понятие статистической гипотезы. Общая постановка задачи проверки гипотез
Проверка статистических гипотез тесно связана с теорией оценивания параметров. В естествознании, технике экономике для вычисления того или иного случайного факта часто прибегают к высказыванию гипотез, которые можно проверить статистически (то есть, опираясь на результаты наблюдений в случайной выборке). Под статистическими подразумевают такие гипотезы, которые относятся или к виду, или к отдельным параметрам распределения случайной величины. Например, статистической является гипотеза о том, что распределение производительности труда рабочих, выполняющих одинаковую работу в одинаковых условиях, имеет нормальный закон распределения. Статистической будет также гипотеза о том, что средние размеры деталей, производимых на однотипных, параллельно работающих станках, не различаются.
Статистическая гипотеза называется простой, если она однозначно определяет распределение случайной величины АГ, в противном случае гипотеза называется сложной. Например, простой гипотезой является предположение о том, что случайная величина X распределена по нормальному закону с математическим ожиданием, равным нулю, и дисперсией равной единице. Если высказывается предположение, что случайная величина X имеет нормальное распределение с дисперсией, равной единице, а математическое ожидание - число из отрезка 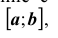 то это сложная гипотеза. Другим примером сложной гипотезы является предположение о том, что непрерывная случайная величина X с вероятностью
то это сложная гипотеза. Другим примером сложной гипотезы является предположение о том, что непрерывная случайная величина X с вероятностью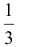 принимает значение из интервала (1; 5 ), в этом случае распределение случайной величины X может быть любым из класса непрерывных распределений.
принимает значение из интервала (1; 5 ), в этом случае распределение случайной величины X может быть любым из класса непрерывных распределений.
Часто распределение величины X известно, и по выборке наблюдений необходимо проверить предположения о значении параметров этого распределения. Такие гипотезы называются параметрическими.
Проверяемая гипотеза называется пулевой и обозначается 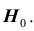 . Наряду с гипотезой
. Наряду с гипотезой 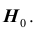 рассматривают одну из альтернативных (конкурирующих) гипотез
рассматривают одну из альтернативных (конкурирующих) гипотез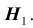 . Например, если проверяется гипотеза о равенстве параметра
. Например, если проверяется гипотеза о равенстве параметра 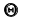 некоторому заданному значению
некоторому заданному значению 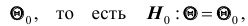 то в качестве альтернативной гипотезы можно рассматривать одну из следующих гипотез:
то в качестве альтернативной гипотезы можно рассматривать одну из следующих гипотез: 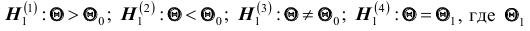 - заданное значение, причём
- заданное значение, причём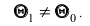 Выбор альтернативной гипотезы определяется конкретной формулировкой задачи.
Выбор альтернативной гипотезы определяется конкретной формулировкой задачи.
Правило, по которому принимается решение принять или отклонить гипотезу 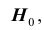 называется критерием и обозначается К. Так как решение принимается на основе выборки наблюдений случайной величины X, необходимо выбрать подходящую статистику, называемую в этом случае статистикой Z критерия К. При проверке простой параметрической гипотезы
называется критерием и обозначается К. Так как решение принимается на основе выборки наблюдений случайной величины X, необходимо выбрать подходящую статистику, называемую в этом случае статистикой Z критерия К. При проверке простой параметрической гипотезы 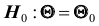 в качестве статистики критерия выбирают ту же статистику, что и для оценки параметра
в качестве статистики критерия выбирают ту же статистику, что и для оценки параметра 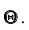
Проверка статистической гипотезы основывается на принципе, в соответствии с которым маловероятные события считаются невозможными, а события, имеющие большую вероятность,- достоверными. Этот принцип можно реализовать следующим образом. Перед анализом выборки фиксируется некоторая малая вероятность а, называемая уровнем значимости. Пусть V- множество значений статистики 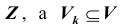 - такое подмножество, что при условии истинности гипотезы
- такое подмножество, что при условии истинности гипотезы 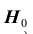 вероятность попадания статистики Z критерия в
вероятность попадания статистики Z критерия в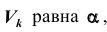 , то
, то 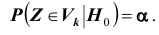
Обозначим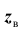 выборочное значение статистики Z, вычисленное по выборке наблюдений. Критерий формулируется так: отклонить гипотезу
выборочное значение статистики Z, вычисленное по выборке наблюдений. Критерий формулируется так: отклонить гипотезу 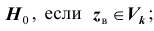 принять гипотезу
принять гипотезу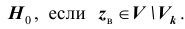 Критерий, основанный на использовании заранее заданного уровня значимости, называется критерием значимости. Множество
Критерий, основанный на использовании заранее заданного уровня значимости, называется критерием значимости. Множество 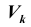 всех значений статистики Z критерия, при которых принимается решение отклонить гипотезу
всех значений статистики Z критерия, при которых принимается решение отклонить гипотезу 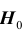 , называется критической областью; область
, называется критической областью; область 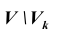 называется областью принятия гипотезы
называется областью принятия гипотезы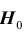
Уровень значимости а определяет размер критической области 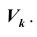 Положение критической области на множестве значений статистики Z зависит от формулировки альтернативной гипотезы
Положение критической области на множестве значений статистики Z зависит от формулировки альтернативной гипотезы 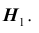 Например, если проверяется гипотеза
Например, если проверяется гипотеза 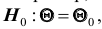 причём альтернативная
причём альтернативная
гипотеза формулируется как 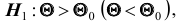 то критическая область размещается на правом (левом) «хвосте» распределения статистики Z, то есть имеет вид неравенства
то критическая область размещается на правом (левом) «хвосте» распределения статистики Z, то есть имеет вид неравенства 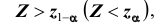 где
где 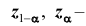 значения статистики Z, которые принимаются с вероятностями
значения статистики Z, которые принимаются с вероятностями 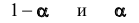 при условии, что верна гипотеза
при условии, что верна гипотеза 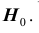 . В этом случае критерий называется односторонним (соответственно -правосторонним и левосторонним). Если альтернативная гипотеза формулируется как
. В этом случае критерий называется односторонним (соответственно -правосторонним и левосторонним). Если альтернативная гипотеза формулируется как 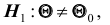 то критическая область размещается на обеих «хвостах» распределения статистики Z, то есть определяется совокупностью неравенств.
то критическая область размещается на обеих «хвостах» распределения статистики Z, то есть определяется совокупностью неравенств.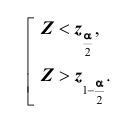 В этом случае критерий называется двусторонним.
В этом случае критерий называется двусторонним.
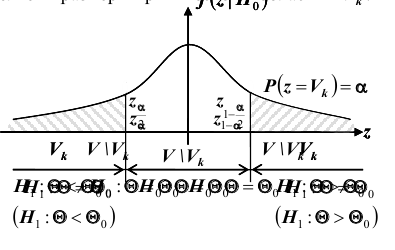
Расположение критической области 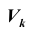 для различных альтернативных гипотез показано рисунках, приведённых выше, где
для различных альтернативных гипотез показано рисунках, приведённых выше, где 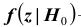 плотность распределения статистики Z критерия при условии, что верна гипотеза
плотность распределения статистики Z критерия при условии, что верна гипотеза 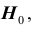
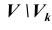 область принятия гипотезы,
область принятия гипотезы,
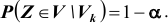
Проверку параметрической статистической гипотезы с помощью критерия значимости можно разбить на этапы:
- сформулировать проверяемую
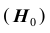 и альтернативную
и альтернативную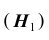 гипотезы;
гипотезы; - назначить уровень значимости а;
- 3) выбрать статистику Z критерия для проверки гипотезы
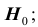
- определить выборочное распределение статистики Z при условии, что верна гипотеза
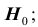
- в зависимости от формулировки альтернативной гипотезы определить критическую область
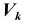 одним из неравенств
одним из неравенств 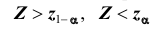 или совокупностью неравенств
или совокупностью неравенств 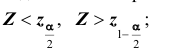
- получить выборку наблюдений и вычислить выборочные значения
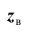 статистики критерия;
статистики критерия; - принять статистическое решение: если
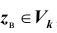 , то отклонить гипотезу
, то отклонить гипотезу 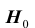 как не согласующуюся с результатами наблюдений; если
как не согласующуюся с результатами наблюдений; если 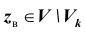 то принять гипотезу
то принять гипотезу 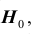 то есть считать, что гипотеза
то есть считать, что гипотеза 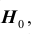 не противоречит результатам наблюдений
не противоречит результатам наблюдений
Пример №15
По паспортным данным автомобильного двигателя расход топлива на 100км пробега составляет Юл. В результате изменения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки проводятся испытания 25-и случайно отобранных автомобилей с модернизированным двигателем. Выборочное среднее расходов топлива на 100км пробега по результатам испытаний составило 9,3л. Предположим, что выборка расходов топлива получена из нормально распределённой генеральной совокупности со средним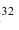 и дисперсией
и дисперсией 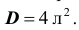 Используя критерий значимости, проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
Используя критерий значимости, проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
Решение. Проверим гипотезу о среднем т нормально распределённой генеральной совокупности. Проверку проведём по этапам:
1) проверяемая гипотеза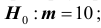 альтернативная гипотеза
альтернативная гипотеза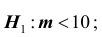
2) уровень значимости 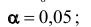
3) в качестве статистики Z критерия используем статистику математического ожидания - выборочное среднее 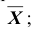
31 Обычно при выполнении пп. 4-7 используют статистику с нормальным распределением, статистику Стьюдента, Фишера.
32 То есть - с математическим ожиданием.
4) так как выборка получена из нормально распределённой генеральной совокупности, выборочное среднее также имеет нормальное распределение с дисперсией 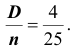 При условии, что верна гипотеза
При условии, что верна гипотеза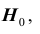 , математическое ожидание этого распределения равно 10. Нормированная статистика
, математическое ожидание этого распределения равно 10. Нормированная статистика 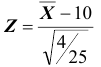 имеет нормальное распределение;
имеет нормальное распределение;
5) альтернативная гипотеза :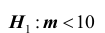 предполагает уменьшение расхода топлива, следовательно, нужно использовать односторонний критерий. Критическая область определяется неравенством
предполагает уменьшение расхода топлива, следовательно, нужно использовать односторонний критерий. Критическая область определяется неравенством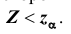 По таблице (см. приложение) находим
По таблице (см. приложение) находим 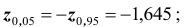
6) выборочное значение нормированной статистики критерия 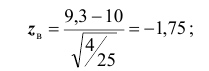
7) статистическое решение: так как выборочное значение статистики критерия принадлежит критической области, гипотеза 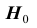 отклоняется. Следует считать, что изменение конструкции двигателя привело к уменьшению расхода топлива. Границу
отклоняется. Следует считать, что изменение конструкции двигателя привело к уменьшению расхода топлива. Границу критической области для исходной статистики Z критерия можно получить из соотношения
критической области для исходной статистики Z критерия можно получить из соотношения 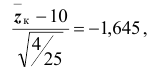 откуда
откуда 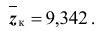 Таким образом, критическая область для статистики Z определяется неравенством
Таким образом, критическая область для статистики Z определяется неравенством 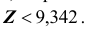
Решение, принимаемое на основе критерия значимости, может быть ошибочным. Пусть выборочное значение статистики критерия попадает в критическую область, и гипотеза 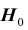 отклоняется в соответствии с критерием. Если, тем не менее, гипотеза
отклоняется в соответствии с критерием. Если, тем не менее, гипотеза 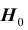 верна, то принимаемое решение неверно. Ошибка, совершаемая при отклонении правильной гипотезы
верна, то принимаемое решение неверно. Ошибка, совершаемая при отклонении правильной гипотезы 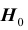 , называется ошибкой первого рода. Вероятность ошибки первого рода равна вероятности попадания статистики критерия в критическую область при условии, что верна гипотеза
, называется ошибкой первого рода. Вероятность ошибки первого рода равна вероятности попадания статистики критерия в критическую область при условии, что верна гипотеза 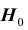 , то
, то
есть равна уровню значимости 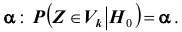
Ошибка второго рода происходит тогда, когда гипотеза принимается, но в действительности верна гипотеза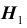 . Вероятность
. Вероятность 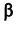 ошибки второго рода вычисляется по формуле:
ошибки второго рода вычисляется по формуле: 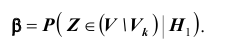
Пример №16
В условиях примера 3 предположим, что наряду с гипотезой 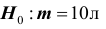 рассматривается альтернативная гипотеза :
рассматривается альтернативная гипотеза :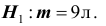 . В качестве статистики критерия снова возьмём выборочное среднее
. В качестве статистики критерия снова возьмём выборочное среднее 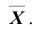 . Предположим, что критическая область задана неравенством
. Предположим, что критическая область задана неравенством 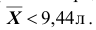 Найти вероятность ошибок первого и второго рода для критерия с такой критической областью.
Найти вероятность ошибок первого и второго рода для критерия с такой критической областью.
Решение. Найдём вероятность ошибки первого рода. Статистика X критерия при условии, что верна гипотеза : 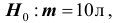 , имеет нормальное распределение с математическим ожиданием, равным 10, и дисперсией, равной
, имеет нормальное распределение с математическим ожиданием, равным 10, и дисперсией, равной 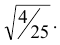 используя таблицу (см. приложение), по формуле
используя таблицу (см. приложение), по формуле 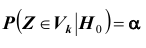 находим
находим 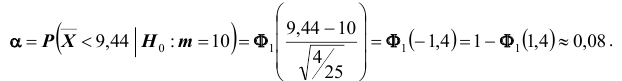
Это означает, что принятый критерий классифицирует примерно 8% автомобилей, имеющих расход 10л на 100км пробега, как автомобили, имеющие меньший расход топлива.
При условии, что верна гипотеза 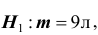 статистика
статистика 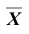 имеет нормальное распределение с математическим ожиданием, равным 9Б и дисперсией, равной
имеет нормальное распределение с математическим ожиданием, равным 9Б и дисперсией, равной 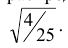 Нетрудно в этом случае найти вероятность ошибки второго рода, воспользовавшись формулой
Нетрудно в этом случае найти вероятность ошибки второго рода, воспользовавшись формулой 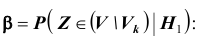
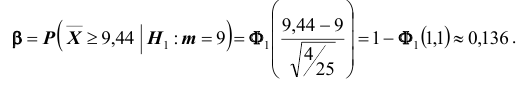
Следовательно, в соответствии с принятым критерием 13,6% автомобилей, имеющих расход топлива 9л на 100км пробега, классифицируются как автомобили, имеющие расход топлива 10л.
Теоретические и эмпирические частоты. Критерии согласия
Эмпирические частоты получают в результате опыта (наблюдения). Теоретические частоты рассчитывают по формулам. Для нормального закона распределения их можно найти следующим образом: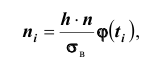 где
где 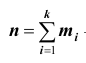 - сумма эмпирических (наблюдаемых) частот; h разность между двумя соседними вариантами (то есть длина частичного интервала);
- сумма эмпирических (наблюдаемых) частот; h разность между двумя соседними вариантами (то есть длина частичного интервала); 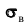 -выборочное среднее квадратическое отклонение;
-выборочное среднее квадратическое отклонение;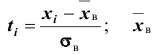 выборочная средняя арифметическая;
выборочная средняя арифметическая;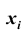 - середина
- середина 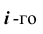 частичного интервала; значения функции
частичного интервала; значения функции 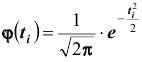 находят по таблице (см. приложения).
находят по таблице (см. приложения).
Обычно эмпирические и теоретические частоты различаются. Возможно, что расхождение случайно и связано с ограниченным количеством наблюдений; возможно, что расхождение неслучайно и объясняется тем, что для вычисления теоретических частот выдвинута статистическая гипотеза о том, что генеральная совокупность распределена нормально, а в действительности это е так. Распределение генеральной совокупности, которое она имеет в силу выдвинутой гипотезы, называют теоретическим.
Возникает необходимость установить правило (критерий), которое позволяло бы судить, является ли расхождение между эмпирическим и теоретическим распределениями случайным или значимым. Если расхождение окажется случайным, то считают, что данные наблюдений (выборки) согласуются с выдвинутой гипотезой о законе распределения генеральной совокупности и, следовательно, гипотезу принимают. Если же расхождение окажется значимым, то данные наблюдений не согласуются с выдвинутой гипотезой, и её отвергают.
Критерием согласия называют критерий, который позволяет установить, является ли расхождение эмпирического и теоретического распределений случайным или значимым, то есть согласуются ли данные наблюдений с выдвинутой статистической гипотезой или не согласуются.
Имеются несколько критериев согласия: критерий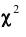 (Пирсона), критерий Колмогорова, критерий Романовского и др. Ограничимся описанием того, как критерий
(Пирсона), критерий Колмогорова, критерий Романовского и др. Ограничимся описанием того, как критерий 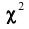 применяется к проверке гипотезы о нормальном распределении
применяется к проверке гипотезы о нормальном распределении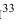 Генеральной совокупности (предлагаем студентам написать рефераты по различным критериям согласия н их применению).
Генеральной совокупности (предлагаем студентам написать рефераты по различным критериям согласия н их применению).
Допустим, что в результате п наблюдений получена выборка:

Выдвинем статистическую гипотезу: генеральная совокупность, из которой извлечена данная выборка, имеет нормальное распределение. Требуется установить, согласуется ли эмпирическое распределение с этой гипотезой. Предположим, что по
33 Критерий применяется аналогично и для других распределений
формуле (*) вычислены теоретические частоты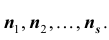 . Обозначим
. Обозначим 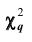 среднее арифметическое квадратов разностей между эмпирическими и теоретическим частотами, взвешенное по обратным величинам теоретических частот:
среднее арифметическое квадратов разностей между эмпирическими и теоретическим частотами, взвешенное по обратным величинам теоретических частот:
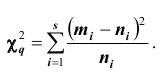
Чем больше согласуются эмпирическое и теоретическое распределения, тем меньше различаются эмпирические и теоретические частоты и тем меньше значение 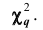 Отсюда следует, что
Отсюда следует, что 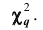 характеризует близость эмпирического и теоретического распределений. В разных опытах
характеризует близость эмпирического и теоретического распределений. В разных опытах 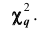 принимает различные, заранее неизвестные значения, то есть является случайной величиной.
принимает различные, заранее неизвестные значения, то есть является случайной величиной.
Плотность вероятности этого распределения (для выборки достаточно большого объёма) не зависит от проверяемого закона распределения, а зависит от параметра к, называемого числом степеней свободы. Так при проверке гипотезы о нормальном распределении генеральной совокупности k=s- 3, где s- число групп, на которые разбиты данные наблюдений. Существуют таблицы (см. приложения), в которых указана вероятность того, что в результате влияния случайных факторов величина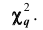 примет значение не меньше вычисленного по данным выборки
примет значение не меньше вычисленного по данным выборки 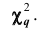
Для определённости примем уровень значимости 0,01. Если вероятность, найденная по таблицам, окажется меньше 0,01, то это означает, что в результате влияния случайных причин наступило событие, которое практически невозможно.
Таким образом, тот факт, что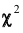 приняло значение
приняло значение 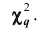 нельзя объяснить случайными причинами; его можно объяснить тем, что генеральная совокупность не распределена нормально и, значит, выдвинутая гипотеза о нормальном распределении генеральной совокупности должна быть отвергнута. Если вероятность, найденная по таблицам, превышает 0,01, то гипотеза о нормальном распределении генеральной совокупности согласуется с данными наблюдений и поэтому может быть принята. Полученные выводы распространяются и на другие уровни значимости.
нельзя объяснить случайными причинами; его можно объяснить тем, что генеральная совокупность не распределена нормально и, значит, выдвинутая гипотеза о нормальном распределении генеральной совокупности должна быть отвергнута. Если вероятность, найденная по таблицам, превышает 0,01, то гипотеза о нормальном распределении генеральной совокупности согласуется с данными наблюдений и поэтому может быть принята. Полученные выводы распространяются и на другие уровни значимости.
На практике надо, чтобы объём выборки был достаточно большим и чтобы каждая группа содержала 5-8 значений признака.
и чтобы каждая группа содержала 5-8 значений признака.
Для проверки гипотезы о нормальном распределении генеральной совокупности нужно:
- вычислить теоретические частоты по формуле (*);
- вычислить
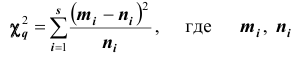 соответственно частоты эмпирические и теоретические;
соответственно частоты эмпирические и теоретические; - вычислить число степеней свободы к = s- 3, где s- число групп, на которые разбита выборка;
- выбрать уровень значимости;
- найти по таблице (см. приложения) по найденным
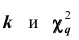 вероятность
вероятность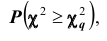 причём, если эта вероятность меньше принятого уровня значимости, то гипотезу о нормальном распределении генеральной совокупности отвергают; если же вероятность больше уровня значимости, то гипотезу принимают.
причём, если эта вероятность меньше принятого уровня значимости, то гипотезу о нормальном распределении генеральной совокупности отвергают; если же вероятность больше уровня значимости, то гипотезу принимают.
Пример №17
Проверить, согласуются ли данные выборки со статистической гипотезой о нормальном распределении генеральной совокупности, из которой извлечена выборка:

Решение. Вычислим выборочное среднее и выборочную дисперсию:
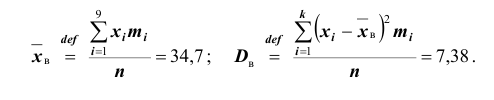
Далее, вычислим теоретические частоты по формуле (*):
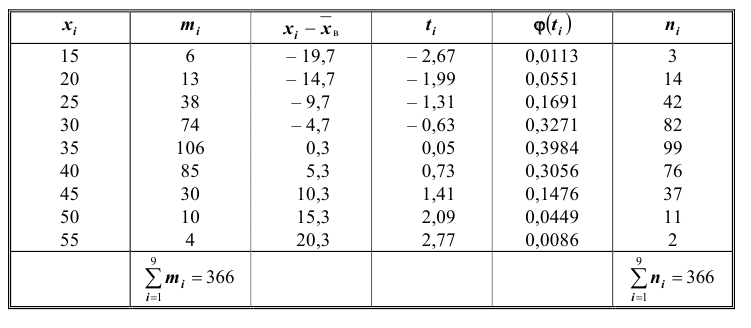
Найдем 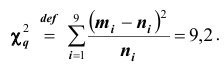 Вычислим число степеней свободы, учитывая, что число групп выборки
Вычислим число степеней свободы, учитывая, что число групп выборки 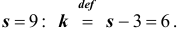 Уровень значимости примем равным 0,01. По таблице (см. приложения) при
Уровень значимости примем равным 0,01. По таблице (см. приложения) при 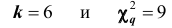 находим вероятность
находим вероятность 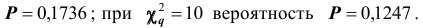 Используя линейную интерполяцию, получаем приближённое значение искомой вероятности 0,16 > 0,01.Следовательно, данные наблюдений согласуются с гипотезой о нормально распределении генеральной совокупности.
Используя линейную интерполяцию, получаем приближённое значение искомой вероятности 0,16 > 0,01.Следовательно, данные наблюдений согласуются с гипотезой о нормально распределении генеральной совокупности.
Понятие о статистике
«Статистика знает все», — утверждали И. Ильф и Е. Петров в своем знаменитом романе «Двенадцать стульев» и продолжали: «Известно, сколько какой пищи съедает в год средний гражданин республики... Известно, сколько в стране охотников, балерин, станков, собак всех пород, велосипедов, памятников, девушек, маяков и швейных машинок... Как много жизни, полной пыла, страстей и мысли, глядит на нас из статистических таблиц!»
Это ироничное описание дает достаточно точное представление о статистике (от латинского status — состояние) — науке, изучающей, обрабатывающей и анализирующей количественные данные о разнообразнейших массовых явлениях в жизни.
Экономическая статистика изучает изменение цен, спроса и предложения товаров, прогнозирует рост и падение производства и потребления. Медицинская статистика изучает эффективность разных лекарств и методов лечения, вероятность возникновения некоторых заболеваний в зависимости от возраста, пола, наследственности, условий жизни, вредных привычек, прогнозирует распространение эпидемий. Демографическая статистика изучает рождаемость, численность населения, его состав (возрастной, национальный, профессиональный). А есть еще статистика финансовая, налоговая, биологическая, метеорологическая...
Статистика имеет многовековую историю. Уже в Древнем мире вели статистический учет населения. Однако случайное толкование статистических данных, отсутствие строгой научной базы статистических прогнозов даже в середине XIX в. еще не позволяли говорить о статистике как науке. Только в XX в. появилась математическая статистика — наука, опирающаяся на законы теории вероятностей. Выяснилось, что статистические методы обработки данных из самых разных областей жизни имеют много общего. Это позволило создать универсальные научно обоснованные методы статистических исследований и проверки статистических гипотез.
Таким образом, математическая статистика — это раздел математики, изучающий математические методы обработки и использования статистических данных для научных и практических выводов.
В математической статистике рассматриваются методы, которые дают возможность по результатам экспериментов (статистическим данным) делать определенные выводы вероятностного характера.
Основные задачи математической статистики
Среди основных задач математической статистики можно отметить следующие:
- Оценка вероятности. Пусть некоторое случайное событие имеет вероятность р > 0, но ее значение нам неизвестно. Требуется оценить эту вероятность по результатам экспериментов, то есть решить задачу об оценке вероятности через частоту.
- Оценка закона распределения. Исследуется некоторая случайная величина, точное выражение для закона распределения которой нам неизвестно. Необходимо по результатам экспериментов найти приближенное выражение для функции, задающей закон распределения.
- Оценка числовых характеристик случайной величины (математического ожидания, дисперсии — см. п. 20.2 и 20.3).
- Проверка статистических гипотез (предположений). Исследуется некоторая случайная величина. Исходя из определенных рассуждений, выдвигается, например, гипотеза, что распределение этой случайной величины близко к нормальному (см. п. 20.4). Необходимо по результатам экспериментов принять или отклонить эту гипотезу. Результаты исследований, проводимых методами математической статистики, применяются для принятия решений. В частности, при планировании и организации производства, при контроле качества продукции, при выборе оптимального времени наладки или замены действующей аппаратуры (например, при определении времени замены двигателя самолета, отдельных частей станков и т. д.).
Как и в каждой науке, в статистике используются свои специфические термины и понятия. Некоторые из них приведены в таблице 33 на с. 318. Запоминать их определения необязательно, достаточно понимать их смысл.
Генеральная совокупность и выборка
Для изучения различных массовых явлений проводятся специальные статистические исследования. Любое статистическое исследование начинается с целенаправленного сбора информации об изучаемом явлении или процессе. Этот этап называют этапом статистических наблюдений. Для получения статистических данных в результате наблюдений похожие элементы некоторой совокупности сравнивают по разным признакам. Как мы уже видели в задачах предыдущего параграфа, учащихся 11 классов можно сравнивать, например, по росту, размеру одежды, успеваимости и т. д. Болты можно сравнивать по длине, диаметру, массе, материалу и т. д. Практически любой признак или непосредственно измеряется, или может получить условную числовую характеристику. Таким образом, некоторый признак элементов совокупности можно рассматривать как случайную величину, принимающую те или иные числовые значения.
| Часто употребляемый термин | Смысл термина | Научный термин | Определение |
| Общий ряд данных | То, откуда выбирают | Генеральная совокупность | Множество всех возможных результатов наблюдения (измерения) |
| Выборка | То, что выбирают |
Статистическая выборка, статистический ряд |
Множество результатов, реально полученных в данном наблюдении (измерении) |
| Варианта | Значение одного из результатов наблюдения (измерения) | Варианта | Одно из значений элементов выборки |
| Ряд данных | Значения всех результатов наблюдения (измерения) | Вариационный ряд | Упорядоченное множество всех вариант |
При изучении реальных явлений часто бывает невозможно обследовать все элементы совокупности. Например, практически невозможно выяснить размеры обуви у всех людей планеты. А проверить, например, наличие листов некачественной фотобумаги в большой партии хотя и реально, но бессмысленно, потому что полная проверка приведет к уничтожению всей партии бумаги. В подобных случаях вместо изучения всех элементов совокупности, называемой генеральной совокупностью, обследуют ее значительную часть, выбранную случайным образом. Эту часть называют выборкой.
Если в выборке присутствуют все значения случайной величины в тех же пропорциях, что и в генеральной совокупности, то эту выборку называют репрезентативной (от французского representatif— показательный).
Например, если менеджер швейной фабрики большого города хочет выяснить, в каком количестве необходимо сшить одежду тех или иных размеров, он должен составить репрезентативную выборку людей этого города. Объем ее может быть и не очень большим (например, 1000 человек), но в такую выборку нельзя, например, брать только детей детского сада или только рабочих одного завода. Очевидно, микромоделью города может служить совокупность жителей многоквартирного дома (или нескольких домов), в котором приблизительно в тех же пропорциях, что и в самом городе, проживают люди разного возраста и разных комплекций.
Пусть S — объем генеральной совокупности, 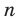 — объем репрезентативной выборки, в которой
— объем репрезентативной выборки, в которой  значений исследуемых признаков распределены по частотам
значений исследуемых признаков распределены по частотам  Тогда в генеральной совокупности частотам
Тогда в генеральной совокупности частотам 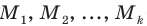 будут соответствовать частоты
будут соответствовать частоты 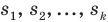 тех же значений признака, что и в выборке
тех же значений признака, что и в выборке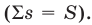 По определению репрезентативной выборки получаем:
По определению репрезентативной выборки получаем: 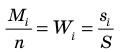 где
где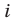 — порядковый номер значения признака
— порядковый номер значения признака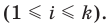 Из этого соотношения находим
Из этого соотношения находим 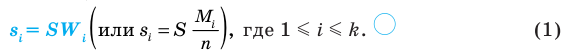
Пример №18
Обувной цех должен выпустить 1000 пар кроссовок молодежного фасона. Для определения того, сколько кроссовок и какого размера необходимо выпустить, были выявлены размеры обуви у 50 случайным образом выбранных подростков. Распределение размеров обуви по частотам представлено в таблице:
- Размер (X) 36 37 38 39 40 41 42 43 44
- Частота (М) 2 5 6 12 11 7 4 2 1
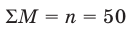
Сколько кроссовок разного размера будет изготавливать фабрика?
Решение:
Будем считать рассмотренную выборку объемом 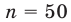 подростков репрезентативной. Тогда в генеральной совокупности (объемом S = 1000) количество кроссовок каждого размера пропорционально количеству кроссовок соответствующего размера в выборке (и для каждого размера находится по формуле (1)). Результаты расчетов будем записывать в таблицу:
подростков репрезентативной. Тогда в генеральной совокупности (объемом S = 1000) количество кроссовок каждого размера пропорционально количеству кроссовок соответствующего размера в выборке (и для каждого размера находится по формуле (1)). Результаты расчетов будем записывать в таблицу: 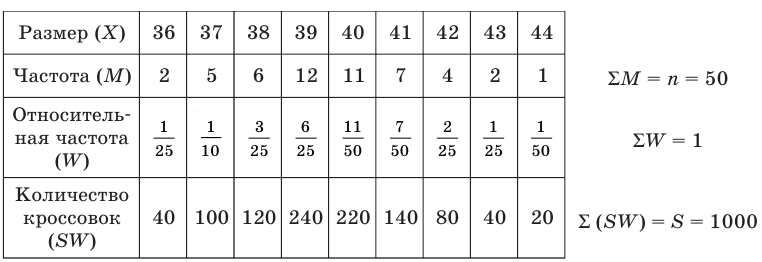
Ответ. 
В промышленности и сельском хозяйстве для определения количественного соотношения изделий разного сорта пользуются так называемым выборочным методом. Суть этого метода будет ясна из описания следующего опыта, теоретическую основу которого составляет закон больших чисел.
В коробке тщательно перемешан горох двух сортов: зеленый и желтый. Небольшой емкостью, например ложкой, вынимают из разных мест коробки порции гороха. В каждой порции подсчитывают число желтых горошин М и число всех горошин  Для каждой порции находят относительную частоту появления желтой горошины
Для каждой порции находят относительную частоту появления желтой горошины  Так делают
Так делают  раз (на практике обычно берут
раз (на практике обычно берут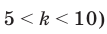 и каждый раз вычисляют относительную частоту. В качестве статистической вероятности извлечения желтой горошины из коробки принимают среднее арифметическое полученных относительных частот
и каждый раз вычисляют относительную частоту. В качестве статистической вероятности извлечения желтой горошины из коробки принимают среднее арифметическое полученных относительных частот 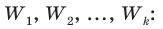
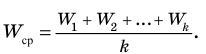
Статистические характеристики рядов данных. Математическое ожидание случайной величины
Ранжирование ряда данных
Определение:
Под ранжированием ряда данных понимают расположение элементов этого ряда в порядке возрастания (имеется в виду, что каждое следующее число или больше, или не меньше предыдущего).
Пример:
Если ряд данных выборки имеет вид 5, 3, 7, 4, 6, 4, 6, 9, 4, то после ранжирования он превращается в ряд 3,4,4,4,5,6,6,7,9. (*)
Размах выборки 
Размах выборки — это разность между наибольшим и наименьшим значениями случайной величины в выборке.
Для ряда (*) размах выборки: R= 9-3 = 6.
Мода
Мода — это значение случайной величины, встречающееся чаще остальных.
В ряду (*) значение 4 встречается чаще всего, итак, Мо = 4.
Медиана (Me)
Медиана — это так называемое серединное значение упорядоченного ряда значений случайной величины:
- — если количество чисел в ряду нечетное, то медиана — это число, записанное посередине;
- — если количество чисел в ряду четное, то медиана — это среднее арифметическое двух чисел, стоящих посередине.
Для ряда (*), в котором 9 членов, медиана — это среднее (то есть пятое) число 5: Ме = 5.
Если рассмотреть ряд 3,3,4,4,4,5,6,6,7,9, в котором 10 членов, то медиана — это среднее арифметическое пятого и шестого членов: 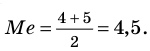
Среднее значение случайной величины X
случайной величины X
Средним значением случайной величины X называется среднее арифметическое всех ее значений. Если случайная величина X принимает  значений
значений 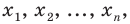 то
то 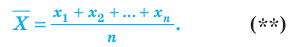
Если случайная величина X принимает значения 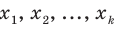 соответственно с частотами
соответственно с частотами 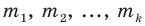 (тогда
(тогда  то среднее арифметическое можно вычислить по формуле
то среднее арифметическое можно вычислить по формуле 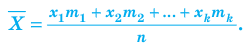 Пусть случайная величина X задана таблицей распределения по частотам М:
Пусть случайная величина X задана таблицей распределения по частотам М: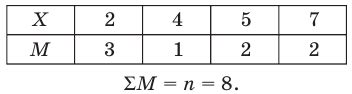
Тогда по формуле (**)
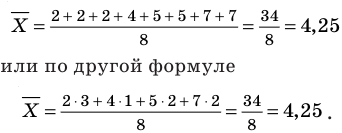
Математическое ожидание (MX) случайной величины X
Пусть случайная величина X принимает значения 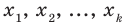 соответственно с вероятностями
соответственно с вероятностями 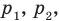
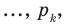 то есть имеет закон распределения:
то есть имеет закон распределения:
Сумма произведений всех значений случайной величины на соответствующие вероятности называется математическим ожиданием величины X:
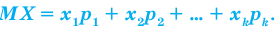 Пусть закон распределения случайной величины X задан таблицей:
Пусть закон распределения случайной величины X задан таблицей: 
Математическое ожидание показывает, какое среднее значение случайной величины X можно ожидать в результате эксперимента (при значительном количестве повторений эксперимента).
Объяснение и обоснование:
Размах, мода и медиана ряда данных
Иногда выборку случайных величин или всю генеральную совокупность этих величин приходится характеризовать одним числом. На практике это необходимо, например, для быстрого сравнения двух или больше совокупностей по общему признаку. Рассмотрим конкретный пример.
Пусть после летних каникул провели опрос 10 девочек и 9 мальчиков одного класса о количестве книг, прочитанных ими за каникулы. Результаты были записаны в порядке опроса. Получили следующие ряды чисел:
- для девочек: 4, 3, 5, 3, 8, 3, 12, 4, 5, 5;
- для мальчиков: 5, 3, 3, 4, 6, 4, 4, 7, 4.
Чтобы удобнее было анализировать информацию, в подобных случаях числовые данные ранжируют, располагая их в порядке возрастания (когда каждое следующее число или больше, или не меньше предыдущего). В результате ранжирования получили следующие ряды.
- Для девочек:
- 3,3,3,4,4,5,5,5,8,12; (1)
- для мальчиков:
- 3,3,4,4,4,4,5,6,7. (2)
Тогда распределение по частотам М случайных величин: X — число книг, прочитанных за каникулы девочками, и  — число книг, прочитанных за каникулы мальчиками, можно задать таблицами:
— число книг, прочитанных за каникулы мальчиками, можно задать таблицами:

Эти распределения можно также проиллюстрировать графически с помощью полигона частот (рис. 159, а, б).
Для сравнения рядов (1) и (2) (то есть рядов значений случайных величин  используют различные характеристики. Приведем некоторые из них.
используют различные характеристики. Приведем некоторые из них.
Размахом ряда чисел (обозначается  называют разность между наибольшим и наименьшим из этих чисел. Поскольку мы анализируем выборку случайных величин, то размах выборки — это разность между наибольшим и наименьшим значениями случайной величины в выборке.
называют разность между наибольшим и наименьшим из этих чисел. Поскольку мы анализируем выборку случайных величин, то размах выборки — это разность между наибольшим и наименьшим значениями случайной величины в выборке.
Для ряда (1) размах R = 12 - 3 = 9, а для ряда (2) размах R = 7-3 = 4. На графике размах — это длина области определения полигона частот (рис. 161).
Важной статистической характеристикой ряда данных является его мода (обозначается 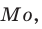 от латинского слова modus — мера, правило).
от латинского слова modus — мера, правило).
Мода — это значение случайной величины, встречающееся чаще остальных.
Так, в ряду (1) две моды — числа 3 и 5:  а в ряду (2) одна мода — число 4:
а в ряду (2) одна мода — число 4: 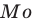 = 4. На графике мода — это значение абциссы точки, в которой достигается максимум полигона частот (см. рис. 159). Отметим, что моды может и не быть, если все значения случайной величины встречаются одинаково часто.
= 4. На графике мода — это значение абциссы точки, в которой достигается максимум полигона частот (см. рис. 159). Отметим, что моды может и не быть, если все значения случайной величины встречаются одинаково часто.
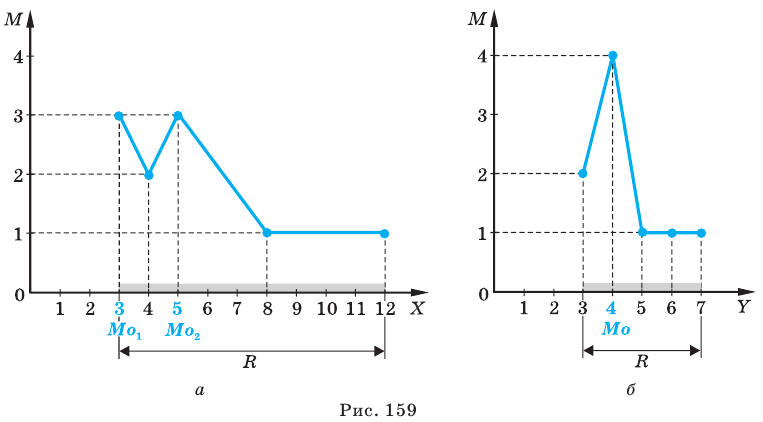
Моду ряда данных обычно находят тогда, когда хотят выяснить некоторый типовой показатель. Например, когда изучают данные о моделях мужских рубашек, проданных в определенный день в универмаге, то удобно использовать такой показатель, как мода, который характеризует модель, пользующуюся наибольшим спросом (собственно, этим и объясняется название «мода»).
Еще одной важной статистической характеристикой ряда данных является его медиана.
Медиана — это так называемое серединное значение упорядоченного ряда значений случайной величины (обозначается Me).
Медиана делит упорядоченный ряд данных на две равные по количеству элементов части.
Если количество чисел в ряду нечетное, то медиана — это число, записанное посередине.
Например, в ряду (2) нечетное количество элементов Тогда его медианой является число, стоящее посередине, то есть на пятом месте: Me = 4.
Тогда его медианой является число, стоящее посередине, то есть на пятом месте: Me = 4.

Следовательно, о мальчиках можно сказать, что одна половина из них прочитала не больше 4 книг, а вторая — не меньше 4 книг. (Отметим, что в случае нечетного  номер среднего члена ряда равен
номер среднего члена ряда равен 
Если количество чисел в ряду четное, то медиана — это среднее арифметическое двух чисел, стоящих посередине.
Например, в ряду (1) четное количество элементов 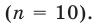 Тогда его медианой является число, равное среднему арифметическому чисел, стоящих посередине, то есть на пятом и шестом местах:
Тогда его медианой является число, равное среднему арифметическому чисел, стоящих посередине, то есть на пятом и шестом местах: 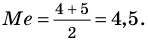
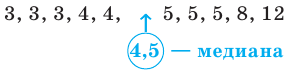
Следовательно, о девочках можно сказать, что одна половина из них прочитала меньше 4,5 книг, а вторая — больше 4,5 книг. (Отметим, что в случае четного  номера средних членов ряда равны
номера средних членов ряда равны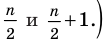
Среднее значение случайной величины и ее математическое ожидание
Средним значением случайной величины X (обозначается 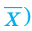 называется среднее арифметическое всех ее значений.
называется среднее арифметическое всех ее значений.
Если случайная величина X принимает 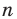 значений
значений 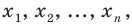 то
то
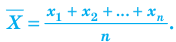
Если случайная величина X принимает значения  соответственно с частотами
соответственно с частотами 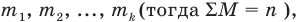 то, заменяя одинаковые слагаемые в числителе на соответствующие произведения, получаем, что среднее арифметическое можно вычислять по формуле
то, заменяя одинаковые слагаемые в числителе на соответствующие произведения, получаем, что среднее арифметическое можно вычислять по формуле 
Последнюю формулу удобно использовать в тех случаях, когда распределение случайной величины по частотам задано в виде таблицы. Напомним, что распределение по частотам М случайных величин: X — число книг, прочитанных за каникулы девочками, и  — число книг, прочитанных за каникулы мальчиками, было задано такими таблицами:
— число книг, прочитанных за каникулы мальчиками, было задано такими таблицами:
Тогда средние значения заданных случайных величин равны:

Поскольку 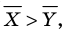 то можно сказать, что за один и тот же промежуток времени девочки в классе читают книг больше, чем мальчики.
то можно сказать, что за один и тот же промежуток времени девочки в классе читают книг больше, чем мальчики.
Если в правой части формулы (3) почленно разделить каждое слагаемое в числителе на знаменатель, то получим следующую формулу: 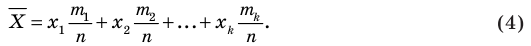
Напомним, что отношение 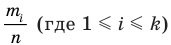 является относительной частотой случайного события — случайная величина X приняла значение
является относительной частотой случайного события — случайная величина X приняла значение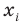 (мы обозначали это событие так:
(мы обозначали это событие так: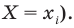 Если считать проведенные случайные эксперименты статистически стойкими, то при значительным количестве экспериментов значения относительных частот близки к соответствующим вероятностям. Обозначим вероятность события — случайная величина X приняла значение
Если считать проведенные случайные эксперименты статистически стойкими, то при значительным количестве экспериментов значения относительных частот близки к соответствующим вероятностям. Обозначим вероятность события — случайная величина X приняла значение 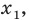 то есть Р (X =
то есть Р (X = 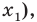 через
через 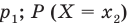 -через
-через 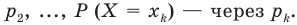 Тогда правая часть равенства (4) приобретет вид
Тогда правая часть равенства (4) приобретет вид 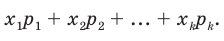
Полученное выражение называется математическим ожиданием случайной величины X и обозначается MX (или М (X)). Сформулируем соответствующее определение для дискретной случайной величины.
Пусть случайная величина X принимает значения 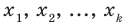 соответственно с вероятностями
соответственно с вероятностями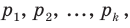 то есть имеет закон распределения:
то есть имеет закон распределения:
Сумма произведений всех значений случайной величины на соответствующие вероятности называется математическим ожиданием величины
X: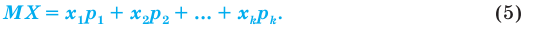
Математическое ожидание показывает, на какое среднее значение случайной величины X можно надеяться в результате эксперимента (при значительном количестве повторений эксперимента). С помощью математического ожидания можно сравнивать случайные величины, заданные законами распределения.
Например, пусть количества очков, выбиваемых при одном выстреле каждым из двух ловких стрелков, имеют следующие законы распределения:
Чтобы выяснить, какой из стрелков стреляет более метко, находят математическое ожидание для каждой случайной величины: 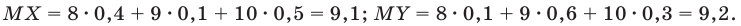
Следовательно, среднее количество очков, выбиваемое при одном выстреле, у второго стрелка несколько больше, чем у первого. Это дает основание сделать вывод о том, что второй стрелок стреляет немного лучше, чем первый.
Согласно закону больших чисел при значительном количестве экспериментов значения относительных частот близки к соответствующим вероятностям. Отсюда можно сделать вывод, что выражение 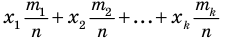
будет приближаться к выражению 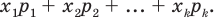 Но по формуле (4) первое из этих выражений является средним (то есть средним арифметическим) значением случайной величины X, а второе (по формуле (5)) — математическим ожиданием этой величины.
Но по формуле (4) первое из этих выражений является средним (то есть средним арифметическим) значением случайной величины X, а второе (по формуле (5)) — математическим ожиданием этой величины.
Таким образом, при значительном количестве экспериментов среднее арифметическое всех значений случайной величины приближается к ее математическому ожиданию.
Обратим внимание, что в пособиях по статистике моду, медиану и среднее значение объединяют одним термином — меры центральной тенденции, подчеркивая тем самым возможность охарактеризовать ряд выборки одним числом, к которому стремятся все ее значения.
Не для каждого ряда данных имеет смысл формально находить центральные тенденции. Например, если исследуется ряд
годовых доходов четырех людей (в тыс. руб.), то очевидно, что ни мода (5), ни медиана (6,5), ни среднее значение (32) не могут выступать в роли единой характеристики всех значений ряда данных. Это объясняется тем, что размах ряда (105) является соизмеримым с наибольшим из его значений.
В данном случае можно искать центральные тенденции, например, для части ряда (5): 5, 5, 8, условно назвав его выборкой годового дохода низкооплачиваемой части населения.
Если в выборке среднее значение существенно отличается от моды, то его нецелесообразно выбирать в качестве типичной характеристики рассматриваемой совокупности данных (чем больше значение моды отличается от среднего значения, тем «более несимметричным» является полигон частот совокупности).
Отклонение от среднего значения, дисперсия, среднее квадратическое отклонение
Отклонение от среднего значения
Определение: Отклонением от среднего значения называют разность между рассматриваемым значением случайной величины и средним значением всей совокупности ряда данных (для случайной величины X отклонение от среднего — это Х-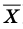 )
)
Пример:
Пусть случайная величина X задана таблицей распределения по частотам М:
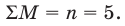 Тогда получаем
Тогда получаем 
Дисперсия (D)
Дисперсией называется среднее арифметическое суммы квадратов всех отклонений от среднего заданных п значений случайной величины 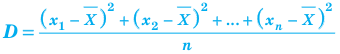
Для рассматриваемой случайной величины X: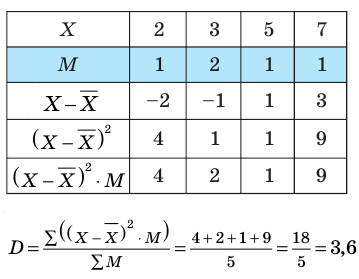
Среднее квадратическое отклонение ( — «сигма»)
— «сигма»)
Средним квадратическим отклонением называется квадратный корень из дисперсии 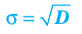
Для рассматриваемой случайной величины X: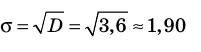
Объяснение и обоснование:
Отклонение от среднего значения и дисперсия
В предыдущем пункте было рассмотрено сравнение совокупностей значений случайных величин с помощью центральных тенденций (моды, медианы, среднего значения). Но бывают ситуации, когда такое сравнение выполнить невозможно.
Например, пусть на одно место токаря претендуют двое рабочих. Для каждого из них установили испытательный срок, в течение которого они должны были изготавливать одинаковые детали. Результаты их работы представлены в таблице: Количество деталей, изготовленных за день
|
День недели |
первым рабочим (X) | вторым рабочим (У) |
| Понедельник | 52 | 61 |
| Вторник | 54 | 40 |
| Среда | 50 | 50 |
|
Четверг |
48 | 55 |
| Пятница | 46 | 44 |
Каждый из рабочих за 5 дней изготовил 250 деталей, следовательно, средняя производительность труда за день обоих рабочих одинакова:
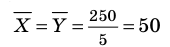 (дет./день).
(дет./день).
Моды у предложенных совокупностей отсутствуют, а медианы одинаковы (50 и 50).
Возникает вопрос: «Кого из этих рабочих взять на работу?» В данном случае как критерий сравнения совокупностей результатов их работы может выступать стабильность производительности труда рабочего. Ее можно оценить с помощью отклонений от среднего значения элементов совокупности.
Отклонением от среднего называют разность между рассматриваемым значением случайной величины и средним значением всей совокупности ряда данных (для случайной величины X отклонение от среднего — это 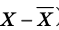 ).
).
Например, если значение величины 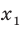 = 52, а среднее значение
= 52, а среднее значение 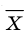 =50, то отклонение
=50, то отклонение 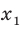 , от среднего будет равняться -
, от среднего будет равняться - 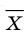 = 52 -50 = 2.
= 52 -50 = 2.
Очевидно, что отклонение от среднего может быть как положительным, так и отрицательным числом. Нетрудно показать, что сумма отклонений всех значений совокупности от среднего значения равна нулю (см., например, сумму отклонений в таблице, приведенной ниже). Поэтому характеристикой стабильности элементов совокупности может служить сумма квадратов отклонений от среднего.
Найдем соответствующие значения для количества деталей, изготовленных за день каждым рабочим и запишем их в таблицу:
Как видим, у второго рабочего сумма квадратов отклонений от среднего больше, чем у первого рабочего 
На практике это означает, что второй рабочий имеет нестабильную производительность труда: в какие-то дни работает не в полную силу, а в какие-то наверстывает упущенное, что всегда сказывается на качестве продукции. Очевидно, что работодатель захочет взять на место токаря первого рабочего (у которого сумма квадратов отклонений от средней производительности труда меньше).
Если бы рабочие работали разное количество дней и изготовили в среднем одинаковое число деталей, то стабильность работы каждого из них можно было бы оценить по величине среднего арифметического суммы квадратов отклонений. Эта величина называется дисперсией (от латинского слова dispersio — рассеяние) и обозначается буквой D.
Таким образом, дисперсией называется среднее арифметическое суммы квадратов всех отклонений от среднего заданных п значений случайной величины.
Для случайной величины X, принимающей  разных значений
разных значений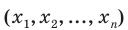 и имеющей среднее значение
и имеющей среднее значение 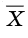 , дисперсия находится по формуле
, дисперсия находится по формуле
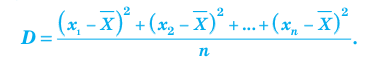
Пример №19
Два токаря вытачивали одинаковые детали, причем первый работал полную рабочую неделю, а второй — 4 дня. Сведения о количестве деталей, которые они изготавливали за каждый рабочий день, приведены в таблице:
Количество деталей, изготовленных за день
|
День недели |
первым токарем (X) | вторым токарем (У) |
| Понедельник | 53 | 52 |
| Вторник | 54 | 46 |
| Среда | 49 | 53 |
| Четверг | 48 | 49 |
| Пятница | 46 |
Сравните стабильность работы токарей, используя дисперсию совокупности значений соответствующей случайной величины.
Решение:
Найдем средние значения величин X и У:
Очевидно, что 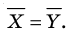
Вычислим сумму квадратов отклонений от средних значений величин X и У, последовательно записывая результаты в таблицу: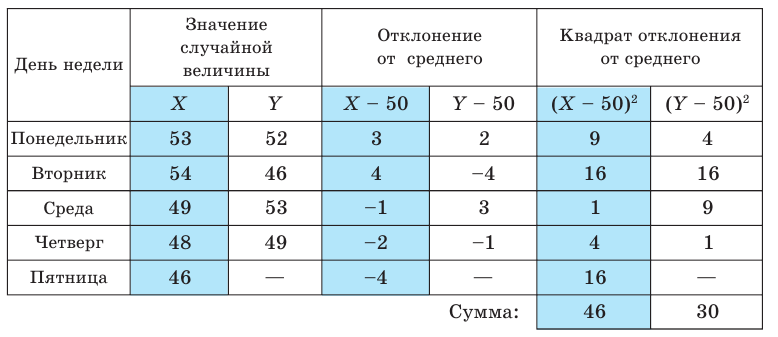
Найдем значения дисперсии:
Как видим,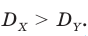 Следовательно, второй токарь работает более стабильно, чем первый.
Следовательно, второй токарь работает более стабильно, чем первый. 
Обратим внимание, что в том случае, когда значения 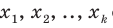 случайной величины X повторяются с частотами
случайной величины X повторяются с частотами 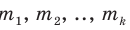 соответственно, то дисперсию случайной величины X можно вычислить по формуле
соответственно, то дисперсию случайной величины X можно вычислить по формуле
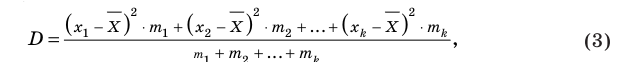
где 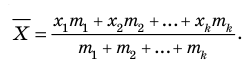
Пример №20
Случайная величина X имеет распределение по частотам М, приведенное в таблице: Найдите ее дисперсию.
Найдите ее дисперсию.
Решение:
Среднее значение случайной величины X равно:
По формуле (3) находим дисперсию: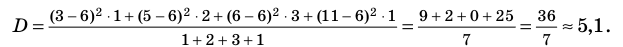
Ответ.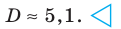
Среднее квадратическое отклонение
Пусть величина X имеет некоторую размерность (например, сантиметры). Тогда ее среднее значение X и отклонение от среднего X - 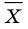 имеют ту же размерность, что и сама величина (сантиметры). Квадрат же отклонения
имеют ту же размерность, что и сама величина (сантиметры). Квадрат же отклонения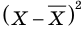 и дисперсия D имеют размерности квадрата этой величины (то есть квадратные сантиметры).
и дисперсия D имеют размерности квадрата этой величины (то есть квадратные сантиметры).
Для оценки степени отклонения от среднего значения удобно иметь дело с величиной той же размерности, что и величина X. С этой целью используют значение квадратного корня из дисперсии 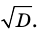
Квадратный корень из дисперсии называют средним квадратическим отклонением и обозначают а (греческая буква «сигма»):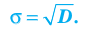
Замечание. Дисперсию и среднее квадратическое отклонение называют в статистике мерами рассеяния значений случайной величины вокруг среднего значения.
Пример №21
Распределение по частотам величины X — числа забитых голов десятью игроками футбольной команды за период соревнований — показано в таблице. Найти среднее квадратическое отклонение от среднего числа забитых голов.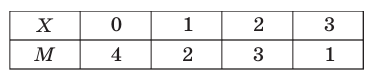
Решение:
Результаты последовательных расчетов будем заносить в таблицу: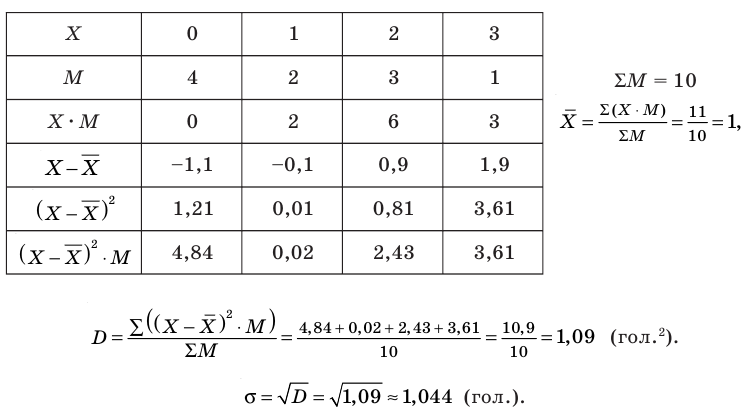
Ответ: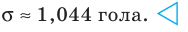
Нормальное распределение. Правило трех сигм
Рассмотрим несколько примеров распределения случайных величин. Значения размеров одежды (X) и обуви (У) тысячи выбранных случайным образом одиннадцатиклассниц школ города и распределение их по частотам представлены в таблицах:
Полигоны частот заданных совокупностей изображены на рисунке 162.
Оказывается, что многие признаки разных явлений природы и техники (рост, масса живых организмов одного вида, результаты измерения характеристик однотипных технических изделий, дальность полета снаряда при стрельбе по цели из одной и той же пушки и др.) имеют подобные с представленными на рисунке 160 распределения своих числовых значений по частотам. Эти распределения называют нормальными распределениями.
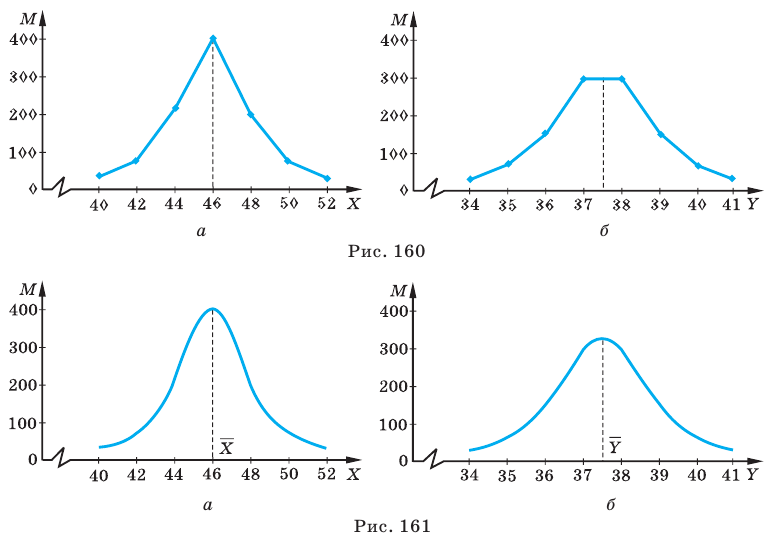
Проведем через точки, отмеченные на рисунке 160, плавные кривые (рис. 161). Эти кривые называют кривыми нормального распределения. Отметим, что кривые нормального распределения симметричны относительно вертикальных прямых, проходящих через средние значения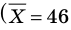
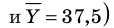 рассмотренных совокупностей.
рассмотренных совокупностей.
Подобно тому, как графики всех парабол можно получить с помощью геометрических преобразований одной параболы 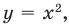 так и все кривые нормальных распределений можно получить с помощью геометрических преобразований одной кривой. Эту кривую называют кривой нормального распределения, или гауссовой кривой, названной в честь немецкого математика Карла Гаусса (рис. 162).
так и все кривые нормальных распределений можно получить с помощью геометрических преобразований одной кривой. Эту кривую называют кривой нормального распределения, или гауссовой кривой, названной в честь немецкого математика Карла Гаусса (рис. 162).
Эта бесконечная «колоколоподобная» кривая симметрична относительно оси ординат и имеет единственный максимум. Площадь части плоскости, ограниченной гауссовой кривой и осью Ох, равна единице. Ее «ветви» очень быстро приближаются к оси абсцисс: площадь криволинейной трапеции, ограниченной гауссовой кривой, осью Ох и прямыми х = -3 и х = 3 больше 0,99 всей площади, то есть больше 99 % .
Функцию, заданную гауссовой кривой, обозначают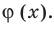 Аналитически она задается достаточно сложной формулой:
Аналитически она задается достаточно сложной формулой:
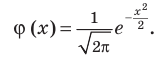
Но для практических расчетов эта формула не очень нужна. Для значений этой функции составлены подробные числовые таблицы.
Примером реального получения кривой нормального распределения может служить результат опыта, проведенного английским ученым Ф. Гальтоном (1822-1911). Для проведения этого опыта в доску забивают в «шахматном порядке» гвозди (рис. 163). Доска устанавливается с небольшим наклоном к горизонтальной поверхности. В верхней части доски делается конусное отверстие, через которое пропускаются одинаковые шары. Расстояние между соседними гвоздями везде одинаково и немного больше диаметра шаров.
Пройдя через отверстие, шар отталкивается от первого верхнего гвоздя и случайным образом огибает его или слева, или справа. Аналогично шар проходит каждый из нижних гвоздей, встречающихся на его пути (с вероятностью, близкой 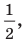 огибает его или слева, или справа). Пройдя все ряды гвоздей, шар попадает в один из вертикальных пеналов-накопителей.
огибает его или слева, или справа). Пройдя все ряды гвоздей, шар попадает в один из вертикальных пеналов-накопителей.
Если число рядов гвоздей значительно увеличить и запустить много шаров, можно заметить, что кривая, огибающая верхний ряд шаров в пеналах, имеет вертикальную ось симметрии и напоминает кривую нормального распределения.
В курсе теории вероятностей доказывается, что 68 % (или приблизительно 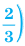 всех значений нормально распределенной случайной величины X имеют отклонения от среднего значения, по абсолютной величине не превышающие среднее квадратическое отклонение
всех значений нормально распределенной случайной величины X имеют отклонения от среднего значения, по абсолютной величине не превышающие среднее квадратическое отклонение  всех значений — не превышающие
всех значений — не превышающие 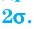 Также доказывается, что почти все значения (точнее, 99,7 % всех значений) имеют отклонения от среднего, не превышающие по абсолютной величине утроенное среднее квадратическое отклонение
Также доказывается, что почти все значения (точнее, 99,7 % всех значений) имеют отклонения от среднего, не превышающие по абсолютной величине утроенное среднее квадратическое отклонение
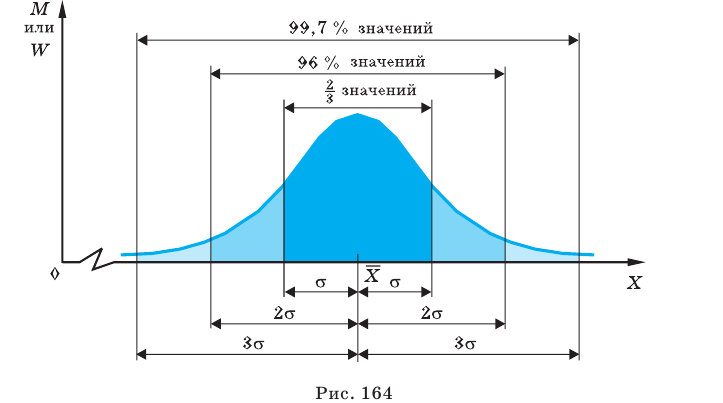
Эту закономерность часто называют правилом трех сигм (рис. 164). Известно, что результаты измерений в массовом производстве (длина, масса конкретных видов продукции) — непрерывные случайные величины, имеющие нормальное распределение.
Например, измерения диаметров  партии труб (объем партии равен
партии труб (объем партии равен  ), изготовленных трубопрокатным заводом, показали, что размеры диаметров находятся в промежутке от 149,7 мм до 150,3 мм. Это означает, что среднее значение их совокупности
), изготовленных трубопрокатным заводом, показали, что размеры диаметров находятся в промежутке от 149,7 мм до 150,3 мм. Это означает, что среднее значение их совокупности
Размеры диаметров труб распределены нормально со средним квадратическим отклонением от среднего значения 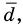 , равным
, равным 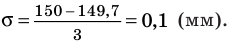
Это проиллюстрировано на рисунке 165.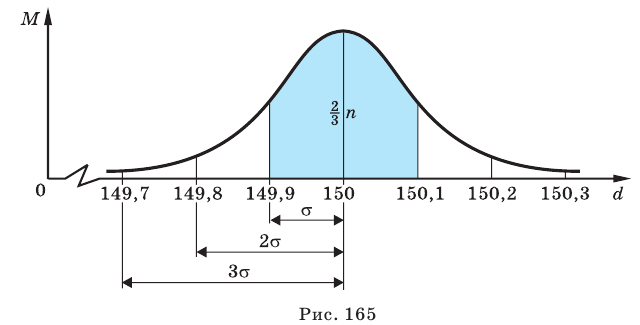
Из приведенных рассуждений можно сделать вывод, что приблизительно 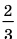 всех труб имеют диаметры от 149,9 мм до 150,1 мм, а значительная их часть (96 %) имеют диаметры от 149,8 мм до 150,2 мм.
всех труб имеют диаметры от 149,9 мм до 150,1 мм, а значительная их часть (96 %) имеют диаметры от 149,8 мм до 150,2 мм.
Пример №22
В некоторых международных играх по разным видам спорта должны принимать участие 600 спортсменов. Известно, что размеры одежды (V) участников игр варьируются от 40-го (у гимнасток) до 62-го (у тяжелоатлетов). Оргкомитет игр решил подарить всем участникам майки с эмблемой игр. Швейной фабрике был сделан заказ на пошив маек свободного покроя трех условных размеров: I, II, III. Какие стандартные размеры (от 40-го до 62-го) целесообразно объединить в условные размеры I, II и III и сколько маек каждого из этих трех размеров необходимо сшить?
Решение:
Полагая, что размеры одежды (V) спортсменов имеют нормальное распределение, найдем среднее значение совокупности размеров 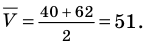
Согласно правилу трех сигм считаем, что практически вся совокупность маек от 40-го до 62-го размера попадает в интервал длиной 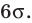 При этом в центральную часть распределения (рис. 166) попадают размеры 48, 50, 52, 54, им целесообразно присвоить условный размер II.
При этом в центральную часть распределения (рис. 166) попадают размеры 48, 50, 52, 54, им целесообразно присвоить условный размер II.
На эти размеры во всей совокупности будет приходиться приблизительно 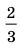 маек, то есть
маек, то есть 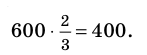
В I условный размер войдут 40, 42, 44 и 46-й размеры; в III — 56, 58, 60 и 62-й размеры. Вследствие симметричности кривой нормального распределения относительно вертикальной прямой, проходящей через среднее значение, на I и III условные размеры маек приходится поровну: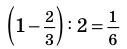 от всей совокупности маек, то есть по
от всей совокупности маек, то есть по 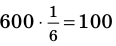 маек.
маек.
Ответ. I (размеры 40-46) — 100 маек; II (размеры 48-54) — 400 маек; III (размеры 56-62) — 100 маек. 
Соединения с повторениями
Размещения с повторениями:
Размещением с повторениями из  элементов по
элементов по называется конечная последовательность, состоящая из
называется конечная последовательность, состоящая из  элементов
элементов  некоторого re-элементного множества М
некоторого re-элементного множества М
Формула числа размещений с повторениями:
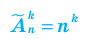
Пример:
Количество различных трехзначных чисел, которые можно составить из цифр 1, 2, 3, 4, 5, 6, если цифры могут повторяться, равно 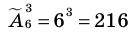 Перестановки с повторениями
Перестановки с повторениями
Перестановкой с повторениями состава 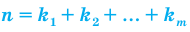 из элементов
из элементов  некоторого множества М называется любая конечная последовательность, состоящая из элементов, в которую элемент
некоторого множества М называется любая конечная последовательность, состоящая из элементов, в которую элемент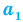 входит
входит 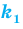 раз, элемент
раз, элемент 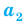 входит
входит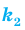 раз,..., элемент
раз,..., элемент 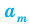 входит
входит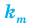 раз Формула числа перестановок с повторениями
раз Формула числа перестановок с повторениями 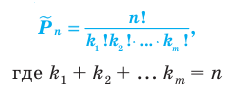
Пример:
Количество различных шестизначных чисел, которые можно составить из трех двоек, двух семерок и одной пятерки, равно 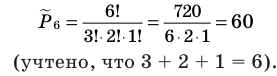
Сочетания с повторениями:
Если задано  -элементное множество, то сочетаниями с повторениями из
-элементное множество, то сочетаниями с повторениями из  элементов по
элементов по  называются наборы, в каждый из которых входят заданных элементов (не обязательно разных), отличающихся только составом элементов (хотя бы одним элементом).
называются наборы, в каждый из которых входят заданных элементов (не обязательно разных), отличающихся только составом элементов (хотя бы одним элементом).
Формула числа сочетаний с повторениями 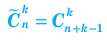
Пример:
Если в продаже есть цветы четырех сортов, то количество разных букетов, составленных из 7 цветов, равно 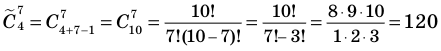
Схема решения комбинаторных задач
Выбор правила
Правило суммы:
Если элемент А можно выбрать 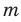 способами, а элемент В —
способами, а элемент В — 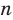 способами, то А или В можно выбрать
способами, то А или В можно выбрать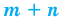 способами.
способами.
Правило произведения
Если элемент А можно выбрать способами, а после этого элемент В —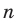 способами, то А и В можно выбрать
способами, то А и В можно выбрать  способами. Выбор формулы
способами. Выбор формулы
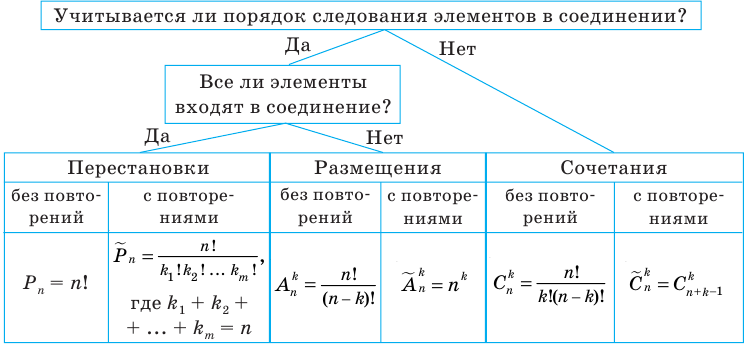
Размещения с повторениями
Для введения понятия размещения с повторениями напомним понятие последовательности, которым вы пользовались в курсе алгебры 9 класса.
Например, рассмотрим последовательность  двузначных чисел, оканчивающихся цифрой 5: 15; 25; 35; 45; 55; 65; 75; 85; 95.
двузначных чисел, оканчивающихся цифрой 5: 15; 25; 35; 45; 55; 65; 75; 85; 95.
У этой последовательности 
Можно сказать, что каждому натуральному числу от 1 до 9 ставится в соответствие единственное двузначное натуральное число, оканчивающееся цифрой 5. Тем самым задается функция, областью определения которой служит множество {1; 2; 3; 4; 5; 6; 7; 8; 9}, а областью значений — множество {15; 25; 35; 45; 55; 65; 75; 85; 95}.
Тогда можно дать следующее определение последовательности.
Функция, областью определения которой является множество натуральных чисел или множество первых п натуральных чисел, называется последовательностью.
Если последовательность определена на множестве всех натуральных чисел, то ее называют бесконечной последовательностью, а если последовательность определена на множестве первых п натуральных чисел, то ее называют конечной.
Размещением с повторениями из п элементов по  называется конечная последовательность, состоящая из
называется конечная последовательность, состоящая из элементов
элементов  некоторого
некоторого -элементного множества М.
-элементного множества М.
Например, из трех цифр множества {1; 5; 7} можно составить такие размещения из двух элементов с повторениями:
(1; 1), (1; 5), (1; 7), (5; 5), (5; 7), (7; 7), (5; 1), (7; 1), (7; 5).
Количество размещений из  элементов по
элементов по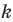 элементов с повторениями обозначается
элементов с повторениями обозначается 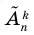 (волнистая линия указывает на возможность повторения элементов). Как видим,
(волнистая линия указывает на возможность повторения элементов). Как видим, 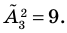
Выясним, сколько всего можно составить размещений с повторениями из 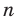 элементов по
элементов по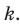 Составление размещения представим себе как последовательное заполнение
Составление размещения представим себе как последовательное заполнение 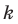 мест, которые мы будем изображать в виде клеточек (рис. 167). На первое место мы можем выбрать один из
мест, которые мы будем изображать в виде клеточек (рис. 167). На первое место мы можем выбрать один из 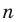 элементов заданного множества (то есть элемент для первой клеточки можно выбрать
элементов заданного множества (то есть элемент для первой клеточки можно выбрать 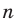 способами). Далее, если элементы можно повторять, то на каждое следующее место мы снова можем выбрать один из
способами). Далее, если элементы можно повторять, то на каждое следующее место мы снова можем выбрать один из 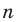 элементов заданного множества.
элементов заданного множества.
Поскольку нам необходимо выбрать элементы и на первое место, и на второе, ..., и на 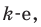 то используем правило произведения и получим формулу для вычисления числа размещений из
то используем правило произведения и получим формулу для вычисления числа размещений из 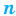 элементов по
элементов по 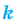 с повторениями:
с повторениями:

Например,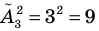 (что совпадает с соответствующим значением, полученным выше).
(что совпадает с соответствующим значением, полученным выше).
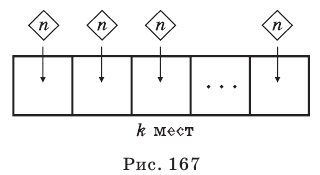
Напомним, что при решении простейших комбинаторных задач важно правильно выбрать формулу, по которой будут проводиться вычисления.Для этого достаточно выяснить:
- — Учитывается ли порядок следования элементов в соединении?
- — Все ли заданные элементы входят в полученное соединение?
Если, например, порядок следования элементов учитывается и из заданных элементов в соединении используется только
заданных элементов в соединении используется только  элементов, то по определению — это размещение из
элементов, то по определению — это размещение из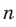 элементов по
элементов по 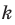 . После определения вида соединения следует также выяснить, могут ли элементы в соединении повторяться, то есть выяснить, какую формулу необходимо использовать — для количества соединений без повторений или с повторениями.
. После определения вида соединения следует также выяснить, могут ли элементы в соединении повторяться, то есть выяснить, какую формулу необходимо использовать — для количества соединений без повторений или с повторениями.
Примеры решения задач:
Пример №23
Найдите количество трехзначных чисел, которые можно составить из цифр 3, 4, 5, 6, 7, 8, 9, если: 1) цифры в числе не повторяются; 2) цифры в числе могут повторяться.
Решение:
Количество трехзначных чисел, которые можно составить из семи цифр 3, 4, 5, 6, 7, 8, 9, равно числу размещений из 7 элементов по 3. Тогда получаем количество трехзначных чисел для задания 1:
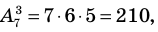 для задания
для задания 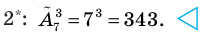
Комментарий:
При выборе формулы принимаем во внимание, что для чисел, которые мы будем составлять, порядок следования элементов учитывается и не все элементы выбираются (только 3 цифры из заданных семи). Следовательно, соответствующее соединение — размещение из 7 элементов по 3 (без повторений для задания 1 и с повторениями для задания 2).
Пример №24
Найдите количество трехзначных чисел, которые можно составить из цифр 3, 4, 5, 6, 7, 8, 0, если: 1) цифры в числе не повторяются; 2) цифры в числе могут повторяться.
Решение:
1) Количество трехзначных чисел, которые можно составить из семи цифр (среди которых нет цифры 0), равно числу размещений из 7 элементов по 3, то есть 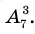 Но среди данных цифр есть цифра 0, с которой не может начинаться трехзначное число. Поэтому из размещений из 7 элементов по 3 необходимо исключить те размещения, в которых первым элементом является Комментарий
Но среди данных цифр есть цифра 0, с которой не может начинаться трехзначное число. Поэтому из размещений из 7 элементов по 3 необходимо исключить те размещения, в которых первым элементом является Комментарий
Выбор формулы производится так же, как и в задаче 1. Следует учесть, что число, составленное из трех цифр, первая из которых цифра 0, не считается трехзначным. Тогда из заданных 7 цифр сначала можно составить все числа, состоящие из 3 цифр (см. задачу 1), а затем из их количества вычесть количество чисел, составленных из трех цифр, начинающихся цифрой 0. В последнем цифра 0. Их количество равно числу размещений из 6 элементов по 2, то есть 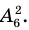 Следовательно, искомое количество трехзначных чисел равно
Следовательно, искомое количество трехзначных чисел равно 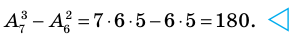
2) На первое место в трехзначном числе мы можем поставить любую цифру, кроме 0, — всего 6 возможностей. Так как цифры в числе могут повторяться, то на второе место можно поставить любую из 7 заданных цифр — имеем 7 возможностей. На третье место снова можно поставить любую из 7 заданных цифр — также 7 возможностей. Поскольку мы должны заполнить и первое место, и второе, и третье, то по правилу произведения получаем, что искомое количество трехзначных чисел равно 6 • 7- 7 = 294. 
Также можно выполнить непосредственное вычисление, последовательно заполняя три места в трехзначном числе и используя правило произведения (см. задание 2). В этом случае, чтобы сделать рассуждения наглядными, удобно изобразить соответствующие разряды в трехзначном числе в виде клеточек, например так:
- 6 возможностей 6 возможностей 5 возможностей
- 6 возможностей 7 возможностей 7 возможностей
Перестановки с повторениями
Если мы будем переставлять цифры в числе 2226 так, чтобы получить разные четырехзначные числа, то получим перестановки с повторениями, составленные из трех двоек и одной шестерки: (2, 2, 2, 6), (2, 2, 6, 2), (2, 6, 2, 2), (6, 2, 2, 2) — всего 4 перестановки (соответственно получаем четыре четырехзначных числа: 2226, 2262, 2622, 6222).
Перестановкой с повторениями состава 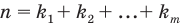 элементов
элементов 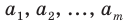 некоторого множества М называется любая конечная последовательность, состоящая из
некоторого множества М называется любая конечная последовательность, состоящая из 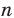 элементов, в которую элемент
элементов, в которую элемент 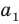 входит
входит 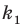 раз,
раз, 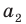 входит
входит 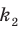 раз, ...,
раз, ..., 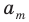 входит
входит 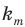 раз.
раз.
Количество перестановок с повторениями из 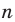 элементов обозначают
элементов обозначают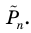 Иногда, чтобы подчеркнуть, что в заданной перестановке из элементов
Иногда, чтобы подчеркнуть, что в заданной перестановке из элементов 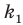 раз повторяется первый элемент
раз повторяется первый элемент 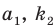 раз повторяется второй элемент
раз повторяется второй элемент 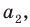
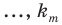 раз повторяется
раз повторяется 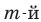 элемент
элемент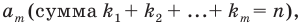 используется также обозначение
используется также обозначение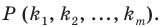 В частности, в рассмотренном примере можно записать:
В частности, в рассмотренном примере можно записать: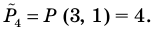
Выясним, сколько всего можно составить перестановок с повторениями из  элементов, если в каждой из перестановок
элементов, если в каждой из перестановок  раз повторяется элемент
раз повторяется элемент 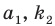 раз повторяется элемент
раз повторяется элемент 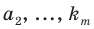 раз повторяется элемент
раз повторяется элемент 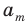
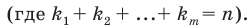 Составление перестановки представим себе как последовательное заполнение
Составление перестановки представим себе как последовательное заполнение 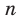 мест, которые мы будем изображать в виде клеточек (на рисунке 168 изображена одна из таких перестановок). Сначала предположим, что все
мест, которые мы будем изображать в виде клеточек (на рисунке 168 изображена одна из таких перестановок). Сначала предположим, что все 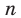 элементов, из которых составляется перестановка, разные. Тогда получаем перестановки без повторений, их количество
элементов, из которых составляется перестановка, разные. Тогда получаем перестановки без повторений, их количество 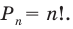 Далее учтем, что при перестановке местами элементов
Далее учтем, что при перестановке местами элементов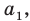 занимающих какие-то
занимающих какие-то 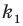 мест (не обязательно подряд), рассмотренная перестановка не изменится (поскольку мы переставляем одинаковые элементы). Элементы, стоящие на
мест (не обязательно подряд), рассмотренная перестановка не изменится (поскольку мы переставляем одинаковые элементы). Элементы, стоящие на 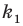 местах, можно переставить
местах, можно переставить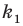 ! способами. Подсчитывая общее количество перестановок из п разных элементов, мы пользовались правилом произведения. Тогда в полученном произведении
! способами. Подсчитывая общее количество перестановок из п разных элементов, мы пользовались правилом произведения. Тогда в полученном произведении 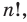 в случае повторения
в случае повторения 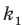 раз элемента
раз элемента 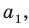 лишним является произведение
лишним является произведение 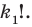 Чтобы избавиться от этого лишнего
Чтобы избавиться от этого лишнего
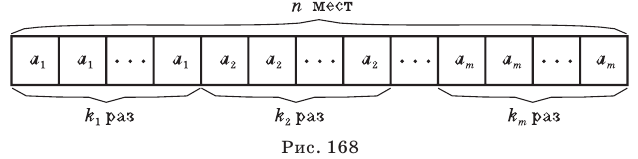
множителя, достаточно число 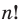 разделить на число
разделить на число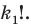 Аналогично, если элемент
Аналогично, если элемент 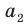 повторяется
повторяется 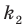 раз, то в полученном произведении
раз, то в полученном произведении 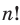 лишним является произведение
лишним является произведение 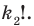 Чтобы избавиться от этого множителя, достаточно число
Чтобы избавиться от этого множителя, достаточно число 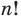 разделить на число
разделить на число 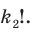 Повторяя эти рассуждения
Повторяя эти рассуждения 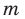 раз, получаем, что количество перестановок с повторениями из
раз, получаем, что количество перестановок с повторениями из  элементов, в каждой из которых
элементов, в каждой из которых 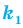 раз повторяется элемент
раз повторяется элемент 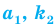 раз повторяется элемент
раз повторяется элемент  раз повторяется элемент
раз повторяется элемент 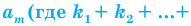
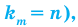 равно
равно
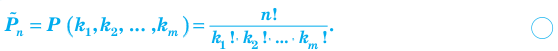
Например, количество перестановок с повторениями, составленных из трех двоек и одной шестерки, равно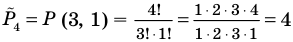 (что совпадает со значением, полученным выше с помощью непосредственного вычисления количества таких перестановок).
(что совпадает со значением, полученным выше с помощью непосредственного вычисления количества таких перестановок).
Примеры решения задач:
Пример №25
Найдите количество разных четырехзначных чисел, которые можно получить при перестановке цифр 1, 1, 4, 4.
Решение:
Искомое количество четырехзначных чисел равно
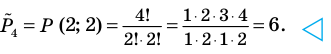
Комментарий:
Поскольку порядок элементов учитывается и для получения четырехзначного числа необходимо использовать все элементы, то искомое соединение — это перестановки с повторениями из 4 элементов. Их количество 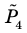 вычисляется по приведенной выше формуле, при этом учитывается состав этих перестановок:
вычисляется по приведенной выше формуле, при этом учитывается состав этих перестановок: 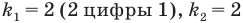 (2 цифры 4),
(2 цифры 4), 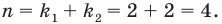
Сочетания с повторениями
Пусть задано 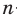 -элементное множество (то есть множество, содержащее
-элементное множество (то есть множество, содержащее 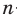 разных элементов). Будем составлять наборы, содержащие
разных элементов). Будем составлять наборы, содержащие 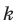 элементов этого множества (один и тот же элемент может входить в набор несколько раз). Два таких набора будем считать одинаковыми тогда и только тогда, когда они имеют одинаковый состав (не учитывая порядок следования элементов в наборе). Такие наборы назовем сочетаниями с повторениями из элементов по
элементов этого множества (один и тот же элемент может входить в набор несколько раз). Два таких набора будем считать одинаковыми тогда и только тогда, когда они имеют одинаковый состав (не учитывая порядок следования элементов в наборе). Такие наборы назовем сочетаниями с повторениями из элементов по 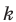 .
.
Таким образом, если задано  -элементное множество, то сочетаниями с повторениями из
-элементное множество, то сочетаниями с повторениями из  элементов по
элементов по  называются наборы, в каждый из которых входит
называются наборы, в каждый из которых входит  заданных элементов (не обязательно разных), отличающихся только составом элементов (хотя бы одним элементом).
заданных элементов (не обязательно разных), отличающихся только составом элементов (хотя бы одним элементом).
Например, из двух букв {a; b} можно составить следующие сочетания с повторениями по четыре элемента: аааа, aaab, aabb, abbb, bbbb. (Отметим, что, в соответствии с принятой выше договоренностью, например, наборы aaab и abaa одинаковы, поскольку они имеют одинаковый состав — три буквы а и одну букву b.)
Количество сочетаний с повторениями из 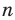 элементов по
элементов по 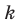 обозначим
обозначим 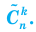 Как видим,
Как видим,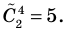
Выясним, сколько всего можно составить сочетаний с повторениями из 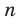 элементов по
элементов по 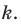 Составление сочетания представим себе как заполнение (в любом порядке)
Составление сочетания представим себе как заполнение (в любом порядке) 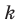 мест, которые мы будем изображать в виде клеточек (рис. 169).
мест, которые мы будем изображать в виде клеточек (рис. 169).
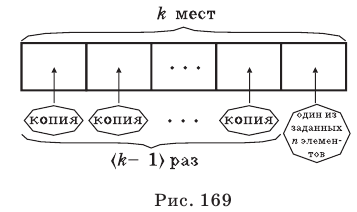
Повторение элемента представим себе как его копирование и помещение копии этого элемента на соответствующем месте. Для того чтобы в последнюю клеточку мы могли поместить любой из заданных элементов, в предыдущие  - 1 клеточки мы должны поместить копии выбранных элементов (см. рис. 169). Но тогда мы должны фактически поместить
- 1 клеточки мы должны поместить копии выбранных элементов (см. рис. 169). Но тогда мы должны фактически поместить 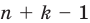 элементов
элементов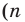 заданных элементов и еще
заданных элементов и еще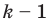 копию) без повторений на
копию) без повторений на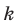 мест (не учитывая порядок следования элементов), а это можно сделать
мест (не учитывая порядок следования элементов), а это можно сделать 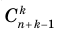 способами. Следовательно,
способами. Следовательно, 
Например, 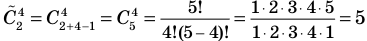 (что совпадает со значением, полученным выше с помощью непосредственного подсчета количества таких сочетаний с повторениями).
(что совпадает со значением, полученным выше с помощью непосредственного подсчета количества таких сочетаний с повторениями).
Примеры решения задач:
Пример №26
В почтовом отделении продаются открытки 5 видов. Найдите количество способов покупки 7 открыток.
Решение:
Искомое число способов равно числу сочетаний с повторениями из 5 элементов по 7, то есть
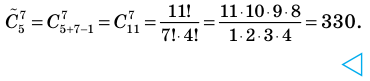
Комментарий:
При выборе открыток порядок их следования не учитывается, значит, соответствующие соединения — сочетания. Условие задачи не запрещает покупать одинаковые открытки, следовательно, используем формулу для числа сочетаний с повторениями: 
Решение более сложных комбинаторных задач
При решении комбинаторных задач с выбором нескольких элементов приходится выяснять, каким правилом необходимо пользоваться, а после этого определять, по каким формулам можно вычислить количество соответствующих соединений. Схема таких рассуждений приведена в таблице 36.
Напомним, что в случае, когда нам приходится выбирать набор, в который входит и первый, и второй, и третий, и т. д. элементы, способы выбора каждого элемента надо перемножать, а если приходится выбирать или первый элемент, или второй, или третий и т. д. элемент, способы выбора каждого элемента надо складывать.
При выборе формулы для подсчета количества соответствующих соединений следует иметь в виду, что в определении только одного вида соединений — сочетаний — не учитывается порядок следования элементов. А те соединения, где учитывается порядок следования элементов (размещения и перестановки), отличаются тем, что в перестановки входят все заданные элементы, а в размещения — не все (конечно, за исключением того случая, когда мы рассматриваем перестановки как частный случай размещения).
Таким образом, как уже отмечалось, для выбора соответствующей формулы достаточно дать ответ на два вопроса.
- — Учитывается ли порядок следования элементов в соединении? (Если «нет», то это сочетания; если «да», то отвечаем на второй вопрос.)
- — Все ли элементы входят в соединение? (Если «да», то это перестановки, если «нет», то это размещения.)
Кроме того, чтобы выбрать соответствующую формулу для соединений (без повторений или с повторениями) необходимо дополнительно выяснить, могут ли элементы в соединении повторяться. Приведем примеры таких рассуждений.
Пример №27
Собрание из 60 членов выбирает председателя, секретаря и трех членов редакционной комиссии по подготовке проекта постановления собрания. Сколькими способами это можно сделать?
Решение:
1) Поскольку надо выбрать и председателя, и секретаря, и членов редакционной комиссии, то будем использовать правило произведения. 2) Сначала выберем председателя и секретаря. Задаем себе вопрос: «Учитывается ли порядок следования элементов?» Ответ: «Да» (потому что первый выбранный будет председателем, а второй — секретарем собрания). Задаем себе второй вопрос: «Все ли элементы входят в соединение?» Ответ: «Нет» (потому что выбираем двух из 60 человек). Следовательно соответствующее соединение будет размещением (без повторений) из 60 элементов по 2, и число таких размещений равно 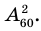 Аналогично выбираем трех членов редакционной коммисии (из оставшихся 58 членов). Снова задаем себе вопрос: «Учитывается ли порядок элементов?» Ответ: «Нет» (потому что независимо от того, в каком порядке будут выбраны члены редакционной комиссии, они все будут выполнять одну и ту же работу). Значит, соответствующее соединение будет сочетанием (без повторений) из 58 элементов по 3, и число таких сочетаний равно
Аналогично выбираем трех членов редакционной коммисии (из оставшихся 58 членов). Снова задаем себе вопрос: «Учитывается ли порядок элементов?» Ответ: «Нет» (потому что независимо от того, в каком порядке будут выбраны члены редакционной комиссии, они все будут выполнять одну и ту же работу). Значит, соответствующее соединение будет сочетанием (без повторений) из 58 элементов по 3, и число таких сочетаний равно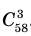 .
.
Тогда выбор и председателя, и секретаря, и трех членов редакционной коммиссии выполняется 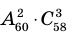 способами, то есть
способами, то есть 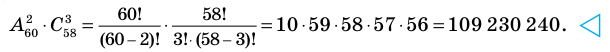
Замечание. Как уже отмечалось, ответ к этой задаче можно не записывать в виде числа, а оставить в виде 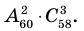 .
.
Некоторые комбинаторные задачи связаны с цифровой записью числа. Анализируя условие и требование таких задач, часто удобно изображать позиции, которые может занимать каждая цифра, в виде пустых клеточек (рис. 170, 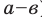 ).
).
Пример №28
Сколько четных трехзначных чисел можно составить из цифр 1, 2, 3, 4, 5:
- 1) если цифры в числе не повторяются;
- 2) если цифры повторяются?
Решение:
Чтобы число было четным, последняя его цифра должна быть четной, то есть из заданных цифр это 2 (рис. 169, б) или 4 (рис. 169, 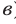 ).
).

Поскольку условию задачи удовлетворяет или первый вариант (последняя цифра 2), или второй (последняя цифра 4), то применим правило суммы. Вычислим количество четных трехзначных чисел в каждом варианте. Задаем себе вопрос: «Учитывается ли порядок следования элементов?» Ответ: «Да» (потому что, например, числа 352 и 532 — разные). Задаем второй вопрос: «Все ли элементы входят в соединение»? Ответ: «Нет» (потому что у нас только два свободных места, а на них «претендуют» 4 цифры (или 5 — если цифры могут повторяться). Следовательно, имеем дело с размещениями: 1) из четырех элементов по два (без повторений) —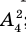 ) из пяти элементов по два (с повторениями) —
) из пяти элементов по два (с повторениями) — 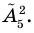 .
.
Количество возможных трехзначных чисел, оканчивающих на 2 и на 4 (см. рис. 170, б и в), одинаково, поэтому по правилу суммы общее количество четных трехзначных чисел будет следующим:
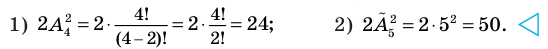
Пример №29
Лифт, в котором находится 9 пассажиров, может останавливаться на 10 этажах. Пассажиры выходят группами по два, три и четыре человека. Сколькими способами эти группы пассажиров могут выходить из лифта на указанных этажах?
Решение:
Так как по условию 9 пассажиров выходят группами по 2, 3 и 4 человека, то лифт должен сделать 3 остановки, чтобы вышли все пассажиры (2 + + 3 + 4 = 9). Отдельно подсчитаем количество способов разделения пассажиров на три группы (по 2, 3 и 4 человека) и отдельно — количество способов выбора трех остановок лифта. Для решения задачи необходимо выбрать и группы пассажиров, и этажи для их выхода, следовательно, будем применять правило произведения.
Из 9 пассажиров можно выбрать группу из 2 человек (не учитывая порядок их выбора, поскольку они выходят на одном этаже) 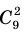 способами. Из семи оставшихся пассажиров можно выбрать группу из 3 человек
способами. Из семи оставшихся пассажиров можно выбрать группу из 3 человек 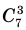 способами. После этого останется 1 группа из 4 членов (формально ее можно выбрать
способами. После этого останется 1 группа из 4 членов (формально ее можно выбрать 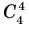 = 1 способом). Следовательно, группы пассажиров можно составить
= 1 способом). Следовательно, группы пассажиров можно составить 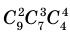 способами.
способами.
Три остановки из 10 этажей можно выбрать 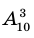 способами (порядок учитывается, поскольку группы могут выходить в разном порядке). Тогда искомое число равно
способами (порядок учитывается, поскольку группы могут выходить в разном порядке). Тогда искомое число равно 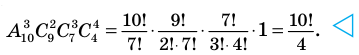
Обратим внимание, что для решения многих комбинаторных задач главным является не столько знание комбинаторных формул, сколько умение построить целесообразную математическую модель заданной ситуации.
Пример №30
В некотором сказочном королевстве не было двух людей с одинаковым набором зубов. Каким может быть максимальное количество жителей этого королевства, если у человека 32 зуба?
Решение:
Пронумеруем все зубы, которые должны быть у человека, числами от 1 до 32. Изобразим набор зубов у каждого жителя королевства в виде 32 клеточек (рис. 171) и в каждую клеточку поставим цифру 1, если на этом месте у рассмотриваемого жителя зуб есть, и цифру 0, если на этом месте у него зуба нет (на рисунке изображен один из возможных наборов зубов).
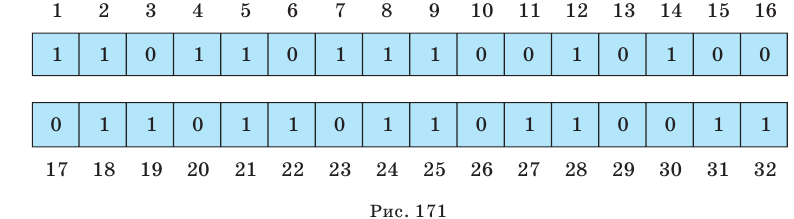
Тогда каждый житель королевства будет закодирован некоторой упорядоченной последовательностью из 32 нулей и единиц. По условию, в королевстве нет людей с одинаковыми наборами зубов, поэтому максимальное количество людей в королевстве равно количеству таких наборов. Эти наборы являются размещениями с повторениями из двух элементов (0 и 1) по 32. Следовательно, их количество равно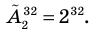 Таким образом, максимальное количество людей в сказочном королевстве может равняться
Таким образом, максимальное количество людей в сказочном королевстве может равняться 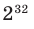 (это приблизительно
(это приблизительно 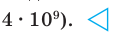
Понятие генеральной совокупности. Выборка из генеральной совокупности
Основными задачами математической статистики являются:
- Разработка методов получения (сбора) информации.
- Построение методов обработки полученной информации.
Определение. Под генеральной совокупностью понимается случайный количественный признак 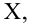 присущий рассматриваемому явлению или каждому элементу исследуемого множества.
присущий рассматриваемому явлению или каждому элементу исследуемого множества.
Определение. Выборкой объема 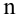 из генеральной совокупности
из генеральной совокупности 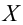 с функцией распределения
с функцией распределения 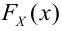 называется последовательность
называется последовательность 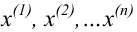 наблюдаемых значений случайной величины
наблюдаемых значений случайной величины 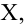 соответствующим
соответствующим  независимым повторениям эксперимента. Выборка должна быть репрезентативной, т.е. наиболее полно и адекватно представлять свойства исследуемого объекта.
независимым повторениям эксперимента. Выборка должна быть репрезентативной, т.е. наиболее полно и адекватно представлять свойства исследуемого объекта.
- Выборка должна быть достаточно большого объема
- Выборка должна представлять все группы исследуемого объекта.
- Выборка должна быть случайной.
Пример. Дана выборка объема 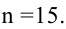
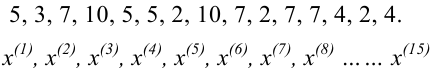
 - варианта.
- варианта.
Определение. Наблюдаемые значения  записанные в порядке возрастания называются вариационным рядом.
записанные в порядке возрастания называются вариационным рядом.
2,2,2,3,4, 4,5,5,5,7,7,7,7, 10, 10.
Определение. Статистический ряд - таблица, первая строка которой - перечень вариант, вторая строка - перечень соответствующих им частот или относительных частот.

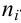 - частота появления значения
- частота появления значения 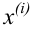 в выборке.
в выборке.
Статистический ряд относительных частот:
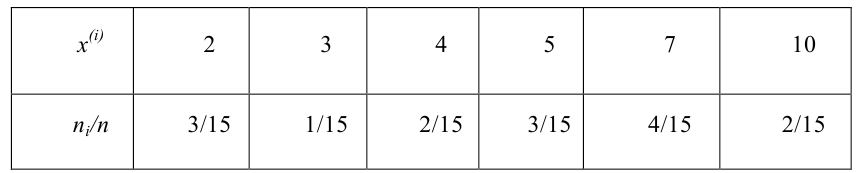
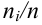 - относительная частота (частость
- относительная частота (частость 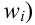
Определение. Размах выборки 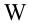 - разность между максимальным и минимальным значением элементов выборки.
- разность между максимальным и минимальным значением элементов выборки.
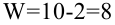
Для большого объема данных или в случае непрерывного признака 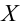 используют группированные выборки, для которых строят интервальный статистический ряд.
используют группированные выборки, для которых строят интервальный статистический ряд. 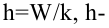 - шаг,
- шаг, 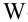 - размах выборки,
- размах выборки, 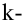 число интервалов разбиения (для выборок большого объема можно, например, выбрать
число интервалов разбиения (для выборок большого объема можно, например, выбрать 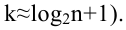
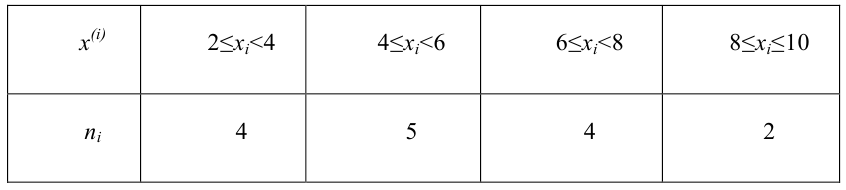
Интервальный ряд относительных частот
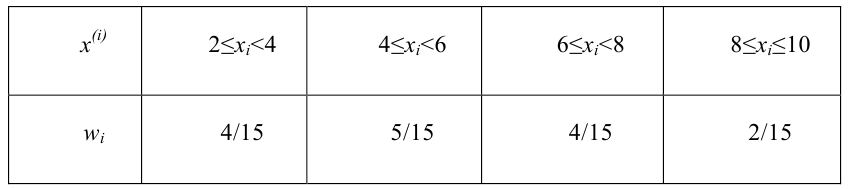
Если в статистическом распределении вместо частот (относительных частот) указать накопленные частоты (относительные накопленные частоты), то такой ряд называют кумулятивным.
Накопленной частотой называется число значений признака  меньших заданного значения
меньших заданного значения  то есть, число вариант
то есть, число вариант  в выборке, отвечающих условию
в выборке, отвечающих условию 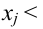
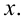
Дискретный кумулятивный ряд:

Интервальный кумулятивный ряд:

Аналогично строятся кумулятивные ряды относительных частот.
Графическое представление выборки
1. Полигон частот (для малых выборок).
Полигон частот - ломаная, отрезки которой соединяют точки с координатами 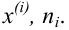
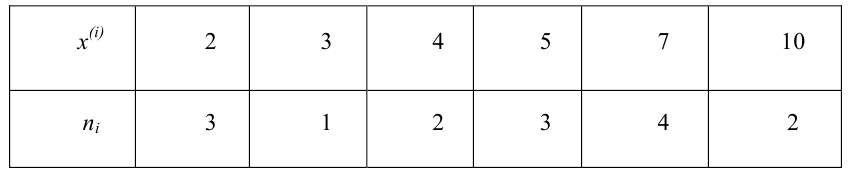
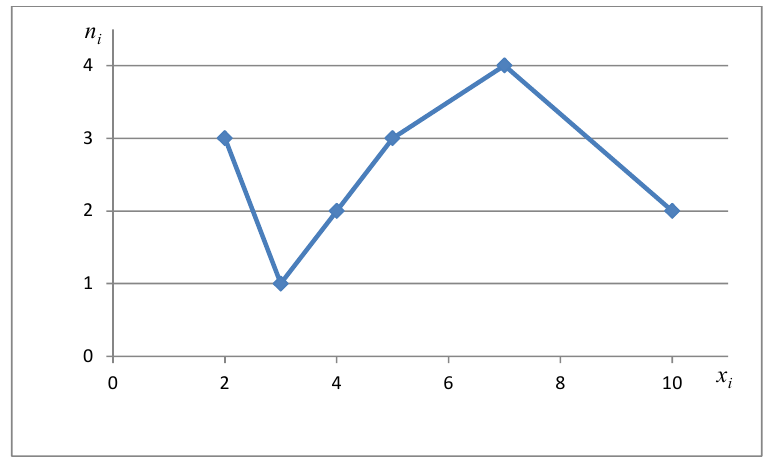
Гистограмма частот (для группированных выборок)
Гистограмма частот - ступенчатая фигура, состоящая из прямоугольников, основанием которых служат частичные интервалы, длиной  а высоты равны отношению
а высоты равны отношению 

Гистограмма относительных частот:
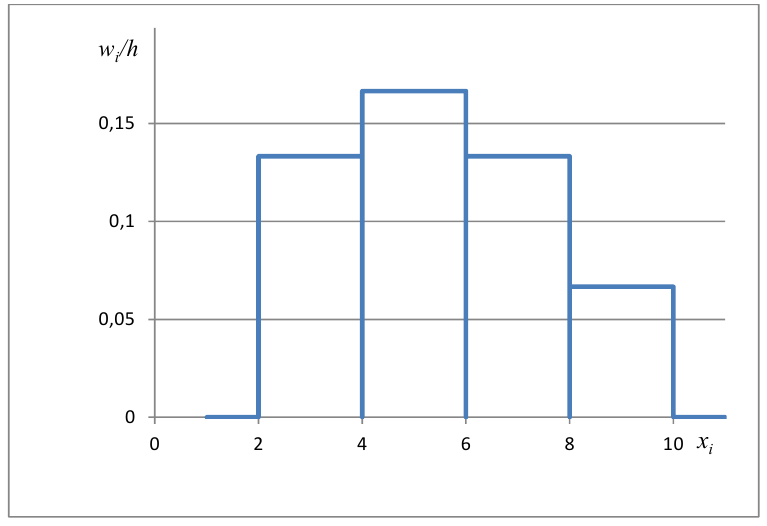
Площадь гистограммы относительных частот равна единице; она даст представление о возможном распределении (плотности) непрерывной генеральной совокупности. 3. Эмпирическая функция распределения.
Эмпирическая функция распределения 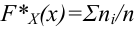 определяет для любого
определяет для любого 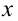 долю вариант
долю вариант 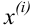 в выборке, для которых справедливо условие
в выборке, для которых справедливо условие 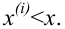
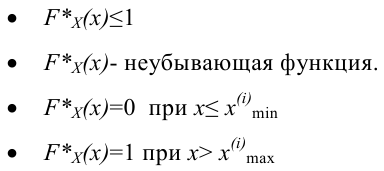
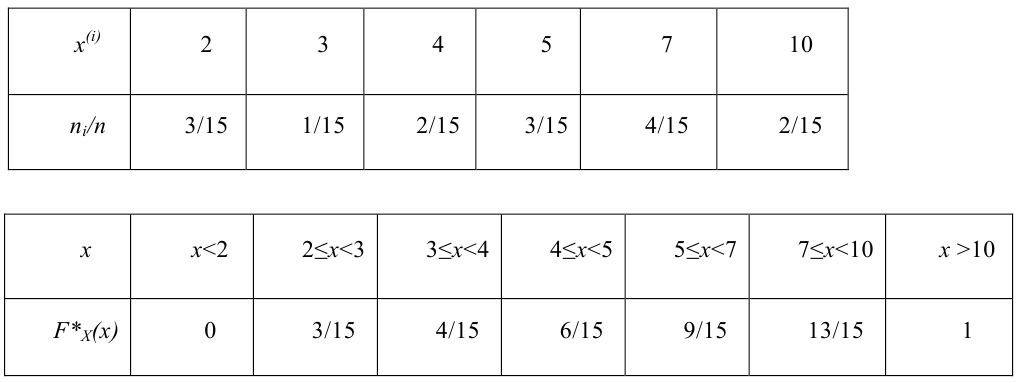
 - накопленная частость.
- накопленная частость.
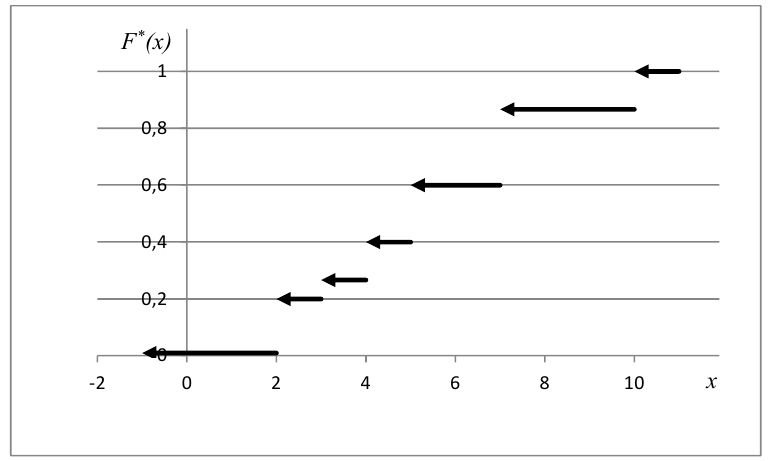
3. Кумулята (для непрерывного признака).

а) наносим точки с координатами 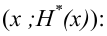

б) соединяем их отрезками
Часто кумуляту обозначают так же, как и эмпирическую функцию распределения, F*x(x).
Точечные оценки
Важной задачей математической статистики является задача оценивания (приближенного определения) по выборочным данным параметров закона распределения признака 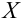 генеральной совокупности. Статистические оценки могут быть точечными и интервальными. Точечной оценкой называют оценку, которая определяется одним числом.
генеральной совокупности. Статистические оценки могут быть точечными и интервальными. Точечной оценкой называют оценку, которая определяется одним числом.
Пусть 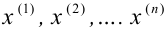 - выборка объема
- выборка объема 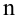 из генеральной совокупности с функцией распределения
из генеральной совокупности с функцией распределения 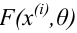 с неизвестным параметром
с неизвестным параметром 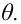 Произвольная функция элементов выборки
Произвольная функция элементов выборки 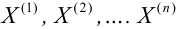 называется статистикой.
называется статистикой.
Значение статистики 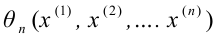 является точечной оценкой параметра
является точечной оценкой параметра 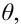 если оно приблизительно равно оцениваемому параметру и может заменить его с достаточной степенью точности в статистических расчетах.
если оно приблизительно равно оцениваемому параметру и может заменить его с достаточной степенью точности в статистических расчетах.
Оценка 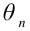 называется несмещенной, если математическое ожидание оценки равно оцениваемому параметру, т.е.
называется несмещенной, если математическое ожидание оценки равно оцениваемому параметру, т.е. 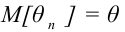
Оценка 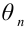 называется состоятельной, если для любого
называется состоятельной, если для любого 
Оценка  называется эффективной, если при фиксированном
называется эффективной, если при фиксированном  она имеет наименьшую дисперсию.
она имеет наименьшую дисперсию.
Точечные оценки числовых характеристик распределения (метод моментов).
Пусть 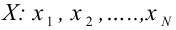 - генеральная совокупность объема
- генеральная совокупность объема  с функцией распределения
с функцией распределения
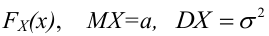
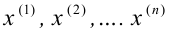 - выборка объема
- выборка объема 
Генеральной средней 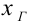 называется среднее арифметическое значений элементов генеральной совокупности.
называется среднее арифметическое значений элементов генеральной совокупности.
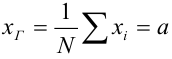
Выборочной средней  называется среднее арифметическое элементов выборки.
называется среднее арифметическое элементов выборки.
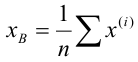
Теорема:  является несмещенной оценкой
является несмещенной оценкой 
Доказательство: 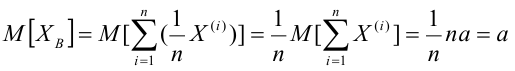
Замечание. 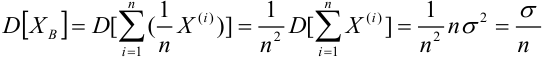
Например: если 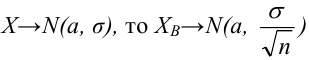
Генеральной дисперсией  называют величину
называют величину 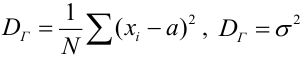
Выборочной дисперсией 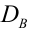 называют величину
называют величину 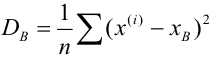
Теорема: выборочная дисперсия 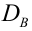 является смещенной оценкой генеральной дисперсии.
является смещенной оценкой генеральной дисперсии.
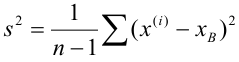 - исправленная выборочная дисперсия, или несмещенная оценка дисперсии генеральной совокупности.
- исправленная выборочная дисперсия, или несмещенная оценка дисперсии генеральной совокупности.
Если математическое ожидание генеральной совокупности известно, то в качестве несмещенной оценки генеральной совокупности используется
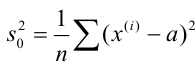
Заключение (основные формулы):
1) Оценка математического ожидания генеральной совокупности
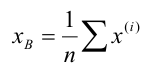
2) Точечные оценки дисперсии генеральной совокупности
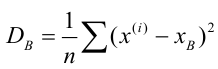 - смещенная оценка дисперсии генеральной совокупности
- смещенная оценка дисперсии генеральной совокупности
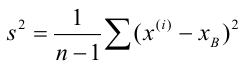 - несмещенная оценка дисперсии генеральной совокупности
- несмещенная оценка дисперсии генеральной совокупности
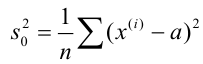 несмещенная оценка дисперсии генеральной совокупности, если известно ее математическое ожидание.
несмещенная оценка дисперсии генеральной совокупности, если известно ее математическое ожидание.
Замечания.
А). На практике в качестве характеристик среднего значения генеральной совокупности также рассматривают моду и медиану распределения. По выборке медиану оценивают по формулам:
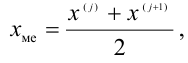 если
если  - четное;
- четное;  если
если 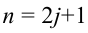 - нечетное.
- нечетное.
Мода - наиболее часто встречающееся в выборке значение признака 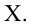
Б). В качестве характеристик вариации рассматривают также выборочное
среднеквадратичное отклонение 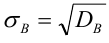 и коэффициент вариации
и коэффициент вариации 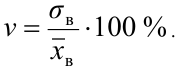
Коэффициент вариации применяют для сравнения вариации признаков сильно отличающихся по величине, или имеющих разные единицы измерения (разные наименования).
Метод наибольшего (максимального) правдоподобия.
Метод наибольшего правдоподобия - это метод оценки неизвестных параметров
распределения, в основе которого - поиск максимального значения функции
правдоподобия.
Достоинства:
- Может использоваться в случае, когда теоретические моменты распределения отсутствуют.
- Оценки в основном состоятельны и эффективны.
- Оценки распределены асимптотически нормально.
- Наиболее полно используются данные о выборке (особенно полезны в случае малых выборок).
Недостатки:
- Оценки могут быть смещенными.
- Сложность вычислений.
- Не всегда совпадают с оценками по методу моментов.
1. Дискретная случайная величина 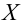
Пусть 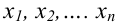 -выборка объема
-выборка объема 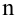 из генеральной совокупности
из генеральной совокупности 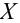 с известной функцией распределения
с известной функцией распределения 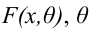 - неизвестный параметр, который нужно определить по выборке,
- неизвестный параметр, который нужно определить по выборке, 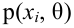 - вероятность того, что в результате испытания
- вероятность того, что в результате испытания  примет значение
примет значение 
Определение. Функцией правдоподобия дискретной случайной величины называется функция аргумента 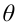
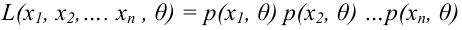
В качестве точечной оценки 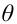 принимается
принимается 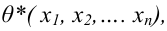 при которой
при которой 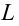 принимает для данной выборки наибольшее значение.
принимает для данной выборки наибольшее значение.
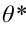 -оценка наибольшего правдоподобия.
-оценка наибольшего правдоподобия.
Определение. Логарифмической функцией правдоподобия называют функцию 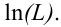 Алгоритм построения
Алгоритм построения 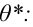
А) осуществляем выборку 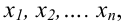 вычисляем вероятности
вычисляем вероятности 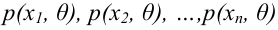 и строим
и строим 
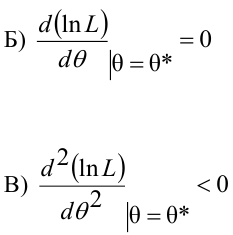
Пример:
Найти методом максимального правдоподобия оценку параметра 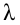 распределения Пуассона.
распределения Пуассона.
Решение:
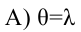
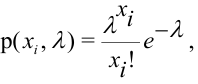 где
где  число испытаний?
число испытаний? 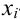 -число появлений события в
-число появлений события в  опыте
опыте
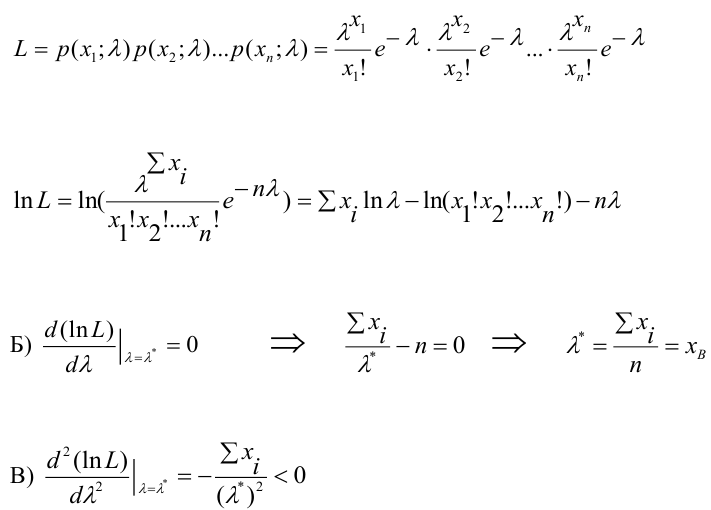
2. Непрерывная случайная величина 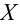
Пусть 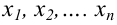 -выборка объема
-выборка объема 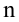 из генеральной совокупности
из генеральной совокупности 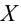 с известной функцией распределения
с известной функцией распределения 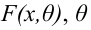 - неизвестный параметр, который нужно определить по выборке,
- неизвестный параметр, который нужно определить по выборке, 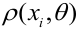 - плотность распределения вероятностей
- плотность распределения вероятностей  в точке
в точке 
Определение. Функцией правдоподобия непрерывной случайной величины 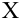 называют
называют 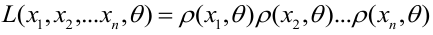
Пример. Найти методом максимального правдоподобия оценку параметра  показательного распределения:
показательного распределения:
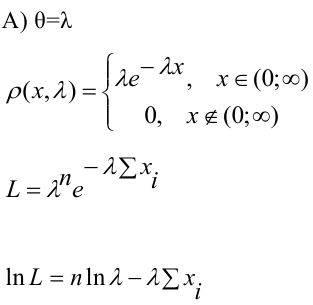
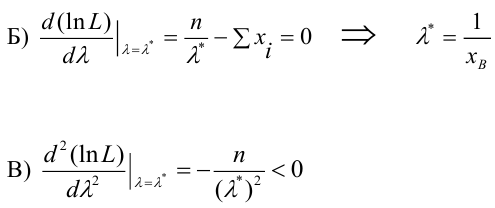
Доверительные интервалы для параметров генеральной совокупности
Пусть 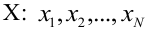 - генеральная совокупность с функцией распределения
- генеральная совокупность с функцией распределения 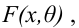 зависящей от параметра
зависящей от параметра 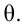
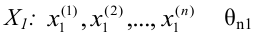 оценка
оценка 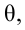 полученная по выборке
полученная по выборке 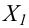
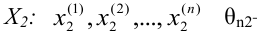 оценка полученная по выборке
оценка полученная по выборке 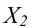

Задача - по выборке объема 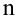 построить интервал, которому с вероятностью
построить интервал, которому с вероятностью 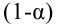 принадлежит истинное значение параметра
принадлежит истинное значение параметра 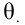

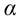 - уровень значимости,
- уровень значимости, 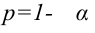 - доверительная вероятность,
- доверительная вероятность, 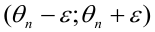 -доверительный интервал.
-доверительный интервал.
Определение. Доверительным интервалом для параметра  генеральной совокупности
генеральной совокупности  с функцией распределения
с функцией распределения 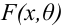 называется интервал
называется интервал 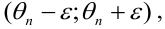 в который истинное значение параметра
в который истинное значение параметра  попадает с вероятностью
попадает с вероятностью 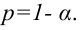
Пример №31
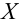 имеет нормальное распределение с параметрами
имеет нормальное распределение с параметрами 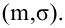 Найти доверительный интервал для математического ожидания
Найти доверительный интервал для математического ожидания  по результатам
по результатам  наблюдений при условии, что
наблюдений при условии, что 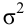 известна, а доверительная вероятность равна
известна, а доверительная вероятность равна 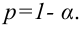
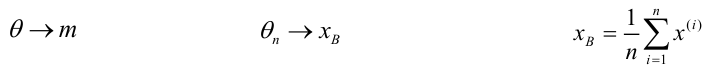
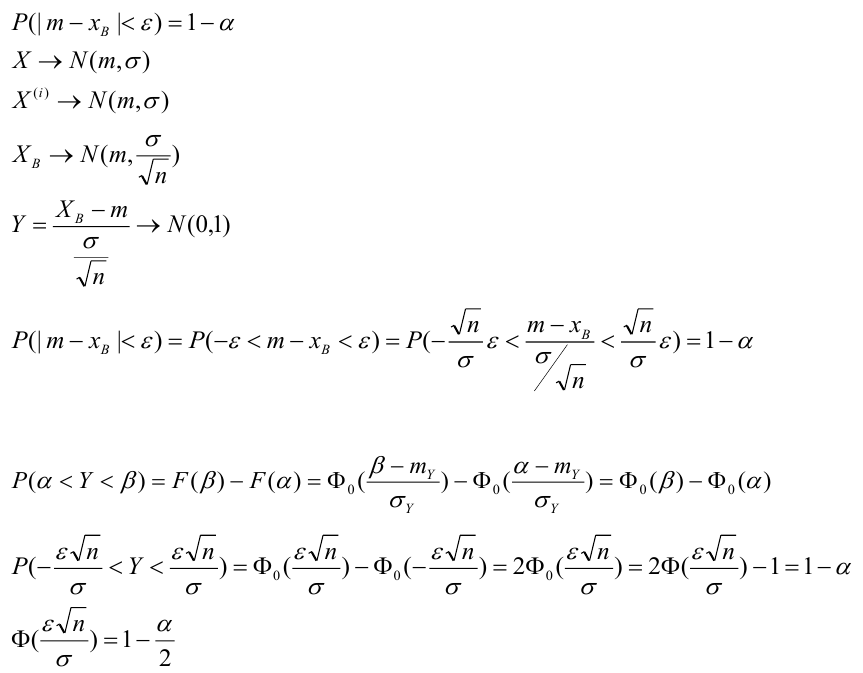
Определение. Квантилью порядка 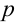 непрерывного теоретического распределения случайной величины
непрерывного теоретического распределения случайной величины 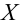 называется действительное число
называется действительное число 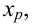 удовлетворяющее уравнению:
удовлетворяющее уравнению:
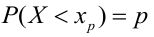 ИЛИ
ИЛИ 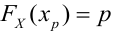
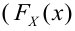 - функция распределения
- функция распределения 
Введем обозначения 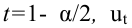 - квантиль порядка
- квантиль порядка 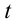 стандартного нормального распределения. Тогда
стандартного нормального распределения. Тогда
Пример №32
 имеет нормальное распределение с параметрами
имеет нормальное распределение с параметрами  Найти доверительный интервал для
Найти доверительный интервал для 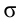 по результатам
по результатам 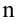 наблюдений при условии, что
наблюдений при условии, что 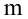 известно, а доверительная вероятность равна
известно, а доверительная вероятность равна 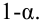
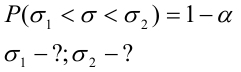
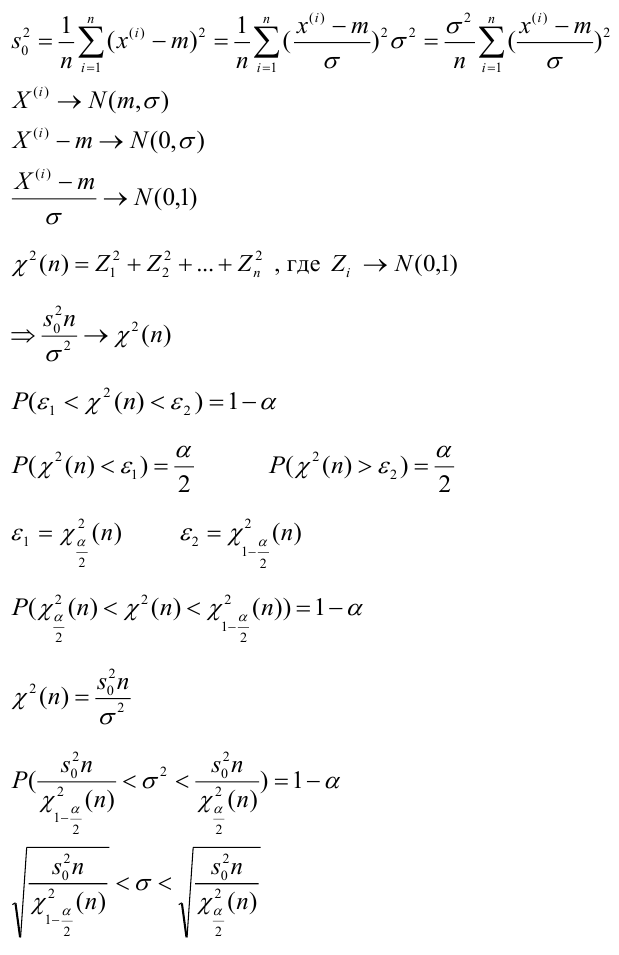
Примечание:
1. Доверительный интервал для математического ожидания в случае, если дисперсия генеральной совокупности неизвестна:
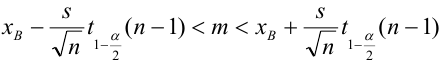
2. Доверительный интервал для дисперсии при неизвестном математическом ожидании:
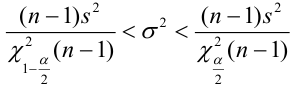
Пример №33
В результате тестирования группа студентов из 25 человек набрала баллы: 4, 0, 3, 4, 1, 0, 3, 1, 0, 1, 0, 0, 3, 1, 0, 1, 1, 3, 2, 3, 4, 2, 1, 2, 3. Построить дискретный вариационный ряд. Построить полигон распределения частот и относительных частот, кумуляту и огиву статистического распределения.
Решение. Проранжируем исходные данные, подсчитаем частоту вариант: 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4, 4 (табл. 1.3).
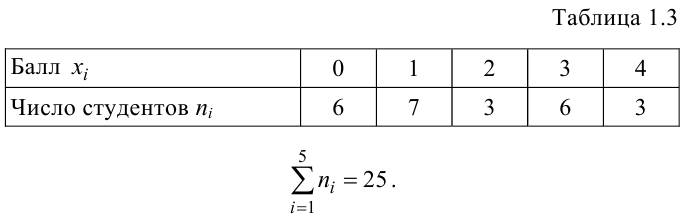
Построим полигон частот.
Полигон относительных частот будет иметь следующий вид.
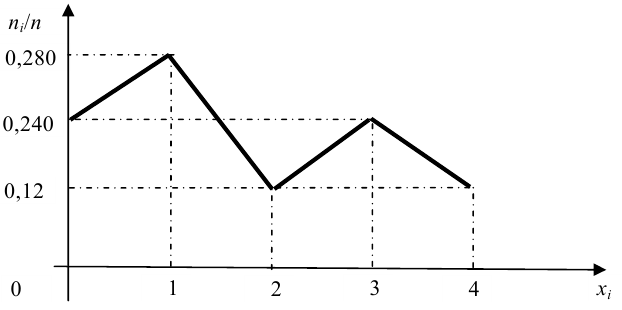
Вычислим накопленные частоты и частости (табл. 1.4).
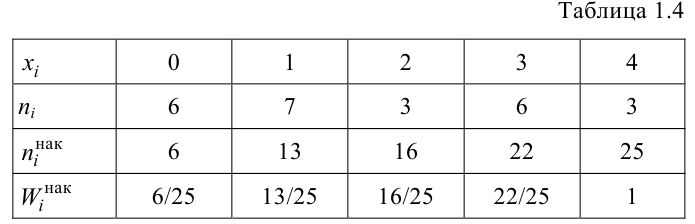
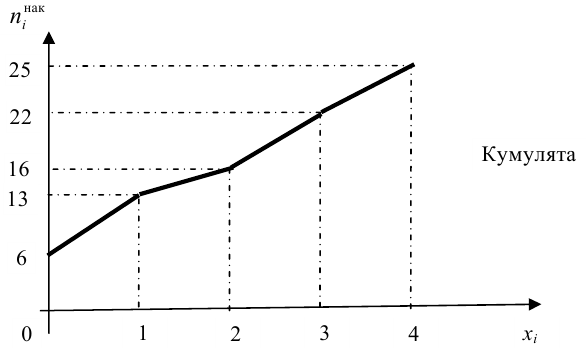
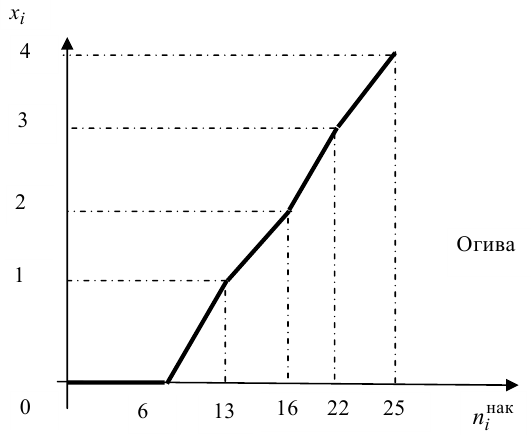
Пример №34
Результаты измерения производительности труда 100 рабочих имеют следующий вид:

Построить интервальный вариационный ряд. Построить гистограмму (полигон) частот. Построить кумуляту и огиву.
Решение. В случае, когда число вариант  достаточно велико
достаточно велико  составляют интервальный вариационный ряд. Наибольшим значением случайной величины является 95, а наименьшим
составляют интервальный вариационный ряд. Наибольшим значением случайной величины является 95, а наименьшим 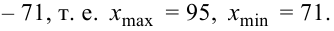
Для определения величины интервала используем формулу Стерджссса:
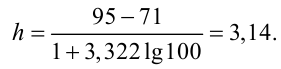
Возьмем за ширину интервала 
Интервальный ряд представлен в табл. 1.5.
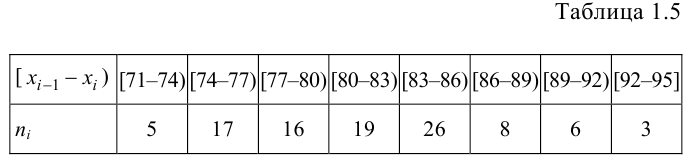
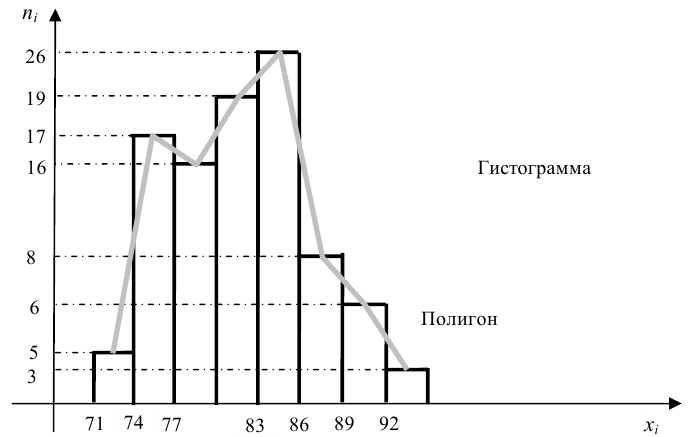
Гистограмма относительных частот является аналогом дифференциальной функции случайной величины.
Найдем накопленные частоты 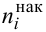 для каждого из интервалов данного интервального вариационного ряда (табл. 1.6).
для каждого из интервалов данного интервального вариационного ряда (табл. 1.6).

Кумулятивный ряд представлен в табл. 1.7.
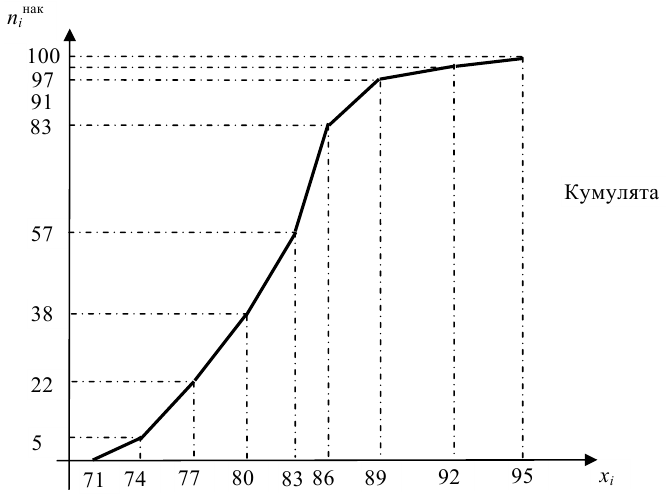
| Рекомендую подробно изучить предметы: |
| Ещё лекции с примерами решения и объяснением: |